
NodeJS Puppeteer: Logging Into Websites
One of the most common tasks that Puppeteer can be used for is logging into websites. This can be useful for various purposes, such as scraping data from websites that require authentication, automating tasks, and web testing. In this guide, we will dive into automating website logins with Node.js Puppeteer, including handling common challenges such as CAPTCHAs, anti-bot mechanisms, and dynamic elements.
- Login to Simple Website With Puppeteer
- Multi-Stage Logins With Puppeteer
- Bypassing Anti-bot Protection With Puppeteer
- Solving CAPTCHAs on Login With Puppeteer
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Login to Simple Website With Puppeteer
Let’s look at how to log in to websites that only ask for a username/email and password. We’ll use the toscrape website.
Go to the website and you will see the login on the right side. The login text is inside an a tag, and the parent of the a tag has the class col-md-4. To click on this Login link, pass the .col-md-4 a CSS selector to the page.click() method.

After clicking on the login link, the login page opens, which asks for the username and password.
To fill in the username, use id="username" attribute.
For a password, use the id="password".
Great, you’ve passed the username and password. Now it's time to log in to the website.
To click on the login button, use class btn btn-primary. Simply pass the class name to the page.click() method.

Awesome! You’ve logged in to the website, and now you can scrape the data or do whatever you want.
Here’s the complete code:
import puppeteer from "puppeteer";
// Define an async function for logging into a website.
const logging = async () => {
// Launch a headless browser instance.
const browser = await puppeteer.launch({
headless: false,
});
// Create a new page in the browser.
const page = await browser.newPage();
// Navigate to the website you want to log into.
await page.goto("http://quotes.toscrape.com/");
// Wait for an element with the class "col-md-4" to appear on the page.
await page.waitForSelector(".col-md-4");
// Click on a link within the "col-md-4" element.
await page.click(".col-md-4 a");
// Wait for an element with the id "username" to appear on the page.
await page.waitForSelector("#username");
// Type a username into the "username" input field with a 100ms delay between key presses.
await page.type("#username", "Your_Username", { delay: 100 });
// Wait for an element with the id "password" to appear on the page.
await page.waitForSelector("#password");
// Type a password into the "password" input field with a 100ms delay between key presses.
await page.type("#password", "Your_Password", { delay: 100 });
// Click on a 'Login' button
await page.click(".btn.btn-primary");
};
// Call the logging function to execute the login process.
logging();
Here, the delay:100 parameter is used so that you can see the key presses. This introduces a delay between key presses while typing text into an input field.
Multi-Stage Logins With Puppeteer
Some websites involve multi-stage logins, which means that the entry fields for your username or email aren't displayed at the same time.
So to login into these types of websites, you must click a Next button to enter your password, and then finally submit it.
Typically, both the username and password fields are on different pages.
To enter the email ID, use the input[name=email] selector.
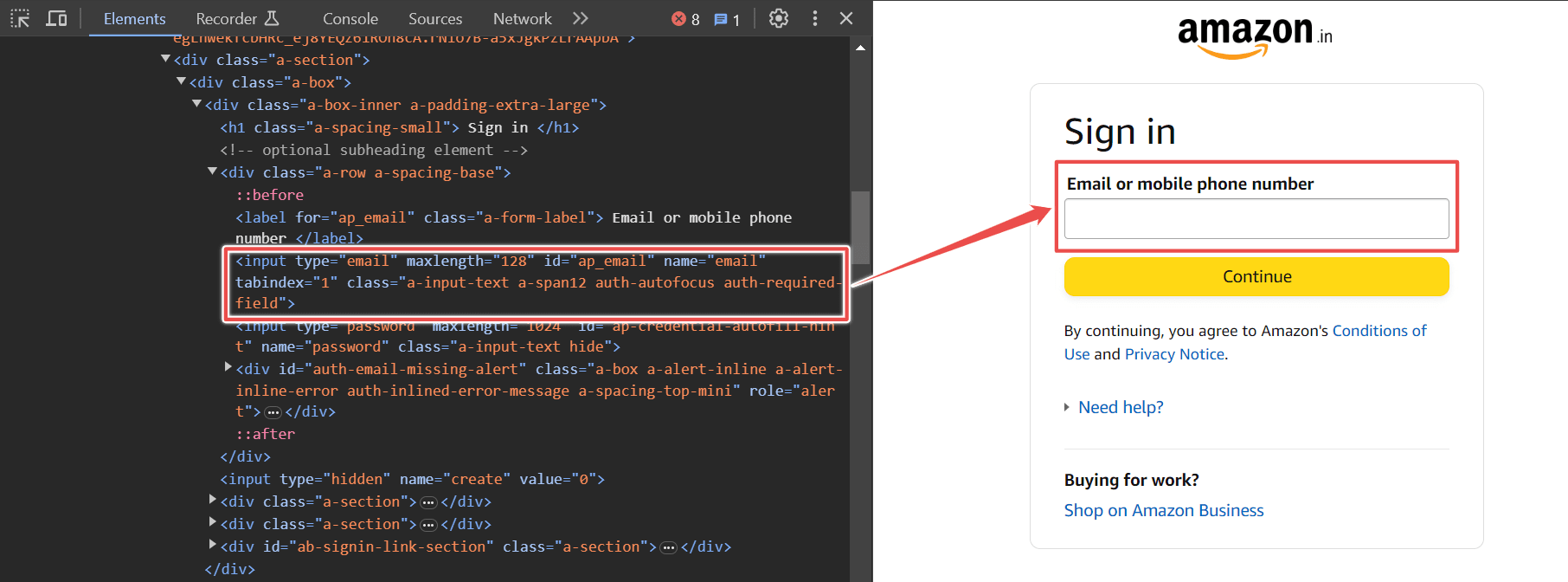
Now click on the Continue button by using the input[id=continue] selector.

You’re now on the next page. To enter the password, use the input[name=password] selector.

Finally, click on the Sign In button by using the input[id=signInSubmit] selector.

Here’s the complete code:
// Import the 'puppeteer' library
import puppeteer from "puppeteer";
// Define an asynchronous function for logging into Amazon.
const logging = async () => {
// Launch a new browser instance with a visible UI.
const browser = await puppeteer.launch({
headless: false,
});
// Create a new browser page.
const page = await browser.newPage();
// Navigate to the Amazon sign-in page.
await page.goto("https://www.amazon.com/ap/signin?openid.pape.max_auth_age=0&openid.return_to=https%3A%2F%2Fwww.amazon.com%2F%3Fref_%3Dnav_custrec_signin&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.assoc_handle=usflex&openid.mode=checkid_setup&openid.claimed_id=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0&");
// Wait for the email input field to appear on the page.
await page.waitForSelector("input[name=email]");
// Enter your email address into the email input field with a delay of 100 milliseconds between keypresses.
await page.type("input[name=email]", "Your Email", { delay: 100 });
// Click the "Continue" button to proceed to the next step.
await page.click("input[id=continue]");
// Wait for the password input field to appear on the page.
await page.waitForSelector("input[name=password]");
// Enter your password into the password input field with a delay of 100 milliseconds between keypresses.
await page.type("input[name=password]", "Your Password", { delay: 100 });
// Click the "Sign In" button to complete the login process.
await page.click("input[id=signInSubmit]");
};
// Call the 'logging' function to initiate the login process when the script is executed.
logging();
Bypassing Anti-bot Protection With Puppeteer
Puppeteer by default leaves browser fingerprints that make it possible for anti-bot systems to detect your Puppeteer scraper as a non-human user.
Luckily for us, the Puppeteer community has created a stealth plugin, whose main goal is to patch the most common browser fingerprints that can use used by anti-bot systems to identify your Puppeteer scraper is using headless Chrome and not a standard Chrome browsers (used by humans).
Therefore, we’ll use the puppeteer-extra-plugin-stealth to prevent detection. If you do not use the Puppeteer StealthPlugin, you will not be able to sign in to the account.

For the email field, you can either use the id="identifierId" or the type="email" selector. In our code, we’re using the type selector instead of the id selector.

To click on the next button, use the id="identifierNext" selector.

To type the password, use the type="password" selector. You can't use the ID here because the ID is not given.

To click on the next button, you can use the id="passwordNext" selector. You’ll see that the button is clicked.

Awesome! You’ve logged in to the Google account.

Here’s the complete code:
// Import required libraries
import puppeteer from "puppeteer-extra";
import StealthPlugin from "puppeteer-extra-plugin-stealth";
// Enable StealthPlugin for Puppeteer
puppeteer.use(StealthPlugin());
// Define login credentials
const username = "Your_Email";
const password = "Your_Password";
(async () => {
try {
// Launch a headless browser instance with specific settings
const browser = await puppeteer.launch({
headless: false,
args: [
'--no-sandbox',
'--disable-gpu',
'--enable-webgl'
]
});
// Define the URL to the login page and user agent
const loginUrl = "https://accounts.google.com";
const userAgent =
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ' +
'(KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36';
// Create a new page with a specific user agent
const page = await browser.newPage();
await page.setUserAgent(userAgent);
// Navigate to the login page and wait until it's loaded
await page.goto(loginUrl, { waitUntil: 'networkidle2' });
// Fill in the email field and click "Next"
await page.waitForSelector('[type="email"]');
await page.type('[type="email"]', username);
await page.click("#identifierNext");
// Wait for the password field to be visible, fill it in, and click "Next"
await page.waitForSelector('[type="password"]', { visible: true });
await page.type('[type="password"]', password);
await page.click("#passwordNext");
} catch (error) {
console.error("Error:", error);
}
})();
Solving CAPTCHAs on Login With Puppeteer
Captcha is an obstacle that keeps bots out. But Puppeteer can help you overcome this issue. To solve the captcha, you can use the puppeteer-extra-plugin-recaptcha plugin, which can solve reCAPTCHAs and hCaptchas automatically.
We’ll be using the 2Captcha API-based CAPTCHA-solving service.
First of all, sign up on 2Captcha to get an API key.

You need to have some balance in your 2Captcha account to solve CAPTCHAs. So, add some balance to your account and use the 2Captcha API.

We’ll solve the CAPTCHA of the ScrapingBee website while logging in. For the email field, use the id="email" selector.

To fill the password field, use the id="password" selector.

After you provide the email and password, the CAPTCHA-solving process will start.
- First, the CAPTCHA will be detected and then solved.
- When the CAPTCHA is detected, its color will turn violet.
- Once the CAPTCHA is solved, its color will change to green.
The below video shows how the CAPTCHA on the above website is being solved.
After the CAPTCHA is solved, click on the button by using the type="submit" selector.
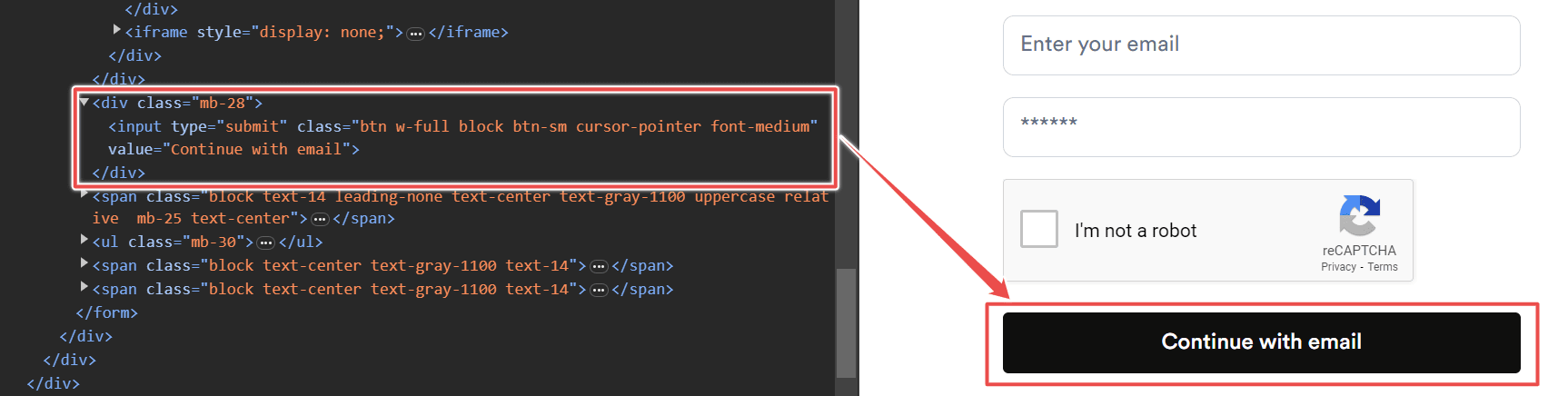
Here’s the complete code:
// Import necessary modules
import puppeteer from 'puppeteer-extra';
import RecaptchaPlugin from 'puppeteer-extra-plugin-recaptcha';
// Configure the reCAPTCHA solving provider
puppeteer.use(
RecaptchaPlugin({
provider: {
id: '2captcha',
token: 'API Key', // Replace with your own 2CAPTCHA API key
},
visualFeedback: true, // Colorize reCAPTCHAs (violet = detected, green = solved)
})
);
// Define the login function
const logging = async () => {
// Launch a headful browser instance
const browser = await puppeteer.launch({
headless: false,
});
// Create a new page
const page = await browser.newPage();
// Navigate to the login page
await page.goto('https://app.scrapingbee.com/account/login');
// Fill in the email and password fields
await page.waitForSelector('#email');
await page.type('#email', 'Your Email', { delay: 100 });
await page.waitForSelector('#password', { delay: 100 });
await page.type('#password', 'Your Password');
// Solve reCAPTCHAs on the page
await page.solveRecaptchas();
// Wait for navigation and click the login button
await Promise.all([
page.waitForNavigation(),
page.click('[type="submit"]'),
]);
};
// Call the login function
logging();
Not Getting Blocked After Logging In
We have covered how to log in to websites, but that's not the end of it. When you access a website, it is much easier for the website to identify you as a scraper if it detects repetitive or unusual patterns in your requests. As a result, you should always take extra steps to ensure your scrapers aren't detected when scraping while logged in.
If you are caught scraping a website, you can face various consequences. Some websites may simply block your IP address, while others may take more serious action, such as suspending or terminating your account.
Here are some steps you should consider taking.
Use Multiple Accounts
Using multiple accounts for web scraping can be effective in reducing the risk of detection. By using multiple accounts, you can limit the number of requests made by each account, as many websites impose rate limits to prevent abuse. Not all websites allow you to have multiple accounts, as some require KYC verification or charge a fee to create an account. However, if it is possible to create multiple accounts, it can be a good way to stay undetected.
Static IP Addresses
With a static IP address, your online presence remains constant, which can help you appear as a legitimate user to websites. This will reduce the risk of triggering security alerts based on IP changes and make it more difficult for the website to detect that you are a scraper.
To increase security, many websites now require you to validate your identity with a text message, email, or authenticator app whenever they detect you logging in using a new IP address.
Residential IPs are better than datacenter IPs for scraping because they are less likely to be blocked by websites. However, there are some cases where a static datacenter proxy will work fine for scraping. For example, if you are scraping a website that is not very popular or that does not have many anti-scraping measures in place, then you may be able to use a static datacenter proxy without getting blocked.
Realistic Request Patterns
Make sure your scraper requests URLs in a realistic pattern. If your scraper is making requests in a way that a normal user would never do, this can flag you as a scraper. For example, a normal user would log in to the website, then click on the search bar to search for any item, and then go to the search result links. However, a scraper never visits the search page and instead goes directly to the product page by using the slimmed-down URLs that a website doesn't show to users.
Risks Of Scraping Behind Logins
Scraping behind logins has more risks for you as a developer or company compared to scraping publicly available web pages. Here are some of the common risks.
Risk 1: Personal Information
When you create an account on a website, you are required to provide personal information such as your name, email, and phone number, which the website can use to tie the scraping activity back to your account.
Risk 2: Account Bans
The major risk of using a scraper is that the website could detect it delete or block your account, and ban you from creating new accounts. This could be a significant issue, especially if you have a paid account or if you are using the account to access important data. For example, if your Facebook or Instagram account is deleted, you will lose all of your photos and messages, and you will never be able to create another account. Similarly, if you are using a paid account on a website and your account is blocked, you may not get a refund.
Risk 3: Lawsuits
Scraping behind a website's login is more clearly illegal. When you create an account with a website, you agree to their terms of service, which often prohibit scraping. There have been a number of successful lawsuits against web scrapers, and many of them have involved scraping behind logins. If you are considering scraping behind a website's login, you should carefully review the website's terms of service and privacy policy.
More Web Scraping Tutorials
In this guide, you’ve learned about automating website logins with Node.js Puppeteer, including handling common challenges such as CAPTCHAs, anti-bot mechanisms, and dynamic elements.
If you would like to learn more about Web Scraping with Puppeteer, then be sure to check out The Puppeteer Web Scraping Playbook.
Or check out one of our more in-depth guides: