
Python Scrapy: Build A LinkedIn People Profile Scraper [2026]
In this guide for our "How To Scrape X With Python Scrapy" series, we're going to look at how to build a Python Scrapy spider that will scrape LinkedIn.com public people profiles.
LinkedIn is the most up-to-date and extensive source of professional people profiles on the internet. As a result it is the most popular web scraping target of recruiting, HR and lead generation companies.
In this article we will focus on building a production LinkedIn spider using Python Scrapy that will scrape LinkedIn Public People Profiles.
In this guide we will go through:
- How To Build a LinkedIn People Profile Scraper
- Storing Data To Database Or S3 Bucket
- Bypassing LinkedIn's Anti-Bot Protection
- Monitoring To Our LinkedIn People Scraper
- Scheduling & Running Our Scraper In The Cloud
The full code for this LinkedIn People Profile Spider is available on Github here.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
If you prefer to follow along with a video then check out the video tutorial version here:
How To Build a LinkedIn People Profile Scraper
Scraping LinkedIn People Profiles is pretty straight forward, once you have the HTML response (this is the hard part, which we will discuss later).
We just need a list of LinkedIn people profile usernames and send requests to the LinkedIn's People Profiles endpoints.
'https://www.linkedin.com/in/reidhoffman/'
Which looks like this:

From here, we just need to create a Scrapy spider that will parse the profile data from the page.
The following is a simple Scrapy spider that will request the people profile page for every username in the profile_list list, and then parse the people profile from the response.
import scrapy
class LinkedInPeopleProfileSpider(scrapy.Spider):
name = "linkedin_people_profile"
custom_settings = {
'FEEDS': { 'data/%(name)s_%(time)s.jsonl': { 'format': 'jsonlines',}}
}
def start_requests(self):
profile_list = ['reidhoffman']
for profile in profile_list:
linkedin_people_url = f'https://www.linkedin.com/in/{profile}/'
yield scrapy.Request(url=linkedin_people_url, callback=self.parse_profile, meta={'profile': profile, 'linkedin_url': linkedin_people_url})
def parse_profile(self, response):
item = {}
item['profile'] = response.meta['profile']
item['url'] = response.meta['linkedin_url']
"""
SUMMARY SECTION
"""
summary_box = response.css("section.top-card-layout")
item['name'] = summary_box.css("h1::text").get().strip()
item['description'] = summary_box.css("h2::text").get().strip()
## Location
try:
item['location'] = summary_box.css('div.top-card__subline-item::text').get()
except:
item['location'] = summary_box.css('span.top-card__subline-item::text').get().strip()
if 'followers' in item['location'] or 'connections' in item['location']:
item['location'] = ''
item['followers'] = ''
item['connections'] = ''
for span_text in summary_box.css('span.top-card__subline-item::text').getall():
if 'followers' in span_text:
item['followers'] = span_text.replace(' followers', '').strip()
if 'connections' in span_text:
item['connections'] = span_text.replace(' connections', '').strip()
"""
ABOUT SECTION
"""
item['about'] = response.css('section.summary div.core-section-container__content p::text').get(default='')
"""
EXPERIENCE SECTION
"""
item['experience'] = []
experience_blocks = response.css('li.experience-item')
for block in experience_blocks:
experience = {}
## organisation profile url
experience['organisation_profile'] = block.css('h4 a::attr(href)').get(default='').split('?')[0]
## location
experience['location'] = block.css('p.experience-item__location::text').get(default='').strip()
## description
try:
experience['description'] = block.css('p.show-more-less-text__text--more::text').get().strip()
except Exception as e:
print('experience --> description', e)
try:
experience['description'] = block.css('p.show-more-less-text__text--less::text').get().strip()
except Exception as e:
print('experience --> description', e)
experience['description'] = ''
## time range
try:
date_ranges = block.css('span.date-range time::text').getall()
if len(date_ranges) == 2:
experience['start_time'] = date_ranges[0]
experience['end_time'] = date_ranges[1]
experience['duration'] = block.css('span.date-range__duration::text').get()
elif len(date_ranges) == 1:
experience['start_time'] = date_ranges[0]
experience['end_time'] = 'present'
experience['duration'] = block.css('span.date-range__duration::text').get()
except Exception as e:
print('experience --> time ranges', e)
experience['start_time'] = ''
experience['end_time'] = ''
experience['duration'] = ''
item['experience'].append(experience)
"""
EDUCATION SECTION
"""
item['education'] = []
education_blocks = response.css('li.education__list-item')
for block in education_blocks:
education = {}
## organisation
education['organisation'] = block.css('h3::text').get(default='').strip()
## organisation profile url
education['organisation_profile'] = block.css('a::attr(href)').get(default='').split('?')[0]
## course details
try:
education['course_details'] = ''
for text in block.css('h4 span::text').getall():
education['course_details'] = education['course_details'] + text.strip() + ' '
education['course_details'] = education['course_details'].strip()
except Exception as e:
print("education --> course_details", e)
education['course_details'] = ''
## description
education['description'] = block.css('div.education__item--details p::text').get(default='').strip()
## time range
try:
date_ranges = block.css('span.date-range time::text').getall()
if len(date_ranges) == 2:
education['start_time'] = date_ranges[0]
education['end_time'] = date_ranges[1]
elif len(date_ranges) == 1:
education['start_time'] = date_ranges[0]
education['end_time'] = 'present'
except Exception as e:
print("education --> time_ranges", e)
education['start_time'] = ''
education['end_time'] = ''
item['education'].append(education)
yield item
Now when we run our scraper:
scrapy crawl linkedin_people_profile
The output of this code will look like this:
{
"profile": "reidhoffman",
"url": "https://www.linkedin.com/in/reidhoffman/",
"name": "Reid Hoffman",
"description": "All aspects of consumer internet and software. Focus is on product development, innovation, business strategy, and finance, but includes general management, operations, business operations, business development, talent management, and marketing. Strong experience in both seed-stage companies (paypal, linkedin, facebook, zynga, last.fm, flickr) and growth companies (mozilla, linkedin, zynga, paypal.)",
"location": "United States",
"followers": "3M",
"connections": "500+",
"experience": [{"organisation_profile": "https://www.linkedin.com/company/greylock-partners", "location": "Menlo Park, CA", "description": "Greylock partners with entrepreneurs to build market-transforming companies. Notable Greylock portfolio includes companies like Linkedin, Airbnb, Facebook, Workday, Roblox, Palo Alto Networks, Dropbox, Pure Storage, Convoy, Pandora, Instagram and Discord. I represent Greylock on the boards of Aurora, Coda, Convoy, Entrepreneur First, Magical Tome, Nauto, and Neeva.", "start_time": "Nov 2009", "end_time": "present", "duration": "13 years"}, {"organisation_profile": "https://www.linkedin.com/company/microsoft", "location": "Seattle, Washington, United States", "description": "Microsoft's mission is to empower every person and every organization on the planet to achieve more.", "start_time": "Mar 2017", "end_time": "present", "duration": "5 years 8 months"}, {"organisation_profile": "", "location": "Palo Alto, California, United States", "description": "Throughout the history of computing, humans have had to learn to speak the language of machines. In the new paradigm, machines will understand our language.", "start_time": "Mar 2022", "end_time": "present", "duration": "8 months"}, {"organisation_profile": "https://www.linkedin.com/company/auroradriver", "location": "Palo Alto, California, United States", "description": "Aurora delivers the benefits of self-driving technology quickly and safely around the world.", "start_time": "Jan 2018", "end_time": "present", "duration": "4 years 10 months"}, {"organisation_profile": "https://www.linkedin.com/company/jobyaviation", "location": "Santa Cruz, California, United States", "description": "Making our city's transportation grid 3-D: safe, climate healthier, and fast.", "start_time": "Aug 2021", "end_time": "present", "duration": "1 year 3 months"}, {"organisation_profile": "https://www.linkedin.com/company/convoy-inc", "location": "Greater Seattle Area", "description": "On demand local and regional trucking.", "start_time": "Jan 2016", "end_time": "present", "duration": "6 years 10 months"}, {"organisation_profile": "https://www.linkedin.com/company/nauto", "location": "Palo Alto, CA", "description": "Artificial intelligence cloud data platform to improve transportation safety, develop autonomy, and improve urban mobility.", "start_time": "Aug 2017", "end_time": "present", "duration": "5 years 3 months"}, {"organisation_profile": "https://www.linkedin.com/company/codainc", "location": "Palo Alto, CA", "description": "Docs are the new apps. Coda is on a mission to make documents the platform for applications. Coda reinvents shared, live-data in docs from the ground up. Coda docs erase the boundaries between words and data. And make it so everyone can work together, in their own way, off a single source of truth.", "start_time": "Oct 2014", "end_time": "present", "duration": "8 years 1 month"}, {"organisation_profile": "https://www.linkedin.com/company/neevaco", "location": "Mountain View, California, United States", "description": "Neeva is search re-imagined. Always ad-free, private, and personal. Co-founded by Sridhar Ramaswamy (ex-SVP of Ads at Google) and Vivek Raghunathan (ex-VP of Monetization at YouTube).", "start_time": "Jan 2019", "end_time": "present", "duration": "3 years 10 months"}, {"organisation_profile": "https://www.linkedin.com/company/entrepreneur-first", "location": "London, United Kingdom", "description": "Turning exceptional individuals into exceptional founders.", "start_time": "Sep 2017", "end_time": "present", "duration": "5 years 2 months"}, {"organisation_profile": "https://www.linkedin.com/company/blockstream", "location": "San Francisco Bay Area", "description": "Blockstream was founded to develop new ways to accelerate innovation in crypto currencies, open assets and smart contracts.", "start_time": "Nov 2014", "end_time": "present", "duration": "8 years"}, {"organisation_profile": "https://www.linkedin.com/company/reinventcapital", "location": "", "description": "Reinvent partners with bold leaders of category-defining companies to help them grow and innovate at scale.", "start_time": "Aug 2018", "end_time": "present", "duration": "4 years 3 months"}, {"organisation_profile": "", "location": "Oxford, United Kingdom", "description": "A wonderful, modern graduate college at Oxford. My alma matter college.", "start_time": "Oct 2016", "end_time": "present", "duration": "6 years 1 month"}],
"education": [{"organisation": "University of Oulu", "organisation_profile": "https://www.linkedin.com/school/university-of-oulu/", "course_details": "Honorary Doctor Faculty of Information Technology and Electrical Engineering", "description": "The University of Oulu is an international science university which creates new knowledge, well-being and innovations for the future through research and education. The University of Oulu, founded in 1958, is one of the biggest and most multidisciplinary universities in Finland.", "start_time": "2020", "end_time": "2020"}, {"organisation": "Babson College", "organisation_profile": "https://www.linkedin.com/school/babson-college/", "course_details": "Honorary Doctor of Laws Entrepreneurship/Entrepreneurial Studies", "description": "", "start_time": "2012", "end_time": "2012"}, {"organisation": "Oxford University", "organisation_profile": "https://www.linkedin.com/school/oxforduni/", "course_details": "M.St. Philosophy", "description": "Activities and Societies: Wolfson College, Matthew Arnold Prize (Proxime Accessit)", "start_time": "1990", "end_time": "1993"}, {"organisation": "Stanford University", "organisation_profile": "https://www.linkedin.com/school/stanford-university/", "course_details": "B.S. Symbolic Systems", "description": "Activities and Societies: Marshall Scholar, Dinkelspiel Award, Golden Grant, Founder of the Symbolic Systems Forum", "start_time": "1985", "end_time": "1990"}, {"organisation": "The Putney School", "organisation_profile": "", "course_details": "Diploma Highschool", "description": "Activities and Societies: X-country skiing, soccer, rebuilding Nova Scotia house", "start_time": "1982", "end_time": "1985"}]
}
This spider scrapes the following data from the LinkedIn profile page:
- Name
- Description
- Number of followers
- Number of connections
- Location
- About
- Experienes - organisation name, organisation profile link, position, start & end dates, description.
- Education - organisation name, organisation profile link, course details, start & end dates, description.
You can expand this spider to scrape other details like volunteering, certifications, skills, publications, etc. by simply adding more parsers to the parse_profile method.
Storing Data To Database Or S3 Bucket
With Scrapy, it is very easy to save our scraped data to JSON lines files, databases or file storage systems (like AWS S3) using Scrapy's Feed Export functionality.
To configure Scrapy to save all our data to a new JSON lines file everytime we run the scraper we simply need to create a Scrapy Feed and configure a dynamic file path.
If we add the following code to our settings.py file, Scrapy will create a new JSON lines file in our data folder using the spider name and time the spider was run.
# settings.py
FEEDS = {
'data/%(name)s_%(time)s.jsonl': {
'format': 'jsonlines',
}
}
If you would like to save your JSON files to a AWS S3 bucket then check out our Saving CSV/JSON Files to Amazon AWS S3 Bucket guide here
Or if you would like to save your data to another type of database then be sure to check out these guides:
- Saving Data to CSV
- Saving Data to SQLite Database
- Saving Data to MySQL Database
- Saving Data to Postgres Database
Bypassing LinkedIn's Anti-Bot Protection
As mentioned above, LinkedIn has one of the most aggressive anti-scraping systems on the internet, making it very hard to scrape.
It uses a combination of IP address, headers, browser & TCP fingerprinting to detect scrapers and block them.
As you might have seen already, if you run the above code LinkedIn is likely blocking your requests and returning their login page like this:

This Scrapy spider is only designed to scrape public LinkedIn people profiles that don't require you to login to view. Scraping behind LinkedIn's login is significantly harder and opens yourself up to much higher legal risks.
To bypass LinkedIn's anti-scraping system will need to using very high quality rotating residential/mobile proxies, browser-profiles and a fortified headless browser.
We have written guides about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Scrapy Proxy Guide: How to Integrate & Rotate Proxies With Scrapy
- Scrapy User Agents: How to Manage User Agents When Scraping
- Scrapy Proxy Waterfalling: How to Waterfall Requests Over Multiple Proxy Providers
However, if you don't want to implement all this anti-bot bypassing logic yourself, the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator which integrates with over 20+ proxy providers and finds the proxy solution that works best for LinkedIn for you.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
To use the ScrapeOps Proxy Aggregator with our LinkedIn Scrapy Spider, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. You can test it out with Curl using the command below:
curl 'https://proxy.scrapeops.io/v1/?api_key=YOUR_API_KEY&url=https://www.linkedin.com/in/reidhoffman/'
We can integrate the proxy easily into our scrapy project by installing the ScrapeOps Scrapy Proxy SDK a Downloader Middleware. We can quickly install it into our project using the following command:
pip install scrapeops-scrapy-proxy-sdk
And then enable it in your project in the settings.py file.
## settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_PROXY_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy_proxy_sdk.scrapeops_scrapy_proxy_sdk.ScrapeOpsScrapyProxySdk': 725,
}
Now when we make requests with our scrapy spider they will be routed through the proxy and LinkedIn won't block them.
Full documentation on how to integrate the ScrapeOps Proxy here.
Monitoring Your LinkedIn People Profile Scraper
When scraping in production it is vital that you can see how your scrapers are doing so you can fix problems early.
You could see if your jobs are running correctly by checking the output in your file or database but the easier way to do it would be to install the ScrapeOps Monitor.
ScrapeOps gives you a simple to use, yet powerful way to see how your jobs are doing, run your jobs, schedule recurring jobs, setup alerts and more. All for free!
Live demo here: ScrapeOps Demo
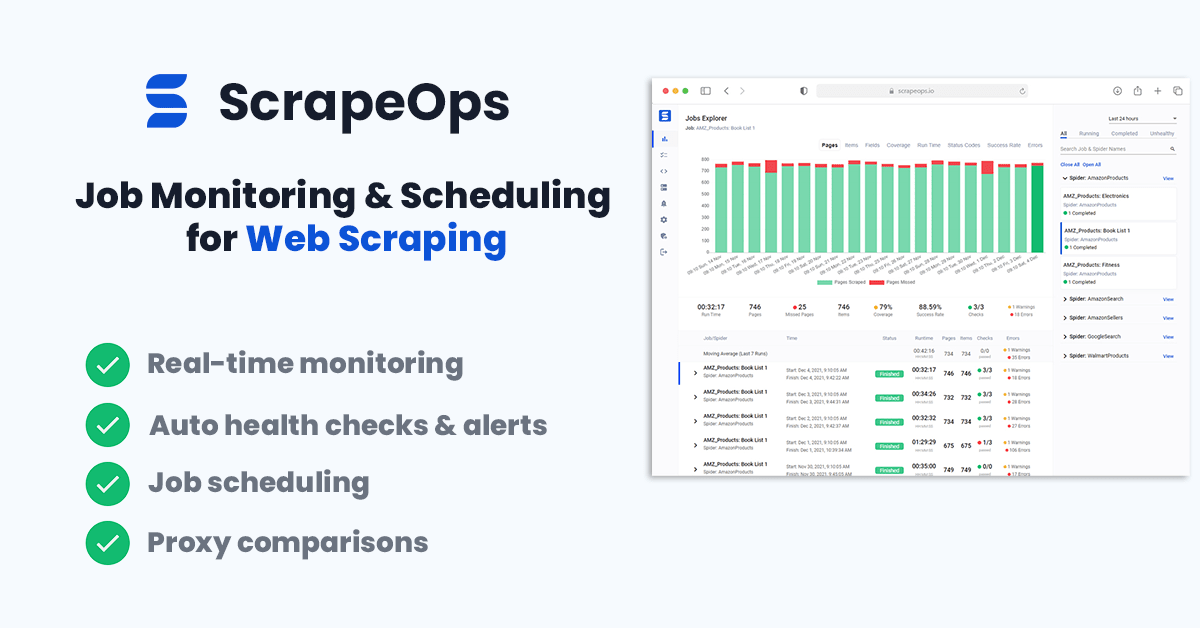
You can create a free ScrapeOps API key here.
We'll just need to run the following to install the ScrapeOps Scrapy Extension:
pip install scrapeops-scrapy
Once that is installed you need to add the following to your Scrapy projects settings.py file if you want to be able to see your logs in ScrapeOps:
# Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
# Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
# Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
Now, every time we run a our LinkedIn People Profile spider (scrapy crawl linkedin_people_profile), the ScrapeOps SDK will monitor the performance and send the data to ScrapeOps dashboard.
Full documentation on how to integrate the ScrapeOps Monitoring here.
Scheduling & Running Our Scraper In The Cloud
Lastly, we will want to deploy our LinkedIn People Profile scraper to a server so that we can schedule it to run every day, week, etc.
To do this you have a couple of options.
However, one of the easiest ways is via ScrapeOps Job Scheduler. Plus it is free!

Here is a video guide on how to connect a Digital Ocean to ScrapeOps and schedule your jobs to run.
You could also connect ScrapeOps to any server like Vultr or Amazon Web Services(AWS).
More Web Scraping Guides
In this edition of our "How To Scrape X" series, we went through how you can scrape LinkedIn.com including how to bypass its anti-bot protection.
The full code for this LinkedIn People Profile Spider is available on Github here.
If you would like to learn how to scrape other popular websites then check out our other How To Scrape With Scrapy Guides here:
- How To Scrape Amazon Products
- How To Scrape Amazon Product Reviews
- How To Scrape Walmart.com
- How To Scrape Indeed.com
Of if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: