
Disable Images Loading In Python Selenium
Selenium is a powerful browser automation library that allows you to build bots and scrapers that can load and interact with web pages in the browser. As a result, Selenium is very popular amongst the Python web scraping community.
In this guide for The Python Selenium Web Scraping Playbook, we will look at how to disable Python Selenium from loading images when opening a page.
Unless you actually need to view the page as a real user would or take screenshots of a page then disabling image loading is a great way to speed up your scrapers and reduce bandwidth usage. Saving you both time and money when scraping at scale.
There are two common ways of disabling image loading when using Python Selenium so we will walk through how to use both approaches:
- Disable Selenium Image Loading Using Blink Settings
- Disable Selenium Image Loading Using Experimental Options
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Disable Selenium Image Loading Using Blink Settings
The most common way to disable image loading in Python Selenium is to add the blink-settings=imagesEnabled=false arguement to your webdriver options when configuring the webdriver:
from selenium import webdriver
## Disable Image Loading
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--blink-settings=imagesEnabled=false')
## Add Options to Webdriver
chrome = webdriver.Chrome(chrome_options=chrome_options)
## Make Request
chrome.get("https://www.chocolate.co.uk/collections/all")
Now when you run the script Selenium will load Chocolate.co.uk without loading the images.
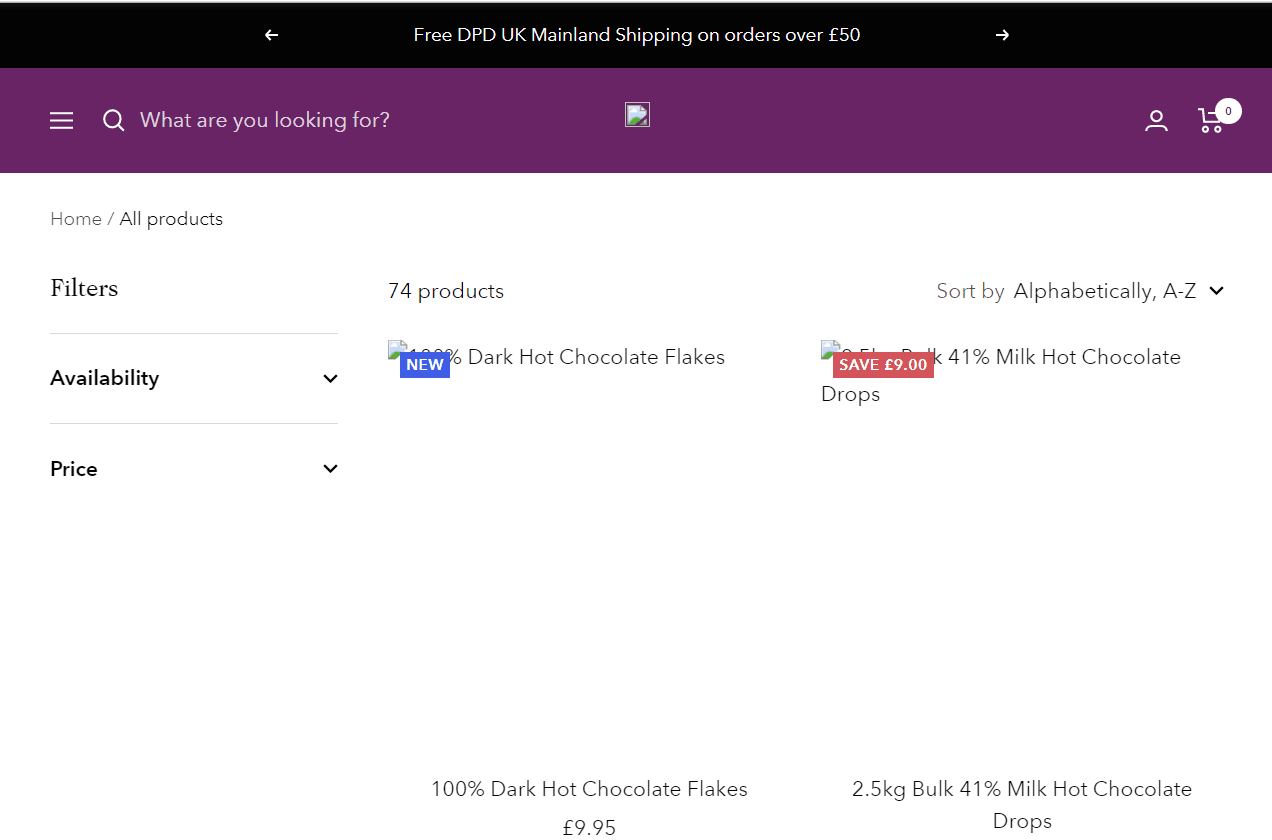
Disable Selenium Image Loading Using Experimental Options
The other approach to disabling image loading is using experimental options.
Here we will define a experimental option using add_experimental_option and adding our perferences "prefs", {"profile.managed_default_content_settings.images": 2}:
from selenium import webdriver
## Disable Image Loading
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option(
"prefs", {"profile.managed_default_content_settings.images": 2}
)
## Add Options to Webdriver
chrome = webdriver.Chrome(chrome_options=chrome_options)
## Make Request
chrome.get("https://www.chocolate.co.uk/collections/all")
Again, now when you run the script Selenium will load Chocolate.co.uk without loading the images.
Both option for disabling image loading in Selenium should work, however, if it isn't working then you can try using the other option or both options at the same time:
from selenium import webdriver
## Disable Image Loading
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--blink-settings=imagesEnabled=false')
chrome_options.add_experimental_option(
"prefs", {"profile.managed_default_content_settings.images": 2}
)
## Add Options to Webdriver
chrome = webdriver.Chrome(chrome_options=chrome_options)
## Make Request
chrome.get("https://quotes.toscrape.com/")
More Web Scraping Tutorials
So that's how you can use both authenticated and unauthenticated proxies with Selenium to scrape websites without getting blocked.
If you would like to learn more about Web Scraping with Selenium, then be sure to check out The Selenium Web Scraping Playbook.
Or check out one of our more in-depth guides: