
Fix BeautifulSoup Returns Empty List or Value
In this guide for The Python Web Scraping Playbook, we will look at how to fix your code when Python's popular BeautifulSoup library returns an empty list or value.
BeautifulSoup will return an empty list or value when it can't find any elements that match your query.
There are a couple reasons for this which we will explain in detail:
- Step #1: Check If Response Contains Data
- Reason #1: Dynamic Websites
- Reason #2: Georestricted Content
- Reason #3: Requests Are Being Blocked
- Step #2: Check BeautifulSoup Selectors
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Step #1: Check If Response Contains Data
The first thing you should do if your .findall() is returning a empty list, or your .find() is returning a empty value is to double check your HTML file actually contains the data/selectors you are looking for.
Oftentimes the issue is that the data you are trying to parse isn't actually in the HTML file.
This can be for a number of reasons:
- Dynamic Websites: The page needs to be JS rendered for it to return all the data.
- Georestricted Content: The website returns different data/layouts or no data at all depending on where the geolocation of the request.
- Ban Pages: The website returned a ban page or CAPTCHA page as a successful 200 response.
To check if this is the problem, you should either:
- Open your HTML file in a browser and see if the page contains the data you want.
- Open your HTML file and do a simple text search for a piece of text you know should be contained in the HTML response.
If the text is not there, then you know that you have one of the 3 issues listed above.
We will look at how to deal with each of these below.
Reason #1: Dynamic Websites
A lot of developers use modern Javascript frameworks like React.js, Angular.js, Vue.js, etc. to build their websites.
Unless they configure their websites to be static or server-side render their content, then oftentimes the data you want won't be returned in the initial HTTP request you make to the website.
To see the HTML page the same way as you see it in your browser, then you need to use a headless browser to simulate a real request with a browser and load all the data into the page before returning the complete HTML response.
To solve this you have a couple of solutions:
Solution 1: Use A Headless Browser
The first option is to use a headless browser like Selenium, Splash, Puppeteer, or Playwright to fetch the fully rendered HTML response before passing it to BeautifulSoup.
From there all the data will be loaded into the page so your selectors should work.
Solution 2: Use A Proxy With Built-In JS Rendering
A lot of smart proxies give you the ability to make your request with a headless browser instead of a normal HTTP request.
If you are already using a HTTP client like Python Requests or Python HTTPX to fetch the HTML response from a website and don't want to reimplement your scraper with Python Selenium or Pyppeteer, then using a smart proxy with the ability to enable JS rendering is a good option.
Here is an example of how you would use the ScrapeOps Proxy Aggregator as it integrates over 20 proxy providers into the same proxy API, and finds the best/cheapest proxy provider for your target domains.
You can activate ScrapeOps' Headless Browser by simply adding render_js=True to your API request, and the ScrapeOps proxy will use a headless browser to make the request.
import requests
response = requests.get(
url='https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'https://quotes.toscrape.com/js',
'render_js': True,
},
timeout=120,
)
soup = BeautifulSoup(response.content, 'html.parser')
## H1 Element
print(soup.h1)
## --> <h1><a href="/" style="text-decoration: none">Quotes to Scrape</a></h1>
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
Solution 3: Parse Hidden JSON
A lot of websites using Javascript frameworks like React.js, Angular.js, Vue.js, will actually return all the data in the HTML response.
However, it is often hidden in a JSON blob within a <script> tag in the inital HTML response.
Take Walmart.com for example. The product data is contained within the <script id="__NEXT_DATA__" type="application/json"> tag in the HTML response.
<script id="__NEXT_DATA__" type="application/json" nonce="">"{
...DATA...
}"
</script>
We don't need to build CSS/XPath selectors for each field, just take the data we want from the JSON response.
import json
import requests
from bs4 import BeautifulSoup
url = "https://www.walmart.com/ip/2021-Apple-iPad-Mini-Wi-Fi-64GB-Purple-6th-Generation/996045822"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
if script_tag is not None:
json_blob = json.loads(script_tag.get_text())
product_data = json_blob["props"]["pageProps"]["initialData"]["data"]["product"]
An extra bonus from this is that the data is very clean so we have to little to no data cleaning.
Reason #2: Georestricted Content
Another reason why your HTML file mightn't contain the data or selectors that you see in when you open the page in your browser is because some websites georistrict the content based on the location of the request.
So if you are using a Russian proxy to fetch the HTML response from the website, but that website only returns the correct data when the request is coming from the United States then your HTML file mightn't actually contain the data.
To fix this, you need to make sure your request is being sent from a proxy IP that is located in the correct location.
With the ScrapeOps Proxy Aggregator you can geotraget your requests with its geotargeting functionality.
For example, you could make sure all your requests are using US IP addresses by adding country=us to your request.
import requests
response = requests.get(
url='https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'https://quotes.toscrape.com/',
'country': 'us',
},
timeout=120,
)
soup = BeautifulSoup(response.content, 'html.parser')
## H1 Element
print(soup.h1)
## --> <h1><a href="/" style="text-decoration: none">Quotes to Scrape</a></h1>
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
Reason #3: Requests Are Being Blocked
Another reason why you might be getting an empty list from BeautifulSoup is because the website is blocking your requests and is returning a ban/CAPTCHA page as a successful 200 response.
Here is an example ban page that Walmart returns as a successful response, when they are blocking your requests.
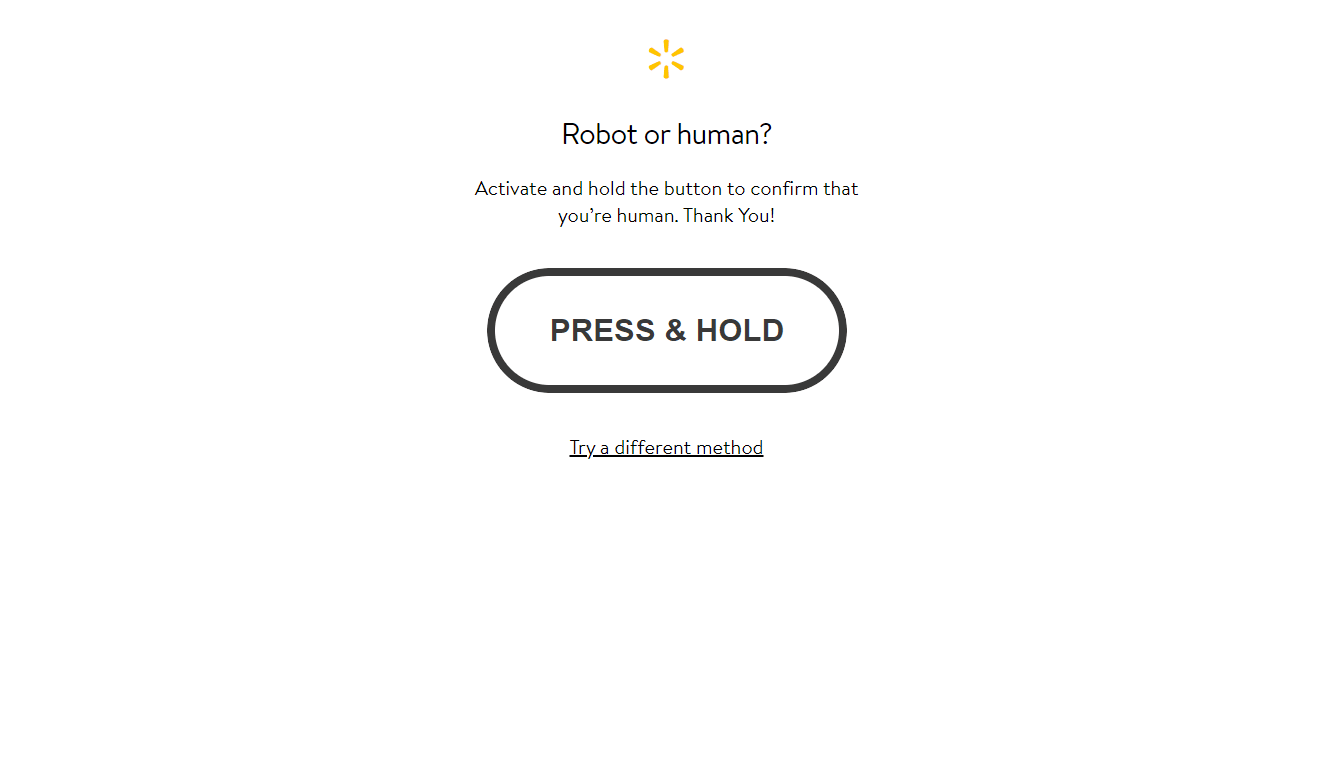
If this is happening to you then you need to optimize your scrapers to not be detected as a scraper.
We have written about how to do this here:
- Guide to Web Scraping Without Getting Blocked
- Web Scraping Guide: Headers & User-Agents Optimization Checklist
However, if you don't want to implement all this anti-bot bypassing logic yourself the easier option is to use a smart proxy solution like ScrapeOps Proxy Aggregator.
The ScrapeOps Proxy Aggregator is a smart proxy that handles everything for you:
- Proxy rotation & selection
- Rotating user-agents & browser headers
- Ban detection & CAPTCHA bypassing
- Country IP geotargeting
- Javascript rendering with headless browsers
To use the ScrapeOps Proxy Aggregator, we just need to send the URL we want to scrape to the Proxy API instead of making the request directly ourselves. We can do this with a simple wrapper function:
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
def scrapeops_url(url):
payload = {'api_key': SCRAPEOPS_API_KEY, 'url': url}
proxy_url = 'https://proxy.scrapeops.io/v1/?' + urlencode(payload)
return proxy_url
## Send URL To ScrapeOps Instead of Directly to Target Website
response = requests.get(scrapeops_url('https://quotes.toscrape.com/'))
You can get a API key with 1,000 free API credits by signing up here.
Step #2: Check BeautifulSoup Selectors
If your have checked your HTML file and confirmed that the data/selectors you want are in the HTML file, then the reason your .findall() is returning a empty list, or your .find() is returning a empty value is because your selectors are incorrect.
Good approaches to debug this are to save the HTML response as a file, and then iterate on your selectors in your code (better yet a Jupyter Notebook).
Or if you are using CSS selectors via BeautifulSoup's .select() method then test your CSS selectors in your browsers Developer Tools.
It is generally seen to be better practice and more efficent to use BeautifulSoup's CSS selector functionality via the .select() method, than to use the .findall() or .find() methods.
If you use CSS selectors it is much easier to test and debug selectors quickly as you can open the page in your browser and run the selectors in the Console Tab using Javascripts .querySelectorAll() method which allows you to use CSS selectors.
document.querySelectorAll('h1')
There isn't a magic bullet to solving this, as it is specific to your particular website and data you want to extract. So you will just have to iterate through various BeautifulSoup selectors until you find one that works consistently.
More Web Scraping Tutorials
So that's how to fix your code when Python's popular BeautifulSoup library returns an empty list or value.
If you would like to learn more about how to use BeautifulSoup then check out our other BeautifulSoup guides:
- BeautifulSoup Guide: Scraping HTML Pages With Python
- How To Install BeautifulSoup
- How To Use BeautifulSoup's find() Method
- How To Use BeautifulSoup's find_all() Method
Or if you would like to learn more about Web Scraping, then be sure to check out The Python Web Scraping Playbook.
Or check out one of our more in-depth guides: