
FlareSolverr Guide: Bypassing Cloudflare Made Simple
FlareSolverr is a Python package designed to help you bypass Cloudflare's anti-bot protection.
In this guide we're going to walk through how to setup and use Scrapy Splash, including:
- How To Install Docker
- Install & Run FlareSolverr
- Use FlareSolverr With Our Scrapers
- Option 1: Send All Requests To FlareSolverr
- Option 2: Use FlareSolverr To Only Retrieve Valid Cloudflare Cookies
- Controlling FlareSolverr Sessions
- Making POST Requests With FlareSolverr
- Alternatives To FlareSolverr
For other method of bypassing Cloudflare then check out our How to Bypass Cloudflare guide.
Cloudflare is continously changing and upgrading their anti-bot protection systems, making it harder for web scrapers and libraries like FlareSolverr to bypass their detection methods. As a result, open source anti-bot bypassing libraries like FlareSolverr can often go out of date and stop working.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
What Is FlareSolverr?
FlareSolverr is a proxy server that you can use to bypass Cloudflare's anti-bot protection so you can scrape data from websites who have deployed their content on Cloudflare's CDN.
Cloudflare allows your scrapers to bypass Cloudflare's anti-bot pages like the one below:
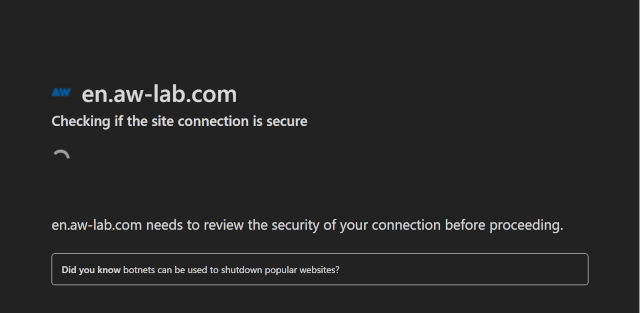
Cloudflare uses numerous browser fingerprinting challenges & checks (more detail here) to determine if a request is coming from a real user or a scraper/bot.
When run, FlareSolverr starts a server that uses Python Selenium with undetected-chromedriver to solve Cloudflares Javascript and browser fingerprinting challenges by impersonating a real web browser.
FlareSolverr opens the target URL with a Selenium browser and waits until the Cloudflare challenge is solved, before returning the HTML and cookies Cloudflare returns to the browser.
You can then use these cookies to bypass Cloudflare using other HTTP clients like Python Requests.
How To Install Docker
As the easiest way to setup FlareSolverr is using Docker (as it already contains the Chromium browser), in this guide we will first show you how to install Docker.
So if you haven't Docker installed already then use one of the following links to install Docker:
Download the Docker installation package, and follow the instructions. Your computer may need to restart after installation.
After installation, if Docker isn't running then click the Docker Desktop icon. You can check that docker is by running the command in your command line:
docker
If it is recognized then you should be good to go.
Install & Run FlareSolverr
Next we need to get FlareSolverr up and running.
1. Download FlareSolver
First we need to download the FlareSolverr Docker image, which we can do by running the following command on Windows or Max OS:
docker pull flaresolverr/flaresolverr
Or on a Linux machine:
sudo docker pull flaresolverr/flaresolverr
If everything has worked correctly, when you open you Docker Desktop on the Images tab you should see the flaresolverr/flaresolverr image (or ghcr.io/flaresolverr/flaresolverr image depending on which option you used).

2. Run FlareSolverr
To run FlareSolverr, we need to run the following command in our command line again.
For Windows and Max OS:
docker run -d \
--name=flaresolverr \
-p 8191:8191 \
-e LOG_LEVEL=info \
--restart unless-stopped \
ghcr.io/flaresolverr/flaresolverr:latest
For Linux:
sudo docker run -d \
--name=flaresolverr \
-p 8191:8191 \
-e LOG_LEVEL=info \
--restart unless-stopped \
ghcr.io/flaresolverr/flaresolverr:latest
To check that FlareSolverr is running correctly, go to http://localhost:8191/ and you should see get a response like this.
{
"msg": "FlareSolverr is ready!",
"version": "3.0.2",
"userAgent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
If you do then, the FlareSolverr server is up and running correctly.
Use FlareSolverr With Our Scrapers
When running, FlareSolverr provides a simple HTTP server that we can send the urls we want to scrape to it, and FlareSolverr will send the request via a Selenium browser and undetected-chromedriver to solve the Cloudflare challenge and return the HTML response and the cookies.
Here is a example of using FlareSolverr to scrape PetsAtHome.com a Cloudflare protected website:
curl -L -X POST 'http://localhost:8191/v1' \
-H 'Content-Type: application/json' \
--data-raw '{
"cmd": "request.get",
"url":"https://www.petsathome.com/",
"maxTimeout": 60000
}'
Here is the same example using Python Requests instead of cURL to send the request to FlareSolverr:
import requests
post_body = {
"cmd": "request.get",
"url":"https://www.petsathome.com/",
"maxTimeout": 60000
}
response = requests.post('http://localhost:8191/v1', headers={'Content-Type': 'application/json'}, json=post_body)
print(response.json())
The response should look something like this:
{
"status": "ok",
"message": "Challenge solved!",
"solution": {
"url": "https://www.petsathome.com/",
"status": 200,
"cookies": [
{
"domain": "www.petsathome.com",
"httpOnly": false,
"name": "WC_MOBILEDEVICEID",
"path": "/",
"secure": false,
"value": "0"
},
{
"domain": ".petsathome.com",
"expiry": 1673531559,
"httpOnly": false,
"name": "FPLC",
"path": "/",
"secure": true,
"value": "k03jwEFLbwxG2InqkF8yDy5%2BxWFeypsVETpfQGAFNO9M33HudoClDsp%2FY9BH89yLrGpQRLYL2WCgOkBrWRwdcK%2BycvG8%2F3m3SjDu3ZDXXHodwcxEhm4fQo7x8G%2BMrw%3D%3D"
},
...
],
"userAgent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"headers": {},
"response": "<html><head>...</head><body>...</body></html>"
},
"startTimestamp": 1673459546891,
"endTimestamp": 1673459560345,
"version": "3.0.2"
}
As you can see FlareSolverr has successfully solved the Cloudflare challenge "message": "Challenge solved!" and returned the cookies and HTML response from the website.
This functionality gives us two ways to use FlareSolverr:
- Option 1: Send all requests via FlareSolverr and leave it deal with any Cloudflare challenges.
- Option 2: Use FlareSolverr to retrieve valid Cloudflare cookies that we can then use with other HTTP clients like Python Requests.
Option 1 is the simplest of the two options as you can just send the URLs you want to scrape to your FlareSolverr server and leave it deal with Cloudflare. However, as browsers are memory & bandwidth intensive using this approach can be unreliable and expensive when done at scale.
Option 2 is a small bit trickier, but a more reliable and cost effective approach if you intend to scrape at scale.
We will run through how to use both options below.
Option 1: Send All Requests To FlareSolverr
The first option is to send all the URLs you want to scrape to FlareSolverr and have it manage bypassing Cloudflare and handling the session cookies for you.
import requests
url_list = [
'https://www.petsathome.com/',
'https://www.petsathome.com/',
]
for url in url_list:
post_body = {
"cmd": "request.get",
"url": url,
"maxTimeout": 60000
}
## Send Request To FlareSolverr
response = requests.post('http://localhost:8191/v1', headers={'Content-Type': 'application/json'}, json=post_body)
if response.status_code == 200:
json_response = response.json()
if json_response.get('status') == 'ok':
html = json_response['solution']['response']
## ...parse data from response
print('Success')
This will work but it make your scraper slower, more expensive and unreliable to run as every request will be going through the Selenium browser.
Option 2: Use FlareSolverr To Only Retrieve Valid Cloudflare Cookies
The other option is to use FlareSolverr to retrieve valid Cloudflare cookies after passing the Cloudflare challenge and then using these cookies with another HTTP client to scrape the subsequent pages you want to scrape.
This is the recommended way of using FlareSolverr but is a small bit trickier.
import requests
post_body = {
"cmd": "request.get",
"url":"https://www.petsathome.com/",
"maxTimeout": 60000
}
response = requests.post('http://localhost:8191/v1', headers={'Content-Type': 'application/json'}, json=post_body)
if response.status_code == 200:
json_response = response.json()
if json_response.get('status') == 'ok':
## Get Cookies & Clean
cookies = json_response['solution']['cookies']
clean_cookies_dict = {cookie['name']: cookie['value'] for cookie in cookies}
## Get User-Agent
user_agent = json_response['solution']['userAgent']
## Make normal request
headers={"User-Agent": user_agent}
response = requests.get("https://www.petsathome.com/", headers=headers, cookies=clean_cookies_dict)
if response.status_code == 200:
## ...parse data from response
print('Success')
Here we make the request with FlareSolverr to retrieve valid Cloudflare cookies after passing the Cloudflare challenge then we:
- Extract & clean the valid Cloudflare cookies
- Extract the user-agent FlareSolverr used to get the cookies
- Make a new requests with Python Requests using the FlareSolverr cookies & user-agent to avoid triggering the Cloudflare challenge
The Cloudflare cookies are linked to the user-agent and IP address that FlareSolverr used when solving the Cloudflare challenge so you need to make sure to use the same user-agent and IP address when making subsequent requests with a different HTTP client.
Controlling FlareSolverr Sessions
FlareSolverr V2 allowed you to control the creation and destruction of browser sessions, meaning that you can have multiple browser sessions running on the FlareSolverr server.
This meant you could have different browser sessions running for different websites, proxy settings, etc. and you can then choose which ever one you want to use.
An example for this, would be that you are scraping a Cloudflare protected website with a pool of proxy IP addresses. In this case, you will need a unique set of Cloudflare cookies for each IP address you use as otherwise Cloudflare could block the requests as your IP address is changing for a single cookie.
However, FlareSolverr V3 still doesn't support this functionality since the refactor so it is currently unavailable.
Making POST Requests With FlareSolverr
FlareSolverr also allows you to make POST requests to Cloudflare protected websites if you need to retrieve valid Cloudflare cookies from POST endpoints.
To do so, you simply need to use request.post instead of request.get in the cmd section of the FlareSolverr post body, and add any POST data you need to send in the postData value of the POST data:
import requests
post_body = {
"cmd": "request.post",
"url":"https://www.example.com/POST",
"postData": POST_DATA,
"maxTimeout": 60000
}
response = requests.post('http://localhost:8191/v1', headers={'Content-Type': 'application/json'}, json=post_body)
print(response.json())
The postData must be a string with application/x-www-form-urlencoded. Eg: a=b&c=d.
Alternatives To FlareSolverr
FlareSolverr is a powerful tool, however, open source solutions like FlareSolverr often go out of date and stop working due to Cloudflare updates.
Cloudflare and other anti-bots providers monitor the web for open source anti-bot bypassing tools and often develop fixes for them in a couple months that detect/block them.
So if you are thinking of using FlareSolverr to relibaly bypass Cloudflare on a website then an alternative is to use smart proxies that develop and maintain their own private anti-bot bypasses.
These are typically more reliable as it is harder for anti-bot companies like Cloudflare to develop detections for, as they are developed by proxy companies who are financially motivated to stay 1 step ahead of anti-bot companies and fix their bypasses the very minute they stop working.
One of the best options is the ScrapeOps Proxy Aggregator as it integrates over 20 smart proxy providers into the same proxy API, and finds the best/cheapest proxy provider for your target domains.
You can activate ScrapeOps' Anti-Bot Bypasses by simply using the bypass flag to your API request.
For example, the the below code we will use the Cloudflare bypass by adding bypass=cloudflare_level_1 to the request:
import requests
response = requests.get(
url='https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'http://example.com/', ## Cloudflare protected website
'bypass': 'cloudflare_level_1',
},
)
print('Body: ', response.content)
Cloudflare is the most common anti-bot system being used by websites today, and bypassing it depends on which security settings the website has enabled.
To combat this, we offer 3 different Cloudflare bypasses designed to solve the Cloudflare challenges at each security level.
| Security Level | Bypass | API Credits | Description |
|---|---|---|---|
| Low | cloudflare_level_1 | 10 | Use to bypass Cloudflare protected sites with low security settings enabled. |
| Medium | cloudflare_level_2 | 35 | Use to bypass Cloudflare protected sites with medium security settings enabled. On large plans the credit multiple will be increased to maintain a flat rate of $3.50 per thousand requests. |
| High | cloudflare_level_3 | 50 | Use to bypass Cloudflare protected sites with high security settings enabled. On large plans the credit multiple will be increased to maintain a flat rate of $4 per thousand requests. |
The advantage of taking this approach is that you can use your normal HTTP client and don't have to worry about:
- Fortifying headless browsers
- Managing numerous headless browser instances & dealing with memory issues
- Reverse engineering the anti-bot protection systems
As this is all managed within the ScrapeOps Proxy Aggregator.
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
More Scrapy Tutorials
In this guide we've introduced you to the fundamental functionality of Scrapy Splash and how to use it in your own projects.
However, if you would like to learn more about Scrapy Splash then check out the offical documentation here.
If you would like to learn more about different Javascript rendering options for Scrapy, then be sure to check out our other guides:
If you would like to learn more about Scrapy in general, then be sure to check out The Scrapy Playbook.