Web Scraping Guide Part 2: Cleaning Dirty Data & Dealing With Edge Cases
After Part 1 showed you how to get data, Part 2 is about making that data usable.
Real‑world pages are messy: sale‑price prefixes, missing fields, mixed currencies, duplicate rows, and relative URLs are all par for the course. To tame that chaos we’ll:
- Detect & normalise edge cases – strip rogue text, unify currencies, and fill blanks.
- Model records with Data Classes / JavaScript Classes – typed, self‑cleaning containers for each product.
- Stream data through a pipeline – de‑duplicate, batch, then persist to CSV (or any sink you prefer).
You’ll see identical patterns implemented five ways:
- Python → Requests + BeautifulSoup and Selenium
- Node.js → Axios + Cheerio, Puppeteer, and Playwright
Pick the stack you use daily—or skim them all to compare approaches. By the end, your scraper will output a rock‑solid dataset ready for databases, BI dashboards, or machine‑learning rigs.
- Python Requests + BeautifulSoup
- Python Selenium
- Node.js Axios + Cheerio
- Node.js Puppeteer
- Node.js Playwright

Python Requests/BS4 Beginners Series Part 2: Cleaning Dirty Data & Dealing With Edge Cases
In Part 1 of this Python Requests/BeautifulSoup 6-Part Beginner Series, we learned the basics of scraping with Python and built our first Python scraper.
Web data can be messy, unstructured, and have many edge cases. So, it's important that your scraper is robust and deals with messy data effectively.
So, in Part 2: Cleaning Dirty Data & Dealing With Edge Cases, we're going to show you how to make your scraper more robust and reliable.
- Strategies to Deal With Edge Cases
- Structure your scraped data with Data Classes
- Process and Store Scraped Data with Data Pipeline
- Testing Our Data Processing
- Next Steps
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Python Requests/BeautifulSoup 6-Part Beginner Series
-
Part 1: Basic Python Requests/BeautifulSoup Scraper - We'll go over the basics of scraping with Python, and build our first Python scraper. (Part 1)
-
Part 2: Cleaning Dirty Data & Dealing With Edge Cases - Web data can be messy, unstructured, and have lots of edge cases. In this tutorial we'll make our scraper robust to these edge cases, using data classes and data cleaning pipelines. (Part 2)
-
Part 3: Storing Data in AWS S3, MySQL & Postgres DBs - There are many different ways we can store the data that we scrape from databases, CSV files to JSON format, and S3 buckets. We'll explore several different ways we can store the data and talk about their pros, and cons and in which situations you would use them. (Part 3)
-
Part 4: Managing Retries & Concurrency - Make our scraper more robust and scalable by handling failed requests and using concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Make our scraper production ready by using fake user agents & browser headers to make our scrapers look more like real users. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Explore how to use proxies to bypass anti-bot systems by hiding your real IP address and location. (Part 6)
The code for this project is available on GitHub.
Strategies to Deal With Edge Cases
Web data is often messy and incomplete which makes web scraping a bit more complicated for us. For example, when scraping e-commerce sites, most products follow a specific data structure. However, sometimes, things are displayed differently:
- Some items have both a regular price and a sale price.
- Prices might include sales taxes or VAT in some cases but not others.
- If a product is sold out, its price might be missing.
- Product descriptions can vary, with some in paragraphs and others in bullet points.
Dealing with these edge cases is part of the web scraping process, so we need to come up with a way to deal with it.
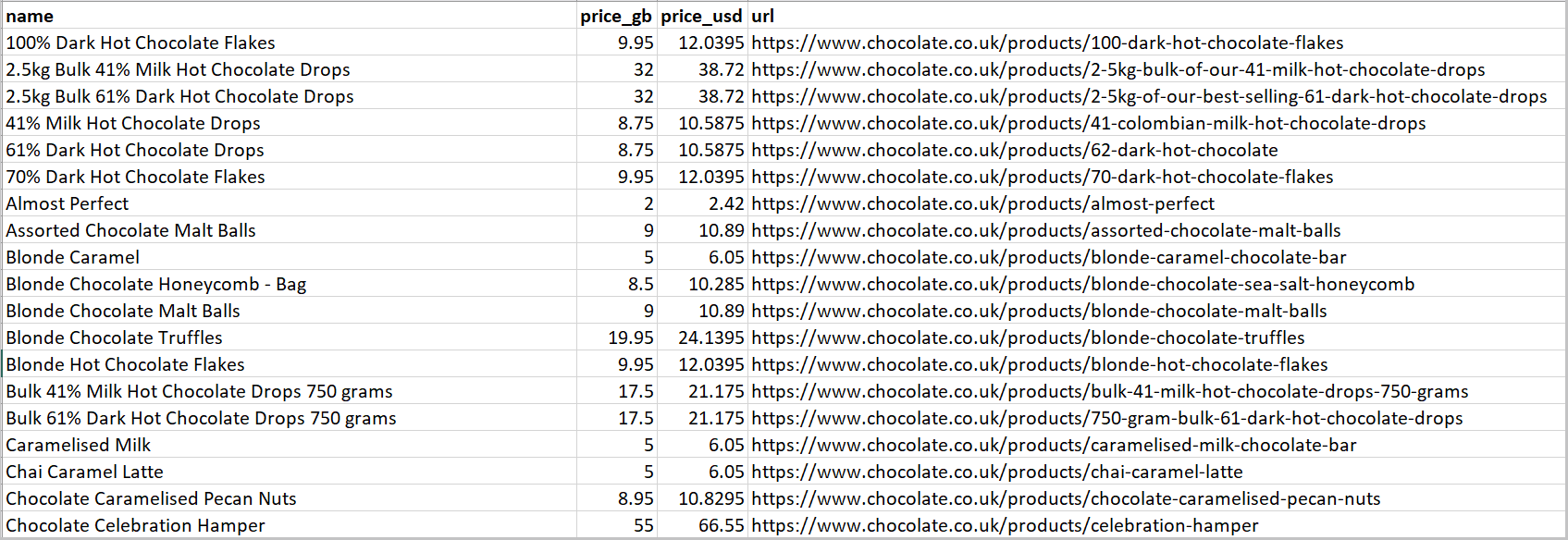
In the case of the chocolate.co.uk website that we’re scraping for this series, if we inspect the data we can see a couple of issues.
Here's a snapshot of the CSV file that will be created when you scrape and store data using Part 1 of this series.
In the price section, you'll notice that some values are solely numerical (e.g. 9.95), while others combine text and numbers, such as "Sale priceFrom £2.00". This shows that the data is not properly cleaned, as the “Sale priceFrom £2.00” should be represented as 2.00.

There might be some other couple of issues such as:
- Some prices are missing, either because the item is out of stock or the price wasn't listed.
- The prices are currently shown in British Pounds (GBP), but we need them in US Dollars (USD).
- Product URLs are relative and would be preferable as absolute URLs for easier tracking and accessibility.
- Some products are listed multiple times.
There are several options to deal with situations like this:
| Options | Description |
|---|---|
| Try/Except | You can wrap parts of your parsers in Try/Except blocks so if there is an error scraping a particular field, it will then revert to a different parser. |
| Conditional Parsing | You can have your scraper check the HTML response for particular DOM elements and use specific parsers depending on the situation. |
| Data Classes | With data classes, you can define structured data containers that lead to clearer code, reduced boilerplate, and easier manipulation. |
| Data Pipelines | With Data Pipelines, you can design a series of post-processing steps to clean, manipulate, and validate your data before storing it. |
| Clean During Data Analysis | You can parse data for every relevant field, and then later in your data analysis pipeline clean the data. |
Every strategy has its pros and cons, so it's best to familiarize yourself with all methods thoroughly. This way, you can easily choose the best option for your specific situation when you need it.
In this project, we're going to focus on using Data Classes and Data Pipelines as they are the most powerful options available in BS4 to structure and process data.
Structure your scraped data with Data Classes
In Part 1, we scraped data (name, price, and URL) and stored it directly in a dictionary without proper structuring. However, in this part, we'll use data classes to define a structured class called Product and directly pass the scraped data into its instances.
Data classes in Python offer a convenient way of structuring and managing data effectively. They automatically handle the creation of common methods like __init__, __repr__, __eq__, and __hash__, eliminating the need for repetitive boilerplate code.
Additionally, data classes can be easily converted into various formats like JSON, CSV, and others for storage and transmission.
The following code snippet directly passes scraped data to the product data class to ensure proper structuring and management.
Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
To use this data class within your code, you must first import it. We'll import the following methods, as they'll be used later in the code: dataclass, field, fields, InitVar, and asdict.
- The
@dataclassdecorator is used to create data classes in Python. - The
field()function allows you to explicitly control how fields are defined. For example, you can: Set default values for fields and specify whether a field should be included in the automatically generated__init__method. - The
fields()function returns a tuple of objects that describe the class's fields. - The
InitVaris used to create fields that are only used during object initialization and are not included in the final data class instance. - The
asdict()method converts a data class instance into a dictionary, with field names as keys and field values as the corresponding values.
from dataclasses import dataclass, field, fields, InitVar, asdict
Let's examine the Product data class. We passed three arguments to it but we defined five arguments within the class.
- name: Defined with a default value of an empty string.
- price_string: This is defined as an
InitVar, meaning it will be used for initialization but not stored as a field. We'll useprice_stringto calculateprice_gbandprice_usd. - price_gb and price_usd: These are defined as
field(init=false), showing that they will not be included in the default constructor generated by the data class. This means they won't be part of the initialization process, but we can utilize them later. - url: This is initialized as an empty string.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
pass
def clean_price(self, price_string):
pass
def convert_price_to_usd(self):
pass
def create_absolute_url(self):
pass
The __post_init__ method allows for additional processing after initializing the object. Here we’re using it to clean and process the input data during initialization to derive attributes such as name, price_gb, price_usd, and url.
Using Data Classes we’re going to do the following:
clean_priceClean thepriceto remove the substrings like "Sale price£" and "Sale priceFrom £”.convert_price_to_usdConvert thepricefrom British Pounds to US Dollars.clean_nameClean the name by stripping leading and trailing whitespaces.create_absolute_urlConvert relative URL to absolute URL.
Clean the Price
Cleans up price strings by removing specific substrings like "Sale price£" and "Sale priceFrom £", then converting the cleaned string to a float. If a price string is empty, the price is set to 0.0.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price£", "")
price_string = price_string.replace("Sale priceFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
Convert the Price
The prices scraped from the website are in the GBP, convert GBP to USD by multiplying the scraped price by the exchange rate (1.21 in our case).
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
"""
Previous code
"""
def convert_price_to_usd(self):
return self.price_gb * 1.21
Clean the Name
Cleans up product names by stripping leading and trailing whitespaces. If a name is empty, it's set to "missing".
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
"""
Previous code
"""
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
Convert Relative to Absolute URL
Creates absolute URLs for products by appending their URLs to the base URL.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
"""
Previous code
"""
def create_absolute_url(self):
if self.url == "":
return "missing"
return "https://www.chocolate.co.uk" + self.url
This is how data classes are helping us to easily structure and manage our messy scraped data. They are properly checking edge cases and replacing unnecessary text. This cleaned data will then be returned to the data pipeline for further processing.
Here’s the snapshot of the data that will be returned from the product data class. It consists of name, price_gb, price_usd, and url.

Here's the complete code for the product data class.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price£", "")
price_string = price_string.replace("Sale priceFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == "":
return "missing"
return "https://www.chocolate.co.uk" + self.url
Let's test our Product data class:
p = Product(
name='Lovely Chocolate',
price_string='Sale priceFrom £1.50',
url='/products/100-dark-hot-chocolate-flakes'
)
print(p)
Output:
Product(name='Lovely Chocolate', price_gb=1.5, price_usd=1.815, url='https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes')
Process and Store Scraped Data with Data Pipeline
Now that we’ve our clean data, we'll use Data Pipelines to process this data before saving it. The data pipeline will help us to pass the data from various pipelines for processing and finally store it in a csv file.
Using Data Pipelines we’re going to do the following:
- Check if an Item is a duplicate and drop it if it's a duplicate.
- Add the process data to the storage queue.
- Save the processed data periodically to the CSV file.
Let's first examine the ProductDataPipeline class and its __init__ constructor.
import os
import time
import csv
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
pass
def clean_raw_product(self, scraped_data):
pass
def is_duplicate(self, product_data):
pass
def add_product(self, scraped_data):
pass
def close_pipeline(self):
pass
Here we define six methods in this ProductDataPipeline class:
__init__: Initializes the product data pipeline with parameters like CSV filename and storage queue limit.save_to_csv: Periodically saves the products stored in the pipeline to a CSV file.clean_raw_product: Cleans scraped data and returns aProductobject.is_duplicate: Checks if a product is a duplicate based on its name.add_product: Adds a product to the pipeline after cleaning and checks for duplicates before storing, and triggers saving to CSV if necessary.
Within the __init__ constructor, five variables are defined, each serving a distinct purpose:
name_seen: This list is used for checking duplicates.storage_queue: This queue holds products temporarily until a specified storage limit is reached.storage_queue_limit: This variable defines the maximum number of products that can reside in thestorage_queue.csv_filename: This variable stores the name of the CSV file used for product data storage.csv_file_open: This boolean variable tracks whether the CSV file is currently open or closed.
Add the Product
To add product details, we first clean them with the clean_raw_product function. This sends the scraped data to the Product class, which cleans and organizes it and then returns a Product object holding all the relevant data. We then double-check for duplicates with the is_duplicate method. If it's new, we add it to a storage queue.
This queue acts like a temporary holding bin, but once it reaches its limit (five items in this case) and no CSV file is open, we'll call the save_to_csv function. This saves the first five items from the queue to a CSV file, emptying the queue in the process.
import os
import time
import csv
class ProductDataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if (
len(self.storage_queue) >= self.storage_queue_limit
and self.csv_file_open == False
):
self.save_to_csv()
Check for Duplicate Product
This method checks for duplicate product names. If a product with the same name has already been encountered, it prints a message and returns True to indicate a duplicate. If the name is not found in the list of seen names, it adds the name to the list and returns False to indicate a unique product.
import os
import time
import csv
class ProductDataPipeline:
"""
Previous code
"""
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
Periodically Save Data to CSV
Now, when the storage_queue_limit reaches 5 (its maximum), the save_to_csv() function is called. The csv_file_open variable is set to True to indicate that CSV file operations are underway. All data is extracted from the queue, appended to the products_to_save list, and the queue is then cleared for subsequent data storage.
The fields method is used to extract the necessary keys. As previously mentioned, fields return a tuple of objects that represent the fields associated with the class. Here, we've 4 fields (name, price_gb, price_usd, and url) that will used as keys.
A check is performed to determine whether the CSV file already exists. If it does not, the keys are written as headers using the writeheader() function. Otherwise, if the file does exist, the headers are not written again, and only the data is appended using the csv.DictWriter.
A loop iterates through the products_to_save list, writing each product's data to the CSV file. The asDict method is responsible for converting each Product object into a dictionary where all the values are used as the row data. Once all data has been written, the csv_file_open variable is set to False to indicate that CSV file operations have concluded.
import os
import time
import csv
class ProductDataPipeline:
"""
Previous code
"""
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
)
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
Wait, you may have noticed that we're storing data in a CSV file periodically instead of waiting for the entire scraping script to finish.
We've implemented a queue-based approach to manage data efficiently and save it to the CSV file at appropriate intervals. Once the queue reaches its limit, the data is written to the CSV file.
This way, if the script encounters errors, crashes, or experiences interruptions, only the most recent batch of data is lost, not the entire dataset. This ultimately improves overall processing speed.
Full Data Pipeline Code
Here's the complete code for the ProductDataPipeline class.
import os
import time
import csv
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode='a', newline='', encoding='utf-8') as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get('name', ''),
price_string=scraped_data.get('price', ''),
url=scraped_data.get('url', '')
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
Let's test our ProductDataPipeline class:
## Initialize The Data Pipeline
data_pipeline = ProductDataPipeline(csv_filename='product_data.csv')
## Add To Data Pipeline
data_pipeline.add_product({
'name': 'Lovely Chocolate',
'price': 'Sale priceFrom £1.50',
'url': '/products/100-dark-hot-chocolate-flakes'
})
## Add To Data Pipeline
data_pipeline.add_product({
'name': 'My Nice Chocolate',
'price': 'Sale priceFrom £4',
'url': '/products/nice-chocolate-flakes'
})
## Add To Duplicate Data Pipeline
data_pipeline.add_product({
'name': 'Lovely Chocolate',
'price': 'Sale priceFrom £1.50',
'url': '/products/100-dark-hot-chocolate-flakes'
})
## Close Pipeline When Finished - Saves Data To CSV
data_pipeline.close_pipeline()
Here we:
- Initialize The Data Pipeline: Creates an instance of
ProductDataPipelinewith a specified CSV filename. - Add To Data Pipeline: Adds three products to the data pipeline, each with a name, price, and URL. Two products are unique and one is a duplicate product.
- Close Pipeline When Finished - Saves Data To CSV: Closes the pipeline, ensuring all pending data is saved to the CSV file.
CSV file output:
name,price_gb,price_usd,url
Lovely Chocolate,1.5,1.815,https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes
My Nice Chocolate,4.0,4.84,https://www.chocolate.co.uk/products/nice-chocolate-flakes
Testing Our Data Processing
When we run our code, we should see all the chocolates, being crawled with the price now displaying in both GBP and USD. The relative URL is converted to an absolute URL after our Data Class has cleaned the data. The data pipeline has dropped any duplicates and saved the data to the CSV file.
Here’s the snapshot of the completely cleaned and structured data:

Here is the full code with the Product Dataclass and the Data Pipeline integrated:
import os
import time
import csv
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ''
price_string: InitVar[str] = ''
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ''
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == '':
return 'missing'
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace('Sale price£', '')
price_string = price_string.replace('Sale priceFrom £', '')
if price_string == '':
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == '':
return 'missing'
return 'https://www.chocolate.co.uk' + self.url
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode='a', newline='', encoding='utf-8') as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get('name', ''),
price_string=scraped_data.get('price', ''),
url=scraped_data.get('url', '')
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
list_of_urls = [
'https://www.chocolate.co.uk/collections/all',
]
## Scraping Function
def start_scrape():
## Loop Through List of URLs
for url in list_of_urls:
## Send Request
response = requests.get(url)
if response.status_code == 200:
## Parse Data
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('product-item')
for product in products:
name = product.select('a.product-item-meta__title')[0].get_text()
price = product.select('span.price')[0].get_text().replace('\nSale price£', '')
url = product.select('div.product-item-meta a')[0]['href']
## Add To Data Pipeline
data_pipeline.add_product({
'name': name,
'price': price,
'url': url
})
## Next Page
next_page = soup.select('a[rel="next"]')
if len(next_page) > 0:
list_of_urls.append('https://www.chocolate.co.uk' + next_page[0]['href'])
if __name__ == "__main__":
data_pipeline = ProductDataPipeline(csv_filename='product_data.csv')
start_scrape()
data_pipeline.close_pipeline()

Python Selenium Beginners Series Part 2: Cleaning Dirty Data & Dealing With Edge Cases
In Part 1 of this Python Selenium 6-Part Beginner Series, we learned the basics of scraping with Python and built our first Python scraper.
Web data can be messy, unstructured, and have many edge cases. So, it's important that your scraper is robust and deals with messy data effectively.
So, in Part 2: Cleaning Dirty Data & Dealing With Edge Cases, we're going to show you how to make your scraper more robust and reliable.
- Strategies to Deal With Edge Cases
- Structure your scraped data with Data Classes
- Process and Store Scraped Data with Data Pipeline
- Testing Our Data Processing
- Next Steps
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Python Selenium 6-Part Beginner Series
-
Part 1: Basic Python Selenium Scraper - We'll go over the basics of scraping with Python, and build our first Python scraper. Part 1
-
Part 2: Cleaning Dirty Data & Dealing With Edge Cases - Web data can be messy, unstructured, and have lots of edge cases. In this tutorial we'll make our scraper robust to these edge cases, using data classes and data cleaning pipelines. This article
-
Part 3: Storing Data in AWS S3, MySQL & Postgres DBs - There are many different ways we can store the data that we scrape from databases, CSV files to JSON format, and S3 buckets. We'll explore several different ways we can store the data and talk about their pros, and cons and in which situations you would use them. Part 3
-
Part 4: Managing Retries & Concurrency - Make our scraper more robust and scalable by handling failed requests and using concurrency. Part 4
-
Part 5: Faking User-Agents & Browser Headers - Make our scraper production ready by using fake user agents & browser headers to make our scrapers look more like real users. (Coming Soon)
-
Part 6: Using Proxies To Avoid Getting Blocked - Explore how to use proxies to bypass anti-bot systems by hiding your real IP address and location. (Coming Soon)
Strategies to Deal With Edge Cases
Web data is often messy and incomplete which makes web scraping a bit more complicated for us. For example, when scraping e-commerce sites, most products follow a specific data structure. However, sometimes, things are displayed differently:
- Some items have both a regular price and a sale price.
- Prices might include sales taxes or VAT in some cases but not others.
- If a product is sold out, its price might be missing.
- Product descriptions can vary, with some in paragraphs and others in bullet points.
Dealing with these edge cases is part of the web scraping process, so we need to come up with a way to deal with it.
In the case of the chocolate.co.uk website that we’re scraping for this series, if we inspect the data we can see a couple of issues.
Here's a snapshot of the CSV file that will be created when you scrape and store data using Part 1 of this series:

In the price section, you'll notice that some values are solely numerical (e.g. 9.95), while others combine text and numbers, such as "Sale priceFrom £2.00". This shows that the data is not properly cleaned, as the “Sale priceFrom £2.00” should be represented as 2.00.
There might be some other couple of issues such as:
- Some prices are missing, either because the item is out of stock or the price wasn't listed.
- The prices are currently shown in British Pounds (GBP), but we need them in US Dollars (USD).
- Product URLs are relative and would be preferable as absolute URLs for easier tracking and accessibility.
- Some products are listed multiple times.
There are several options to deal with situations like this:
| Options | Description |
|---|---|
| Try/Except | You can wrap parts of your parsers in Try/Except blocks so if there is an error scraping a particular field, it will then revert to a different parser. |
| Conditional Parsing | You can have your scraper check the HTML response for particular DOM elements and use specific parsers depending on the situation. |
| Data Classes | With data classes, you can define structured data containers that lead to clearer code, reduced boilerplate, and easier manipulation. |
| Data Pipelines | With Data Pipelines, you can design a series of post-processing steps to clean, manipulate, and validate your data before storing it. |
| Clean During Data Analysis | You can parse data for every relevant field, and then later in your data analysis pipeline clean the data. |
Every strategy has its pros and cons, so it's best to familiarize yourself with all methods thoroughly. This way, you can easily choose the best option for your specific situation when you need it.
In this project, we're going to focus on using Data Classes and Data Pipelines as they are the most powerful options available in BS4 to structure and process data.
Structure your scraped data with Data Classes
In Part 1, we scraped data (name, price, and URL) and stored it directly in a dictionary without proper structuring. However, in this part, we'll use data classes to define a structured class called Product and directly pass the scraped data into its instances.
Data classes in Python offer a convenient way of structuring and managing data effectively. They automatically handle the creation of common methods like __init__, __repr__, __eq__, and __hash__, eliminating the need for repetitive boilerplate code.
Additionally, data classes can be easily converted into various formats like JSON, CSV, and others for storage and transmission.
The following code snippet directly passes scraped data to the product data class to ensure proper structuring and management.
Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
To use this data class within your code, you must first import it. We'll import the following methods, as they'll be used later in the code: dataclass, field, fields, InitVar, and asdict.
- The
@dataclassdecorator is used to create data classes in Python. - The
field()function allows you to explicitly control how fields are defined. For example, you can: Set default values for fields and specify whether a field should be included in the automatically generated__init__method. - The
fields()function returns a tuple of objects that describe the class's fields. - The
InitVaris used to create fields that are only used during object initialization and are not included in the final data class instance. - The
asdict()method converts a data class instance into a dictionary, with field names as keys and field values as the corresponding values.
from dataclasses import dataclass, field, fields, InitVar, asdict
Let's examine the Product data class. We passed three arguments to it but we defined five arguments within the class.
- name: Defined with a default value of an empty string.
- price_string: This is defined as an
InitVar, meaning it will be used for initialization but not stored as a field. We'll useprice_stringto calculateprice_gbandprice_usd. - price_gb and price_usd: These are defined as
field(init=false), showing that they will not be included in the default constructor generated by the data class. This means they won't be part of the initialization process, but we can utilize them later. - url: This is initialized as an empty string.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
pass
def clean_price(self, price_string):
pass
def convert_price_to_usd(self):
pass
def create_absolute_url(self):
pass
The __post_init__ method allows for additional processing after initializing the object. Here we’re using it to clean and process the input data during initialization to derive attributes such as name, price_gb, price_usd, and url.
Using Data Classes we’re going to do the following:
clean_priceClean thepriceto remove the substrings like "Sale price£" and "Sale priceFrom £”.convert_price_to_usdConvert thepricefrom British Pounds to US Dollars.clean_nameClean the name by stripping leading and trailing whitespaces.create_absolute_urlConvert relative URL to absolute URL.
Clean the Price
Cleans up price strings by removing specific substrings like "Sale price£" and "Sale priceFrom £", then converting the cleaned string to a float. If a price string is empty, the price is set to 0.0.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price£", "")
price_string = price_string.replace("Sale priceFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
Convert the Price
The prices scraped from the website are in the GBP, convert GBP to USD by multiplying the scraped price by the exchange rate (1.21 in our case).
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
"""
Previous code
"""
def convert_price_to_usd(self):
return self.price_gb * 1.21
Clean the Name
Cleans up product names by stripping leading and trailing whitespaces. If a name is empty, it's set to "missing".
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
"""
Previous code
"""
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
Convert Relative to Absolute URL
Creates absolute URLs for products by appending their URLs to the base URL.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
"""
Previous code
"""
def create_absolute_url(self):
if self.url == "":
return "missing"
return "https://www.chocolate.co.uk" + self.url
This is how data classes are helping us to easily structure and manage our messy scraped data. They are properly checking edge cases and replacing unnecessary text. This cleaned data will then be returned to the data pipeline for further processing.
Here’s the snapshot of the data that will be returned from the product data class. It consists of name, price_gb, price_usd, and url.
Here's the complete code for the product data class.
from dataclasses import dataclass, field, fields, InitVar, asdict
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price£", "")
price_string = price_string.replace("Sale priceFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == "":
return "missing"
return "https://www.chocolate.co.uk" + self.url
Let's test our Product data class:
p = Product(
name='Lovely Chocolate',
price_string='Sale priceFrom £1.50',
url='/products/100-dark-hot-chocolate-flakes'
)
print(p)
Output:
Product(name='Lovely Chocolate', price_gb=1.5, price_usd=1.815, url='https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes')
Process and Store Scraped Data with Data Pipeline
Now that we’ve our clean data, we'll use Data Pipelines to process this data before saving it. The data pipeline will help us to pass the data from various pipelines for processing and finally store it in a csv file.
Using Data Pipelines we’re going to do the following:
- Check if an Item is a duplicate and drop it if it's a duplicate.
- Add the process data to the storage queue.
- Save the processed data periodically to the CSV file.
Let's first examine the ProductDataPipeline class and its __init__ constructor.
import os
import time
import csv
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
pass
def clean_raw_product(self, scraped_data):
pass
def is_duplicate(self, product_data):
pass
def add_product(self, scraped_data):
pass
def close_pipeline(self):
pass
Here we define six methods in this ProductDataPipeline class:
__init__: Initializes the product data pipeline with parameters like CSV filename and storage queue limit.save_to_csv: Periodically saves the products stored in the pipeline to a CSV file.clean_raw_product: Cleans scraped data and returns aProductobject.is_duplicate: Checks if a product is a duplicate based on its name.add_product: Adds a product to the pipeline after cleaning and checks for duplicates before storing, and triggers saving to CSV if necessary.
Within the __init__ constructor, five variables are defined, each serving a distinct purpose:
name_seen: This list is used for checking duplicates.storage_queue: This queue holds products temporarily until a specified storage limit is reached.storage_queue_limit: This variable defines the maximum number of products that can reside in thestorage_queue.csv_filename: This variable stores the name of the CSV file used for product data storage.csv_file_open: This boolean variable tracks whether the CSV file is currently open or closed.
Add the Product
To add product details, we first clean them with the clean_raw_product function. This sends the scraped data to the Product class, which cleans and organizes it and then returns a Product object holding all the relevant data. We then double-check for duplicates with the is_duplicate method. If it's new, we add it to a storage queue.
This queue acts like a temporary holding bin, but once it reaches its limit (five items in this case) and no CSV file is open, we'll call the save_to_csv function. This saves the first five items from the queue to a CSV file, emptying the queue in the process.
import os
import time
import csv
class ProductDataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if (
len(self.storage_queue) >= self.storage_queue_limit
and self.csv_file_open == False
):
self.save_to_csv()
Check for Duplicate Product
This method checks for duplicate product names. If a product with the same name has already been encountered, it prints a message and returns True to indicate a duplicate. If the name is not found in the list of seen names, it adds the name to the list and returns False to indicate a unique product.
import os
import time
import csv
class ProductDataPipeline:
"""
Previous code
"""
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
Periodically Save Data to CSV
Now, when the storage_queue_limit reaches 5 (its maximum), the save_to_csv() function is called. The csv_file_open variable is set to True to indicate that CSV file operations are underway. All data is extracted from the queue, appended to the products_to_save list, and the queue is then cleared for subsequent data storage.
The fields method is used to extract the necessary keys. As previously mentioned, fields return a tuple of objects that represent the fields associated with the class. Here, we've 4 fields (name, price_gb, price_usd, and url) that will used as keys.
A check is performed to determine whether the CSV file already exists. If it does not, the keys are written as headers using the writeheader() function. Otherwise, if the file does exist, the headers are not written again, and only the data is appended using the csv.DictWriter.
A loop iterates through the products_to_save list, writing each product's data to the CSV file. The asDict method is responsible for converting each Product object into a dictionary where all the values are used as the row data. Once all data has been written, the csv_file_open variable is set to False to indicate that CSV file operations have concluded.
import os
import time
import csv
class ProductDataPipeline:
"""
Previous code
"""
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
)
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
Wait, you may have noticed that we're storing data in a CSV file periodically instead of waiting for the entire scraping script to finish.
We've implemented a queue-based approach to manage data efficiently and save it to the CSV file at appropriate intervals. Once the queue reaches its limit, the data is written to the CSV file.
This way, if the script encounters errors, crashes, or experiences interruptions, only the most recent batch of data is lost, not the entire dataset. This ultimately improves overall processing speed.
Full Data Pipeline Code
Here's the complete code for the ProductDataPipeline class.
import os
import time
import csv
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode='a', newline='', encoding='utf-8') as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get('name', ''),
price_string=scraped_data.get('price', ''),
url=scraped_data.get('url', '')
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
Let's test our ProductDataPipeline class:
## Initialize The Data Pipeline
data_pipeline = ProductDataPipeline(csv_filename='product_data.csv')
## Add To Data Pipeline
data_pipeline.add_product({
'name': 'Lovely Chocolate',
'price': 'Sale priceFrom £1.50',
'url': '/products/100-dark-hot-chocolate-flakes'
})
## Add To Data Pipeline
data_pipeline.add_product({
'name': 'My Nice Chocolate',
'price': 'Sale priceFrom £4',
'url': '/products/nice-chocolate-flakes'
})
## Add To Duplicate Data Pipeline
data_pipeline.add_product({
'name': 'Lovely Chocolate',
'price': 'Sale priceFrom £1.50',
'url': '/products/100-dark-hot-chocolate-flakes'
})
## Close Pipeline When Finished - Saves Data To CSV
data_pipeline.close_pipeline()
Here we:
- Initialize The Data Pipeline: Creates an instance of
ProductDataPipelinewith a specified CSV filename. - Add To Data Pipeline: Adds three products to the data pipeline, each with a name, price, and URL. Two products are unique and one is a duplicate product.
- Close Pipeline When Finished - Saves Data To CSV: Closes the pipeline, ensuring all pending data is saved to the CSV file.
CSV file output:
name,price_gb,price_usd,url
Lovely Chocolate,1.5,1.815,https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes
My Nice Chocolate,4.0,4.84,https://www.chocolate.co.uk/products/nice-chocolate-flakes
Testing Our Data Processing
When we run our code, we should see all the chocolates, being crawled with the price now displaying in both GBP and USD. The relative URL is converted to an absolute URL after our Data Class has cleaned the data. The data pipeline has dropped any duplicates and saved the data to the CSV file.
Here’s the snapshot of the completely cleaned and structured data:
Here is the full code with the Product Dataclass and the Data Pipeline integrated:
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from dataclasses import dataclass, field, fields, InitVar, asdict
import csv
import time
import os
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price\n£", "")
price_string = price_string.replace("Sale price\nFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == "":
return "missing"
return self.url
class ProductDataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(
self.csv_filename) > 0
)
with open(
self.csv_filename, mode="a", newline="", encoding="utf-8"
) as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if (
len(self.storage_queue) >= self.storage_queue_limit
and self.csv_file_open == False
):
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
list_of_urls = [
"https://www.chocolate.co.uk/collections/all",
]
def start_scrape():
print("Scraping started...")
for url in list_of_urls:
driver.get(url)
products = driver.find_elements(By.CLASS_NAME, "product-item")
for product in products:
name = product.find_element(
By.CLASS_NAME, "product-item-meta__title").text
price = product.find_element(
By.CLASS_NAME, "price").text
url = product.find_element(
By.CLASS_NAME, "product-item-meta__title"
).get_attribute("href")
data_pipeline.add_product(
{"name": name, "price": price, "url": url})
try:
next_page = driver.find_element(By.CSS_SELECTOR, "a[rel='next']")
if next_page:
list_of_urls.append(next_page.get_attribute("href"))
print("Scraped page", len(list_of_urls), "...") # Show progress
time.sleep(1) # Add a brief pause between page loads
except:
print("No more pages found!")
if __name__ == "__main__":
options = Options()
options.add_argument("--headless") # Enables headless mode
# Using ChromedriverManager to automatically download and install Chromedriver
driver = webdriver.Chrome(
options=options, service=Service(ChromeDriverManager().install())
)
data_pipeline = ProductDataPipeline(csv_filename="product_data.csv")
start_scrape()
data_pipeline.close_pipeline()
print("Scraping completed successfully!")
driver.quit() # Close the browser window after finishing

Node.js Axios/CheerioJS Beginners Series Part 2: Cleaning Dirty Data & Dealing With Edge Cases
In Part 1 of this Node.js Axios/CheerioJS Beginners Series, we learned the basics of scraping with Node.js and built our first Node.js scraper.
Web data can be messy, unstructured, and have many edge cases. So, it's important that your scraper is robust and deals with messy data effectively.
So, in Part 2: Cleaning Dirty Data & Dealing With Edge Cases, we're going to show you how to make your scraper more robust and reliable.
- Strategies to Deal With Edge Cases
- Structure your scraped data with Data Classes
- Process and Store Scraped Data with Data Pipeline
- Testing Our Data Processing
- Next Steps
Node.js Axios/CheerioJS 6-Part Beginner Series
This 6-part Node.js Axios/CheerioJS Beginner Series will walk you through building a web scraping project from scratch, covering everything from creating the scraper to deployment and scheduling.
- Part 1: Basic Node.js Cheerio Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
- Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. This article
- Part 3: Storing Scraped Data - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
- Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
- Part 5: Mimicking User Behavior - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
- Part 6: Avoiding Detection with Proxies - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
The code for this project is available on Github.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Strategies to Deal With Edge Cases
Web data is often messy and incomplete which makes web scraping a bit more complicated for us. For example, when scraping e-commerce sites, most products follow a specific data structure. However, sometimes, things are displayed differently:
- Some items have both a regular price and a sale price.
- Prices might include sales taxes or VAT in some cases but not others.
- If a product is sold out, its price might be missing.
- Product descriptions can vary, with some in paragraphs and others in bullet points.
Dealing with these edge cases is part of the web scraping process, so we need to come up with a way to deal with it.
In the case of the chocolate.co.uk website that we’re scraping for this series, if we inspect the data we can see a couple of issues.
Here's a snapshot of the CSV file that will be created when you scrape and store data using Part 1 of this series.
In the price section, you'll notice that some values are solely numerical (e.g. 9.95), while others combine text and numbers, such as "Sale priceFrom £2.00". This shows that the data is not properly cleaned, as the “Sale priceFrom £2.00” should be represented as 2.00.

There might be some other couple of issues such as:
- Some prices are missing, either because the item is out of stock or the price wasn't listed.
- The prices are currently shown in British Pounds (GBP), but we need them in US Dollars (USD).
- Product URLs are relative and would be preferable as absolute URLs for easier tracking and accessibility.
- Some products are listed multiple times.
There are several options to deal with situations like this:
| Options | Description |
|---|---|
| Try/Catch | You can wrap parts of your parsers in Try/Except blocks so if there is an error scraping a particular field, it will then revert to a different parser. |
| Conditional Parsing | You can have your scraper check the HTML response for particular DOM elements and use specific parsers depending on the situation. |
| Data Classes | With data classes, you can define structured data containers that lead to clearer code, reduced boilerplate, and easier manipulation. |
| Data Pipelines | With Data Pipelines, you can design a series of post-processing steps to clean, manipulate, and validate your data before storing it. |
| Clean During Data Analysis | You can parse data for every relevant field, and then later in your data analysis pipeline clean the data. |
Every strategy has its pros and cons, so it's best to familiarize yourself with all methods thoroughly. This way, you can easily choose the best option for your specific situation when you need it.
In this project, we're going to focus on using Data Classes and Data Pipelines as they are the most powerful options available in BS4 to structure and process data.
Structure your scraped data with Data Classes
In Part 1, we scraped data (name, price, and URL) and stored it directly in a dictionary without proper structuring. However, in this part, we'll use data classes to define a structured class called Product and directly pass the scraped data into its instances.
Data classes in Node.js offer a convenient way to structure and manage the scraped data effectively. It allows you to build and extend methods to more easily work with the data.
Additionally, data classes can be easily converted into various formats like JSON, CSV, and others for storage and transmission.
The following code snippet directly passes scraped data to the product data class to ensure proper structuring and management.
new Product(rawProduct.name, rawProduct.price, rawProduct.url);
Let's examine the Product data class. We pass three arguments to the constructor but we define four fields in the class.
- name: The name of the product
- priceGb and priceUsd: The integer value derived from the price string.
- url: The url of the product
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {}
cleanPrice(priceStr) {}
convertPriceToUsd(priceGb) {}
createAbsoluteUrl(url) {}
}
You'll notice in the constructor, we call a variety of methods to clean the data before setting the field values.
Using this Data Class we are going to do the following:
cleanName: Clean the name by stripping leading and trailing whitespaces.cleanPrice: Clean the price to remove the substrings like "Sale price£" and "Sale priceFrom £”.convertPriceToUsd: Convert the price from British Pounds to US Dollars.createAbsoluteUrl: Convert relative URL to absolute URL.
Clean the Price
Cleans up price strings by removing specific substrings like "Sale price£" and "Sale priceFrom £", then converting the cleaned string to a float. If a price string is empty, the price is set to 0.0.
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
}
Convert the Price
The prices scraped from the website are in the GBP, convert GBP to USD by multiplying the scraped price by the exchange rate (1.21 in our case).
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
// Previous code...
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
}
Clean the Name
Cleans up product names by stripping leading and trailing whitespace. If a name is empty, it's set to "missing".
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
// Previous code...
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
}
Convert Relative to Absolute URL
Creates absolute URLs for products by appending their URLs to the base URL.
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
// Previous code...
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
Here's the complete code for the product data class.
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
Now, let's test our Product data class:
const p = new Product(
"Lovely Chocolate",
"Sale priceFrom £1.50",
"/products/100-dark-hot-chocolate-flake"
);
console.log(p);
Outputs:
Product {
name: 'Lovely Chocolate',
priceGb: 1.5,
priceUsd: 1.935,
url: 'https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flake'
}
This is how data classes are helping us to easily structure and manage our messy scraped data. They are properly checking edge cases and replacing unnecessary text. This cleaned data will then be returned to the data pipeline for further processing.
Here’s the snapshot of what the data that will be returned from the product data class looks like. It consists of name, priceGb, priceUsd, and url

Process and Store Scraped Data with Data Pipeline
Now that we’ve our clean data, we'll use Data Pipelines to process this data before saving it. The data pipeline will help us to pass the data from various pipelines for processing and finally store it in a csv file.
Using Data Pipelines we’re going to do the following:
- Check if an Item is a duplicate and drop it if it's a duplicate.
- Add the process data to the storage queue.
- Save the processed data periodically to the CSV file.
Let's first examine the ProductDataPipeline class and its constructor.
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
this.csvFileOpen = false;
}
saveToCsv() {}
cleanRawProduct(rawProduct) {}
isDuplicateProduct(product) {}
addProduct(rawProduct) {}
async close() {}
}
Here we define six methods in this ProductDataPipeline class:
constructor: Initializes the product data pipeline with parameters like CSV filename and storage queue limit.saveToCsv: Periodically saves the products stored in the pipeline to a CSV file.cleanRawProduct: Cleans scraped data and returns a Product object.isDuplicate: Checks if a product is a duplicate based on its name.addProduct: Adds a product to the pipeline after cleaning and checks for duplicates before storing, and triggers saving to CSV if necessary.close: Makes sure any queued data is written and closes the data pipeline.
Within the constructor, five variables are defined, each serving a distinct purpose:
seenProducts: This set is used for checking duplicates.storageQueue: This queue holds products temporarily until a specified storage limit is reached.storageQueueLimit: This variable defines the maximum number of products that can reside in thestorageQueue.csvFilename: This variable stores the name of the CSV file used for product data storage.csvFileOpen: This boolean variable tracks whether the CSV file is currently open or closed.
Add the Product
To add product details, we first clean them with the cleanRawProduct function. This sends the scraped data to the Product class, which cleans and organizes it and then returns a Product object holding all the relevant data. We then double-check for duplicates with the isDuplicate method. If it's new, we add it to a storage queue.
This queue acts like a temporary holding bin, but once it reaches its limit (five items in this case) and no CSV file is open, we'll call the saveToCsv function. This saves the first five items from the queue to a CSV file, emptying the queue in the process.
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
Check for Duplicate Product
This method checks for duplicate product names. If a product with the same name has already been encountered, it prints a message and returns true to indicate a duplicate. If the name is not found in the list of seen names, it adds the name to the list and returns false to indicate a unique product.
class ProductDataPipeline {
// Previous code...
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
}
Periodically Save Data to CSV
Now, when the storageQueueLimit reaches 5 (its maximum), the saveToCsv() function is called. The csvFileOpen variable is set to true to indicate that CSV file operations are underway. All data is extracted from the queue, appended to the storageQueue list, and the queue is then cleared for subsequent data storage.
A check is performed to determine whether the CSV file already exists. If it does not, the keys are written as headers first. Otherwise, if the file does exist, the headers are not written again, and only the data is appended using the file.write.
Then, a loop iterates through the storageQueue list, writing each product's data to the CSV file. We use template literals. Once all data has been written, the csvFileOpen variable is set to false to indicate that CSV file operations have concluded.
class ProductDataPipeline {
// Previous code...
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
}
Wait, you may have noticed that we're storing data in a CSV file periodically instead of waiting for the entire scraping script to finish.
We've implemented a queue-based approach to manage data efficiently and save it to the CSV file at appropriate intervals. Once the queue reaches its limit, the data is written to the CSV file.
This way, if the script encounters errors, crashes, or experiences interruptions, only the most recent batch of data is lost, not the entire dataset. This ultimately improves overall processing speed.
Full Data Pipeline Code
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
Let's test our ProductDataPipeline class:
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
// Add to data pipeline
pipeline.addProduct({
name: "Lovely Chocolate",
price: "Sale priceFrom £1.50",
url: "/products/100-dark-hot-chocolate-flakes",
});
// Add to data pipeline
pipeline.addProduct({
name: "My Nice Chocolate",
price: "Sale priceFrom £4",
url: "/products/nice-chocolate-flakes",
});
// Add to duplicate data pipeline
pipeline.addProduct({
name: "Lovely Chocolate",
price: "Sale priceFrom £1.50",
url: "/products/100-dark-hot-chocolate-flakes",
});
// Close pipeline when finished - saves data to CSV
pipeline.close();
Here we:
- Initialize The Data Pipeline: Creates an instance of ProductDataPipeline with a specified CSV filename.
- Add To Data Pipeline: Adds three products to the data pipeline, each with a name, price, and URL. Two products are unique and one is a duplicate product.
- Close Pipeline When Finished - Saves Data To CSV: Closes the pipeline, ensuring all pending data is saved to the CSV file.
CSV file output:
name,priceGb,priceUsd,url
Lovely Chocolate,1.5,1.935,https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes
My Nice Chocolate,4,5.16,https://www.chocolate.co.uk/products/nice-chocolate-flakes
Testing Our Data Processing
When we run our code, we should see all the chocolates, being crawled with the price now displaying in both GBP and USD. The relative URL is converted to an absolute URL after our Data Class has cleaned the data. The data pipeline has dropped any duplicates and saved the data to the CSV file.
Here’s the snapshot of the completely cleaned and structured data:
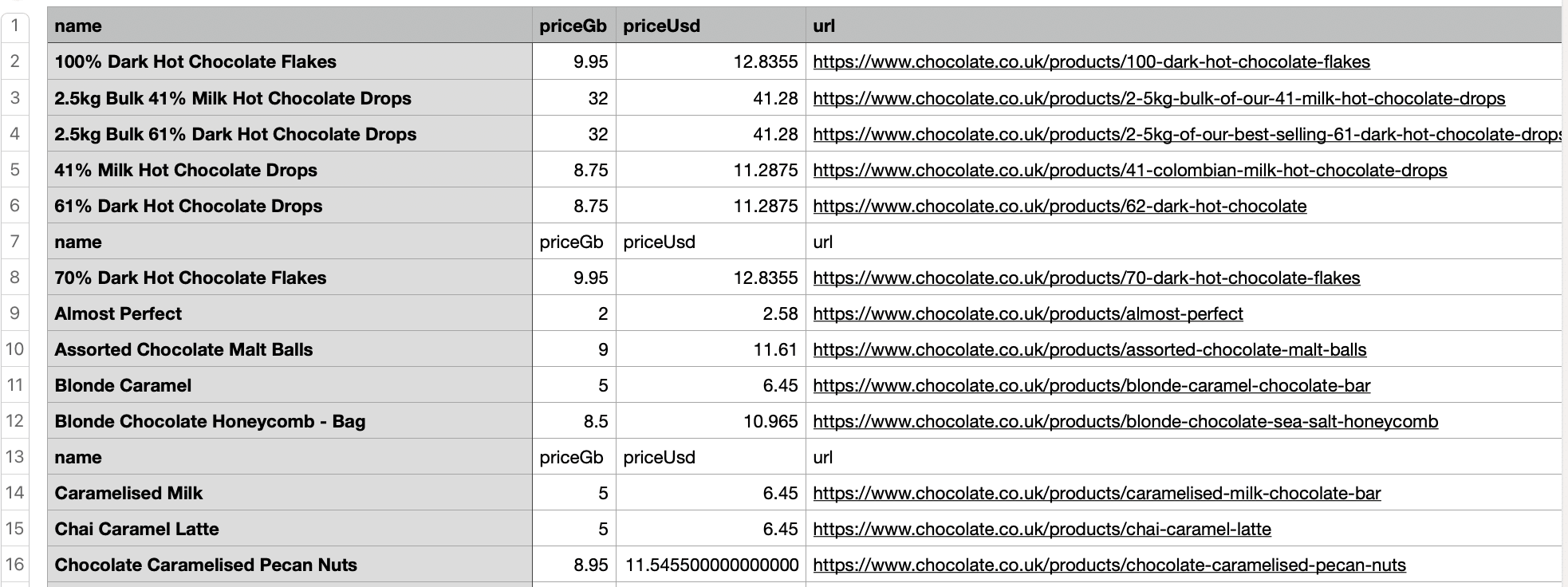
Here is the full code with the Product Dataclass and the Data Pipeline integrated:
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function scrape() {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
for (const url of listOfUrls) {
const response = await axios.get(url);
if (response.status == 200) {
const html = response.data;
const $ = cheerio.load(html);
const productItems = $("product-item");
for (const productItem of productItems) {
const title = $(productItem).find(".product-item-meta__title").text();
const price = $(productItem).find(".price").first().text();
const url = $(productItem)
.find(".product-item-meta__title")
.attr("href");
pipeline.addProduct({ name: title, price: price, url: url });
}
const nextPage = $("a[rel='next']").attr("href");
if (nextPage) {
listOfUrls.push("https://www.chocolate.co.uk" + nextPage);
}
}
}
await pipeline.close();
}
(async () => {
await scrape();
})();

NodeJS Puppeteer Beginners Series Part 2: Cleaning Dirty Data & Dealing With Edge Cases
In Part 1 of this Node.js Puppeteer Beginners Series, we learned the basics of scraping with Node.js and built our first Node.js scraper.
In Part-2 of the series, we’ll explore how to structure data using a dedicated Product class and enhance our scraper's flexibility with a ProductDataPipeline for managing tasks like scheduling and data storage.
- Strategies to Deal With Edge Cases
- Structure Your Scraped Data with JavaScript Classes
- Process and Store Scraped Data with Data Pipeline
- Full Code Integration
- Testing Our Data Processing
- Next Steps
Node.js Puppeteer 6-Part Beginner Series
-
Part 1: Basic Node.js Puppeteer Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using NpdeJS Puppeteer. (Part 1)
-
Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. Click here for Part 2
-
Part 3: Storing Scraped Data in AWS S3, MySQL & Postgres DBs - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
-
Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Strategies to Deal With Edge Cases
Web data is often messy and incomplete, which makes web scraping a bit more complicated for us. For example, when scraping e-commerce sites, most products follow a specific data structure. However, sometimes, things are displayed differently:
- Some items have both a regular price and a sale price.
- Prices might include sales taxes or VAT in some cases but not others.
- If a product is sold out, its price might be missing.
- Product descriptions can vary, with some in paragraphs and others in bullet points.
Dealing with these edge cases is part of the web scraping process, so we need to come up with a way to handle them.
In the case of the e-commerce website we're scraping, if we inspect the data, we can see a couple of issues. Here are some examples:
- Some prices are missing, either because the item is out of stock or the price wasn't listed.
- The prices are currently shown in British Pounds (GBP), but we need them in US Dollars (USD).
- Product URLs are relative and would be preferable as absolute URLs for easier tracking and accessibility.
- Some products are listed multiple times.

There are several options to deal with situations like this:
| Options | Description |
|---|---|
| Try/Catch | Wrap parts of your parsers in try/catch blocks so if there's an error scraping a particular field, it can handle it gracefully. |
| Conditional Parsing | Have your scraper check the HTML response for particular DOM elements and use specific parsers depending on the situation. |
| JavaScript Classes | Use classes to define structured data containers, leading to clearer code and easier manipulation. |
| Data Pipelines | Design a series of post-processing steps to clean, manipulate, and validate your data before storing it. |
| Clean During Analysis | Parse data for every relevant field, and then later in your data analysis pipeline, clean the data. |
Each strategy comes with its own advantages and disadvantages, so it's important to understand all the available methods. This way, you can easily choose the best option for your specific situation when you need it.
In this project, we're going to focus on using JavaScript Classes and Data Pipelines as they are the most powerful options available to structure and process data.
Structure Your Scraped Data with JavaScript Classes
In Part 1, we scraped data (name, price, and URL) and stored it directly in an array without proper structuring.
In this part, we'll use JavaScript classes to define a structured class called Product and directly pass the scraped data into its instances.
JavaScript classes offer a convenient way of structuring and managing data effectively. They can handle methods for cleaning and processing data, making your scraping code more modular and maintainable.
Defining the Product Class
The following code snippet directly passes scraped data to the Product class to ensure proper structuring and management. This class accepts three parameters:
name:the product's name.priceString:a string representing the product's price in GBP (e.g., "£10.99").url:a relative URL for the product.
Using Data Classes we’re going to do the following:
- cleanName(name): Cleans up product names by stripping leading and trailing whitespaces. If a name is empty, it's set to "missing".
- cleanPrice(priceString): Cleans up price strings by removing anything that's not a numeric character, then converting the cleaned string to a float. If a price string is empty, the price is set to 0.0.
- convertPriceToUSD(): Converts the price from British Pounds to US Dollars using a fixed exchange rate (1.21 in our case).
- createAbsoluteURL(relativeURL): Creates absolute URLs for products by appending their relative URLs to the base URL.
Clean the Name
- This method removes any extra spaces from the name and returns it.
- If the name is empty or just spaces, it defaults to "missing".
class Product {
constructor(name, priceString, url) {
this.name = this.cleanName(name);
this.priceGBP = this.cleanPrice(priceString);
this.priceUSD = this.convertPriceToUSD();
this.url = this.createAbsoluteURL(url);
}
cleanName(name) {
return name.trim() || "missing";
}
}
Clean the Price
- This method removes any non-numeric characters (except for periods) from the price string, leaving only the numeric part.
- It then converts this cleaned string into a floating-point number using
parseFloat(). - If the price string is empty or invalid, it defaults to 0.0.
class Product {
constructor(name, priceString, url) {
this.name = this.cleanName(name);
this.priceGBP = this.cleanPrice(priceString);
this.priceUSD = this.convertPriceToUSD();
this.url = this.createAbsoluteURL(url);
}
cleanName(name) {
return name.trim() || "missing";
}
cleanPrice(priceString) {
if (!priceString) return 0.0;
priceString = priceString.replace(/[^0-9\.]+/g, '');
return parseFloat(priceString) || 0.0;
}
}
Convert the Price
- This method converts the price in GBP to USD using a fixed exchange rate of 1.21.
- It multiplies
this.priceGBPby 1.21 and returns the price in USD.
class Product {
constructor(name, priceString, url) {
this.name = this.cleanName(name);
this.priceGBP = this.cleanPrice(priceString);
this.priceUSD = this.convertPriceToUSD();
this.url = this.createAbsoluteURL(url);
}
cleanName(name) {
return name.trim() || "missing";
}
cleanPrice(priceString) {
if (!priceString) return 0.0;
priceString = priceString.replace(/[^0-9\.]+/g, '');
return parseFloat(priceString) || 0.0;
}
convertPriceToUSD() {
const exchangeRate = 1.21;
return this.priceGBP * exchangeRate;
}
}
Convert Relative to Absolute URL
- This method creates an absolute URL by appending the relative URL to the base URL https://www.chocolate.co.uk
- If no relative URL is provided, it defaults to "missing".
class Product {
constructor(name, priceString, url) {
this.name = this.cleanName(name);
this.priceGBP = this.cleanPrice(priceString);
this.priceUSD = this.convertPriceToUSD();
this.url = this.createAbsoluteURL(url);
}
cleanName(name) {
return name.trim() || "missing";
}
cleanPrice(priceString) {
if (!priceString) return 0.0;
priceString = priceString.replace(/[^0-9\.]+/g, '');
return parseFloat(priceString) || 0.0;
}
convertPriceToUSD() {
const exchangeRate = 1.21;
return this.priceGBP * exchangeRate;
}
createAbsoluteURL(relativeURL) {
const baseURL = "https://www.chocolate.co.uk";
return relativeURL ? `${baseURL}${relativeURL}` : "missing";
}
}
Data classes are helping us effectively structure and manage the messy data we've scraped. They handle edge cases, removing irrelevant text and cleaning up the information. The cleaned data is then sent back into the data pipeline for further processing.
Here’s a snapshot of the data returned by the product data class, which includes the name, price_gb, price_usd, and url.
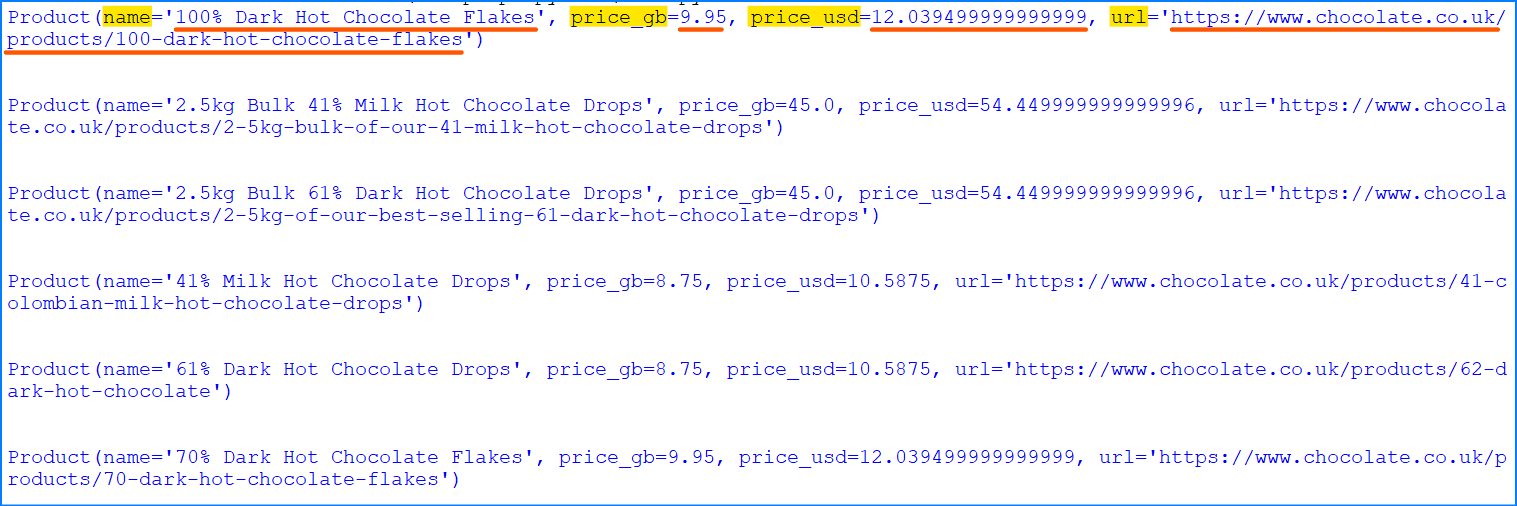
Here's the complete code for the product data class.
class Product {
constructor(name, priceString, url) {
this.name = this.cleanName(name);
this.priceGBP = this.cleanPrice(priceString);
this.priceUSD = this.convertPriceToUSD();
this.url = this.createAbsoluteURL(url);
}
cleanName(name) {
return name.trim() || "missing";
}
cleanPrice(priceString) {
if (!priceString) return 0.0;
priceString = priceString.replace(/[^0-9\.]+/g, '');
return parseFloat(priceString) || 0.0;
}
convertPriceToUSD() {
const exchangeRate = 1.21;
return this.priceGBP * exchangeRate;
}
createAbsoluteURL(relativeURL) {
const baseURL = "https://www.chocolate.co.uk";
return relativeURL ? `${baseURL}${relativeURL}` : "missing";
}
}
Process and Store Scraped Data with Data Pipeline
Now that we have our clean data, we'll use a data pipeline to process this data before saving it. The pipeline will guide the data through several steps, ultimately storing it in a CSV file.
Using data pipelines, we're going to do the following:
- Identify and remove any duplicate items.
- Add the processed data to the storage queue.
- Periodically save the processed data to the CSV file.
Let's first examine the ProductDataPipeline class and its constructor. Here we define six methods in this ProductDataPipeline class:
saveToCSV: Periodically saves the products stored in the pipeline to a CSV file.cleanRawProduct: Cleans scraped data and returns a Product object.isDuplicate: Checks if a product is a duplicate based on its name.addProduct: Adds a product to the pipeline after cleaning and checks for duplicates before storing, and triggers saving to CSV if necessary.
Within the constructor, five variables are defined, each serving a distinct purpose:
namesSeen: This list is used for checking duplicates.storageQueue: This queue holds products temporarily until a specified storage limit is reached.storageQueueLimit: This variable defines the maximum number of products that can reside in the storageQueue.csvFilename: This variable stores the name of the CSV file used for product data storage.csvFileOpen: This boolean variable tracks whether the CSV file is currently open or closed.
Full Data Pipeline Code
Here's the complete code for the ProductDataPipeline class.
const fs = require('fs');
class ProductDataPipeline {
constructor(csvFilename = '', storageQueueLimit = 5) {
this.namesSeen = [];
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
this.csvFileOpen = false;
}
saveToCSV() {
this.csvFileOpen = true;
const productsToSave = [...this.storageQueue];
this.storageQueue = [];
if (productsToSave.length === 0) return;
const headers = Object.keys(productsToSave[0]);
const fileExists = fs.existsSync(this.csvFilename);
const csvWriter = fs.createWriteStream(this.csvFilename, { flags: 'a' });
if (!fileExists) {
csvWriter.write(headers.join(',') + '\n');
}
productsToSave.forEach(product => {
const row = headers.map(header => product[header]).join(',');
csvWriter.write(row + '\n');
});
csvWriter.end();
this.csvFileOpen = false;
}
cleanRawProduct(scrapedData) {
return new Product(
scrapedData.name || '',
scrapedData.price || '',
scrapedData.url || ''
);
}
isDuplicate(product) {
if (this.namesSeen.includes(product.name)) {
console.log(`Duplicate item found: ${product.name}. Item dropped.`);
return true;
}
this.namesSeen.push(product.name);
return false;
}
addProduct(scrapedData) {
const product = this.cleanRawProduct(scrapedData);
if (!this.isDuplicate(product)) {
this.storageQueue.push(product);
if (this.storageQueue.length >= this.storageQueueLimit && !this.csvFileOpen) {
this.saveToCSV();
}
}
}
closePipeline() {
if (this.csvFileOpen) {
setTimeout(() => this.saveToCSV(), 3000);
} else if (this.storageQueue.length > 0) {
this.saveToCSV();
}
}
}
Let's test our ProductDataPipeline class:
const dataPipeline = new ProductDataPipeline('product_data.csv');
// Add products to the data pipeline
dataPipeline.addProduct({
name: 'Lovely Chocolate',
price: 'Sale priceFrom £1.50',
url: '/products/100-dark-hot-chocolate-flakes'
});
dataPipeline.addProduct({
name: 'My Nice Chocolate',
price: 'Sale priceFrom £4',
url: '/products/nice-chocolate-flakes'
});
dataPipeline.addProduct({
name: 'Lovely Chocolate',
price: 'Sale priceFrom £1.50',
url: '/products/100-dark-hot-chocolate-flakes'
});
// Close the pipeline when finished - saves data to CSV
dataPipeline.closePipeline();
Here we:
- Initialize The Data Pipeline: Creates an instance of
ProductDataPipelinewith a specified CSV filename. - Add To Data Pipeline: Adds three products to the data pipeline, each with a name, price, and URL. Two products are unique and one is a duplicate.
- Close Pipeline When Finished: Closes the pipeline, ensuring all pending data is saved to the CSV file.
The output CSV file will look like this:
name,priceGBP,priceUSD,url
Lovely Chocolate,1.5,1.815,https://www.example.com/products/100-dark-hot-chocolate-flakes
My Nice Chocolate,4.0,4.84,https://www.example.com/products/nice-chocolate-flakes
Testing Our Data Processing
When we run our code, we should see all the chocolates being crawled, with the price now displaying in both GBP and USD. The relative URL is converted to an absolute URL after our Product class has cleaned the data. The data pipeline has dropped any duplicates and saved the data to the CSV file.
Here’s the snapshot of the completely cleaned and structured data:
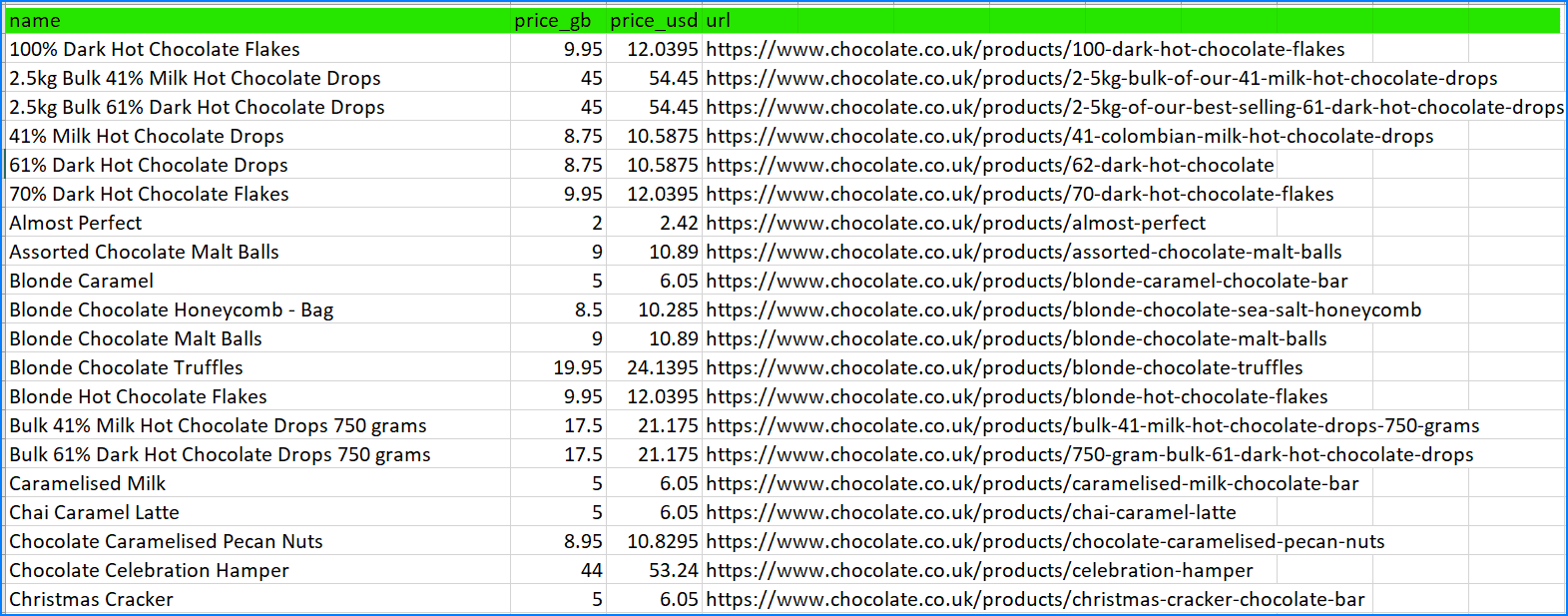
Here is the full code with the Product class and the ProductDataPipeline integrated:
const puppeteer = require('puppeteer');
const fs = require('fs');
class Product {
constructor(name, priceString, url) {
this.name = this.cleanName(name);
this.priceGBP = this.cleanPrice(priceString);
this.priceUSD = this.convertPriceToUSD();
this.url = this.createAbsoluteURL(url);
}
cleanName(name) {
return name.trim() || "missing";
}
cleanPrice(priceString) {
if (!priceString) return 0.0;
priceString = priceString.replace(/[^0-9\.]+/g, '');
return parseFloat(priceString) || 0.0;
}
convertPriceToUSD() {
const exchangeRate = 1.21;
return this.priceGBP * exchangeRate;
}
createAbsoluteURL(relativeURL) {
const baseURL = "https://www.chocolate.co.uk";
return relativeURL ? `${baseURL}${relativeURL}` : "missing";
}
}
class ProductDataPipeline {
constructor(csvFilename = '', storageQueueLimit = 5) {
this.namesSeen = [];
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
this.csvFileOpen = false;
}
saveToCSV() {
this.csvFileOpen = true;
const productsToSave = [...this.storageQueue];
this.storageQueue = [];
if (productsToSave.length === 0) return;
const headers = Object.keys(productsToSave[0]);
const fileExists = fs.existsSync(this.csvFilename);
const csvWriter = fs.createWriteStream(this.csvFilename, { flags: 'a' });
if (!fileExists) {
csvWriter.write(headers.join(',') + '\n');
}
productsToSave.forEach(product => {
const row = headers.map(header => product[header]).join(',');
csvWriter.write(row + '\n');
});
csvWriter.end();
this.csvFileOpen = false;
}
cleanRawProduct(scrapedData) {
return new Product(
scrapedData.name || '',
scrapedData.price || '',
scrapedData.url || ''
);
}
isDuplicate(product) {
if (this.namesSeen.includes(product.name)) {
console.log(`Duplicate item found: ${product.name}. Item dropped.`);
return true;
}
this.namesSeen.push(product.name);
return false;
}
addProduct(scrapedData) {
const product = this.cleanRawProduct(scrapedData);
if (!this.isDuplicate(product)) {
this.storageQueue.push(product);
if (this.storageQueue.length >= this.storageQueueLimit && !this.csvFileOpen) {
this.saveToCSV();
}
}
}
closePipeline() {
if (this.csvFileOpen) {
setTimeout(() => this.saveToCSV(), 3000);
} else if (this.storageQueue.length > 0) {
this.saveToCSV();
}
}
}
const startScrape = async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const baseURL = 'https://www.chocolate.co.uk/collections/all';
const dataPipeline = new ProductDataPipeline('product_data.csv');
let nextPageExists = true;
let currentPage = baseURL;
while (nextPageExists) {
await page.goto(currentPage, { waitUntil: 'networkidle2' });
const products = await page.evaluate(() => {
const items = document.querySelectorAll('.product-item');
return Array.from(items).map(item => ({
name: item.querySelector('.product-item-meta__title').innerText,
price: item.querySelector('.price').innerText,
url: item.querySelector('.product-item-meta a').getAttribute('href')
}));
});
products.forEach(product => dataPipeline.addProduct(product));
nextPageExists = await page.evaluate(() => {
const nextPage = document.querySelector('a[rel="next"]');
return nextPage ? nextPage.href : null;
});
if (nextPageExists) {
currentPage = nextPageExists;
}
}
await browser.close();
dataPipeline.closePipeline();
};
startScrape();

NodeJS Playwright Beginner Series Part 2: Cleaning Dirty Data & Dealing With Edge Cases
In Part 1 of this Node.js Playwright Beginners Series, we learned the basics of scraping with Node.js and built our first Node.js scraper.
Data on the web is often messy or incomplete, which means we need to clean it up and handle missing information to keep our scraper running smoothly.
In Part-2 of our Node.js Playwright Beginner Series, we’ll explore how to structure data using a dedicated Product class and enhance our scraper's flexibility with a ProductDataPipeline for managing tasks like scheduling and data storage.
- Strategies to Deal With Edge Cases:
- Structure your Scraped Data with Data Classes
- Process and Store Scraped Data with Data Pipeline
- Testing Our Data Processing
- Next Steps
Node.js Playwright 6-Part Beginner Series
-
Part 1: Basic Node.js Playwright Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
-
Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. Part 2
-
Part 3: Storing Scraped Data in AWS S3, MySQL & Postgres DBs - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
-
Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Strategies to Deal With Edge Cases
In Part 1 of this series, we used basic trim() and replace() methods to clean data on the fly and returned null when the title or price was missing.
While this worked in the short term, it lacked a solid structure and missed several important factors.
In the case of the chocolate.co.uk website that we’re scraping for this series, if we inspect the data we can see a couple of issues. For example:
- Unclean Price Data: Prices may include extra prefixes like "Sale price" or "Sale priceFrom" that need to be removed.
- Currency Conversion: Prices are provided in British pounds (GBP), but we need them in US dollars (USD).
- Relative URLs: Scraped URLs are relative, so we need to convert them into absolute URLs for direct use.
- Missing Data: The name, price, or URL might be missing, and we need to handle these cases.
Here’s a look at some problematic entries from the CSV file generated in Part-1:

Here are several strategies to handle situations like this:
| Option | Description |
|---|---|
| Try/Except | Wrap parts of your parsers in Try/Except blocks. If an error occurs when scraping a specific field, the scraper will switch to an alternative parser. |
| Conditional Parsing | Set up your scraper to check the HTML response for certain DOM elements, and apply different parsers based on the situation. |
| Data Classes | Use data classes to create structured containers, making your code clearer, reducing repetitive boilerplate, and simplifying data manipulation. |
| Data Pipelines | Implement data pipelines to design a series of post-processing steps that clean, manipulate, and validate your data before storing it. |
| Clean During Data Analysis | Parse all relevant fields first, then clean and process the data during the analysis phase. |
Each method has its own advantages and drawbacks, so it’s important to be familiar with all of them. This allows you to choose the most suitable approach for your specific scenario.
For this project, we’ll focus on Data Classes and Data Pipelines as they offer the most structured and efficient way to process data using Playwright.
Here’s a system diagram that maps out our code structure, including the Product and ProductPipeline classes:
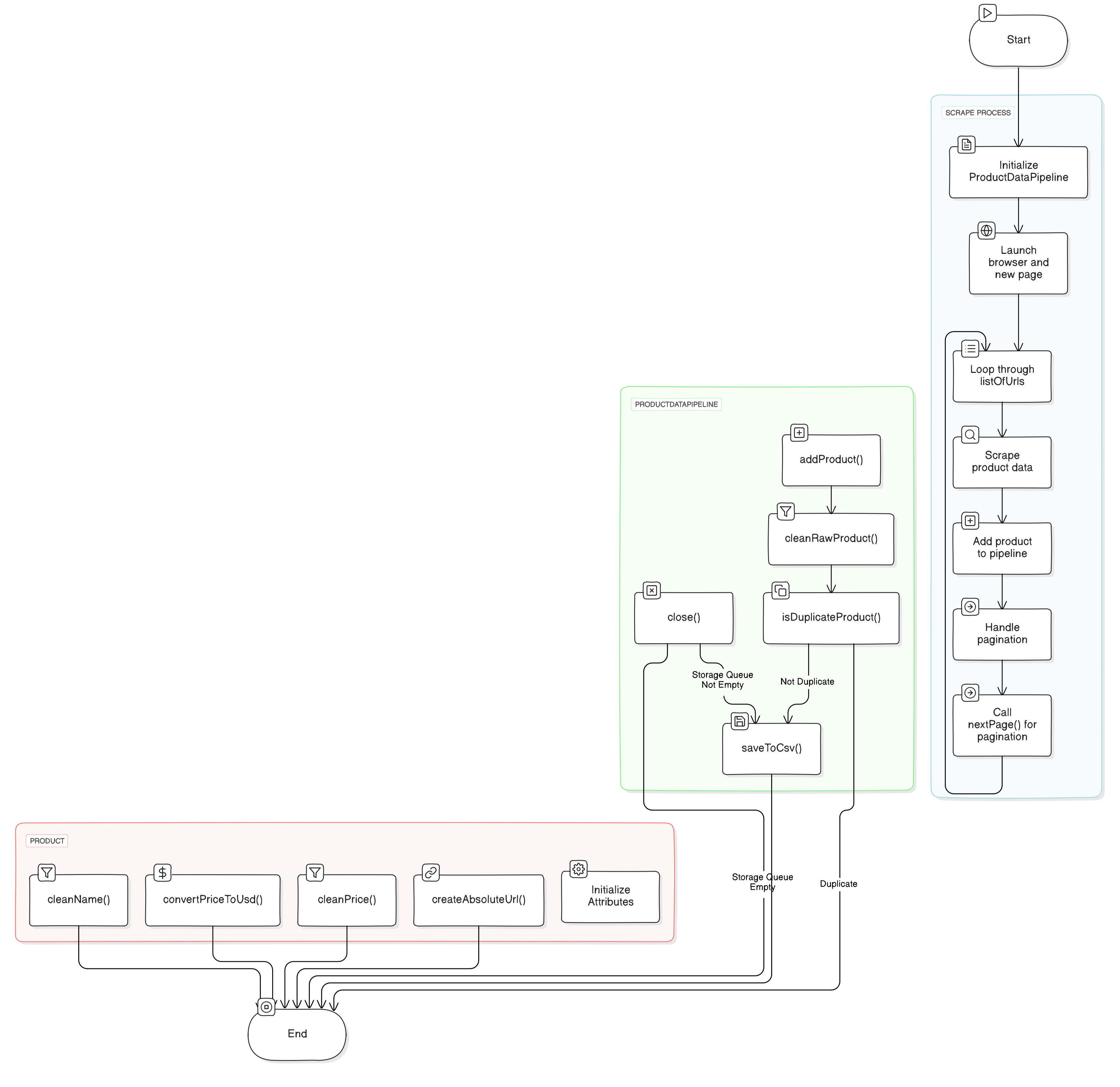
Structure Your Scraped Data with Data Classes
In Part 1, we scraped data (name, price, and URL) and stored it directly in a dictionary without any formal structure.
In this section, however, we'll implement data classes to create a structured Product class. The Product class will help turn raw, unstructured data from the website into a clean and structured object. Instances of this class will contain sanitized data that can be easily converted into formats like CSV, JSON, or others for local storage.
Data classes in Playwright provide an efficient method for structuring and managing data in your web scraping tasks. They help streamline the process by organizing scraped elements into clean, reusable data structures.
This approach eliminates repetitive code, enhances readability, and simplifies the handling of common tasks such as parsing and validation of scraped data.
Here's how a new instance will be created by passing unclean raw data to the Product class:
new Product(rawProduct.name, rawProduct.price, rawProduct.url);
While we're passing three parameters, the resulting instance will have four key properties:
- name: The product name, cleaned of any unwanted characters
- priceGb: The price in British pounds (GBP)
- priceUsd: The price converted to US dollars (USD)
- url: The absolute URL that you can navigate to directly
Here's a look at the Product class structure:
class Product {
constructor(name, priceStr, url, conversionRate = 1.32) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb, conversionRate);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {}
cleanPrice(priceStr) {}
convertPriceToUsd(priceGb, conversionRate) {}
createAbsoluteUrl(url) {}
}
We’re introducing a fourth parameter to the Product class: conversionRate, which defaults to 1.32, the current exchange rate. You can update this value as needed or use an API like ExchangeRate-API for dynamic rate updates.
Since it’s a default parameter, you don’t need to specify it when creating an instance of the Product class unless you want to override the default rate.
You'll notice the use of several methods that we'll define in the upcoming sections. Each method is responsible for handling specific tasks, leading to a cleaner, more modular codebase.
Here's a quick overview of what each method does:
- cleanName(): Cleans up the product name.
- cleanPrice(): Strips unwanted characters from the price string.
- convertPriceToUsd(): Converts the GBP price to USD.
- createAbsoluteUrl(): Converts relative URLs to absolute ones.
Clean the Price
The cleanPrice() method performs several checks to ensure the price data is valid and clean:
- If the price data is missing or contains only empty spaces, it returns 0.0.
- If the price exists, it removes unnecessary prefixes and trims any extra spaces. (Eg. "Sale price£" and "Sale priceFrom £")
- Finally, it attempts to convert the cleaned price string to a floating-point number. If the conversion fails, it returns 0.0.
Here’s the method:
cleanPrice(priceStr) {
if (!priceStr?.trim()) {
return 0.0;
}
const cleanedPrice = priceStr
.replace(/Sale priceFrom £|Sale price£/g, "")
.trim();
return cleanedPrice ? parseFloat(cleanedPrice) : 0.0;
}
In the script above:
-
We used optional chaining (?.) in
!priceStr?.trim(), which ensures thattrim()is only called ifpriceStrexists. This feature is available in Node.js to prevent errors when accessing properties ofnullorundefined. -
The
replace(/Sale priceFrom £|Sale price£/g, "")uses regular expressions to detect and remove the unwanted prefixes ("Sale priceFrom £" and "Sale price£") from the price string. -
The parseFloat() method is used because the price value extracted from the web is a string, so it needs to be converted into a floating-point number for numeric calculations.
-
The conditional return
cleanedPrice ? parseFloat(cleanedPrice) : 0.0ensures that if the cleaned price string is empty or non-numeric, the method returns 0.0 instead of attempting an invalid conversion.
The optional chaining (?.) operator accesses an object's property or calls a function. If the object accessed or function called using this operator is undefined or null, the expression short circuits and evaluates to undefined instead of throwing an error - (Source: MDN)
Convert the Price
The convertPriceToUsd() method takes the price in GBP and converts it to USD using the current exchange rate (1.32 in our case).
Here's how:
convertPriceToUsd(priceGb, conversionRate) {
return priceGb * conversionRate;
}
Clean the Name
The cleanName() method performs the following checks:
- If the name is missing or contains only spaces, it returns "missing".
- Otherwise, it returns the trimmed and cleaned name.
cleanName(name) {
return name?.trim() || "missing";
}
Convert Relative to Absolute URL
The createAbsoluteUrl() method performs the following checks:
- If the URL is missing or consists only of empty spaces, it returns "missing".
- Otherwise, it returns the trimmed URL prefixed with https://www.chocolate.co.uk
createAbsoluteUrl(url) {
return (url?.trim()) ? `https://www.chocolate.co.uk${url.trim()}` : "missing";
}
This code will convert "/products/almost-perfect" to "https://www.chocolate.co.uk/products/almost-perfect," providing a navigable link.
Here’s the snapshot of the data that will be returned from the product data class. It consists of name, price_gb, price_usd, and url.

Complete Code for the Data Class
Now that we've defined all our methods, let's take a look at the complete code for Product class.
class Product {
constructor(name, priceStr, url, conversionRate = 1.32) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb, conversionRate);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
return name?.trim() || "missing";
}
cleanPrice(priceStr) {
if (!priceStr?.trim()) {
return 0.0;
}
const cleanedPrice = priceStr
.replace(/Sale priceFrom £|Sale price£/g, "")
.trim();
return cleanedPrice ? parseFloat(cleanedPrice) : 0.0;
}
convertPriceToUsd(priceGb, conversionRate) {
return priceGb * conversionRate;
}
createAbsoluteUrl(url) {
return (url?.trim()) ? `https://www.chocolate.co.uk${url.trim()}` : "missing";
}
}
Let's test if our Product class works as expected by creating a new instance with some messy data and checking if it cleans it up:
const p = new Product(
"Almost Perfect",
"Sale priceFrom £3.00",
"/products/almost-perfect");
console.log(p);;
// Product {
// name: 'Almost Perfect',
// priceGb: 3,
// priceUsd: 3.96,
// url: 'https://www.chocolate.co.uk/products/almost-perfect'
// }
This output is exactly what we anticipated. Next, we'll dive into the ProductPipeline class, where we'll implement the core logic.
Process and Store Scraped Data with Data Pipeline
A Pipeline refers to a sequence of steps where data moves through various stages, getting transformed and processed at each step. It’s a common pattern in programming for organizing tasks efficiently.
Here’s how our ProductDataPipeline will operate:
- Take raw product data
- Clean and structure the data
- Filter out duplicates
- Queue the product for storage
- Save data to CSV
- Perform final cleanup
Let's take a look at the overall structure of ProductDataPipeline:
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
this.csvFileOpen = false;
}
saveToCsv() {}
cleanRawProduct(rawProduct) {}
isDuplicateProduct(product) {}
addProduct(rawProduct) {}
async close() {}
}
The class above requires only two parameters, but it defines five properties, each serving a distinct purpose that will become clearer as we proceed. Here’s an overview of these properties:
- seenProducts: A Set that checks for duplicates, as a set automatically rejects any repeated values.
- storageQueue: A Queue that temporarily holds products until the
storageQueueLimitis reached. - storageQueueLimit: An integer representing the maximum number of products allowed in the
storageQueue. This value is passed as an argument when creating an instance of the class. - csvFilename: The name of the CSV file where the product data will be stored. This value is also passed as an argument when creating an instance of the class.
- csvFileOpen: A boolean flag to track whether the CSV file is currently open or closed, which will be useful in the
addProduct()andsaveToCsv()methods you'll see in later sections.
Similarly, there are five key methods that process and store our data as it moves through the pipeline. Here’s a brief overview of each:
- saveToCsv(): Periodically writes the products stored in the
storageQueueto a CSV file once thestorageQueueLimitis reached. - cleanRawProduct(): Cleans the raw data extracted from the web and converts it into a
Productinstance to structure and sanitize it. - isDuplicateProduct(): Checks if the product already exists in the
seenProductsset to avoid duplicate entries. - addProduct(): Cleans, checks for duplicates and adds the product to the pipeline. If the queue limit is reached, it saves the data to CSV.
- close(): Async method that ensures any remaining queued data is saved to the file before closing the pipeline.
Clean the Product Data
We’ve already covered how to clean data using the Product class. Here, we simply apply that by taking the raw data and creating an instance of the Product class:
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
Add the Product
The addProduct() method processes each product in a structured way:
- First, it cleans the raw product data by converting it into a
Productinstance using thecleanRawProduct()method. - Then, it checks if the product is a duplicate using the
isDuplicateProduct()method, and if it isn't, the product is added to thestorageQueue. - If the
storageQueuereaches its defined limit and the CSV file isn't already open, thesaveToCsv()method is triggered to save the queued data.
Here is the code:
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
Check for Duplicate Product
To ensure we don't add duplicate products to the storageQueue, we need a way to uniquely identify each product.
We'll use the URL of the products for this purpose, as it is unique to each product—even if two products have the same price.
Here’s how it works:
- When adding a product, its URL is added to the seenProducts set.
- The
isDuplicateProduct()method checks if the product's URL is already in theseenProductsset. - If the URL is not found, it indicates that the product is new, and we add the URL to the set and return
false. - If the URL is found, it means the product is a duplicate, so we return
true.
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
Periodically Save Data to CSV
Saving all the data to a CSV file at once could result in data loss if an error or interruption occurs during processing.
To mitigate this risk, we use a periodic approach where data is saved to the CSV file as soon as the storageQueue reaches its default limit of 5 items.
This way, if something goes wrong, only the latest batch of data is at risk, not the entire dataset. This method improves efficiency and data integrity.
In the saveToCsv() method:
- We determine if the CSV file already exists. If it does, the headers are assumed to be present.
- If the file does not exist, we write the headers ("name,priceGb,priceUsd,url\n") since headers should only be written once at the top of the file.
- Then we add the product data from the
storageQueueto the CSV file using file.write() method. - After writing all data, we close the file with file.end() method and set
csvFileOpento false to indicate that the CSV operations are complete
Here’s the code for saveToCsv():
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
In the code above, we utilized four methods from Node.js' fs module:
- existsSync(filename): This method checks if a file exists synchronously, returning true if the file is found, and false otherwise.
- createWriteStream(filename, flags: "a" ): Opens a writable stream with the option to append data (
{ flags: "a" }), ensuring new content is added without overwriting existing data. - write(data): Writes data to the stream, allowing content to be appended line by line when working with file streams.
- end(): Closes the writable stream, ensuring that all buffered data is flushed to the file and the file is properly closed. This should be called when no more data will be written.
Closing the Pipeline
When the close() method is called, it ensures that the pipeline completes all of its tasks. However, there might still be some products left in the storageQueue, which haven’t been saved to the CSV file yet.
We handle this by writing any remaining data to the CSV before closing.
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 1000));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
Full Data Pipeline Code
Here, we’ve combined all the methods we defined in the previous sections. This is how our complete ProductDataPipeline class looks:
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 1000));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
Now, let's test our pipeline to see if it works as expected.
We'll manually add the data extracted in Part 1 of this series, and after passing it through our pipeline, we'll save it to a file named "chocolate.csv":
const fs = require("fs");
class Product {
// Code for Product class
}
class ProductDataPipeline {
// Code for ProductDataPipeline
}
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
// Add to data pipeline
pipeline.addProduct({
name: "Lovely Chocolate",
price: "Sale priceFrom £1.50",
url: "/products/100-dark-hot-chocolate-flakes",
});
// Add to data pipeline
pipeline.addProduct({
name: "My Nice Chocolate",
price: "Sale priceFrom £4",
url: "/products/nice-chocolate-flakes",
});
// Add to duplicate data pipeline
pipeline.addProduct({
name: "Lovely Chocolate",
price: "Sale priceFrom £1.50",
url: "/products/100-dark-hot-chocolate-flakes",
});
// Close pipeline when finished - saves data to CSV
pipeline.close();
CSV file output:
name,price_gb,price_usd,url
Lovely Chocolate,1.5,1.98,https://www.chocolate.co.uk/products/100-dark-hot-chocolate-flakes
My Nice Chocolate,4,5.28,https://www.chocolate.co.uk/products/nice-chocolate-flakes
In the above example, we:
- Imported the
fsmodule. - Defined the
ProductandProductDataPipelineclasses. - Created a new pipeline instance.
- Added three unclean products, two of which are duplicates, to test the pipeline's handling of duplicates.
- Closed the pipeline to finish processing.
The output shows that the pipeline successfully cleaned the data, ignored duplicates, and saved the cleaned data to a file named "chocolate.csv" in our current directory.
Testing Our Data Processing
Now, let’s bring everything together by testing the complete code from Part 1 and Part 2 to ensure it scrapes, cleans, and stores all the data from chocolate.co.uk without any errors.
Below is the full code, including the scrape() and nextPage() methods from Part 1.
The scrape() method has been slightly modified to reflect the Product and ProductPipeline classes, but the changes are self-explanatory, so we won’t dive into the details here:
const { chromium } = require('playwright');
const fs = require('fs');
class Product {
constructor(name, priceStr, url, conversionRate = 1.32) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb, conversionRate);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
return name?.trim() || "missing";
}
cleanPrice(priceStr) {
if (!priceStr?.trim()) {
return 0.0;
}
const cleanedPrice = priceStr
.replace(/Sale priceFrom £|Sale price£/g, "")
.trim();
return cleanedPrice ? parseFloat(cleanedPrice) : 0.0;
}
convertPriceToUsd(priceGb, conversionRate) {
return priceGb * conversionRate;
}
createAbsoluteUrl(url) {
return (url?.trim()) ? `https://www.chocolate.co.uk${url.trim()}` : "missing";
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 1000));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function scrape() {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
for (let url of listOfUrls) {
console.log(`Scraping: ${url}`);
await page.goto(url);
const productItems = await page.$$eval("product-item", items =>
items.map(item => {
const titleElement = item.querySelector(".product-item-meta__title");
const priceElement = item.querySelector(".price");
return {
title: titleElement ? titleElement.textContent.trim() : null,
price: priceElement ? priceElement.textContent.trim() : null,
url: titleElement ? titleElement.getAttribute("href") : null
};
})
);
for (const rawProduct of productItems) {
if (rawProduct.title && rawProduct.price && rawProduct.url) {
pipeline.addProduct({
name: rawProduct.title,
price: rawProduct.price,
url: rawProduct.url
});
}
}
await nextPage(page);
}
await pipeline.close();
await browser.close();
}
async function nextPage(page) {
let nextUrl;
try {
nextUrl = await page.$eval("a.pagination__nav-item:nth-child(4)", item => item.href);
} catch (error) {
console.log('Last Page Reached');
return;
}
listOfUrls.push(nextUrl);
}
(async () => {
await scrape();
})();
// Scraping: https://www.chocolate.co.uk/collections/all
// Scraping: https://www.chocolate.co.uk/collections/all?page=2
// Scraping: https://www.chocolate.co.uk/collections/all?page=3
// Last Page Reached
After running the code, we should see all the pages from chocolate.co.uk being scraped, with prices displayed in both GBP and USD. The relative URLs are converted to absolute URLs after passing through our Product class, and the data pipeline has successfully removed any duplicates and saved the clean data into the CSV file.
Here’s a screenshot of the fully cleaned and structured data:
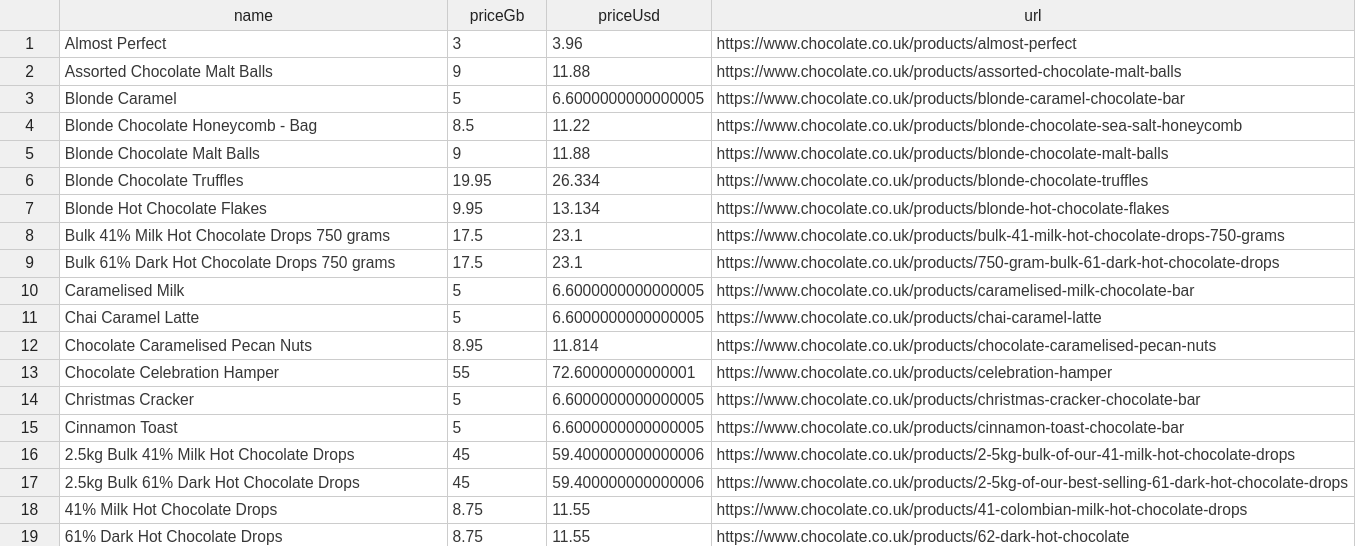
Next Steps
We hope you've gained a solid understanding of the basics of data classes, data pipelines, and periodic data storage in CSV files. If you’d like to inspect or fork the source code, grab the language‑agnostic snippets from the original Gist = github.com/triposat/1d22724de6f227642c8faa6080f00520 - or clone the full Node‑centric example at github.com/The-NodeJs-Web-Scraping-Playbook/Beginner-Series-Part-2-Cleaning.
Questions, bugs, or optimisation ideas? Drop them in the comments and we’ll jump in.
Ready to move beyond flat files? In Part 3 we’ll benchmark storage back‑ends - JSON, PostgreSQL, MySQL, AWS S3, and more - so you can pick the right sink for your workload, budget, and scaling plans. Stay tuned!