
The State of Web Scraping 2025
Now that 2025 is well underway, the ScrapeOps Team decided to look at the big events & trends in the world of web scraping, and give our predictions on what 2025 will look like for web scraping.
Including the good, the bad, and the ugly:
- Web Scraping's $13B Gold Rush: Boom or Bubble?
- AI Agents: Could AI Agents Revolutionize Web Scraping?
- Self Healing Scrapers: The Holy Grail for Web Scrapers?
- The Anti-Bot Arms Race: Scrapers Keep The Lead
- The Great Proxy Shakeup: New Players, New Rules
- Web Scraping Arsenal: Top Tools & Libraries for 2025
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: Web Scraping in 2025 - Booming, Battling, and Breaking Barriers
- $13B Gold Rush: Web scraping is exploding at 15% YoY, but rising costs, lawsuits, and bot defenses threaten the momentum.
- AI Scrapers—Hype or Reality? LLM-powered scrapers sound great—until you hit sky-high costs, slow speeds, and inconsistent results. Hybrid AI-assisted scrapers are the real game-changer.
- Anti-Bot Warfare: Cloudflare, DataDome, and login walls are tightening the noose—scrapers are fighting back with mobile proxies, fortified browsers, and stealth tech.
- Proxy Wars: Domain-based pricing is growing but remains inconsistent, while budget residential proxies are shaking up the traditional market players.
- Legal Minefield: Courts are drawing lines—public scraping is (mostly) legal, bypassing defenses is not. AI dataset scraping faces new EU/US crackdowns.
- Scraper's Arsenal: Python (Scrapy, Selectolax), Node.js (Playwright, Cheerio), and AI-powered tools (Firecrawl, ScrapeGraphAI) are leading the charge.
2025 could be a pivotal year: Innovate or get blocked. The scraping game is evolving—are you?

Web Scraping's $13B Gold Rush: Boom or Bubble?
Once a niche tool, web scraping now powers innovation across e-commerce, AI, and data-driven decision-making, cementing itself as a cornerstone of the digital economy.
According to the ScrapeOps Web Scraping Market Research Report 2025, the web scraping industry is projected to grow at 15% annually and hit $13.05 billion by 2033. This analysis is based on an aggregation of multiple independent market research reports, confirming a strong and sustained demand for web data extraction.
However, this rapid growth is coming has a cost, with rising expenses, ethical debates, and increasingly sophisticated anti-scraping measures threatening the pace of adoption.
The Numbers Behind the Growth
Google Trends data shows that the interest in web scraping is steadily compounding at ~10% per year, with a 46% increase in interest in the last 4 years since 2020.
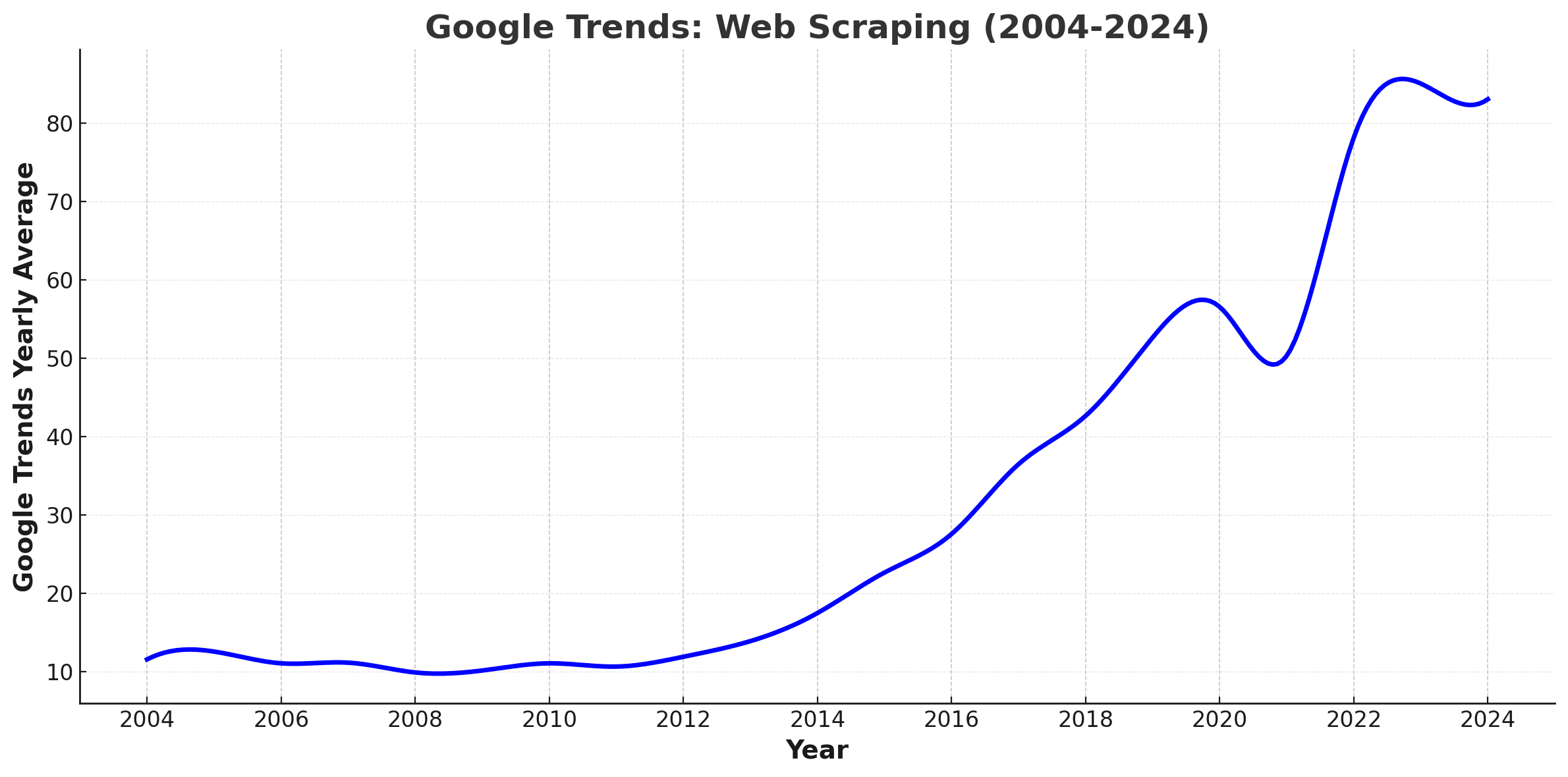
This trend is reflected in the market research reports, with every market research report predicting the web scraping market to continue to grow year over year for the next 5-10 years. Growing on about ~15% every year.
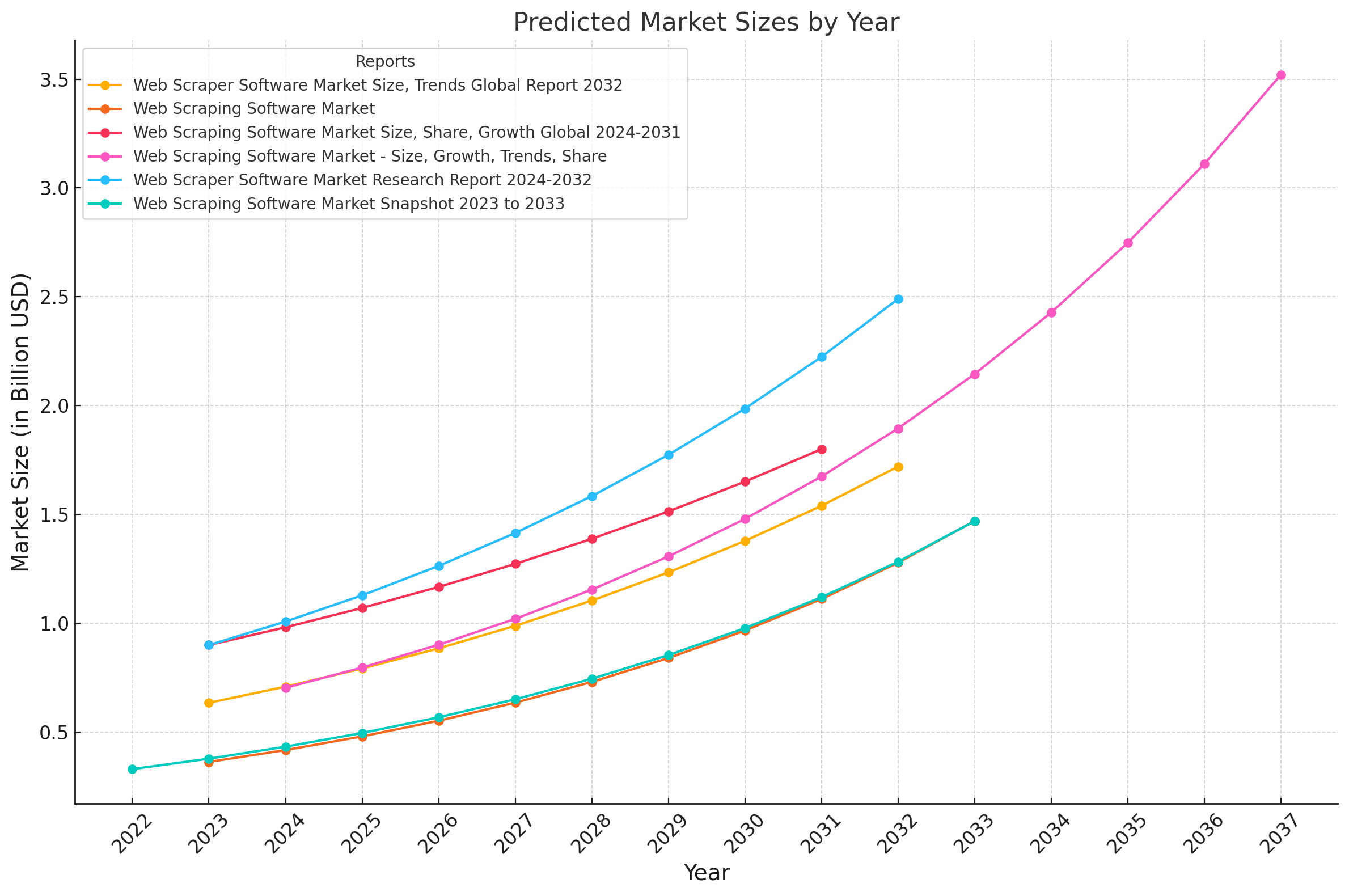
| Report | Predicted Market Size | CAGR |
|---|---|---|
| Web Scraping Software Market Report, 2025 | $4.27B (2024) to $13.05B (2033) | 15% |
| Web Scraper Software Market Size, Trends Global Report 2032 | $634.53M (2023) to $1.72B (2032) | 13.29% |
| Web Scraping Software Market | $501.9M (2025) to $2030.4M (2035) | 15% |
| Web Scraping Software Market Size, Share, Growth Global 2024-2031 | $0.90B (2023) to $1.80B (2031) | 13.3% |
| Web Scraping Software Market - Size, Growth, Trends, Share | $703.56M (2024) to $3.52B (2037) | 13.2% |
| Web Scraper Software Market Research Report 2024-2032 | $0.90B (2023) to $2.49B (2032) | 11.9% |
| Web Scraping Software Market Snapshot 2023 to 2033 | $330M (2022) to $1.469B (2033) | 15% |
These reports collectively indicate a robust upward trajectory for the web scraping industry, driven by the increasing demand for data extraction and analysis across various sectors.
Driving Forces Behind the Growth
What's fueling this explosion in web scraping interest? Here are the three forces shaping its meteoric rise.
-
AI and Machine Learning Data Demands: The explosive growth in AI and ML applications has created unprecedented demand for high-quality, domain-specific datasets. Web scraping has become the go-to method for sourcing training data, enabling advancements in personalized recommendations, predictive analytics, and generative AI systems.
-
E-Commerce and Competitive Intelligence: The continued boom in e-commerce has driven businesses to rely on web scraping for real-time pricing, product availability, and market trend analysis. With global competition intensifying, scraping has become essential for staying competitive and informed.
-
Data-Driven Decision Making: Businesses across industries increasingly rely on publicly available data to analyze markets, optimize strategies, and forecast trends. Web scraping provides scalable, real-time access to this data, making it indispensable in a competitive, data-centric economy.
2025 Outlook
The web scraping industry is poised for another year of significant growth, but the challenges are mounting. As demand continues to rise, businesses must navigate the growing complexities of anti-bot measures, rising costs, and regulatory scrutiny.
Will the industry overcome these hurdles to unlock its full potential, or will the cost of scraping outweigh its benefits? 2025 is shaping up to be a pivotal year.
The ScrapeOps Web Scraping Market Research Report 2025 aggregates all the available market research reports and provides a comprehensive analysis of the web scraping industry.

AI Agents: The Future of Web Scraping?
AI agents capable of extracting data from websites and controlling browsers are emerging as a potential game-changer for web scraping, promising to revolutionize how we extract data from websites and automate web tasks.
These tools can autonomously navigate websites, handle dynamic content, and extract structured data with minimal human intervention.
While traditional scrapers require custom development and constant maintenance to handle website changes, AI agents can operate with simple instructions and adapt to changes on the fly.
AI Agents = Surge In Web Scraping Demand?
The rise of AI agents and AI crawlers are fundamentally changing the internet. With their promised ability to navigate websites, extract data and interact with websites with easy setups and little to no human intervention, they are opening up a whole new world of web scraping accessibilty, use cases and demand.
Data from Vercel, shows that the number of requests to their networks from AI agent bots has increased exponentially over the last 12 months. With GPTBot, Claude, AppleBot, and PerplexityBot combined accounting for nearly 1.3 billion fetches in November 2024. A little over 28% of Googlebot's volume, the internet's traditional big crawler.
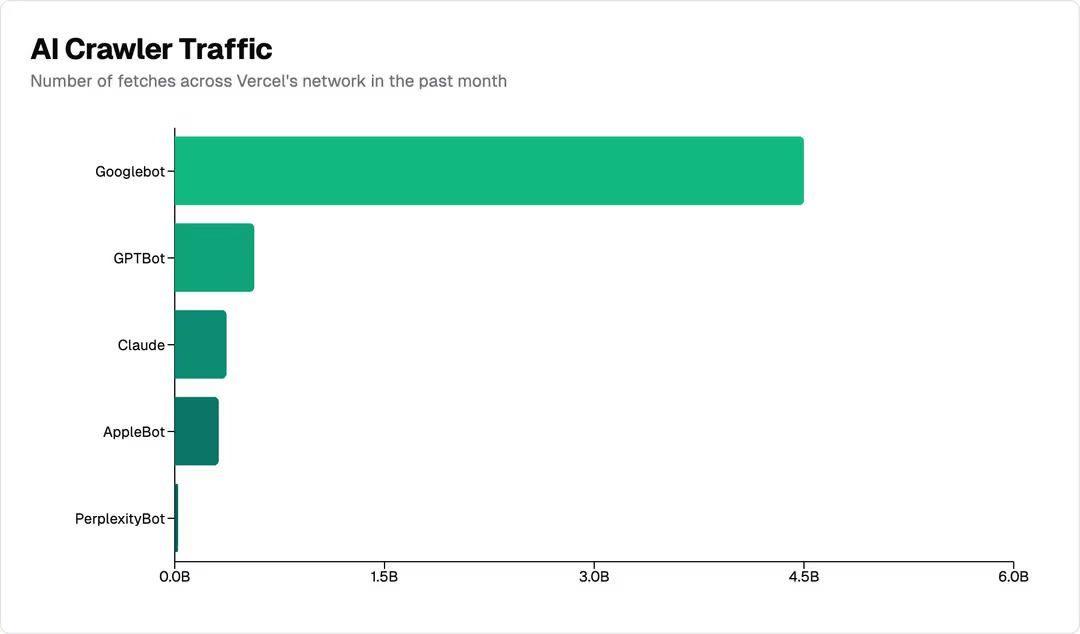
AI Crawlers generate more than 50 billion requests to the Cloudflare network every day, or just under 1% of all web requests we see.
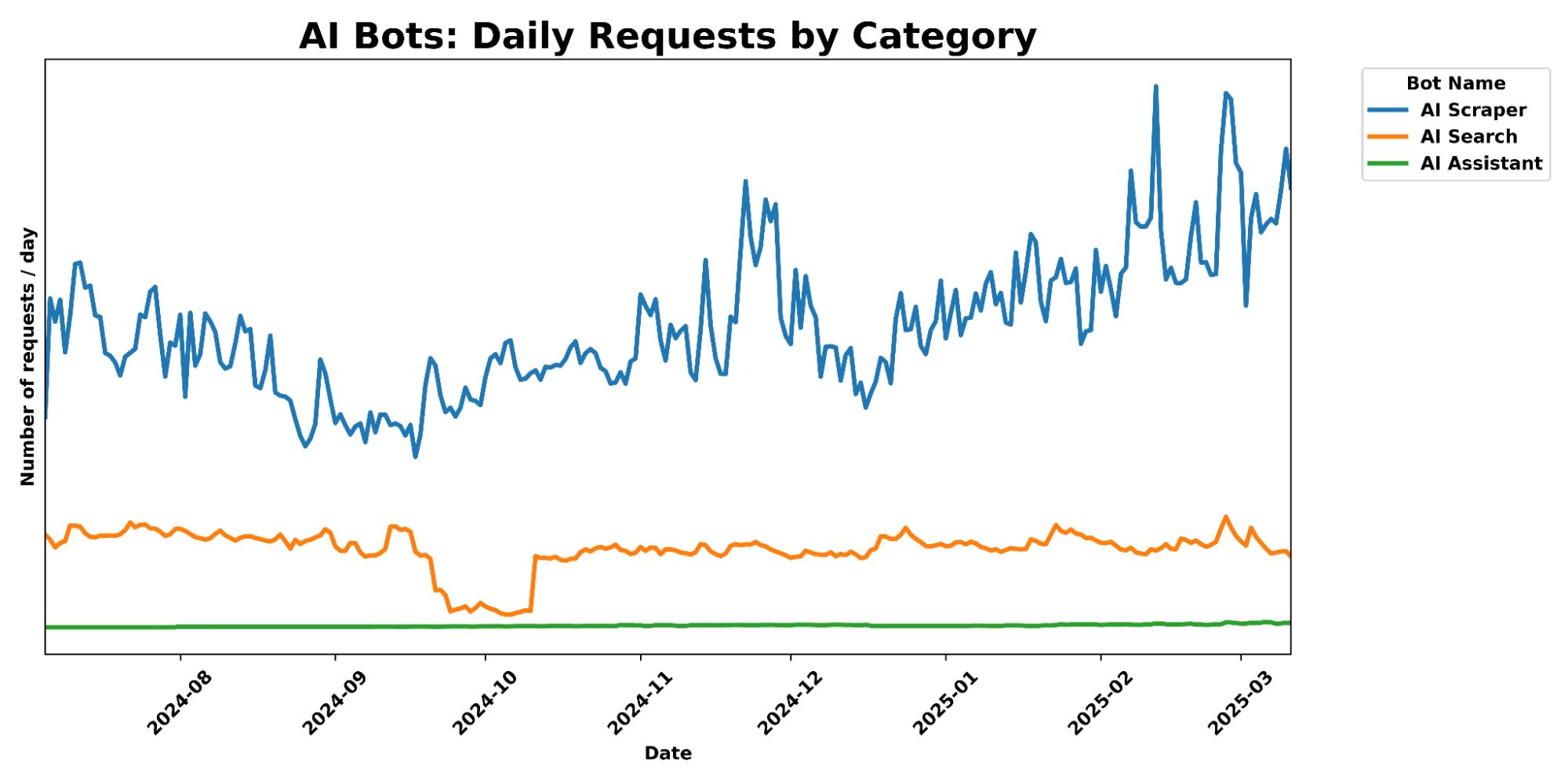
Given that AI agents are still in their infancy, this points a huge surge in web scraping activity in the coming years as AI agent systems continue to improve and become more widespread.
However, challenges remain:
-
Crawler Inefficency: Vercel's data shows that AI crawlers are inefficient, with ChatGPT and Claude spending ~34% of their fetches on 404 pages respectively, and ChatGPT spending an additional 14.36% of fetches following redirects. Contrasting sharply with Googlebot's 8.22% of fetches on 404s and 1.49% on redirects. Suggesting that AI bots/crawlers still have more optimising to do.
-
Inaccuracies: Although very capable, AI bots still suffer from inaccuracies, can often get confused by dynamic content, and veer off scope unless strictly constrained.
-
Cost: Given that AI bot/crawlers often use a LLM model to understand and navigate a website, the operational cost of running a AI agent based bot/crawler is significantly higher than a traditional scraper. Where the majority of the cost is in the orginal development and maintenance of the scraper.
-
Blocking: Many websites are now developing blocking mechanisms to specifically target AI crawlers/bots. From forcing JS rendering (as of November 2024, none of the major LLM providers have JS rendering enabled), to designing next generation honeypot traps to detect and block AI crawlers like Cloudflare's AI Labyrinth.
So what's behind this surge in AI agent activity?
2024 Highlights: AI Agent Scraping Tools Emerge
2024 saw the first wave of AI-powered browser automation and scraping tools hit the market, with more revealed in 2025 so far:
Browser Automation AI Agents
While still in early stages, browser automation AI agents significantly reduce the barrier to entry to browser automation and web scraping. Enabling users to automate tasks that would otherwise require custom development or hours of manual labour with simple text prompts.
Since late 2024, we've seen a ever growing list of browser automation AI agents emerge:
| Tool | Description |
|---|---|
| Anthropic's Computer Use | This documentation outlines how Anthropic enables AI agents to safely interact with computer resources and manage file operations. |
| OpenAI's Operator | OpenAI's Operator is a platform that integrates AI models with external systems to streamline and manage complex workflows. |
| Skyvern | An open‑source project on GitHub, Skyvern provides AI-powered automation tools designed to simplify task execution and workflow integration. |
| Browser Use | Browser Use offers a secure environment for AI agents to safely navigate and interact with live web content. |
| Axiom.ai | Axiom.ai is a no‑code automation platform that leverages AI to automate repetitive web tasks and streamline online workflows. |
| BrowseGPT | BrowseGPT extends GPT models with real‑time web browsing capabilities to provide up‑to‑date information and enhance response accuracy. |
Takeaway: These tools have the potential to unlock a new wave of web scraping tools and applications, enabling users to automate even more complex web tasks with less and less upfront development. Also, dramatically increasing the demand for underlying proxy and browser automation technologies.
Deep Research AI Agents
Deep research AI agents enable users to perform complex web searches and analysis without the need for humans to manually search the web.
Within 5-10 minutes, one of these research agents can develop a research plan, search over 50+ web pages, adapting the research plan as it goes and summarising the results in a concise report. Something that before would have taken a human hours or days to do manually.
| Tool | Description |
|---|---|
| OpenAI's Deep Research Agent | OpenAI's Deep Research Agent is designed to empower users with advanced AI-driven research capabilities for more nuanced and comprehensive inquiry. |
| Perplexity Deep Research | Perplexity Deep Research offers an AI-enhanced research experience that dives deeper into complex queries by aggregating and analyzing diverse sources of information. |
| Gemini Deep Research | Gemini Deep Research by Google leverages next-generation AI to provide in-depth, context-rich research insights and analysis. |
| Hugging Face's Open Source Deep Research Agent | Hugging Face's Open Source Deep Research Agent is a community-driven project that utilizes open-source AI models to facilitate rigorous and transparent deep research. |
Takeaway: Again, this presents a dramatic shift in the web scraping market, whereas before users would manually only do a few searches to answer a question or query. Now, they can instruct a deep research agent to perform a comprehensive search on a topic and get a detailed report in return, potentially dramatically increasing the volume of web queries users will perform for their daily queries.
AI Agent Workflows
The emergence of AI agents is also reshaping the way companies and individuals think about automation workflows they use in their daily business operations and life.
With numerous of low code and no code tools emerging to enable users to create their own AI agents, and the ease at which you can give these agents access to the internet with AI agent optimized search tools like Tavily, Perplexity, Firecrawl, etc. is facilitating a new wave of web scraping use cases via AI enabled automation workflows.
| Tool | Description |
|---|---|
| N8N | n8n is an extendable, open‑source workflow automation tool that empowers users to connect various apps and automate processes via a visual interface. |
| Make | Make is a cloud‑based automation platform (formerly Integromat) that lets users visually design and automate workflows across diverse applications and services. |
| Zapier | Zapier is a widely‑used online automation platform that connects apps and services to streamline workflows and eliminate repetitive tasks without coding. |
| LangGraph | LangGraph provides a visual interface for designing and managing LangChain applications, simplifying the creation of complex language model workflows. |
Takeaway: As more and more platforms integrate AI agents with internet access, we will see a surge in demand for the web scraping tools and technologies that power these AI agents.
2025 Outlook: Scraper Copilots, Custom Models & AI Middleware
In 2025, AI won't replace scrapers — it'll supercharge them. We're entering the era of scraper copilots, purpose-built AI models, and AI agent automation infrastructures:
-
AI-Enhanced Development Will Become Standard: Along with generic AI enabled coding tools like Cursor, Windsurf, etc. expect to see the emergence of AI powered assistants for web scraping. That help you build, monitor and maintain scrapers. Current examples include Oxylabs OxyCopilot which is blending AI-driven parsing with robust proxy management.
-
Emergence of AI Parsers: In 2025, expect to see the emergence of purpose-built AI models and tooling for web scraping, that can generate a scraper from a example URL and automatically heal your scrapers when they break. Zyte has lead the way with Zyte AI which is a tool that can generate a scraper from a example URL and automatically heal your scrapers when they break.
-
AI Middleware & Tooling Ecosystem Expands: Tools like Firecrawl, Tavily, and Browse.ai are emerging as the AI middleware layer between LLMs and the web — handling crawling, extraction, and rendering in ways that are optimized for agent use. This “agent stack” will continue to evolve and standardize.
-
AI for Monitoring & Maintenance: Companies will deploy AI agents to monitor scraper health, detect page structure changes, and even auto-update selectors or scraping logic — reducing downtime and dev intervention.
-
Selective AI Integration: Companies will use AI agents for complex, low-volume scraping tasks while keeping traditional scrapers for high-volume, straightforward jobs.
-
Traditional Scraping Will Still Dominate High-Scale Jobs: Despite AI's growing footprint, traditional scraping with custom-built extractors, headless browsers, and proxies will remain the foundation for high-scale, high-volume scraping operations in 2025.
Overall, 2025 is shaping up to be the year of augmented scraping — where AI enhances, but doesn't replace, the tooling and techniques that power modern web data extraction.

Self Healing Scrapers: The Holy Grail for Web Scrapers?
Could 2025 be the year that web scrapers finally achieve the "holy grail" of automated, cost-effective, self-healing AI-driven parsers?
The thought of it is aluring...
- Give a LLM a URL of a page you want to scrape and the data you want to extract, and it will develop a custom parser for that page.
- Intergrated in the scraper would be a monitoring tool that would track the performance of the parser and alert you when it breaks.
- Then the system would automatically heal itself so that you don't experience any data downtime.
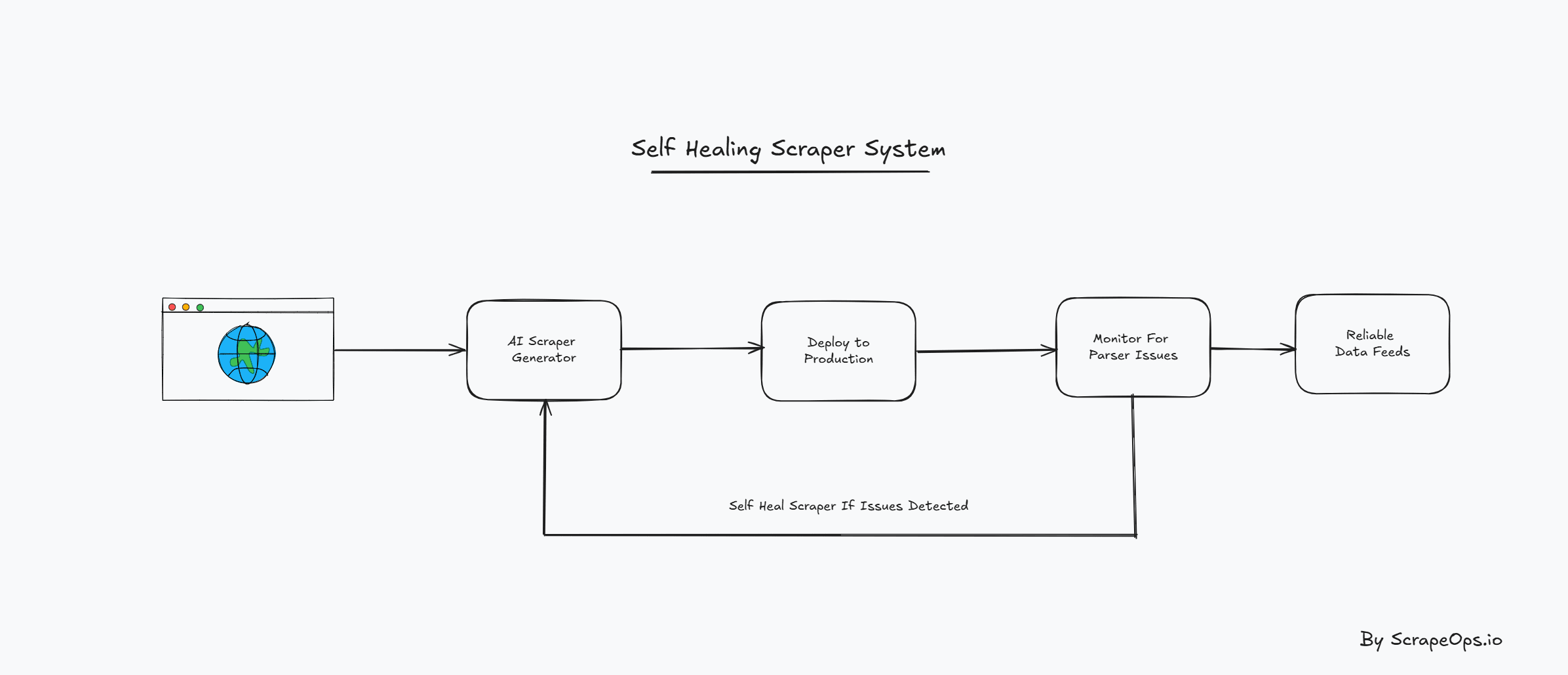
This would significantly reduce the time and effort to develop and deploy scrapers, and remove the headache every developer knows about having to periodically go any debug a broken scraper that isn't returning the correct data.
It is all theoritically feasible, but where are we at currently?
Current Best Attempts at AI Parsers
Although we know of a number of companies experimenting with developing this, to date nobody has been able to crack it.
LLM Based AI Parsers
The current best solutions are tools like Firecrawl, ScrapeGraphAI and Crawl4AI that are using LLMs to parse the data directly from every page that needs to be scraped so that automatically adapt to changes on the page.
While accurate for most use cases, the are typically only affordable for small-scale projects or when scraping small volumes from thousands of different websites. As each parsing operation makes a LLM call that incurs significant costs, making traditional scrapers far more economical.
In our teardown of the the best AI LLM based AI parsers, we found that the cost of scraping a single page with an LLM based AI parser was between $666 and $3,025 per million pages. Which is simply not scalable for most web scraping projects.
| Tool | Cost Per Million Pages |
|---|---|
| Custom Scraper | $1-$5 |
| Firecrawl | $666 |
| ScrapeGraphAI | $2,000 |
| Skrape.ai | $5,000 |
| Open Source | $3,025 |
Verdict: While the LLM based AI parsers are promising, they are currently only affordable for small-scale projects or when scraping small volumes from thousands of different websites.
Black Box AI Parsing Solutions
Over the last year, we seen more and more web scraping and proxies companies start pivoting their companies from "web scraping companies" to offering "data solutions".
Whilst most major players are offering some form of data API for popular industries (e-commerce, SEO, market research, etc.) and websites, behind the scenes most of these are still likely manually developed and maintained.
The company making the biggest strides toward true self healing scrapers is Zyte with their AI parsing functionality within the Zyte API.
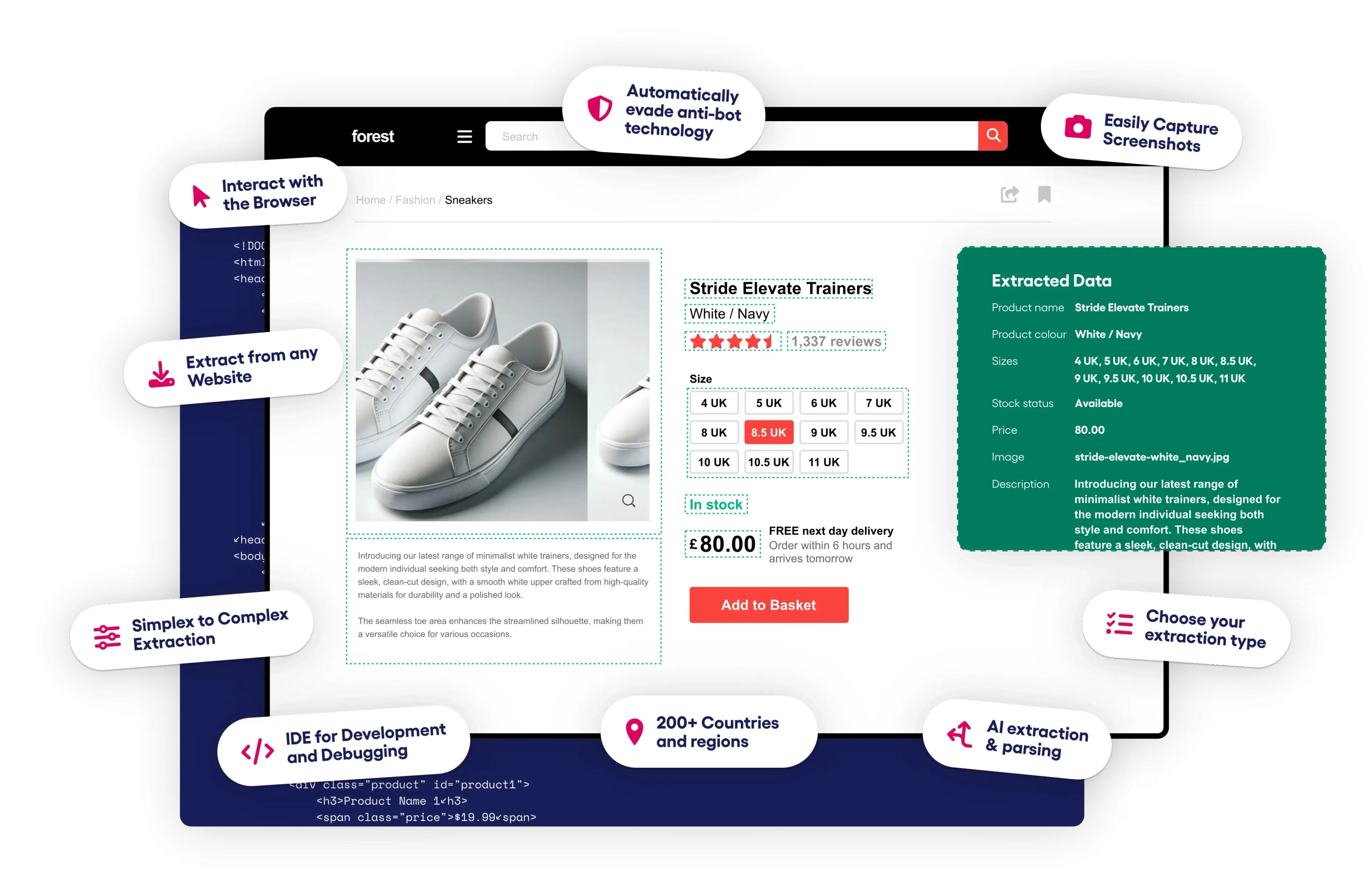
Behind the scenes Zyte has trained a custom AI models for numerous page types (product pages, blog posts, etc.) that extract data from a page with a combination of articifical intelligence, image object detection from page screenshots and LLM parsing.
Check out their patents to get a more behind the scenes look at how they are achieving this.
This solution works for specific use cases, but the big issue is that you are required to use it via their proxy network and you are limited to the use cases they have trained their AI models for.
Verdict: Zyte's AI parsing solution is a step in the right direction, but it is not a true self healing scraper.
True Self Healing Scrapers
Although it is early days, we're starting to see some companies and open source projects fulfilling the promise of true self healing scrapers.
- Spider Creator is a open source project that uses LLMs and Browser Use to generate Playwright based spiders with with minimal manual coding. This library is still highly experimental.
- Blat is planning to offer true self healing scrapers. Simply give Blat a batch of sample URLs for the type of pages your want to scrape, an example data schema and their AI agent will generate scraping code for you.
Simply give Blat a batch of sample URLs for the type of pages your want to scrape, an example data schema and their AI agent will generate scraping code for you.
Verdict: Although it is early days, we're starting to see some companies and open source projects fulfilling the promise of true self healing scrapers.
2025 Outlook: The Road Ahead for AI Parsers
AI parsers in 2025 are poised to tackle these challenges, with several promising trends on the horizon:
-
Shift Toward Static Code Generators:
Expect tools to emerge that can analyze multiple pages and generate robust, reusable scraper code. This shift would lower costs and improve scalability, bringing us closer to the "holy grail" of AI parsing. -
Improved LLM Integration:
Proxy APIs and open-source tools will refine their use of LLMs, improving handling of dynamic content and edge cases. Faster processing and more reliable data extraction will be key focuses. -
Expanding Open-Source Tools:
Tools like Firecrawl, ScrapeGraphAI, and Crawl4AI are likely to evolve and more will emerge, offering more accessible and feature-rich solutions for developers. -
Hybrid Approaches:
The most practical workflows in 2025 will combine AI tools for adaptability with traditional parsers for cost efficiency. This blend will provide the best of both worlds while overcoming the limitations of current AI solutions.
While 2025 may not fully deliver the ultimate AI-driven scraper, the industry is moving rapidly toward more scalable and cost-effective solutions. Developers who experiment with emerging tools and adopt hybrid strategies will be best positioned to capitalize on these innovations.

The Anti-Bot Arms Race: Scrapers Keep The Lead
Although, web scrapers have largely stayed one step ahead of anti-bot solutions, on the whole it is becoming increasingly more difficult and expensive to scrape websites.
More and more websites are now using sophisticated anti-bot systems like Cloudflare, DataDome, PerimeterX, etc. with higher security settings to prevent web scrapers from accessing their websites.
These anti-bot systems are increasingly moving away from simple header and IP fingerprinting, to more complicated browser and TCP fingerprinting with webRTC, canvas fingerprinting and analyzing mouse movements allowing them to better differentiate automated scrapers from real-users.
Web scraping likely won't become impossible anytime soon, however, many developers and businesses are increasingly having to use expensive residential/mobile proxies in combination with fortified headless browsers to bypass the anti-bot challenges on protected websites.
Potentially, changing the economics of certain web scraping use cases to the point that scraping that data becomes uneconomical.
Anti-Bot Breakdown
The following graph shows a breakdown of the top 10,000 most popular websites and which anti-bot systems do they use.
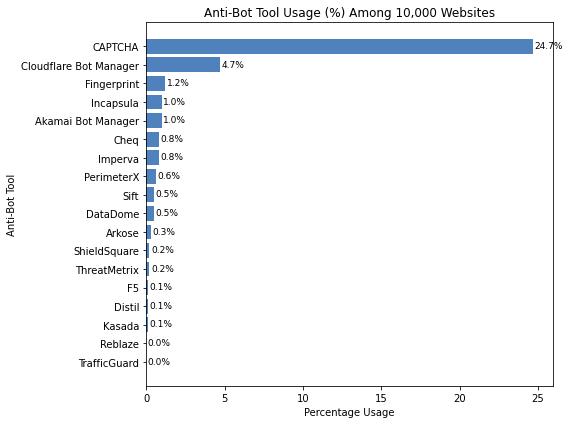
Of all the anti-bot solutions out there, Cloudflare Bot Manager is the most popular among websites. Largely because more and more websites are using Cloudflare for its other products (CDN, etc.), making it the easiest option for many websites to implement.
Whilst the vanilla Cloudflare anti-bot can still be bypassed relatively easily, when a website is using the advanced Bot Manager it can be quite challenging to deal with. Most of the time, you need to fallback to a headless browser and good proxy/header management.
DataDome presents one of the most difficult challenges for web scrapers. It uses a combination of sophisticated browser and request fingerprinting techniques along with onpage challenges to detect and block scrapers. DataDome like any other anti-bot can be bypassed, however, it comes down to is it worth the cost.
For more information on how to bypass anti-bot systems like Cloudflare, DataDome, PerimeterX, etc. then check out our bypass guides here:
Emerging New Scraping Defences
In 2024, we saw more occurrences of websites implementing more diverse strategies to protect their data from scrapers. With more and more websites resorting to:

Data Cloaking
Data cloaking is a anti-scraping defence strategy that returns a fake version of the page to the scraper instead of the real page when the anti-bot system detects a scraper.
Up until recently, this appeared to be a growing but niche technique used by a few websites, but in Match 2025 Cloudflare unveiled their latest anti-bot system, AI Labyrinth which makes this technique available to all websites. Even on their free plan.
Today, we're excited to announce AI Labyrinth, a new mitigation approach that uses AI-generated content to slow down, confuse, and waste the resources of AI Crawlers and other bots that don't respect “no crawl” directives. When you opt in, Cloudflare will automatically deploy an AI-generated set of linked pages when we detect inappropriate bot activity, without the need for customers to create any custom rules.
Returning fake versions of the page is a vastly increases the complexity of scrapers to validate the response is real and contains valid data, as with this technique the scraper needs to now validate that the data is real, not just that the page isn't a ban page.
Given the popularity of Cloudflare, this is could become a major challenge for web scrapers in 2025.
Weaponizing JavaScript
Increasingly, websites are using JavaScript to make it more difficult to scrape their website. This is often done in conjunction with an anti-bot system.
The prime example of this, was in January 2025 when Google started to use JavaScript to block scrapers from accessing their search results.
Overnight, thousands of scrapers from companies that relied on scraping Google search results (SEMRush, Ahrefs, etc.) were confronted with this message blocking their access to Google search results:
Requiring the use of JavaScript to access the search results doesn't block the scrapers as we can still access the pages with headless browsers, but it does make it significantly more expensive and slower to scrape.
Moving Data Behind Logins
In 2023, X (formerly Twitter) followed in the footsteps of LinkedIn, Instagram, and Facebook, when decided to require a login to view tweets after their website was overloaded with scrapers in the aftermath of closing free access to the Twitter API.
However in 2024, we started to see non-social media companies start to require a login to access parts of their website. For example, Amazon started to more aggressively trigger the login screen when requesting product reviews past page 5. This makes sense as it is unlikely to have a SEO impact and for real-users to go past page 5 without already being logged in.
Varying Scraping Difficulty On The Same Website
A trend that became more prevalent this year, was the scraping difficulty varying considerably on the same website.
Whereas before an anti-bot system was applied universally across the entire website, there have been more and more cases of certain page types having more or less aggressive anti-bot systems.
- High Demand Pages: Pages that are high demand by scrapers are often protected with more aggressive anti-bot systems. Example: Indeed.com has increased the protection on individual job posts, whilst leaving the job post lists at lower protection.
- Internal API Endpoints: Scraping internal API endpoints is a great way to get clean data without worrying about changing page structures, however, websites are increasingly using anti-bot systems to block scrapers from accessing these endpoints. Example: websites are making scraping GraphQL endpoints more difficult with more aggressive anti-bot systems.
- Unnatural URL Formats: Websites are using higher security settings on non-standard URL formats (e.g. /product/123456/reviews) that real-users are less likely to request in a attempt to block scrapers. Example: The chances of being blocked on Walmart.com are significantly higher if request product pages directly with their unique product ID verus the full product name formatted URL.
This means that you might need different scraping strategies and proxies to scrape different parts of the same website. Increasing the complexity of your scrapers and proxy costs.
2025 Outlook
Expect to see ever more sophisticated anti-bots being used on websites. More complicated browser, TCP, and IP fingerprinting techniques are going to require web scrapers to use:
- Higher quality proxies - increased need for residential & mobile proxies.
- Better browser headers & cookie management techniques.
- Fortified headless browsers.
- Or one of the growing number of purpose built anti-bot bypassing solutions becoming available like Bright Data Web Unlocker, Oxylabs Web Unblocker, Zyte API or Smartproxy Site Unblocker.
Need a Proxy? Then check out our Proxy Aggregator and get access to over 20 different proxy providers via a single proxy port. Or check out our Proxy Comparison Tool to compare the pricing, features and limits of every proxy provider on the market so you can find the one that best suits your needs.

The Great Proxy Shakeup: New Players, New Rules
Proxy providers continue to be the backbone of the web scraping industry. Providing the underlying infrastructure needed to scrape websites at scale, but continually needing to evolve to meet the threat of anti-bot systems.
However, recent trends and changes are having a big impact:
- Domain level proxy pricing
- Disruption of residential & mobile proxy market
- Premium anti-bot solutions
Domain-Level Proxy Pricing: Progress and Challenges
First introduced in 2023 and gaining momentum in 2024, domain-level proxy pricing aims to address a critical issue in the proxy market: pricing fairness.
Instead of applying a flat rate to all domains, this model adjusts costs based on the difficulty of scraping a specific website. In theory, this approach offers more accurate and fair pricing, reflecting the varying levels of effort required for different websites.
However, the implementation across providers has been uneven:
- Zyte API has fully embraced this model, explicitly advertising domain-specific rates and success-based pricing.
- Other providers, such as ScrapeAPI, ScrapeDo, and Web Unlocker by Bright Data, have adopted domain-level pricing elements without full transparency, leaving users to discover costs through trial and error.
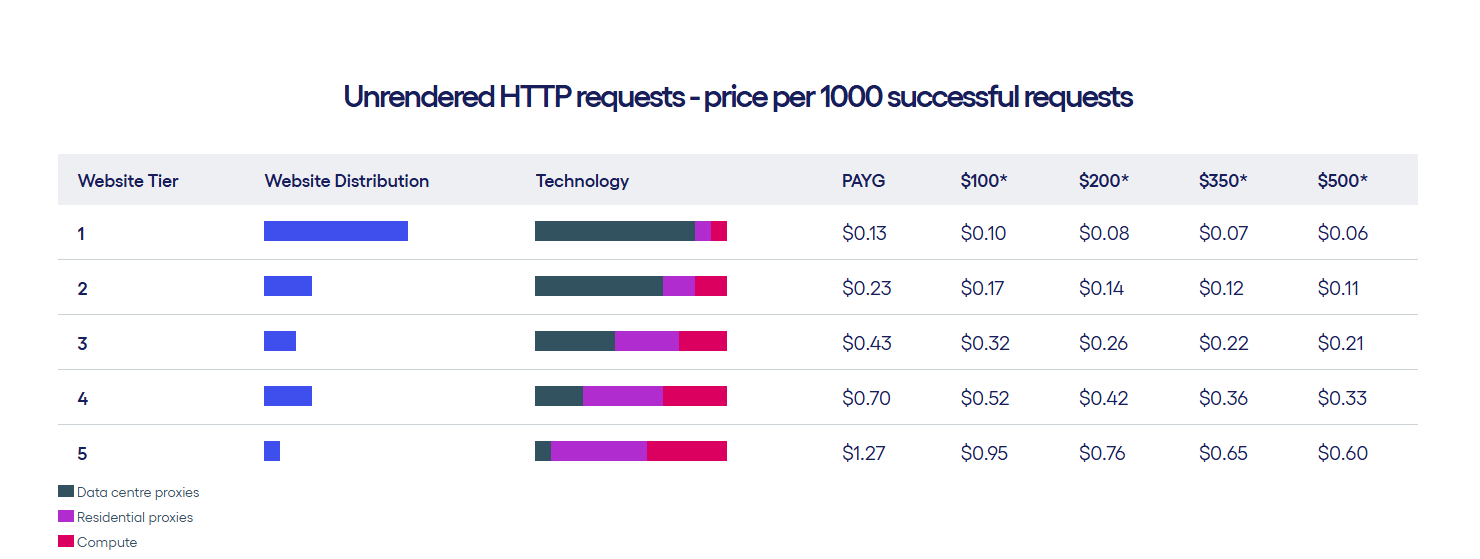
However, the introduction of domain-level pricing has led to a number of challenges:
- Opaque Pricing: Many providers do not clearly disclose domain-specific costs with user friendly tools, making it harder to predict and budget for scraping projects.
- Inconsistent Pricing Across Providers: The cost of scraping a site like Amazon can vary significantly between providers, with little-to-no correlation to success rates or overall performance.
- Limited Savings on Easier Domains: While challenging domains see price increases, easier domains rarely experience meaningful cost reductions, leaving users with higher overall expenses.
A price vs. success rate comparison for a single domain highlights this inconsistency.
Amazon.com Proxy API Performance Example
For example, a look at a price versus performance breakdown of 10 different Proxy API providers for Amazon.com highlights the price vs. performance inconsistency.
Although the advertised base price for most for 7 of the proxy providers was in the $100 per million range (the 3 other were premium unlockers +$1000), 4 of them were in fact charging 0.75 to 6x multiples for Amazon.com requests.
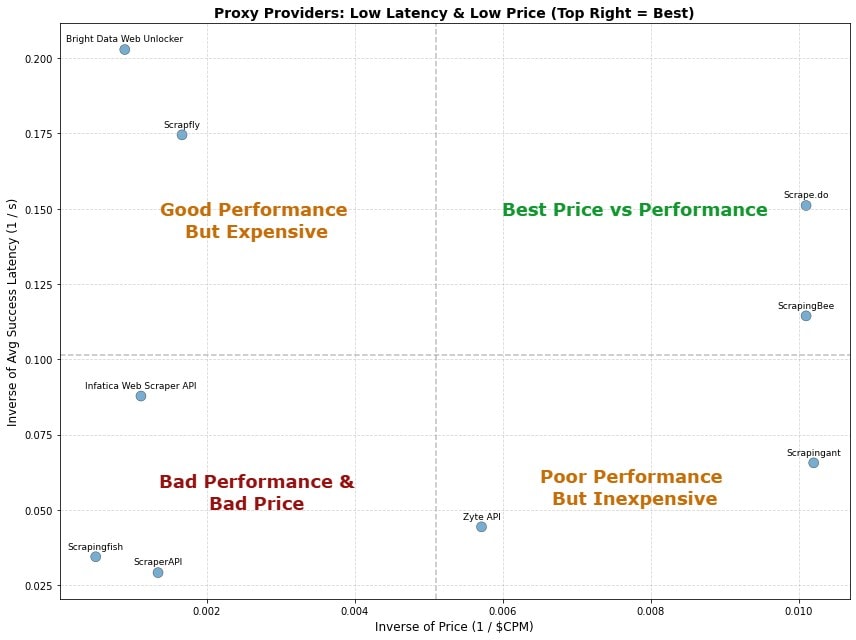
Here we are using a metric called Average Success Latency to measure the average time it takes for a request to return a successful response. This is one of the best indicators of the quality of the proxy provider as it takes into account both the success rate and the latency to get a successful response. Using this metric you can normalize performance data and find the proxy provider that gives you the best throughput through a single concurrent thread.
As you can see from the data, proxy prices are varying from $98 to $2,000 per million requests (assumed scraping 1M pages) with little correlation between performance (success rate & avg. latency to get successful response) and cost.
| Proxy Provider | Base CPM | Multiplier | CPM | Detail | Success Rate | Avg Success Latency |
|---|---|---|---|---|---|---|
| Scrapingant | $98 | 1.00 | $98 | Base Price | 70% | 15.24s |
| ScrapingBee | $99 | 1.00 | $99 | Base Price | 100% | 8.74s |
| Scrape.do | $99 | 1.00 | $99 | Base Price | 100% | 6.62s |
| Zyte API | $100 | 1.75 | $175 | Tier 2 Domain | 100% | 22.54s |
| Scrapfly | $100 | 6.00 | $600 | Averaging 6X Multiplier | 100% | 5.73s |
| ScraperAPI | $149 | 5.00 | $745 | E-commerce Multiplier | 100% | 34.29s |
| Infatica Web Scraper API | $90 | 10.00 | $900 | E-commerce Multiplier | 90% | 11.39s |
| Bright Data Web Unlocker | $1120 | 1.00 | $1120 | Base Price | 100% | 4.93s |
| Smartproxy Site Unlocker | $1400 | 1.00 | $1400 | Base Price | 0% | 0.00s |
| Scrapingfish | $2000 | 1.00 | $2000 | Base Price | 100% | 29.04s |
Whilst, Scrapfly and Bright Data Web Unlocker are giving ~20% better performance than Scrape.do, they are 6X and 11X more expensive respectively.
We also see that some of the most expensive proxy providers are actually giving worse performance than the cheaper providers i.e. Scrapingfish, Smartproxy and ScraperAPI in this test.
This is a pattern across the entire web scraping industry, where there is often a lack of correlation between price and performance.
At ScrapeOps, we developed the Proxy API Aggregator and Residential Proxy Aggregator to simplify this process. By aggregating multiple proxy providers into a single API, we handle the complexity of finding the best proxy for your specific use case. This ensures you always get the optimal performance at the lowest cost, without the headache of manually testing and comparing providers.
Disruption of Residential & Mobile Proxy Market
Although 90% of websites can still be scraped with well optimized scrapers using datacenter proxies, as a consequence of the increased use of sophisticated anti-bot systems to protect websites there is an increasing need for residential and mobile proxies.
This has led to a huge growth in the number of residential & mobile proxy providers, leading to 60-75% decreases in the cost of residential proxies over the last 5 years.
The big residential proxy providers have cut prices by 20-50% over the last year alone.
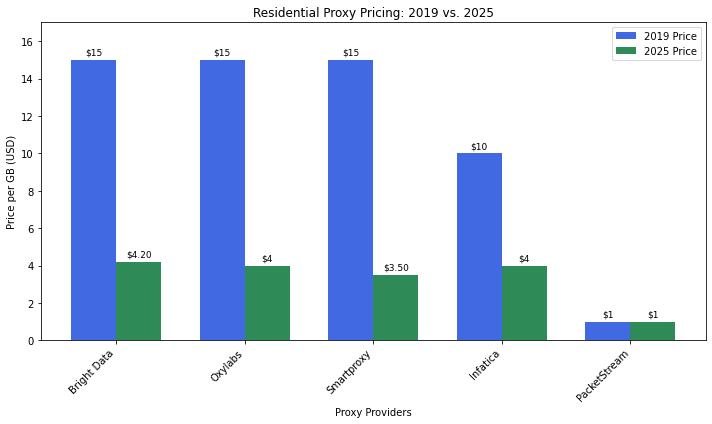
There is now an increasing number of smaller proxy providers building out their own residential and mobile proxy networks by offering VPN, Proxy SDKs for Apps & Chrome Extensions, paid bandwidth services and through direct deals with ISPs.
These proxy providers are offering much lower prices along with pay-as-you-go plans, very low monthly commitment plans and no bandwidth expiry dates.
| Proxy Provider | Pricing Model | Starting Price Per GB |
|---|---|---|
| DataImpulse | Pay-As-You-Go | $1/GB |
| PacketStream | Pay-As-You-Go | $1/GB |
| WTFProxy | Pay-As-You-Go | $3/GB |
| Asocks | Pay-As-You-Go | $3/GB |
These newer proxy providers have largely built their proxy networks using mobile device SDKs and direct ISP deals.
Forcing larger proxy companies like Bright Data, Oxylabs, and Smartproxy to cut prices and start offering smaller/pay-as-you-go plans that are more flexible to smaller use cases.
Premium Anti-Bot Solutions
With the increasing use of sophisticated anti-bot systems to protect websites, there is a well established trend of proxy providers offering purpose built anti-bot bypassing solutions to help developers scrape the most difficult websites.
As of 2025, nearly every major proxy provider now offers some form of premium anti-bot solution to their users.
| Proxy Provider | Anti-Bot Solution | Pricing Method |
|---|---|---|
| BrightData | Web Unlocker | Pay per successful request |
| Oxylabs | Web Unblocker | Pay per GB |
| Smartproxy | Site Unblocker | Pay per GB |
| Zyte | Zyte API | Pay per successful request |
| ScraperAPI | Ultra Premium | Pay per successful request |
| ScrapingBee | Stealth Proxy | Pay per successful request |
| Scrapfly | Anti-Scraping Protection | Pay per successful request |
These anti-bot solutions do work, but they can become extremely expensive when used at scale. With prices ranging from $1,000 to $5,000 to scrape 1M pages per month.
As part of the ScrapeOps Proxy Aggregator we aggregate these anti-bot bypassing solutions together and find the best performing and cheapest option for your use case.
For example, a user can activate the Cloudflare Bypass by simply adding bypass=cloudflare_level_1 to your API request, and the ScrapeOps proxy will use the best & cheapest Cloudflare bypass available for your target domain.
import requests
response = requests.get(
url='https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'http://example.com/', ## Cloudflare protected website
'bypass': 'cloudflare_level_1',
},
)
print('Body: ', response.content)
Here is a list of available bypasses:
| Bypass | Description |
|---|---|
cloudflare_level_1 | Use to bypass Cloudflare protected sites with low security settings. |
cloudflare_level_2 | Use to bypass Cloudflare protected sites with medium security settings. |
cloudflare_level_3 | Use to bypass Cloudflare protected sites with high security settings. |
incapsula | Use to bypass Incapsula protected sites. |
perimeterx | Use to bypass PerimeterX protected sites. |
datadome | Use to bypass DataDome protected sites. |
2025 Outlook
Expect to see these trends to continue with more and more proxy providers launching premium anti-bot solutions and more competition in the proxy provider market further driving down prices and improving the product offerings.
Need a Proxy? Then check out our Proxy Aggregator and get access to over 20 different proxy providers via a single proxy port. Or check out our Proxy Comparison Tool to compare the pricing, features and limits of every proxy provider on the market so you can find the one that best suits your needs.

Web Scraping's Legal Battleground 2025
The legal landscape for web scraping saw landmark developments in 2024, with several pivotal cases reshaping the industry. As we step into 2025, the rules for what is legal and ethical are becoming clearer—but also stricter.
Key Legal Cases and Developments��
Meta vs. Bright Data
A California court ruled that scraping publicly available data from Facebook and Instagram, without logging in, does not violate Meta's terms of service. This verdict reinforced the legality of public data scraping, provided it doesn't involve bypassing anti-bot measures or violating the Computer Fraud and Abuse Act (CFAA). However, the ruling also underscored Meta's right to protect its platforms through anti-bot technology. This case sets an important precedent but leaves questions about bypassing anti-bot measures unresolved.
Generative AI Lawsuits
Generative AI remained a flashpoint in 2024, with lawsuits like Getty Images vs. Stability AI and Authors Guild vs. OpenAI challenging the use of scraped copyrighted data for AI training. In early rulings, courts hinted that scraping copyrighted data for training may require explicit permissions or licensing. These cases are set to conclude in 2025, and their outcomes could redefine how training datasets are sourced and used.
X Corp's Legal Offensive
X Corp (formerly Twitter) continued its aggressive crackdown on web scrapers, suing Bright Data, John Doe entities, and watchdog groups. Courts validated X's right to enforce terms of service for scraping login-restricted data but left room for public data scraping under specific conditions. X Corp's ongoing legal battles signal a rising trend of companies using litigation to deter scrapers.
Other Significant Cases
- Ryanair vs. Booking Holdings: European courts sided with Ryanair, upholding its T&Cs and barring unauthorized scraping of its flight data. This ruling highlights the growing power of contractual terms in Europe.
- Air Canada vs. LocalHost: Air Canada pursued damages for scraping its fare data, raising further questions about contractual violations and CFAA applicability. A decision is expected in 2025.
New Laws and Regulatory Developments
- EU AI Act: Slated for full implementation in 2025, this law imposes stringent requirements on data used for AI model training, with potential fines for companies that scrape copyrighted or personal data.
- U.S. Copyright Office Guidance: A proposed framework for AI training data suggests stricter limits on the use of scraped datasets containing copyrighted content, with public commentary and rulings expected throughout 2025.
2025 Outlook
The legal framework for web scraping is sharpening its edges, and businesses that rely on scraping must adapt or risk severe consequences. While scraping publicly available data remains largely permissible, here's what developers and companies should prepare for in 2025:
-
AI Training Under the Microscope: Regulations like the EU's AI Act and U.S. copyright rulings could impose heavy penalties for scraping copyrighted or personal data to train models. If your use case involves training generative AI, audit your datasets now to avoid legal headaches later.
-
No Tolerance for Login-Based Scraping: Courts are increasingly siding with websites enforcing anti-scraping clauses in their terms of service, especially for content behind logins. Avoid scraping any content that requires authentication without explicit permission.
-
Privacy-Centric Compliance: Regulations like GDPR and CCPA are not just compliance checkboxes—they're becoming enforcement priorities. Scrapers must now anonymize data pipelines and explicitly avoid scraping identifiable user data without consent.
-
Opportunities in Ethical Scraping: As businesses face growing challenges extracting data, solutions that focus on ethical and compliant scraping (e.g., scraping with API partnerships or licensed data) could see significant growth. Companies that innovate here will thrive while others grapple with regulatory barriers.
Scraping is becoming a higher-stakes game, and those who innovate responsibly will thrive in the evolving landscape.

Web Scraping Arsenal: Top Tools & Libraries for 2025
The web scraping landscape in 2025 is defined by a mix of enduring favorites and emerging innovations. While legacy tools like BeautifulSoup, Scrapy, and Puppeteer remain essential, new libraries and frameworks are pushing the boundaries of what's possible, particularly in AI-driven parsing and headless browser automation.
Emerging Libraries of 2025
While core challenges of building web scrapers big and small have been solved by popular web scraping stacks like Scrapy, Requests + BeautifulSoup, and Playwright, the majority of the new libraries are focused on AI integrations and anti-bot bypassing extensions:
-
Firecrawl: A hybrid AI-powered scraping library designed to parse dynamic content while generating reusable scraping code.
Use Case: Developers looking to leverage LLMs for parsing while minimizing manual coding. -
ScrapeGraphAI: This AI-first library simplifies large-scale data extraction using semantic models for precise data structuring.
Use Case: Projects involving complex relationships between scraped elements, such as e-commerce recommendation engines. -
Scrapy Impersonate: A library that allows you to impersonate a browser and scrape websites that require browser automation.
Use Case: Bypassing anti-bot systems that block scrapers based on TLS and JA3 fingerprinting. -
Spider Creator: A library that allows you to create Playwright based spiders with with minimal manual coding using LLMs and Browser Use. Use Case: Creating scrapers quicker and easier than ever before.
Python
Python continues to lead the pack for web scraping, offering versatility and a rich ecosystem of libraries.
-
Scrapy: Scrapy remains the go-to for large-scale scraping projects. In 2025, it added more robust support for JavaScript-heavy pages and native integrations for CAPTCHA solving, solidifying its role in handling complex scraping tasks.
Use Case: Best for scraping at scale, such as e-commerce product catalogs or job listings. -
BeautifulSoup: A staple for beginners, BeautifulSoup remains ideal for small-scale projects due to its simplicity. Its latest updates improved support for modern HTML5 structures, keeping it relevant for quick tasks.
Use Case: Parsing static HTML pages for data extraction in smaller projects. -
Selectolax: Gaining popularity as a faster alternative to BeautifulSoup, Selectolax is now the choice for performance-critical tasks. It leverages an ultra-lightweight HTML5 parser, ideal for scraping at speed.
Use Case: High-speed scraping where efficiency is critical, such as time-sensitive price monitoring.
Node.js
JavaScript's dominance in the browser ecosystem makes Node.js a strong contender for web scraping, especially for dynamic content.
-
Playwright: This headless browser library leads the way in cross-browser compatibility and dynamic content scraping. Its latest updates enhance CAPTCHA handling, mobile emulation, and debugging capabilities.
Use Case: Ideal for scraping dynamic, JavaScript-heavy websites or SPAs like React and Vue.js. -
Cheerio: A lightweight DOM manipulation library, Cheerio is perfect for smaller-scale projects that don't require browser automation.
Use Case: Quick scraping tasks involving HTML parsing, such as blog posts or simple listings. -
Apify SDK: Built for scalability, Apify SDK offers seamless queue management, proxy rotation, and AI-powered extraction features.
Use Case: Advanced workflows requiring queueing, scaling, and hybrid AI integrations.
Other Languages
While Python and Node.js dominate, other languages have standout libraries for web scraping:
Golang
- Colly: This lightweight and fast framework continues to be the top choice for Go developers. It supports concurrency out of the box and excels in speed-critical scraping.
Use Case: Large-scale scraping with high-speed requirements, such as monitoring stock prices or crypto trends.
PHP
- Guzzle: Guzzle remains a reliable HTTP client for developers in the PHP ecosystem, with recent updates improving asynchronous request handling.
Use Case: HTTP requests and interacting with APIs in PHP-based applications.
Ruby
- Nokogiri: This robust HTML and XML parser continues to thrive, offering excellent performance for Ruby-based scraping projects.
Use Case: Data extraction from structured content, such as news articles or product pages.
2025 Outlook
The tools shaping web scraping in 2025 reflect the growing need for both simplicity and sophistication. Key trends include:
- AI-Enhanced Libraries: Hybrid tools like Firecrawl and ScrapeGraphAI are redefining how developers approach scraping, allowing for reduced manual effort and smarter data extraction.
- Stealth and Browser Automation Tools: Libraries like Playwright and Puppeteer continue to innovate, ensuring developers stay ahead in the arms race against anti-bot measures.
- Scaling Solutions: Libraries emphasizing scalability, like Apify SDK and ScrapeGoat, are enabling efficient and cost-effective large-scale scraping.
Whether you're a beginner or an enterprise developer, 2025 offers more options than ever to tackle the challenges of modern web scraping, from dynamic content to anti-bot defenses.
2025 Is Looking Good!
In 2025, web scraping continues to navigate through a landscape marked by advanced anti-bot measures and evolving legal considerations. This scenario has been a consistent feature over recent years, yet each challenge has contributed to the strengthening and advancement of the field.
The web scraping domain has witnessed substantial growth, characterized by an expanding array of tools, libraries, and solutions designed to streamline the web scraping process. This ongoing development suggests a promising outlook for the future of web scraping.
Need a Proxy? Then check out our Proxy Aggregator and get access to over 20 different proxy providers via a single proxy port. Or check out our Proxy Comparison Tool to compare the pricing, features and limits of every proxy provider on the market so you can find the one that best suits your needs.