
Python Scrapy: Build A Amazon Reviews Scraper [2023]
In this guide for our "How To Scrape X With Python Scrapy" series, we're going to look at how to build a Python Scrapy spider that will scrape Amazon.com product reviews.
Amazon is the most popular e-commerce website for web scrapers with billions of product pages being scraped every month, and is home to a huge database of product reviews. Which can be very useful for market research and competitor monitoring.
In our language agnostic How To Scrape Amazon.com guide, we went into detail about how to Amazon pages are structured and how to scrape Amazon search, product and review pages.
However, in this article we will focus on building a production Amazon scraper using Python Scrapy that will scrape Amazon Product Reviews.
In this guide we will go through:
- How To Build a Amazon Review Scraper
- Paginating Through Amazon Product Reviews
- Storing Data To Database Or S3 Bucket
- Bypassing Amazon's Anti-Bot Protection
- Monitoring To Our Amazon Reviews Scraper
- Scheduling & Running Our Scraper In The Cloud
If you would like to scrape Amazon Products then check out this guide How To Scrape Amazon Products with Scrapy.
The full code for this Amazon Review Spider is available on Github here.
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
How To Build a Amazon Review Scraper
Scraping Amazon reviews is pretty straight forward. We just need a list of product ASIN codes and send requests to the Amazon's product reviews endpoints.
'https://www.amazon.com/product-reviews/B09G9FPHY6/'
The problem with this approach is that Amazon redirects to the login page, blocking access to reviews for scrappy:
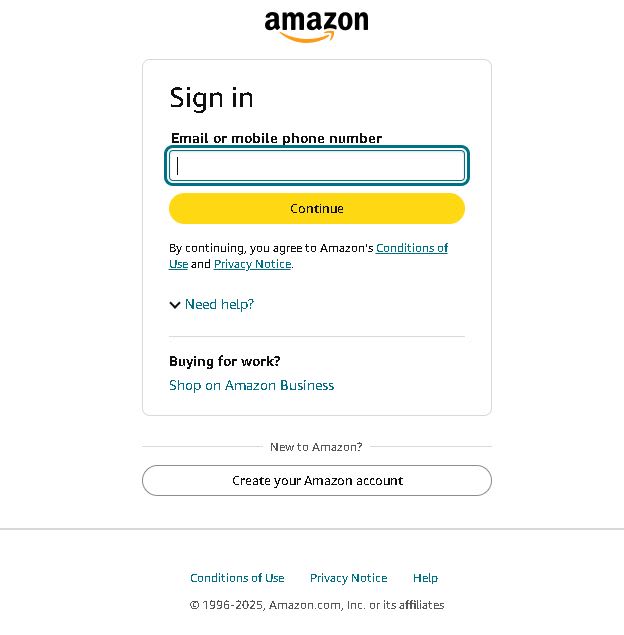
Amazon uses ASIN (Amazon Standard Identification Number) codes to identify product. Every product listed on Amazon has its own unique ASIN code, which you can use to construct URLs to scrape that product page, reviews, or other sellers.
The updated code addresses the login redirection by navigating through Amazon’s search results page to find product URLs. Once the product page is located, it scrapes the associated reviews.
Updated Steps:
-
Search for Products by ASIN: Query Amazon's search page with the ASIN to discover the product's actual URL.
-
Discover Product URLs: Extract the product page link from search results.
-
Parse Reviews: Access the product’s review section and scrape details.
-
Handle Pagination: Follow pagination links in the review section to gather all reviews.
Advantages:
-
Bypasses the login page issue by dynamically discovering product URLs.
-
Utilizes search results to ensure accurate navigation.
----------.
import scrapy
from urllib.parse import urljoin
class AmazonReviewsSpider(scrapy.Spider):
name = "amazon_reviews"
def start_requests(self):
asin_list = ['B09G9FPHY6']
for asin in asin_list:
amazon_reviews_url = f'https://www.amazon.com/s?k={asin}/'
yield scrapy.Request(url=amazon_reviews_url, callback=self.discover_product_urls, meta={'asin': asin, 'page': 1})
def discover_product_urls(self, response):
page = response.meta['page']
asin= response.meta['asin']
## Discover Product URLs
search_products = response.css("div.s-result-item[data-component-type=s-search-result]")
for product in search_products:
relative_url = product.css("a::attr(href)").get()
amazon_reviews_url = urljoin('https://www.amazon.com/', relative_url).split("?")[0]
yield scrapy.Request(url=amazon_reviews_url, callback=self.parse_reviews, meta={'asin': asin, 'retry_count': 0})
def parse_reviews(self, response):
asin = response.meta['asin']
retry_count = response.meta['retry_count']
## Parse Product Reviews
review_elements = response.css('li[data-hook="review"]')
for review_element in review_elements:
product_data = {
"asin": asin,
"text": "".join(review_element.css("span[data-hook=review-body] ::text").getall()).strip(),
"title": review_element.css("*[data-hook=review-title]>span::text").get(),
"location_and_date": review_element.css("span[data-hook=review-date] ::text").get(),
"verified": bool(review_element.css("span[data-hook=avp-badge-linkless] ::text").get()),
"rating": review_element.css("*[data-hook*=review-star-rating] ::text").re(r"(\d+\.*\d*) out")[0],
}
print(product_data)
yield product_data
Now when we run our scraper:
scrapy crawl amazon_reviews
The output of this code will look like this:
[
{
"asin": "B09G9FPHY6",
"text": "The 9th generation iPad is a fantastic tablet that offers a great balance of performance and affordability. Its A13 Bionic chip provides snappy performance for everyday tasks like browsing the web, streaming videos, and playing casual games. The vibrant 10.2-inch Retina display delivers crisp visuals for enjoying media and working on creative projects. The long battery life allows for extended use without needing to constantly recharge. Whether you need it for work, school, or entertainment, the 9th generation iPad is a reliable and versatile device that offers excellent value for the price.\n \nRead more",
"title": "Affordable Excellence",
"location_and_date": "Reviewed in the United States on December 27, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "Apple kept making and selling this 9th Gen (A13) iPad, even after releasing fancy new “all-screen” 10th gen (A14) iPad at higher price. Probably to have a lower-cost choice in iPad lineup. Apple only stopped production about 6 months ago (in mid- 2024), selling stockpile as NEW during 2024 Holiday Season at great price. It’s the last iPad with Touch ID Home Button, which I prefer over the Touch ID on side Power Button (or Face ID). It’s also the last iPad with headphones jack, which I appreciate. It works with 1st Gen Apple Pencil if you already have one from older iPad. It charges over Lightning connector, which is fine for me because all my devices (except my MacBook) still charge using Lightning (not USB-C). Performance is excellent for what I do with an iPad. The screen looks great. Long battery life (including standby time) per charge.\n \nRead more",
"title": "A proven older design, one last time, at super discount.",
"location_and_date": "Reviewed in the United States on December 19, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "I bought this tablet as a backup to my iPad 9. That’s right I like my iPad 9 so much that I bought another one. I use the iPad 9 as a daily driver. Mostly I use it for consuming content on the web and handling simple tasks like email and texting. Coupled with the Logitech Combo Touch Keyboard Folio it’s a good size and it gets the job done. For more demanding tasks I use my iPad Pro or my MacBook.Apple build quality, as usual, is S class. My original iPad 9 has always worked like a champ (still does after nearly 3 years) and I have never experienced any real problems with it. When I saw that with the introduction of the iPad 10 the iPad 9 was going on sale I couldn’t resist. People say “would buy again” well I actually *did* buy again. This is a very good machine and I highly recommend purchasing one for light work.\n \nRead more",
