NodeJS Crawlee - Web Scraping Guide
NodeJS Crawlee is a flexible and powerful library that simplifies the process of web scraping, making it efficient and accessible.
This guide is designed to introduce both beginner and intermediate developers to Crawlee, covering a range of topics from the basic setup, through to advanced techniques, and strategies for deployment.
- TL:DR - Quick Start
- Setting Up Your Environment
- Creating Your First Crawler
- Adding More URLs
- Building a Real-World Project
- Crawling Techniques
- Data Scraping and Saving
- Advanced Configurations and Customization
- Avoiding Blocks and Managing Proxies
- Scaling and Performance Optimization
- Deployment and Running in the Cloud
- Conclusion
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TL;DR: Quick Start
For those short on time, here’s a rapid introduction to using Crawlee for scraping:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
async requestHandler({ $, request, enqueueLinks }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
await enqueueLinks();
},
});
await crawler.run(['https://books.toscrape.com']);
This snippet demonstrates initializing a CheerioCrawler to fetch the webpage title from a given URL, output it to the console, and enqueue further links found on the page for subsequent crawling.
Setting Up Your Environment
To begin with Crawlee, ensure you have NodeJS installed. Here’s how to prepare your environment:
- Install NodeJS: Download and install NodeJS from nodejs.org.
- Initialize a New Project:
mkdir my-crawler
cd my-crawler
npm init -y - Install Crawlee: Add Crawlee to your project dependencies.
npm install crawlee
These steps set up a new NodeJS project and install Crawlee, making it ready for development.
Creating Your First Crawler
Crafting a simple crawler to fetch data from a webpage and display it is an excellent way to get started with Crawlee. This basic example outlines the initial steps in setting up a Crawlee project:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
async requestHandler({ $, request }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
},
});
await crawler.run(['https://books.toscrape.com']);
The script above initializes a CheerioCrawler to fetch and print the title of a specified URL. The general steps involved in creating your first crawler include:
- Setting Up the Environment: Import the necessary Crawlee components and set up your project environment.
- Initializing the Crawler: Create an instance of the crawler with a
requestHandlerfunction, which processes each webpage. - Handling Requests: Use the
requestHandlerto extract and manipulate data from the webpage. - Running the Crawler: Execute the crawler with a target URL to begin scraping.
This example demonstrates how to quickly set up and run a basic web scraping task using Crawlee, providing a foundation for more advanced projects.
Key Concepts
- Requests: Each URL the crawler visits is considered a request. The
requestHandlerfunction processes each request, where you can specify what data to extract. - Queues: Crawlee uses queues to manage URLs. The initial URL is added to the queue, and as the crawler discovers more links, it can dynamically add them to the queue.
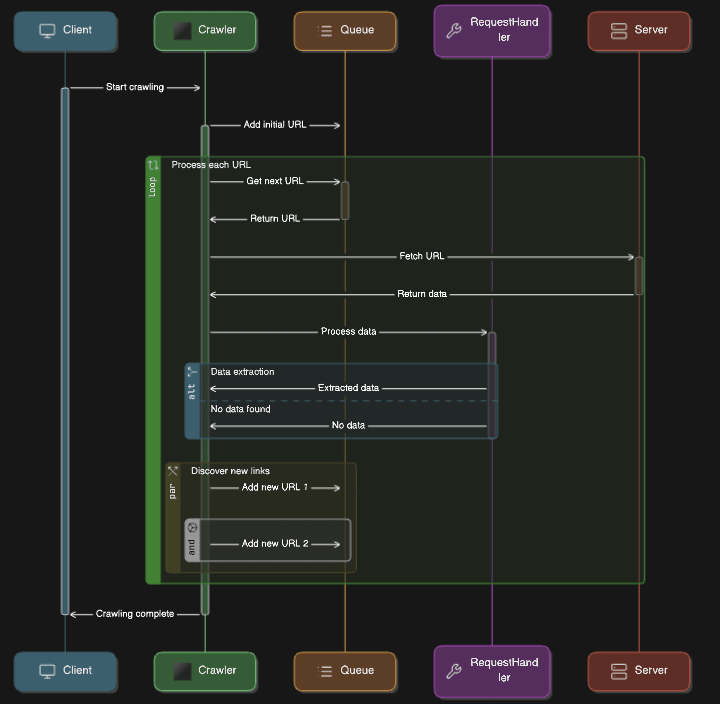
Understanding these concepts is crucial for building efficient crawlers that can handle multiple URLs and dynamic content.
Adding More URLs
To expand your crawler to process multiple URLs, you can dynamically enqueue additional pages. This method allows your crawler to discover and process new pages as it navigates through a website, enhancing its ability to gather comprehensive data.
Here's an example of handling this:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
async requestHandler({ $, request, enqueueLinks }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
await enqueueLinks({
strategy: 'same-domain', // Only enqueue links within the same domain
});
},
});
await crawler.run(['https://books.toscrape.com']);
- In this example, the
enqueueLinksfunction is used to queue additional pages from the same domain for further crawling. - The
strategy: 'same-domain'ensures that only links within the same domain as the initial URL are enqueued, preventing the crawler from navigating away from the target website. - This strategy is particularly useful for maintaining focus on a specific site and avoiding unnecessary or irrelevant pages.
By utilizing this approach, the crawler can automatically discover new pages as it processes each one, effectively expanding its reach and ability to collect data from a broader section of the website.
This method is essential for tasks such as scraping large websites, conducting comprehensive site audits, or gathering extensive datasets for analysis.
Building a Real-World Project
Developing a comprehensive example project involves collecting links from a website and extracting relevant data. This example demonstrates how to manage more complex scraping tasks, allowing you to gather and store data systematically.
import { CheerioCrawler } from 'crawlee';
import fs from 'fs';
const results = [];
const crawler = new CheerioCrawler({
async requestHandler({ $, request, enqueueLinks }) {
console.log(`Scraping ${request.url}`);
const title = $('title').text();
results.push({ url: request.url, title });
await enqueueLinks();
},
});
await crawler.run(['https://books.toscrape.com']);
fs.writeFileSync('results.json', JSON.stringify(results, null, 2));
This script performs several key tasks:
- Initialization of the Crawler: The
CheerioCrawlerinstance is created, ready to handle web scraping tasks. - Request Handling: For each page the crawler visits, the
requestHandlerfunction is called. Within this function:- The title of the page is extracted using Cheerio's
$function, which provides a jQuery-like syntax for navigating the HTML. - The URL and title are stored in an array called
results. - The
enqueueLinksfunction is called without any specific strategy, so it enqueues all found links by default, allowing the crawler to continue to discover and scrape additional pages.
- The title of the page is extracted using Cheerio's
- Running the Crawler: The crawler is run with the initial URL
https://books.toscrape.com, starting the process of visiting the site and following links. - Storing Results: Once the crawling process is complete, the accumulated results are written to a
results.jsonfile usingfs.writeFileSync. This JSON file contains the collected URLs and their corresponding page titles, formatted for easy readability.
This approach demonstrates how to effectively collect and store data from multiple pages on a website.
By following this method, you can build robust web scraping projects capable of handling real-world scenarios, such as gathering large datasets, performing detailed site analyses, or creating comprehensive content inventories.
Crawling Techniques
Crawlee offers several techniques and capabilities for crawling websites effectively, allowing you to retrieve data efficiently and handle various challenges that come with web scraping.
These advanced techniques ensure robust and reliable data extraction from a wide range of websites.
Here are some advanced crawling techniques and features that Crawlee supports:
HTTP Crawling
Crawlee’s HTTP crawling capabilities facilitate handling HTTP requests, generating browser-like headers, and parsing HTML content efficiently. This method is suitable for websites that do not rely heavily on JavaScript for rendering content.
Here’s a typical setup:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
async requestHandler({ $, request }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
},
preNavigationHooks: [
async ({ request }) => {
request.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
};
}
]
});
await crawler.run(['https://books.toscrape.com']);
In this example, a custom User-Agent header is set to mimic a real browser. This approach helps in reducing the chances of being blocked by websites, as it makes the HTTP requests appear as though they are coming from a genuine browser.
Real Browser Crawling
For sites that require JavaScript rendering or more complex interactions, Crawlee supports real browser crawling using tools like Playwright and Puppeteer.
These tools allow Crawlee to interact with websites in the same way a human user would, enabling the scraping of dynamic and script-heavy pages.
Here’s how to use Playwright:
import { PlaywrightCrawler } from 'crawlee';
const crawler = new PlaywrightCrawler({
async requestHandler({ page, request }) {
const title = await page.title();
console.log(`Title of ${request.url}: ${title}`);
},
});
await crawler.run(['https://books.toscrape.com']);
This setup uses PlaywrightCrawler to fetch the title of a webpage using an actual browser instance. By using Playwright, the crawler can handle JavaScript execution and more sophisticated website interactions, which are essential for scraping modern web applications that heavily rely on client-side rendering.
These techniques, whether using HTTP-based methods or real browser interactions, equip Crawlee with the flexibility to handle a diverse array of web scraping challenges, ensuring efficient and thorough data extraction from a variety of web sources.
Data Scraping and Saving
Data scraping and saving using Crawlee involves efficiently extracting information from web pages and then storing it in a structured format.
Various methods can be employed to save the scraped data, such as writing to a JSON file or a database. This flexibility ensures that the data can be easily accessed and utilized for different purposes.
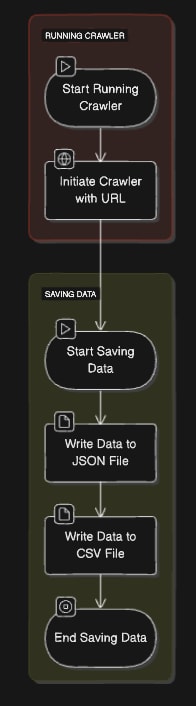
Here’s an approach to handle JSON APIs and save data in different formats:
import { CheerioCrawler } from 'crawlee';
import fs from 'fs';
const results = [];
const crawler = new CheerioCrawler({
async requestHandler({ $, request }) {
const data = {
url: request.url,
title: $('title').text(),
description: $('meta[name="description"]').attr('content')
};
results.push(data);
},
});
await crawler.run(['https://books.toscrape.com']);
fs.writeFileSync('data.json', JSON.stringify(results, null, 2));
fs.writeFileSync('data.csv', results.map(row => Object.values(row).join(',')).join('\n'));
In this script, several key operations are performed:
- Initialization of the Crawler: A
CheerioCrawlerinstance is created to handle the web scraping tasks. - Request Handling: For each page visited, the
requestHandlerfunction is executed:- The script extracts the URL, title, and meta description of the page.
- This data is stored in an object and added to the
resultsarray.
- Running the Crawler: The crawler is initiated with the URL
https://books.toscrape.com, starting the process of visiting the site and collecting data. - Saving Data: Once the crawling process is complete, the accumulated data is written to two files:
data.json: The data is saved in JSON format, which is useful for structured data storage and easy parsing by various programming languages and tools.data.csv: The data is also saved in CSV format, which is ideal for use in spreadsheet applications and for simpler data analysis tasks.
By saving the scraped data in both JSON and CSV formats, this script provides flexibility in how the data can be used and analyzed later.
JSON is well-suited for more complex data structures and programmatic access, while CSV is convenient for tabular data representation and manual inspection.
This approach ensures that the scraped data is readily available for various applications, from data analysis to reporting and integration with other systems.
Advanced Configurations and Customization
Crawlee offers extensive configuration options that allow for customized scraper behavior, making it versatile and robust for various web scraping needs. These configurations enable better error handling, retries, and other advanced features that ensure the reliability and efficiency of your scraping tasks.
Here is an example that includes advanced error handling and retries:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
async requestHandler({ $, request }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
},
maxRequestRetries: 3,
handleFailedRequestFunction: async ({ request }) => {
console.log(`Request failed for ${request.url}`);
}
});
await crawler.run(['https://books.toscrape.com']);
This code demonstrates several advanced configurations:
- Request Handler: The
requestHandlerfunction processes each request, logging the title of the page being scraped. This function is central to defining how the crawler interacts with each page. - Maximum Request Retries: The
maxRequestRetriesoption is set to 3, which means that if a request fails, the crawler will retry up to three times before giving up. This is crucial for handling transient network issues or temporary server unavailability, improving the reliability of your scraping process. - Error Handling: The
handleFailedRequestFunctionis an asynchronous function that gets called when a request fails after all retry attempts. In this example, it logs an error message with the URL of the failed request. This helps in identifying and diagnosing issues with specific pages or URLs.
By incorporating these advanced configurations, the crawler becomes more resilient and capable of handling various challenges that might arise during web scraping. These features ensure that temporary problems do not cause the entire scraping process to fail and provide mechanisms for logging and managing errors effectively.
Overall, such advanced configurations and customizations in Crawlee enhance its robustness, making it a powerful tool for complex and large-scale web scraping projects.
Avoiding Blocks and Managing Proxies
To circumvent detection and blocks by websites, it's crucial to integrate proxy rotation and session management into your crawlers. This ensures that your scraping activities appear more natural and reduces the likelihood of being blocked.
Here's a setup using ScrapeOps Proxy Aggregator:
import { CheerioCrawler, ProxyConfiguration } from 'crawlee';
// ScrapeOps proxy configuration
const PROXY_HOST = 'proxy.scrapeops.io';
const PROXY_HOST_PORT = '5353';
const PROXY_USERNAME = 'scrapeops.headless_browser_mode=true';
const PROXY_PASSWORD = 'YOUR_API_KEY'; // <-- enter your API_Key here
const proxyUrl = `https://${PROXY_USERNAME}:${PROXY_PASSWORD}@${PROXY_HOST}:${PROXY_HOST_PORT}`;
// ScrapeOps proxy configuration
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: [
proxyUrl,
],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ $, request }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
}
});
await crawler.run(['https://books.toscrape.com']);
This script demonstrates how to configure and use a proxy service to manage IP rotation and session management, which helps in avoiding blocks and bans from target websites:
-
Proxy Configuration:
- The
ProxyConfigurationclass is used to set up proxy details. - The proxy URL is constructed using your ScrapeOps credentials, including the host, port, username, and API key.
- The
-
Crawler Setup:
- The
CheerioCrawleris initialized with theproxyConfiguration. - The
requestHandlerfunction processes each request and logs the title of the page, ensuring the crawler operates through the proxy.
- The
-
Running the Crawler:
- The crawler is run with the initial URL
https://books.toscrape.com, leveraging the proxy configuration for each request.
- The crawler is run with the initial URL
By integrating proxy rotation through ScrapeOps, your crawler can distribute requests across multiple IP addresses, reducing the likelihood of being flagged or blocked by target websites. This approach enhances the reliability and effectiveness of your scraping activities, particularly when dealing with sites that have strict anti-scraping measures.
Using proxies is essential for maintaining access to target sites, especially when performing extensive or repeated data extraction tasks. This method helps mimic more organic browsing behavior, ensuring more sustainable and uninterrupted scraping operations.
Scaling and Performance Optimization
For projects that require handling large volumes of data or scraping multiple sites simultaneously, it's essential to optimize the performance of your crawlers. Efficient scaling ensures that your scraping tasks are completed quickly and effectively, without overloading your system or the target websites.
Here’s how you can scale your scraping tasks:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
maxConcurrency: 10, // Number of concurrent requests
async requestHandler({ $, request }) {
console.log(`Title of ${request.url}: ${$('title').text()}`);
}
});
await crawler.run(['https://books.toscrape.com']);
In this configuration, several optimizations are made to enhance performance:
-
Max Concurrency:
- The
maxConcurrencyoption is set to 10, allowing the crawler to handle ten requests simultaneously. This setting significantly increases the throughput, enabling the crawler to process more pages in less time.
- The
-
Request Handler:
- The
requestHandlerfunction processes each request, logging the title of the page being scraped. This function is called for each URL, handling the actual data extraction.
- The
-
Running the Crawler:
- The crawler is run with the initial URL
https://books.toscrape.com, utilizing the set concurrency level to efficiently scrape the website.
- The crawler is run with the initial URL
By increasing the concurrency level, the crawler can perform multiple tasks in parallel, which is crucial for large-scale scraping projects. This approach not only reduces the overall time required to complete the scraping but also ensures that resources are utilized more effectively.
Optimizing for performance and scalability involves balancing the concurrency settings with the capabilities of your infrastructure and the constraints of the target websites. Careful tuning of these parameters can lead to substantial improvements in scraping efficiency, allowing you to gather large datasets quickly and reliably.
Deployment and Running in the Cloud
Deploying your Crawlee projects using container technology like Docker and cloud services ensures enhanced scalability, reliability, and ease of management. Containers allow you to package your application and its dependencies into a single, portable unit, which can be run consistently across various environments.

Here’s a basic Dockerfile and deployment instructions:
Dockerfile
FROM node:14
WORKDIR /app
COPY package.json ./
RUN npm install
COPY . .
CMD ["node", "index.js"]
Build and Run
To build and run your Docker container, use the following commands:
docker build -t my-crawler .
docker run my-crawler
This Dockerfile and these commands do the following:
- Base Image: The
FROM node:14line specifies the base image, which includes Node.js version 14. - Working Directory: The
WORKDIR /appline sets the working directory inside the container to/app. - Copy and Install Dependencies: The
COPY package.json ./andRUN npm installlines copy thepackage.jsonfile into the container and install the dependencies listed in it. - Copy Application Code: The
COPY . .line copies the rest of your application code into the container. - Command to Run the Application: The
CMD ["node", "index.js"]line specifies the command to run your application.
For production environments, consider deploying your container to a cloud provider such as AWS, GCP, or Azure. These cloud providers offer scalable infrastructure and various services to manage your containers efficiently:
- AWS: Use Amazon ECS (Elastic Container Service) or Amazon EKS (Elastic Kubernetes Service) for managing containers.
- GCP: Use Google Kubernetes Engine (GKE) or Cloud Run for container management.
- Azure: Use Azure Kubernetes Service (AKS) or Azure Container Instances (ACI) for deploying containers.
Conclusion
This comprehensive guide has explored the essential aspects of web scraping with NodeJS Crawlee, from setting up your environment to advanced techniques and deployment strategies. By utilizing Crawlee's powerful features and configurations, you can create robust scraping solutions tailored to a wide range of use cases.
For more detailed information and further exploration, visit the official Crawlee website.
More Web Scraping Tutorials
If you would like to learn more about Web Scraping using NodeJS, then be sure to check out The NodeJS Web Scraping Playbook.
Or check out one of our more in-depth guides: