
With 2021 having come to an end, now is the time to look back at the big events & trends in the world of web scraping, and try to project what will 2022 look like for web scraping.
Including the good, the bad, and the ugly:
- "Web Scraping" Falling Out Of Fashion
- Anti-Bots: The Arms Race Continues
- Legal Issues: Maybe A Little Less Grey?
- Fighting Dirty: Increased Use of Pressure Tactics
- AI Data Extractors
- Web Scraping Libraries
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
"Web Scraping" Falling Out Of Fashion
After consistent growth in interest every year over the last 10 years, 2021 seems to have been a year when "web scraping" became uncool.
Google searches for the term "web scraping" have dropped 30-40% compared to 2020 volumes.
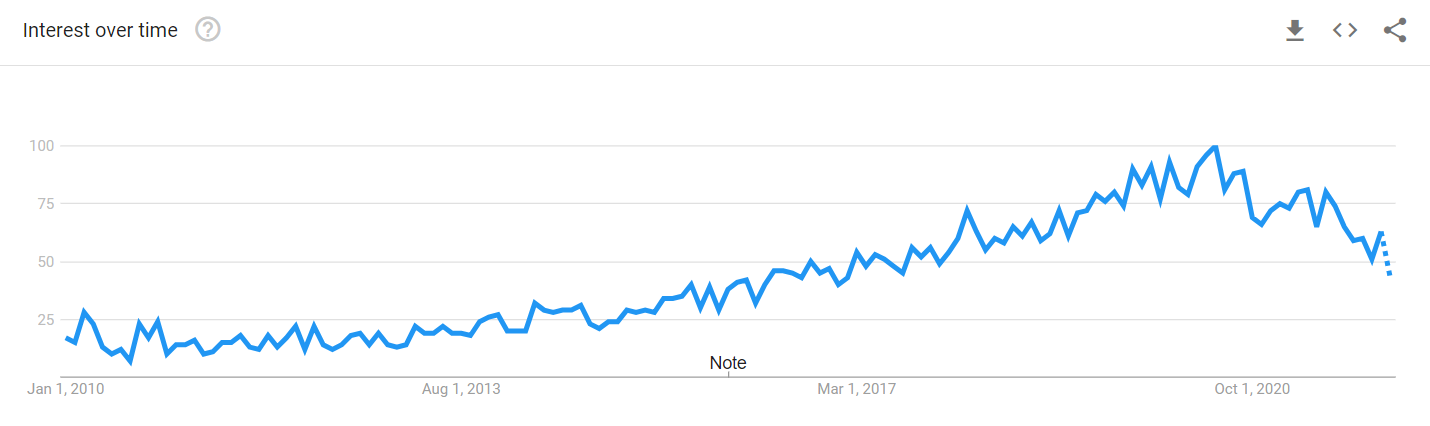
It's hard to know for sure, but it is likely a combination of:
- Growing number of companies offering industry specific data feeds (product info, SERP results, etc.) so people don't have to scrape the data themselves.
- More companies offering ready made product monitoring tools for e-commerce, etc. so companies aren't building their own in-house web scraping infrastructures.
- The term "web scraping" is falling out of fashion in favour of terms like "data feeds" and "data extraction".
In 2021, two of the largest players in web scraping, Luminati and Scrapinghub, rebranded to "Bright Data" and "Zyte" respectively, highlighting the shift away from web scraping to a more data focus.
Or maybe, just people and companies don't want web data as much anymore, who knows...
2022 Outlook
Expect to see more existing web scraping players and new entrants focus on becoming data feed providers, instead of being web-scraping-as-a-service or proxy providers. Not only are the optics better, but the profit margins are significantly higher too!

Anti-Bots: The Arms Race Continues!
The endless war between web scrapers and websites trying to block them continued unabated in 2021, with web scrapers still largely staying one step ahead.
Websites and anti-bot providers have continued to develop more sophisticated anti-bot measures. They are increasingly moving away from simple header and IP fingerprinting, to more complicated browser and TCP fingerprinting with webRTC, canvas fingerprinting and analysing mouse movements so that they can differentiate automated scrapers from real-users.
But as of yet no anti-bot has found the magic bullet to completely prevent web scrapers.
With the right combination of proxies, user agents and browsers, you can scrape every website. Even those that seem unscrapable.
However, whilst scraping a website might be still possible, anti-bots can make it not worth the effort and cost if you have to resort to ever more expensive web scraping setups (using headless browsers with residential/mobile IP networks, etc).
Cloudflare, DataDome, PerimeterX
Of all the anti-bot solutions out there, Cloudflare probably was the most widespread pain in the a** for web scrapers. Not necessarily because it is the best anti-bot, but because it is the most widely used.
Whilst the vanilla Cloudflare anti-bot can still be bypassed relatively easily, when a website is using the advanced version it can be quite challenging to deal with. Most of the time, you need to fallback to a headless browser and good proxy/user agent management.
DataDome, PerimeterX, and others have also proven themselves to be challenging to bypass in 2021.
Moving Data Behind Logins
Following in the footsteps of LinkedIn, in 2021 Facebook and Instagram led the way in a growing trend of websites moving their data behind login pages.
This not only provides websites an easy and low-barrier way to block scrapers that has limited impact on real user UX, but also tilts the legal situation in their favour if someone explicitedly decides to scrape behind the login and violate their T&Cs.
2022 Outlook
Expect to see ever more sophisticated anti-bots being used on websites. More complicated browser, TCP, and IP fingerprinting techniques are going to require you to use:
- Higher quality proxies.
- Better user agent/cookie management techniques.
- Headless browsers.
- Or one of the growing number of purpose built anti-bot bypassing solutions becoming available like Web Unlocker, Zyte Smart Browser or ScraperAPI.
E-commerce scrapers should be safe from websites moving their data behind their logins, however, expect Facebook, Instagram, and other social networks to become harder to scrape as they expand and refine their usage of login pop-ups to block scrapers.
Need a Proxy? Then check out our Proxy Comparison Tool to compare the pricing, features and limits of every proxy provider on the market so you can find the one that best suits your needs.

Legal Issues: Maybe A Little Less Grey?
Web scraping has always been in a grey area, and probably will always be. However, in 2021 web scraping became a little less grey with the outcome of the Van Buren v. United States.
In this case, the US Supreme Court ruled that accessing permissible areas of a computer system with prior authorization, even for an improper or prohibited purpose, is not a violation of the CFAA (Computer Fraud and Abuse Act).
This outcome was great news for web scrapers, as it means that so long as a websites has made their data public you are not in violation of the CFAA when you scrape the data even if it is prohibited in some other way (T&Cs, robots.txt, etc).
The US Supreme Court has sent back the LinkedIn v. HiQ case to the Ninth Circuit for a further consideration in light of the Van Buren ruling, so the LinkedIn case will give us further insight on how the courts will view web scraping moving forward.
2022 Outlook
Given the US Supreme Courts Van Buren ruling, and the Ninth Circuit's previous ruling in the LinkedIn v. HiQ case, then odds are the Ninth Circuit's next ruling on the LinkedIn vs HiQ case will be ruled in web scrapings favour (I'm not a laywer). Giving companies and developers more clarity and certainty over web scrapings legal position.
Companies and developers can continue to operate on the assumption that scraping publically available information is okay. But if you login to a website and scrape data only available whilst being logged in, then you have explicitedly agreed to the websites T&Cs when creating your account and could be in breach of their T&Cs which might prohibit web scraping.

Fighting Dirty: Increased Use of Pressure Tactics
With the legal situation continuing to favour web scrapers, some big companies have started to resort to pressure tactics to try and prevent their sites being scraped. Threatening scrapers with costly legal cases that a small company can't afford.
There have been an increasing number of stories where Facebook/Instagram, LinkedIn, etc. have suspended the accounts of any employee or company associated with scraping companies, and sent cease and desist letters to them threatening legal action if they don't ban all scraping of their sites on the scrapers plaforms.
This is despite the fact that in most cases, the scraping company only allows users to scrape data that is publically available and not behind a login, which has been deemed legal in the recent court cases.
2022 Outlook
Expect to see more of this. If the courts continue to rule in favour of a open public internet, and anti-bot techniques aren't good enough to stop web scraping then some big companies will try to prevent scraping by pressuring companies with costly legal cases or the loss of personal/professional access to their platforms.

AI Data Extractors
One of the most exciting trends in web scraping at the moment, is the growing capabilities of AI data parsers and crawlers.
Maintaining the parsing logic within spiders can be a pain, especially when you scraping hundreds or thousands of websites.
So having a AI based parser that can automatically extract your required data and deal with any HTML structure changes would be a huge value add to many developers.
As of 2021, most of the big web scraping providers have launched their own data API that uses AI to parse the data:
However, as of now and depending on the use case, the website coverage, data quality or pricing of these AI data extractors often doesn't meet the requirements for many developers looking to build data feeds.
2022 Outlook
Expect to see the performance of existing AI data extractors improve, more AI data extractor tools launched by existing players and new entrants into the web scraping market.
Hopefully, we will see some open source or unbundled AI data parsing tools, so you can use the AI parsing functionality without having to use a specific proxy network.

Web Scraping Libraries
When it comes to web scraping libraries & frameworks, Python is still king!
However, with the growing shift to scraping with headless browsers, Node.js is gaining ground fast.
Python
Web scraping with Python is still dominated by the popular Python Requests/BeautifulSoup combo and Python Scrapy, with their dominance looking unlikely to change.
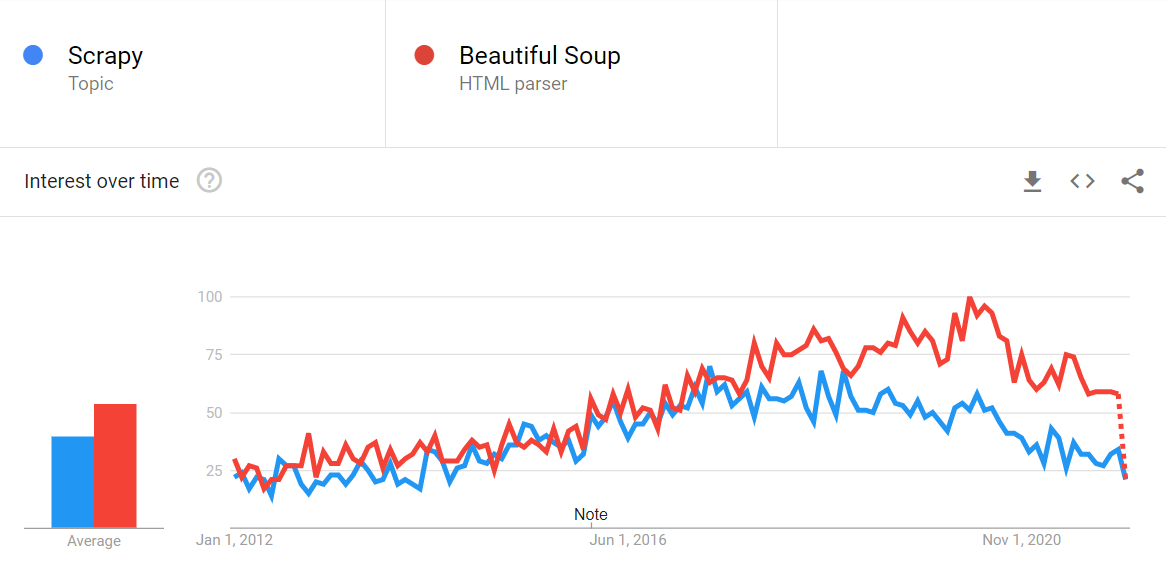
- Python Requests/BeautifulSoup - Due to its large community, ease of use and short learning curve, Python Requests/BeautifulSoup dwarfs Python Scrapy when it comes to interest and downloads (~23M vs ~700k monthly downloads).
- Python Scrapy - Although not as popular as it once was, Scrapy is still the go-to-option for many Python developers looking to build large scale web scraping infrastructures because of all the functionality ready to use right out of the box.
Although not as popular as BeautifulSoup & Scrapy, there are many other great web scraping libraries for Python that mightn't be as well-known but which are very powerful:
- Requests-HTML - Requests-HTML is a combined Python requests and parsing library that supports async requests, CSS/XPath selectors, Javascript support and more. As it uses lxml under the hood, it is much faster at parsing than BeautifulSoup (~600k monthly downloads).
- Selectolax - Selectolax is a HTML5 parser with CSS selectors that is a great alternative to BeautifulSoup as it is much faster (~34k monthly downloads).
- pyspider - pyspider is a powerful spider framework, simplier version of Scrapy, that has a built in scheduler that manages concurrency, retries, request queueing, etc. behind the scenes (~6k monthly downloads).
- AutoScraper - AutoScraper is a lightweight scraper for Python that identify the correct CSS selectors for your parsers after you giving a couple examples of the data you would like to scrape.
There are also a number of Python wrappers for Selenium, Puppeteer and Playwright that allow you to create headless browser scrapers using Python.
For years, Selenium was the go-to headless browser for web scrapers, however, with the launch of Puppeteer and Playwright developers have increasingly started building their scrapers with Node.js due to their ease of use and better functionality.
Node.js
With the increasing popularity of Node.js and the growing need to use headless browsers to bypass anti-bots, Node.js has become the 2nd most popular language used in web scraping.
Although, Node.js isn't as popular as Python for normal HTTP request web scraping there are a number of great web scraping libraries on offer:
- Fetch, Request, Axios, SuperAgent - There are a number of popular HTTP clients used for web scraping. They range from Fetch and Request, light-weight HTTP clients that cover all the basics, to Axios and SuperAgent, which have a bit more functionality and support promises and async/await.
- Cheerio - Is a lightweight implementation of the core jQuery API that runs on the server-side. With Cheerio you can use the jQuery API to parse, manipulate and extract data from a web page.
- JSDOM - Unlike Cheerio, which uses jQuery, JSDOM is a pure Javascript implementation of the DOM that allows you to interact, and scrape HTML websites. JSDOM parses the provided HTML and emulates the browser to create a DOM you can query with the normal Javascript DOM API.
- Apify SDK - Although primarily designed to be used with Apify's paid service, the Apify SDK is a powerful library that simplifies the development and management of web crawlers, scrapers, data extractors and web automation jobs. It is a scraper management tool that provides tools to manage and automatically scale a pool of headless browsers, to maintain queues of URLs to crawl, store crawling results to a local filesystem or into the cloud, rotate proxies, etc. It can be use by itself on run on Apify Cloud.
Headless Browsers
The area where Javascript web scraping really stands out is with the numerous headless browsers options it has available. Headless browsers request the data from a website, and render the HTML and any browser-side Javascript so your scraper sees the page the same way you would see in your browser.
Headless browsers are great when you need to scrape:
- Small or beginner projects.
- Single page apps using React, AngularJS, Vue.js, etc.
- Jobs that require a lot of interaction with the page to get the data you need (fill out forms/search bars, click buttons, scroll pages, etc).
- When a website is using a sophisticated anti-bot that you need to bypass.
There a numerous headless browser libraries available that make it very easy to spin up a headless browser to scrape a site.
- Puppeteer - Puppeteer is the most popular browser automation library, that just like the name implies, allows you to manipulate a web page like a puppet and scrape the data you need using a Chrome browser.
- Playwright - Released by Microsoft in 2020, Playwright.js is the new kid on the block and it very similar to Puppeteer in many ways (many of the Puppeteer team left Google, and created Playwright at Microsoft). However, it has been gaining a lot of traction because of its cross-browser support (can drive Chromium, WebKit, and Firefox browsers, whilst Puppeteer only drives Chromium) and some developer experience improvements that would have been breaking changes with Puppeteer.
- Nightmare & PhantomJS - Nightmare.js and PhantomJS are two headless browser drivers that are still in use, but which fell out of popularity with the launch of Puppeteer. Both are kinda out-of-date now and aren't really maintained anymore, so its recommended to use either Puppeteer or Playwright.
Other Languages
Although Python and Node.js are the most popular languages for web scraping, if you would prefer to use a different language then there a lots of libraries to choose from for pretty much every language out there.
Java
- JSoup - JSoup is a powerful yet simple Java library designed to make fetching pages, parsing HTML and extracting data simple by using DOM traversal or CSS selectors to find the data.
- Jaunt - Jaunt is a web automation library for web-scraping, web-automation and JSON querying. It provides a light-weight headless browser that allows you to fetch pages, parse the data and work with forms, however, it doesn't support Javascript.
- HTMLUnit - HTMLUnit is another headless browser for Java which was originally designed for HTML unit testing but which can also be used for web scraping.
- Apache Nutch - Apache Nutch is a very powerful and scalable web crawling library that is easily extenible with out-of-the-box parsers, HTML filters, etc.
Golang
- goquery - goquery is the jQuery of Golang. It allows you to traverse the DOM and extract data with CSS selectors like you would with jQuery making it a great library for web scraping.
- Colly - Colly is a powerful web scraping framework that offers similar functionality to Python's Scrapy. With Colly you can write any kind of crawler or spider, parse the data you need and control the request frequency and concurrency. If you need more complicated HTML parsing then it can be paired with goquery.
PHP
- Guzzle - Guzzle is a popular HTTP client that makes it simple to send both synchronous and asynchronous HTTP requests, making it a great option to request a web page from your target website.
- Goutte – Goutte is web scraping library for PHP that allows you to make requests, parse the respone, interact with the page and extract the data built by the creator of the Symfony Framework. It also has a BrowserKit Component that allows you to simulate the behavior of a web browser.
Ruby
- Nokogiri - Nokogiri is a popular HTML and XML parsing gem for Ruby, that makes it very easy to parse data from HTML responses using XPath and CSS selectors.
- Kimurai - Kimurai is purpose built web scraping framework for Ruby that allows you to make HTTP requests and scrape the responses. It also works out of the box with Headless Chromium, Firefox and PhantomJS.
2022 Outlook
Whilst there is always room for improvement, making requests and parsing HTML content is a solved problem in pretty much every programming language at this point, so we're unlikely to see any major changes here.
The big areas for improvement are the creation of extensions for these existing libraries/frameworks to simplify some of the common problems developers face when scraping.
ScrapeOps is a good example. ScrapeOps is a new monitoring and alerting tool dedicated to web scraping. With a simple 30 second install ScrapeOps gives you all the monitoring, alerting, scheduling and data validation functionality you need for web scraping straight out of the box.
Live demo here: ScrapeOps Demo
The primary goal with ScrapeOps is to give every developer the same level of scraping monitoring capabilities as the most sophisticated web scrapers, without any of the hassle of setting up your own custom solution.
Once you have completed the simple install (3 lines in your scraper), ScrapeOps will:
- 🕵️♂️ Monitor - Automatically monitor all your scrapers.
- 📈 Dashboards - Visualise your job data in dashboards, so you see real-time & historical stats.
- 💯 Data Quality - Validate the field coverage in each of your jobs, so broken parsers can be detected straight away.
- 📉 Auto Health Checks - Automatically check every jobs performance data versus its 7 day moving average to see if its healthy or not.
- ✔️ Custom Health Checks - Check each job with any custom health checks you have enabled for it.
- ⏰ Alerts - Alert you via email, Slack, etc. if any of your jobs are unhealthy.
- 📑 Reports - Generate daily (periodic) reports, that check all jobs versus your criteria and let you know if everything is healthy or not.
It is only available for Python Scrapy at the moment, but we will be releasing integrations for Python Requests/BeautifulSoup, Node.js, Puppeteer, Java, etc. scrapers over the coming weeks.
2022 Is Looking Good!
Sure, web scraping faces some anti-bot and legal challenges in 2022, however, it has faced those challenges every year for the past few years and came out stronger because of it.
The web scraping ecosystem is growing, with more libraries, frameworks and products available than ever before to simplify our web scraping headaches so the future is looking bright.
Need a Proxy? Then check out our Proxy Comparison Tool to compare the pricing, features and limits of every proxy provider on the market so you can find the one that best suits your needs.