
How To Bypass PerimeterX in 2026
PerimeterX is one of the most common and sophisticated anti-scraping protection system in widespread use today.
Companies like Zillow use PerimeterX (now part of HUMAN) to try and prevent companies and developers scraping data from their websites.
PerimeterX's technology is pretty sophisticated, however, with the right set of tools you can bypass it and reliably scrape the data you need.
So in this guide, we're going to go through each of those options so you can choose the one that works best for you.
- What is PerimeterX?
- Option #1: Scrape Google Cache Version
- Option #2: Scrape With Fortified Headless Browsers
- Option #3: Smart Proxy With A PerimeterX Bypass
- Option #4: Reverse Engineer PerimeterX's Anti-Bot Protection
First, let's get a quick overview of what is PerimeterX.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
What is PerimeterX?
PerimeterX is a cyber security firm that provides a suite of tools to protect web applications from account takeovers, credential stuffing, carding, denial of inventory, scalping and web scraping.
They use machine learning algorithms and risk scores to analyse the request fingerprints and behavioral signals to detect and block bot attacks in real time.
In contrast to other anti-bot solutions like Cloudflares Bot Manager, PerimeterX's solution isn't a CDN so you can't bypass it simply finding the websites master server.
Instead, you need to optimize your requests so that their fingerprints don't get detected by PerimeterX's Bot Defender.

Option #1: Scrape Google Cache Version
Depending on how fresh your data needs to be, one option to bypass PerimeterX is to scrape the data from the Google Cache instead of the actual website.
When Google crawls the web to index web pages, it creates a cache of the data it finds. Most PerimeterX protected websites let Google crawl their websites so you can scrape this cache instead.
Scraping the Google cache can be easier than scraping a PerimeterX protected website, but it is only a viable option if the data on the website you are looking to scrape doesn't change that often.
To scrape the Google cache simply add https://webcache.googleusercontent.com/search?q=cache: to the start of the URL you would like to scrape.
For example, if you would like to scrape https://example.com/ then the URL to scrape the Google cache version would be:
'https://webcache.googleusercontent.com/search?q=cache:https://example.com/'
Some websites (like LinkedIn), tell Google to not cache their web pages or Google's crawl frequency is too low meaning some pages mightn't be cached already. So this method doesn't work with every website.

Option #2: Scrape With Fortified Headless Browsers
If you want to scrape the live website, then one option is to do the entire scraping job with a headless browser that has been fortified to look like a real users browser.
Vanilla headless browsers leak their identify in their JS fingerprints which anti-bot systems like PerimeterX can easily detect. However, developers have released a number of fortified headless browsers that patch the biggest leaks:
- Puppeteer: The stealth plugin for puppeteer.
- Playwright: The stealth plugin is coming to Playwright soon. Follow developments here and here.
- Selenium: The undetected-chromedriver an optimized Selenium Chromedriver patch.
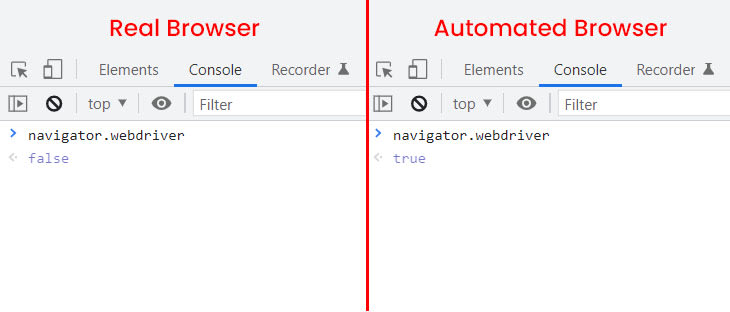
For example, a commonly known leak present in headless browsers like Puppeteer, Playwright and Selenium is the value of the navigator.webdriver. In normal browsers, this is set to false, however, in unfortified headless browsers it is set to true.
There are over 200 known headless browser leaks which these stealth plugins attempt to patch. However, it is believed to be much higher as browsers are constantly changing and it is in browser developers & anti-bot companies interest to not reveal all the leaks they know of.
Headless browser stealth plugins patch a large majority of these browser leaks, and can often bypass a lot of anti-bot services like PerimeterX, Incapsula, DataDome and Cloudflare depending on what security level they have been implement on the website with.
However, they don't get them all. To truely make your headless browser appear like a real browser then you will have to do this yourself.
Another way to make your headless browsers more undetectable to PerimeterX is to pair them with high-quality residential or mobile proxies. These proxies typically have higher IP address reputation scores than datacenter proxies and anti-bot services are more relucant to block them making them more reliable.
The downside of pairing headless browsers with residential/mobile proxies is that costs can rack up fast.
As residential & mobile proxies are typically charged per GB of bandwidth used and a page rendered with a headless browser can consume 2MB on average (versus 250kb without headless browser). Meaning it can get very expensive as you scale.
The following is an example of using residential proxies from BrightData with a headless browser assuming 2MB per page.
| Pages | Bandwidth | Cost Per GB | Total Cost |
|---|---|---|---|
| 25,000 | 50 GB | $13 | $625 |
| 100,000 | 200 GB | $10 | $2000 |
| 1 Million | 2TB | $8 | $16,000 |
If you want to compare proxy providers you can use this free proxy comparison tool, which can compare residential proxy plans and mobile proxy plans.

Option #3: Smart Proxy With A PerimeterX Bypass
The downsides with using open source Pre-Fortified Headless Browsers, is that anti-bot companies like PerimeterX can see how they bypass their anti-bot protections systems and easily patch the issues that they exploit.
As a result, most open source PerimeterX bypasses only have a couple months of shelf life before they stop working.
The alternative to using open source PerimeterX bypasses, is to use smart proxies that develop and maintain their own private PerimeterX bypass.
These are typically more reliable as it is harder for PerimeterX to develop patches for them, and they are developed by proxy companies who are financially motivated to stay 1 step ahead of PerimeterX and fix their bypasses the very minute they stop working.
Most smart proxy providers (ScraperAPI, Scrapingbee, Oxylabs, Smartproxy) have some form of PerimeterX bypass that work to varying degrees and vary in cost.
However, one of the best options is to use the ScrapeOps Proxy Aggregator as it integrates over 20 proxy providers into the same proxy API, and finds the best/cheapest proxy provider for your target domains.
You can activate ScrapeOps' PerimeterX Bypass by simply adding bypass=perimeterx to your API request, and the ScrapeOps proxy will use the best & cheapest PerimeterX bypass available for your target domain.
import requests
response = requests.get(
url='https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'http://example.com/', ## PerimeterX protected website
'bypass': 'perimeterx',
},
)
print('Body: ', response.content)
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
The advantage of taking this approach is that you can use your normal HTTP client and don't have to worry about:
- Fortifying headless browsers
- Managing numerous headless browser instances & dealing with memory issues
- Reverse engineering the PerimeterX's anti-bot protection
As this is all managed within the ScrapeOps Proxy Aggregator.

Option #4: Reverse Engineer PerimeterX's Anti-Bot Protection
The final and most complex way to bypass the PerimeterX's anti-bot protection is to actually reverse engineer PerimeterX's anti-bot protection system and develop a bypass that passes all PerimeterX anti-bot checks without the need to use a full fortified headless browser instance.
This approach works (and is what many smart proxy solutions do), however, it is not for the faint hearted.
Advantages: The advantage of this approach, is that if you are scraping at large scales and you don't want to run hundreds (if not thousands) of costly full headless browser instances. You can instead develop the most resource efficient PerimeterX bypass possible, that can use a slimmed down headless browser that is solely designed to pass the PerimeterX JS, TLS and IP fingerprint tests or no headless browser at all (this is very hard).
Disadvantages: The disadvantages to this approach is that you will have to dive deep into a anti-bot system that has been made purposedly hard to understand from the outside, and split test different techniques to trick their verification system. Then maintain this system as PerimeterX continue to develop their anti-bot protection.
It is possible to bypass PerimeterX like this, but I would only recommend someone to take this approach unless they either are:
- Genuinely interested the intellectual challenge of reverse engineering a sophisticated anti-bot system like PerimeterX, or
- The economic returns from having a more cost effective PerimeterX bypass, warrant the days or weeks of engineering time that you will have to devote to building and maintaining it.
For companies scraping at very large volumes (+500M pages per month) or smart proxy solutions who's businesses depend on cost effective ways to access sites, then building your own custom PerimeterX bypass might be a good option.
For most other developers, you are probably better off using one of the other three PerimeterX bypassing methods.
For those of you who do want to take the plunge, the following is run down of how PerimeterX's Bot Defender works and how you can approach bypassing it.
Understanding PerimeterX's Bot Defender
When we say we want to bypass PerimeterX, what we really mean is that we want to bypass their Bot Defender which has now been merged with Human's Bot Security Tools.
A system designed to prevent account takeovers, credential stuffing, carding, denial of inventory, scalping and web scraping without impacting real users.
PerimeterX bot detection system can be split into two categories:
- Backend Detection Techniques: These are bot fingerprinting techniques that are performed on the backend server.
- Client-Side Detection Techniques: These are bot fingerprinting techniques that are performed in the users browser (client-side).
To bypass PerimeterX you must pass both sets of verficiation tests.
Passing PerimeterX's Backend Detection Techniques
The following are the known backend bot fingerprinting techniques PerimeterX performs on the server side prior to returning a HTML response and how to pass them:
#1: IP Quality
One of the most fundamental tests PerimeterX conducts is computing a IP address reputation score for the IP addresses you use to send requests. Taking into account factors like is it known to be part of any known bot networks, its location, ISP, reputation history.
To obtain the highest IP address reputation scores you should use residential/mobile proxies over datacenter proxies or any proxies associated with VPNs. However, datacenter proxies can still work if they are high quality.
#2: HTTP Browser Headers
PerimeterX analyses the HTTP headers you send with your requests and compares them to a database of known browser headers patterns.
Most HTTP clients send user-agents and other headers that clearly identify them by default, so you need to override these headers and use a complete set of browser headers that match the type of browser you want to appear as. In this header optimization guide, we go into detail on how to do this and you can use our free Fake Browser Headers API to generate a list of fake browser headers.
#3: TLS & HTTP/2 Fingerprints
PerimeterX also uses is TLS & HTTP/2 fingerprinting which is a much more complex anti-bot detection method. Every HTTP request client generates a static TLS and HTTP/2 fingerprint that PerimeterX can use to determine if the request is coming from a real user or bot.
Different versions of browsers and HTTP clients tend to posess different TLS and HTTP/2 fingerprints which PerimeterX can then compare to the browser headers you send to match sure that you really are who claim to be in the browser headers you set.
The problem is that faking TLS and HTTP/2 fingerprints is much harder than simply adding fake browser headers to your request. You first need to capture and analyze the packets from the browsers you want to impersonate, then alter the TLS and HTTP/2 fingerprints used to make the request.
However, many HTTP clients like Python Requests don't give you the ability to alter these TLS and HTTP/2 fingerprints. You will need to use programming languages and HTTP client like Golang HTTP or Got which gives you enough low-level control of the request that you can fake the TLS and HTTP/2 fingerprints.
Libraries like CycleTLS, Got Scraping. utls help you spoof TLS/JA3 fingerprints in GO and Javascript.
This is a complicated topic, so I would suggest you dive into how TLS & HTTP/2 fingerprinting works. Here are some resources to help you:
- Passive Fingerprinting of HTTP/2 Clients (Akami White Paper, 2017)
- What happens in a TLS handshake?
- TLS Fingerprinting with JA3 and JA3S
The way PerimeterX detects your scrapers with these fingerprinting methods is when you make a request using user-agents and browser headers that say you are a Chrome browser, however, your TLS and HTTP/2 fingerprints say you are using the Python Requests HTTP client.
So to trick PerimeterX fingerprinting techniques you need to make sure your browser headers, TLS & HTTP/2 fingerprints are all consistent and are telling PerimeterX the request is coming from a real browser.
When you use a automated browser to make the requests then all of this is handled for you. However, it gets quite tricky when you are trying to make requests using a normal HTTP client.
PerimeterX's server-side detection techniques is its first line of defence. If you fail any of these tests your request will be blocked by PerimeterX.
The server-side detection techniques assign your request a risk score which PerimeterX then uses to determine if client side.
Each individual website can set their own anti-bot protection risk thresholds, to determine who should be challenged and with what challenges (background client-side challenges or CAPTCHAs). So your goal is to obtain the lowest risk score possible. Especially for the most protected websites.
Passing PerimeterX's Client-Side Detection PerimeterX
Okay, assuming you've been able to build a system to pass all PerimeterX's server-side anti-bot checks, now you need to deal with its client-side verfication tests.
Understanding PerimeterX's Challenge Script
When you (or your scraper) visits a website, the request will be assigned a PerimeterX cookie and the browser will fetch the PerimeterX client-side challenge scripts.
Here is an example of the <script> tag used on Zillow.com
<script>
(function(){
window._pxAppId = 'PXHYx10rg3';
// Custom parameters
// window._pxParam1 = "<param1>";
var p = document.getElementsByTagName('script')[0],
s = document.createElement('script');
s.async = 1;
s.src = '/HYx10rg3/init.js';
p.parentNode.insertBefore(s,p);
}());
</script>
This script will send a GET request to https://zillow.com/HYx10rg3/init.js to get the PerimeterX client-side bot detection scripts.
Here is an example of the PerimeterX challenge script returned when you visit Zillow.com.
As you can see this script is obfuscated and minified, so it won't make much sense until you deobfuscate and unminify it.
After this a series of POST requests will be sent to PerimeterX to retrieve extra data and clearance cookies. The higher the PerimeterX security level the website has set the more POST requests it will make.
PerimeterX's challenge script you will need to build a custom deobfuscator as a standard JavaScript deobfuscator won't work. PerimeterX uses the following techniques to obfuscate their script:
- String Concealing: Which converts strings to either Base64 encoded or additionally encrypted with XOR ciphers.
- Proxy Variables/Functions: Which replaces direct references to a variable/function's identifier with an intermediate variable.
- Unary Expressions: Which uses JavaScript's unary expression functionality to concel variables.
Look into abstract syntax tree (AST) manipulation if you would like to deobfuscate PerimeterX's challenge script.
PerimeterX encrypts their scripts and payloads with a symmetric-key algorithm, and you can decrypt their script by using the original sts and uuid values contained in the POST requests.
PerimeterX's Javascript Challenges
The following are the main client-side bot fingerprinting techniques PerimeterX performs in the users browser which you will need to pass:
#1: Browser Web APIs
Modern browsers have hundreds of APIs that allow us as developers to design apps that interact with the users browser. Unfortuntately, when PerimeterX loads in the users browser it gets access to all these APIs too.
Allowing it to access huge amounts of information about the browser environment, that it can then use to detect scrapers lying about their true identies. For example PerimeterX can query:
- Browser-Specific APIs: Some web APIs like
window.chromeonly exists on a Chrome browser. So if your browser headers, TLS and HTTP/2 fingerprints all say that you are making a request with a Chrome browser, but thewindow.chromeAPI doesn't exist when PerimeterX checks the browser then it is a clear sign that you are faking your fingerprints. - Automated Browser APIs: Automated browsers like Selenium have APIs like
window.document.__selenium_unwrapped. If PerimeterX sees that these APIs exist then it knows you aren't a real user. - Sandbox Browser Emulatator APIs: Sandboxed browser browser emulators like JSDOM, which runs in NodeJs, has the
processobject which only exists in NodeJs. - Environment APIs: If your user-agent is saying you are using a MacOs or Windows machine but the
navigator.platformvalue is set toLinux x86_64, then that makes your request look suspicious.
If you are using a fortified browser it will have fixed a lot of these leaks, however, you will likely have to fix more and make sure that your browser headers and TLS & HTTP/2 fingerprints match the values returned from the browser web APIs.
#2: Canvas Fingerprinting
PerimeterX uses WebGL to render an image and create a canvas fingerprint.
Canvas fingerprinting is a technique that allows PerimeterX to classify the type of device being used (combination of browser, operating system, and graphics hardware of the system).
Canvas fingerprinting is one of the most common browser fingerprinting techniques that uses the HTML5 API to draw graphics and animations of a page with Javascript, which can then be used to product a fingerprint of the device.
You can use BrowserLeaks Live Demo to see your browsers canvas fingerprint.
PerimeterX maintains a large dataset of legitimate canvas fingerprints and user-agent pairs. So when a request is coming from a user who is claiming to be a Firefox browser running on a Windows machine in their headers, but their canvas fingerprint is saying they are actually a Chrome browser running on a Linux machine then is a sign for PerimeterX to challenge or block the request.
#3: Event Tracking
If you need to mavigate around or interact with a web page to get the data you need, then you will have to contend with PerimeterX's event tracking.
PerimeterX adds event listeners to webpages so that it can monitor user actions like mouse movements, clicks, and key presses. If you have a scraper that need to interacts with a page, but the mouse never moves then it is a clear sign to PerimeterX that the request is coming from an automated browser and not a real user.
Low-Level Bypass
Overall, actually reverse engineering and developing a low level bypass (that doesn't use headless browser) for PerimeterX's anti-bot system is extremely challenging as you will need to:
- Deobfuscate & decrypt the PerimeterX challenge script
- Understand the Javascript challenges contained in the deobfuscated script
- Solve the Javascript challenges and return the correct result.
Here is a deobfuscated snippet of some of the Browser API tests PerimeterX carries out.
try {
(n.PX10010 = !!window.emit)((n.PX10225 = !!window.spawn))(
(n.PX10855 = !!window.fmget_targets)
)((n.PX11065 = !!window.awesomium))((n.PX10456 = !!window.__nightmare))(
(n.PX10441 = Xr(window.RunPerfTest))
)((n.PX10098 = !!window.geb))((n.PX10557 = !!window._Selenium_IDE_Recorder))(
(n.PX10170 = !!window._phantom || !!window.callPhantom)
)((n.PX10824 = !!document.__webdriver_script_fn))(
(n.PX10087 = !!window.domAutomation || !!window.domAutomationController)
)(
(n.PX11042 =
window.hasOwnProperty("webdriver") ||
!!window["webdriver"] ||
document.getElementsByTagName("html")[0].getAttribute("webdriver") ===
"true")
);
} catch (n) {}
We will go into more detail into how to actually reverse engineer PerimeterX's Javascript challenges in another article as that is a big topic.
More Web Scraping Guides
So when it comes to bypassing PerimeterX you have multiple options. Some are pretty quick and easy, others are a lot more complex. Each with their own tradeoffs.
If you would like to learn how to scrape some popular websites then check out our other How To Scrape Guides:
Or if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: