
How to Scrape Target with Puppeteer
Target is the official website of Target Corporation, a leading American retail company offering a wide range of products, including clothing, household goods, electronics, toys, and groceries.
In this guide, we'll explore how to scrape product details from Target.com using Puppeteer and NodeJS. This can be valuable for competitive pricing analysis, demand forecasting, consumer behavior insights, and real-time inventory tracking.
- TL:DR – How to Scrape Target.com
- How To Architect Our Scraper
- Understanding How To Scrape Target
- Setting Up Our Target Scraper Project
- Build A Target Search Data Scraper
- Build A Target Product Data Scraper
- Legal and Ethical Considerations
- Conclusion
- More Puppeteer Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TL:DR – How to Scrape Target.com
This article walks you through building a scraper from scratch, explaining every detail to help you understand how scrapers work and how to create one using Puppeteer. However, if you're short on time or just need the main code, feel free to copy it from below.
-
Configure API Key: Create a
config.jsonfile and add your ScrapeOps API key. This helps bypass anti-bot protection and target specific geolocations. If you don’t have an API key, sign up on ScrapeOps to get 1,000 free API credits on your first registration.{
"api_key": "YOUR_SCRAPEOPS_API_KEY"
} -
Install Dependencies: Save the following JSON as
package.jsonto define the scraper's dependencies, then runnpm installto install them:{
"name": "target",
"version": "1.0.0",
"main": "target-scraper.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"type": "commonjs",
"description": "",
"dependencies": {
"csv-parser": "^3.0.0",
"json2csv": "^6.0.0-alpha.2",
"puppeteer": "^23.10.0",
"winston": "^3.17.0"
}
} -
Run the Scraper: Save the provided code as
target-scraper.js, then execute it withnode target-scraper.js:const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const LOCATION = "us";
const keywords = ["apple pen"];
const MAX_PAGES = 1;
const MAX_THREADS = 2;
const MAX_RETRIES = 2;
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
class ProductSearchData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.url = this.validateString(data.url, "No URL");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
}
class ProductData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.price = this.parsePrice(data.price);
this.rating = this.parseRating(data.rating);
this.reviewCount = this.parseReviewCount(data.reviewCount);
this.details = this.validateString(data.details, "No Details");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
parsePrice(value) {
const priceMatch = typeof value === 'string' ? value.match(/\d+(\.\d{1,2})?/) : null;
return priceMatch ? parseFloat(priceMatch[0]) : 0;
}
parseRating(value) {
return typeof value === 'string' && !isNaN(parseFloat(value)) ? parseFloat(value) : 0;
}
parseReviewCount(value) {
return typeof value === 'string' && !isNaN(parseInt(value)) ? parseInt(value) : 0;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'networkidle2' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const results = [];
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
return results;
});
for (const product of productData) {
await datapipeline.addData(new ProductSearchData(product));
}
console.log(`Successfully scraped data from: ${url}`);
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request for: ${url}, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function scrapeProductData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const title = document.querySelector("h1[data-test='product-title']")?.innerText || "N/A";
const ratingHolder = document.querySelector("span[data-test='ratings']");
const rating = ratingHolder ? ratingHolder.innerText.split(" ")[0] : "N/A";
const reviewCount = ratingHolder ? ratingHolder.innerText.split(" ").slice(-2, -1)[0] : "0";
const price = document.querySelector("span[data-test='product-price']")?.innerText || "N/A";
const details = document.querySelector("div[data-test='productDetailTabs-itemDetailsTab']")?.innerText || "N/A";
return { title, price, rating, reviewCount, details };
});
await datapipeline.addData(new ProductData(productData))
console.log("Successfully scraped and saved product data");
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info("Started Scraping Search Data");
const aggregateFiles = [];
const scrapeSearchDataTasks = keywords.flatMap(keyword => {
const tasks = [];
for (let pageNumber = 0; pageNumber < MAX_PAGES; pageNumber++) {
tasks.push(async () => {
const formattedKeyword = encodeURIComponent(keyword);
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-page-${pageNumber}-search-data.csv`;
const dataPipeline = new DataPipeline(csvFilename);
const url = `https://www.target.com/s?searchTerm=${formattedKeyword}&Nao=${pageNumber * 24}`;
await scrapeSearchData(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
}
return tasks;
});
await scrapeConcurrently(scrapeSearchDataTasks, MAX_THREADS);
const urls = await getAllUrlsFromFiles(aggregateFiles);
logger.info("Started Scraping Product Data")
const scrapeProductDataTasks = urls.flatMap(data =>
data.urls.map(url => async () => {
const filename = data.filename.replace('search-data', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
})
);
await scrapeConcurrently(scrapeProductDataTasks, MAX_THREADS);
logger.info('Scraping completed');
})();
You can customize the scraper by modifying the following variables:
LOCATION: The country code for scraping requests (default: 'us'). Used to simulate traffic from a specific region.MAX_RETRIES: The maximum number of retry attempts if a request fails (default: 2).MAX_THREADS: The number of concurrent threads for scraping and processing data (default: 2).MAX_PAGES: The number of pages to scrape per keyword (default: 1). Each page contains multiple search results.keywords: A list of search terms to scrape (default: ["apple pen"]). Each keyword triggers a separate search query on Target.
How To Architect Our Target Scraper
Our Target scraper consists of two main components:
scrapeSearchData
This scraper searches Target using a keyword, extracts product titles and URLs from the search results, and paginates through multiple pages. The extracted data is stored in a CSV file named after the keyword and page number (e.g., apple-pen-page-0-search-data.csv).
Example output:
{
"title": "link-stylus-pen-for-apple-ipad-9th-10th-generation",
"url": "https://www.target.com/p/link-stylus-pen-for-apple-ipad-9th-10th-generation/-/A-92572740?preselect=91675797#lnk=sametab"
}
scrapeProductData
This scraper reads the URLs from the first step, visits each product page, and extracts details such as title, price, rating, review count, and product description.
The scraped data is stored in another CSV file named after the keyword and page number (e.g., laptops-page-0-product-data.csv).
Example output:
{
"title": "Link Stylus Pen For Apple iPad 9th & 10th Generation",
"price": 39.99,
"rating": 2.9,
"reviewCount": 12,
"details": "Highlights Compatible with 2018-2024 iPad & iPad Pro: The stylus supports for iPad series 2018-2024 model ... More"
}
Target.com actively detects and blocks bots, so we'll need to use third-party services to handle the bypasses. We'll use ScrapeOps for this because it's convenient and, as we'll see, easy to integrate.
Additionally, ScrapeOps allows us to simulate any geographic location, enabling us to scrape location-specific data.
Understanding How To Scrape Target
Target.com uses dynamic content loading, which can cause delays in displaying product information. To handle this, we'll send our requests through ScrapeOps with a wait parameter to ensure all data is fully available before scraping.
Additionally, we'll use auto-scrolling in our script to make sure all products appear on the page. Here's an overview of how our Target scraper will work:
Step 1: How To Request Target Pages
Let's first understand the URL structure of Target.com when searching for a product. If you search for "laptop" on Target, you'll see a URL like this:
https://www.target.com/s?searchTerm=laptop
Here is how it looks:
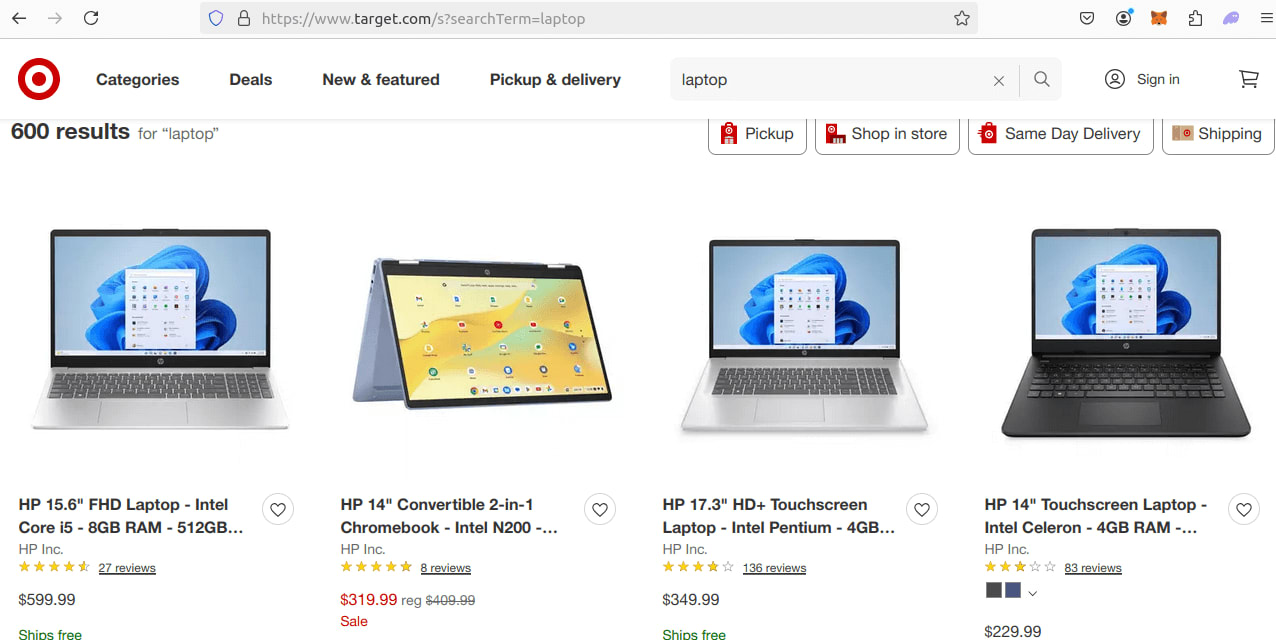
Now, navigate to the next page. The URL changes to include a parameter like Nao=24, which represents page 2. If you go to the following page, the parameter updates to Nao=48.
This pattern indicates that the Nao parameter controls pagination, where each page adds 24 to the previous value. From this, we can construct the URL dynamically using JavaScript as follows:
https://www.target.com/s?searchTerm=${encodeURIComponent(keyword)}&Nao=${pageNum * 24}
By navigating to these URLs for a given keyword and page number, we can scrape product titles, ratings, and prices. However, descriptions aren't available, and titles are often truncated with ellipses (...). To get the complete details, we'll need to visit each product's individual page.
We don't need to manually construct URLs for individual product pages because our first scraper will already collect the product URLs from the listing pages. Nonetheless, let's inspect the structure by clicking on a product to see how the individual product page is laid out:
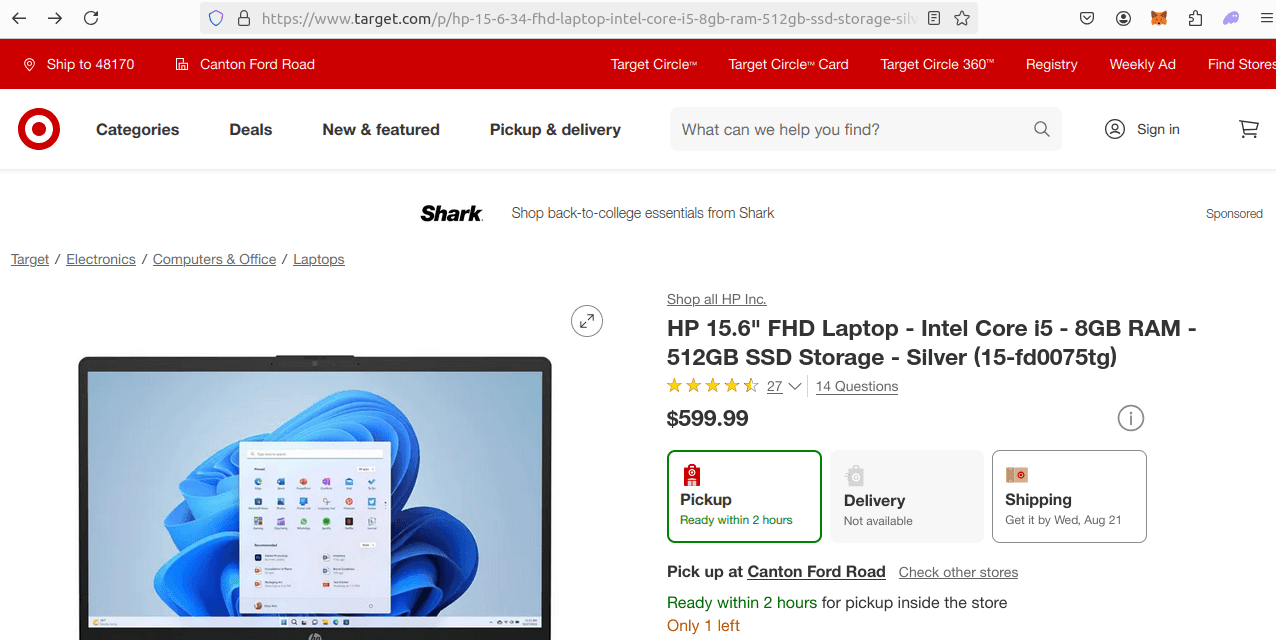
From the above image, you can see that the individual product page URL is also quite straightforward:
https://www.target.com/p/hp-15-6-34-fhd-laptop-intel-core-i5-8gb-ram-512gb-ssd-storage-silver-15-fd0075tg/-/A-89476632#lnk=sametab
Step 2: How To Extract Data From Target Results and Pages
To scrape product data from Target, we first need to identify the key elements on both the product listing page and the product detail page.
We'll use CSS selectors to locate the necessary data, such as product titles, URLs, ratings, prices, and additional details. Below, we break down how to extract information from each page type.
On the product listing page, each product is wrapped in a div element with the attribute data-test='@web/site-top-of-funnel/ProductCardWrapper'. Inside this wrapper, the product link is contained within an <a> tag.
The link provides the product title in the URL itself, which we can extract and structure accordingly.
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
The screenshot below highlights the product card structure:
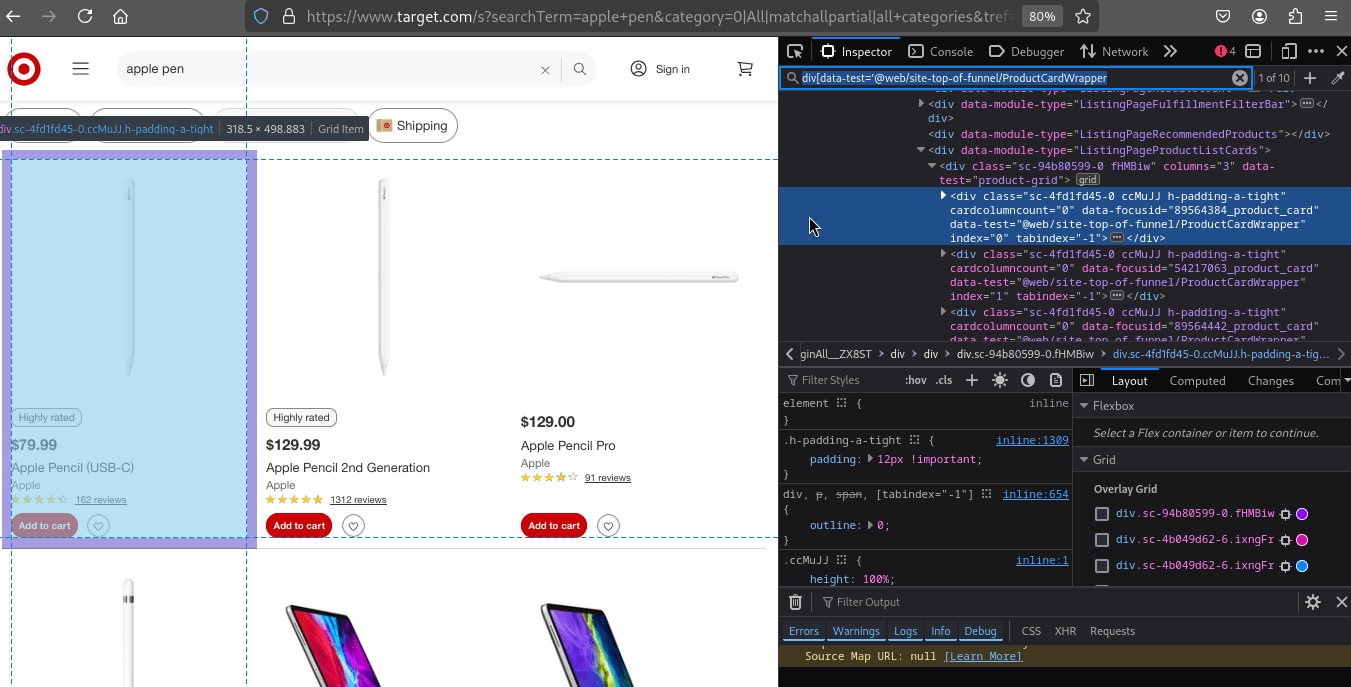
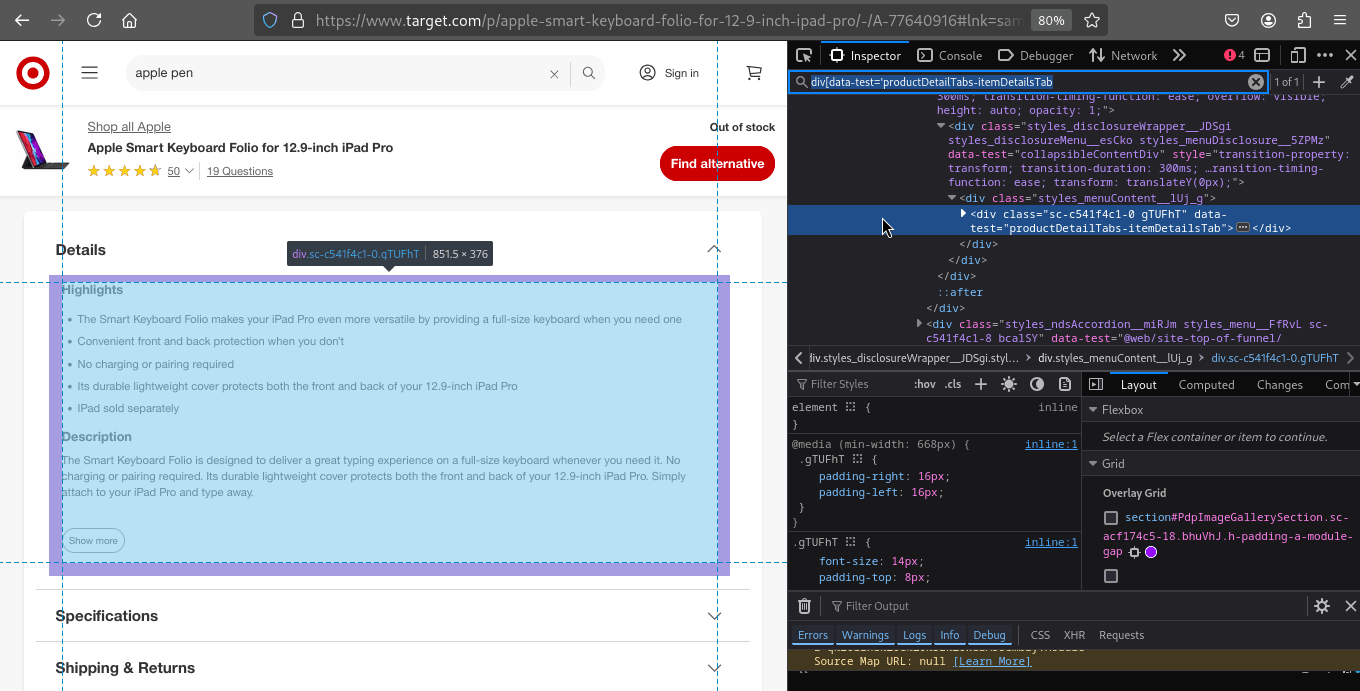
Once we have the product URL from the listing page, we can navigate to the product detail page and extract more specific information, such as the product title, rating, review count, price, and additional details.
const title = document.querySelector("h1[data-test='product-title']")?.innerText || "N/A";
const ratingHolder = document.querySelector("span[data-test='ratings']");
const rating = ratingHolder ? ratingHolder.innerText.split(" ")[0] : "N/A";
const reviewCount = ratingHolder ? ratingHolder.innerText.split(" ").slice(-2, -1)[0] : "0";
const price = document.querySelector("span[data-test='product-price']")?.innerText || "N/A";
const details = document.querySelector("div[data-test='productDetailTabs-itemDetailsTab']")?.innerText || "N/A";
- Product Title: Extracted from an
<h1>tag withdata-test='product-title'. - Rating & Review Count: Found in a
<span>element withdata-test='ratings', where the first word represents the rating, and the second-to-last word represents the review count. - Price: Extracted from a
<span>tag withdata-test='product-price'. - Product Details: Captured from the
<div>withdata-test='productDetailTabs-itemDetailsTab'.
The following screenshot shows the details section of the product page:
Step 3: How To Control Pagination
As we’ve already seen, Target.com handles pagination using the Nao parameter in the URL. When you navigate to the second page of search results, you’ll notice Nao=24 in the address bar. This pattern continues as you browse more pages.
The full URL structure for pagination looks like this:
https://www.target.com/s?searchTerm=${encodeURIComponent(keyword)}&Nao=${pageNum * 24}
Here��’s how it works:
- Page 1: Nao=0 → 0 * 24
- Page 2: Nao=24 → 1 * 24
- Page 3: Nao=48 → 2 * 24
- And so on...
This consistent pattern allows us to dynamically construct URLs for any page by simply adjusting the Nao parameter based on the page number.
Step 4: Geolocated Data
Target.com displays content based on the user's location. To scrape accurate and relevant data, we need to simulate requests from desired geographic regions.
To achieve this, we'll be using the ScrapeOps Proxy API, which makes it easy to control the location from which our requests appear to be coming. This is crucial for scraping region-specific product availability, prices, and other localized content.
By including a country parameter in our request, we can specify the location:
- To appear as a US-based user, set
"country": "us". - To appear as a UK-based user, set
"country": "uk".
This flexibility allows us to gather geotargeted data seamlessly. You can find the complete list of supported countries here.
Setting Up Our Target Scraper Project
Let's get started by setting up our Target scraper project using NodeJS and Puppeteer. We'll also be using json2csv for exporting data, winston for logging, and csv-parser for handling CSV files.
-
Create a New Project Folder:
mkdir target-scraper
cd target-scraper -
Initialize a New NodeJS Project:
npm init -y -
Install Our Dependencies: We'll be using the following NodeJS libraries:
- Puppeteer for web scraping
- json2csv to convert scraped data to CSV
- Winston for logging
- csv-parser to read and process CSV files
Install them using:
npm install puppeteer json2csv winston csv-parser -
Create a Configuration File: We'll store our ScrapeOps API key in a
config.jsonfile like this:{
"api_key": "YOUR_SCRAPEOPS_API_KEY"
}
We're now ready to start writing code for our scraper.
Build A Target Search Data Scraper
With the big picture of our scraper in mind, let's start building our first scraper, scrapeSearchData, to extract product titles and URLs from the product listing pages. In this section, we'll cover:
- Scraping Target.com for a specific keyword and collecting all product titles and URLs.
- Handling pagination by tweaking the input URL parameters.
- Structuring the scraped data using dedicated classes and implementing fallbacks for missing information.
- Storing the data in CSV format using data pipelines and NodeJS CSV libraries.
- Enhancing speed and efficiency by implementing retry mechanisms and concurrency.
- Bypassing anti-bot measures and targeting specific geolocations.
Step 1: Create a Simple Search Data Scraper
Now it's time to write the actual code. We'll create a function named scrapeSearchData that takes a URL and scrapes all the product titles and URLs from the listing page. Here's what we'll be doing:
-
Create a Winston Logger – We'll set up a logger to log all the info and warnings to the console, helping us track the scraper's activity and debug issues.
-
Implement an Auto-Scroll Utility – We'll use a separate utility function for auto-scrolling to the end of the page to ensure all products are fully loaded.
-
Build the
scrapeSearchDataFunction – This is the main function that performs the actual scraping. -
Retry Mechanism – We'll add a retry mechanism to handle potential errors, such as network issues or temporary blocks.
Assuming you have some familiarity with Puppeteer and know how to inspect elements to get CSS selectors, we won't go into the basics of Puppeteer setup or selector selection. Here's the code:
const puppeteer = require('puppeteer');
const winston = require('winston');
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
const MAX_RETRIES = 2;
async function scrapeSearchData(url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
logger.info(`Navigating to: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const results = [];
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
return results;
});
console.log(productData);
logger.info(`Successfully scraped data from: ${url}`);
await browser.close();
success = true;
} catch (error) {
logger.warn(`Error scraping ${url}: ${error.message}`);
logger.info(`Retrying request for: ${url}, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
(async () => {
logger.info("Started Scraping Search Data")
const keyword = "apple pen";
const pageNumber = 0;
const url = `https://www.target.com/s?searchTerm=${encodeURIComponent(keyword)}&Nao=${pageNumber * 24}`;
await scrapeSearchData(url);
logger.info('Scraping completed');
})()
In the above code:
MAX_RETRIEScontrols the maximum number of retry attempts, set to 2 in this example.keywordis set to "apple pen" but can be changed to any search term.pageNumberis set to 0, representing the First Page of search results.
Let's run the code and see the output. Here’s what I got, confirming that the scraper is working correctly:
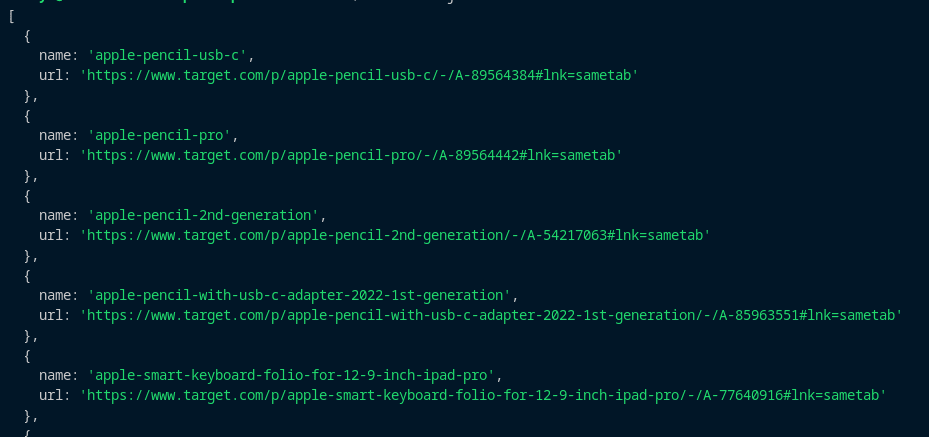
With this working, we'll move on to the next step, where we'll structure the scraped data and save it as a CSV file.
Step 2: Storing the Scraped Data
In the previous section, we simply printed the scraped data to the console. Now, we'll store this data in a CSV file for easy review and analysis later. However, before saving, we need to properly structure the data and handle cases where some information might be missing.
We'll do this in two parts:
-
Structuring the Data: We'll create a
ProductSearchDataclass to clean and organize the raw data into a consistent format. -
Saving the Data: We'll create a
DataPipelineclass to efficiently store the data as a CSV, manage duplicates, and optimize memory usage by saving data in batches.
The ProductSearchData class will ensure that all product details are properly formatted and assigns fallback values when data is missing. This helps us avoid issues like empty fields in our CSV. Here's how the class looks:
class ProductSearchData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.url = this.validateString(data.url, "No URL");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
}
-
Consistent Data Structure: By converting the raw data into a well-defined object, we ensure consistent CSV columns.
-
Handling Missing Data: If the title or URL is missing, we set a default value of "No Title" or "No URL". This avoids blank fields that could cause confusion during data analysis.
To efficiently store our structured data, we'll create a DataPipeline class. This class not only saves the data to a CSV file but also:
-
Batch Saves: It writes data to the CSV only when the storage queue reaches a set limit (50 items in this case). This reduces the frequency of disk I/O operations, improving performance.
-
Duplicate Filtering: It uses a
Setto track product titles and filter out duplicates, ensuring our CSV file only contains unique products. -
Seamless Continuation: If the script stops unexpectedly, it picks up from where it left off without data loss, thanks to its efficient queue management.
Here’s how the DataPipeline class is implemented:
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
We'll now update our scraping script from Step 1 to use the ProductSearchData and DataPipeline classes. This will allow us to structure and store the scraped data.
The updated script will look like this:
const puppeteer = require('puppeteer');
const winston = require('winston');
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
const MAX_RETRIES = 2;
class ProductSearchData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.url = this.validateString(data.url, "No URL");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const results = [];
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
return results;
});
for (const product of productData) {
await datapipeline.addData(new ProductSearchData(product));
}
console.log(`Successfully scraped data from: ${url}`);
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request for: ${url}, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
(async () => {
logger.info("Started Scraping Search Data")
const aggregateFiles = [];
const keyword = "apple pen";
const pageNumber = 0;
const formattedKeyword = encodeURIComponent(keyword);
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-page-${pageNumber}-search-data.csv`;
const url = `https://www.target.com/s?searchTerm=${formattedKeyword}&Nao=${pageNumber * 24}`
const dataPipeline = new DataPipeline(csvFilename);
await scrapeSearchData(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
logger.info('Scraping completed');
})()
Step 3: Adding Concurrency
When scraping multiple pages or keywords on Target.com, processing them one by one can be time-consuming. To enhance efficiency, we can introduce concurrency by launching multiple Puppeteer browser instances simultaneously.
This allows us to scrape multiple pages in parallel, significantly reducing overall execution time.
We'll implement a function called scrapeConcurrently, which manages the concurrent execution of tasks. This function controls the maximum number of tasks (maxConcurrency) running at once, preventing system overload while optimizing resource utilization.
Why Concurrency?
-
Improved Performance: By scraping multiple pages simultaneously, we maximize CPU and network usage, speeding up the data collection process.
-
Efficient Resource Management: Limiting the number of concurrent tasks prevents excessive resource usage, maintaining system stability.
-
Scalable Scraping: This approach is ideal for handling long lists of keywords or navigating through multiple pagination URLs.
The scrapeConcurrently function manages a pool of asynchronous tasks, ensuring that no more than a set number (maxConcurrency) run at once. It keeps track of executing tasks using a Set and processes new ones as slots become available.
Here's how it works:
-
Task Pooling: Tasks are added to an executing set. If the set reaches the
maxConcurrencylimit, the function waits for one of the tasks to complete before adding another. -
Dynamic Adjustment: As each task finishes, it is removed from the set, allowing the next one to start. This keeps the number of active tasks constant.
-
Error Handling: If a task fails, it continues with the next available one, preventing the entire process from stopping.
Here is the implementation:
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
}).catch(error => {
executing.delete(promise);
console.error(`Task failed: ${error.message}`);
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
We'll now integrate this concurrency handler into our Target.com scraper. Here’s the plan:
-
Max Concurrency Control: Use
MAX_THREADSto specify the maximum number of concurrent Puppeteer instances. This allows flexibility to adjust concurrency based on system resources. -
Pagination and Keyword Management: Scrape multiple pages for each keyword simultaneously, enhancing throughput.
Here is the updated script:
const puppeteer = require('puppeteer');
const winston = require('winston');
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
const MAX_RETRIES = 2;
const keywords = ["apple pen"];
const MAX_PAGES = 1;
const MAX_THREADS = 2;
class ProductSearchData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.url = this.validateString(data.url, "No URL");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const results = [];
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
return results;
});
for (const product of productData) {
await datapipeline.addData(new ProductSearchData(product));
}
console.log(`Successfully scraped data from: ${url}`);
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request for: ${url}, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info("Started Scraping Search Data");
const aggregateFiles = [];
const scrapeSearchDataTasks = keywords.flatMap(keyword => {
const tasks = [];
for (let pageNumber = 0; pageNumber < MAX_PAGES; pageNumber++) {
tasks.push(async () => {
const formattedKeyword = encodeURIComponent(keyword);
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-page-${pageNumber}-search-data.csv`;
const dataPipeline = new DataPipeline(csvFilename);
const url = `https://www.target.com/s?searchTerm=${formattedKeyword}&Nao=${pageNumber * 24}`;
await scrapeSearchData(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
}
return tasks;
});
await scrapeConcurrently(scrapeSearchDataTasks, MAX_THREADS);
})()
Step 4: Bypassing Anti-Bots
Scraping Target.com can be challenging due to advanced anti-bot measures such as rate limiting, and IP blocking.
To bypass these defenses, we’ll use the ScrapeOps Proxy API. This allows us to route our requests through rotating proxies, effectively masking our scraper’s identity.
We'll create a helper function called getScrapeOpsUrl() that generates a proxied URL with custom settings like location and wait time. This allows for dynamic request routing while maintaining control over request speed and frequency.
The getScrapeOpsUrl() function builds a proxied URL with custom settings for:
- API Key: Secured in a
config.jsonfile for easy access and modification. - Target URL: The URL of the page we want to scrape.
- Country: Optional parameter to route requests through a specific location, defaulting to the United States ("us").
- Wait Time: Specifies a delay before receiving the response, emulating realistic browsing patterns.
After integrating the proxy mechanism into our Target.com scraper, the updated scraper will look like this:
const puppeteer = require('puppeteer');
const winston = require('winston');
const MAX_RETRIES = 2;
const keywords = ["apple pen"];
const MAX_PAGES = 1;
const MAX_THREADS = 2;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
class ProductSearchData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.url = this.validateString(data.url, "No URL");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'networkidle2' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const results = [];
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
return results;
});
for (const product of productData) {
await datapipeline.addData(new ProductSearchData(product));
}
console.log(`Successfully scraped data from: ${url}`);
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request for: ${url}, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info("Started Scraping Search Data");
const aggregateFiles = [];
const scrapeSearchDataTasks = keywords.flatMap(keyword => {
const tasks = [];
for (let pageNumber = 0; pageNumber < MAX_PAGES; pageNumber++) {
tasks.push(async () => {
const formattedKeyword = encodeURIComponent(keyword);
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-page-${pageNumber}-search-data.csv`;
const dataPipeline = new DataPipeline(csvFilename);
const url = `https://www.target.com/s?searchTerm=${formattedKeyword}&Nao=${pageNumber * 24}`;
await scrapeSearchData(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
}
return tasks;
});
await scrapeConcurrently(scrapeSearchDataTasks, MAX_THREADS);
})()
Step 5: Production Run
Now, let's run our scraper and evaluate its performance using the following configuration:
const MAX_PAGES = 4;
const MAX_THREADS = 2;
const MAX_RETRIES = 2;
const keywords = ["apple pen"];
To execute the scraper, run the following command in your terminal:
node target-scraper.js
From the Winston logs, we observed that our scraper completed in approximately 37 seconds while using two Puppeteer instances running in parallel. Given that we processed one keyword with 4 pages, the calculation breaks down as follows:
- Total tasks: 1 keyword × 4 page = 4 task
- Average time per task: 37 seconds / 4 task = 9.25 seconds per task
This performance shows how concurrency with two Puppeteer instances helps distribute the workload efficiently.
Build A Target Product Data Scraper
With our first scraper successfully collecting titles and URLs, and the DataPipeline efficiently removing duplicates and saving the data in batches to CSV, we're well on our way. Now, it's time to complete the script by building the second scraper.
This next scraper will:
- Read the CSV files generated by
scrapeSearchDatato extract all product URLs. - Visit each URL and scrape detailed product information, including the title, rating, price, and description.
- Store the scraped product details in organized CSV files.
We'll also implement concurrency and anti-bot bypass mechanisms, following the same strategies used in the previous sections. This will ensure our scraper is both efficient and resilient.
Step 1: Create Simple Product Data Scraper
Let's start by creating the main function to scrape product details, assuming we already have a product URL. The approach will be similar to the one used in scrapeSearchData, so the logic should feel familiar.
Here's the implementation:
const puppeteer = require('puppeteer');
const winston = require('winston');
const MAX_RETRIES = 2;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
async function scrapeProductData(url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const title = document.querySelector("h1[data-test='product-title']")?.innerText || "N/A";
const ratingHolder = document.querySelector("span[data-test='ratings']");
const rating = ratingHolder ? ratingHolder.innerText.split(" ")[0] : "N/A";
const reviewCount = ratingHolder ? ratingHolder.innerText.split(" ").slice(-2, -1)[0] : "0";
const price = document.querySelector("span[data-test='product-price']")?.innerText || "N/A";
const details = document.querySelector("div[data-test='productDetailTabs-itemDetailsTab']")?.innerText || "N/A";
return { title, price, rating, reviewCount, details };
});
console.log(productData)
console.log("Successfully scraped and saved product data");
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
(async () => {
logger.info("Started Scraping Search Data");
const url = "https://www.target.com/p/link-stylus-pen-for-apple-ipad-9th-10th-generation/-/A-92572740?preselect=91675797#lnk=sametab";
await scrapeProductData(url);
logger.info('Scraping completed');
})();
In this code:
- CSS selectors are used to target the product details we want to extract.
- The
autoScrollutility function from the previous section ensures that all dynamic content is fully loaded before scraping. - A retry mechanism and error handling are implemented to enhance reliability, just as we did before.
- For now, the scraped data is simply printed to the console for validation.
Step 2: Loading URLs To Scrape
Instead of manually typing the product URLs, we'll now load them from CSV files generated by the scrapeSearchData scraper. To achieve this, we’ll create two utility functions:
- readCsvAndGetUrls: This function takes a filename as input and extracts all the URLs from that file.
- getAllUrlsFromFiles: This function loops through an array of filenames and uses
readCsvAndGetUrlsto gather URLs from each file.
Here’s how it's implemented:
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
If you have the CSV files generated by scrapeSearchData, you can test these functions as follows:
const files = ['apple-pen-page-0-search-data.csv'];
(async () => {
const urls = await getAllUrlsFromFiles(files);
console.log(urls);
})()
Here’s the output from running the code:
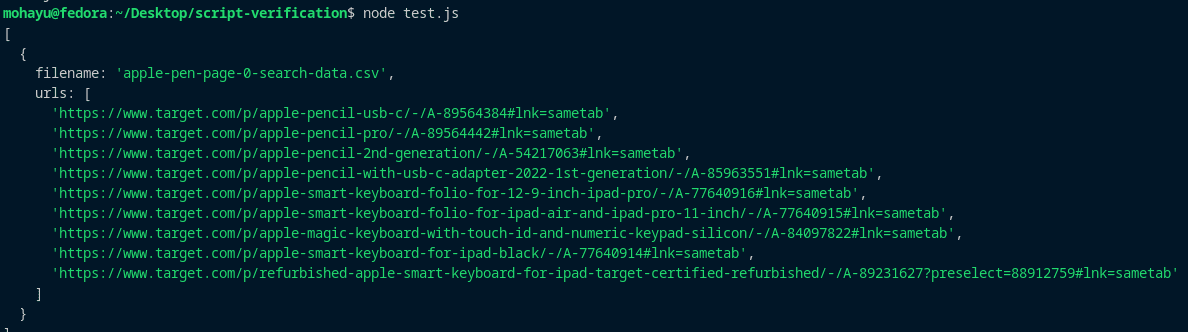
Step 3: Storing the Scraped Data
We already have the DataPipeline class handling the storage, so now we need to build the ProductData class to structure the scraped data and provide fallbacks for missing values.
Here’s how it's implemented:
class ProductData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.price = this.parsePrice(data.price);
this.rating = this.parseRating(data.rating);
this.reviewCount = this.parseReviewCount(data.reviewCount);
this.details = this.validateString(data.details, "No Details");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
parsePrice(value) {
const priceMatch = typeof value === 'string' ? value.match(/\d+(\.\d{1,2})?/) : null;
return priceMatch ? parseFloat(priceMatch[0]) : 0;
}
parseRating(value) {
return typeof value === 'string' && !isNaN(parseFloat(value)) ? parseFloat(value) : 0;
}
parseReviewCount(value) {
return typeof value === 'string' && !isNaN(parseInt(value)) ? parseInt(value) : 0;
}
}
This class not only structures the data but also ensures consistent formatting by adding fallback values like "No Title" and "No Details" when information is missing.
Next, we'll integrate this class into the scrapeProductData function. Here’s what our complete code looks like so far:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const MAX_RETRIES = 2;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
class ProductData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.price = this.parsePrice(data.price);
this.rating = this.parseRating(data.rating);
this.reviewCount = this.parseReviewCount(data.reviewCount);
this.details = this.validateString(data.details, "No Details");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
parsePrice(value) {
const priceMatch = typeof value === 'string' ? value.match(/\d+(\.\d{1,2})?/) : null;
return priceMatch ? parseFloat(priceMatch[0]) : 0;
}
parseRating(value) {
return typeof value === 'string' && !isNaN(parseFloat(value)) ? parseFloat(value) : 0;
}
parseReviewCount(value) {
return typeof value === 'string' && !isNaN(parseInt(value)) ? parseInt(value) : 0;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeProductData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(url, { waitUntil: 'domcontentloaded' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const title = document.querySelector("h1[data-test='product-title']")?.innerText || "N/A";
const ratingHolder = document.querySelector("span[data-test='ratings']");
const rating = ratingHolder ? ratingHolder.innerText.split(" ")[0] : "N/A";
const reviewCount = ratingHolder ? ratingHolder.innerText.split(" ").slice(-2, -1)[0] : "0";
const price = document.querySelector("span[data-test='product-price']")?.innerText || "N/A";
const details = document.querySelector("div[data-test='productDetailTabs-itemDetailsTab']")?.innerText || "N/A";
return { title, price, rating, reviewCount, details };
});
await datapipeline.addData(new ProductData(productData))
console.log("Successfully scraped and saved product data");
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
(async () => {
logger.info("Started Scraping Search Data");
const aggregateFiles = ["apple-pen-page-0-search-data.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
logger.info("Started Scraping Product Data")
for (const data of urls) {
for (const url of data.urls) {
const filename = data.filename.replace('search-data', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
}
}
logger.info('Scraping completed');
})();
Step 4: Adding Concurrency
We'll reuse the scrapeConcurrently utility function that we built for scrapeSearchData.
Since the implementation is similar to what we've covered before, we'll directly integrate it into our scraper. Here's how the final version of the executing IIFE function looks:
(async () => {
logger.info("Started Scraping Search Data");
const aggregateFiles = ["apple-pen-page-0-search-data.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
logger.info("Started Scraping Product Data")
const scrapeProductDataTasks = urls.flatMap(data =>
data.urls.map(url => async () => {
const filename = data.filename.replace('search-data', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
})
);
await scrapeConcurrently(scrapeProductDataTasks, MAX_THREADS);
logger.info('Scraping completed');
})();
Step 5: Bypassing Anti-Bots
To bypass anti-bot measures, we'll use the getScrapeOpsUrl function that we already created. We just need to integrate it into scrapeProductData by using it when passing the URL to the goto function.
Here's the only change required:
// await page.goto(url, { waitUntil: 'domcontentloaded' });
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
Now that we've completed writing our scraper, here’s the full combined code for both scrapers:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const LOCATION = "us";
const keywords = ["apple pen"];
const MAX_PAGES = 1;
const MAX_THREADS = 2;
const MAX_RETRIES = 2;
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'target-scraper.log' })
]
});
class ProductSearchData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.url = this.validateString(data.url, "No URL");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
}
class ProductData {
constructor(data = {}) {
this.title = this.validateString(data.title, "No Title");
this.price = this.parsePrice(data.price);
this.rating = this.parseRating(data.rating);
this.reviewCount = this.parseReviewCount(data.reviewCount);
this.details = this.validateString(data.details, "No Details");
}
validateString(value, fallback) {
return typeof value === 'string' && value.trim() !== '' ? value.trim() : fallback;
}
parsePrice(value) {
const priceMatch = typeof value === 'string' ? value.match(/\d+(\.\d{1,2})?/) : null;
return priceMatch ? parseFloat(priceMatch[0]) : 0;
}
parseRating(value) {
return typeof value === 'string' && !isNaN(parseFloat(value)) ? parseFloat(value) : 0;
}
parseReviewCount(value) {
return typeof value === 'string' && !isNaN(parseInt(value)) ? parseInt(value) : 0;
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'networkidle2' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const results = [];
document.querySelectorAll("div[data-test='@web/site-top-of-funnel/ProductCardWrapper']").forEach(card => {
const linkElement = card.querySelector("a[href]");
if (linkElement) {
const href = linkElement.getAttribute("href");
const title = href.split("/")[2];
const url = `https://www.target.com${href}`;
results.push({ title, url });
}
});
return results;
});
for (const product of productData) {
await datapipeline.addData(new ProductSearchData(product));
}
console.log(`Successfully scraped data from: ${url}`);
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request for: ${url}, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function scrapeProductData(datapipeline, url, retries = MAX_RETRIES) {
let tries = 0;
let success = false;
while (tries <= retries && !success) {
try {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
console.log(`Navigating to: ${url}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
await autoScroll(page);
const productData = await page.evaluate(() => {
const title = document.querySelector("h1[data-test='product-title']")?.innerText || "N/A";
const ratingHolder = document.querySelector("span[data-test='ratings']");
const rating = ratingHolder ? ratingHolder.innerText.split(" ")[0] : "N/A";
const reviewCount = ratingHolder ? ratingHolder.innerText.split(" ").slice(-2, -1)[0] : "0";
const price = document.querySelector("span[data-test='product-price']")?.innerText || "N/A";
const details = document.querySelector("div[data-test='productDetailTabs-itemDetailsTab']")?.innerText || "N/A";
return { title, price, rating, reviewCount, details };
});
await datapipeline.addData(new ProductData(productData))
console.log("Successfully scraped and saved product data");
await browser.close();
success = true;
} catch (error) {
console.error(`Error scraping ${url}: ${error.message}`);
console.log(`Retrying request, attempts left: ${retries - tries}`);
tries += 1;
}
}
if (!success) {
throw new Error(`Max retries exceeded for ${url}`);
}
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise(resolve => {
const distance = 100;
const delay = 100;
const scrollInterval = setInterval(() => {
window.scrollBy(0, distance);
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
clearInterval(scrollInterval);
resolve();
}
}, delay);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push({ filename: file, urls: await readCsvAndGetUrls(file) });
}
return urls;
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
(async () => {
logger.info("Started Scraping Search Data");
const aggregateFiles = [];
const scrapeSearchDataTasks = keywords.flatMap(keyword => {
const tasks = [];
for (let pageNumber = 0; pageNumber < MAX_PAGES; pageNumber++) {
tasks.push(async () => {
const formattedKeyword = encodeURIComponent(keyword);
const csvFilename = `${keyword.replace(/\s+/g, '-').toLowerCase()}-page-${pageNumber}-search-data.csv`;
const dataPipeline = new DataPipeline(csvFilename);
const url = `https://www.target.com/s?searchTerm=${formattedKeyword}&Nao=${pageNumber * 24}`;
await scrapeSearchData(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(csvFilename);
});
}
return tasks;
});
await scrapeConcurrently(scrapeSearchDataTasks, MAX_THREADS);
const urls = await getAllUrlsFromFiles(aggregateFiles);
logger.info("Started Scraping Product Data")
const scrapeProductDataTasks = urls.flatMap(data =>
data.urls.map(url => async () => {
const filename = data.filename.replace('search-data', 'product-data');
const dataPipeline = new DataPipeline(filename);
await scrapeProductData(dataPipeline, url);
await dataPipeline.closePipeline();
})
);
await scrapeConcurrently(scrapeProductDataTasks, MAX_THREADS);
logger.info('Scraping completed');
})();
Step 6: Production Run
Now that we've completed our Target scraper, let's run it and evaluate its performance using the following configuration:
const MAX_RETRIES = 2;
const MAX_THREADS = 2;
const MAX_PAGES = 1;
const keywords = ['apple pen'];
For this run, we used 2 threads, but this can be increased for better performance.
From our Winston logs, we observed the following timings:
- Searching for the keyword took: 16 seconds
- The first scraper retrieved 10 product URLs from the listing page
- The second scraper took 96 seconds to scrape all 10 product pages
- Time per product page: 96 / 10 = 9.6 seconds
Performance Breakdown:
- Total time for 1 page: 16 seconds (search) + 96 seconds (product pages) = 112 seconds
- Average time per product page: 9.6 seconds
At 9.6 seconds per product page, this is a solid performance considering we only used 2 threads. By increasing the number of threads, we could further improve efficiency and reduce scraping time.
Legal and Ethical Considerations
Web scraping comes with legal and ethical responsibilities. You must respect privacy laws, intellectual property rights, and website policies.
If data is accessible without logging in, it’s generally considered public. If a login is required, the data is private, and scraping it may violate terms of service or privacy laws.
Websites have Terms and Conditions that define permitted use, and many include a robots.txt file that outlines scraping guidelines. While robots.txt isn’t legally binding, ignoring it could result in blocks or legal action.
Conclusion
In this guide, we built a powerful Target scraper using Puppeteer and NodeJS. You learned how to extract data efficiently, optimize performance with concurrency, and handle challenges like retries and proxies. With these techniques, you can scale your scraping workflows and adapt them for other e-commerce sites like Walmart.
To explore the technologies used in this guide, check out these resources:
More Puppeteer and NodeJS Web Scraping Guides
Here at ScrapeOps, we've got a ton of learning resources. Whether you're brand new or a seasoned web developer, we've got something for you. Check out our extensive Puppeteer Web Scraping Playbook and build something!
If you'd like to learn more from our "How To Scrape" series, take a look at the links below.
- How to Scrape Google Search With Puppeteer
- How to Scrape Reddit With Puppeteer
- How to Scrape Pinterest With NodeJS and Puppeteer