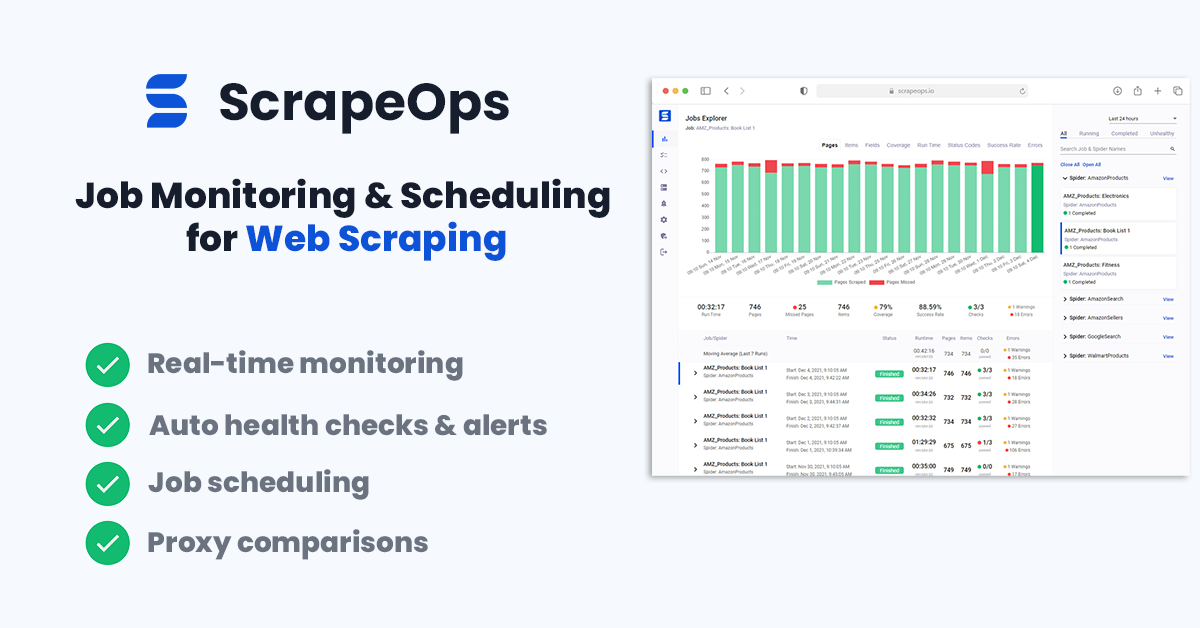
Something's breaking in web scraping.
Success rates are slipping. Costs are spiralling. Teams are struggling to keep up.
The proxies are cheaper. The infrastructure is more sophisticated.
But the math no longer works.
Proxies that once cost $30 per GB now go for $1.
Yet the cost of a successful scrape, one clean, validated payload, has doubled or tripled or 10X.
Web scraping hasn't gotten harder because of access.
It's gotten harder because of economics.
Retries, JS rendering, and anti-bot bypasses now consume more budget than bandwidth.
Every website is still technically scrapable, but fewer make financial sense to scrape at scale.
The barrier isn't access anymore. It's affordability.
This is Scraping Shock, the moment cheap access collides with expensive success.
In this article, we will dive deep into the most important trend affecting web scraping today: