After being part of the web scraping community for years, as web scrapers ourselves or working in scraping & proxy providers, we decided to build ScrapeOps.
A free web scraping tool that we hope will make every web scrapers life a whole lot easier by solving two problems every developer has faced:
❌ Problem #1: No good purpose built job monitoring and scheduling tools for web scraping.
❌ Problem #2: Finding cheap proxies that work is a pain in the a**.
ScrapeOps is designed to be the DevOps tool for web scraping. A web scraping extension that gives you all the monitoring, alerting, scheduling and data validation functionality you need for web scraping straight out of the box, no matter what programming language or web scraping library you are using.
With just a 30 seconds install, you can schedule your scraping jobs, monitor their performance, get alerts and compare the performance of every single proxy provider for your target domains in a single dashboard!
Here is a link to our live demo: Live Demo

Web Scraping Problems We Want To Solve
Whilst working at two of the largest scraping providers in the market for the last few years, I got to talk to a lot of developers scraping the web and it became clear that there were two problems that nobody was solving for web scrapers...
❌ Problem #1: No Job Monitoring or Scheduling Tools For Web Scraping
From talking to +100 web scrapers about their web scraping stacks, one thing that really stood out was how adhoc many monitoring and alerting setups were.
Although there is no shortage of logging and active monitoring tools out there, it is quite common for developers to be scraping millions of pages each month but have very basic monitoring and alerting capabilities in place.
Often relying on just eye balling log files or using the basic dashboards their proxy provider provides.
Logging tools like DataDog, Elastic, etc. are extremely powerful and are capable of doing the job, but they can get very expensive, very fast. Plus, they aren't actually ideally suited to monitoring web scrapers without a lot of customisation work.
For most developers, web scraping is just a means to an end. A way to get the data they need to run their product.
You don't have the time or resources to build a custom monitoring setup.
You just want a simple to setup monitoring & alerting suite, that tracks every jobs scraping stats in real-time and have easy ways to check if your scrapers are healthy or not.
Then when they aren't healthy, get automatically alerted via Slack, Teams, etc. and offer tools to allow you to dig deeper into what may be causing the issue.
❌ Problem #2: Finding Cheap Proxies That Work Is A Pain In The A**
If you've spent anytime web scraping, you surely have encountered this problem...
Whilst there are hundreds of proxy providers out there that claim to be great, actually finding one that works and that won't require you to sell your left kidney to pay for it can be a complete pain in the ___.
At the moment, you have no option other than to ask Mr. Google for the best proxy providers, then hope that the proxy providers with the best SEO are the best proxy for your use case and within your budget.
From there you have to start spinning up test scripts to test out each proxy provider individually.
When you eventually find a proxy that works and is reasonably priced you have no idea how their performance has been over the last few days, weeks or months.
The proxy may be working on the day you tested it, but for the last 2 weeks it might have been completely unusable. You have zero way of knowing!
These are the two big problems we have set out to solve with ScrapeOps...
Introducing ScrapeOps
ScrapeOps has been built by web scrapers, for web scrapers, with the simple mission of creating the best job monitoring and management solution that developers can install into any scraper in 30 seconds.
Then by aggregating and analysing everyones request data, bring some much-needed transparency to the web scraping proxy market for the benefit of developers.
Our solution has 3 core parts:
#1 - Complete Job Monitoring & Alerting Solution
Our primary goal with ScrapeOps is to give every developer the same level of scraping monitoring capabilities as the most sophisticated web scrapers, without any of the hassle of setting up your own custom solution.
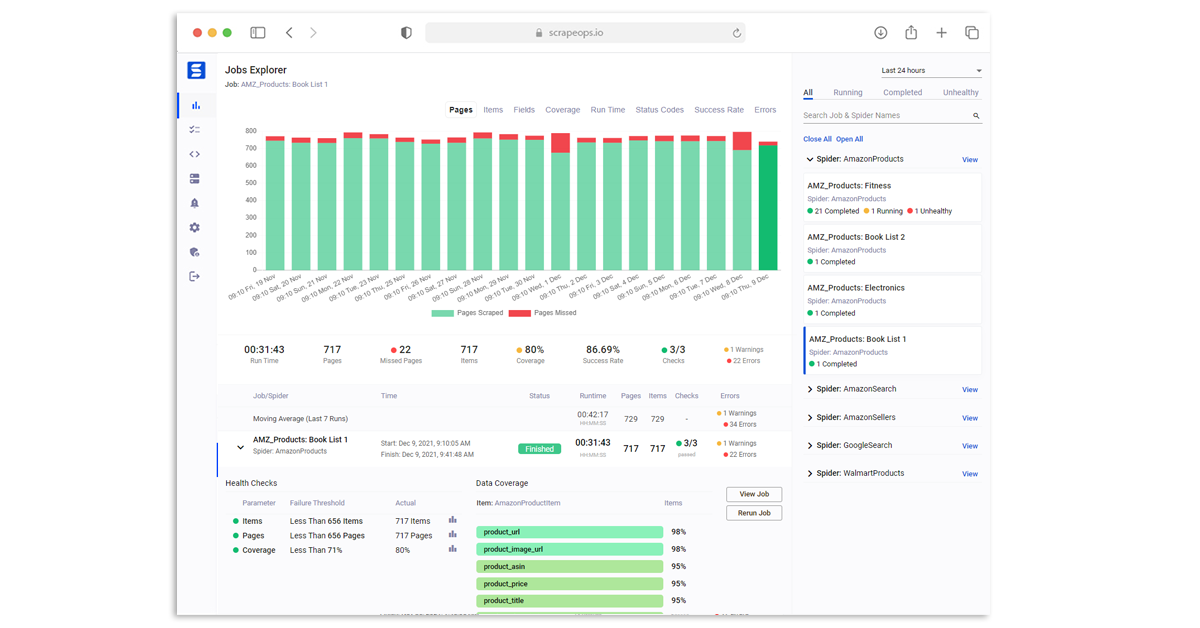
Once you have completed the simple install (3 lines in your scraper), ScrapeOps will:
- 🕵️♂️ Monitor - Automatically monitor all your scrapers.
- 📈 Dashboards - Visualise your job data in dashboards, so you see real-time & historical stats.
- 💯 Data Quality - Validate the field coverage in each of your jobs, so broken parsers can be detected straight away.
- 📉 Auto Health Checks - Automatically check every jobs performance data versus its 7 day moving average to see if its healthy or not.
- ✔️ Custom Health Checks - Check each job with any custom health checks you have enabled for it.
- ⏰ Alerts - Alert you via email, Slack, etc. if any of your jobs are unhealthy.
- 📑 Reports - Generate daily (periodic) reports, that check all jobs versus your criteria and let you know if everything is healthy or not.
Job stats tracked include:
- ✅ Pages Scraped & Missed
- ✅ Items Parsed & Missed
- ✅ Item Field Coverage
- ✅ Runtimes
- ✅ Response Status Codes
- ✅ Success Rates
- ✅ Latencies
- ✅ Errors & Warnings
- ✅ Bandwidth
Live demo here: ScrapeOps Demo
#2 - Job Scheduling & Management
With ScrapeOps you wil be able to schedule, run and manage all your scrapers (any language) across multiple servers and have the scraping stats populated in a single dashboard. There is no vendor lockin, so you can manage scrapers on AWS, GCP, DigitalOcean, etc. platforms.

Currently, we only support mangaging Scrapy spiders using a Scrapyd integration, but will be rolling out a SSH scheduling feature soon that will work with any programing language.
The monitoring and logger functionality is completely seperate, so you can use the monitoring functionality without having to change how you currently schedule your scrapers.
Learn how to integrate with Scrapyd here.
#3 - Proxy Insights & Comparisons
By aggregating together the request data of all users, we will be able to give our users real-time and historical performance data for every proxy provider on the market. Allowing you to easily compare proxy providers
With this proxy data you will be able to quickly get answers to issues like:
- When Looking For Proxies: Who is the best proxy provider for my target domains in terms of cost and performance?
- If Your Proxy Provider's Performance Drops: Is it a global issue affecting all providers, or is localized to your provider's proxy pools?
- Thinking of Switching Proxy Providers: How has the new proxy provider's performance being for the last 3-6 months? Is it degrading, stable, or improving? Have they had any outages? How fast are they able to recover?
Need a Proxy? Then check out our Proxy Comparison Tool to compare the pricing, features and limits of every proxy provider on the market so you can find the one that best suits your needs.
Launching Our Public Beta
After building and refining it with Alpha users over the last few months, we're now launching a free public Beta of ScrapeOps.
For the next 6 weeks we are running a public beta that is completely free with unlimited usage. Beta users that give feedback during the beta will get free unlimited access to the premium version forever as a thank you.
We decided to start with a Python Scrapy extension first, but will also be adding a extension for Python Requests in the next 3 weeks. Then quickly moving on to NodeJs, Selenium, Puppeteer, etc.
If you would like to get notified when early beta access is available for your preferred scraping language then you can submit your email using the links below:
You can sign up for the Beta program here.
Python Scrapy Integration
Getting setup with the logger is simple. Just install the Python package:
pip install scrapeops-scrapy
And add 3 lines to your settings.py file:
## settings.py
## Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
## Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
## Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
From there, your scraping stats will be automatically logged and automatically shipped to your dashboard.
You can view the full documentation here.
Sign Up To The Beta Program
If you are scraping with Python Scrapy, and haven't done so already, then be sure to sign up to the Beta program here or sign up to get early access to the Python Requests, and other languages beta programs here.
Beta users that give feedback during the beta will get free unlimited access to the premium version forever as a thank you.
We would love your feedback, on the current functionality and any ideas for how the tool could be improved.