With an estimated 40% of websites using Cloudflare's CDN, learning how to bypass Cloudflare when web scraping has become essential for developers targeting popular retail, job-board, and finance sites.
Luckily, bypassing Cloudflare's anti-bot protection is possible — but it is not one-size-fits-all. Approaches range from managed smart proxies (fastest to ship) to TLS impersonation, browser APIs, and full reverse engineering.
Full performance tests via the ScrapeOps Proxy Aggregator (100k pages per domain) on all 20 benchmark sites. Provider counts show how many integrated APIs met each tier; the second table is the cheapest qualifying plan per domain (≥80% success, <15s avg latency).
Domain
Success Rate / Avg. Success Latency
Failing
80% / 15s
60% / 25s
40% / 35s
indeed.com
10
2
1
4
zillow.com
14
2
1
1
realtor.com
2
0
1
4
redfin.com
14
0
1
4
glassdoor.com
10
2
0
4
nike.com
14
3
2
1
adidas.com
6
4
4
4
bestbuy.com
7
0
1
8
wayfair.com
11
2
1
3
etsy.com
4
5
3
1
newegg.com
14
2
3
1
skechers.com
17
2
0
1
sneakersnstuff.com
16
1
2
1
coinmarketcap.com
19
0
0
1
coingecko.com
17
3
0
0
investing.com
13
2
1
3
etf.com
15
1
2
1
mediamarkt.de
14
2
1
0
pccomponentes.com
13
2
2
2
controller.com
12
4
0
2
Best-performing provider per domain (lowest cost plan meeting ≥80% success and <15s avg success latency).
Domain
Best Provider
Success Rate & Success Latency
API Credits
Plan
CPM
indeed.com
Scrapingant
97%13.4s
1
Enthusiast$19/month
$190
zillow.com
Scrapedo
99%3.4s
1
Basic$29/month
$290
realtor.com
Scrapingdogrender
98%4.2s
5
Standard$90/month
$450
redfin.com
Scrapingant
98%3.9s
1
Enthusiast$19/month
$190
glassdoor.com
Scrapingbee
91%8.5s
1
Freelance$49/month
$327
nike.com
Zyte Api
99%8.9s
1
Pay-As-You-Go$13
$130
adidas.com
Scrapedo
100%4.9s
1
Basic$29/month
$290
bestbuy.com
Scrapedo
97%3.7s
1
Basic$29/month
$290
wayfair.com
Scrapingant
97%11.9s
1
Enthusiast$19/month
$190
etsy.com
Scraperapi
91%12.4s
1
Hobby$49/month
$490
newegg.com
Zyte Api
99%5.7s
1
Pay-As-You-Go$13
$130
skechers.com
Zyte Api
98%1.8s
1
Pay-As-You-Go$13
$130
sneakersnstuff.com
Scrapingant
97%9.0s
1
Enthusiast$19/month
$190
coinmarketcap.com
Zyte Api
99%1.3s
1
Pay-As-You-Go$13
$130
coingecko.com
Zyte Api
99%2.0s
1
Pay-As-You-Go$13
$130
investing.com
Scrapedo
97%3.0s
1
Basic$29/month
$290
etf.com
Zyte Api
97%1.6s
1
Pay-As-You-Go$13
$130
mediamarkt.de
Scrapingant
90%7.7s
1
Enthusiast$19/month
$190
pccomponentes.com
Scrapedo
97%2.4s
1
Basic$29/month
$290
controller.com
Scrapingant
99%2.3s
1
Enthusiast$19/month
$190
Smart proxy APIs ranked first because they trade some cost for good performance and reliability. You pay for vendor-maintained Cloudflare bypasses instead of owning detection cat-and-mouse yourself.
Coverage: On our 20-domain benchmark, every site had at least one integrated smart-proxy provider that met our qualifying tiers (80% success rate and 15 seconds average success latency).
Success & speed: Winning plans averaged about ~97% success and ~5.6s average success latency in the aggregate run—stronger and more consistent than DIY stacks in our tests.
Operations: Difficulty stays low (standard HTTP client + API key), you are not patching headless browsers or solvers on every target change.
Support & updates: Providers iterate on bypasses as Cloudflare changes, you benefit from that without reverse-engineering challenges yourself.
Below is a summary of the test results for each option. Expand a card to see a short summary plus the same results tables as in the detailed section (scroll horizontally on small screens). Use View Bypass Details to jump to the full section for context and how-tos.
Cloudflare is a web infrastructure company that provides Content Delivery Network (CDN) services, DDoS mitigation, and security features to websites.
With over 40% of websites using their services, Cloudflare sits between users and website servers, acting as a reverse proxy that filters all incoming traffic.
Cloudflare uses a multi-layered approach to identify and block automated traffic:
IP Reputation Analysis: Cloudflare maintains databases of known bot networks, VPNs, and suspicious IP addresses. IP addresses with poor reputation scores are more likely to be challenged or blocked.
TLS/HTTP Fingerprinting: Every browser and HTTP client creates unique fingerprints based on how they establish TLS connections and send HTTP requests. Cloudflare compares these fingerprints against known browser patterns.
Browser Fingerprinting: JavaScript challenges run in the browser to check for headless browser indicators, automation tools (like Selenium), and inconsistencies in browser APIs.
Challenge Pages: When suspicious activity is detected, Cloudflare serves its "Checking your browser" page, which runs JavaScript challenges in the background to verify the visitor is human.
CAPTCHAs: For high-risk traffic, Cloudflare may require users to solve hCaptcha challenges that automated systems struggle to complete.
Understanding these detection mechanisms is essential for bypassing Cloudflare, as each method we'll cover targets different aspects of their protection system.
We evaluated each bypass approach against real Cloudflare-protected sites rather than synthetic test pages. Unless a section notes otherwise, the same 20-domain benchmark set was used:
These domains span common Cloudflare configurations so coverage numbers in this guide reflect mixed protection levels, not a single easy or hard target.
We used two testing methodologies depending on how much data the approach needs to compare fairly:
Full performance tests: For Smart Proxy API & Stealth Browser API approaches, we routed through the ScrapeOps Proxy Aggregator, recorded success rate, average success latency, and estimated plan cost at 100k pages (picking the cheapest qualifying plan where success stayed at least 80% and average success latency stayed under 15 seconds).
Per-domain pass/fail (spot checks): For DIY and single-tool approaches, we sent 10 requests per domain on the benchmark set, checked each response against the expected successful page content, and marked the method as working for that domain only if more than 80% of those requests succeeded.
The table below summarizes which methodology we applied to each bypass category in this guide.
Not benchmarked, implementations are one-offs and not comparable in a standardized run
Option #1: Smart Proxy With Cloudflare Built-In Bypass
Use a smart or residential proxy that maintains private Cloudflare bypass logic on the provider side. You keep sending ordinary HTTP requests while they handle TLS fingerprinting, challenges, and session churn.
Smart Proxy Method
Smart proxies develop and maintain private Cloudflare bypasses that are more reliable than open source solutions, with proxy companies financially motivated to stay ahead of Cloudflare's detection systems.
Bypass Rank:#1 of 8
Domain Coverage:100%
Difficulty:Easy
Cost:Medium
Best For:Best all-round solution, works on every domain, quick bypass and reasonable pricing when you just want to focus on the data and let someone else handle the bypasses.
Most open source Cloudflare bypasses only have a couple months of shelf life before they stop working. Anti-bot companies like Cloudflare can analyze public bypass code and quickly patch the vulnerabilities they exploit.
Smart proxies take a different approach, they develop and maintain their own private Cloudflare bypasses that aren't visible to anti-bot companies. These are typically more reliable because:
Private Implementation: Cloudflare can't easily analyze and patch what they can't see
Financial Motivation: Proxy companies are financially incentivized to stay one step ahead of Cloudflare
Rapid Response: Bypasses are fixed the minute they stop working, often within hours
Dedicated Teams: Full-time engineers focused solely on anti-bot bypass development
Smart proxy providers handle all the complexity of TLS fingerprinting, JavaScript challenge solving, and session management—you just make simple HTTP requests.
To validate the effectiveness of smart proxy services for Cloudflare bypass, we tested the Proxy APIs available within the ScrapeOps Proxy Aggregator across the 20 Cloudflare protected test domains.
ScrapeOps Proxy Aggregator Results
The ScrapeOps Proxy Aggregator routes requests through 20+ integrated proxy providers, automatically selecting the best provider for each target domain.
For each domain, the next table shows how many integrated providers met three benchmark tiers:
80%+ success rate with ≤15 s average success latency,
60%+ success rate with ≤25 s average success latency,
40%+ success rate with ≤35 s average success latency,
and how many could not meet even the loosest tier (Failing).
Domain
Success Rate / Avg. Success Latency
Failing
80% / 15s
60% / 25s
40% / 35s
indeed.com
10
2
1
4
zillow.com
14
2
1
1
realtor.com
2
0
1
4
redfin.com
14
0
1
4
glassdoor.com
10
2
0
4
nike.com
14
3
2
1
adidas.com
6
4
4
4
bestbuy.com
7
0
1
8
wayfair.com
11
2
1
3
etsy.com
4
5
3
1
newegg.com
14
2
3
1
skechers.com
17
2
0
1
sneakersnstuff.com
16
1
2
1
coinmarketcap.com
19
0
0
1
coingecko.com
17
3
0
0
investing.com
13
2
1
3
etf.com
15
1
2
1
mediamarkt.de
14
2
1
0
pccomponentes.com
13
2
2
2
controller.com
12
4
0
2
The table below lists the best-performing provider the aggregator chose for each domain based on scraping 100,000 pages of that website.
The best provider was choosen based on which delievered the lowest cost plan whilst obtaining a success rate of at least 80% and a average succeess latency of less than 15 seconds.
Domain
Best Provider
Success Rate & Success Latency
API Credits
Plan
CPM
indeed.com
Scrapingant
97%13.4s
1
Enthusiast$19/month
$190
zillow.com
Scrapedo
99%3.4s
1
Basic$29/month
$290
realtor.com
Scrapingdogrender
98%4.2s
5
Standard$90/month
$450
redfin.com
Scrapingant
98%3.9s
1
Enthusiast$19/month
$190
glassdoor.com
Scrapingbee
91%8.5s
1
Freelance$49/month
$327
nike.com
Zyte Api
99%8.9s
1
Pay-As-You-Go$13
$130
adidas.com
Scrapedo
100%4.9s
1
Basic$29/month
$290
bestbuy.com
Scrapedo
97%3.7s
1
Basic$29/month
$290
wayfair.com
Scrapingant
97%11.9s
1
Enthusiast$19/month
$190
etsy.com
Scraperapi
91%12.4s
1
Hobby$49/month
$490
newegg.com
Zyte Api
99%5.7s
1
Pay-As-You-Go$13
$130
skechers.com
Zyte Api
98%1.8s
1
Pay-As-You-Go$13
$130
sneakersnstuff.com
Scrapingant
97%9.0s
1
Enthusiast$19/month
$190
coinmarketcap.com
Zyte Api
99%1.3s
1
Pay-As-You-Go$13
$130
coingecko.com
Zyte Api
99%2.0s
1
Pay-As-You-Go$13
$130
investing.com
Scrapedo
97%3.0s
1
Basic$29/month
$290
etf.com
Zyte Api
97%1.6s
1
Pay-As-You-Go$13
$130
mediamarkt.de
Scrapingant
90%7.7s
1
Enthusiast$19/month
$190
pccomponentes.com
Scrapedo
97%2.4s
1
Basic$29/month
$290
controller.com
Scrapingant
99%2.3s
1
Enthusiast$19/month
$190
Performance Summary
Metric
Result
Domain coverage
20/20 domains — each benchmark site had a best-scoring integrated provider in the results above
Success rate (best provider per domain)
~89.5%–99.6% (average ~96.9%) on measured successful responses
Average response time (successful requests)
~5.6 seconds for the best provider per domain; range ~1.3s–13.4s depending on the site
Key Observations:
Full domain coverage: All 20 targets—including job boards (e.g. Indeed, Glassdoor), real estate (Zillow, Realtor.com, Redfin), retail and apparel (Nike, Adidas, Wayfair, Best Buy), and crypto/finance (CoinMarketCap, CoinGecko, Investing.com) were able to be scraped using Proxy APIs contained within the ScrapeOps Proxy Aggregator.
Per-domain success rates for that winning provider stayed in the high 80s to high 90s; the lowest in this dataset was mediamarkt.de at 89.5%, while several domains exceeded 99% (e.g. Adidas at 99.6%).
Automatic provider selection split wins across multiple backends: Zyte API, ScrapingAnt, and ScrapeDO each led on multiple domains; ScrapingBee, ScraperAPI, and ScrapingDog each topped individual targets—matching the diversity shown in the provider criteria counts.
Latency reflects HTTP-level bypasses (no full browser session for these tests): fastest successful responses were under ~2 seconds on some domains, while heavier pages pushed toward ~10–13 seconds.
Smart proxies with professionally maintained Cloudflare bypasses delivered the strongest aggregate results in our comparison.
The combination of private bypass implementations, rapid updates, and intelligent multi-provider routing makes this approach a strong fit for production workloads when you want high success rates without running your own bypass stack.
Smart proxies are the pragmatic choice when you need reliable Cloudflare bypass without the engineering overhead of maintaining your own solution.
Ideal Use Cases
Production Scraping: When uptime and reliability matter more than squeezing every cent of margin
Variable Targets: Scraping multiple domains with different Cloudflare configurations
Teams Without Anti-Bot Expertise: Skip the learning curve of reverse engineering Cloudflare
Speed-Critical Workloads: HTTP-only requests are 10-100x faster than browser-based approaches
High Volume: Scale to millions of requests without managing browser infrastructure
When NOT to Use This Method
Extremely Tight Budgets: Per-request pricing adds up; DIY may be cheaper at very high volumes
Sites Without Protection: Overkill for sites that work with basic HTTP requests
JavaScript Rendering Required: Smart proxies return HTML; if you need JS execution, consider browser APIs
Full Control Required: If you need custom browser interactions or session logic
Cost Considerations
Smart proxy pricing varies significantly by provider and bypass level. Here's what to expect:
Volume
Basic Proxy
Smart Proxy (Low Security)
Smart Proxy (High Security)
10,000 pages/month
~$10-30
~$50-100
~$100-400
100,000 pages/month
~$50-150
~$200-500
~$500-2,000
1M pages/month
~$200-500
~$1,000-3,000
~$3,000-10,000
The tradeoff: Smart proxies cost more than basic proxies but eliminate engineering time and provide significantly higher success rates on protected sites.
Pros
Simple HTTP API, use your existing HTTP client and codebase
No browser overhead, fast response times (milliseconds vs seconds)
Most smart proxy providers offer similar functionality with varying pricing and effectiveness. The ScrapeOps Proxy Aggregator is unique in that it integrates 20+ proxy providers into a single API, automatically routing your requests to the best/cheapest provider for each target domain.
The ScrapeOps Proxy Aggregator integrates over 20 proxy providers into the same proxy API, and finds the best/cheapest proxy provider for your target domains.
This section answers common questions about using smart proxies for bypassing Cloudflare.
What's the difference between smart proxies and browser APIs?
Smart proxies return HTML via HTTP requests—they're fast (milliseconds) but can't execute JavaScript or interact with pages. Browser APIs provide full browser sessions where you can run JavaScript, click buttons, and interact with dynamic content. Choose smart proxies for static content and speed; choose browser APIs when you need JavaScript execution.
How do I know which bypass level to use?
Start with cloudflare_level_1 and monitor your success rate. If you're getting blocked or seeing challenge pages, upgrade to level_2. Only use level_3 for sites with the most aggressive protection—it costs more but handles advanced fingerprinting and behavioral analysis.
Why use ScrapeOps Proxy Aggregator instead of a single provider?
Different proxy providers perform better on different domains. The ScrapeOps Aggregator automatically routes requests to the best-performing and cheapest provider for each target domain, optimizing both success rate and cost without you having to manage multiple provider accounts.
Can smart proxies handle JavaScript-rendered content?
Standard smart proxy requests return the initial HTML response, which won't include JavaScript-rendered content. Some providers offer 'render' or 'js_render' options that execute JavaScript before returning content, though this is slower and more expensive. For complex JS interactions, browser APIs are usually a better choice.
How do smart proxies handle cookies and sessions?
Most smart proxy providers handle session cookies automatically as part of their bypass. For sites requiring persistent sessions across multiple requests, look for session or sticky session options that maintain the same IP and cookies across requests.
TLS impersonation makes your client look like a real browser at the wire: same TLS/JA3 and HTTP/2 fingerprints, no headless browser and no JavaScript execution. It fits targets where Cloudflare leans on fingerprinting more than interactive challenges.
TLS Impersonation Method
Impersonate browser TLS/JA3 and HTTP/2 fingerprints using curl_cffi to pass Cloudflare's fingerprint-based detection without executing JavaScript or running a headless browser.
Bypass Rank:#2 of 8
Domain Coverage:80%
Difficulty:Easy
Cost:Free
Best For:Lightweight, high-volume scraping when TLS fingerprinting is the main detection method. Fast and resource-efficient.
Cloudflare uses TLS fingerprinting to identify bots. Every HTTP client—whether a real browser or Python's requests library, creates a unique fingerprint based on how it negotiates TLS connections and structures HTTP/2 frames. Standard libraries like requests and httpx have fingerprints that Cloudflare recognizes as non-browser and blocks.
curl_cffi is a Python binding for curl-impersonate that sends requests with TLS fingerprints matching real browsers (Chrome, Safari, Firefox, Edge). Cloudflare sees a request that looks like it came from a real browser and allows it through—without you needing to run any JavaScript or launch a headless browser.
We tested curl_cffi across 20 Cloudflare-protected domains. If you prefer the httpx API, httpx-curl_cffi provides the same TLS fingerprinting via an httpx transport adapter.
Domain
Status
indeed.com
PASS
zillow.com
PASS
realtor.com
FAIL
redfin.com
PASS
glassdoor.com
PASS
nike.com
PASS
adidas.com
FAIL
bestbuy.com
FAIL
wayfair.com
PASS
etsy.com
FAIL
Domain
Status
newegg.com
PASS
skechers.com
PASS
sneakersnstuff.com
PASS
coinmarketcap.com
PASS
coingecko.com
PASS
investing.com
PASS
etf.com
FAIL
mediamarkt.de
PASS
pccomponentes.com
PASS
controller.com
FAIL
Overall, curl_cffi achieved 16 out of 20 domains (80%) working in our tests. It works best on sites where TLS fingerprinting is the main detection method, while failing on sites that require JavaScript execution or have stricter multi-layer protection.
TLS impersonation is ideal when you need a lightweight, fast bypass that doesn't consume the CPU and memory of a headless browser. It works well on sites where fingerprinting is the primary detection method.
Ideal Use Cases
High-Volume Scraping: Lightweight requests scale to millions of pages without the overhead of browser instances.
Sites Using Basic Fingerprinting: When Cloudflare relies mainly on TLS/HTTP fingerprint checks rather than JavaScript challenges.
Async Workflows: curl_cffi has native async support for concurrent scraping.
Memory-Constrained Environments: No browser process, just HTTP requests with spoofed fingerprints.
Budget Constraints: Free, open-source, no API costs.
When NOT to Use This Method
Sites Requiring JavaScript Execution: If Cloudflare serves a "Checking your browser" page that runs JS challenges, curl_cffi cannot execute it. Use FlareSolverr or fortified browsers instead.
Mandatory CAPTCHAs: TLS impersonation cannot solve hCaptcha or Turnstile. Consider smart proxies or browser APIs.
High-Security Sites: Sites with aggressive multi-layer detection may still block you.
Pros
Free and open-source with no API costs
Lightweight—no headless browser, minimal CPU/RAM
Fast—standard HTTP request latency
Async support for high-concurrency scraping
Strong success rate on fingerprint-based detection (80% in our tests)
Cons
Cannot execute JavaScript challenges
Fails on sites requiring JS-based verification
CAPTCHAs remain unsolvable
Can break when Cloudflare updates fingerprint detection
curl_cffi is a Python binding for curl-impersonate that can mimic browser TLS/JA3 and HTTP/2 fingerprints.
Installation
pip install curl_cffi
Basic Usage
from curl_cffi.requests import Session # Create a session that impersonates Chrome with Session(impersonate="chrome136")as session: response = session.get("https://cloudflare.com/") print(response.status_code) print(response.text[:500])
Best For: High-volume scraping where TLS fingerprinting is the main detection method, async workflows, memory-constrained environments. If you prefer the httpx API, httpx-curl_cffi provides the same TLS fingerprinting via an httpx transport adapter.
When should I use TLS impersonation vs FlareSolverr?
Use TLS impersonation when Cloudflare's main detection is fingerprint-based—it's lightweight and fast. Use FlareSolverr when sites require JavaScript execution to pass the challenge. FlareSolverr runs a headless browser and is slower and more resource-intensive, but can solve JS challenges that curl_cffi cannot.
Can curl_cffi solve Cloudflare CAPTCHAs?
No. Cloudflare's hCaptcha and Turnstile challenges cannot be solved by curl_cffi. If a site consistently shows CAPTCHAs, you'll need smart proxies, browser APIs, or human-powered CAPTCHA solving services.
Which browser version should I impersonate?
Generally use the latest stable version (e.g., chrome136). Newer fingerprints are less likely to be flagged. Ensure your HTTP headers (User-Agent, etc.) match the browser you're impersonating—header/fingerprint mismatches are a common detection vector.
Paid stealth browser APIs are hosted Puppeteer/Playwright (or similar) with unblocking, proxies, fingerprints, and CAPTCHA handling built in. You write the automation; the vendor runs hardened browsers and keeps the anti-bot stack updated.
Paid Stealth Browser APIs Method
Commercial browser APIs provide managed browser sessions with built-in unblocking capabilities, fingerprint management, and native Puppeteer/Playwright integration—eliminating the need for custom stealth patches and infrastructure management. Domain coverage is the share of benchmark domains where at least one of Bright Data, Scrapeless, or ZenRows reached ≥60% success (combined across providers).
Bypass Rank:#3 of 8
Domain Coverage:65%
Difficulty:Easy
Cost:Medium
Best For:Best solution if you do not want to deal with managing fortifying headless browsers yourself, and your scraping requires heavy page interaction.
Browser APIs are managed browser services designed specifically for web scraping at scale. Unlike running your own fortified headless browser locally, these services handle:
Session Handling: Persistent sessions, cookie management, and retry logic
Infrastructure: Cloud-based browser instances that scale on demand
You interact with these services using familiar Puppeteer or Playwright APIs, but the underlying browser runs on their infrastructure with all stealth optimizations pre-configured.
To validate the effectiveness of browser API services, we tested Bright Data Scraping Browser, ZenRows Scraping Browser, and Scrapeless Scraping Browser across 20 domains including job boards (Indeed, Glassdoor), real estate (Zillow, Realtor, Redfin), retail (Nike, Best Buy, Etsy, Wayfair), and crypto/finance sites (CoinMarketCap, CoinGecko). Each service was tested using default configurations with Puppeteer integration. Success rates are shown per domain.
Domain
Bright Data
Scrapeless
ZenRows
indeed.com
29%
22%
90%
zillow.com
82%
41%
71%
realtor.com
9%
0%
1%
redfin.com
81%
52%
0%
glassdoor.com
0%
1%
0%
nike.com
81%
61%
100%
adidas.com
99%
1%
0%
bestbuy.com
29%
30%
1%
wayfair.com
9%
38%
60%
etsy.com
0%
0%
1%
newegg.com
19%
31%
1%
skechers.com
81%
42%
100%
sneakersnstuff.com
41%
60%
60%
coinmarketcap.com
78%
61%
48%
coingecko.com
89%
60%
89%
investing.com
58%
30%
51%
etf.com
82%
51%
88%
mediamarkt.de
82%
29%
2%
pccomponentes.com
79%
71%
0%
controller.com
52%
11%
1%
Combined domain coverage: 13/20 benchmark domains (65%) had at least one provider at ≥60% success (Bright Data, Scrapeless, or ZenRows).
Summary Comparison
Provider
Avg. Success Rate
Best For
Considerations
Bright Data
~54%
Enterprise, broad domain coverage
Highest average; strong on Adidas (99%), CoinGecko (89%); struggles on job boards and some retail
ZenRows
~36%
Strong on specific domains (Indeed 90%, Nike/Skechers 100%)
Inconsistent—excellent on some sites, near-zero on others
Scrapeless
~32%
High concurrency, cost-conscious
Newer platform; moderate rates across domains; AI-driven
Overall, browser APIs outperform self-hosted fortified browsers (which showed 0–35% in our tests) but success is domain-dependent. For difficult targets, expect variable results. Bright Data posted the highest average success rate across domains in this run; combined domain coverage (≥60% on any provider) is higher than any single provider’s slice of the benchmark because different vendors excel on different sites.
Browser APIs are ideal when you want the power of browser automation without the operational overhead of maintaining stealth patches, proxy infrastructure, and browser orchestration.
Ideal Use Cases
High-Value Targets: Sites with aggressive anti-bot protection where DIY stealth solutions fail
Production Workloads: When reliability matters more than cost optimization
Teams Without Anti-Bot Expertise: Skip the learning curve of stealth patches and fingerprint management
Variable Scale: Projects that need to scale up/down without managing browser infrastructure
Rapid Prototyping: Get scraping quickly without building evasion infrastructure
When NOT to Use This Method
Tight Budgets: Per-request pricing adds up quickly at high volumes
Simple Sites: Overkill for sites that work with basic HTTP requests or curl_cffi
Full Control Required: If you need deep customization of browser behavior
Vendor Lock-in Concerns: Your scraping logic becomes dependent on third-party services
Cost Considerations
Browser API pricing is typically per-request or per-minute of browser time. Here's a rough comparison:
Volume
Self-Hosted (Fortified Browser + Proxies)
Browser API Service
10,000 pages/month
~$50-100 (proxy costs)
~$100-300
100,000 pages/month
~$200-500 (proxy + infrastructure)
~$500-1,500
1M pages/month
~$1,000-3,000
~$2,000-8,000
The tradeoff: Browser APIs cost more per request but eliminate engineering time spent on stealth maintenance, infrastructure management, and debugging detection issues.
Pros
Zero maintenance overhead for stealth patches and browser updates
Choose the browser API that best fits your needs. Each provider offers similar core functionality but differs in pricing, features, and target use cases. All support Puppeteer and Playwright integration via WebSocket connections.
Bright Data's Scraping Browser is a managed browser service designed specifically for web scraping at scale with automated unblocking capabilities. Unlike a plain headless browser, it acts like a true browser instance with built-in site unlocking, fingerprint management, CAPTCHA solving, retries, and session handling.
Status: Industry leader with extensive infrastructure. Part of a larger proxy network ecosystem. Well-documented with enterprise support options.
Performance Notes: Highly effective against Cloudflare and most anti-bot systems. Automatic retry logic and session management handle edge cases. Best-in-class success rates but premium pricing reflects this.
Key Features
Feature
Description
Automated Unblocking
Built-in CAPTCHA solving, JavaScript challenges, and dynamic anti-bot mitigation
Framework Compatible
Native Puppeteer and Playwright support via WebSocket endpoint
Session Management
Automatic headers, cookies, and session persistence
Detection Avoidance
Both headless and headed modes with fingerprint rotation
Best For: Enterprise teams needing maximum reliability, projects requiring high success rates against difficult targets, workflows that benefit from Bright Data's broader proxy ecosystem.
ZenRows Scraping Browser is part of the Universal Scraper API suite. It integrates a built-in browser that renders JavaScript, simulates human-like behavior (scrolling, interaction patterns), and blends anti-bot techniques directly into each session.
Status: Growing platform with focus on developer experience. Part of a broader scraping API ecosystem. Good documentation and responsive support.
Performance Notes: Effective against most Cloudflare configurations. Built-in human behavior simulation helps with behavioral analysis. Competitive pricing for mid-scale projects.
Key Features
Feature
Description
Human-Like Behavior
Automatic scrolling, mouse movements, and interaction patterns
All-In-One
Integrated proxies, rendering, and anti-bot bypass
Simplified Integration
Clean API that replaces complex headless browser setups
Scrapeless Scraping Browser is an AI-powered browser built on a customized Chromium engine with anti-detection logic. It abstracts away browser orchestration, session handling, fingerprint spoofing, and proxy management.
Status: Newer entrant focused on AI-driven automation. Competitive pricing with high-concurrency support. Growing documentation and community.
Performance Notes: AI-driven behavior simulation adapts to different sites. Strong performance on high-concurrency workloads. Good value for large-scale scraping projects.
Best For: Large-scale scraping with high concurrency requirements, projects needing AI-driven behavior simulation, cost-conscious teams wanting browser API capabilities.
Instead of developers maintaining their own stealth patches and proxy infrastructure for Puppeteer or Playwright, browser APIs combine rendering, anti-bot mitigation, and session handling behind a single WebSocket endpoint.
What Browser APIs Replace
Capability
DIY Approach
Browser API
Stealth Patches
Manual updates to puppeteer-extra-stealth, Patchright, etc.
Automatic, managed by provider
Fingerprint Management
Custom code for canvas, WebGL, fonts, etc.
Built-in rotation and consistency
Proxy Rotation
Separate proxy provider integration
Included in the service
CAPTCHA Solving
Third-party integration (2Captcha, etc.)
Built-in or integrated
Session Persistence
Custom cookie/storage handling
Automatic session management
Infrastructure
Docker, Kubernetes, cloud VMs
Fully managed
Migration From Local Browsers
If you already have Puppeteer or Playwright scripts, migrating to a Browser API typically requires changing just one line:
// Before: Local Puppeteer with stealth const puppeteer =require('puppeteer-extra'); constStealthPlugin=require('puppeteer-extra-plugin-stealth'); puppeteer.use(StealthPlugin()); const browser =await puppeteer.launch({headless:false}); // After: Browser API const puppeteer =require('puppeteer-core'); const browser =await puppeteer.connect({ browserWSEndpoint:'wss://provider.example.com?apikey=YOUR_KEY', });
The rest of your scraping logic—page navigation, selectors, data extraction—remains unchanged.
Future-Proofing
Future anti-bot defenses increasingly rely on behavioral and session analysis, meaning services that simulate entire browser environments with human-like patterns are more robust than standalone headless browsers. Browser APIs invest continuously in staying ahead of detection methods, making them a sustainable choice for long-term scraping projects.
This section answers common questions about using browser APIs for bypassing Cloudflare and other anti-bot systems.
How do browser APIs differ from fortified headless browsers?
Fortified headless browsers (like Patchright or Undetected ChromeDriver) run locally and require you to maintain stealth patches, proxy integration, and infrastructure. Browser APIs are cloud-hosted services where all stealth, proxy rotation, and CAPTCHA solving are managed for you. You connect via WebSocket and interact using standard Puppeteer/Playwright APIs.
Are browser APIs more expensive than self-hosted solutions?
Per-request, yes. Browser APIs typically cost $0.01-0.05 per page depending on the provider and plan. However, they eliminate engineering time for stealth maintenance, infrastructure management, and debugging. For teams without dedicated anti-bot expertise, the total cost of ownership is often lower than self-hosted solutions.
Can I use my existing Puppeteer/Playwright scripts with browser APIs?
Yes, with minimal changes. Instead of launching a local browser with puppeteer.launch(), you connect to the provider's WebSocket endpoint with puppeteer.connect(). All your existing page navigation, selectors, and data extraction code works unchanged.
Which browser API provider should I choose?
Bright Data is best for enterprise needs and maximum reliability. ZenRows offers good developer experience and competitive mid-tier pricing. Scrapeless excels at high-concurrency workloads with AI-driven behavior. Consider your scale, budget, and whether you need additional features like the provider's proxy network.
Do browser APIs work against all Cloudflare configurations?
Browser APIs have high success rates (typically 90-99%) against most Cloudflare configurations, including JavaScript challenges and Turnstile CAPTCHAs. However, sites with the most aggressive protection (Bot Fight Mode, custom rules) may still present challenges. Most providers offer guarantees and only charge for successful requests.
What happens if a browser API request fails?
Most providers include automatic retries and only bill for successful requests. If a request fails after retries, you're typically not charged. Check each provider's specific policies on retry logic, timeout handling, and billing for failed requests.
This change log tracks any updates and revisions made to the Browser API Method over time.
Mar 24, 2026Section published
Initial publication of the Browser API method as Option #5 for bypassing Cloudflare protection, featuring Bright Data Scraping Browser, ZenRows Scraping Browser API, and Scrapeless Scraping Browser. Includes performance tests across benchmark domains.
Cloudflare solvers (e.g. FlareSolverr) drive a real browser through the challenge page, then return HTML and cookies such as cf_clearance for your scraper to reuse. Heavier than TLS-only approaches, but they cover JavaScript-based checks.
FlareSolverr Method
FlareSolverr uses a headless browser to execute Cloudflare's JavaScript challenges and return valid cf_clearance cookies. More resource-intensive than TLS impersonation but can solve JS-based challenges.
Bypass Rank:#4 of 8
Domain Coverage:55%
Difficulty:Medium
Cost:Free
Best For:Sites requiring JavaScript execution. Use when TLS impersonation fails. Resource-intensive with moderate success rates.
FlareSolverr is a proxy server that bypasses Cloudflare and DDoS-GUARD protection using a headless browser. It uses Selenium with undetected-chromedriver to solve Cloudflare's JavaScript and browser fingerprinting challenges.
When Cloudflare suspects a visitor is a bot, it displays a "Checking your browser" challenge page that runs JavaScript. FlareSolverr opens the target URL in a headless browser, waits until the challenge is solved, then returns the HTML and cookies to your scraper. You can use those cookies with a lightweight HTTP client for subsequent requests.
We tested FlareSolverr across 20 Cloudflare-protected domains:
Domain
Status
indeed.com
PASS
zillow.com
FAIL
realtor.com
FAIL
redfin.com
FAIL
glassdoor.com
WARN
nike.com
PASS
adidas.com
FAIL
bestbuy.com
PASS
wayfair.com
WARN
etsy.com
PASS
Domain
Status
newegg.com
WARN
skechers.com
PASS
sneakersnstuff.com
PASS
coinmarketcap.com
PASS
coingecko.com
PASS
investing.com
FAIL
etf.com
PASS
mediamarkt.de
PASS
pccomponentes.com
PASS
controller.com
FAIL
FlareSolverr achieved 11 working + 3 partially working out of 20 domains (55-70%) in our tests. It works best on sites that require JavaScript execution to pass Cloudflare's challenge, but is slower and more resource-intensive than lightweight HTTP requests.
Deprecated Cloudflare Solvers
The following older Cloudflare solvers no longer work against current Cloudflare protection:
Ideally, FlareSolverr is a fallback when TLS impersonation fails, because the site requires JavaScript execution. On paper it's more resource-intensive but can solve challenges that curl_cffi cannot. In practice, it's not always reliable and often fails to solve the challenge.
Ideal Use Cases
Sites Requiring JavaScript Execution: When Cloudflare's challenge runs JS that must complete before access is granted.
Cookie Harvesting: Solve the challenge once, get valid cf_clearance cookies, then scrape with lightweight HTTP clients.
Budget Constraints: Free, open-source alternative to commercial bypass services.
Moderate Scale: Thousands to tens of thousands of pages where browser overhead is acceptable.
When NOT to Use This Method
High Volume: Headless browser solvers consume significant CPU/RAM—impractical for millions of requests.
Real-Time Requirements: High latency (10-60+ seconds per challenge).
High Security Sites: Sites with CAPTCHAs, Turnstile, or aggressive fingerprinting often defeat FlareSolverr.
Reliability Critical: Can break when Cloudflare updates; requires community patches.
Important Consideration
Open-source Cloudflare solvers have a limited shelf life. Many older solvers (cloudscraper, cloudflare-scrape) have been abandoned. Always verify the tool has recent commits and community activity.
Pros
Free and open-source with no API costs
Can solve JavaScript challenges that TLS impersonation cannot
Cookie harvesting allows lightweight HTTP clients for most requests
Works on sites requiring JS execution
Cons
Resource-intensive (CPU/RAM)—each request launches a browser
Once you have valid cookies, use them with your regular HTTP client:
import requests # Use cookies from FlareSolverr session = requests.Session() session.headers['User-Agent']= flaresolverr_user_agent for cookie in flaresolverr_cookies: session.cookies.set(cookie['name'], cookie['value'], domain=cookie['domain']) # Now make requests without FlareSolverr response = session.get('https://target-site.com/data')
Memory Issues
Each FlareSolverr request launches a new browser window, consuming significant memory. Throttle requests and deploy on a server with adequate RAM. Consider using session persistence to reuse browser instances.
Best For: Sites requiring JavaScript execution, cookie harvesting for lightweight HTTP clients, moderate request volumes.
When should I use FlareSolverr vs TLS impersonation?
Try [TLS impersonation](#option-2-tls-impersonation) first, it's lighter and faster. Use FlareSolverr when the site requires JavaScript execution to pass Cloudflare's challenge. FlareSolverr runs a headless browser and can solve JS challenges that curl_cffi cannot.
Why do older Cloudflare solvers like cloudscraper no longer work?
Cloudflare continuously updates their anti-bot protection. Older solvers were designed for previous challenge systems that have since been deprecated. When maintainers stop updating, tools quickly become ineffective. Always check a solver's last commit date and community activity.
Should I use FlareSolverr for every request?
No. Use FlareSolverr for 'cookie harvesting'—solve the initial challenge to get valid cf_clearance cookies, then use those cookies with a lightweight HTTP client for subsequent requests. Running every request through FlareSolverr is slow and resource-intensive.
Can FlareSolverr solve Cloudflare CAPTCHAs?
No. hCaptcha and Turnstile challenges cannot be solved automatically. If a site consistently shows CAPTCHAs, you'll need smart proxies, browser APIs, or human-powered CAPTCHA solving services.
Added performance testing across 20 Cloudflare-protected domains with domain results.
Jun 1, 2025cloudscraper Deprecated
Marked cloudscraper as no longer working against current Cloudflare protection due to lack of updates.
Oct 26, 2022Original Section Published
Initial publication of the Cloudflare Solver method, featuring FlareSolverr.
Option #5: Scrape With Fortified Headless Browsers
Fortified headless browsers patch automation leaks (navigator.webdriver, canvas, WebGL, and similar) so Puppeteer, Playwright, or Selenium sessions read like a normal user. You self-host the stack and own debugging when Cloudflare updates.
Fortified Headless Browser Method
Fortified headless browsers patch automation leaks and fingerprint artifacts to make automated browsers appear like real user browsers, allowing them to bypass anti-bot detection.
Bypass Rank:#5 of 8
Domain Coverage:35%
Difficulty:Medium
Cost:Free
Best For:Best solution if you want an open source solution and can handle some debugging and technical challenges along the way.
Vanilla headless browsers leak their identity in their JavaScript fingerprints which anti-bot systems can easily detect. Fortified headless browsers are modified versions of standard automation tools (Puppeteer, Playwright, Selenium) that patch these detection vectors.
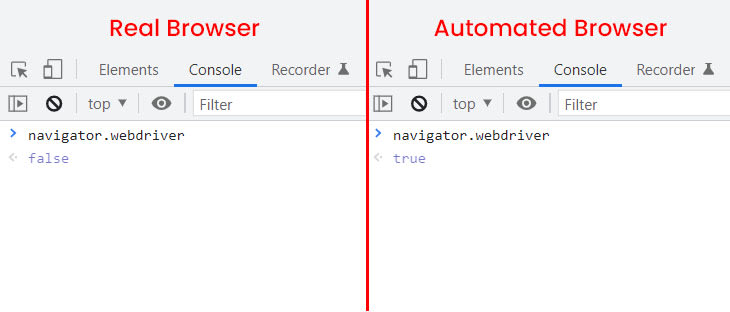
For example, a commonly known leak present in headless browsers like Puppeteer, Playwright and Selenium is the value of navigator.webdriver. In normal browsers, this is set to false, however, in unfortified headless browsers it is set to true.
There are over 200 known headless browser leaks which stealth plugins attempt to patch. However, the actual number is believed to be much higher as browsers are constantly changing and it's in browser developers' & anti-bot companies' interest to not reveal all the leaks they know of.
Categories of Fortified Browser Tools
The ecosystem of fortified headless browsers can be broken down into three categories:
Category
Tools
Description
Stealth Plugins
Puppeteer Extra + Stealth, Playwright Stealth
Plugin frameworks that add stealth patches to existing automation tools
Patched Variants
Patchright, Undetected ChromeDriver
Modified forks of automation tools with stealth patches built-in
Browser Patches
Rebrowser Patches
Low-level patches that fix automation leaks in the browser itself
How Does The Fortified Headless Browser Bypass Perform?
To validate the effectiveness of fortified headless browser tools, we tested three popular options across 20 domains including job boards (Indeed, Glassdoor), real estate (Zillow, Realtor, Redfin), retail (Nike, Best Buy, Etsy, Wayfair), and crypto/finance sites (CoinMarketCap, CoinGecko). Each tool was tested in its default configuration without additional proxy integration.
Newer, smaller community; fails on job boards and most retail
Puppeteer Extra + Stealth
~35% (4 pass, 3 partial)
Node.js projects
Slower plugin updates; same pass rate as Patchright
Undetected ChromeDriver
0%
Python/Selenium stacks
Failed on all 20 test domains; Selenium overhead
Overall, Patchright and Puppeteer Extra + Stealth tied with ~35% success, achieving full bypass on Best Buy, CoinMarketCap, and MediaMarkt, plus partial success on Nike, Skechers, and CoinGecko. Undetected ChromeDriver failed on every domain in our test, suggesting fortified browsers struggle against the anti-bot protections used by job boards, real estate sites, and most retail domains.
When & Why To Use The Fortified Headless Browser Bypass?
Fortified headless browsers are the go-to solution when you need to execute JavaScript, render dynamic content, or interact with pages while evading bot detection. They strike a balance between effectiveness and resource usage.
Ideal Use Cases
This method works best when:
JavaScript-Heavy Sites: Single-page applications, React/Vue/Angular sites, or pages requiring JavaScript execution to render content.
Interactive Scraping: When you need to click buttons, fill forms, scroll pages, or interact with elements to access data.
Medium Security Sites: Websites with Cloudflare's standard protection where TLS fingerprinting alone isn't enough.
Cookie Harvesting: Solving initial challenges to get valid session cookies for subsequent lightweight HTTP requests.
When NOT to Use This Method
Avoid fortified headless browsers when:
High Volume Scraping: Browser instances consume 100-500MB RAM each, making them impractical for millions of concurrent requests.
Speed is Critical: Page loads take 2-10+ seconds versus milliseconds for HTTP requests.
Simple Static Content: If a site works with curl_cffi or similar TLS fingerprinting tools, headless browsers add unnecessary overhead.
Maximum Stealth Required: For sites with the most aggressive anti-bot protection, even fortified browsers may be detected.
Cost Considerations
Pairing headless browsers with residential/mobile proxies can get expensive fast. Headless browsers typically consume 2MB of bandwidth per page (versus 250kb without). Here's an example cost breakdown using BrightData residential proxies:
Choose the tool that best fits your programming language and automation framework. Each has trade-offs in terms of stealth effectiveness, ease of use, and community support.
Undetected ChromeDriver is a patched Selenium ChromeDriver that hides common automation signals. It's the most popular fortified browser solution for Python.
Status: Actively maintained with a large community. Widely used in production scraping stacks.
Performance Notes: Effective against most Cloudflare configurations. Can struggle with sites using advanced fingerprinting or behavioral analysis. Works best when paired with quality proxies.
Installation
pip install undetected-chromedriver
Basic Usage
import undetected_chromedriver as uc driver = uc.Chrome() driver.get('https://cloudflare.com/') print(driver.title) driver.quit()
Usage With Proxies
To use authenticated proxies with Undetected ChromeDriver, you need to create a Chrome extension that handles proxy authentication:
Patchright is a patched version of Playwright with comprehensive stealth fixes to reduce automation artifacts. It's growing in popularity due to its effectiveness against modern anti-bot systems.
Status: Growing community support. More effective than basic Playwright stealth plugins and actively maintained.
Performance Notes: Currently one of the most effective open-source stealth solutions. Patches more detection vectors than Puppeteer stealth plugins. Works well against Cloudflare and similar anti-bot systems.
Status: Actively used but plugin updates have slowed. Known to be detectable on some advanced bot tests, but still functional for many sites.
Performance Notes: Was the original stealth solution and pioneered many techniques. Effectiveness has declined as anti-bot systems have adapted. Still works for medium-security sites but may struggle with aggressive protection.
Rebrowser Patches provides low-level patches to remove detectable automation leaks from Puppeteer and Playwright internals. Rather than being a standalone tool, these patches fix issues at the source.
Status: Actively maintained and used to patch several downstream automation builds. Addresses detection vectors that plugin-based solutions can't fix.
Performance Notes: These patches fix fundamental issues in how automation tools communicate with browsers (like the Runtime.Enable leak). They can significantly improve stealth when combined with other tools but require more setup.
How It Works
Rebrowser Patches modifies the actual automation protocol communication to remove detectable patterns. For example, it patches the Runtime.Enable command that anti-bot systems use to detect automation.
Key Patches Included:
Runtime.Enable leak fix: Removes the detectable CDP command pattern
Best For: Advanced users who want maximum stealth, developers building custom automation solutions, projects where standard stealth plugins aren't enough.
This section answers some frequently asked questions about using fortified headless browsers for bypassing Cloudflare.
What's the difference between Patchright and Undetected ChromeDriver?
Patchright is a patched version of Playwright (JavaScript/Python) that modifies the automation tool itself to remove detection vectors. Undetected ChromeDriver patches the Selenium ChromeDriver specifically for Python. Patchright generally has better bypass rates on modern sites, while Undetected ChromeDriver has a larger community and more mature ecosystem for Python developers.
Why is Puppeteer Stealth less effective than it used to be?
Puppeteer Stealth was the pioneer of browser automation stealth, but anti-bot companies have studied it extensively and developed specific detection methods. Plugin updates have also slowed compared to newer solutions. While it still works for many sites, tools like Patchright now patch more detection vectors and receive more active development.
Should I use headless or headed mode for stealth scraping?
Headed mode (headless=false) is generally more stealthy because some anti-bot systems can detect headless-specific fingerprints. However, headed mode requires a display (real or virtual like Xvfb). For production, many scrapers use headed mode with a virtual display, accepting the slight overhead for better success rates.
Do I need proxies with fortified headless browsers?
For light usage on medium-security sites, fortified browsers alone may work. However, for consistent results, pairing with quality proxies is recommended. Residential or mobile proxies provide higher IP reputation scores, making anti-bot systems less likely to challenge or block you even if some fingerprint artifacts remain.
What are Rebrowser Patches and when should I use them?
Rebrowser Patches fix low-level automation leaks that plugin-based solutions can't address—like the Runtime.Enable CDP command pattern. Use them when you need maximum stealth and are willing to do more setup. They're best combined with stealth plugins for layered protection against detection.
How do I choose between these tools for my project?
For Python: Use Undetected ChromeDriver if you prefer Selenium, or Patchright if you prefer Playwright (better bypass rates). For Node.js: Use Patchright for best results, or Puppeteer Extra + Stealth if you're already invested in the Puppeteer ecosystem. For maximum stealth, combine any of these with Rebrowser Patches.
This change log tracks any updates and revisions made to the Fortified Headless Browser Method over time.
Mar 24, 2026Performance tests added
Added performance testing for Undetected ChromeDriver, Patchright, and Puppeteer Extra + Stealth across 20 Cloudflare-protected domains with domain results.
Jun 1, 2024Patchright Added as Recommended Alternative
Added Patchright as a more effective alternative to standard Playwright stealth plugins following community adoption and testing.
Oct 26, 2022Original Section Published
Initial publication of the Fortified Headless Browser method as Option #4 for bypassing Cloudflare protection, featuring Undetected ChromeDriver and Puppeteer Stealth.
Cached or archived copies (Wayback Machine, search-engine cache, CDNs) sometimes expose the same HTML without Cloudflare in front. Use this when freshness requirements are loose and a snapshot is enough.
Cached Version Method
Instead of bypassing Cloudflare directly, sometimes it is possible to retrieve data from cached or archived versions of websites that don't have anti-bot protection.
Bypass Rank:#6 of 8
Domain Coverage:10%
Difficulty:Easy
Cost:Free
Best For:Best solution if the website data does not need to be fresh and rarely changes. Only viable when the target site has usable cached snapshots. Our testing shows only ~10% of sites do.
The Cached Version Bypass Method is a technique that allows you to bypass Cloudflare's anti-bot protection by retrieving data from cached or archived versions of websites.
Websites have traditionally allowed search engines and other archiving services to crawl and cache their websites, to improve search engine rankings and contribute to a open and accessible internet.
The bypass method works by retrieving the cached version of the website from the archiving service like Internet Archive's Wayback Machine and using that data instead of the live website.
To validate the effectiveness of this bypass method, we tested the performance of this method using the Internet Archive's Wayback Machine.
Here are the performance results across the 20 domains:
Domain
Status
indeed.com
FAIL
zillow.com
FAIL
realtor.com
FAIL
redfin.com
FAIL
glassdoor.com
FAIL
nike.com
FAIL
adidas.com
FAIL
bestbuy.com
FAIL
wayfair.com
FAIL
etsy.com
FAIL
Domain
Status
newegg.com
FAIL
skechers.com
FAIL
sneakersnstuff.com
FAIL
coinmarketcap.com
PASS
coingecko.com
PASS
investing.com
FAIL
etf.com
FAIL
mediamarkt.de
FAIL
pccomponentes.com
FAIL
controller.com
FAIL
Overall, the Cached Version Bypass Method performs poorly in practice, only 2 out of 20 tested domains (10%) returned usable cached data. The vast majority of sites now block archiving services from crawling their content, making this method unreliable for most targets.
It remains a viable option only when you've verified that your specific target site has recent, usable snapshots and you don't need real-time freshness.
The Cached Version Bypass Method is low-effort to try, but works for only a small minority of sites—our testing found a 10% success rate. It's still worth checking before investing in more complex bypass techniques, since archived content is served from third-party servers like archive.org where Cloudflare's protection doesn't apply.
Ideal Use Cases
This method works best when your scraping requirements align with the limitations of archived data:
Infrequent Updates: Websites that don't update frequently are often well-preserved in archives. Product descriptions, articles, blog posts, documentation, and other content that doesn't change frequently is often well-preserved in archives.
Heavily Protected Sites: When a target site has aggressive Cloudflare anti-bot measures that make direct scraping impractical or expensive, cached versions offer an alternative path to the data.
Backup Data Source: Use as a fallback when your primary scraping method encounters blocks or rate limits.
When NOT to Use This Method
Avoid the Cached Version Bypass when:
Real-Time Data is Critical: Price monitoring, inventory tracking, news aggregation, or any use case where data freshness matters.
Dynamic Content: Single-page applications, JavaScript-rendered content, user dashboards, or personalized pages are rarely captured correctly by archiving services.
Authenticated Content: Login-protected pages, user-specific data, and gated content are never archived.
High-Frequency Updates: Sites that update multiple times per day will have stale data in archives.
Important Consideration
With the rise of generative AI and concerns about content being used to train AI models, many websites are now actively blocking archiving services from crawling their content. Our testing found that only 2 out of 20 domains (10%) had usable cached data—a significant decline from previous years.
Always verify that your target site has recent, usable snapshots before building your scraping pipeline around this method.
Pros
Completely free to use with no API costs
Zero anti-bot protection on archived content
Access to years of historical data and page versions
No need for proxies, headless browsers, or complex setups
Great starting point before investing in advanced techniques
Cons
Low success rate, only ~10% of tested sites had usable cached data
Data freshness varies, snapshots may be days, weeks, or months old
Incomplete coverage, dynamic pages, APIs, and gated content are rarely archived
No control over when new snapshots are created
Declining effectiveness as more sites block archiving services
May not capture JavaScript-rendered content accurately
To use the Cached Version Bypass Method, you will have to update your scrapers to send the requests to the cached version of the website instead of the live website.
The Internet Archive's Wayback Machine stores archived snapshots of webpages. Because the archived page is served from archive.org and not the original host, Cloudflare protections do not apply to requests for those archived snapshots.
How to Use It
Step 1: Check for available snapshots
Use the Wayback Machine API to find the closest archived version:
import requests wayback_url ='https://archive.org/wayback/available?url=example.com' response = requests.get(wayback_url) data = response.json() if data.get('archived_snapshots'): archived_url = data['archived_snapshots']['closest']['url'] print("Use this snapshot:", archived_url) else: print("No archived version available.")
This returns the nearest snapshot for example.com if one exists. The archived URL can then be used directly.
Step 2: Request the archived page
Once you have the archived URL, you fetch it like a normal webpage:
archived_html = requests.get(archived_url).text # parse archived_html as needed
This content is served by the archive rather than the protected site.
Step 3: Iterate through multiple snapshots (optional)
If you need historical data, you can collect snapshot lists using the wildcard pattern:
This returns a list of all snapshots around those timestamps.
Frequently Asked Questions: Cached Version Bypass
This section answers some frequently asked questions about the Cached Version Bypass Method.
What is the Cached Version Bypass Method?
The Cached Version Bypass Method involves retrieving website data from the Internet Archive's Wayback Machine instead of scraping the live Cloudflare-protected website directly. Since archived content is served from third-party servers like archive.org, Cloudflare's protection simply doesn't apply, allowing you to access the data without triggering anti-bot systems.
When should I use the Cached Version method instead of other bypass techniques?
This method is ideal for research and analysis projects, static content extraction (product descriptions, articles, documentation), historical data collection, and as a backup data source when primary methods hit blocks. It works best when you don't need real-time data and want a free, simple solution without proxies or headless browsers.
How fresh is the data from cached versions?
Data freshness varies significantly—snapshots may be days, weeks, or months old depending on how often the site is archived. Since Google, Bing, and Yahoo have discontinued their cache features, only the Wayback Machine is available, and you have no control over when new snapshots are created. Always verify your target site has recent, usable snapshots before building your pipeline around this method.
Why don't all websites work with the cached version method?
With the rise of generative AI and concerns about content being used to train AI models, many websites are now actively blocking archiving services from crawling their content. Additionally, dynamic content, JavaScript-rendered pages, single-page applications, authenticated content, and gated pages are rarely captured correctly by archiving services. This has significantly reduced the coverage and freshness of available snapshots compared to previous years.
Is using cached versions legal for web scraping?
While accessing publicly archived data is generally legal, you should still review the terms of service of both the archiving service and the original website. The cached data remains subject to any copyright or usage restrictions that apply to the original content. Always consult with legal counsel if you're unsure about your specific use case.
This change log tracks any updates and revisions made to the Cached Version Bypass Method over time.
Mar 24, 2026Performance tests added
Added performance testing across 20 Cloudflare-protected domains (Wayback Machine benchmark) with domain results.
Jan 15, 2026Replaced Google Cache with Alternative Data Sources
Google discontinued their cache feature in February 2024. This section now covers Wayback Machine, official APIs, mobile versions, and RSS/sitemap data as alternatives to direct scraping.
Dec 1, 2024Bing and Yahoo Cache Features Removed
Microsoft removed Bing's cache link and cache: operator support from search results. Yahoo's cache, which relied on Bing's infrastructure, also stopped functioning. Search engines now link to third-party archives like the Wayback Machine instead.
Sep 1, 2024Google Cache Operator Fully Disabled
Google disabled the cache: search operator entirely, so using cache:example.com no longer returns archived copies. Google's public documentation for the cache: operator was also removed, confirming the feature is no longer supported.
Feb 1, 2024Google Cache Discontinued
Google officially removed the 'Cached' link from search results and discontinued the webcache.googleusercontent.com service. The previous advice to use Google Cache for scraping Cloudflare-protected sites is no longer valid.
Oct 26, 2022Original Section Published
Initial publication of the Google Cache scraping method as Option #2 for bypassing Cloudflare protection.
Origin bypass means finding the site’s real host IP (DNS history, misconfigurations, headers) and requesting it directly so traffic never hits Cloudflare’s edge. It only works when the origin is reachable and not locked to Cloudflare-only traffic.
Origin Server Method
Instead of bypassing Cloudflare's anti-bot protection, you can sometimes completely bypass Cloudflare by finding the IP address of the origin server and sending your requests directly to it.
Bypass Rank:#7 of 8
Domain Coverage:0%
Difficulty:Easy
Cost:Free
Best For:Only when you find a misconfigured exposed origin; our 20-domain benchmark had 0% success—typically only smaller or poorly locked-down sites.
The Origin Server Bypass Method is a technique that allows you to bypass Cloudflare's anti-bot protection by sending requests directly to the website's origin server IP address instead of to Cloudflare's CDN network.
Instead of having to trick Cloudflare into thinking your requests are from a real user, you bypass Cloudflare completely by finding the IP address of the origin server that hosts the website and send your requests to that instead—completely bypassing Cloudflare and all its protections!
Cloudflare is a sophisticated anti-bot protection system, but it is setup by humans who:
Mightn't fully understand Cloudflare,
Might cut corners, or
Make mistakes when setting up their website on Cloudflare.
Because of this, sometimes with a bit of snooping around you can find the IP address of the server that hosts the master version of the website. Once you find this IP address, you can configure your scrapers to send the requests to this server instead of Cloudflare's servers which have the anti-bot protection active.
The Origin Server Bypass Method is the ultimate low-effort, high-reward approach when it works. If you can find an exposed origin server, you can scrape without any anti-bot protection at all—no proxies, no headless browsers, no fingerprinting concerns.
Ideal Use Cases
This method works best when:
Misconfigured Cloudflare Setup: The website administrators haven't properly restricted access to the origin server or haven't set up Origin CA certificates.
Legacy Infrastructure: Older websites that added Cloudflare as an afterthought without updating their server configuration.
Cost-Sensitive Projects: When you need free, unlimited access without spending on proxies or anti-bot bypass services.
Simple Scraping Needs: When you just need the HTML content and don't require JavaScript rendering.
When NOT to Use This Method
Avoid the Origin Server Bypass when:
Properly Configured Sites: Well-secured websites limit their origin servers to only accept traffic from Cloudflare IP ranges.
Origin CA Certificates: Sites using Cloudflare's Origin CA certificates will reject direct connections.
Dynamic Content: If the site relies heavily on Cloudflare's edge features (Workers, caching), the origin may not serve the same content.
Time Constraints: Finding the origin IP can be time-consuming with no guarantee of success.
Important Consideration
Even if you find what appears to be an origin server, it may be a development or staging server rather than the production server. Verify that the data matches the live site before building your scraping pipeline around it.
Pros
Completely bypasses all Cloudflare anti-bot protection
Free to use with no API costs or proxy fees
No need for headless browsers or complex fingerprinting
Simple HTTP requests work, making scraping fast and efficient
No rate limiting from Cloudflare (though origin may have its own limits)
Cons
Low success rate, most sites are properly configured
Time-consuming to find origin IP with no guarantee of success
Origin server may be restricted to Cloudflare IP ranges only
Found server might be staging/development, not production
Site admins can fix the vulnerability at any time, breaking your scraper
To validate the effectiveness of this bypass method, we tested whether we could find and access origin servers for our test domains.
Here are the performance results across the 20 domains:
Domain
Status
indeed.com
FAIL
zillow.com
FAIL
realtor.com
FAIL
redfin.com
FAIL
glassdoor.com
FAIL
nike.com
FAIL
adidas.com
FAIL
bestbuy.com
FAIL
wayfair.com
FAIL
etsy.com
FAIL
Domain
Status
newegg.com
FAIL
skechers.com
FAIL
sneakersnstuff.com
FAIL
coinmarketcap.com
FAIL
coingecko.com
FAIL
investing.com
FAIL
etf.com
FAIL
mediamarkt.de
FAIL
pccomponentes.com
FAIL
controller.com
FAIL
In our benchmark, none of the 20 test domains (0%) yielded a working origin bypass—every domain either hid the origin IP or rejected direct access. Most major websites properly configure their infrastructure to prevent direct origin access. When this method does work on a misconfigured site, it provides the easiest and most reliable bypass available.
To use the Origin Server Bypass Method, you need to find the IP address of the origin server and configure your scraper to send requests directly to it.
How to Find the Origin IP Address
There are several methods to find the origin IP address of a website's server:
Method 1: SSL Certificates
If the target website is using SSL certificates (most sites are), those SSL certificates are registered in the Censys database.
Although websites have deployed their website onto the Cloudflare CDN, sometimes their current or old SSL certificates are registered to the original server. You can look up the website in the Censys database and see if any of these servers host the origin website.
Method 2: DNS Records Of Other Services
Sometimes other subdomains, mail exchanger (MX) servers, FTP/SCP services or hostnames are hosted on the same server as the main website but haven't been protected by the Cloudflare network.
Check the DNS records for other subdomains or A, AAAA, CNAME, and MX DNS records that reveal the IP address of the main server using Censys or Shodan.
One trick: send an email to a non-existing email address at your target website (fakeemail@targetwebsite.com). Assuming the delivery fails, you should receive a notification from the email server which will contain the IP address (provided the website isn't using a 3rd party email provider).
Method 3: Old DNS Records
The DNS history of every server is available on the internet. Sometimes the website is still hosted on the same server as it was before they deployed it to the Cloudflare CDN. Tools like CrimeFlare maintain databases of likely origin servers derived from current and old DNS records.
Useful Tools
The following tools can help you find the original IP address of the server:
For example, the origin IP address of PetsAtHome.com, a Cloudflare protected site, is publicly accessible:
Origin IP Address --> 'http://88.211.26.45/'
Step 1: Send requests to the origin IP
import requests # Instead of requesting through Cloudflare # response = requests.get('https://www.petsathome.com/') # Request directly to the origin server response = requests.get('http://88.211.26.45/', headers={ 'Host':'www.petsathome.com'# Important: Set the Host header }) print(response.text)
Step 2: Handle Host Headers
Sometimes accessing the website via the origin IP address by inserting it in your browser's address bar won't work, as the server may be expecting an HTTP Host header. When this is the case, you can query the origin server with a tool like curl or Postman which allows you to set Host headers, or add a static mapping to your hosts file.
# Using curl with Host header curl -H "Host: www.targetsite.com" http://ORIGIN_IP_ADDRESS/
This section answers some frequently asked questions about the Origin Server Bypass Method.
What is the Origin Server Bypass Method?
The Origin Server Bypass Method involves finding the IP address of a website's origin server and sending requests directly to it, bypassing Cloudflare's CDN and anti-bot protection entirely. Since your requests never touch Cloudflare's servers, none of their protection mechanisms apply.
Why doesn't this method work for most websites?
Most well-configured websites restrict their origin servers to only accept traffic from Cloudflare's IP ranges, use Origin CA certificates that reject direct connections, or have properly hidden their origin IP addresses. The method only works when website administrators have made configuration mistakes or cut corners during setup.
How do I know if I found the real origin server or a staging server?
You can never be 100% certain, but there are indicators: browse around and verify the data matches the live site, try registering an account on the 'origin version' and see if you can log in to the real website with it, and check if product/content IDs match between both versions. If everything aligns, it's likely the production origin server.
What happens if the site fixes their configuration?
If the website administrators discover and fix the exposed origin server, your scraper will stop working immediately. This is why it's important to have backup bypass methods ready and to monitor your scrapers for sudden failures. The origin server method should be seen as a lucky shortcut, not a permanent solution.
Do I need proxies when accessing the origin server directly?
Generally no—since you're bypassing Cloudflare, you don't need proxies to avoid their detection. However, the origin server itself may have rate limiting or IP-based blocking, so proxies might still be useful for high-volume scraping to avoid overloading a single IP address.
This change log tracks any updates and revisions made to the Origin Server Bypass Method over time.
Mar 24, 2026Performance tests added
Added performance testing across 20 Cloudflare-protected domains for origin server access; all attempts failed (0/20) in this run. Updated domain coverage metric to reflect empirical results.
Oct 26, 2022Original Section Published
Initial publication of the Origin Server Bypass Method as Option #1 for bypassing Cloudflare protection.
Reverse engineering means studying Cloudflare’s WAF, Bot Management, and challenge scripts, then implementing a minimal client that passes TLS, HTTP/2, header, and JS checks yourself—no hosted proxy or full browser farm unless you choose to add one.
Reverse Engineering Method
Build a custom low-level bypass by reverse engineering Cloudflare's anti-bot protection system, passing TLS fingerprint, browser header, and JavaScript challenge checks without using a full headless browser.
Bypass Rank:#8 of 8
Domain Coverage:N/A
Difficulty:Expert
Cost:Free
Best For:Not recommended. Only go down this route if you enjoy technical challenges and reverse engineering.
This approach involves deeply analyzing Cloudflare's Web Application Firewall (WAF) and Bot Manager to understand exactly how they detect bots, then building a custom bypass that passes all their checks without relying on resource-heavy headless browsers.
The goal is to create the most resource-efficient Cloudflare bypass possible—one solely designed to pass Cloudflare's TLS, HTTP/2, browser header, and JavaScript fingerprint tests using lightweight HTTP requests.
This is what many smart proxy solutions do internally. They've invested heavily in reverse engineering Cloudflare's detection systems so their customers don't have to.
Cloudflare's bot detection can be split into two categories:
Category
Description
Techniques
Backend Detection
Server-side fingerprinting before the page loads
IP reputation, HTTP headers, TLS/HTTP2 fingerprints
This method is not recommended for most developers. It's an extreme approach reserved for very specific situations where the engineering investment makes economic sense.
Ideal Use Cases
This method works best when:
Massive Scale Operations: Companies scraping 500M+ pages per month where browser instance costs become prohibitive.
Building Proxy Infrastructure: Smart proxy providers who need cost-effective bypasses as their core business.
Intellectual Challenge: Researchers or developers genuinely interested in understanding sophisticated anti-bot systems.
Maximum Resource Efficiency: When you need the absolute lowest resource footprint per request.
When NOT to Use This Method
Avoid reverse engineering when:
Any Other Option Works: If smart proxies, fortified browsers, or solvers meet your needs, use them instead.
Time-Sensitive Projects: This approach can take weeks or months to implement successfully.
Limited Engineering Resources: You need dedicated, skilled engineers to build and maintain the bypass.
Small to Medium Scale: The cost savings don't justify the engineering investment below enterprise scale.
Why Most People Shouldn't Do This
For most developers, you are better off using one of the other six Cloudflare bypassing methods. The engineering effort required is substantial:
You must dive deep into an anti-bot system that has been purposefully obfuscated
You need to continuously split test different techniques to find what works
You must maintain the system as Cloudflare evolves their protection (which they do regularly)
The economic returns from having a more cost-effective Cloudflare bypass must warrant the days or weeks of engineering time you'll devote to building and maintaining it.
Pros
Most resource-efficient bypass possible (no browser overhead)
Lowest cost per request at extreme scale
Full control over every aspect of the bypass
Deep understanding of anti-bot systems
Can be faster than browser-based approaches
Cons
Extremely difficult to implement correctly
Requires weeks or months of engineering effort
Needs continuous maintenance as Cloudflare evolves
Must understand TLS, HTTP/2, and JavaScript internals
High risk of wasted effort if bypass stops working
Unlike other methods in this guide, we did not performance test reverse engineering approaches across our test domains. The nature of this method makes standardized testing impractical:
Each implementation is unique: Reverse engineered bypasses are custom-built, making comparison meaningless
Labor intensive to replicate: Building even one working bypass would require significant engineering effort
Constantly changing target: Any specific bypass technique may stop working as Cloudflare updates
What we know from the industry:
Aspect
Reality
Success Rate
Highly variable—depends entirely on implementation quality
Domain Coverage
Can theoretically achieve near-100% if done correctly
Maintenance Burden
Requires ongoing updates as Cloudflare evolves
Cost Efficiency
Most efficient at scale, but high upfront investment
Recommendation: Unless you're operating at massive scale or building proxy infrastructure, use Smart Proxies with Built-in Bypass instead—they've already done the reverse engineering for you. For lightweight bypass, try TLS Impersonation first.
Cloudflare detects you when your user-agent says "Chrome" but your TLS fingerprint says "Python Requests." All fingerprints must be consistent—headers, TLS, and HTTP/2 must all tell the same story.
Cloudflare uses Google's Picasso Fingerprinting to classify devices via HTML5 canvas rendering. Your canvas fingerprint must match your claimed browser/OS combination.
Reverse engineering for interoperability purposes is generally legal in most jurisdictions, but you should consult with a legal professional for your specific situation. The legality also depends on what you're scraping and the terms of service of the target websites.
How long does it take to build a working Cloudflare bypass?
Expect weeks to months of dedicated engineering effort for a production-quality bypass. The initial implementation is just the beginning—Cloudflare updates their detection regularly, so ongoing maintenance is required.
Why do smart proxy providers charge so much if they've already done this work?
Building and maintaining a Cloudflare bypass requires significant ongoing engineering investment. Smart proxy providers spread this cost across thousands of customers, making it much cheaper than building your own. At enterprise scale (500M+ requests/month), the economics may favor building in-house.
Can I partially reverse engineer and use headless browsers for the rest?
Yes, hybrid approaches are common. You might handle TLS fingerprinting with curl_cffi and only use headless browsers for sites requiring JavaScript challenge solving. This balances resource efficiency with development complexity.
What programming languages are best for building a bypass?
Go and Rust offer the best low-level control for TLS fingerprint manipulation. Python can work with curl_cffi bindings. Node.js with got-scraping is another option. The key is having control over TLS cipher suites and HTTP/2 settings.
How often does Cloudflare update their detection?
Cloudflare continuously evolves their detection. Major updates happen every few months, but smaller changes can happen weekly. Any bypass you build will require ongoing monitoring and updates to remain effective.
This change log tracks any updates and revisions made to the Reverse Engineering Method over time.
Oct 26, 2022Original Section Published
Initial publication of the Reverse Engineering method as Option #7 for bypassing Cloudflare protection, covering basic concepts of TLS fingerprinting and JavaScript challenge solving.
So when it comes to bypassing Cloudflare you have multiple options. Some are pretty quick and easy, others are a lot more complex. Each with their own tradeoffs.
If you would like to learn how to scrape some popular websites then check out our other How To Scrape Guides:
Or if you would like to learn more about web scraping in general, then be sure to check out The Web Scraping Playbook, or check out one of our more in-depth guides: