
Scrapy Splash Guide: A JS Rendering Service For Web Scraping
Developed by Zyte (formerly Scrapinghub), the creators of Scrapy, Scrapy Splash is a light weight browser with an HTTP API that you can use to scrape web pages that render data using Javascript or AJAX calls.
Although it is a bit outdated, it is the only headless browser that was specifically designed for web scraping, and has been heavily battletested by developers.
In this guide we're going to walk through how to setup and use Scrapy Splash, including:
- How To Install Docker
- Install & Run Scrapy Splash
- Use Scrapy Splash With Our Spiders
- Controling Scrapy Splash
- Running JavaScript Scripts
- Using Proxies With Scrapy Splash
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Base Scrapy Project
If you'd like to follow along with a project that is already setup and ready to go you can clone our scrapy project that is made espcially to be used with this tutorial.
Once you download the code from our github repo. You can just copy/paste in the code snippets we use below and see the code working correctly on your computer.
The only thing that you need to do after downloading the code is to install a python virtual environment. If you don't know how to do that you can check out our guide here
If you prefer video tutorials, then check out the video version of this article.
How To Install Docker
As Scrapy Splash comes in the form of a Docker Image, to install and use Scrapy Splash we first need to have Docker installed on our machine. So if you haven't Docker installed already then use one of the following links to install Docker:
Download the Docker installation package, and follow the instructions. Your computer may need to restart after installation.
After installation, if Docker isn't running then click the Docker Desktop icon. You can check that docker is by running the command in your command line:
docker
If it is recognized then you should be good to go.
Install & Run Scrapy Splash
Next we need to get Scrapy Splash up and running.
1. Download Scrapy Splash
First we need to download the Scrapy Splash Docker image, which we can do by running the following command on Windows or Max OS:
docker pull scrapinghub/splash
Or on a Linux machine:
sudo docker pull scrapinghub/splash
If everything has worked correctly, when you open you Docker Desktop on the Images tab you should see the scrapinghub/splash image.
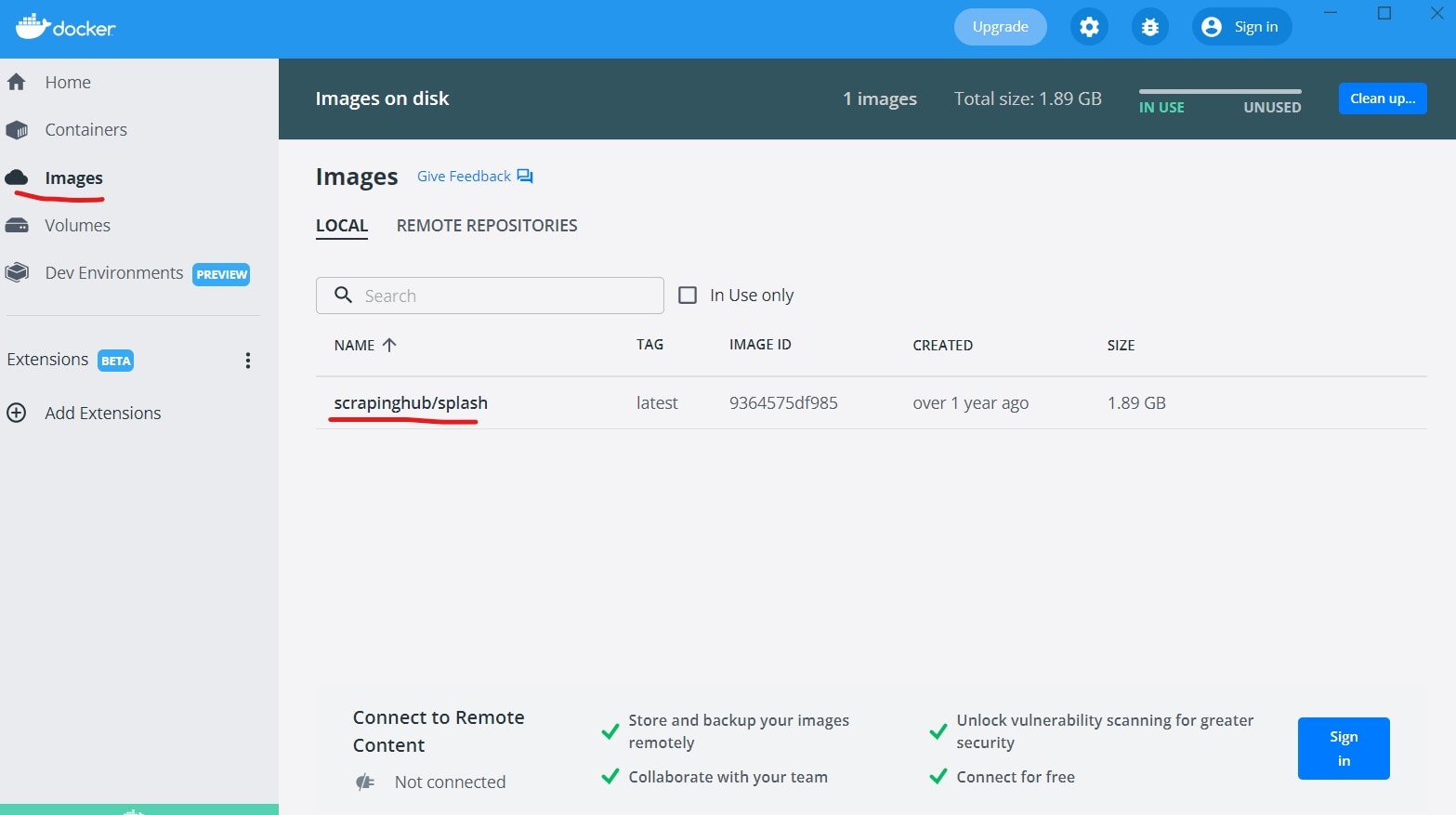
2. Run Scrapy Splash
To run Scrapy Splash, we need to run the following command in our command line again.
For Windows and Max OS:
docker run -it -p 8050:8050 --rm scrapinghub/splash
For Linux:
sudo docker run -it -p 8050:8050 --rm scrapinghub/splash
To check that Splash is running correctly, go to http://localhost:8050/ and you should see the following screen.

If you do then, Scrapy Splash is up and running correctly.
Use Scrapy Splash With Our Spiders
When running Splash provides a simple HTTP server that we can send the urls we want to scrape to it, then Splash will make the fetch the page, fully render the page and return the rendered page to our spider.
You can send requests directly to it using its API endpoint like this:
curl 'http://localhost:8050/render.html?url=https://quotes.toscrape.com/js/'
However, when using Scrapy we can use the scrapy-splash downloader integration.
1. Set Up Scrapy Splash Integration
To use Scrapy Splash in our project, we first need to install the scrapy-splash downloader.
pip install scrapy-splash
Then we need to add the required Splash settings to our Scrapy projects settings.py file.
# settings.py
# Splash Server Endpoint
SPLASH_URL = 'http://localhost:8050'
# Enable Splash downloader middleware and change HttpCompressionMiddleware priority
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# Enable Splash Deduplicate Args Filter
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# Define the Splash DupeFilter
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
2. Use Scrapy Splash In Spiders
To actually use Scrapy Splash in our spiders to render the pages we want to scrape we need to change the default Request to SplashRequest in our spiders.
# spiders/quotes.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(url, callback=self.parse)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
Now all our requests will be made through our Splash server and any javascript on the page will be rendered.
Controling Scrapy Splash
Like other headless browsers you can tell Scrapy Splash to do certain actions before returning the HTML response to your spider.
Splash can:
- Wait for page elements to load
- Scroll the page
- Click on page elements
- Take screenshots
- Turn off images or use Adblock rules to make rendering faster
You can configure Splash to do these actions through a combination of passing it arguments or using Lua Scripts.
We will go over the most common actions here but the Splash documentation has a scripting tutorial on how to write them.
1. Wait For Time
You can tell Splash to wait X number of seconds for updates after the initial page has loaded to make sure you get all the data you need by adding a wait agrument to your request:
# spiders/quotes.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(url, callback=self.parse, args={'wait': 0.5})
def parse(self, response):
...
2. Wait For Page Element
You can use a Lua script to wait for a specific element to appear on the page before it returns a response.
First, you create a Lua script:
function main(splash, args)
assert(splash:go(args.url))
while not splash:select('div.quote') do
splash:wait(0.1)
print('waiting...')
end
return {html=splash:html()}
end
Then load add this as a arg in your Splash request by converting it to a string, and telling sending the request to Splash's execute endpoint by adding endpoint='execute' to the request:
# spiders/quotes.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_splash import SplashRequest
lua_script = """
function main(splash, args)
assert(splash:go(args.url))
while not splash:select('div.quote') do
splash:wait(0.1)
print('waiting...')
end
return {html=splash:html()}
end
"""
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/scroll'
yield SplashRequest(
url,
callback=self.parse,
endpoint='execute',
args={'wait': 0.5, 'lua_source': lua_script, url :'https://quotes.toscrape.com/scroll'}
)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
3. Scrolling The Page
To scroll the page down when dealing with infinite scrolling pages you can use a Lua script like this.
function main(splash)
local num_scrolls = 10
local scroll_delay = 1.0
local scroll_to = splash:jsfunc("window.scrollTo")
local get_body_height = splash:jsfunc(
"function() {return document.body.scrollHeight;}"
)
assert(splash:go(splash.args.url))
splash:wait(splash.args.wait)
for _ = 1, num_scrolls do
scroll_to(0, get_body_height())
splash:wait(scroll_delay)
end
return splash:html()
end
And add it to our Splash like we did above:
# spiders/quotes.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_splash import SplashRequest
lua_script = """
function main(splash)
local num_scrolls = 10
local scroll_delay = 1.0
local scroll_to = splash:jsfunc("window.scrollTo")
local get_body_height = splash:jsfunc(
"function() {return document.body.scrollHeight;}"
)
assert(splash:go(splash.args.url))
splash:wait(splash.args.wait)
for _ = 1, num_scrolls do
scroll_to(0, get_body_height())
splash:wait(scroll_delay)
end
return splash:html()
end
"""
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/scroll'
yield SplashRequest(
url,
callback=self.parse,
endpoint='execute',
args={'wait': 2, 'lua_source': lua_script}
)
def parse(self, response):
...
4. Click Page Elements
To click on a button or page element you can use a simple javascript script like this.
# spiders/quotes.py
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_splash import SplashRequest
lua_script = """
function main(splash,args)
assert(splash:go(args.url))
local element = splash:select('body > div > nav > ul > li > a')
element:mouse_click()
splash:wait(splash.args.wait)
return splash:html()
end
"""
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(
url,
callback=self.parse,
endpoint='execute',
args={'wait': 2, 'lua_source': lua_script, url: 'https://quotes.toscrape.com/js/'}
)
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
5. Take Screenshot
You can take a screenshot of the fully rendered page, using Splash's screenshot functionality.
# spiders/quotes_screenshot.py
import scrapy
import base64
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes_screenshot'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(
url,
callback=self.parse,
endpoint='render.json',
args={
'html': 1,
'png': 1,
'width': 1000,
})
def parse(self, response):
imgdata = base64.b64decode(response.data['png'])
filename = 'some_image.png'
with open(filename, 'wb') as f:
f.write(imgdata)
Running JavaScript Scripts
You can configure Splash to run JavaScript code on the rendered page by using the js_source parameter.
In the following example we will first rename the top header on the page with javascript and then take a screenshot of the page.
The JavaScript code is executed after the page finished loading (including any delay defined by ‘wait’) but before the page is rendered. This allows to use the javascript code to modify the page being rendered.
import scrapy
from quotes_js_scraper.items import QuoteItem
import base64
from scrapy_splash import SplashRequest
javascript_script = """
element = document.querySelector('h1').innerHTML = 'The best quotes of all time!'
"""
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(
url,
callback=self.parse,
endpoint='render.json',
args={
'wait': 2,
'js_source': javascript_script,
'html': 1,
'png': 1,
'width': 1000,
})
def parse(self, response):
imgdata = base64.b64decode(response.data['png'])
filename = 'some_image.png'
with open(filename, 'wb') as f:
f.write(imgdata)
Using Proxies With Scrapy Splash
If you need to use proxies when scraping you can configure Splash to use your proxy by passing in the proxy details to the SplashRequest:
args={'proxy': 'http://scrapeops:YOUR_API_KEY_HERE@proxy.scrapeops.io:5353' }
In our example below we will show how it works if you are using the ScrapeOps Proxy API Aggregator.
The only part you should have to change is the YOUR_API_KEY_HERE - replace this with your scrapeops api key.
(Following code is working as of October 2023)
import scrapy
from quotes_js_scraper.items import QuoteItem
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
def start_requests(self):
url = 'https://quotes.toscrape.com/js/'
yield SplashRequest(url, callback=self.parse, args={'proxy': 'http://scrapeops:YOUR_API_KEY_HERE@proxy.scrapeops.io:5353' })
def parse(self, response):
quote_item = QuoteItem()
for quote in response.css('div.quote'):
quote_item['text'] = quote.css('span.text::text').get()
quote_item['author'] = quote.css('small.author::text').get()
quote_item['tags'] = quote.css('div.tags a.tag::text').getall()
yield quote_item
More Scrapy Tutorials
In this guide we've introduced you to the fundamental functionality of Scrapy Splash and how to use it in your own projects.
However, if you would like to learn more about Scrapy Splash then check out the offical documentation here.
If you would like to learn more about different Javascript rendering options for Scrapy, then be sure to check out our other guides:
If you would like to learn more about Scrapy in general, then be sure to check out The Scrapy Playbook.