
How to Scrape Walmart With Puppeteer
Walmart, one of the largest retail corporations globally, offers over 75 million products across its physical stores and e-commerce platform. Scraping Walmart can provide valuable insights for affiliate marketing, trend analysis, and optimizing e-commerce strategies.
In this guide, we’ll walk through how to scrape Walmart's website using NodeJS and the Puppeteer library.
- TLDR - How to Scrape Walmart
- How to Architect Our Walmart Scraper
- Understanding How to Scrape Walmart
- Build a Walmart Search Scraper
- Build a Walmart Product Data Scraper
- Legal and Ethical Considerations
- Conclusion
- More Puppeteer and NodeJS Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Scrape Walmart
If you're short on time or just need the scraper code, follow these steps:
-
Create a new directory called "Walmart Scraper" and add the following
package.jsonfile:{
"name": "walmart",
"version": "1.0.0",
"main": "walmart-scraper.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"dependencies": {
"csv-parser": "^3.0.0",
"json2csv": "^6.0.0-alpha.2",
"puppeteer": "^23.10.0",
"winston": "^3.17.0"
}
} -
Install dependencies by running
npm install. -
Create a
config.jsonfile and add your ScrapeOps API key to prevent being blocked by Walmart:{
"api_key": "your_api_key"
}If you don’t have an API key, sign up for ScrapeOps and get 1,000 free API credits.
-
Copy the scraper code into a file named "walmart-scraper.js" and run it with
node walmart-scraper.js:const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const LOCATION = 'us';
const MAX_RETRIES = 2;
const MAX_THREADS = 2;
const MAX_PAGES = 2;
const keywords = ['airpods', 'candles'];
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductURL {
constructor(url) {
this.url = this.validateUrl(url);
}
validateUrl(url) {
if (typeof url === 'string' && url.trim().startsWith('https://www.walmart.com')) {
return url.trim();
}
return 'Invalid URL';
}
}
class ProductData {
constructor(data = {}) {
this.id = data.id || "Unknown ID";
this.type = data.type || "Unknown Type";
this.name = this.validateString(data.name, "No Name");
this.brand = this.validateString(data.brand, "No Brand");
this.averageRating = data.averageRating || 0;
this.shortDescription = this.validateString(data.shortDescription, "No Description");
this.thumbnailUrl = data.thumbnailUrl || "No Thumbnail URL";
this.price = data.price || 0;
this.currencyUnit = data.currencyUnit || "USD";
}
validateString(value, fallback) {
if (typeof value === 'string' && value.trim() !== '') {
return value.trim();
}
return fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeProductUrls(dataPipeline, keyword, maxPages = MAX_PAGES, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
for (let pageNum = 1; pageNum <= maxPages; pageNum++) {
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
logger.info(`Fetching: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
if (data) {
const items = data.props?.pageProps?.initialData?.searchResult?.itemStacks?.[0]?.items || [];
for (const item of items) {
const url = new ProductURL('https://www.walmart.com' + (item.canonicalUrl || '').split('?')[0]);
await dataPipeline.addData({ title: item.name, url: url.url });
}
// Break the loop if no products are found
if (items.length === 0) {
logger.info('No more products found.');
break;
}
} else {
logger.warn('No data found on this page.');
}
}
} catch (error) {
logger.error(`Error during scraping: ${error.message}`);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
} finally {
await browser.close();
await dataPipeline.closePipeline();
}
}
}
async function scrapeProductData(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
logger.info(`Fetching: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
const productData = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
const jsonBlob = JSON.parse(scriptTag.textContent);
const rawProductData = jsonBlob.props?.pageProps?.initialData?.data?.product;
if (rawProductData) {
return {
id: rawProductData.id,
type: rawProductData.type,
name: rawProductData.name,
brand: rawProductData.brand,
averageRating: rawProductData.averageRating,
shortDescription: rawProductData.shortDescription,
thumbnailUrl: rawProductData.imageInfo?.thumbnailUrl,
price: rawProductData.priceInfo?.currentPrice?.price,
currencyUnit: rawProductData.priceInfo?.currentPrice?.currencyUnit,
};
}
}
return null;
});
if (productData) {
await dataPipeline.addData(new ProductData(productData));
} else {
logger.info(`No product data found for ${url}`);
}
break;
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`, error);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
await browser.close();
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
(async () => {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
const scrapeProductUrlsTasks = keywords.map(keyword => async () => {
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-urls.csv`;
const dataPipeline = new DataPipeline(csvFilename);
await scrapeProductUrls(dataPipeline, keyword);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
await scrapeConcurrently(scrapeProductUrlsTasks, MAX_THREADS);
const urls = await getAllUrlsFromFiles(aggregateFiles);
const scrapeProductDataTasks = urls.flatMap(data =>
data.urls.map(url => async () => {
const filename = data.filename.replace('urls', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
})
);
await scrapeConcurrently(scrapeProductDataTasks, MAX_THREADS);
logger.info('Scraping completed.');
})();
When you run the scraper, it will collect product details like ID, type, name, brand, average rating, short description, thumbnail URL, price, currency unit, and more for the keywords "airpods" and "candles" across the first two pages. It will scrape all products listed on these pages.
However, you can easily modify the scraper to target different keywords or change other settings. Here are some constants you can adjust to suit your needs:
LOCATION: The country where you want to scrape products from (default: 'us').MAX_RETRIES: The maximum number of retry attempts for failed requests (default: 2).MAX_THREADS: The maximum number of concurrent threads to scrape data (default: 2).MAX_PAGES: The number of pages to scrape per keyword (default: 2).keywords: The list of search terms you want to scrape (default: ['airpods', 'candles']).
Feel free to tweak these constants in the code according to your requirements.
How to Architect Our Walmart Scraper
Our Walmart scraper will consist of two main components: scrapeProductUrls and scrapeProductData.
scrapeProductUrls
This scraper runs first and collects the URLs for the products based on a provided keyword. For instance, if the keyword is "candles", the scraper will search Walmart using the URL:
https://www.walmart.com/search?q=candles&sort=best_seller&page=1&affinityOverride=default
In this URL, the query parameter q=candles is the keyword and page=1 specifies the page number. These values will change dynamically when you modify the keyword or move to a different page.
The scraper will extract all product URLs from this page using a method we'll cover later in the guide. These URLs will be saved in a file named after the keyword, e.g., "candles-urls.csv".
Example of the data scraped:
{
"title": "Way to Celebrate! Gold Birthday Candle, Number 1",
"url": "https://www.walmart.com/ip/Way-to-Celebrate-Gold-Birthday-Candle-Number-1/759950640"
}
scrapeProductData
The second scraper will read the URLs from the file generated by the first scraper. It will navigate to each product page and scrape important details like product name, type, brand, short description, average rating, thumbnail URL, price, and currency unit. This data will be saved in a file named after the keyword, such as "candles-product-data.csv".
Example of the data scraped:
{
"id": "24PEFGU3B1AV",
"type": "Birthday Candles",
"name": "Way to Celebrate! Gold Birthday Candle, Number 1",
"brand": "Way To Celebrate",
"averageRating": 4.7,
"shortDescription": "<p>Way to Celebrate Celebrate in style with this Gold Mini Number Candle...</p>",
"thumbnailUrl": "https://i5.walmartimages.com/seo/Way-to-Celebrate-Gold-Birthday-Candle-Number-1_6035f18a-177a-4ea7-bacc-136d90d67d7f.adbada876f66bb3e19cd25936deaadc8.jpeg",
"price": 0.97,
"currencyUnit": "USD"
}
This architecture breaks the task into two phases: the first phase collects the product URLs, and the second phase gathers detailed product data.
Understanding How to Scrape Walmart
Walmart has anti-bot protection that prevents unauthorized scraping. If you attempt to scrape Walmart without taking precautions—such as using the ScrapeOps API—you’ll likely be blocked immediately. For instance:

On the bright side, scraping Walmart is relatively straightforward because all the data we need is available as a JSON response. It is embedded within a <script> tag on the page:
<script id="__NEXT_DATA__" type="application/json" nonce="">
{
...DATA...
}
</script>
This means we don’t need to rely on CSS selectors to locate the data. Instead, we can directly parse the JSON response to extract the information we need.
Let’s break down the process into simple, easy-to-follow steps:
Step 1: How To Request Walmart Pages
Let’s start by understanding how Walmart’s URLs work when performing a search. Open the Walmart site in your browser and search for a keyword.
For example, when we searched for "airpods" and navigated to page 2, the URL looked like this:
https://www.walmart.com/search?q=airpods&page=2&affinityOverride=default
This shows that the URL structure uses q=airpods for the search keyword and page=2 for pagination.
To navigate programmatically, we just need to replace it with q={your_keyword} and page={page_number}, and it will take us directly to the desired search results page.
Here’s how you can dynamically construct the URL in JavaScript:
const keyword = "airpods"
const page = 1
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${page}&affinityOverride=default`
We’ll use Puppeteer to navigate to this URL, scrape all the product URLs, and save them to a file. Later, the scrapeProductData scraper will read these URLs from the file, visit each individual product page, and extract the product data.
This is the core mechanism for requesting and navigating Walmart pages.
Step 2: How To Extract Data From Walmart
As mentioned earlier, all the data we need is available as a JSON blob within a <script> tag with the ID __NEXT_DATA__.
To see this in action, right-click on the Walmart site you opened in the previous section and select "View Page Source". Then press Ctrl+F (or Cmd+F on Mac) to open the search bar and type script id="__NEXT_DATA__". This will highlight the relevant portion of the HTML, which looks like this:
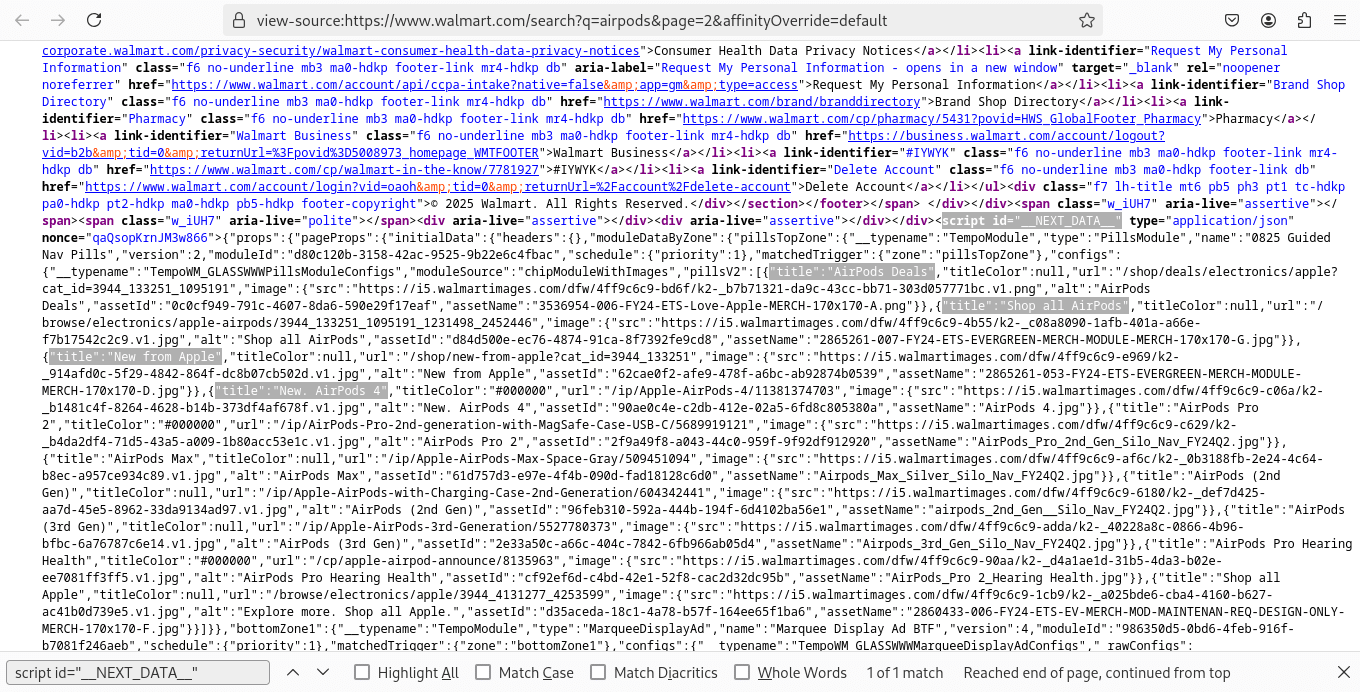
You’ll notice that the JSON contains all the product information we need. In the screenshot, some product titles are highlighted to illustrate this.
To extract this data using Puppeteer, we’ll run the following code:
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
Once we have this JSON, we can query it to pinpoint specific pieces of information.
The <script> tag is present in both the search results pages (listing products for a given keyword) and individual product pages. This means both our scrapers, scrapeProductUrls and scrapeProductData, will use the same strategy to extract data.
Step 3: How to Bypass Anti-Bots and Handle Geolocation
Walmart actively detects and blocks bots attempting to scrape their site, but thankfully, we have an easy solution: ScrapeOps Proxy.
Upon signing up, ScrapeOps provides 1,000 free API credits, which are more than enough for this demo. It not only bypasses anti-bot measures but also handles geolocation.
Using ScrapeOps is straightforward. After signing up and obtaining your API key, you can integrate it into your code like this:
const LOCATION = 'us';
const api_key = YOUR_API_KEY;
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: api_key,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
In the example above, we use 'us' for the United States location. To scrape data specific to other countries, simply replace 'us' with the appropriate country code, such as 'uk' for the United Kingdom.
Whenever you navigate to a Walmart page using Puppeteer’s page.goto() method, just wrap your URL with the getScrapeOpsUrl function:
await page.goto(getScrapeOpsUrl(url))
With ScrapeOps handling anti-bot protection and geolocation for us, we can scrape Walmart pages conveniently. Now that you understand these essential concepts, let’s dive into writing the actual code for our Walmart scraper.
Build a Walmart Search Scraper
In this section, we'll build our first scraper, scrapeProductUrls, to extract product URLs from Walmart search results for a given keyword. Here's what we'll cover:
- Extracting product titles and URLs from multiple pages for a specific keyword.
- Cleaning and structuring the data using well-defined classes.
- Incrementally saving the scraped data in a CSV file through a Data Pipeline.
- Using concurrency to improve the scraping speed.
- Implementing anti-bot measures to prevent getting blocked.
Step 1: Create a Simple Search Data Scraper
In this step, we’ll create our first scraper, scrapeProductUrls, to extract product URLs from Walmart search results for a given keyword. Here's a detailed explanation of the code and how it works:
- URL Construction: The scraper constructs a Walmart search URL for the given
keywordandpageNum:
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
This URL directs to Walmart's search page for the given keyword, with pagination handled by adjusting the page parameter.
-
Navigating Pages: The scraper iterates over the desired number of pages (
MAX_PAGES) and navigates to each page using Puppeteer'spage.goto()method, ensuring the page is fully loaded before extracting data. -
Extracting Data: The scraper extracts the JSON data embedded in the
<script id=__NEXT_DATA__>tag, which contains all the product details:const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
This data is parsed to retrieve the product items, including product names and URLs.
-
Handling Retries: If the scraping process encounters issues (e.g., network errors), the scraper will retry the process up to a specified number of times (
MAX_RETRIES). -
Error Handling: The scraper is equipped with error handling (
try-catch) to log any issues encountered during scraping and retry the process if necessary. -
Logging: The scraping process is logged using the winston logging library. Logs include info on successful requests, warnings for missing data, and errors during the scraping process. This will help in monitoring and debugging.
-
Print Data: The extracted product URLs and titles onto the console. In the next steps, we'll utilize a Data Pipeline to handle storing the data in CSV format.
Here's the implementation:
const puppeteer = require('puppeteer');
const winston = require('winston');
const MAX_RETRIES = 2;
const MAX_PAGES = 2;
const keyword = 'candles';
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
async function scrapeProductUrls(keyword, maxPages = MAX_PAGES, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
while (retries > 0) {
try {
for (let pageNum = 1; pageNum <= maxPages; pageNum++) {
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
if (data) {
const items = data.props?.pageProps?.initialData?.searchResult?.itemStacks?.[0]?.items || [];
for (const item of items) {
const url = 'https://www.walmart.com' + (item.canonicalUrl || '').split('?')[0];
console.log({ title: item.name, url: url });
}
if (items.length === 0) {
logger.info('No more products found.');
break;
}
} else {
logger.warn('No data found on this page.');
}
}
} catch (error) {
logger.error(`Error during scraping: ${error.message}`);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
} finally {
await browser.close();
}
}
}
(async () => {
logger.info("Started Scraping Search Results")
await scrapeProductUrls(keyword);
logger.info('Scraping completed.');
})();
The scraper will extract product titles and URLs for the given keyword across multiple pages, and the results will look like this:
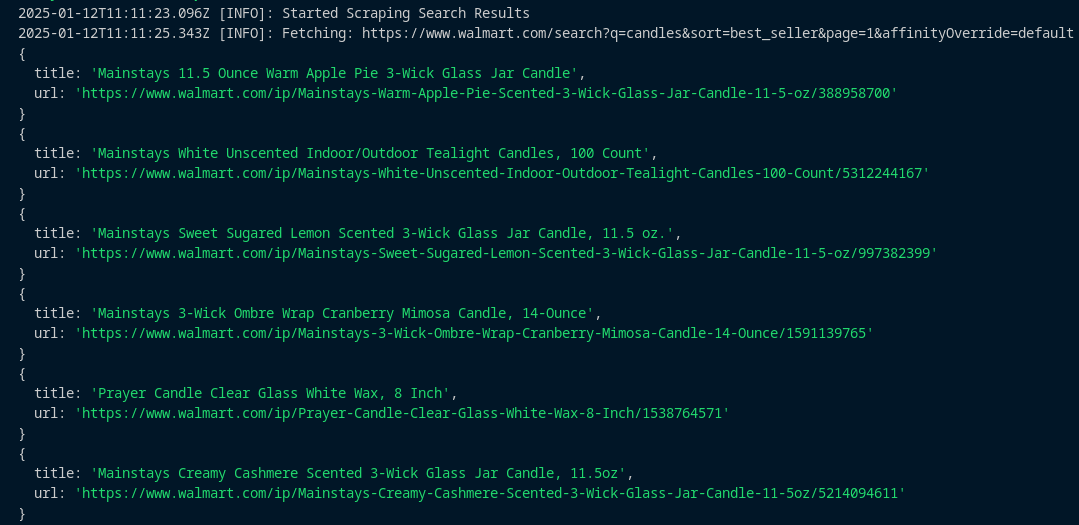
Step 2: Storing the Scraped Data
In the previous step, we focused on scraping product URLs and titles from Walmart. Now, we will organize and store this data into a structured format, ensuring that it is persistent and clean. For this, we will:
- Create a
ProductURLClass: This class will validate and structure the scraped data. - Design a
DataPipelineClass: This class will handle deduplication, batching, and efficient storage of data into a CSV file.
ProductURL Class: Validating and Structuring Data
The ProductURL class is responsible for validating and transforming raw data into clean JavaScript objects. Here is the implementation:
class ProductURL {
constructor(data = {}) {
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
return typeof title === 'string' && title.trim() !== '' ? title.trim() : 'No Title';
}
validateUrl(url) {
if (typeof url === 'string' && url.startsWith('https://www.walmart.com')) {
return url.trim();
}
return 'Invalid URL';
}
}
- Title Validation: Ensures the title is a non-empty string. Defaults to "No Title" if invalid.
- URL Validation: Confirms that the URL starts with "https://www.walmart.com". Invalid URLs are marked as "Invalid URL".
DataPipeline Class: Managing Storage and Deduplication
The DataPipeline class ensures data is stored efficiently and avoids duplicates by tracking titles that have already been added. It uses batching to write data to a CSV file.
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.csvFilename = csvFilename;
this.storageQueueLimit = storageQueueLimit;
this.storageQueue = [];
this.seenTitles = new Set();
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToWrite = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToWrite.length > 0) {
const csvData = parse(dataToWrite, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
}
isDuplicate(title) {
if (this.seenTitles.has(title)) {
logger.warn(`Duplicate item detected: ${title}. Skipping.`);
return true;
}
this.seenTitles.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) {
await this.saveToCsv();
}
}
}
- Deduplication: Tracks seen titles using a Set.
- Batching: Writes data to a CSV file only when the queue reaches the storage limit.
- CSV Storage: Uses the json2csv library to convert objects to CSV format.
Full Implementation: Scraping and Storing Walmart Data
Below is the complete implementation, including the scraper, the ProductURL class, and the DataPipeline class:
const puppeteer = require('puppeteer');
const winston = require('winston');
const { parse } = require('json2csv');
const fs = require('fs');
const path = require('path');
const MAX_RETRIES = 2;
const MAX_PAGES = 2;
const keyword = 'candles';
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductURL {
constructor(data = {}) {
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
return typeof title === 'string' && title.trim() !== '' ? title.trim() : 'No Title';
}
validateUrl(url) {
if (typeof url === 'string' && url.startsWith('https://www.walmart.com')) {
return url.trim();
}
return 'Invalid URL';
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.csvFilename = csvFilename;
this.storageQueueLimit = storageQueueLimit;
this.storageQueue = [];
this.seenTitles = new Set();
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToWrite = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToWrite.length > 0) {
const csvData = parse(dataToWrite, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
}
isDuplicate(title) {
if (this.seenTitles.has(title)) {
logger.warn(`Duplicate item detected: ${title}. Skipping.`);
return true;
}
this.seenTitles.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) {
await this.saveToCsv();
}
}
}
async function scrapeProductUrls(dataPipeline, keyword, maxPages = MAX_PAGES, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
for (let pageNum = 1; pageNum <= maxPages; pageNum++) {
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
if (data) {
const items = data.props?.pageProps?.initialData?.searchResult?.itemStacks?.[0]?.items || [];
for (const item of items) {
const productData = new ProductURL({
title: item.name,
url: 'https://www.walmart.com' + (item.canonicalUrl || '').split('?')[0]
});
await dataPipeline.addData(productData);
}
if (items.length === 0) {
logger.info('No more products found.');
break;
}
} else {
logger.warn('No data found on this page.');
}
}
break;
} catch (error) {
logger.error(`Error during scraping: ${error.message}`);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
await browser.close();
}
(async () => {
logger.info('Started Walmart Scraping');
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-urls.csv`;
const dataPipeline = new DataPipeline(csvFilename);
await scrapeProductUrls(dataPipeline, keyword);
await dataPipeline.closePipeline();
logger.info('Scraping completed.');
})();
The scraped data will be stored in a CSV file named "candles-urls.csv", like this:
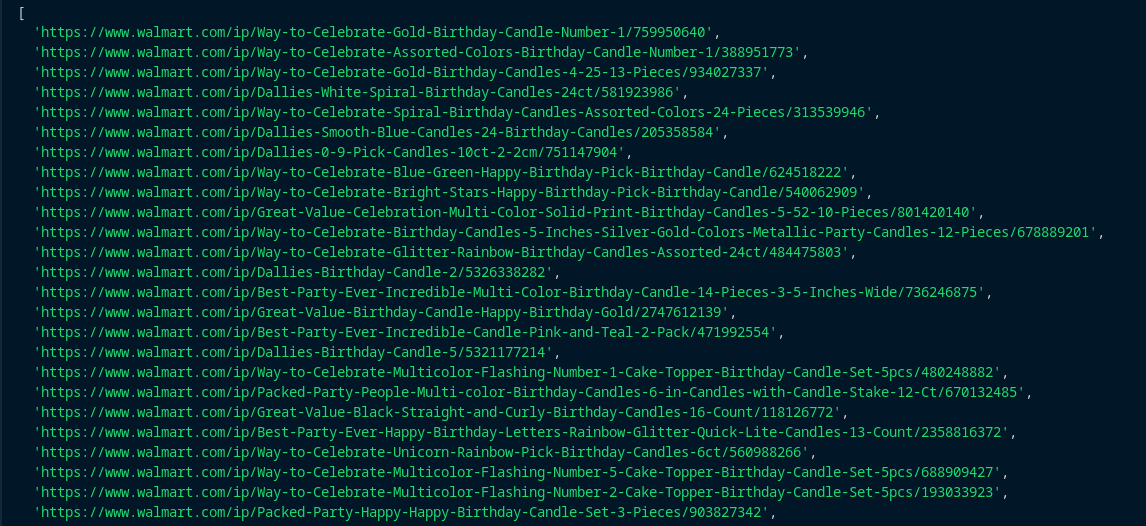
Step 3: Adding Concurrency
When dealing with multiple keywords, processing them sequentially can be time-consuming, as each keyword is scraped one at a time.
To enhance efficiency, we can introduce concurrency by launching multiple Puppeteer browser instances simultaneously. This allows us to handle multiple scraping tasks concurrently.
To achieve this, we implement a function called scrapeConcurrently, which manages the concurrent execution of tasks. This function ensures that no more than a specified number of tasks (maxConcurrency) run simultaneously.
Here’s the approach:
scrapeConcurrently Function:
The scrapeConcurrently function accepts a list of asynchronous tasks and a maximum concurrency limit. It maintains a set of executing tasks and processes new ones as slots become available.
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
Next, we integrate this function into our scraper to enable concurrent processing. Here's the updated workflow:
const puppeteer = require('puppeteer');
const winston = require('winston');
const { parse } = require('json2csv');
const fs = require('fs');
const path = require('path');
const MAX_RETRIES = 2;
const MAX_PAGES = 2;
const MAX_THREADS = 2;
const keywords = ['airpods', 'candles'];
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductURL {
constructor(data = {}) {
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
return typeof title === 'string' && title.trim() !== '' ? title.trim() : 'No Title';
}
validateUrl(url) {
if (typeof url === 'string' && url.startsWith('https://www.walmart.com')) {
return url.trim();
}
return 'Invalid URL';
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.csvFilename = csvFilename;
this.storageQueueLimit = storageQueueLimit;
this.storageQueue = [];
this.seenTitles = new Set();
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToWrite = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToWrite.length > 0) {
const csvData = parse(dataToWrite, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
}
isDuplicate(title) {
if (this.seenTitles.has(title)) {
logger.warn(`Duplicate item detected: ${title}. Skipping.`);
return true;
}
this.seenTitles.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) {
await this.saveToCsv();
}
}
}
async function scrapeProductUrls(dataPipeline, keyword, maxPages = MAX_PAGES, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
for (let pageNum = 1; pageNum <= maxPages; pageNum++) {
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
if (data) {
const items = data.props?.pageProps?.initialData?.searchResult?.itemStacks?.[0]?.items || [];
for (const item of items) {
const productData = new ProductURL({
title: item.name,
url: 'https://www.walmart.com' + (item.canonicalUrl || '').split('?')[0]
});
await dataPipeline.addData(productData);
}
if (items.length === 0) {
logger.info('No more products found.');
break;
}
} else {
logger.warn('No data found on this page.');
}
}
break;
} catch (error) {
logger.error(`Error during scraping: ${error.message}`);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
await browser.close();
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info('Started Walmart Scraping');
const aggregateFiles = [];
const scrapeProductUrlsTasks = keywords.map(keyword => async () => {
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-urls.csv`;
const dataPipeline = new DataPipeline(csvFilename);
await scrapeProductUrls(dataPipeline, keyword);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
await scrapeConcurrently(scrapeProductUrlsTasks, MAX_THREADS);
logger.info('Scraping completed.');
})();
-
Use
MAX_THREADSto specify the maximum number of concurrent Puppeteer instances. This allows flexibility to adjust the concurrency based on system resources. -
Modify the Puppeteer options to toggle between
headless: trueandheadless: falsefor visibility during execution.
Now, executing the code with multiple keywords will enable concurrent scraping. This setup efficiently handles large keyword lists while maintaining flexibility to adjust concurrency limits as needed.
Step 4: Bypassing Anti-Bots
To bypass anti-bots, we'll use the ScrapeOps Proxy API. This will help us get around anti-bot measures and anything else trying to block our scraper.
We'll create a function called getScrapeOpsUrl(). This function takes a url and a location, along with a wait parameter that tells ScrapeOps how long to wait before sending back the results.
The function combines all of this into a proxied URL with our custom settings.
const LOCATION = "us";
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
Key parameters:
- api_key: Contains the ScrapeOps API key, retrieved from the
config.jsonfile. - url: Specifies the target URL to scrape.
- country: Defines the routing location for the request, defaulting to "us".
- wait: Sets the wait time (in milliseconds) before ScrapeOps returns the response.
After integrating proxy support into our scraper, the updated implementation will be:
const puppeteer = require('puppeteer');
const winston = require('winston');
const { parse } = require('json2csv');
const fs = require('fs');
const path = require('path');
const MAX_RETRIES = 2;
const MAX_PAGES = 2;
const MAX_THREADS = 2;
const keywords = ['airpods', 'candles'];
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductURL {
constructor(data = {}) {
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
return typeof title === 'string' && title.trim() !== '' ? title.trim() : 'No Title';
}
validateUrl(url) {
if (typeof url === 'string' && url.startsWith('https://www.walmart.com')) {
return url.trim();
}
return 'Invalid URL';
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.csvFilename = csvFilename;
this.storageQueueLimit = storageQueueLimit;
this.storageQueue = [];
this.seenTitles = new Set();
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToWrite = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToWrite.length > 0) {
const csvData = parse(dataToWrite, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
}
isDuplicate(title) {
if (this.seenTitles.has(title)) {
logger.warn(`Duplicate item detected: ${title}. Skipping.`);
return true;
}
this.seenTitles.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) {
await this.saveToCsv();
}
}
}
async function scrapeProductUrls(dataPipeline, keyword, maxPages = MAX_PAGES, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
for (let pageNum = 1; pageNum <= maxPages; pageNum++) {
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
logger.info(`Fetching: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
if (data) {
const items = data.props?.pageProps?.initialData?.searchResult?.itemStacks?.[0]?.items || [];
for (const item of items) {
const productData = new ProductURL({
title: item.name,
url: 'https://www.walmart.com' + (item.canonicalUrl || '').split('?')[0]
});
await dataPipeline.addData(productData);
}
if (items.length === 0) {
logger.info('No more products found.');
break;
}
} else {
logger.warn('No data found on this page.');
}
}
break;
} catch (error) {
logger.error(`Error during scraping: ${error.message}`);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
await browser.close();
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info('Started Walmart Scraping');
const aggregateFiles = [];
const scrapeProductUrlsTasks = keywords.map(keyword => async () => {
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-urls.csv`;
const dataPipeline = new DataPipeline(csvFilename);
await scrapeProductUrls(dataPipeline, keyword);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
await scrapeConcurrently(scrapeProductUrlsTasks, MAX_THREADS);
logger.info('Scraping completed.');
})();
Step 5: Production Run
Now let's run our scraper and evaluate its performance. We will search for the following keywords and configuration:
const MAX_PAGES = 2;
const MAX_THREADS = 2;
const keywords = ["airpods", "candles"];
To execute the scraper, run the following command in your terminal:
node walmart-scraper.js
From the Winston logs, we observed that our scraper completed in approximately 18 seconds while using two Puppeteer instances running in parallel. Given that we processed two keywords with two pages each, the calculation breaks down as follows:
- Total tasks: 2 keywords × 2 pages = 4 tasks
- Average time per task: 18 seconds / 4 tasks = 4.5 seconds per task
An average of 4.5 seconds per task is a strong performance for our setup. This efficient runtime demonstrates how using concurrency with two Puppeteer instances and ScrapeOps proxy support can significantly improve scraping speed while maintaining stability.
Build a Walmart Product Data Scraper
With the scrapeProductUrls scraper successfully generating CSV files, the next step is to build the second scraper, scrapeProductData. Here's how it will work:
- Extract all Walmart product URLs from the CSV files created by the first scraper.
- Visit each product URL to scrape detailed product data
- Gather product details like the type, brand, title, rating, and price, etc.
- Clean and organize the scraped data into a structured format using data classes.
- Use concurrent browser instances to speed up the scraping process for multiple product pages.
- Add mechanisms to bypass Walmart's anti-bot measures for uninterrupted scraping.
By implementing these steps, the scrapeProductData scraper will allow us to gather in-depth product details efficiently while maintaining scalability and reliability.
Step 1: Create a Simple Product Data Scraper
In this section, we will develop the logic to scrape product details from Walmart. Here’s the workflow for how the scraper will operate:
- Navigate to the Walmart product page URL.
- Wait for the page to fully load HTML using
domcontentloaded. - Extract relevant product details such as title, price, brand, description, and ratings from the page.
- Print the scraped data to the console for validation.
Below is the implementation:
const puppeteer = require('puppeteer');
const winston = require('winston');
const fs = require('fs');
const MAX_RETRIES = 3;
const url = "https://www.walmart.com/ip/2021-Apple-10-2-inch-iPad-Wi-Fi-64GB-Space-Gray-9th-Generation/483978365";
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
async function scrapeProductData(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const productData = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
const jsonBlob = JSON.parse(scriptTag.textContent);
const rawProductData = jsonBlob.props?.pageProps?.initialData?.data?.product;
if (rawProductData) {
return {
id: rawProductData.id,
name: rawProductData.name,
brand: rawProductData.brand,
averageRating: rawProductData.averageRating,
shortDescription: rawProductData.shortDescription,
thumbnailUrl: rawProductData.imageInfo?.thumbnailUrl,
price: rawProductData.priceInfo?.currentPrice?.price,
currencyUnit: rawProductData.priceInfo?.currentPrice?.currencyUnit,
};
}
}
return null;
});
if (productData) {
console.log(productData);
logger.info(`Successfully scraped product data for ${url}`);
} else {
logger.warn(`No product data found for ${url}`);
}
break;
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`, error);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
logger.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
await browser.close();
}
(async () => {
logger.info("Started Scraping");
await scrapeProductData(url);
logger.info('Scraping completed.');
})();
- We manually provide a single
urlfor testing. - The scraper retries up to
MAX_RETRIEStimes in case of errors. - Extracts information like name, price, brand, averageRating, and shortDescription from Walmart’s page.
- Logs scraping activities using the winston library.
After running the script, the console will display the scraped data:
2025-01-12T12:00:00.123Z [INFO]: Fetching: https://www.walmart.com/ip/2021-Apple-10-2-inch-iPad-Wi-Fi-64GB-Space-Gray-9th-Generation/483978365
2025-01-12T12:00:10.567Z [INFO]: Successfully scraped product data for https://www.walmart.com/ip/2021-Apple-10-2-inch-iPad-Wi-Fi-64GB-Space-Gray-9th-Generation/483978365
{
id: '4SR8VU90LQ0P',
type: 'Tablet Computers',
name: '2021 Apple 10.2-inch iPad Wi-Fi 64GB - Space Gray (9th Generation)',
brand: 'Apple',
averageRating: 4.7,
shortDescription: '<p><strong> Delightfully capable. Surprisingly affordable. </strong><br> </p><p><strong> iPad. More function. More fun. <br> </strong></p><p><strong>Powerful. Easy to use. Versatile. iPad has a beautiful 10.2-inch Retina display,1 powerful A13 Bionic chip, and an Ultra Wide front camera with Center Stage. Work, play, create, learn, stay connected, and more. All at an incredible value. </strong></p><p></p>',
thumbnailUrl: 'https://i5.walmartimages.com/seo/2021-Apple-10-2-inch-iPad-Wi-Fi-64GB-Space-Gray-9th-Generation_611e6938-abd6-4af7-976b-682f5bb25ea0.27993cd01177da4dd6c82b6aea862d96.jpeg',
price: 278,
currencyUnit: 'USD'
}
2025-01-12T12:00:10.568Z [INFO]: Scraping completed.
This scraper forms the foundation for extracting detailed product data from Walmart. Future enhancements could include concurrency and storage in CSV
Step 2: Loading URLs To Scrape
To improve the efficiency of our Walmart product data scraper, we will load product URLs from a CSV file. Instead of manually entering each URL, we will use the "candles-urls.csv" file that contains all the URLs to scrape. Here's how the process works:
- Read the "candles-urls.csv" file, which contains the URLs of the products.
- Extract all the URLs from the CSV file.
- Store these URLs in an array to iterate over them and scrape each one.
Below is the implementation for reading the CSV file and extracting the URLs:
const fs = require('fs');
const csv = require('csv-parser');
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
async function main() {
const aggregateFiles = ["candles-urls.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
console.log(urls);
}
main();
How It Works:
- The
readCsvAndGetUrlsfunction reads the CSV file and extracts URLs from the url field. - The
getAllUrlsFromFilesfunction aggregates URLs from multiple CSV files by callingreadCsvAndGetUrlsfor each file. - For testing, we specify "candles-urls.csv" as the input file and log the extracted URLs to the console.
When you run the script, the URLs will be displayed in an array:
Integration with Main Scraper:
To integrate this into the main Walmart product data scraper, we will loop through all the URLs loaded from the CSV file and scrape each one sequentially.
Here’s the updated implementation with integrated URL loading:
const puppeteer = require('puppeteer');
const winston = require('winston');
const fs = require('fs');
const csv = require('csv-parser');
const MAX_RETRIES = 3;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
async function scrapeProductData(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const productData = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
const jsonBlob = JSON.parse(scriptTag.textContent);
const rawProductData = jsonBlob.props?.pageProps?.initialData?.data?.product;
if (rawProductData) {
return {
id: rawProductData.id,
name: rawProductData.name,
brand: rawProductData.brand,
averageRating: rawProductData.averageRating,
shortDescription: rawProductData.shortDescription,
thumbnailUrl: rawProductData.imageInfo?.thumbnailUrl,
price: rawProductData.priceInfo?.currentPrice?.price,
currencyUnit: rawProductData.priceInfo?.currentPrice?.currencyUnit,
};
}
}
return null;
});
if (productData) {
console.log(productData);
logger.info(`Successfully scraped product data for ${url}`);
} else {
logger.warn(`No product data found for ${url}`);
}
break;
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`, error);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
logger.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
await browser.close();
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
(async () => {
logger.info("Started Scraping");
const aggregateFiles = ["candles-urls.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
for (let url of urls) {
await scrapeProductData(url);
}
logger.info('Scraping completed.');
})();
How It Works:
- The scraper first loads URLs from the "candles-urls.csv" file using the
getAllUrlsFromFilesfunction. - After retrieving the URLs, it loops through each one and calls
scrapeProductDatato scrape the relevant product details from Walmart.
When the scraper runs, it processes each URL from the CSV file and logs the product data:
This approach enables scalable scraping by reading URLs from a CSV file and processing each one sequentially.
Step 3: Storing the Scraped Data
We will transform the raw scraped data into structured data and store it in CSV files. The key components are:
- The
ProductDataclass, which is responsible for validating and transforming the raw product data into structured JavaScript objects. - The
DataPipelineclass, which manages deduplication, batching, and efficient storage of the product data in CSV files.
ProductData Class: Transforming and Validating Data
The ProductData class ensures that each field has a valid value. Here's the implementation:
class ProductData {
constructor(data = {}) {
this.id = data.id || "Unknown ID";
this.type = data.type || "Unknown Type";
this.name = this.validateString(data.name, "No Name");
this.brand = this.validateString(data.brand, "No Brand");
this.averageRating = data.averageRating || 0;
this.shortDescription = this.validateString(data.shortDescription, "No Description");
this.thumbnailUrl = data.thumbnailUrl || "No Thumbnail URL";
this.price = data.price || 0;
this.currencyUnit = data.currencyUnit || "USD";
}
validateString(value, fallback) {
if (typeof value === 'string' && value.trim() !== '') {
return value.trim();
}
return fallback;
}
}
This class validates the fields such as product ID, type, name, brand, description, price, etc., ensuring they have a fallback value if they are empty or invalid.
Here is how everything integrated:
const puppeteer = require('puppeteer');
const winston = require('winston');
const fs = require('fs');
const csv = require('csv-parser');
const { parse } = require('json2csv');
const MAX_RETRIES = 3;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductData {
constructor(data = {}) {
this.id = data.id || "Unknown ID";
this.type = data.type || "Unknown Type";
this.name = this.validateString(data.name, "No Name");
this.brand = this.validateString(data.brand, "No Brand");
this.averageRating = data.averageRating || 0;
this.shortDescription = this.validateString(data.shortDescription, "No Description");
this.thumbnailUrl = data.thumbnailUrl || "No Thumbnail URL";
this.price = data.price || 0;
this.currencyUnit = data.currencyUnit || "USD";
}
validateString(value, fallback) {
if (typeof value === 'string' && value.trim() !== '') {
return value.trim();
}
return fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeProductData(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const productData = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
const jsonBlob = JSON.parse(scriptTag.textContent);
const rawProductData = jsonBlob.props?.pageProps?.initialData?.data?.product;
if (rawProductData) {
return {
id: rawProductData.id,
name: rawProductData.name,
brand: rawProductData.brand,
averageRating: rawProductData.averageRating,
shortDescription: rawProductData.shortDescription,
thumbnailUrl: rawProductData.imageInfo?.thumbnailUrl,
price: rawProductData.priceInfo?.currentPrice?.price,
currencyUnit: rawProductData.priceInfo?.currentPrice?.currencyUnit,
};
}
}
return null;
});
if (productData) {
await dataPipeline.addData(new ProductData(productData));
logger.info(`Successfully scraped product data for ${url}`);
} else {
logger.warn(`No product data found for ${url}`);
}
break;
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`, error);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
logger.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
await browser.close();
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
(async () => {
logger.info("Started Scraping");
const aggregateFiles = ["candles-urls.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
for (let url of urls) {
const filename = url.filename.replace('urls', 'product-data');
const dataPipeline = new DataPipeline(filename);
for (const productUrl of url.urls) {
await scrapeProductData(dataPipeline, productUrl);
}
await dataPipeline.closePipeline();
}
logger.info('Scraping completed.');
})();
- It reads all the URLs from the "candles-urls.csv" file and stores them in an array.
- The script then scrapes the product details for each URL.
- After scraping, it stores all the product data in a CSV file named after the keyword, i.e., "candles-product-data.csv".
Step 4: Adding Concurrency
In this step, we’ll introduce concurrency into the scrapeProductData function, just like we did with scrapeProductUrls. The concurrency functionality will allow us to scrape multiple product details simultaneously, enhancing efficiency. We will integrate it using the scrapeConcurrently function.
Here’s how to integrate concurrency into the scrapeProductData function for Walmart:
const puppeteer = require('puppeteer');
const winston = require('winston');
const fs = require('fs');
const csv = require('csv-parser');
const { parse } = require('json2csv');
const MAX_RETRIES = 2;
const MAX_THREADS = 2;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductData {
constructor(data = {}) {
this.id = data.id || "Unknown ID";
this.type = data.type || "Unknown Type";
this.name = this.validateString(data.name, "No Name");
this.brand = this.validateString(data.brand, "No Brand");
this.averageRating = data.averageRating || 0;
this.shortDescription = this.validateString(data.shortDescription, "No Description");
this.thumbnailUrl = data.thumbnailUrl || "No Thumbnail URL";
this.price = data.price || 0;
this.currencyUnit = data.currencyUnit || "USD";
}
validateString(value, fallback) {
if (typeof value === 'string' && value.trim() !== '') {
return value.trim();
}
return fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeProductData(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
logger.info(`Fetching: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
const productData = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
const jsonBlob = JSON.parse(scriptTag.textContent);
const rawProductData = jsonBlob.props?.pageProps?.initialData?.data?.product;
if (rawProductData) {
return {
id: rawProductData.id,
name: rawProductData.name,
brand: rawProductData.brand,
averageRating: rawProductData.averageRating,
shortDescription: rawProductData.shortDescription,
thumbnailUrl: rawProductData.imageInfo?.thumbnailUrl,
price: rawProductData.priceInfo?.currentPrice?.price,
currencyUnit: rawProductData.priceInfo?.currentPrice?.currencyUnit,
};
}
}
return null;
});
if (productData) {
await dataPipeline.addData(new ProductData(productData));
logger.info(`Successfully scraped product data for ${url}`);
} else {
logger.warn(`No product data found for ${url}`);
}
break;
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`, error);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
logger.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
await browser.close();
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info("Started Scraping");
const aggregateFiles = ["candles-urls.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
const scrapeProductDataTasks = urls.flatMap(data =>
data.urls.map(url => async () => {
const filename = data.filename.replace('urls', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
})
);
await scrapeConcurrently(scrapeProductDataTasks, MAX_THREADS);
logger.info('Scraping completed.');
})();
- The
scrapeConcurrentlyfunction controls the concurrency, allowing multiple browser instances to scrape multiple URLs simultaneously. MAX_THREADScontrols how many concurrent browser instances can run at a time. In this case, it’s set to 2 (you can adjust as necessary).- All scraping tasks are added to a queue, and the
scrapeConcurrentlyfunction ensures that no more than the specified number of tasks are run in parallel.
With this integration, when you run the script, it will simultaneously scrape data from multiple Walmart product pages, speeding up the scraping process.
Step 5: Bypassing Anti-Bots
We’ve already created the getScrapeOpsUrl function, which adds geolocation and anti-bot protection to our URL. Now, all we need to do is use this function wherever we are calling page.goto(url). We will simply replace page.goto(url) with page.goto(getScrapeOpsUrl(url)), and that’s it.
After integrating both the scrapeProductUrls and scrapeProductData scrapers, the complete code looks like this:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const LOCATION = 'us';
const MAX_RETRIES = 2;
const MAX_THREADS = 2;
const MAX_PAGES = 2;
const keywords = ['airpods', 'candles'];
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'walmart-scraper.log' })
]
});
class ProductURL {
constructor(url) {
this.url = this.validateUrl(url);
}
validateUrl(url) {
if (typeof url === 'string' && url.trim().startsWith('https://www.walmart.com')) {
return url.trim();
}
return 'Invalid URL';
}
}
class ProductData {
constructor(data = {}) {
this.id = data.id || "Unknown ID";
this.type = data.type || "Unknown Type";
this.name = this.validateString(data.name, "No Name");
this.brand = this.validateString(data.brand, "No Brand");
this.averageRating = data.averageRating || 0;
this.shortDescription = this.validateString(data.shortDescription, "No Description");
this.thumbnailUrl = data.thumbnailUrl || "No Thumbnail URL";
this.price = data.price || 0;
this.currencyUnit = data.currencyUnit || "USD";
}
validateString(value, fallback) {
if (typeof value === 'string' && value.trim() !== '') {
return value.trim();
}
return fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeProductUrls(dataPipeline, keyword, maxPages = MAX_PAGES, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
for (let pageNum = 1; pageNum <= maxPages; pageNum++) {
const url = `https://www.walmart.com/search?q=${encodeURIComponent(keyword)}&sort=best_seller&page=${pageNum}&affinityOverride=default`;
logger.info(`Fetching: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
const data = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
return JSON.parse(scriptTag.textContent);
}
return null;
});
if (data) {
const items = data.props?.pageProps?.initialData?.searchResult?.itemStacks?.[0]?.items || [];
for (const item of items) {
const url = new ProductURL('https://www.walmart.com' + (item.canonicalUrl || '').split('?')[0]);
await dataPipeline.addData({ title: item.name, url: url.url });
}
// Break the loop if no products are found
if (items.length === 0) {
logger.info('No more products found.');
break;
}
} else {
logger.warn('No data found on this page.');
}
}
} catch (error) {
logger.error(`Error during scraping: ${error.message}`);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
} finally {
await browser.close();
await dataPipeline.closePipeline();
}
}
}
async function scrapeProductData(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
while (retries > 0) {
try {
logger.info(`Fetching: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
const productData = await page.evaluate(() => {
const scriptTag = document.querySelector('#__NEXT_DATA__');
if (scriptTag) {
const jsonBlob = JSON.parse(scriptTag.textContent);
const rawProductData = jsonBlob.props?.pageProps?.initialData?.data?.product;
if (rawProductData) {
return {
id: rawProductData.id,
type: rawProductData.type,
name: rawProductData.name,
brand: rawProductData.brand,
averageRating: rawProductData.averageRating,
shortDescription: rawProductData.shortDescription,
thumbnailUrl: rawProductData.imageInfo?.thumbnailUrl,
price: rawProductData.priceInfo?.currentPrice?.price,
currencyUnit: rawProductData.priceInfo?.currentPrice?.currencyUnit,
};
}
}
return null;
});
if (productData) {
await dataPipeline.addData(new ProductData(productData));
} else {
logger.info(`No product data found for ${url}`);
}
break;
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`, error);
retries--;
if (retries > 0) {
logger.info('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
await browser.close();
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
(async () => {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
const scrapeProductUrlsTasks = keywords.map(keyword => async () => {
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-urls.csv`;
const dataPipeline = new DataPipeline(csvFilename);
await scrapeProductUrls(dataPipeline, keyword);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
await scrapeConcurrently(scrapeProductUrlsTasks, MAX_THREADS);
const urls = await getAllUrlsFromFiles(aggregateFiles);
const scrapeProductDataTasks = urls.flatMap(data =>
data.urls.map(url => async () => {
const filename = data.filename.replace('urls', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
})
);
await scrapeConcurrently(scrapeProductDataTasks, MAX_THREADS);
logger.info('Scraping completed.');
})();
Step 6: Production Run
Now that we’ve finished our scraper, let’s run it and assess its performance. We’ll use the following configurations for the run:
const MAX_RETRIES = 2;
const MAX_THREADS = 4;
const MAX_PAGES = 2;
const keywords = ['airpods', 'candles'];
We are using 4 threads for this run, but you can adjust this number based on the number of CPU cores available on your machine. According to our Winston logs, our scraper took approximately 136 seconds to scrape data from a Walmart product page. Given that one Walmart product page contains about 40 products (and therefore 40 URLs to scrape), this performance is bad at all.
Let's break down the numbers:
- Total time for 4 pages: 136 seconds
- Time per page: 136 / 4 = 34 seconds
For a scraping job of this scale, 34 seconds per page is a solid result, indicating good performance.
Legal and Ethical Considerations
Before scraping any website, including Walmart, it’s essential to review their Terms of Service and robots.txt. Violating these can result in temporary or permanent bans.
You can find Walmart's robots.txt here, which specifies which parts of the site can be crawled or scraped.
Public data, typically available without login, is generally free to scrape. However, private data or content behind authentication may be subject to stricter regulations.
If you're uncertain about the legality of scraping, especially with private or sensitive data, it's best to consult an attorney to ensure compliance.
Conclusion
In this guide, we’ve walked through building a robust Walmart scraper using Puppeteer and NodeJS. You’ve learned how to extract data efficiently, implement concurrency to speed up the process and handle various challenges like retries and proxy integration. With these skills, you can scale your web scraping tasks and collect valuable product information from Walmart.
If you'd like to learn more about the technologies used in this article, check out the following resources:
More Puppeteer and NodeJS Web Scraping Guides
Here at ScrapeOps, we've got a ton of learning resources. Whether you're brand new or a seasoned web developer, we've got something for you.
Check out our extensive Puppeteer Web Scraping Playbook and build something!
If you'd like to learn more from our "How To Scrape" series, take a look at the links below.
- How to Scrape Google Search With Puppeteer
- How to Scrape Reddit With Puppeteer
- How to Scrape Pinterest With NodeJS and Puppeteer