"title": "Good deal at this price",
"location_and_date": "Reviewed in the United States on November 17, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "The display quality is excellent. There are no issues with connectivity. It’s a good weight and I think the screen is the perfect size for taking on an airplane. Anything bigger and you just start to get too big to carry around. I have the 256GB and I’m glad I got it because the system will run better with more memory to access. If you can pick this up for a couple hundred bucks you won’t be disappointed. Good luck!\n \nRead more",
"title": "Great iPad - Great deal - can’t go wrong",
"location_and_date": "Reviewed in the United States on January 13, 2025",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "I refer to this iPad as MY-iPad! It was a replacement for an old model. This was is just a great with more pluses! It’s quality, size, functionality, and easy to set up makes it a 10 in my book🙌🏽🙌🏽 Overall a very good purchase (got on sale) that helped! 😁\n \nRead more",
"title": "MYiPad",
"location_and_date": "Reviewed in the United States on January 9, 2025",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "This is a great little device. We needed a tablet that could run zoom and \"virtual learning\" things more smoothly than our daughter's fire tablet. We were also looking for something she can play Roblox on without all the glitches that comes with Fire tablets. We found this on sale for the same price as a Fire 10 which seemed like a steal, so we went ahead and got it. I am very glad, because it just runs a lot more smoothly in general than fire tablets (which is the only other type we've had for her). It seems to charge at a decent speed, and the battery holds for several days. Although she doesn't use it very frequently during the week so maybe if she used it more, it wouldn't last as long.I will say shipping took forever. It was supposed to be a 1 week ship and it got delayed and took 2 weeks.Also, a notice for android users: It was really hard for me to set up for a kids tablet. I do love that there are kid setting options, but setting it up was very confusing for me, as an android user. And thank goodness my wife is an apple girly, because it seems like it would be very hard to navigate the kids side on the parent account without another apple device. I am the tech setter-upper in the house, and I'm sure this was user error, but I ended up having to go through all my wife's accounts to set it up rather than my own. Also (in case you're not used to apples), it seems like you cannot set it up for an adult and then add the child account onto the same device, like you would be able to for a Fire. It has to solely be set up for that child and then managed on a second apple device.Overall it works very well, looks shnazzy, serves all our purposes, and was a great price.\n \nRead more",
"title": "Perfect for my child but hard to set up",
"location_and_date": "Reviewed in the United States on September 21, 2024",
"verified": true,
"rating": "4.0"
},
{
"asin": "B09G9FPHY6",
"text": "The Apple iPad (9th Generation) is an outstanding tablet that offers impressive performance and versatility. Equipped with the A13 Bionic chip, it delivers fast and responsive performance for multitasking, gaming, and media consumption. The 10.2-inch Retina Display provides vibrant colors and sharp details, making it perfect for watching videos, reading, or browsing the web. With 64GB of storage, you'll have ample space for apps, photos, and documents.Overall, the 9th Generation iPad is a reliable and powerful device that caters to a wide range of needs, making it an excellent choice for both work and play.\n \nRead more",
"title": "Love our Apple iPads!",
"location_and_date": "Reviewed in the United States on December 2, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "The Apple iPad (9th Generation) is a perfect blend of affordability and performance. The A13 Bionic chip ensures smooth multitasking, whether for streaming, gaming, or productivity. The 10.2-inch Retina Display is vibrant and crisp, making it ideal for reading, watching videos, or creative work. The 12MP front camera is excellent for video calls, and the 8MP back camera works well for casual photography. Touch ID adds secure convenience, and the all-day battery life is a game-changer. At 64GB, it’s perfect for everyday use. Highly recommend for students, professionals, or anyone looking for a reliable tablet!\n \nRead more",
"title": "Fantastic Value and Performance!",
"location_and_date": "Reviewed in the United States on November 25, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "Estou fazendo a avaliação atrasada. Já utilizei 3 anos e está ótimo\n \n \nRead more",
"title": "Ótimo produto, já usei 3 anos",
"location_and_date": "Reviewed in Brazil on November 4, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "Melhor iPad, com custo benefício excelente. Funciona perfeitamente, a integração com o iPhone é incrível. Recomendo bastante, pra estudar, ver filmes e séries, anotar, apresentar slides, ter como agenda… perfeito!\n \n \nRead more",
"title": "Incrível",
"location_and_date": "Reviewed in Brazil on July 16, 2024",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "Review de uso por 2 meses:- A tela dele é muito linda, macia ao toque, ele é rápido, é leve, é grande mas confortável. Ótimo pra estudar, pra ver série, fazer pesquisa. Os 64 GB de espaço dá pra usar tranquilo por muito tempo sem precisar apagar arquivos. Eu substituí o meu iPad Air 1ª Geração de 2014 com 16 GB de espaço que usei desde 2014 mesmo, e a diferença pra esse modelo aqui é ABSURDA!- A bateria dura bastante. Como eu uso muito o iPad, eu tenho que recarregá-lo a cada 2 dias. Isso porque eu uso Instagram, Twitter, Podcasts, HBO Max, Prime Video, YouTube e aplicativos de notas para estudo na faculdade (além de pesquisas no Safari). O sistema diz que eu tenho uma média de 7h de uso diário. O recarregamento é muito rápido, vai de 10% a 100% em 40min~1h. Isso pra mim é rápido. Só recarrego novamente 2 dias depois. Pra mim dá muita segurança de que não me deixa na mão.- Eu não tenho a Apple Pencil porque é MUITO cara, então comprei uma da GooJoDoq 12ª geração no Al1expr3ss, foi 94 reais, e ela é perfeita! É perfeito pra escrever. Única coisa que só a Apple Pencil tem é a sensibilidade de pressão. Quem for artista ou tiver objetivo de um iPad para desenho, talvez a falta de sensor de pressão para a caneta GooJoDoq faça diferença, então terá que comprar a Apple Pencil mesmo. Para mim, não faz diferença e a caneta é realmente MUITO boa.- A câmera é boa, mas tem um filtro típico da Apple que não me agrada muito, deixa a cara um pouco lavada. Porém a tecnologia de Palco Central e desfoque do fundo nativo são realmente muito bons. Dá um aspecto mais profissional em ligações por vídeos. Os microfones também são excelentes, dando opções para isolamento de voz, que retira todo o ruído em volta e foca só na sua voz. É incrível isso.- Um ponto negativo desse iPad é o sensor de pressão digital não ser muito rápido e só funcionar com a tela acordada. Então você tem que apertar um botão pra ligar a tela e então colocar o dedo no sensor pra desbloquear. É uma inconveniência, que dentro de todas as qualidades desse iPad eu acho que é só um grão na areia.- Por fim, eu paguei 2700 em Março/2022, pela loja Tech Play Store. Recomendo a loja, a entrega foi rápida e o iPad é realmente novo, lacrado, com garantia oficial no site da Apple.\n \n \nRead more",
"title": "Ele é realmente incrível (2 meses de uso)",
"location_and_date": "Reviewed in Brazil on May 3, 2022",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "Gostei do produto, atendeu minhas expectativas e chegou muito rápido. Como não fiz uso contínuo não posso mensurar a durabilidade da bateria, mas me parece boa. Recebi há uma semana, o carreguei, fiz as configurações e está com 45% de carga. Meu uso é para escrever, tirar fotos e navegar, portanto, o custo-benefício é muito bom em relação ao Pro e ao Air, de maior valor. Atende perfeitamente às minhas necessidades.\n \n \nRead more",
"title": "Confiança e credibilidade no vendedor.",
"location_and_date": "Reviewed in Brazil on December 12, 2021",
"verified": true,
"rating": "5.0"
},
{
"asin": "B09G9FPHY6",
"text": "شكرا امازون\n \n \nRead more",
"title": "ممتاز",
"location_and_date": "Reviewed in Egypt on November 29, 2024",
"verified": true,
"rating": "5.0"
}
]
Storing Data To Database Or S3 Bucket
With Scrapy, it is very easy to save our scraped data to CSV files, databases or file storage systems (like AWS S3) using Scrapy's Feed Export functionality.
To configure Scrapy to save all our data to a new CSV file everytime we run the scraper we simply need to create a Scrapy Feed and configure a dynamic file path.
If we add the following code to our settings.py file, Scrapy will create a new CSV file in our data folder using the spider name and time the spider was run.
# settings.py
FEEDS = {
'data/%(name)s_%(time)s.csv': {
'format': 'csv',
}
}
If you would like to save your CSV files to a AWS S3 bucket then check out our Saving CSV/JSON Files to Amazon AWS S3 Bucket guide here
Or if you would like to save your data to another type of database then be sure to check out these guides:
- Saving Data to JSON
- Saving Data to SQLite Database
- Saving Data to MySQL Database
- Saving Data to Postgres Database
Bypassing Amazon's Anti-Bot Protection
As you might have seen already if you run this code Amazon might be blocking you and returning a error page like this:

Or telling you that if you want automated access to their data reach out to them.
This is because Amazon uses anti-bot protection to try and prevent (or at least make it harder) developers from scraping their site.
You will need to using rotating proxies, browser-profiles and possibly fortify your headless browser if you want to scrape Amazon reliably at scale.
We have written guides about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Scrapy Proxy Guide: How to Integrate & Rotate Proxies With Scrapy
- Scrapy User Agents: How to Manage User Agents When Scraping
- Scrapy Proxy Waterfalling: How to Waterfall Requests Over Multiple Proxy Providers
However, if you don't want to implement all this anti-bot bypassing logic yourself, the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
To use the ScrapeOps Proxy Aggregator with our Amazon Scrapy Spider, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. You can test it out with Curl using the command below:
curl 'https://proxy.scrapeops.io/v1/?api_key=YOUR_API_KEY&url=https://amazon.com'
We can integrate the proxy easily into our scrapy project by installing the ScrapeOps Scrapy Proxy SDK a Downloader Middleware. We can quickly install it into our project using the following command:
pip install scrapeops-scrapy-proxy-sdk
And then enable it in your project in the settings.py file.
## settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_PROXY_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy_proxy_sdk.scrapeops_scrapy_proxy_sdk.ScrapeOpsScrapyProxySdk': 725,
}
Now when we make requests with our scrapy spider they will be routed through the proxy and Amazon won't block them.
Full documentation on how to integrate the ScrapeOps Proxy here.
Monitoring Your Amazon Reviews Scraper
When scraping in production it is vital that you can see how your scrapers are doing so you can fix problems early.
You could see if your jobs are running correctly by checking the output in your file or database but the easier way to do it would be to install the ScrapeOps Monitor.
ScrapeOps gives you a simple to use, yet powerful way to see how your jobs are doing, run your jobs, schedule recurring jobs, setup alerts and more. All for free!
Live demo here: ScrapeOps Demo
You can create a free ScrapeOps API key here.
We'll just need to run the following to install the ScrapeOps Scrapy Extension:
pip install scrapeops-scrapy
Once that is installed you need to add the following to your Scrapy projects settings.py file if you want to be able to see your logs in ScrapeOps:
# Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
# Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
# Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
Now, every time we run a our Amazon spider (scrapy crawl amazon_reviews), the ScrapeOps SDK will monitor the performance and send the data to ScrapeOps dashboard.
Full documentation on how to integrate the ScrapeOps Monitoring here.
Scheduling & Running Our Scraper In The Cloud
Lastly, we will want to deploy our Amazon scraper to a server so that we can schedule it to run every day, week, etc.
To do this you have a couple of options.
However, one of the easiest ways is via ScrapeOps Job Scheduler. Plus it is free!

Here is a video guide on how to connect a Digital Ocean to ScrapeOps and schedule your jobs to run.
You could also connect ScrapeOps to any server like Vultr or Amazon Web Services(AWS).
More Web Scraping Guides
In this edition of our "How To Scrape X" series, we went through how you can scrape Amazon.com including how to bypass its anti-bot protection.
The full code for this Amazon Spider is available on Github here.
If you would like to learn how to scrape other popular websites then check out our other How To Scrape With Scrapy Guides here:
Of if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: