
freeCodeCamp Scrapy Beginners Course Part 13 - Conclusion & Next Steps
In Part 13 of the Scrapy Beginner Course, we summarize what we learned during this course and outline some of the next steps you can take to advance your knowledge of Scrapy even further.
We will walk through:
- Course Wrapup
- Become A Expert Scrapy Developer
- Scraping Dynamic Websites
- Scraping Behind Logins
- Custom Middlewares & Extensions
- Scaling Scrapy Spiders With Worker Architectures
If you prefer video tutorials, then check out the video version of this course on the freeCodeCamp channel here.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Course Wrapup
Over the course of this 12-part Scrapy developer tutorial series, we covered all the basics you need to become a Scrapy developer:
- Part 1: Course & Scrapy Overview
- Part 2: Setting Up Environment & Scrapy
- Part 3: Creating Scrapy Project
- Part 4: First Scrapy Spider
- Part 5: Crawling With Scrapy
- Part 6: Cleaning Data With Item Pipelines
- Part 7: Storing Data In CSVs & Databases
- Part 8: Faking Scrapy Headers & User-Agents
- Part 9: Using Proxies With Scrapy Spiders
- Part 10: Deploying & Scheduling Spiders With Scrapyd
- Part 11: Deploying & Scheduling Spiders With ScrapeOps
- Part 12: Deploying & Scheduling Spiders With Scrapy Cloud
We built an end-to-end Scrapy project that scrapes all the books from BooksToScrape.com, cleans the data and stores the extracted data in various file types or databases.
Then, we also looked at why you need to optimize your headers and use proxies when web scraping to avoid your scrapers from getting blocked by a website's anti-bot systems.
Finally, we looked at how you can deploy bookscraper to the cloud and schedule it to run periodically with Scrapyd, ScrapeOps SSH Server Integration or Scrapy Cloud.
Become A Expert Scrapy Developer
What we covered in this 12-part Scrapy developer tutorial series are the basics you need to use Scrapy in production.
However, there are a lot of other techniques that we didn't cover that you might need at a future point depending on the type of website you are trying to scrape and the scale of your web scraping.
To become an expert Scrapy developer, then you will need to become aware of and master these topics as well.
Here are some of the most important that you will encounter:
Scraping Dynamic Websites
Today, a lot of developers use modern Javascript frameworks like React.js, Angular.js, Vue.js, etc. to build their websites.
Unless they configure their websites to be static or server-side render their content, then oftentimes the data you want won't be returned in the initial HTTP request you make to the website.
This creates a problem for Scrapy as your spider won't be able to access the data on the page you want to scrape.
In cases like these, you will need to either:
- Use a Scrapy headless browser integration like Scrapy-Puppeteer or Scrapy Selenium to scrape the data.
- Find and scrape a hidden API endpoint if one is available.
- Find and scrape a hidden JSON blob in the HTML response if one is available.
Scraping Behind Logins
In some use cases, you might need to log into the website to access and scrape the data you want to scrape.
This can be a challenging task depending on how the websit'es login system works and creates some unique challenges remaining undetected by the website's anti-bot detection systems.
If you would like to learn more about this then check out this video and guide.
Custom Middlewares & Extensions
Scrapy is a very powerful and versatile web scraping framework out of the box, but where it really shines is its ability to be easily extended and customized for your specific use case using middlewares & extensions.
The Scrapy community has published hundreds of open source middlewares & extensions that you can easily use in your scrapers to give your spiders enhanced functionality.
However, a key skill for any developer looking to become an advanced Scrapy developer is learning how to build your own custom middlewares & extensions.
Scaling Scrapy Spiders With Worker Architectures
If your use case requires you to scrape millions of pages every day, then oftentimes using a single Scrapy spider running on a single server won't cut it.
In cases like these, you will need to look at more advanced web scraping architectures comprising multiple workers all scraping the same website at the same time.
There are a number of ways to achieve this but one of the best performing is to use Scrapy-Redis a powerful open-source Scrapy extension that enables you to run distributed crawls/scrapes across multiple servers and scale up your data processing pipelines.
Scrapy-Redis is very useful if you need to split a large scrape over multiple machines if a single spider running on one machine wouldn't be able to handle the entire scrape.
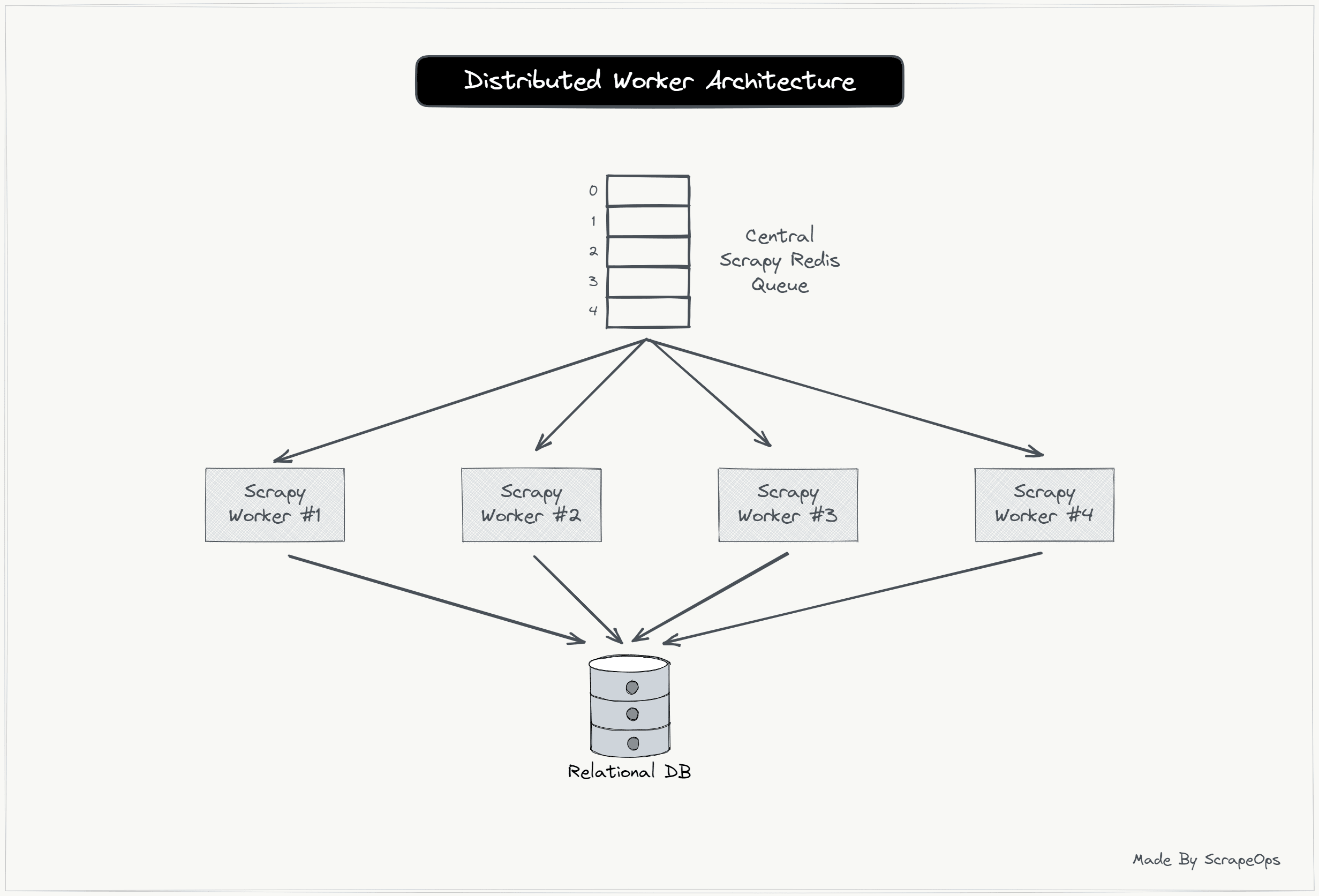
For more information on Scrapy Redis, then check out this guide and video: