
How to Scrape Quora With Puppeteer
Quora is a Q&A platform where users ask questions and get answers from a community of experts and enthusiasts. Scraping can help collect data like questions, answers, and user opinions for research, market analysis, or content generation.
This article covers how to scrape questions and answers from Quora using NodeJS and Puppeteer.
- TLDR - How to Scrape Quora
- How to Architect Our Quora Scraper
- Understanding How to Scrape Quora
- Setting Up Our Quora Scraper Project
- Build A Quora Search Scraper
- Build A Quora Posts Scraper
- Legal and Ethical Considerations
- Conclusion
- More Puppeteer and NodeJS Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Scrape Quora
If you're short on time and just need the scraper code, follow these steps:
-
Create a new directory:
mkdir quora-scraper -
Copy the
quora-scraper.jsandpackage.jsonfiles into the "quora-scraper" directory. -
Add a
config.jsonfile in the same directory and include your ScrapeOps API key:{
"api_key": "your_api_key"
} -
Navigate to the directory and install dependencies:
npm install -
Run the scraper:
node quora-scraper.js
That's it—you're ready to start scraping!
package.json:
{
"name": "quora-scraper",
"version": "1.0.0",
"main": "quora-scraper.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"csv-parser": "^3.0.0",
"json2csv": "^6.0.0-alpha.2",
"puppeteer": "^23.10.0",
"winston": "^3.17.0"
}
}
quora-scraper.js:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const LOCATION = "us";
const MAX_RETRIES = 3;
const MAX_SEARCH_DATA_THREADS = 2;
const MAX_ANSWER_DATA_THREADS = 2;
const MAX_SEARCH_RESULTS = 2;
const keywords = ["What is nextTick in NodeJS"];
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class SearchData {
constructor(data = {}) {
this.rank = data.rank || 0;
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
if (typeof title === 'string' && title.trim() !== '') {
return title.trim();
}
return "No title";
}
validateUrl(url) {
try {
return (url && new URL(url).hostname) ? url.trim() : "Invalid URL";
} catch {
return "Invalid URL";
}
}
}
class AnswersData {
constructor(data = {}) {
this.title = this.validateAuthor(data.title);
this.answer = this.validateAnswer(data.answer);
}
validateAuthor(author) {
if (typeof author === 'string' && author.trim() !== '') {
return author.trim();
}
return "No author";
}
validateAnswer(answer) {
if (typeof answer === 'string' && answer.trim() !== '') {
return answer.trim();
}
return "No answer";
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchResults(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
let searchResults;
while (retries > 0) {
try {
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
searchResults = await page.$$eval('#rso .g', results => {
return results.map((result, index) => {
const title = result.querySelector('h3') ? result.querySelector('h3').innerText : null;
const url = result.querySelector('a') ? result.querySelector('a').href : null;
const rank = index + 1;
return { rank, title, url };
});
});
if (searchResults.length > 0) {
break;
}
} catch (error) {
console.log(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
if (!searchResults || searchResults.length === 0) {
logger.error(`Failed to scrape results for ${url} after multiple attempts.`);
await browser.close();
return;
}
searchResults = searchResults.filter(({ url }) => url.startsWith('https://www.quora.com/') && !url.includes('/profile'));
for (const result of searchResults) {
await dataPipeline.addData(new SearchData(result));
}
logger.info(`Successfully Scraped ${searchResults.length} Search Results for ${dataPipeline.csvFilename.match(/([^/]+\.csv)/)[0]}`);
await browser.close();
}
async function scrapeAnswersData(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
let totalAnswers = 0;
const page = await browser.newPage();
while (retries > 0) {
try {
console.log(`Attempting to scrape ${url}, Retries left: ${retries}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: "networkidle2" });
await page.waitForSelector('button[aria-haspopup="menu"][role="button"]', { state: 'attached' });
await page.click('button[aria-haspopup="menu"][role="button"]');
await page.waitForSelector('.puppeteer_test_popover_menu');
const options = await page.$$('.q-click-wrapper.puppeteer_test_popover_item');
await options[1].click();
await autoScroll(page);
const answers = await page.evaluate(() => {
const answerElements = document.querySelectorAll('[class^="q-box dom_annotate_question_answer_item_"]');
return Array.from(answerElements).map((answer) => {
const readMoreButton = answer.querySelector('button.puppeteer_test_read_more_button');
if (readMoreButton) {
readMoreButton.click();
}
const authorName = answer.querySelector('.q-box.spacing_log_answer_header');
const authorNameText = authorName ? authorName.innerText.split("\n")[0] : "Unknown Author";
const authorAnswer = answer.querySelector('.q-box.spacing_log_answer_content.puppeteer_test_answer_content').innerText;
return { title: authorNameText, answer: authorAnswer };
});
});
totalAnswers = answers.length;
answers.forEach((answer) => {
dataPipeline.addData(new AnswersData(answer));
});
break;
} catch (error) {
console.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
console.log('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
console.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
logger.info(`Successfully Scraped ${totalAnswers} Answers for ${url}`);
await browser.close();
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
const scrapeSearchResultsTasks = keywords.map(keyword => async () => {
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
const fileName = path.resolve(keyword.replace(/\s+/g, '-').toLowerCase() + "-search-results.csv");
const dataPipeline = new DataPipeline(fileName);
await scrapeSearchResults(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(fileName);
});
await scrapeConcurrently(scrapeSearchResultsTasks, MAX_SEARCH_DATA_THREADS);
const urls = await getAllUrlsFromFiles(aggregateFiles);
const scrapeAnswersTasks = urls.map(url => async () => {
const dataPipeline = new DataPipeline(url.match(/([^/]+)$/)[1] + "-Answers.csv");
await scrapeAnswersData(dataPipeline, url);
await dataPipeline.closePipeline();
});
await scrapeConcurrently(scrapeAnswersTasks, MAX_ANSWER_DATA_THREADS);
}
main();
Here are the key control points in the scraper that you may want to adjust:
LOCATION: Sets the country code for the location from which Quora will return data.MAX_RETRIES: Defines the number of attempts the scraper will make if it encounters an error while scraping a page.MAX_SEARCH_DATA_THREADS: The number of pages the scraper will scrape concurrently when collecting search results.MAX_ANSWER_DATA_THREADS: The number of pages the scraper will scrape concurrently when collecting answers data.MAX_SEARCH_RESULTS: The maximum number of pages to scrape for a given keyword search.keywords: A list of keywords for which you want to gather search results.
How to Architect Our Quora Scraper
Our Quora scraper consists of two parts: scrapeSearchResults and scrapeAnswersData.
scrapeSearchResults Scraper
-
This scraper runs first and generates a CSV file containing questions and their URLs.
-
You provide keywords to the scraper, and it uses these keywords to perform a Google search. For example, if the keyword is "learn rust", the scraper will search Google with the query:
https://www.google.com/search?q=learn+rust+site:quora.com&num=5
Here, num specifies the maximum number of search results.
- The scraper collects the question titles and their corresponding URLs from the search results.
- It then saves this data in a CSV file named after the keyword, such as
learn-rust.csv.
scrapeAnswersData Scraper
- This scraper uses the CSV file generated by the first scraper as input.
- It reads the file to extract all the URLs for the questions listed. For each question URL, it scrapes all the available answers from Quora.
- The scraped answers for each question are saved in separate CSV files. Each file is named after the corresponding question, such as
How-do-I-learn-the-Rust-programming-language.csv.
Understanding How to Scrape Quora
If you’ve ever tried searching on Quora, you’ll notice that access is blocked almost immediately with a login modal prompting you to sign in.

This means that performing a direct search on Quora isn’t possible without logging in. But don’t worry—there’s a way to work around this limitation.
To bypass the login requirement, we can use an alternative approach: leveraging Google Search to find Quora content. By appending site:quora.com to your search queries, we can retrieve Quora pages through Google and then scrape them directly.
Let’s break the process into simple steps to make it easy to follow:
Step 1: How To Request Quora Pages
Quora doesn’t allow searching without logging in, but we can use Google’s site: operator to search Quora pages directly. The site: operator lets us restrict search results to a specific domain.
For example, if you want to search for "learn rust" only on Quora, you can use:
learn rust site:quora.com
Here’s what the search results look like:
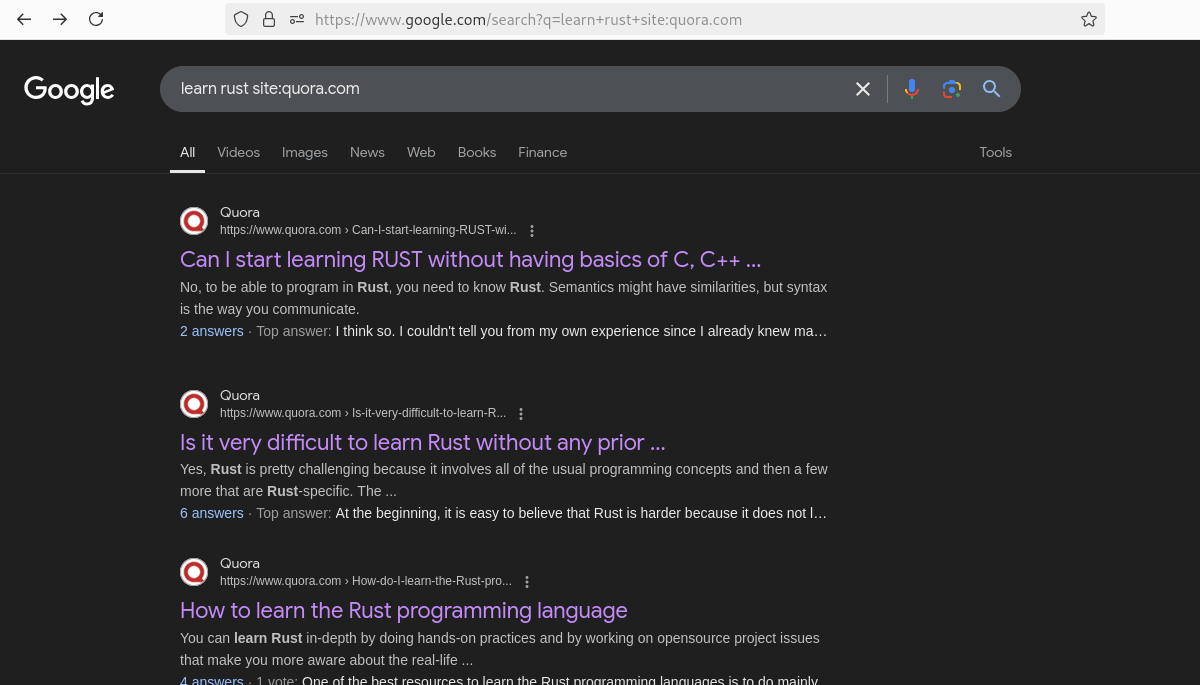
When searching programmatically, the query URL would look like this:
https://www.google.com/search?q=learn+rust+site:quora.com
We can also control the number of results per page using the num parameter in the URL. For example, to get up to 10 results per page:
https://www.google.com/search?q=learn+rust+site:quora.com&num=10
To build this programmatically, we can construct the URL like this:
const keyword = "learn rust";
const MAX_SEARCH_RESULTS = 10;
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
Once we have the search results, we can scrape the titles and URLs of the questions. Quora question links follow a simple format, like this:
https://www.quora.com/Name-of-your-post
For example, clicking a result like "How do I learn the Rust programming language?" would lead to this URL:
https://www.quora.com/How-do-I-learn-the-Rust-programming-language
Here’s what the Quora post looks like in a browser:
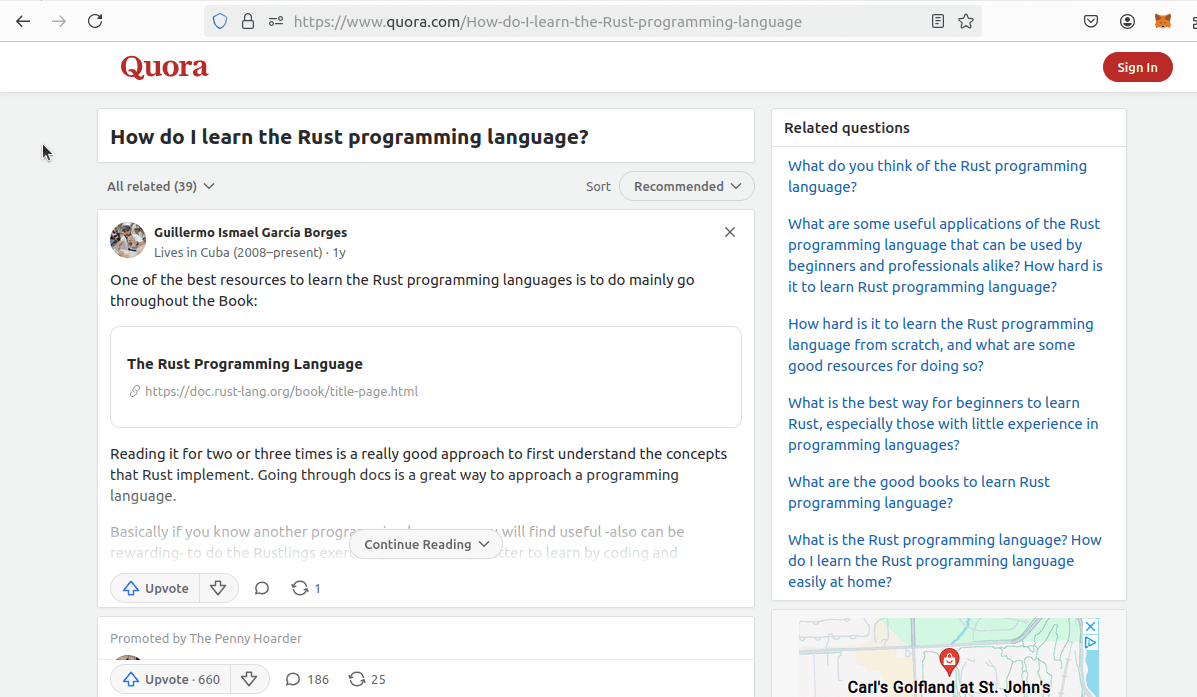
After extracting the links, we can use a second scraper (scrapeAsnwersData) to fetch detailed answers from each question page.
Step 2: How To Extract Data From Quora Results and Pages
Next, let’s determine the data we need to extract. From the Google search results, we only require the URLs and titles of Quora pages. Inspecting the search result elements reveals their structure:
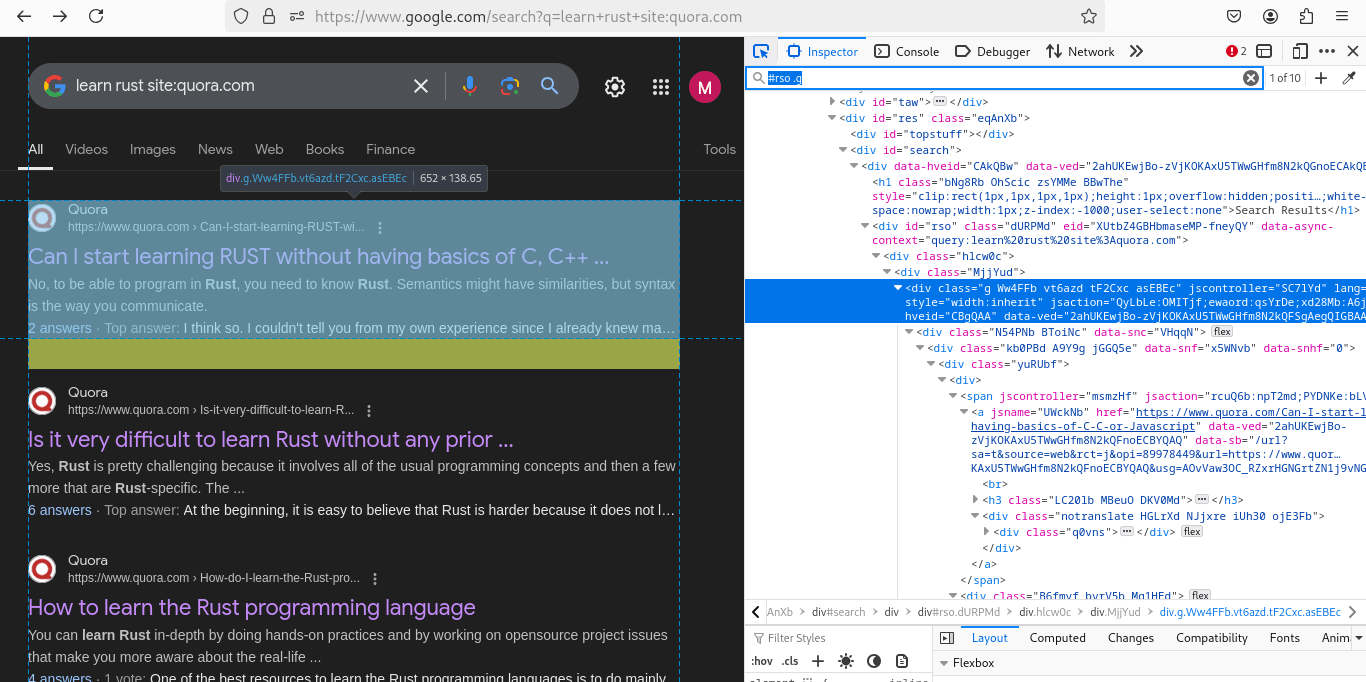
Each search result is contained within a div with the selector "#rso .g". Narrowing it further, the title is located in an h3 tag, and the link is inside an a tag.
These selectors are straightforward, but extracting data from Quora post pages is more challenging due to nested elements.
Here’s what a Quora post page looks like:
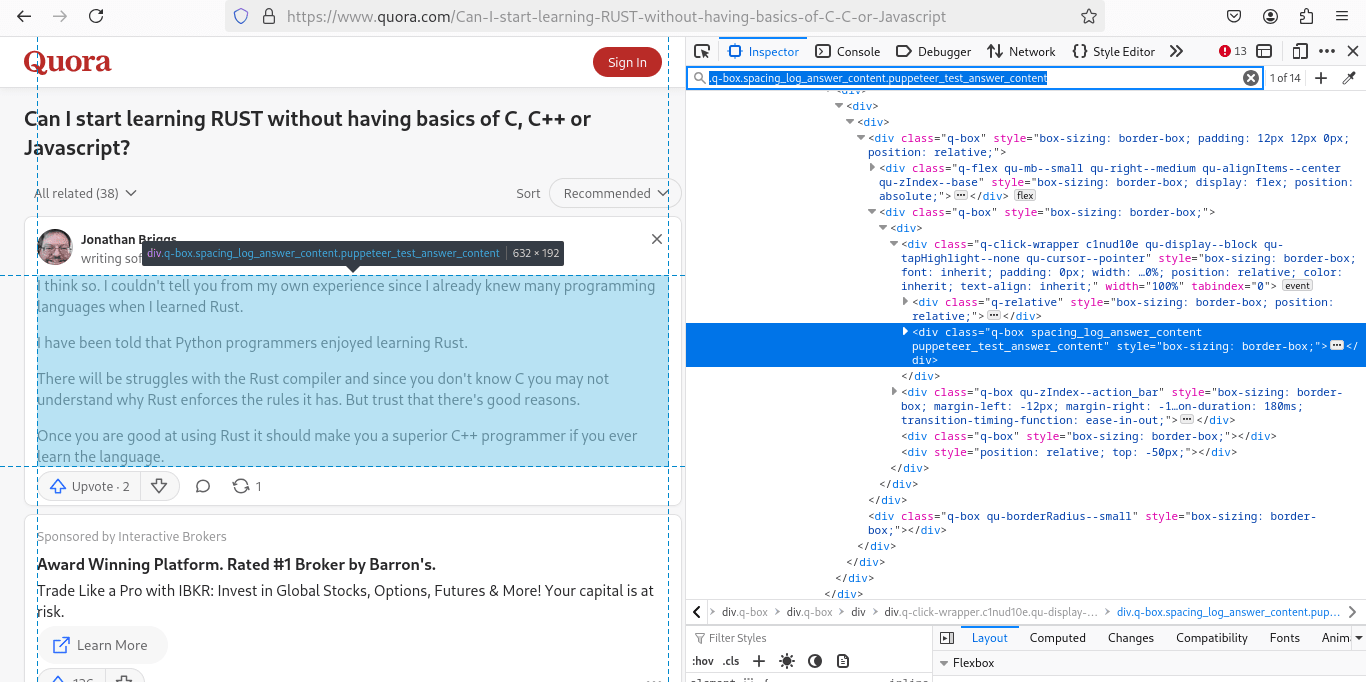
On a Quora post, we are primarily interested in the answers. To ensure we only scrape relevant ones, we first filter them using the dropdown menu:
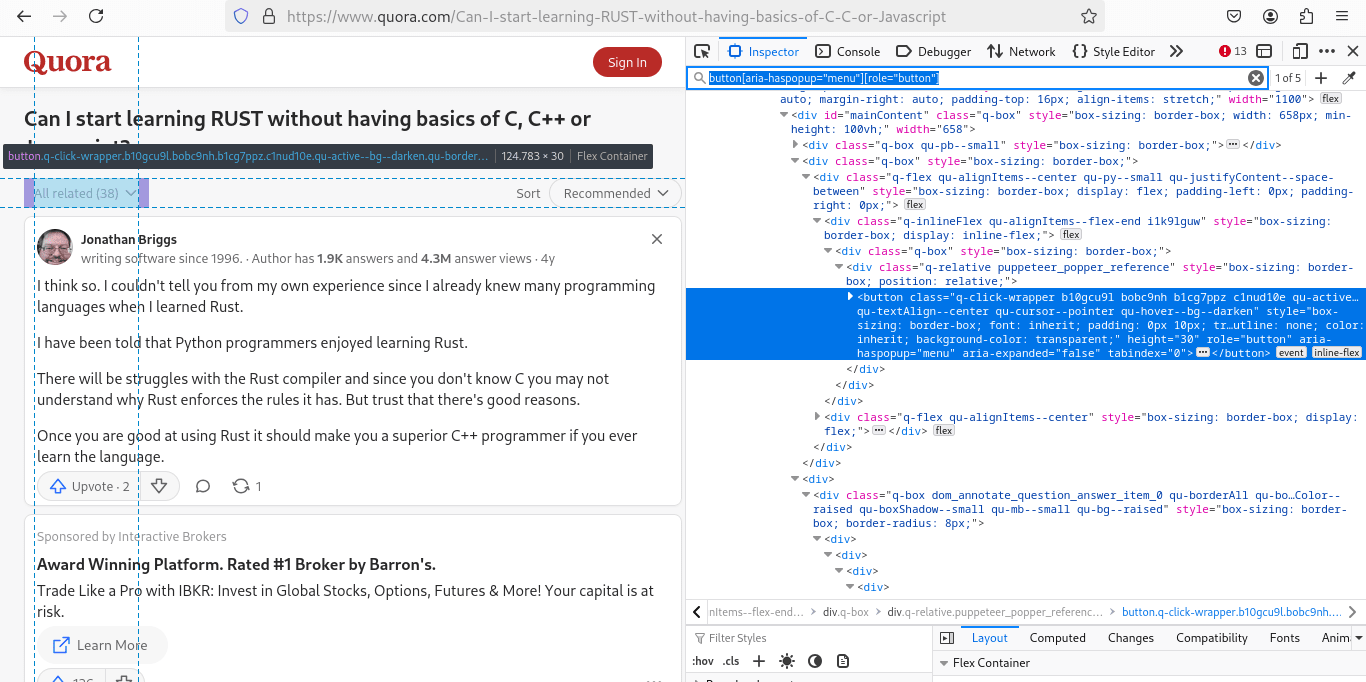
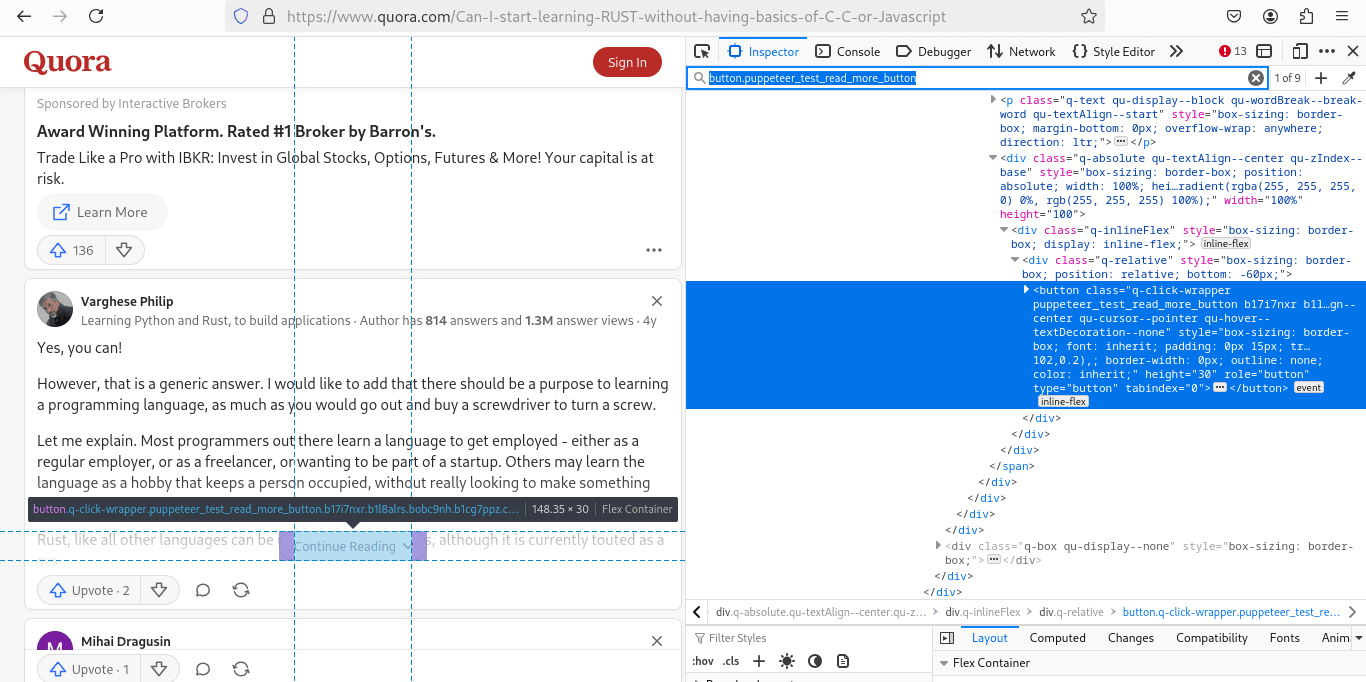
After filtering, we need to expand the "Continue Reading" button to access the full answer text:
Here are the CSS selectors I identified for scraping Quora pages:
- Dropdown filter button:
button[aria-haspopup="menu"][role="button"] - Dropdown items:
q-click-wrapper.puppeteer_test_popover_item - Continue Reading button:
button.puppeteer_test_read_more_button - Author name:
.q-box.spacing_log_answer_header - Answer content:
.q-box.spacing_log_answer_content.puppeteer_test_answer_content
Keep in mind that these selectors can change over time, so always inspect the page to ensure you’re using the correct ones.
Step 3: Geolocated Data
We don't need to worry about specific geolocation for Quora, but we'll be using the ScrapeOps Proxy API, which handles this for us.
When using the API, you can include a country parameter to route your traffic through a server in the desired country.
- To appear in the US, use
"country": "us". - To appear in the UK, use
"country": "uk".
Setting Up Our Quora Scraper Project
Let's get started by setting up the project for Puppeteer and NodeJS. Follow the steps below to create the necessary files and install dependencies.
Create a New Project Folder:
mkdir quora-scraper
cd quora-scraper
Create a package.json File:
npm init -y
This will generate the package.json file for managing dependencies.
Create the quora-scraper.js File:
touch quora-scraper.js
Install the Required Dependencies:
npm install puppeteer json2csv winston csv-parser
This will install the required libraries for:
- scraping (
Puppeteer), - parsing JSON to CSV (json2csv),
- logging (winston), and
- handling csv file operations (csv-parser).
Once these steps are done, you'll have everything set up for scraping Quora with Puppeteer and NodeJS!
Build A Quora Search Scraper
In this section, we'll create our first scraper, scrapeSearchResults, to extract Quora search results from Google. Here's what we'll cover:
- Extracting titles and URLs from Google search results.
- Cleaning and structuring the data using data classes.
- Storing the scraped data in CSV format via a data pipeline.
- Implementing concurrency for faster scraping.
- Handling anti-bot protections to avoid being blocked.
- Integrating proxy support to enhance scraping reliability.
Step 1: Create a Simple Search Data Scraper
In this step, we’ll build our first scraper named scrapeSearchResults to extract Quora links from Google search results. Here's a detailed explanation of what the code does and how it works:
- The scraper takes a
keywordas input and constructs a Google search URL targeting Quora results. Example:
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
This URL searches Google for Quora links related to the provided keyword.
-
Titles and URLs are extracted from the search results using the Puppeteer's $$eval() method.
-
In case of issues like slow network speeds or failed requests, the scraper retries up to a specified number of times (
MAX_RETRIES). -
A
try-catchblock is used to catch and handle errors gracefully, ensuring that the scraper doesn't crash unexpectedly. -
All activities, errors, and important events are logged using the winston library for better debugging and monitoring.
-
After scraping, the results are filtered to include only valid Quora links and exclude irrelevant ones (e.g., profile pages).
-
The final scraped data is printed to the console.
Here is the implementation:
const puppeteer = require('puppeteer');
const winston = require('winston');
const keyword = ["learn react"];
const MAX_SEARCH_RESULTS = 10;
const MAX_RETRIES = 3;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
async function scrapeSearchResults(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
let searchResults;
while (retries > 0) {
try {
await page.goto(url, { waitUntil: 'domcontentloaded' });
searchResults = await page.$$eval('#rso .g', results => {
return results.map((result, index) => {
const title = result.querySelector('h3') ? result.querySelector('h3').innerText : null;
const url = result.querySelector('a') ? result.querySelector('a').href : null;
const rank = index + 1;
return { rank, title, url };
});
});
if (searchResults.length > 0) {
break;
}
} catch (error) {
logger.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
if (!searchResults || searchResults.length === 0) {
logger.error(`Failed to scrape results for ${url} after multiple attempts.`);
await browser.close();
return;
}
searchResults = searchResults.filter(({ url }) => url.startsWith('https://www.quora.com/') && !url.includes('/profile'));
for (const result of searchResults) {
console.log(result)
}
logger.info(`Successfully Scraped ${searchResults.length} Search Results for ${url}`);
await browser.close();
}
async function main() {
logger.info("Started Scraping Search Results")
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
await scrapeSearchResults(url);
}
main()
Running the above code will produce results similar to this:
2024-12-13T06:58:23.707Z [INFO]: Started Scraping Search Results
{
rank: 1,
title: 'How to learn React.js within 1 month',
url: 'https://www.quora.com/How-do-I-learn-React-js-within-1-month'
}
{
rank: 2,
title: 'Is ReactJS easy to learn for beginners?',
url: 'https://www.quora.com/Is-ReactJS-easy-to-learn-for-beginners'
}
...
{
rank: 10,
title: 'Which is the best platform to learn React language?',
url: 'https://www.quora.com/Which-is-the-best-platform-to-learn-React-language'
}
2024-12-13T06:58:27.697Z [INFO]: Successfully Scraped 10 Search Results for https://www.google.com/search?q=learn%20react+site:quora.com&num=10
Step 2: Storing the Scraped Data
In the previous section, we printed the scraped data to the console. However, to make it useful, we need to store it in a persistent format. In this step:
- We create a
SearchDataclass to transform raw scraped data into clean JavaScript objects, ensuring data validity. - We design a
DataPipelineclass to handle duplicated, batching, and efficient storage into a CSV file.
SearchData Class: Transforming and Validating Data:
The SearchData class is responsible for transforming raw scraper output into structured JavaScript objects while cleaning up the data. Here's the implementation:
class SearchData {
constructor(data = {}) {
this.rank = data.rank || 0;
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
if (typeof title === 'string' && title.trim() !== '') {
return title.trim();
}
return "No title";
}
validateUrl(url) {
try {
return (url && new URL(url).hostname) ? url.trim() : "Invalid URL";
} catch {
return "Invalid URL";
}
}
}
- Rank: Defaulted to 0 if not provided.
- Title: Trimmed and validated. Invalid titles default to "No title".
- URL: Validated using the URL constructor. Invalid URLs are marked as "Invalid URL".
DataPipeline Class: Managing Storage and Deduplication:
The DataPipeline class efficiently manages data storage while ensuring deduplication and batching. Here's the code:
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
- Remove Duplicates: Tracks seen titles using a
Setto avoid duplicates. - Batching: Uses a queue to store data and writes to the CSV only when the queue reaches the specified limit.
- CSV Storage: Converts data to CSV format using json2csv and appends it to the file.
Full Implementation: Here’s how everything integrates:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const keywords = ["learn react"];
const MAX_SEARCH_RESULTS = 10;
const MAX_RETRIES = 3;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class SearchData {
constructor(data = {}) {
this.rank = data.rank || 0;
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
if (typeof title === 'string' && title.trim() !== '') {
return title.trim();
}
return "No title";
}
validateUrl(url) {
try {
return (url && new URL(url).hostname) ? url.trim() : "Invalid URL";
} catch {
return "Invalid URL";
}
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchResults(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
let searchResults;
while (retries > 0) {
try {
await page.goto(url, { waitUntil: 'domcontentloaded' });
searchResults = await page.$$eval('#rso .g', results => {
return results.map((result, index) => {
const title = result.querySelector('h3') ? result.querySelector('h3').innerText : null;
const url = result.querySelector('a') ? result.querySelector('a').href : null;
const rank = index + 1;
return { rank, title, url };
});
});
if (searchResults.length > 0) {
break;
}
} catch (error) {
console.log(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
if (!searchResults || searchResults.length === 0) {
logger.error(`Failed to scrape results for ${url} after multiple attempts.`);
await browser.close();
return;
}
searchResults = searchResults.filter(({ url }) => url.startsWith('https://www.quora.com/') && !url.includes('/profile'));
for (const result of searchResults) {
await dataPipeline.addData(new SearchData(result));
}
logger.info(`Successfully Scraped ${searchResults.length} Search Results for ${dataPipeline.csvFilename.match(/([^/]+\.csv)/)[0]}`);
await browser.close();
}
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
for (let keyword of keywords) {
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
const fileName = path.resolve(keyword.replace(/\s+/g, '-').toLowerCase() + "-search-results.csv");
const dataPipeline = new DataPipeline(fileName);
await scrapeSearchResults(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(fileName);
}
}
main()
When you run the above code, a file named learn-react-search-results.csv will be created in your current directory. This file will contain all the scraped data, including rank, title, and URL.
Example log output:
2024-12-13T07:22:11.431Z [INFO]: Started Scraping Search Results
2024-12-13T07:22:15.516Z [INFO]: Successfully Scraped 10 Search Results for learn-react-search-results.csv
Step 3: Adding Concurrency
If we have multiple keywords, our scraper processes them sequentially—scraping one keyword at a time. To improve efficiency, we can handle concurrency by launching multiple Puppeteer browser instances simultaneously.
To achieve this, we introduce a function named scrapeConcurrently, which manages our scraping tasks concurrently. Here's the implementation:
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
Next, we integrate this function into our scraper to enable concurrent processing. Here's the updated workflow:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const keywords = ["learn react", "learn rust"];
const MAX_SEARCH_RESULTS = 10;
const MAX_RETRIES = 3;
const MAX_SEARCH_DATA_THREADS = 2;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class SearchData {
constructor(data = {}) {
this.rank = data.rank || 0;
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
if (typeof title === 'string' && title.trim() !== '') {
return title.trim();
}
return "No title";
}
validateUrl(url) {
try {
return (url && new URL(url).hostname) ? url.trim() : "Invalid URL";
} catch {
return "Invalid URL";
}
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchResults(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
let searchResults;
while (retries > 0) {
try {
await page.goto(url, { waitUntil: 'domcontentloaded' });
searchResults = await page.$$eval('#rso .g', results => {
return results.map((result, index) => {
const title = result.querySelector('h3') ? result.querySelector('h3').innerText : null;
const url = result.querySelector('a') ? result.querySelector('a').href : null;
const rank = index + 1;
return { rank, title, url };
});
});
if (searchResults.length > 0) {
break;
}
} catch (error) {
console.log(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
if (!searchResults || searchResults.length === 0) {
logger.error(`Failed to scrape results for ${url} after multiple attempts.`);
await browser.close();
return;
}
searchResults = searchResults.filter(({ url }) => url.startsWith('https://www.quora.com/') && !url.includes('/profile'));
for (const result of searchResults) {
await dataPipeline.addData(new SearchData(result));
}
logger.info(`Successfully Scraped ${searchResults.length} Search Results for ${dataPipeline.csvFilename.match(/([^/]+\.csv)/)[0]}`);
await browser.close();
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
const scrapeSearchResultsTasks = keywords.map(keyword => async () => {
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
const fileName = path.resolve(keyword.replace(/\s+/g, '-').toLowerCase() + "-search-results.csv");
const dataPipeline = new DataPipeline(fileName);
await scrapeSearchResults(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(fileName);
});
await scrapeConcurrently(scrapeSearchResultsTasks, MAX_SEARCH_DATA_THREADS);
}
main()
MAX_SEARCH_DATA_THREADSto specify the maximum number of Puppeteer browser instances running simultaneously.
When running the updated code:
- The scraper processes keywords concurrently, significantly reducing overall execution time.
- To visualize the scraping process, change
headless: truetoheadless: falsein the Puppeteer options.
Now, executing the code with multiple keywords will enable concurrent scraping. This setup efficiently handles large keyword lists while maintaining flexibility to adjust concurrency limits as needed.
Example log output:
2024-12-13T07:43:50.017Z [INFO]: Started Scraping Search Results
2024-12-13T07:43:56.383Z [INFO]: Successfully Scraped 10 Search Results for learn-rust-search-results.csv
2024-12-13T07:43:57.003Z [INFO]: Successfully Scraped 10 Search Results for learn-react-search-results.csv
Step 4: Bypassing Anti-Bots
To bypass anti-bots, we'll use the ScrapeOps Proxy API. This will help us get around anti-bot measures and anything else trying to block our scraper.
We'll create a function called getScrapeOpsUrl(). This function takes a url and a location, along with a wait parameter that tells ScrapeOps how long to wait before sending back the results.
The function combines all of this into a proxied URL with our custom settings.
const LOCATION = "us";
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
Key parameters:
- api_key: Contains the ScrapeOps API key, retrieved from the config.json file.
- url: Specifies the target URL to scrape.
- country: Defines the routing location for the request, defaulting to "us".
- wait: Sets the wait time (in milliseconds) before ScrapeOps returns the response.
After integrating proxy support into our scraper, the updated implementation will be:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const keywords = ["learn react", "learn rust"];
const LOCATION = "us";
const MAX_SEARCH_RESULTS = 10;
const MAX_RETRIES = 3;
const MAX_SEARCH_DATA_THREADS = 2;
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class SearchData {
constructor(data = {}) {
this.rank = data.rank || 0;
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
if (typeof title === 'string' && title.trim() !== '') {
return title.trim();
}
return "No title";
}
validateUrl(url) {
try {
return (url && new URL(url).hostname) ? url.trim() : "Invalid URL";
} catch {
return "Invalid URL";
}
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchResults(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
let searchResults;
while (retries > 0) {
try {
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
searchResults = await page.$$eval('#rso .g', results => {
return results.map((result, index) => {
const title = result.querySelector('h3') ? result.querySelector('h3').innerText : null;
const url = result.querySelector('a') ? result.querySelector('a').href : null;
const rank = index + 1;
return { rank, title, url };
});
});
if (searchResults.length > 0) {
break;
}
} catch (error) {
console.log(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
if (!searchResults || searchResults.length === 0) {
logger.error(`Failed to scrape results for ${url} after multiple attempts.`);
await browser.close();
return;
}
searchResults = searchResults.filter(({ url }) => url.startsWith('https://www.quora.com/') && !url.includes('/profile'));
for (const result of searchResults) {
await dataPipeline.addData(new SearchData(result));
}
logger.info(`Successfully Scraped ${searchResults.length} Search Results for ${dataPipeline.csvFilename.match(/([^/]+\.csv)/)[0]}`);
await browser.close();
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
const scrapeSearchResultsTasks = keywords.map(keyword => async () => {
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
const fileName = path.resolve(keyword.replace(/\s+/g, '-').toLowerCase() + "-search-results.csv");
const dataPipeline = new DataPipeline(fileName);
await scrapeSearchResults(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(fileName);
});
await scrapeConcurrently(scrapeSearchResultsTasks, MAX_SEARCH_DATA_THREADS);
}
main()
Step 5: Production Run
Let's run our code to production and test its efficiency. We'll use 3 keywords, and 3 threads, and set the maximum results to 10. Update the code as follows:
const keywords = ["learn rust", "learn react", "learn python"];
const MAX_SEARCH_RESULT_THREADS = 3;
const MAX_SEARCH_RESULTS = 10;
After updating, run the quora-scraper.js script. Below are the logs generated during execution:
2024-12-14T09:18:43.007Z [INFO]: Started Scraping Search Results
2024-12-14T09:18:53.315Z [INFO]: Successfully Scraped 10 Search Results for learn-python-search-results.csv
2024-12-14T09:18:54.819Z [INFO]: Successfully Scraped 10 Search Results for learn-rust-search-results.csv
2024-12-14T09:18:55.918Z [INFO]: Successfully Scraped 10 Search Results for learn-react-search-results.csv
From the Winston logs, we can calculate the total time to scrape all three keywords: 12 seconds. Dividing by the number of keywords gives us 12 / 3 = 4 seconds per keyword. This performance is quite efficient!
Build A Quora Posts Scraper
With the scrapeSearchResults scraper successfully generating CSV files, it’s time to build the second scraper, scrapeAnswersData. This is how it will work:
- Read the CSV files generated by the first scraper to extract all Quora question URLs.
- Navigate to the Quora post URLs and scrape only the relevant answers data.
- Clean and structure the scraped data using data classes.
- Store the structured data in CSV format through a data pipeline.
- Implement concurrency to accelerate the scraping process.
- Handle anti-bot protections to prevent being blocked.
- Integrate proxy support to improve scraping reliability.
Step 1: Create a Simple Answer Data Scraper
In this section, we will develop the main logic for scraping answers data. Here’s the workflow for how the scraper will operate:
- Navigate to the Quora post URL.
- Wait until the page fully loads by using networkidle2.
- Click on the filter button labeled "All related" and select "Answers" to filter for relevant answers.
- Scroll to the bottom of the page to ensure all answers are fully loaded.
- Before scraping answers and author names, click the "Continue Reading" button to expand truncated answers.
- Extract the author title and the answer content.
- For now, print the scraped data to the console for validation.
Below is the implementation of the scraper logic:
const puppeteer = require('puppeteer');
const winston = require('winston');
const MAX_RETRIES = 3;
const url = "https://www.quora.com/What-is-the-best-resource-to-learn-React-js";
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
async function scrapeAnswersData(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
let totalAnswers = 0;
const page = await browser.newPage();
while (retries > 0) {
try {
console.log(`Attempting to scrape ${url}, Retries left: ${retries}`);
await page.goto(url, { waitUntil: "networkidle2" });
await page.waitForSelector('button[aria-haspopup="menu"][role="button"]', { state: 'attached' });
await page.click('button[aria-haspopup="menu"][role="button"]');
await page.waitForSelector('.puppeteer_test_popover_menu');
const options = await page.$$('.q-click-wrapper.puppeteer_test_popover_item');
await options[1].click();
await autoScroll(page);
const answers = await page.evaluate(() => {
const answerElements = document.querySelectorAll('[class^="q-box dom_annotate_question_answer_item_"]');
return Array.from(answerElements).map((answer) => {
const readMoreButton = answer.querySelector('button.puppeteer_test_read_more_button');
if (readMoreButton) {
readMoreButton.click();
}
const authorName = answer.querySelector('.q-box.spacing_log_answer_header');
const authorNameText = authorName ? authorName.innerText.split("\n")[0] : "Unknown Author";
const authorAnswer = answer.querySelector('.q-box.spacing_log_answer_content.puppeteer_test_answer_content').innerText;
return { title: authorNameText, answer: authorAnswer };
});
});
totalAnswers = answers.length;
answers.forEach((answer) => {
console.log(answer)
});
break;
} catch (error) {
console.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
console.log('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
console.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
logger.info(`Successfully Scraped ${totalAnswers} Answers for ${url}`);
await browser.close();
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
async function main() {
logger.info("Started Scraping Search Results")
await scrapeAnswersData(url)
}
main()
In the implementation:
- A utility function for auto-scrolling ensures all content on the page is loaded by scrolling to the bottom.
- A simple Winston logger is used to log scraper activity, including errors and retries.
- The URL is currently passed directly into the scraper function. In later sections, this will be updated to dynamically read URLs from a file generated by the
scrapeSearchResultsscraper.
After running the code, the console will display all the scraped data for the specified Quora post, along with detailed logs of the scraping process:
2024-12-14T09:34:59.033Z [INFO]: Started Scraping Search Results
Attempting to scrape https://www.quora.com/What-is-the-best-resource-to-learn-React-js, Retries left: 3
{
title: 'Daniel H Chang',
answer: 'In a cozy room with readily available coffee, in the comfort of your favorite text editor.'
}
...
{
title: 'Amit Dubey',
answer: 'Learning JavaScript makes more sense when you learn and write code on your own. Complete challenges in coding. Like these will help.'
}
2024-12-14T09:35:29.397Z [INFO]: Successfully Scraped 34 Answers for https://www.quora.com/What-is-the-best-resource-to-learn-React-js
Step 2: Loading URLs To Scrape
To streamline our scraper, we will load Quora post URLs directly from the files generated in the previous steps instead of manually typing each URL.
In this example, we’ll use the "learn-rust-search-results.csv" file, which contains the URLs to scrape. Here’s how the process works:
- Read the "learn-rust-search-results.csv" file containing the search results generated by the previous scraper.
- Extract all the URLs from the file.
- Store the URLs in an array to iterate over them for scraping.
Below is the implementation for reading the CSV file and extracting URLs:
const fs = require('fs');
const csv = require('csv-parser');
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
async function main() {
const aggregateFiles = ["learn-rust-search-results.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
console.log(urls);
}
main();
How It Works:
- The
readCsvAndGetUrlsfunction reads the specified CSV file and extracts rows where the url field exists. - The
getAllUrlsFromFilesfunction aggregates URLs from multiple CSV files by callingreadCsvAndGetUrlsfor each file. - For testing purposes, we specify "learn-rust-search-results.csv" as the input file and log the extracted URLs to the console.
When you run this code with the correct CSV file, the URLs are displayed as an array, similar to the following output:
[
'https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript',
'https://www.quora.com/How-do-I-learn-the-Rust-programming-language',
'https://www.quora.com/Is-it-very-difficult-to-learn-Rust-without-any-prior-programming-experience',
... 7 More Rows
]
Integration with Main Scraper:
To enhance our scraper, we’ll integrate the CSV-based URL loader into the main logic. Instead of scraping a single hardcoded URL, the scraper will now loop through all URLs from the file and process each one sequentially.
The updated implementation of the scraper:
const puppeteer = require('puppeteer');
const winston = require('winston');
const fs = require('fs');
const csv = require('csv-parser');
const MAX_RETRIES = 3;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
async function scrapeAnswersData(url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
let totalAnswers = 0;
const page = await browser.newPage();
while (retries > 0) {
try {
console.log(`Attempting to scrape ${url}, Retries left: ${retries}`);
await page.goto(url, { waitUntil: "networkidle2" });
await page.waitForSelector('button[aria-haspopup="menu"][role="button"]', { state: 'attached' });
await page.click('button[aria-haspopup="menu"][role="button"]');
await page.waitForSelector('.puppeteer_test_popover_menu');
const options = await page.$$('.q-click-wrapper.puppeteer_test_popover_item');
await options[1].click();
await autoScroll(page);
const answers = await page.evaluate(() => {
const answerElements = document.querySelectorAll('[class^="q-box dom_annotate_question_answer_item_"]');
return Array.from(answerElements).map((answer) => {
const readMoreButton = answer.querySelector('button.puppeteer_test_read_more_button');
if (readMoreButton) {
readMoreButton.click();
}
const authorName = answer.querySelector('.q-box.spacing_log_answer_header');
const authorNameText = authorName ? authorName.innerText.split("\n")[0] : "Unknown Author";
const authorAnswer = answer.querySelector('.q-box.spacing_log_answer_content.puppeteer_test_answer_content').innerText;
return { title: authorNameText, answer: authorAnswer };
});
});
totalAnswers = answers.length;
answers.forEach((answer) => {
console.log(answer)
});
break;
} catch (error) {
console.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
console.log('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
console.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
logger.info(`Successfully Scraped ${totalAnswers} Answers for ${url}`);
await browser.close();
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = ["learn-rust-search-results.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
for (let url of urls) {
await scrapeAnswersData(url);
}
}
main()
How It Works:
- The main function initializes by logging the start of the scraping process.
- The
aggregateFilesarray specifies all CSV files containing URLs to scrape. - After retrieving all URLs using
getAllUrlsFromFiles, the scraper loops through each URL and calls thescrapeAnswersDatafunction.
Example Output:
When you run the integrated scraper, it processes all URLs in the CSV file. For each URL, it logs the scraping status and displays the answers extracted from the post:
2024-12-14T09:56:09.937Z [INFO]: Started Scraping Search Results
Attempting to scrape https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript, Retries left: 3
{
title: 'Jonathan Briggs',
answer: [Answer Data]
}
{
title: 'Varghese Philip',
answer: [Answer Data]
}
...
2024-12-14T09:56:22.878Z [INFO]: Successfully Scraped 8 Answers for https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript
Attempting to scrape https://www.quora.com/How-do-I-learn-the-Rust-programming-language, Retries left: 3
{
title: 'Guillermo Ismael García Borges',
answer: [Answer Data]
}
...
2024-12-14T09:57:34.162Z [INFO]: Successfully Scraped 6 Answers for https://www.quora.com/How-do-I-learn-the-Rust-programming-language
Step 3: Storing the Scraped Data
In the previous section, we printed the scraped data to the console. To make the data more useful, we now need to store it in a persistent format. In this step:
- We create an
AnswersDataclass to transform raw scraped data into structured JavaScript objects, ensuring data validity. - We use the
DataPipelineclass, which was created earlier, to handle deduplication, batching, and efficient storage into CSV files.
AnswersData Class: Transforming and Validating Data:
The AnswersData class is responsible for transforming raw scraper output into structured JavaScript objects and cleaning up the data. Here's the implementation:
class AnswersData {
constructor(data = {}) {
this.title = this.validateAuthor(data.title);
this.answer = this.validateAnswer(data.answer);
}
validateAuthor(author) {
if (typeof author === 'string' && author.trim() !== '') {
return author.trim();
}
return "No author";
}
validateAnswer(answer) {
if (typeof answer === 'string' && answer.trim() !== '') {
return answer.trim();
}
return "No answer";
}
}
- Title: This field represents the author’s name. If the name is invalid or missing, it defaults to "No author".
- Answer: This field holds the text of the answer. If the answer is empty or invalid, it defaults to "No answer".
Here is how everything integrates:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const MAX_RETRIES = 3;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class AnswersData {
constructor(data = {}) {
this.title = this.validateAuthor(data.title);
this.answer = this.validateAnswer(data.answer);
}
validateAuthor(author) {
if (typeof author === 'string' && author.trim() !== '') {
return author.trim();
}
return "No author";
}
validateAnswer(answer) {
if (typeof answer === 'string' && answer.trim() !== '') {
return answer.trim();
}
return "No answer";
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeAnswersData(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
let totalAnswers = 0;
const page = await browser.newPage();
while (retries > 0) {
try {
console.log(`Attempting to scrape ${url}, Retries left: ${retries}`);
await page.goto(url, { waitUntil: "networkidle2" });
await page.waitForSelector('button[aria-haspopup="menu"][role="button"]', { state: 'attached' });
await page.click('button[aria-haspopup="menu"][role="button"]');
await page.waitForSelector('.puppeteer_test_popover_menu');
const options = await page.$$('.q-click-wrapper.puppeteer_test_popover_item');
await options[1].click();
await autoScroll(page);
const answers = await page.evaluate(() => {
const answerElements = document.querySelectorAll('[class^="q-box dom_annotate_question_answer_item_"]');
return Array.from(answerElements).map((answer) => {
const readMoreButton = answer.querySelector('button.puppeteer_test_read_more_button');
if (readMoreButton) {
readMoreButton.click();
}
const authorName = answer.querySelector('.q-box.spacing_log_answer_header');
const authorNameText = authorName ? authorName.innerText.split("\n")[0] : "Unknown Author";
const authorAnswer = answer.querySelector('.q-box.spacing_log_answer_content.puppeteer_test_answer_content').innerText;
return { title: authorNameText, answer: authorAnswer };
});
});
totalAnswers = answers.length;
answers.forEach((answer) => {
dataPipeline.addData(new AnswersData(answer));
});
break;
} catch (error) {
console.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
console.log('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
console.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
logger.info(`Successfully Scraped ${totalAnswers} Answers for ${url}`);
await browser.close();
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = ["learn-rust-search-results.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
for (let url of urls) {
const dataPipeline = new DataPipeline(url.match(/([^/]+)$/)[1] + "-Answers.csv");
await scrapeAnswersData(dataPipeline, url);
await dataPipeline.closePipeline();
}
}
main()
When you run this code, it will scrape answers from Quora pages listed in the "learn-rust-search-results.csv" file. For each URL, a corresponding CSV file (e.g., "Name-Of-Question-Answers.csv") will be created. Each file will contain the author’s name and the text of their answer.
Example log output:
2024-12-14T10:19:37.205Z [INFO]: Started Scraping Search Results
Attempting to scrape https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript, Retries left: 3
2024-12-14T10:20:02.043Z [INFO]: Successfully Scraped 8 Answers for https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript
Attempting to scrape https://www.quora.com/How-do-I-learn-the-Rust-programming-language, Retries left: 3
2024-12-14T10:20:23.594Z [INFO]: Successfully Scraped 6 Answers for https://www.quora.com/How-do-I-learn-the-Rust-programming-language
...
Step 4: Adding Concurrency
In this step, we'll introduce concurrency to the scrapeAnswersData function, similar to what we did with the scrapeSearchResults function. We've already created our concurrency functionality with the scrapeConcurrently function, and now we’ll integrate it into the scrapeAnswersData scraper.
Here’s how to integrate concurrency into the scrapeAnswersData function:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const MAX_RETRIES = 3;
const MAX_ANSWER_DATA_THREADS = 2;
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class AnswersData {
constructor(data = {}) {
this.title = this.validateAuthor(data.title);
this.answer = this.validateAnswer(data.answer);
}
validateAuthor(author) {
if (typeof author === 'string' && author.trim() !== '') {
return author.trim();
}
return "No author";
}
validateAnswer(answer) {
if (typeof answer === 'string' && answer.trim() !== '') {
return answer.trim();
}
return "No answer";
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeAnswersData(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
let totalAnswers = 0;
const page = await browser.newPage();
while (retries > 0) {
try {
console.log(`Attempting to scrape ${url}, Retries left: ${retries}`);
await page.goto(url, { waitUntil: "networkidle2" });
await page.waitForSelector('button[aria-haspopup="menu"][role="button"]', { state: 'attached' });
await page.click('button[aria-haspopup="menu"][role="button"]');
await page.waitForSelector('.puppeteer_test_popover_menu');
const options = await page.$$('.q-click-wrapper.puppeteer_test_popover_item');
await options[1].click();
await autoScroll(page);
const answers = await page.evaluate(() => {
const answerElements = document.querySelectorAll('[class^="q-box dom_annotate_question_answer_item_"]');
return Array.from(answerElements).map((answer) => {
const readMoreButton = answer.querySelector('button.puppeteer_test_read_more_button');
if (readMoreButton) {
readMoreButton.click();
}
const authorName = answer.querySelector('.q-box.spacing_log_answer_header');
const authorNameText = authorName ? authorName.innerText.split("\n")[0] : "Unknown Author";
const authorAnswer = answer.querySelector('.q-box.spacing_log_answer_content.puppeteer_test_answer_content').innerText;
return { title: authorNameText, answer: authorAnswer };
});
});
totalAnswers = answers.length;
answers.forEach((answer) => {
dataPipeline.addData(new AnswersData(answer));
});
break;
} catch (error) {
console.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
console.log('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
console.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
logger.info(`Successfully Scraped ${totalAnswers} Answers for ${url}`);
await browser.close();
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = ["learn-rust-search-results.csv"];
const urls = await getAllUrlsFromFiles(aggregateFiles);
const scrapeAnswersTasks = urls.map(url => async () => {
const dataPipeline = new DataPipeline(url.match(/([^/]+)$/)[1] + "-Answers.csv");
await scrapeAnswersData(dataPipeline, url);
await dataPipeline.closePipeline();
});
await scrapeConcurrently(scrapeAnswersTasks, MAX_ANSWER_DATA_THREADS);
}
main()
After this integration, when we run the code, multiple browser instances will scrape multiple URLs simultaneously. The number of concurrent browser instances will be controlled by the MAX_ANSWERS_DATA_THREADS variable, which in this case is set to 2.
Example Log Output:
2024-12-14T11:04:07.137Z [INFO]: Started Scraping Search Results
Attempting to scrape https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript, Retries left: 3
Attempting to scrape https://www.quora.com/How-do-I-learn-the-Rust-programming-language, Retries left: 3
2024-12-14T11:04:32.864Z [INFO]: Successfully Scraped 6 Answers for https://www.quora.com/How-do-I-learn-the-Rust-programming-language
2024-12-14T11:04:37.059Z [INFO]: Successfully Scraped 8 Answers for https://www.quora.com/Can-I-start-learning-RUST-without-having-basics-of-C-C-or-Javascript
...
From the Winston logs, we can observe that it took about 30 seconds to scrape two Quora posts. This means that, on average, scraping a single Quora post took about 15 seconds when using 2 concurrent threads.
Step 5: Bypassing Anti-Bots
We’ve already created the getScrapeOpsUrl function, which adds geolocation and anti-bot protection to our URL. Now, all we need to do is use this function wherever we are calling page.goto(url).
We will simply replace page.goto(url) with page.goto(getScrapeOpsUrl(url)), and that’s it.
After integrating both the scrapeSearchResults and scrapeAnswersData scrapers, the complete code looks like this:
const puppeteer = require('puppeteer');
const { parse } = require('json2csv');
const winston = require('winston');
const fs = require('fs');
const path = require('path');
const csv = require('csv-parser');
const LOCATION = "us";
const MAX_RETRIES = 3;
const MAX_SEARCH_DATA_THREADS = 2;
const MAX_ANSWER_DATA_THREADS = 2;
const MAX_SEARCH_RESULTS = 2;
const keywords = ["What is nextTick in NodeJS"];
const { api_key: API_KEY } = JSON.parse(fs.readFileSync('config.json', 'utf8'));
function getScrapeOpsUrl(url, location = LOCATION) {
const params = new URLSearchParams({
api_key: API_KEY,
url,
country: location,
wait: 5000,
});
return `https://proxy.scrapeops.io/v1/?${params.toString()}`;
}
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(({ timestamp, level, message }) => {
return `${timestamp} [${level.toUpperCase()}]: ${message}`;
})
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'quora-scraper.log' })
]
});
class SearchData {
constructor(data = {}) {
this.rank = data.rank || 0;
this.title = this.validateTitle(data.title);
this.url = this.validateUrl(data.url);
}
validateTitle(title) {
if (typeof title === 'string' && title.trim() !== '') {
return title.trim();
}
return "No title";
}
validateUrl(url) {
try {
return (url && new URL(url).hostname) ? url.trim() : "Invalid URL";
} catch {
return "Invalid URL";
}
}
}
class AnswersData {
constructor(data = {}) {
this.title = this.validateAuthor(data.title);
this.answer = this.validateAnswer(data.answer);
}
validateAuthor(author) {
if (typeof author === 'string' && author.trim() !== '') {
return author.trim();
}
return "No author";
}
validateAnswer(answer) {
if (typeof answer === 'string' && answer.trim() !== '') {
return answer.trim();
}
return "No answer";
}
}
class DataPipeline {
constructor(csvFilename, storageQueueLimit = 50) {
this.namesSeen = new Set();
this.storageQueue = [];
this.storageQueueLimit = storageQueueLimit;
this.csvFilename = csvFilename;
}
async saveToCsv() {
const filePath = path.resolve(this.csvFilename);
const dataToSave = this.storageQueue.splice(0, this.storageQueue.length);
if (dataToSave.length === 0) return;
const csvData = parse(dataToSave, { header: !fs.existsSync(filePath) });
fs.appendFileSync(filePath, csvData + '\n', 'utf8');
}
isDuplicate(title) {
if (this.namesSeen.has(title)) {
logger.warn(`Duplicate item found: ${title}. Item dropped.`);
return true;
}
this.namesSeen.add(title);
return false;
}
async addData(data) {
if (!this.isDuplicate(data.title)) {
this.storageQueue.push(data);
if (this.storageQueue.length >= this.storageQueueLimit) {
await this.saveToCsv();
}
}
}
async closePipeline() {
if (this.storageQueue.length > 0) await this.saveToCsv();
}
}
async function scrapeSearchResults(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
let searchResults;
while (retries > 0) {
try {
await page.goto(getScrapeOpsUrl(url), { waitUntil: 'domcontentloaded' });
searchResults = await page.$$eval('#rso .g', results => {
return results.map((result, index) => {
const title = result.querySelector('h3') ? result.querySelector('h3').innerText : null;
const url = result.querySelector('a') ? result.querySelector('a').href : null;
const rank = index + 1;
return { rank, title, url };
});
});
if (searchResults.length > 0) {
break;
}
} catch (error) {
console.log(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
}
if (!searchResults || searchResults.length === 0) {
logger.error(`Failed to scrape results for ${url} after multiple attempts.`);
await browser.close();
return;
}
searchResults = searchResults.filter(({ url }) => url.startsWith('https://www.quora.com/') && !url.includes('/profile'));
for (const result of searchResults) {
await dataPipeline.addData(new SearchData(result));
}
logger.info(`Successfully Scraped ${searchResults.length} Search Results for ${dataPipeline.csvFilename.match(/([^/]+\.csv)/)[0]}`);
await browser.close();
}
async function scrapeAnswersData(dataPipeline, url, retries = MAX_RETRIES) {
const browser = await puppeteer.launch({ headless: true });
let totalAnswers = 0;
const page = await browser.newPage();
while (retries > 0) {
try {
console.log(`Attempting to scrape ${url}, Retries left: ${retries}`);
await page.goto(getScrapeOpsUrl(url), { waitUntil: "networkidle2" });
await page.waitForSelector('button[aria-haspopup="menu"][role="button"]', { state: 'attached' });
await page.click('button[aria-haspopup="menu"][role="button"]');
await page.waitForSelector('.puppeteer_test_popover_menu');
const options = await page.$$('.q-click-wrapper.puppeteer_test_popover_item');
await options[1].click();
await autoScroll(page);
const answers = await page.evaluate(() => {
const answerElements = document.querySelectorAll('[class^="q-box dom_annotate_question_answer_item_"]');
return Array.from(answerElements).map((answer) => {
const readMoreButton = answer.querySelector('button.puppeteer_test_read_more_button');
if (readMoreButton) {
readMoreButton.click();
}
const authorName = answer.querySelector('.q-box.spacing_log_answer_header');
const authorNameText = authorName ? authorName.innerText.split("\n")[0] : "Unknown Author";
const authorAnswer = answer.querySelector('.q-box.spacing_log_answer_content.puppeteer_test_answer_content').innerText;
return { title: authorNameText, answer: authorAnswer };
});
});
totalAnswers = answers.length;
answers.forEach((answer) => {
dataPipeline.addData(new AnswersData(answer));
});
break;
} catch (error) {
console.error(`Error scraping ${url}. Retries left: ${retries}`);
retries--;
if (retries > 0) {
console.log('Retrying...');
await new Promise(resolve => setTimeout(resolve, 2000));
} else {
console.error(`Failed to scrape ${url} after multiple retries.`);
}
}
}
logger.info(`Successfully Scraped ${totalAnswers} Answers for ${url}`);
await browser.close();
}
async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
async function readCsvAndGetUrls(csvFilename) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(csvFilename)
.pipe(csv())
.on('data', (row) => {
if (row.url) urls.push(row.url);
})
.on('end', () => resolve(urls))
.on('error', reject);
});
}
const scrapeConcurrently = async (tasks, maxConcurrency) => {
const results = [];
const executing = new Set();
for (const task of tasks) {
const promise = task().then(result => {
executing.delete(promise);
return result;
});
executing.add(promise);
results.push(promise);
if (executing.size >= maxConcurrency) {
await Promise.race(executing);
}
}
return Promise.all(results);
};
async function getAllUrlsFromFiles(files) {
const urls = [];
for (const file of files) {
urls.push(...await readCsvAndGetUrls(file));
}
return urls;
}
async function main() {
logger.info("Started Scraping Search Results")
const aggregateFiles = [];
const scrapeSearchResultsTasks = keywords.map(keyword => async () => {
const url = `https://www.google.com/search?q=${encodeURIComponent(keyword)}+site:quora.com&num=${MAX_SEARCH_RESULTS}`;
const fileName = path.resolve(keyword.replace(/\s+/g, '-').toLowerCase() + "-search-results.csv");
const dataPipeline = new DataPipeline(fileName);
await scrapeSearchResults(dataPipeline, url);
await dataPipeline.closePipeline();
aggregateFiles.push(fileName);
});
await scrapeConcurrently(scrapeSearchResultsTasks, MAX_SEARCH_DATA_THREADS);
const urls = await getAllUrlsFromFiles(aggregateFiles);
const scrapeAnswersTasks = urls.map(url => async () => {
const dataPipeline = new DataPipeline(url.match(/([^/]+)$/)[1] + "-Answers.csv");
await scrapeAnswersData(dataPipeline, url);
await dataPipeline.closePipeline();
});
await scrapeConcurrently(scrapeAnswersTasks, MAX_ANSWER_DATA_THREADS);
}
main();
Step 6: Production Run
Now, let's run our entire "quora-scrape.js" script and assess the performance. We'll use one keyword, set the maximum search results to 4, and run both scrapers with 2 threads. After executing, we can analyze the performance using the Winston log.
From the logs, we can conclude that it took approximately 5 seconds to scrape all the search results and around 11 seconds to scrape each post.
Legal and Ethical Considerations
When scraping the web, you need to pay attention to your target site's Terms of Service and their robots.txt. Legal or not, when you violate a site's terms, you can get suspended or even permanently banned.
Quora's terms are available to view here. Here is their robots.txt.
Public data is generally free to scrape. Public data is any data that is not gated behind a login page or some other type of authentication.
When scraping private data, you are subject to a site's terms and privacy laws in the site's jurisdiction. If you don't know if your scraper is legal, you should consult an attorney.
Conclusion
Thank you for reading! You now have a comprehensive understanding of web scraping with Puppeteer in Node.js. You’ve successfully built a scraper that handles data extraction from Quora, including scraping, data storage, concurrency, and proxy integration. This scraper is equipped to efficiently handle large-scale scraping tasks.
If you'd like to learn more about the technologies used in this article, check out the following resources:
More Puppeteer and NodeJS Web Scraping Guides
Here at ScrapeOps, we've got a ton of learning resources. Whether you're brand new or a seasoned web developer, we've got something for you.
Check out our extensive Puppeteer Web Scraping Playbook and build something!
If you'd like to learn more from our "How To Scrape" series, take a look at the links below.