
Python Scrapy: Build A Amazon Products Scraper [2023]
In this guide for our "How To Scrape X With Python Scrapy" series, we're going to look at how to build a Python Scrapy spider that will crawl Amazon.com for products and scrape product pages.
Amazon is the most popular e-commerce website for web scrapers with billions of product pages being scraped every month.
In our language agnostic How To Scrape Amazon.com guide, we went into detail about how to Amazon pages are structured and how to scrape Amazon search, product and review pages.
However, in this article we will focus on building a production Amazon scraper using Python Scrapy that will crawl and scrape Amazon Search and Product pages.
In this guide we will go through:
- How To Architect Our Amazon Product Scraper
- How To Scrape Amazon Products
- How To Paginate Through All Amazon Products
- Storing Data To Database Or S3 Bucket
- Bypassing Amazon's Anti-Bot Protection
- Monitoring To Our Amazon Review Scraper
- Scheduling & Running Our Scraper In The Cloud
If you would like to scrape Amazon Reviews then check out this guide How To Scrape Amazon Product Reviews with Scrapy.
The full code for this Amazon Spider is available on Github here.
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
How To Architect Our Amazon Product Scraper
How we design our Amazon product scraper is going to heavily depend on:
- The use case for scraping this data?
- What data we want to extract from Amazon?
- How often do we want to extract data?
- How much data do we want to extract?
- Your technical sophistication?
How you answer these questions will change what type of scraping architecture we build.
For this Amazon scraper example we will assume the following:
- Objective: The objective for this scraping system is to monitor product rankings for our target keywords and monitor the individual products every day.
- Required Data: We want to store the product rankings for each keyword and the essential product data (price, reviews, etc.)
- Scale: This will be a relatively small scale scraping process (handful of keywords), so no need to design a more sophisticated infrastructure.
- Data Storage: To keep things simple for the example we will store to a CSV file, but provide examples on how to store to MySQL & Postgres DBs.
To do this will design a Scrapy spider that combines both a product discovery crawler and a product data scraper.
As the spider runs it will crawl Amazon's product search pages, extract product URLs and then send them to the product scraper via a callback. Saving the data to a CSV file via Scrapy Feed Exports.
The advantage of this scraping architecture is that is pretty simple to build and completely self-contained.
How To Build a Amazon Product Crawler
The first part of scraping Amazon is designing a web crawler that will build a list of product URLs for our product scraper to scrape.
Step 1: Understand Amazon Search Pages
With Amazon.com the easiest way to do this is to build a Scrapy crawler that uses the Amazon search pages which returns up to 20 products per page.

For example, here is how we would get search results for iPad.
'https://www.amazon.com/s?k=ipad&page=1'
This URL contains a number of parameters that we will explain:
kstands for the search keyword. In our case,k=ipad. Note: If you want to search for a keyword that contains spaces or special characters then remember you need to encode this value.pagestands for the page number. In our cases, we've requestedpage=1.
Using these parameters we can query the Amazon search endpoint to start building a list of URLs to scrape.
To extract product URLs (or ASIN codes) from this page, we need to look through every product on this page, extract the relative URL to the product and the either create an absolute product URL or extract the ASIN.
The alternative approach is to crawl Amazon for ASIN (Amazon Standard Identification Number) codes. Every product listed on Amazon has its own unique ASIN code, which you can use to construct URLs to scrape that product page, reviews, or other sellers.
For example, you can retrieve the product page of any product using its ASIN:
## URL Structure
'https://www.amazon.com/dp/ASIN'
## Example
'https://www.amazon.com/dp/B09G9FPHY6'
Step 2: Build Amazon Search Crawler
The first thing we need to do is to build a Scrapy spider that will send a request to the Amazon Search page, and paginate through every available results page.
Here is an example Python Scapy crawler that will paginate through each page of search results for each keyword in our keyword_list.
import json
import scrapy
from urllib.parse import urljoin
import re
class AmazonSearchProductSpider(scrapy.Spider):
name = "amazon_search_product"
def start_requests(self):
keyword_list = ['ipad']
for keyword in keyword_list:
amazon_search_url = f'https://www.amazon.com/s?k={keyword}&page=1'
yield scrapy.Request(url=amazon_search_url, callback=self.discover_product_urls, meta={'keyword': keyword, 'page': 1})
def discover_product_urls(self, response):
page = response.meta['page']
keyword = response.meta['keyword']
## Get All Pages
if page == 1:
available_pages = response.xpath(
'//*[contains(@class, "s-pagination-item")][not(has-class("s-pagination-separator"))]/text()'
).getall()
last_page = available_pages[-1]
for page_num in range(2, int(last_page)):
amazon_search_url = f'https://www.amazon.com/s?k={keyword}&page={page_num}'
yield scrapy.Request(url=amazon_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': page_num})
We can run this spider using the following command:
scrapy crawl amazon_search_product
When we run this spider it will crawl through every available Amazon search page for your target keyword (in this case ipad). However, it won't output any data.
Now that we have a product discovery spider we can extract the product URLs and scrape each individual Amazon product page.
How To Build a Amazon Product Scraper
To scrape actual product data we will add a callback to our product discovery crawler, that will request each product page and then a product scraper to scrape all the product information we want.
Step 1: Add Product Scraper Callback
First, we need to update our discover_product_urls() method to extract all the product URLs from the search_products and then send a request to each one.
import json
import scrapy
from urllib.parse import urljoin
import re
class AmazonSearchProductSpider(scrapy.Spider):
name = "amazon_search_product"
def start_requests(self):
keyword_list = ['ipad']
for keyword in keyword_list:
amazon_search_url = f'https://www.amazon.com/s?k={keyword}&page=1'
yield scrapy.Request(url=amazon_search_url, callback=self.discover_product_urls, meta={'keyword': keyword, 'page': 1})
def discover_product_urls(self, response):
page = response.meta['page']
keyword = response.meta['keyword']
## Discover Product URLs
search_products = response.css("div.s-result-item[data-component-type=s-search-result]")
for product in search_products:
relative_url = product.css("a::attr(href)").get()
product_url = urljoin('https://www.amazon.com/', relative_url).split("?")[0]
yield scrapy.Request(url=product_url, callback=self.parse_product_data, meta={'keyword': keyword, 'page': page})
## Get All Pages
if page == 1:
available_pages = response.xpath(
'//*[contains(@class, "s-pagination-item")][not(has-class("s-pagination-separator"))]/text()'
).getall()
last_page = available_pages[-1]
for page_num in range(2, int(last_page)):
amazon_search_url = f'https://www.amazon.com/s?k={keyword}&page={page_num}'
yield scrapy.Request(url=amazon_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': page_num})
def parse_product_data(self, response):
## Add product data extraction code here
pass
This will extract all the URLs from the Amazon search page, request the URL and then trigger a parse_product_data scraper when it recieves a response.
Step 2: Understand Amazon Product Page
Here is an example Amazon product page URL:
'https://www.amazon.com/2021-Apple-10-2-inch-iPad-Wi-Fi/dp/B09G9FPHY6/ref=sr_1_1'
Alternatively, we could use URLs solely based on the products ASIN code:
'https://www.amazon.com/dp/B09G9FPHY6'
Which looks like this in our browser:

Unlike websites like Walmart.com, who return the data in JSON format within the HTML response, with Amazon, we will need to create parsers to extract the data from the actual HTML.
Step 3: Build Our Amazon Product Page Scraper
To scrape the resulting Amazon product page we need to populate our callback parse_product_data(), which will parse the data from the Amazon product page after Scrapy has recieved a response:
import json
import scrapy
from urllib.parse import urljoin
import re
class AmazonSearchProductSpider(scrapy.Spider):
name = "amazon_search_product"
def start_requests(self):
keyword_list = ['ipad']
for keyword in keyword_list:
amazon_search_url = f'https://www.amazon.com/s?k={keyword}&page=1'
yield scrapy.Request(url=amazon_search_url, callback=self.discover_product_urls, meta={'keyword': keyword, 'page': 1})
def discover_product_urls(self, response):
page = response.meta['page']
keyword = response.meta['keyword']
## Discover Product URLs
search_products = response.css("div.s-result-item[data-component-type=s-search-result]")
for product in search_products:
relative_url = product.css("a::attr(href)").get()
product_url = urljoin('https://www.amazon.com/', relative_url).split("?")[0]
yield scrapy.Request(url=product_url, callback=self.parse_product_data, meta={'keyword': keyword, 'page': page})
## Get All Pages
if page == 1:
available_pages = response.xpath(
'//*[contains(@class, "s-pagination-item")][not(has-class("s-pagination-separator"))]/text()'
).getall()
last_page = available_pages[-1]
for page_num in range(2, int(last_page)):
amazon_search_url = f'https://www.amazon.com/s?k={keyword}&page={page_num}'
yield scrapy.Request(url=amazon_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': page_num})
def parse_product_data(self, response):
image_data = json.loads(re.findall(r"colorImages':.*'initial':\s*(\[.+?\])},\n", response.text)[0])
variant_data = re.findall(r'dimensionValuesDisplayData"\s*:\s* ({.+?}),\n', response.text)
feature_bullets = [bullet.strip() for bullet in response.css("#feature-bullets li ::text").getall()]
price = response.css('.a-price span[aria-hidden="true"] ::text').get("")
if not price:
price = response.css('.a-price .a-offscreen ::text').get("")
product_data = {
"name": response.css("#productTitle::text").get("").strip(),
"price": price,
"stars": response.css("i[data-hook=average-star-rating] ::text").get("").strip(),
"rating_count": response.css("div[data-hook=total-review-count] ::text").get("").strip(),
"feature_bullets": feature_bullets,
"images": image_data,
"variant_data": variant_data,
}
# Print the data before yielding
self.logger.info(f"Scraped Data: {product_data}")
print(product_data)
yield product_data
Now when we run our scraper:
scrapy crawl amazon_search_product
We will get an ouptut like this:
{"name": "Apple iPad 9.7inch with WiFi 32GB- Space Gray (2017 Model) (Renewed)",
"price": "$137.00",
"stars": "4.6 out of 5 stars",
"rating_count": "8,532 global ratings",
"feature_bullets": [
"Make sure this fits by entering your model number.",
"9.7-Inch Retina Display, wide Color and True Tone",
"A9 third-generation chip with 64-bit architecture",
"M9 motion coprocessor, 1.2MP FaceTime HD Camera",
"8MP insight Camera, touch ID, Apple Pay"],
"images": [{"hiRes": "https://m.media-amazon.com/images/I/51dBcW+NXPL._AC_SL1000_.jpg",
"thumb": "https://m.media-amazon.com/images/I/51pGtRLfaZL._AC_US40_.jpg",
"large": "https://m.media-amazon.com/images/I/51pGtRLfaZL._AC_.jpg",
"main": {...},
"variant": "MAIN",
"lowRes": None,
"shoppableScene": None},
{"hiRes": "https://m.media-amazon.com/images/I/51c43obovcL._AC_SL1000_.jpg",
"thumb": "https://m.media-amazon.com/images/I/415--n36L8L._AC_US40_.jpg",
"large": "https://m.media-amazon.com/images/I/415--n36L8L._AC_.jpg",
"main": {...},
"variant": "PT01",
"lowRes": None,
"shoppableScene": None},
"variant_data": ["{`B074PXZ5GC`:[`9.7 inches`,`Wi-Fi`,`Silver`],`B00TJGN4NG`:[`16GB`,`Wi-Fi`,`White`],`B07F93611L`:[`5 Pack`,`Wi-Fi`,`Space grey`],`B074PWW6NS`:[`Refurbished`,`Wi-Fi`,`Black`],`B0725LCLYQ`:[`9.7`,`Wi-Fi`,`Space Gray`],`B07D3DDJ4L`:[`32GB`,`Wi-Fi`,`Space Gray`],`B07G9N7J3S`:[`32GB`,`Wi-Fi`,`Gold`]}"]}
Storing Data To Database Or S3 Bucket
With Scrapy, it is very easy to save our scraped data to CSV files, databases or file storage systems (like AWS S3) using Scrapy's Feed Export functionality.
To configure Scrapy to save all our data to a new CSV file everytime we run the scraper we simply need to create a Scrapy Feed and configure a dynamic file path.
If we add the following code to our settings.py file, Scrapy will create a new CSV file in our data folder using the spider name and time the spider was run.
# settings.py
FEEDS = {
'data/%(name)s_%(time)s.csv': {
'format': 'csv',
}
}
If you would like to save your CSV files to a AWS S3 bucket then check out our Saving CSV/JSON Files to Amazon AWS S3 Bucket guide here
Or if you would like to save your data to another type of database then be sure to check out these guides:
- Saving Data to JSON
- Saving Data to SQLite Database
- Saving Data to MySQL Database
- Saving Data to Postgres Database
Bypassing Amazon's Anti-Bot Protection
As you might have seen already if you run this code Amazon might be blocking you and returning a error page like this:

Or telling you that if you want automated access to their data reach out to them.
This is because Amazon uses anti-bot protection to try and prevent (or at least make it harder) developers from scraping their site.
You will need to using rotating proxies, browser-profiles and possibly fortify your headless browser if you want to scrape Amazon reliably at scale.
We have written guides about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Scrapy Proxy Guide: How to Integrate & Rotate Proxies With Scrapy
- Scrapy User Agents: How to Manage User Agents When Scraping
- Scrapy Proxy Waterfalling: How to Waterfall Requests Over Multiple Proxy Providers
However, if you don't want to implement all this anti-bot bypassing logic yourself, the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
To use the ScrapeOps Proxy Aggregator with our Amazon Scrapy Spider, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. You can test it out with Curl using the command below:
curl 'https://proxy.scrapeops.io/v1/?api_key=YOUR_API_KEY&url=https://amazon.com'
We can integrate the proxy easily into our scrapy project by installing the ScrapeOps Scrapy Proxy SDK a Downloader Middleware. We can quickly install it into our project using the following command:
pip install scrapeops-scrapy-proxy-sdk
And then enable it in your project in the settings.py file.
## settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_PROXY_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy_proxy_sdk.scrapeops_scrapy_proxy_sdk.ScrapeOpsScrapyProxySdk': 725,
}
Now when we make requests with our scrapy spider they will be routed through the proxy and Amazon won't block them.
Full documentation on how to integrate the ScrapeOps Proxy here.
Monitoring Your Amazon Scraper
When scraping in production it is vital that you can see how your scrapers are doing so you can fix problems early.
You could see if your jobs are running correctly by checking the output in your file or database but the easier way to do it would be to install the ScrapeOps Monitor.
ScrapeOps gives you a simple to use, yet powerful way to see how your jobs are doing, run your jobs, schedule recurring jobs, setup alerts and more. All for free!
Live demo here: ScrapeOps Demo
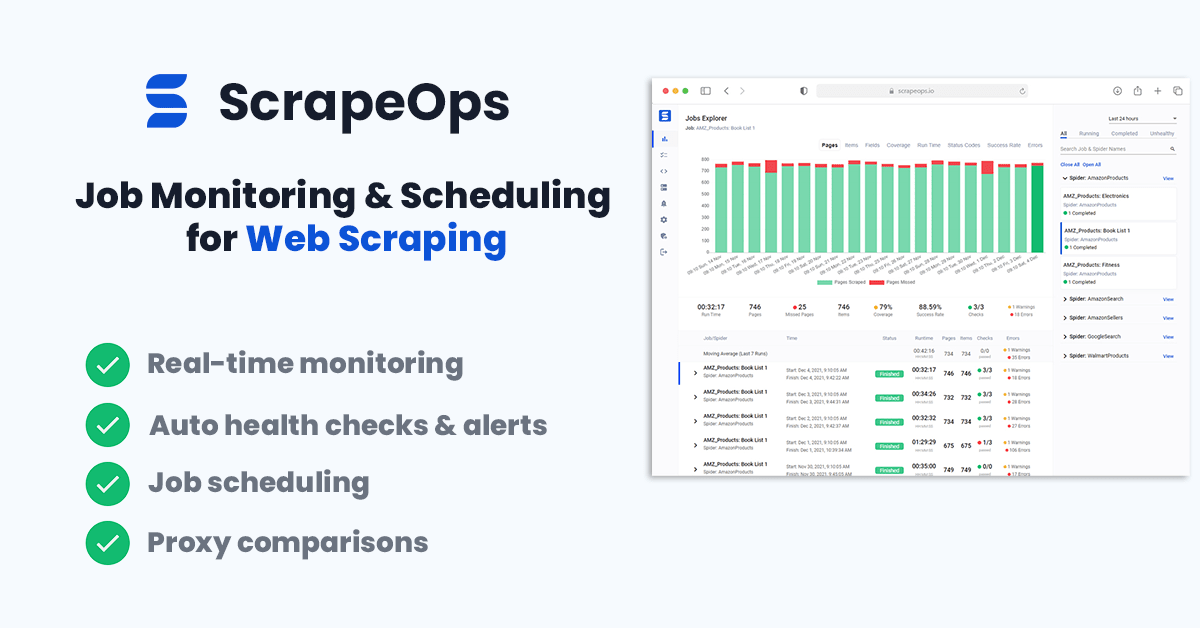
You can create a free ScrapeOps API key here.
We'll just need to run the following to install the ScrapeOps Scrapy Extension:
pip install scrapeops-scrapy
Once that is installed you need to add the following to your Scrapy projects settings.py file if you want to be able to see your logs in ScrapeOps:
# Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
# Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
# Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
Now, every time we run our Amazon spider (scrapy crawl amazon_search_product), the ScrapeOps SDK will monitor the performance and send the data to ScrapeOps dashboard.
Full documentation on how to integrate the ScrapeOps Monitoring here.
Scheduling & Running Our Scraper In The Cloud
Lastly, we will want to deploy our Amazon scraper to a server so that we can schedule it to run every day, week, etc.
To do this you have a couple of options.
However, one of the easiest ways is via ScrapeOps Job Scheduler. Plus it is free!

Here is a video guide on how to connect a Digital Ocean to ScrapeOps and schedule your jobs to run.
You could also connect ScrapeOps to any server like Vultr or Amazon Web Services(AWS).
More Web Scraping Guides
In this edition of our "How To Scrape X" series, we went through how you can scrape Amazon.com including how to bypass its anti-bot protection.
The full code for this Amazon Spider is available on Github here.
If you would like to learn how to scrape other popular websites then check out our other How To Scrape With Scrapy Guides here:
Of if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: