
freeCodeCamp Scrapy Beginners Course Part 11: Deploying & Scheduling Spiders With ScrapeOps
In Part 11 of the Scrapy Beginner Course, we go through how you can deploy, schedule and run your spiders on any server with ScrapeOps.
There are several ways to run and deploy your scrapers to the cloud which we will cover in this course:
However, in Part 11 we will show you how to deploy, schedule and run your spiders in the cloud with ScrapeOps:
- What Are The ScrapeOps Job Scheduler & Monitor?
- ScrapeOps Scrapy Monitor
- Setting Up The ScrapeOps Scrapy Monitor
- ScrapeOps Server Manager & Scheduler
- Connecting ScrapeOps To Your Server
- Deploying Code From Github To Server With ScrapeOps
- Scheduling & Running Spiders In Cloud With ScrapeOps
The code for this part of the course is available on Github here!
If you prefer video tutorials, then check out the video version of this course on the freeCodeCamp channel here.
This guide is part of the 12 Part freeCodeCamp Scrapy Beginner Course where we will build a Scrapy project end-to-end from building the scrapers to deploying on a server and run them every day.
If you would like to skip to another section then use one of the links below:
- Part 1: Course & Scrapy Overview
- Part 2: Setting Up Environment & Scrapy
- Part 3: Creating Scrapy Project
- Part 4: First Scrapy Spider
- Part 5: Crawling With Scrapy
- Part 6: Cleaning Data With Item Pipelines
- Part 7: Storing Data In CSVs & Databases
- Part 8: Faking Scrapy Headers & User-Agents
- Part 9: Using Proxies With Scrapy Spiders
- Part 10: Deploying & Scheduling Spiders With Scrapyd
- Part 11: Deploying & Scheduling Spiders With ScrapeOps
- Part 12: Deploying & Scheduling Spiders With Scrapy Cloud
The code for this project is available on Github here!
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
What Are The ScrapeOps Job Scheduler & Monitor?
The ScrapeOps Job Scheduler & Monitor is free to use web scraper monitoring and job scheduling tool that you can easily integrate with any Scrapy spider to monitor your spiders and run them remotely in the cloud.
It comprises two parts:
You can use one without using the other, for the best experience you should use both solutions as it will allow you to deploy, schedule, run and monitor your web scraping jobs in production.
ScrapeOps Scrapy Monitor
The ScrapeOps Monitor is a free monitoring and alerting tool dedicated to web scraping. With a simple 30-second install ScrapeOps gives you all the monitoring, alerting, scheduling and data validation functionality you need for web scraping straight out of the box.
Live demo here: ScrapeOps Demo
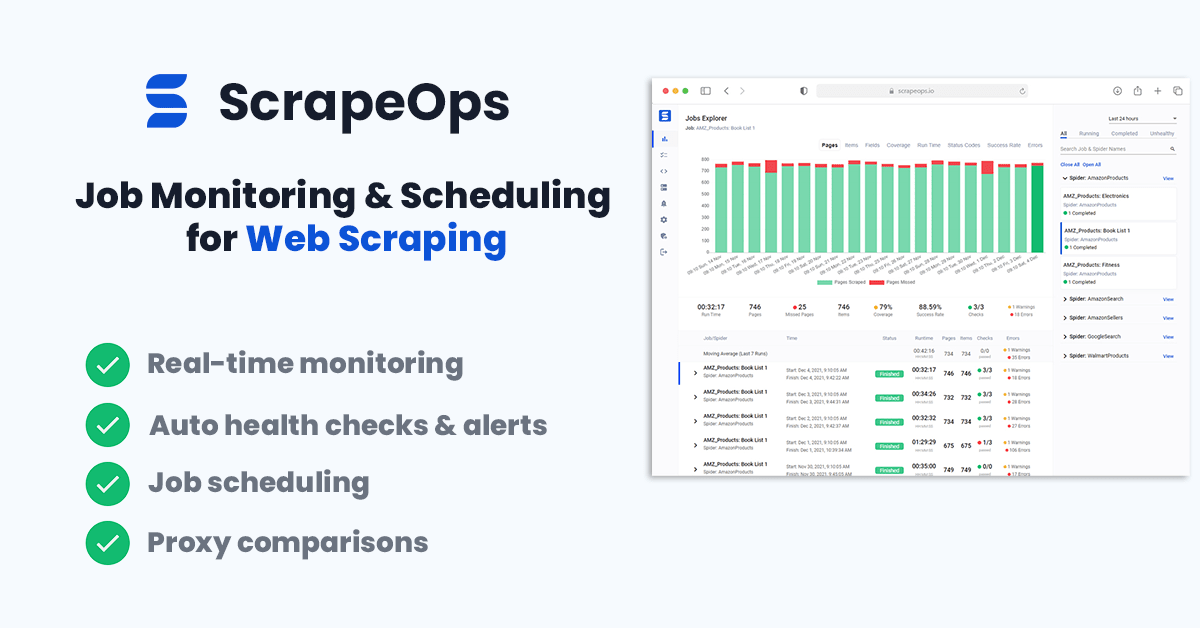
The primary goal of the ScrapeOps Monitor is to give every developer the same level of scraping monitoring capabilities as the most sophisticated web scrapers, without any of the hassle of setting up your own custom solution.
The ScrapeOps Monitor is a full end-to-end web scraping monitoring and management tool dedicated to web scraping that automatically sets up all the monitors, health checks and alerts for you. If you have an issue with integrating ScrapeOps or need advice on setting up your scrapers then they have a support team on-hand to assist you.
Features
Once you have completed the simple install (3 lines in your scraper), ScrapeOps will:
- 🕵️♂️ Monitor - Automatically monitor all your scrapers.
- 📈 Dashboards - Visualise your job data in dashboards, so you see real-time & historical stats.
- 💯 Data Quality - Validate the field coverage in each of your jobs, so broken parsers can be detected straight away.
- 📉 Auto Health Checks - Automatically check every job's performance data versus its 7-day moving average to see if it's healthy or not.
- ✔️ Custom Health Checks - Check each job with any custom health checks you have enabled for it.
- ⏰ Alerts - Alert you via email, Slack, etc. if any of your jobs are unhealthy.
- 📑 Reports - Generate daily (periodic) reports, that check all jobs versus your criteria and let you know if everything is healthy or not.
Job stats tracked include:
- ✅ Pages Scraped & Missed
- ✅ Items Parsed & Missed
- ✅ Item Field Coverage
- ✅ Runtimes
- ✅ Response Status Codes
- ✅ Success Rates
- ✅ Latencies
- ✅ Errors & Warnings
- ✅ Bandwidth
Setting Up The ScrapeOps Scrapy Monitor
Getting set up with the ScrapeOps logger is simple. Just install the Python package:
pip install scrapeops-scrapy
And add 3 lines to your settings.py file:
## settings.py
## Add Your ScrapeOps API key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
## Add In The ScrapeOps Extension
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
## Update The Download Middlewares
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
From there, your scraping stats will be automatically logged and automatically shipped to your dashboard.

ScrapeOps Server Manager & Scheduler
The ScrapeOps Server Manager & Scheduler allows you to deploy, schedule & run any type of scraper (Python, NodeJs, Scrapy, etc) on a server that is accessible via SSH. Which includes most major server & VM providers (Digital Ocean, Vultr, AWS, etc.):
- 🔗 Integrate With Any SSH Capably Server
- 🕷 Deploy scrapers directly from GitHub to your servers.
- ⏰ Schedule Periodic Jobs
For this course, we will look at how to integrate the ScrapeOps server manager and scheduler with a Digital Ocean server. However, here is a guide to integrating it with an AWS Server
Get $100 Free Credits with Vultr using this link, and $100 Free Credits with Digital Ocean using this link.
Connecting ScrapeOps To Your Server
Deploying Code From Github To Server With ScrapeOps
Scheduling & Running Spiders In Cloud With ScrapeOps
Next Steps
In this part, we looked at how we can use Scrapyd to deploy and run our spiders in the cloud and control them using ScrapeOps and ScrapydWeb.
So in Part 11, we will look at how you can use ScrapeOps free server manager & job scheduler to deploy and run Scrapy spiders in the cloud.
All parts of the 12 Part freeCodeCamp Scrapy Beginner Course are as follows:
- Part 1: Course & Scrapy Overview
- Part 2: Setting Up Environment & Scrapy
- Part 3: Creating Scrapy Project
- Part 4: First Scrapy Spider
- Part 5: Crawling With Scrapy
- Part 6: Cleaning Data With Item Pipelines
- Part 7: Storing Data In CSVs & Databases
- Part 8: Faking Scrapy Headers & User-Agents
- Part 9: Using Proxies With Scrapy Spiders
- Part 10: Deploying & Scheduling Spiders With Scrapyd
- Part 11: Deploying & Scheduling Spiders With ScrapeOps
- Part 12: Deploying & Scheduling Spiders With Scrapy Cloud