
Python Scrapy: Build A Walmart Scraper [2026]
In this guide for our "How To Scrape X With Python Scrapy" series, we're going to look at how to build a Python Scrapy spider that will crawl Walmart.com for products and scrape product pages.
Walmart is the 2nd most popular e-commerce website for web scrapers with billions of product pages being scraped every month.
In our language agnostic How To Scrape Walmart.com guide, we went into detail about how to Walmart pages are structured and how to scrape them.
However, in this article we will focus on building a production Amazon scraper using Python Scrapy.
In this guide we will go through:
- How To Architect Our Walmart Scraper
- How To Build a Walmart Product Crawler
- How To Build a Walmart Product Scraper
- Storing Data To Database Or S3 Bucket
- Bypassing Walmart's Anti-Bot Protection
- Monitoring To Our Walmart Scraper
- Scheduling & Running Our Scraper In The Cloud
The full code for this Walmart Spider is available on Github here.
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
How To Architect Our Walmart Scraper
How we design our Walmart scraper is going to heavily depend on:
- The use case for scraping this data?
- What data we want to extract from Walmart?
- How often do we want to extract data?
- How much data do we want to extract?
- Your technical sophistication?
How you answer these questions will change what type of scraping architecture we build.
For this Walmart scraper example we will assume the following:
- Objective: The objective for this scraping system is to monitor product rankings for our target keywords and monitor the individual products every day.
- Required Data: We want to store the product rankings for each keyword and the essential product data (price, reviews, etc.)
- Scale: This will be a relatively small scale scraping process (handful of keywords), so no need to design a more sophisticated infrastructure.
- Data Storage: To keep things simple for the example we will store to a CSV file, but provide examples on how to store to MySQL & Postgres DBs.
To do this will design a Scrapy spider that combines both a product discovery crawler and a product data scraper.
As the spider runs it will crawl Walmart's product search pages, extract product URLs and then send them to the product scraper via a callback. Saving the data to a CSV file via Scrapy Feed Exports.
The advantage of this scraping architecture is that is pretty simple to build and completely self-contained.
How To Build a Walmart Product Crawler
The first part of scraping Walmart is designing a web crawler that will build a list of product URLs for our product scraper to scrape.
Step 1: Understand Walmart Search Pages
With Walmart.com the easiest way to do this is to build a Scrapy crawler that uses the Walmart search pages which returns up to 40 products per page.

For example, here is how we would get search results for iPads.
'https://www.walmart.com/search?q=ipad&sort=best_seller&page=1&affinityOverride=default'
This URL contains a number of parameters that we will explain:
qstands for the search query. In our case,q=ipad. Note: If you want to search for a keyword that contains spaces or special characters then remember you need to encode this value.sortstands for the sorting order of the query. In our case, we usedsort=best_seller, however other options arebest_match,price_lowandprice_high.pagestands for the page number. In our cases, we've requestedpage=1.
Using these parameters we can customise our requests to the search endpoint to start building a list of URLs to scrape.
Walmart only returns a maximum of 25 pages, so if you would to get more results for your particular query then you can:
- More Specific: Say I wanted to find iPhones on Walmart but wanted more than 25 pages of results. Instead of setting the query parameter as "iPhone" you could go "iPhone 14", "iPhone 13", etc.
- Change Sorting: You could make requests with different sorting parameters (
sort=price_lowandsort=price_high) and then filter it for the unique values.
Extracting the list of products returned in the response is actually pretty easy with these Walmart search requests, as the data is available as hidden JSON data on the page.

So we just need to extract the JSON blob in the <script id="__NEXT_DATA__" type="application/json"> tag and parse it into JSON.
<script id="__NEXT_DATA__" type="application/json" nonce="">"{
...DATA...
}"
</script>
This JSON response is pretty big but the data we are looking for is in:
product_list = json_blob["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
Step 2: Build Walmart Search Crawler
So the first thing we need to do is to build a Scrapy spider that will send a request to the Walmart Search page, and if that keyword has more than 40 products (total_product_count) calculate the total number of pages and send requests for each page so that we can discover every product.
Here is an example Python Scapy crawler that will paginate through each page of search results for each keyword in our keyword_list.
import json
import math
import scrapy
from urllib.parse import urlencode
class WalmartSpider(scrapy.Spider):
name = "walmart"
def start_requests(self):
keyword_list = ['ipad']
for keyword in keyword_list:
payload = {'q': keyword, 'sort': 'best_seller', 'page': 1, 'affinityOverride': 'default'}
walmart_search_url = 'https://www.walmart.com/search?' + urlencode(payload)
yield scrapy.Request(url=walmart_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': 1})
def parse_search_results(self, response):
page = response.meta['page']
keyword = response.meta['keyword']
script_tag = response.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
if script_tag is not None:
json_blob = json.loads(script_tag)
## Request Next Page
if page == 1:
total_product_count = json_blob["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["count"]
max_pages = math.ceil(total_product_count / 40)
if max_pages > 25:
max_pages = 25
for p in range(2, max_pages):
payload = {'q': keyword, 'sort': 'best_seller', 'page': p, 'affinityOverride': 'default'}
walmart_search_url = 'https://www.walmart.com/search?' + urlencode(payload)
yield scrapy.Request(url=walmart_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': p})
We can run this spider using the following command:
scrapy crawl walmart
When we run this spider it will crawl through every available search page for your target keyword (in this case ipad). However, it won't ouptut any data.
Now that we have a product discovery spider we can extract the product URLs and scrape each individual Walmart product page.
How To Build a Walmart Product Scraper
To scrape actual product data we will add a callback to our product discovery crawler, that will request each product page and then a product scraper to scrape all the product information we want.
Step 1: Add Product Scraper Callback
First we need to update our parse_search_results() method to extract all the product URLs from the product_list and then send a request to each one.
import json
import math
import scrapy
from urllib.parse import urlencode
class WalmartSpider(scrapy.Spider):
name = "walmart"
def start_requests(self):
keyword_list = ['ipad']
for keyword in keyword_list:
payload = {'q': keyword, 'sort': 'best_seller', 'page': 1, 'affinityOverride': 'default'}
walmart_search_url = 'https://www.walmart.com/search?' + urlencode(payload)
yield scrapy.Request(url=walmart_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': 1})
def parse_search_results(self, response):
page = response.meta['page']
keyword = response.meta['keyword']
script_tag = response.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
if script_tag is not None:
json_blob = json.loads(script_tag)
## Request Product Page
product_list = json_blob["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for product in product_list:
walmart_product_url = 'https://www.walmart.com' + product.get('canonicalUrl', '').split('?')[0]
yield scrapy.Request(url=walmart_product_url, callback=self.parse_product_data, meta={'keyword': keyword, 'page': page})
## Request Next Page
if page == 1:
total_product_count = json_blob["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["count"]
max_pages = math.ceil(total_product_count / 40)
if max_pages > 25:
max_pages = 25
for p in range(2, max_pages):
payload = {'q': keyword, 'sort': 'best_seller', 'page': p, 'affinityOverride': 'default'}
walmart_search_url = 'https://www.walmart.com/search?' + urlencode(payload)
yield scrapy.Request(url=walmart_search_url, callback=self.parse_search_results, meta={'keyword': keyword, 'page': p})
This will extract all the URLs from the Walmart search page, request the URL and then trigger a parse_product_data scraper when it recieves a response.
Step 2: Understand Walmart Product Page
Here is an example Walmart product page URL:
'https://www.walmart.com/ip/2021-Apple-10-2-inch-iPad-Wi-Fi-64GB-Space-Gray-9th-Generation/483978365'
Which looks like this in our browser:

Again, as Walmart returns the data in JSON format in the <script id="__NEXT_DATA__" type="application/json"> tag of the HTML response it is pretty easy to extract the data.
<script id="__NEXT_DATA__" type="application/json" nonce="">"{
...DATA...
}"
</script>
We don't need to build CSS/xPath selectors for each field, just take the data we want from the JSON response.
The product data can be found here:
product_data = json_blob["props"]["pageProps"]["initialData"]["data"]["product"]
And the product reviews can be found here:
product_reviews = json_blob["props"]["pageProps"]["initialData"]["data"]["reviews"]
Step 3: Build Our Walmart Product Page Scraper
To scrape the resulting Walmart product page we need to create a new callback parse_product_data() which will parse the data from the Walmart product page after Scrapy has recieved a response:
def parse_product_data(self, response):
script_tag = response.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
if script_tag is not None:
json_blob = json.loads(script_tag)
raw_product_data = json_blob["props"]["pageProps"]["initialData"]["data"]["product"]
yield {
'keyword': response.meta['keyword'],
'page': response.meta['page'],
'id': raw_product_data.get('id'),
'type': raw_product_data.get('type'),
'name': raw_product_data.get('name'),
'brand': raw_product_data.get('brand'),
'averageRating': raw_product_data.get('averageRating'),
'manufacturerName': raw_product_data.get('manufacturerName'),
'shortDescription': raw_product_data.get('shortDescription'),
'thumbnailUrl': raw_product_data['imageInfo'].get('thumbnailUrl'),
'price': raw_product_data['priceInfo']['currentPrice'].get('price'),
'currencyUnit': raw_product_data['priceInfo']['currentPrice'].get('currencyUnit'),
}
The JSON blob with the product data is pretty big so we have configured our spider to only extract the data we want.
Now when we run our scraper and set it to save the data to a CSV file we will get an output like this.
Command:
scrapy crawl walmart -o walmart_data.csv
Example CSV file:
keyword,page,id,type,name,brand,averageRating,manufacturerName,shortDescription,thumbnailUrl,price,currencyUnit
laptop,1,5NVHP4PH1JJC,Laptop Computers,"Apple MacBook Pro - M1 Max - M1 Max 32-core GPU - 32 GB RAM - 1 TB SSD - 16.2"" 3456 x 2234 @ 120 Hz - Wi-Fi 6 - silver - kbd: US",Apple,,Apple,"Apple MacBook Pro - 16.2"" - M1 Max - 32 GB RAM - 1 TB SSD - US",https://i5.walmartimages.com/asr/1cd3a721-d772-49ce-a358-ab967374facb.2feb4a1e4014da6fd046fc420be620ff.jpeg,3299,USD
laptop,1,46B4WY2GAAOX,Laptop Computers,"Open Box | Apple MacBook Air | 13.3-inch Intel Core i5 8GB RAM Mac OS 256GB SSD | Bundle: Wireless Mouse, Bluetooth Headset, Black Case",Apple,5,Apple,"This Apple MacBook Air comes in Silver. It has an 13.3-inch widescreen TFT LED backlit active-matrix ""glossy"" display with 1440 x 900 native resolution. Powered by Intel Core i5 and Intel HD Graphics. Solid State Drive (SSD) capacity of 256GB with 8GB of RAM. Bundle includes Black Case, Bluetooth Headset, and Wireless Mouse! This device has been tested to be in great working condition. It will show signs of use and cosmetic blemishes which may included some scratched/dings, all of which do not affect the usability of this device.",https://i5.walmartimages.com/asr/234c14d3-10a8-4ebe-8137-8781c24752ba.c8d39b76f9fa9a3c86688628f9770551.jpeg,499,USD
laptop,1,2998G5SREYR3,Laptop Computers,Apple MacBook Pro 15.4-Inch Laptop Intel QuadCore i7 2.0GHz 480GB SSD / 16GB DDR3 Memory - Used,Apple,,Apple,"2.0GHz Intel QuadCore i7 64-bit processor / New 85W MagSafe Power adapter; 16GB Brand New & tested memory / 480GB SSD (Solid State) Hard Drive; Fresh installation of OS X v10.12 Sierra / ""7 hour battery""; 15.4 inch LED-backlit display display, Two USB ports, ThunderBolt Port, FireWire; Airport Wifi Card; ""multi-touch"" (4 finger) trackpad; Bluetooth; iSight Web Cam; 8x SuperDrive with double-layer DVD support (DVD±R DL/DVD±RW/CD-RW)",https://i5.walmartimages.com/asr/d4432229-1742-4e4c-8ff4-d1d38297c670_1.3ae9b5c21fca12cc49331d8dc9775e11.jpeg,484.03,USD
laptop,1,5DESVQJ63D9U,Laptop Computers,"Apple MacBook Air 13.3"" Retina 2019 Model Intel Core i5 8GB 128GB Space Gray MVFH2LL/A - B Grade Used",Apple,,Apple,"The Apple 13.3"" MacBook Air features a Retina Display with True Tone technology, which automatically adjusts the white balance to match the color temperature of the surrounding light. With over 4 million pixels, the 13.3"" Retina Display features a 2560 x 1600 screen resolution and a 16:10 aspect ratio for 227 pixels per inch (ppi). The integrated Touch ID sensor allows you to unlock your MacBook Air with your fingerprint and authenticate your identity. Featuring a significantly smaller footprint, the MacBook Air takes up 17 percent less volume, is 10 percent thinner measuring just 0.61 inches at its thickest point, and at just 2.75 pounds is a quarter pound lighter than the previous generation. The system is powered by an 8th Gen 1.6 GHz Intel Core i5 dual-core processor and has 8GB of onboard 2133 MHz LPDDR3 RAM and a 128GB PCIe-based SSD. MacBook is in Excellent Condition and 100% Fully Functional. Device has been fully tested and is in excellent working condition. 60 Days Seller Warranty included. MacBook will not be shipped in original packaging and will not include original accessories. Device will show signs of wear like scratches, scuffs and minor dents.",https://i5.walmartimages.com/asr/255519d7-26a2-4dc7-9e7d-cdf7fd46cb17.73863d297a31ccafef221ac7a7598982.png,499.95,USD
laptop,1,44ZDXM21GH84,Laptop Computers,"2022 Apple MacBook Air Laptop with M2 chip: 13.6-inch Liquid Retina Display, 8GB RAM, 512GB SSD Storage, Starlight",Apple,,Apple,"Supercharged by the next-generation M2 chip, the redesigned MacBook Air combines incredible performance and up to 18 hours of battery life into its strikingly thin aluminum enclosure.",https://i5.walmartimages.com/asr/5e4944d1-9527-4104-9e3e-404768cb0bc4.d329112d06b4830652cd0d892272ae51.jpeg,1469,USD
laptop,1,5O87BXGTP01P,Laptop Computers,"Gateway 15.6"" Ultra Slim Notebook, FHD, Intel® Core™ i3-1115G4, Dual Core, 8GB Memory, 256GB SSD, Tuned by THX™, 1.0MP Webcam, HDMI, Fingerprint Scanner, Cortana, Windows 10 Home, Blue",Gateway,4.4,GPU Company,"<p><strong>Check out more Gateway Products at <a href=""http://www.walmart.com/gateway"" rel=""nofollow"">Walmart.com/Gateway</a></strong></p> <p><strong>Introducing the Gateway 15.6” Ultra Slim Notebook</strong></p> <p>The 15.6” Ultra Slim Notebook from Gateway is the ultimate portable notebook that brings crystal-clear picture for all of your tasks. With a sleek and metallic design, this computer also features a 256 GB Solid State Drive. You’re guaranteed to experience clarity with a 15.6” LCD IPS Display and precision touchpad. The computer is powered by 11th Gen Intel® Core™ i3-1115G4 Processor and has 8 GB memory RAM.</p> <ul><li>Click to add <a href=""https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.walmart.com%2Fip%2FMicrosoft-365-Personal-15-month-Subscription-Email-Delivery-889842435153%2F354236902&data=04%7C01%7Cscottne%40microsoft.com%7C336060c129f04e3caec408d9a08b84a9%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637717343417773134%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=N%2BKCylN93UDb0LNVOQsvjD8GS%2BWqxpfnevV%2B7hYr6E4%3D&reserved=0"" rel=""nofollow"">Microsoft 365 Personal</a> and get 15 months for the price of 12 months</li></ul> <p><strong>Introducing boundary-breaking 11th Gen Processors</strong></p> <p><strong><em>Imagine what you can do.</em></strong></p> <ul><li>Accomplish tasks with unmatched speed and intelligence</li><li>Create and game with ease</li><li>Connect fast with best-in-class Wi-Fi</li></ul> <p><strong><em>11th Gen Intel® Core™ i3 Processor</em></strong></p> <p>Get more from your new laptop.</p> <ul><li>Performance for Productivity</li><li>Smooth streaming for all-day entertainment</li><li>Fast, reliable connectivity</li></ul> <p><strong>Tuned by THX Audio </strong></p> <p>This device features audio that has been Tuned by THX. Tuned by THX products enable listeners to get the best audio quality possible by providing custom fidelity improvements, balanced reproduction, and optimal frequency response. It is the ideal way to get the best audio for on-the-go entertainment.</p> <p><strong>More value than you can handle </strong></p> <p>The notebook is equipped with Windows 10 Home to make sure you get exactly what you need to get all of your tasks done, oh and not to mention the built-in fingerprint scanner. While only weighing 4.2 lbs., the notebook features a front facing camera, 2 built in stereo speakers, and a built- in microphone with 5.1 Bluetooth. This notebook is packed with 128 GB storage with up to 8.5 hours of battery life, so no more needing to panic about plugging your computer in to keep it going.</p>",https://i5.walmartimages.com/asr/621f4a8d-6059-45dd-8825-38af1da7ee09.6e3b906b5c9db93df4a7bbd6d43f14fe.jpeg,299,USD
laptop,1,69C7FIXFERQ8,Laptop Computers,"Apple MacBook Air 2015 Laptop (MJVM2LL/A) 11.6"" Display - Intel Core i5, 4GB Memory 128GB Flash Storage - Silver (Fair Cosmetics, Fully Functional)",Apple,,Apple,"The 11.6"" MacBook Air Notebook Computer (Early 2015) from Apple is an ultraportable notebook computer with a thin and lightweight design. Apple's engineers have leveraged the lessons they learned in designing the miniaturized iPad and applied them to the design of this 2.38-pound computer. To say that the Air is svelte is all at once stating the obvious and understating the truth. The system is defined by its unibody aluminum enclosure. At its thickest point the computer is only 0.68"" -- it tapers down to 0.11"" at its thinnest. The system is loaded with 128GB of flash storage rather than an old-fashioned hard drive. Flash storage doesn't just give you a lighter, thinner computer. It also allows for impressive battery life -- up to 9 hours of web browsing and 30 days of standby time. The MacBook Air is housed in an aluminum unibody enclosure, which is as strong as it is light. Because it is cut from a solid block of aluminum, the housing is stronger than those found on laptops built via traditional means. At 11.6"" in size, the 16:9 display features a native resolution of 1366 x 768. It features a glossy finish and LED backlight technology for enhanced image quality and energy efficiency.",https://i5.walmartimages.com/asr/87092d84-c183-4ac9-88c7-07d507c97814.e2262f28f6a07b7f85055e7deb290824.jpeg,189,USD
laptop,1,4YQGI1K7FBAB,Laptop Computers,"Apple 13.3-inch MacBook Pro Laptop, Intel Core i5, 8GB RAM, Mac OS, 500GB HDD, Special Bundle Deal: Black Case, Wireless Mouse, Bluetooth Headset - Silver (Certified Refurbished)",Apple,2.9,Apple,"<p>This MacBook Pro features a 13.3in display size with 1280 by 800 resolution. This MacBook Pro is equipped with of 500GB flash storage, powered by a 2.5GHz Intel Mobile Core i5 ""Ivy Bridge"" processor. This is a certified refurbished product that has been tested to be in great working condition. The product may show signs of use and cosmetic blemishes.</p>",https://i5.walmartimages.com/asr/5d35114d-7489-46f9-9cd7-6088044adb58_1.4528860e133164ad4c09f027b6cf0e1e.jpeg,349,USD
Storing Data To Database Or S3 Bucket
With Scrapy, it is very easy to save our scraped data to CSV files, databases or file storage systems (like AWS S3) using Scrapy's Feed Export functionality.
To configure Scrapy to save all our data to a new CSV file everytime we run the scraper we simply need to create a Scrapy Feed and configure a dynamic file path.
If we add the following code to our settings.py file, Scrapy will create a new CSV file in our data folder using the spider name and time the spider was run.
# settings.py
FEEDS = {
'data/%(name)s_%(time)s.csv': {
'format': 'csv',
}
}
If you would like to save your CSV files to a AWS S3 bucket then check out our Saving CSV/JSON Files to Amazon AWS S3 Bucket guide here
Or if you would like to save your data to another type of database then be sure to check out these guides:
- Saving Data to JSON
- Saving Data to SQLite Database
- Saving Data to MySQL Database
- Saving Data to Postgres Database
Bypassing Walmart's Anti-Bot Protection
As you might have seen already if you run this code a couple times Walmart might already have started to redirecting you to its blocked page.
This is because Walmart uses anti-bot protection to try and prevent (or at least make it harder) developers from scraping their site.
You will need to using rotating proxies, browser-profiles and possibly fortify your headless browser if you want to scrape Walmart reliably at scale.
We have written guides about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Scrapy Proxy Guide: How to Integrate & Rotate Proxies With Scrapy
- Scrapy User Agents: How to Manage User Agents When Scraping
- Scrapy Proxy Waterfalling: How to Waterfall Requests Over Multiple Proxy Providers
However, if you don't want to implement all this anti-bot bypassing logic yourself, the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
To use the ScrapeOps Proxy Aggregator with our Walmart Scrapy Spider, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. You can test it out with Curl using the command below:
curl 'https://proxy.scrapeops.io/v1/?api_key=YOUR_API_KEY&url=https://walmart.com'
We can integrate the proxy easily into our scrapy project by installing the ScrapeOps Scrapy proxy SDK a Downloader Middleware. We can quickly install it into our project using the following command:
pip install scrapeops-scrapy-proxy-sdk
And then enable it in your project in the settings.py file.
## settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_PROXY_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy_proxy_sdk.scrapeops_scrapy_proxy_sdk.ScrapeOpsScrapyProxySdk': 725,
}
Now when we make requests with our scrapy spider they will be routed through the proxy and Walmart won't block them.
Full documentation on how to integrate the ScrapeOps Proxy here.
Monitoring Your Walmart Scraper
When scraping in production it is vital that you can see how your scrapers are doing so you can fix problems early.
You could see if your jobs are running correctly by checking the output in your file or database but the easier way to do it would be to install the ScrapeOps Monitor.
ScrapeOps gives you a simple to use, yet powerful way to see how your jobs are doing, run your jobs, schedule recurring jobs, setup alerts and more. All for free!
Live demo here: ScrapeOps Demo
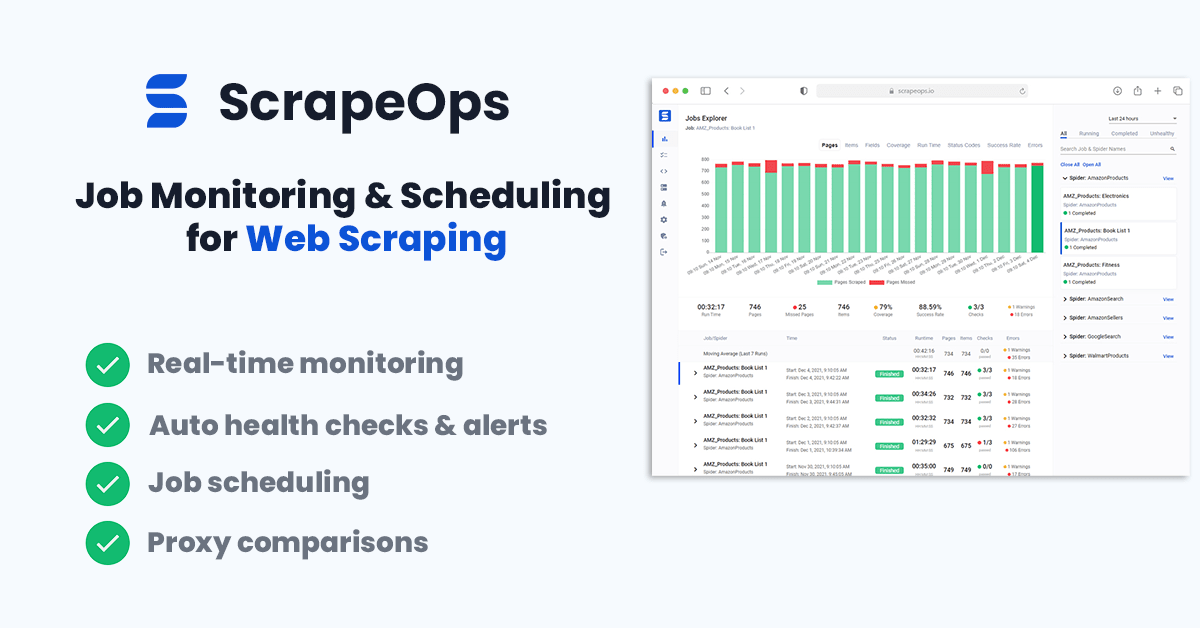
You can create a free ScrapeOps API key here.
We'll just need to run the following to install the ScrapeOps Scrapy Extension:
pip install scrapeops-scrapy
Once that is installed you need to add the following to your Scrapy projects settings.py file if you want to be able to see your logs in ScrapeOps:
# Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
# Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
# Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
Now, every time we run a our walmart spider (scrapy crawl walmart), the ScrapeOps SDK will monitor the performance and send the data to ScrapeOps dashboard.
Full documentation on how to integrate the ScrapeOps Monitoring here.
Scheduling & Running Our Scraper In The Cloud
Lastly, we will want to deploy our Walmart scraper to a server so that we can schedule it to run every day, week, etc.
To do this you have a couple of options.
However, one of the easiest ways is via ScrapeOps Job Scheduler. Plus it is free!

Here is a video guide on how to connect a Digital Ocean to ScrapeOps and schedule your jobs to run.
You could also connect ScrapeOps to any server like Vultr or Amazon Web Services(AWS).
More Web Scraping Guides
In this edition of our "How To Scrape X" series, we went through how you can scrape Walmart.com including how to bypass its anti-bot protection.
The full code for this Walmart Spider is available on Github here.
If you would like to learn how to scrape other popular websites then check out our other How To Scrape With Scrapy Guides:
Of if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: