
Selenium Guide: How To Find Elements by XPath
Finding elements by XPath is a fundamental skill in Selenium automation, allowing developers and testers to precisely locate and interact with specific elements on a web page.
Once you have a solid grasp of how XPath works, you can find pretty much any element on any page regardless of the element selection that your scraper supports.
So, in this guide we will walk you through find elements on a page by XPath in Selenium:
- What is Selenium?
- What is Xpath?
- Why Should You Choose to Find By Xpath?
- How to Find Elements By Xpath in Selenium
- Real World Scraping By XPath
- Conclusion
- More Cool Articles
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
What is Selenium?
Selenium is a scraping framework that uses a browser. With Selenium, we can handle dynamic web elements and simulate an end user on a webpage.
To use Selenium, you need a web browser and a webdriver (this is used to control your browser). Make sure your driver version matches your Chrome version.
For example, if you have Google Chrome 119.0.6045.105, you should install Chromedriver with the same version number. You can check your version of Chrome with the following command:
google-chrome --version
Once you have your webdriver installed, you can install Selenium using pip.
pip install selenium
Now that Selenium has been installed, you're all set to get started scraping some content from the web.
To test our installation, we'll make a relatively simple Python script. Create a new Python file and add the following code:
from selenium import webdriver
from selenium.webdriver.common.by import By
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://quotes.toscrape.com")
#save the title of the page as a variable
title = driver.title
#print the title of the page
print(f"Page title: {title}")
#close the browser
driver.quit()
Selenium give us a wonderful toolset for finding different elements on any page including:
- NAME
- ID
- TAG_NAME
- CLASS_NAME
- CSS_SELECTOR
- XPATH
While there is a ton of power and flexibility in all of the methods above, this article focuses primarily on finding elements via XPath.
What is XPath?
XPath is an extremely powerful tool for locating elements because it gives us a way to find literally anything on the page relatively quickly. While it is designed for XML, HTML documents also conform to the XPath standard.
Every web document has a structure, and because of that structure, there is a path, or more precisely, an XPath to every single element on a webpage.
This structured approach gives us the power to traverse a document, find elements based on parent or more precisely ancestor elements.
Not only is there an absolute path to every element on the page, there is also a relative path to each element.
Elements on the page are each given a number, so in the event that elements change on the page, we can find an element, save its location, and then check the same location later on to see if it has changed!
Why Should You Choose to Find by XPath?
When finding elements by XPath, you get far more control over which elements you'd like to find.
You can filter objects on the page by basically any criteria you would ever want such as:
- By HTML tag
- By Id
- By CSS Selector
- By Text
- By Ancestor or Descendant
Brief Overview Of The DOM
The Document Object Model or "DOM" for short determines the hierarchical structure of an HTML page. Let's look at some HTML page to see how it is laid out. Take a look at the HTML below:
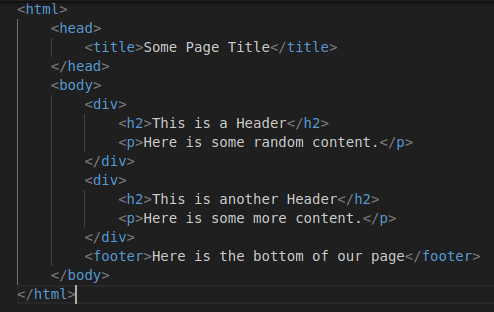
If you look, our parent element <html> is laid out at the top and to the left of the document.
- If you look at the bottom, you will find the tag
</html>which closes the<html>element and specifies the end of our HTML content. - Between these tags, you will notice other tags, child elements of this
<html>tag.
Now, you can take a look at the <head> tag.
- Similar to the
<html>tag, it is closed with a</head>tag. * Since the<head>content is a part of the<html>content, it the<html>tag is considered a parent element of the<head>tag. - Inside the
<head>tag, we have a<title>tag. - So the
<title>is a child of the parent element,<head>and<head>is a child element of the parent<html>.
Understanding the XPath Syntax and Operators
Let's take another look at the XPath we copied earlier to see how XPath syntax is laid out. While it may look scary, once you understand the structure, it is actually very straightforward.
/html/body/div/div[1]/div[1]/h1/a
/htmlspecifies that we want to find children ordescendantsof the<html>tag./bodyspecifies that we want children of any<body>tags that are children of the<html>tag/divsays we want<div>elements that descend from the previous two tags/div[1]/div[1]means that we want the first child of the first child of the previously mentioned<div>tag/h1specifies that we want the header, or<h1>matching all the criteria we've used to filter thus far- Finally,
/aspecifies that we want the<a>tag meeting all the criteria that we've specified up to this point
As you probably noticed in the example above, we used the / operator to specify a specific root element. If we want to find elements regardless of their location, we can use the // operator.
For instance, if we wanted to find all <a> elements on the page, we could instead specify //a as opposed to the long XPath we specified above.
XPath Nodes
Let's take a look at the HTML code again that we looked at previously when we learned about the DOM.
Let's now convert this layout into a tree of nodes so we can better understand both how they are structured both in HTML and more specifically XPath.
The figure below shows this information as a tree:

In the figure above, you should notice the following:
- The root node
html(light blue) is the ancestor to everything on the page - Our root node has two children,
headandbody(blue) - The
headnode has only one child, thetitlenode (light yellow) - The
bodynode has two children,divanddiv(light yellow) - The
divelements also have two children each,h1andp(yellow)
In most webpages, there is almost always a root html ancestor, with at least two children, head and body.
- The head usually contains information such as the
titleandmetawhich often contain information relevant to the initial setup and display of the page. - The
bodynode is most often an ancestor of any information that is actually displayed on the page.
Xpath Elements
When we are selecting XPath elements, we can use the following operators:
headwould select all theheadelements on the page we looked at above/headwould select all children that descend from the root node,head.can be used to select the current node...selects the parent of the current node, (if you are familiar with using terminal/shell commands, you may remember thatcd ..is used to move into theparentof the current directory, in Xpath, it is to select theparentof the current node)@is used to select a node with a specific attribute for instance:[@class='quote']
XPath Predicates
Predicates are used to select a node containing a certain value. This makes finding elements of a certain type very easy.
We can use this to find pretty much anything containing CSS.
-
If we are looking for all elements of the
quoteclass, we would use the predicate:[@class='quote']. -
If we want to select all
divelements of classquote, we could use//div[@class='quote']. -
If we want to find all the tag elements of the quotes, we could use
//div[@class='tag']. -
If we want to find all elements with the link
inspirationalwe could use//*[@href='/tag/inspirational']. -
//div[@class='quote]selects alldivelements with theclassofquote -
//div[@class='tag']would select alldivelements of theclass:tag -
//*[@href='/tag/inspirational']selects all elements on the page that with thehref(link) attribute to/tag/inspirational
How to Find Elements by XPath in Selenium
To get started finding something by XPath, you can simply right-click the object on a page inside a regular browser and choose the inspect option.
From there, you can actually copy the XPath directly from your browser.

After copying the XPath, you can even paste it directly into your Python script!
/html/body/div/div[1]/div[1]/h1/a
We'll take a more detailed look at this in the next section.
Locating Elements With Absolute XPath
As shown above, we use the / operator to locate elements using the absolute path. Each time we use this operator, we are specifying a root in the path.
While the full path is /html/body/div/div[1]/div[1]/h1/a, this says that we want all a elements with root h1 that are rooted from div[1] which is also rooted from another div[1] and so on until we get to the base root: /html.
When finding elements by absolute path, it is imperative to do so carefully. This method is excellent for finding specific elements on the page, but a single typo can completely ruin your results.
You should search for the absolute XPath only if you know for certain the absolute location of the item that you're looking for.
Locating Elements With Relative XPath
When looking for a relative path, instead of using the / operator, we use the // operator.
This method can be far more fruitful when parsing a very large page because we then search the page for any elements that meet the criteria.
Here's a Python script that finds all <h1> elements:
from selenium import webdriver
from selenium.webdriver.common.by import By
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://quotes.toscrape.com")
#find the h1 element
all_h1 = driver.find_elements(By.XPATH, "//h1")
for h1 in all_h1:
print(f"h1: {h1.text}")
driver.quit()
Advanced Concepts - XPath Functions & Axes
When using XPath, functions and axes are both a great way to parse and navigate the page.
If we'd like to search for specific text, we can use the contains() and text() functions. To search different axes, we can use the :: operator to specify what we'd like to search for.
If we'd like all children of a div element, we could search for div::*, or we could specify it like this:
//ancestor::div
The above XPath looks for anything that has a div as an ancestor.
Navigating Complex Structures With XPath
What if we'd like to use our XPath to traverse an entire page?
We could look for all elements by how they're ancestors and descendants.
Let's get all the children and all the parents of the div elements.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.by import By
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://quotes.toscrape.com")
#find all ancestors of div elements
all_div_ancestors =driver.find_elements(By.XPATH, "//ancestor::div")
for ancestor in all_div_ancestors:
print(f"Ancestor: {ancestor.text}")
#find all children of div elements
all_div_children = driver.find_elements(By.XPATH, "//child::div")
for child in all_div_children:
print(f"Child: {child.text}")
driver.quit()
In the code above, we do the following:
- launch the browser and navigate to the page with
webdriver.Chrome()anddriver.get() - Find all ancestors of
divelements with//ancestor::divand print them - Find all children of
divelements with//child::divand print them
Data Manipulation and Validation
As previously mentioned, we can also use XPath to extract text. Let's use XPath to find all occurences of the name, "Albert Einstein".
To do this, we can execute the following script:
from selenium import webdriver
from selenium.webdriver.common.by import By
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://quotes.toscrape.com")
#find all elements of the "quote" classfrom selenium import webdriver
from selenium.webdriver.common.by import By
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://quotes.toscrape.com")
#find all elements containing the word "Einstein"
quotes = driver.find_elements(By.XPATH, "//*[contains(text(), 'Einstein')]")
for quote in quotes:
print(quote.text)
#close the browser
driver.quit()
In the code above we do the following:
- open a browser and navigate to a page with
webdriver.Chrome()anddriver.get() - Find all elements with the name "Einstein" using the
contains()andtext()XPath functions
Let's write a script that shows the flexibility of XPath with:
- Html elements
- finding elements by location
- finding elements by css selector
- finding elements by text
- finding child elements
- finding elements by id
- finding next element
- finding the previous element
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://quotes.toscrape.com")
#find the h1 element
h1 = driver.find_element(By.XPATH, "//h1")
print(f"h1: {h1.text}")
#find first element in the body
first_element = driver.find_element(By.XPATH, "/html/body[1]")
print(f"First element: {first_element.text}")
#find all elements of the "quote" class
all_quotes = driver.find_elements(By.XPATH, "//*[@class='quote']")
print("All quotes:")
for quote in all_quotes:
print(quote.text)
#find all elements containing the word "by"
authors = driver.find_elements(By.XPATH, "//*[contains(text(), 'by')]")
print("Authors:")
for author in authors:
print(author.text)
#given a range of numbers, find all tags descended from the Einstein quote
tag_string = "/html/body/div/div[2]/div[1]/div[1]/div/a"
print(f"Einstein tags:")
for tagnumber in range(1,5):
tag = driver.find_element(By.XPATH, f"{tag_string}[{tagnumber}]")
print(tag.text)
#find elements descended from "//html/body/div/div[2]"
all_div_2_stuff = driver.find_element(By.XPATH, "//html/body/div/div[2]")
print("All div[2] stuff:")
print(all_div_2_stuff.text)
#find the login link
login = driver.find_element(By.XPATH, "//*[@href='/login']")
#click this link to move to the login page
login.click()
#find the input box with the id of 'username' and save it as a variable
username = driver.find_element(By.XPATH, "//input[@id='username']")
#find the input box with the id of 'password' and save it as a variable
password = driver.find_element(By.XPATH, "//input[@id='password']")
#input the username
username.send_keys("new_user")
#input the password
password.send_keys("mysupersecretpassword")
#sleep for 3 seconds so you can see these input boxes getting filled
sleep(3)
#find the element following 'username' and print the location
element_after_body = driver.find_element(By.XPATH, "//following-sibling::input[@id='username']")
print(element_after_body.location)
#find the element preceding username and print the location
element_before_username = driver.find_element(By.XPATH, "//preceding-sibling::input[@id='username']")
print("Element before body")
print(element_before_username.location)
#close the browser
driver.quit()
Designed to show off the flexibility of Xpath, the script above does the following:
- launch an instance of Chrome with
webdriver.Chrome()and navigate to a webpage withdriver.get() - Finds an
h1element regardless of its location with//h1 - Finds the first element in the body of the page with
//html/body[1] - Finds all
quoteelements with//*[@class=quote] - Finds all authors by finding anything containing the text, "by" in combination with the
contains()andtext()functions://*[contains(text(), 'by')] - Finds all tags descended from the first Einstein quote by specifying the absolute path to the tags
/html/body/div/div[2]/div[1]/div[1]/div/a[{tagnumber}] - Find the
loginlink with//*[@href='/login']and follow the link withlogin.click() - Once on the login page we find the
usernameinput box with//input[@id='username']and find thepasswordinput box with//input[@id='password'] - Fill the input boxes with the
send_keys()method and use thesleep()function so that we can look at the boxes after they've been filled - Find the element following
usernamewith//following-sibling::input[@id='username']and print its location - Find the element preceding
usernamewith//preceding-sibling::input[@id='username']and print its location as well
Real World Scraping by XPath
Now that you're familiar with XPath, let's use a simple XPath expression on Amazon! We'll start by integrating with the ScrapeOps Proxy.
When using a a scraper in production, this is always a best practice in order to avoid detection because many websites will actively try to detect and block scrapers.
Paste the following code into a new Python file:
from selenium import webdriver
from selenium.webdriver.common.by import By
from urllib.parse import urlencode
API_KEY= "YOUR-SUPER-SECRET-API-KEY"
#converts a url to a ScrapeOps url
def get_scrapeops_url(url):
payload = {
"api_key": API_KEY,
"url": url
}
#encode the url you want to scrape, and combine it with the url of the proxy
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
#return the url of the proxied site
return proxy_url
#open an instance of Chrome
driver = webdriver.Chrome()
#navigate to a webpage
driver.get("https://www.amazon.com")
#find all elements containing the $ character
prices = driver.find_elements(By.XPATH, "//*[contains(text(), '$')]")
print("Price Mentions:")
for price in prices:
#if the text contains relevant information, print it
if price.text.strip() != "$" and price.text.strip() != "":
print(price.text)
#close the browser
driver.quit()
In the code above, we:
- create a
get_scrapeops_url()function to convert regular urls into proxied urls - navigate to the website with
driver.get() - Find all elements that contain a
$withdriver.find_elements(By.XPATH, "//*[contains(text(), '$')]") - Iterate through the list with a
forloop and if the text contains more information than just$, we print it to the screen
As you can plainly see above, we can get all the information we want with a very small and simple XPath expression.
Why Should You Choose to Find By XPath?
While it may be more difficult at first, you should choose to find elements by their XPath for a variety of reasons:
- Every element has an XPath
- XPath provides a structured approach to finding any element on a page
- XPath has a variety of functions that can use search for specific text and values
- Once the syntax is understood, XPath is far more clear and concise than other selection methods
- XPath allows you to navigate up and down the page
- Xpath allows you to easily specify elements with a parent/child relationship
No matter what information you're trying to extract from a page, you can find it using XPath and you can find it quickly!
Conclusion
You've made it to the end! By now you should have a basic grasp on how to use Selenium and how to find page elements using their XPath.
Once you get more expereience with it, XPath will give you the power to find literally anything on the page.
If you're interested in learning more about scraping in general, take a look at the Python Scraping Playbook.
To learn more about Selenium, you can check out the Official Selenium Documentation.
More Cool Articles
Interested in learning more about scraping, but don't know where to start?
Choose one of the articles below and level up your skillset!