How To Bypass Anti-Bots With NodeJS
Bots, automated software programs, are deployed across various websites to perform various repetitive tasks. However, these bots often encounter anti-bot measures designed to protect websites from malicious activities such as data scraping, spamming, and unauthorized access. While these security measures safeguard valuable content and maintain server integrity, they pose significant challenges for legitimate web scrapers.
This guide will outline various methods for bypassing anti-bot measures during web scraping using NodeJS.
- TLDR: How To Bypass Anti-Bots With NodeJS
- Understanding Anti-Bot Mechanisms
- Summary: How To Bypass Anti-Bots With NodeJS
- Method #1: Optimize Request Fingerprints
- Method #2: Use Rotating Proxy Pools
- Method #3: Use Fortified Headless Browsers
- Method #4: Use Managed Anti-Bot Bypasses
- Method #5: Solving CAPTCHAs
- Method #6: Scrape Google Cache Version
- Method #7: Reverse Engineer Anti-Bot Systems
- Case Study - Scrape Petsathome.com
- Conclusion
- More Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: How To Bypass Anti-Bots With NodeJS
For those who need a quick solution, here is a simple script using NodeJS and a rotating proxy service to bypass basic anti-bot measures.
The script sends a request through the ScrapeOps proxy to avoid detection.
const playwright = require("playwright");
const cheerio = require("cheerio");
// ScrapeOps proxy configuration
PROXY_USERNAME = "scrapeops.headless_browser_mode=true";
PROXY_PASSWORD = "SCRAPE_OPS_API_KEY";
PROXY_SERVER = "proxy.scrapeops.io";
PROXY_SERVER_PORT = "5353";
(async () => {
const browser = await playwright.chromium.launch({
headless: true,
proxy: {
server: `http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`,
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
},
});
const context = await browser.newContext({ ignoreHTTPSErrors: true });
const page = await context.newPage();
try {
await page.goto("https://www.example.com", { timeout: 180000 });
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
let $ = cheerio.load(bodyHTML);
// do additional scraping logic...
} catch (err) {
console.log(err);
}
await browser.close();
})();
In this example:
- Playwright is configured to use the ScrapeOps proxy server for requests.
- By rotating through a pool of proxies, you can distribute your requests across multiple IP addresses, reducing the risk of being blocked.
- The proxy details (username, password, host, and port) are configured to authenticate and route your request through a different IP.
- You can simply plug your website into the
www.example.comand be ready to go.
Understanding Anti-Bot Mechanisms
Websites employ a variety of techniques to detect and block bot traffic. Some of the most common methods include:
-
IP Blocking: This method restricts access based on the IP address. Websites track the IP addresses of incoming requests and block those exhibiting unusual patterns, such as making too many requests in a short period.
-
User-Agent Detection: Websites analyze the User-Agent string in HTTP headers to identify bots. Bots often use default User-Agent strings that can be easily detected.
-
JavaScript Challenges: Some websites require the execution of JavaScript to verify the client's authenticity. This can involve solving puzzles or performing actions that are difficult for bots to replicate.
-
CAPTCHA Challenges: CAPTCHAs present puzzles that are easy for humans but challenging for bots. These can be in the form of text recognition, image selection, or other tasks.
-
Rate Limiting: This technique limits the number of requests a single IP address can make within a specified timeframe, making it difficult for bots to scrape data quickly.
Anti-Bot Measurement Systems
Several advanced anti-bot systems are widely used to protect websites:
-
PerimeterX: This system uses machine learning and behavioral analysis to detect and block bot traffic in real-time.
-
DataDome: Known for its comprehensive approach, DataDome offers real-time bot detection and protection using machine learning algorithms.
-
Cloudflare: A popular service that provides security and performance enhancements, including bot mitigation through JavaScript challenges and rate limiting.
Importance of Bypassing Anti-Bots
For legitimate use cases such as data analysis, market research, and competitive intelligence, bypassing anti-bot measures is crucial. Effective strategies enable web scrapers to access valuable information while complying with legal and ethical standards.
However, it's important to note that bypassing anti-bot measures should always be done responsibly and in accordance with the law and the target website's terms of service and other legal documents.
How To Bypass Anti-Bots With NodeJS
NodeJS, with its powerful libraries and asynchronous capabilities, is an excellent choice for developing web scrapers capable of bypassing anti-bot measures.
Tools such as Puppeteer, Axios, and Selenium provide the necessary functionality to mimic human-like interactions and evade detection. NodeJS's non-blocking I/O model makes it particularly suitable for handling multiple concurrent requests, which is often required when dealing with sophisticated anti-bot measures.
Challenges Posed by Websites
Modern websites use a variety of techniques to prevent automated access and protect their content. These anti-bot measures are designed to distinguish between human users and bots, making it challenging to scrape data effectively. Here are some of the key challenges:
-
Rate Limiting: Websites often implement rate limits to restrict the number of requests that can be made from a single IP address within a specific timeframe. Exceeding these limits can result in temporary or permanent blocks.
-
IP Blocking: Websites can identify and block IP addresses that exhibit unusual patterns of behavior, such as making numerous requests in a short period or using known proxy servers.
-
User-Agent Detection: Many websites analyze the User-Agent string sent by browsers to detect and block requests that originate from known bots. This string identifies the browser and operating system being used.
-
JavaScript Challenges: Advanced anti-bot systems use JavaScript challenges that require the browser to execute scripts, perform actions, or render dynamic content to verify the legitimacy of the user.
-
CAPTCHAs: CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart) present challenges like image recognition or text-based puzzles that are designed to be easy for humans but difficult for bots.
-
Session and Cookie Tracking: Websites may use cookies and session identifiers to track user interactions. Bots that fail to manage or mimic these sessions accurately can be detected and blocked.
-
Behavioral Analysis: Some anti-bot systems analyze user behavior, such as mouse movements, scrolling patterns, and click sequences, to distinguish between human and automated interactions.
Potential Solutions
Bypassing these anti-bot mechanisms requires a combination of strategies to mimic human-like behavior and avoid detection. Here’s how you can address each challenge using NodeJS:
-
Optimize Request Fingerprints: Rotate HTTP headers and User-Agent strings to mimic different browsers and devices. This helps in avoiding detection based on static request patterns.
-
Use Rotating Proxy Pools: Utilize a pool of proxies to rotate IP addresses, distributing requests across multiple IPs to avoid hitting rate limits and IP-based blocks.
-
Use Fortified Headless Browsers: Puppeteer with the stealth plugin or Playwright can help render content and interact with web pages as a real user would.
-
Use Managed Anti-Bot Bypasses: Opt for proxy providers that offer built-in anti-bot bypass solutions. These providers manage sophisticated anti-bot measures for you, allowing you to focus on data extraction.
-
Solving CAPTCHAs: Integrate with CAPTCHA-solving services that use human workers or advanced algorithms to solve CAPTCHAs programmatically.
-
Scrape Google Cache Version: Access cached versions of web pages from search engines like Google to bypass direct anti-bot defenses.
-
Reverse Engineer Anti-Bot Systems: Analyze the specific anti-bot mechanisms of the target website and develop custom solutions to address them. This may involve inspecting network traffic, understanding request patterns, and adapting your approach based on findings.
By implementing these solutions, you can effectively navigate the challenges posed by modern anti-bot systems and achieve successful web scraping. Each approach has its own strengths and can be combined for optimal results.
Method #1: Optimize Request Fingerprints
Challenge
Websites often analyze user-agent strings and headers sent by web browsers to identify and block bot traffic. This method is based on the assumption that bots use default or non-human-like configurations.
Solution: Header Optimization
HTTP headers and User Agents are crucial components of web requests. By optimizing these headers, scrapers can better mimic genuine browser requests. This involves customizing the headers to closely resemble those sent by popular web browsers.
Example Code:
const axios = require('axios');
async function fetchPage() {
const response = await axios.get('http://example.com', {
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Referer': 'http://example.com'
}
});
console.log(response.data);
}
fetchPage();
Explanation:
User-Agent: This header identifies the client software. Setting it to a commonly used User-Agent string can help avoid detection.Accept-Language: This header indicates the preferred language of the client. Setting it to a commonly used value can make the request appear more genuine.Accept-Encoding: This header indicates the content encoding types the client can handle. Setting it to standard values likegzip, deflate, brmakes the request appear more browser-like.Connection: This header controls whether the network connection stays open after the current transaction. Setting it tokeep-alivemimics typical browser behavior.Referer: This header indicates the URL of the page that referred the request. Setting it appropriately can make the request seem more legitimate.
By rotating headers and User-Agent strings, web scrapers can avoid detection and access restricted content.
Use Cases:
- 403 Forbidden errors: Occur when the server refuses to fulfill the request.
- 429 Too Many Requests errors: Indicate that the client has sent too many requests in a given amount of time.
This method works best when combined with other techniques, such as rotating IP addresses and managing cookies, to further mimic human behavior.
Method #2: Use Rotating Proxy Pools
Challenge
Websites may block access from IP addresses that exhibit suspicious behavior or high request rates. This method targets the IP addresses of incoming requests and blocks those making too many requests or exhibiting non-human patterns.
Solution: IP Rotation Using Proxies
IP rotation involves changing the IP address used for web scraping requests to evade detection. This can be achieved using proxy services that provide a pool of IP addresses. Proxies act as intermediaries between the client and the target website, masking the client's actual IP address.
Code Example Using ScrapeOps API:
const playwright = require("playwright");
const cheerio = require("cheerio");
// ScrapeOps proxy configuration
PROXY_USERNAME = "scrapeops.headless_browser_mode=true";
PROXY_PASSWORD = "SCRAPE_OPS_API_KEY";
PROXY_SERVER = "proxy.scrapeops.io";
PROXY_SERVER_PORT = "5353";
(async () => {
const browser = await playwright.chromium.launch({
headless: true,
proxy: {
server: `http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`,
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
},
});
const context = await browser.newContext({ ignoreHTTPSErrors: true });
const page = await context.newPage();
try {
await page.goto("https://www.example.com", { timeout: 180000 });
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
let $ = cheerio.load(bodyHTML);
// do additional scraping logic...
} catch (err) {
console.log(err);
}
await browser.close();
})();
Explanation: This script configures Playwright to use the ScrapeOps proxy server for requests. By rotating through a pool of proxies, you can distribute your requests across multiple IP addresses, reducing the risk of being blocked. The proxy details (username, password, host, and port) are configured to authenticate and route your request through a different IP.
Importance of Paid Proxies: While free or public proxies may be tempting, they often come with significant drawbacks such as slow speeds, unreliability, and high chances of being blacklisted. Paid proxy services offer better performance, and reliability, and are less likely to be blocked, making them a better choice for serious web scraping operations.
Use Cases:
- 403 Forbidden errors: Indicate that the server is refusing to fulfill the request from a particular IP address.
- JavaScript challenges: Require the execution of JavaScript to verify the client's authenticity. Rotating proxies can help bypass these challenges by distributing the requests across multiple IP addresses.
This method can be enhanced by using residential proxies, which use IP addresses assigned to real residential locations, making them less likely to be detected and blocked by websites.
Method #3: Use Fortified Headless Browsers
Challenge
Websites may employ JavaScript challenges to detect bot behavior, requiring user interaction or executing JavaScript code to verify the browser's capabilities.
These challenges can include rendering dynamic content, solving puzzles, or performing other actions that are difficult for bots to replicate.
Solution: Dynamic Rendering Using Headless Browsers
Headless browsers like Puppeteer and Playwright can render dynamic content, simulate user interactions, and execute JavaScript, making them effective tools for bypassing sophisticated anti-bot measures. These tools
operate in a similar way to regular web browsers but without a graphical user interface, making them ideal for automated tasks.
Example Code:
const puppeteer = require('puppeteer');
async function fetchPage() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('http://example.com', { waitUntil: 'networkidle2' });
const content = await page.content();
console.log(content);
await browser.close();
}
fetchPage();
Explanation:
puppeteer.launch: This function launches a new browser instance in headless mode (without a graphical user interface).page.goto: This function navigates to the specified URL and waits until the network is idle (i.e., all network connections are closed) before proceeding.page.content: This function retrieves the HTML content of the page.browser.close: This function closes the browser instance.
Fortified headless browsers, such as Selenium with undetected-chromedriver, further enhance the ability to bypass advanced anti-bot systems. These tools can mimic user interactions, such as mouse movements and keyboard inputs, making them appear more human-like.
Use Cases:
- Bypassing Cloudflare and other sophisticated anti-bot systems: These systems often rely on JavaScript challenges and other techniques that require a full browser to execute. Headless browsers can handle these challenges and retrieve the desired content.
Using headless browsers requires more computational resources than simpler HTTP requests, but they offer a higher success rate for bypassing sophisticated anti-bot measures.
Method #4: Use Managed Anti-Bot Bypasses
Challenge
Some anti-bot systems are very difficult to bypass and require the use of highly fortified browsers in combination with residential proxies and optimized headers/cookies. These systems employ advanced machine learning algorithms and behavioral analysis to detect and block bot traffic.
Solution: Managed Anti-Bot Bypasses
Proxy providers offer managed anti-bot bypass solutions that handle complex evasion techniques on behalf of the user. These services ensure successful requests but can be costly. They often combine multiple techniques, such as IP rotation, header optimization, and JavaScript execution, to bypass anti-bot measures.
Explanation:
params: This object specifies the parameters for the request, including the API key, target URL, and the level of anti-bot bypass required.https://proxy.scrapeops.io/v1/: This URL points to the ScrapeOps Proxy Aggregator service, which handles the complex evasion techniques on behalf of the user.
Proxy Providers:
| Proxy Provider | Anti-Bot Solution | Pricing Method |
|---|---|---|
| ScrapeOps | Anti-Bot Bypasses | Pay per successful request |
| BrightData | Web Unlocker | Pay per successful request |
| Oxylabs | Web Unblocker | Pay per GB |
| Smartproxy | Site Unblocker | Pay per GB |
| Zyte | Zyte API | Pay per successful request |
| ScraperAPI | Ultra Premium | Pay per successful request |
| ScrapingBee | Stealth Proxy | Pay per successful request |
| Scrapfly | Anti-Scraping Protection | Pay per successful request |
These providers offer managed services that take care of the complexities of bypassing advanced anti-bot measures, allowing developers to focus on their core tasks.
While managed anti-bot bypass services can be expensive, they offer a reliable solution for accessing high-value content on well-protected websites.
These anti-bot solutions do work, but they can become extremely expensive when used at scale. Prices range from $1,000 to $5,000 to scrape 1M pages per month.
As part of the ScrapeOps Proxy Aggregator we aggregate these anti-bot bypassing solutions together and find the best-performing and cheapest option for your use case.
For example, a user can activate the Cloudflare Bypass by simply adding bypass=cloudflare_level_1 to your API request, and the ScrapeOps proxy will use the best & cheapest Cloudflare bypass available for your target domain.
const axios = require('axios');
const baseUrl = 'https://proxy.scrapeops.io/v1/';
const params = {
api_key: 'YOUR_API_KEY',
url: 'http://example.com/',
bypass: 'cloudflare_level_1'
};
axios.get(baseUrl, { params })
.then(response => {
console.log('Response:', response.data);
})
.catch(error => {
console.error('Error:', error);
});
Here is a list of available bypasses to send as parameters:
| Bypass | Description |
|---|---|
cloudflare_level_1 | Use to bypass Cloudflare protected sites with low security settings. |
cloudflare_level_2 | Use to bypass Cloudflare protected sites with medium security settings. |
cloudflare_level_3 | Use to bypass Cloudflare protected sites with high security settings. |
incapsula | Use to bypass Incapsula protected sites. |
perimeterx | Use to bypass PerimeterX protected sites. |
datadome | Use to bypass DataDome protected sites. |
Method #5: Solving CAPTCHAs
Challenge
CAPTCHA challenges present images, text, or puzzles that humans can typically solve but are difficult for bots. These challenges are designed to differentiate between human users and automated bots.
Solution: Utilize CAPTCHA-Solving Services
Automating CAPTCHA solving involves using third-party services that employ human workers to solve CAPTCHA challenges programmatically. These services typically provide APIs that can be integrated into web scraping scripts to solve CAPTCHAs on demand.
Code Example Using 2Captcha:
const Captcha = require("2captcha");
const solver = new Captcha.Solver("TWO_CAPTCHA_API_KEY");
solver
.recaptcha("RECAPTCHA_ID", "RECAPTCHA_URL")
.then((res) => {
console.log("reCAPTCHA passed successfully.");
})
.catch((err) => {
console.error(err.message);
});
Explanation: By utilizing service 2captcha, and bypassing the CAPTCHA ID and the URL appropriately, the service is able to effectively resolve any presented CAPTCHA challenge.
Use Cases: This method is effective for automating the process of solving CAPTCHAs, ensuring that your scraping operations remain uninterrupted. It's particularly useful for websites that frequently use CAPTCHA challenges to deter bots.
By integrating CAPTCHA-solving services into web scraping scripts, developers can automate the process of bypassing CAPTCHA challenges and accessing the desired content.
Method #6: Scrape Google Cache Version
Challenge
Google Cache allows access to a snapshot of a website, bypassing real-time anti-bot measures. When Google crawls and indexes a website, it stores a cached version of the page. This cached version can be accessed through Google's servers, which do not apply the same anti-bot measures as the original website.
Solution
Scrape the cached version of the target page available through Google Cache. This approach can be particularly useful when the target website employs aggressive anti-bot measures.
Example Code:
const axios = require('axios');
async function fetchGoogleCache() {
const response = await axios.get('http://webcache.googleusercontent.com/search?q=cache:http://example.com');
console.log(response.data);
}
fetchGoogleCache();
Explanation:
http://webcache.googleusercontent.com/search?q=cache:: This URL format accesses the cached version of the specified URL (http://example.com) on Google Cache.axios.get: This function sends a GET request to the Google Cache URL and retrieves the cached content.
Advantages:
- Bypasses real-time anti-bot measures: Since the request is made to Google's servers, the target website's anti-bot measures are not triggered.
- Fast and reliable access: Google Cache provides a quick and reliable way to access website content without dealing with anti-bot challenges.
Disadvantages:
- Cached version may not reflect the most recent content: The cached version may be outdated, depending on how frequently Google crawls and updates the cache.
Use Cases:
- Accessing historical content: Google Cache can be useful for accessing older versions of web pages.
- Bypassing aggressive anti-bot measures: When other methods fail, Google Cache can provide an alternative way to access content.
While scraping Google Cache is a useful technique, it should be used judiciously and in conjunction with other methods to ensure access to the most recent and relevant content.
Method #7: Reverse Engineer Anti-Bot Systems
Reverse engineering anti-bot systems involves a deep analysis and replication of security measures to effectively bypass them. This method requires a detailed understanding of both the target website's defenses and the underlying technologies used to implement these protections.
Challenge
The core challenge of reverse engineering anti-bot systems is to comprehend and replicate the mechanisms designed to detect and block automated requests. This often entails a thorough examination of network traffic, JavaScript code, and server-client interactions to develop a strategy that circumvents these defenses.
Solution: Reverse Engineering Techniques
To tackle the problem, one needs to analyze various aspects of the anti-bot systems, including:
- Network Traffic Analysis: Observing and decoding the requests and responses between the client and server to identify any anti-bot measures in play.
- JavaScript Code Analysis: Inspecting and understanding the JavaScript code executed on the client side, which may involve security checks or dynamic challenges.
- Behavior Replication: Developing methods to replicate required behaviors, such as executing JavaScript or simulating user interactions, to pass the anti-bot checks.
Advantages:
- Resource Efficiency: A well-designed custom bypass can be more resource-efficient compared to running multiple headless browser instances, making it suitable for large-scale operations.
- Customization: Directly addressing the inner workings of anti-bot systems allows for precise control and potentially higher success rates.
- Long-Term Adaptability: Once established, a custom bypass can be adjusted to accommodate updates and changes in anti-bot technologies.
Disadvantages:
- Technical Complexity: The process demands advanced knowledge of network protocols, JavaScript obfuscation, and browser behaviors, making it a complex and time-consuming task.
- Maintenance: As anti-bot systems evolve, maintaining the bypass solution requires continuous updates and adaptations.
- Legal and Ethical Considerations: Custom bypass solutions may infringe on the terms of service of the targeted websites, raising potential legal and ethical issues.
Suitability:
Reverse engineering is most suitable for:
- Experienced Developers: Those with expertise in cybersecurity, reverse engineering, and network analysis.
- Large-Scale Operations: Enterprises or proxy services where efficiency and cost-effectiveness are crucial.
For many developers and smaller-scale projects, simpler and more straightforward bypass methods are often more practical and efficient.
Technical Overview:
Successfully bypassing anti-bot protections involves understanding both server-side and client-side verification techniques:
-
Server-side Techniques:
- IP Reputation: Ensuring proxies have a high reputation to avoid IP-based blocks.
- HTTP Headers: Crafting headers that mimic legitimate browsers to bypass integrity checks.
- TLS & HTTP/2 Fingerprints: Adjusting client fingerprints to match those of legitimate browsers.
-
Client-side Techniques:
- Browser Web APIs: Emulating browser environments to bypass checks relying on specific APIs.
- Canvas Fingerprinting: Matching device fingerprints to avoid detection based on hardware configurations.
- Event Tracking: Simulating user interactions to mimic legitimate user behavior.
- CAPTCHAs: Implementing algorithms or using human-based solving services to overcome CAPTCHAs.
Ethical Challenges
Reverse engineering may contravene the terms of service of targeted platforms and services. It is important to consider the legal implications and ensure compliance with relevant terms and agreements.
Reverse engineering anti-bot protections represent a potent strategy for bypassing sophisticated security measures but, however, entails significant technical complexity. This method is best suited for those with advanced technical skills and resources to handle its demands.
Given the complexity and resource requirements, reverse engineering will not be explored further in this chapter. Instead, those interested are encouraged to delve into topics such as network protocols, JavaScript deobfuscation, and browser fingerprinting for a deeper understanding of this approach.
Case Study - Scrape Petsathome.com
This chapter examines the application of various scraping methods and techniques explained so far on the website Petsathome.com.
Attempt with Vanilla NodeJS Code
When scraping Petsathome.com using basic/vanilla Node.js code, the page loads normally without any restrictions. The following code snippet demonstrates how to fetch and output the page title using axios and cheerio:
const axios = require('axios');
const cheerio = require('cheerio');
const url = 'https://www.petsathome.com/';
axios.get(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
const pageTitle = $('title').text();
console.log(pageTitle);
})
.catch(error => {
console.error('Error fetching the webpage:', error);
});
The result of running this code is shown in the screenshot below:
Implementing Anti-Bot Bypass Techniques
The subsequent sections apply various anti-bot bypass techniques to the Petsathome.com website, detailing the results of each method.
1. Optimizing Request Fingerprints
The initial approach involved modifying request headers to mimic those of a legitimate browser. This technique aimed to avoid detection and blocking.
Here’s the result of optimizing request fingerprints:
2. Using Rotating Proxy Pools
By employing rotating proxy pools, the access was significantly improved by varying IP addresses. This method reduced the chances of blocks and circumvented IP-based rate limiting.
Using ScrapeOps's proxy server yielded the same result:
3. Deploying Fortified Headless Browsers
Utilizing headless browsers, configured to simulate human behavior, effectively bypassed Cloudflare's initial defenses. These browsers rendered JavaScript and managed dynamic content efficiently.
Using Puppeteer with stealth features resulted in the following output:
4. Leveraging Managed Anti-Bot Bypass Services
Managed anti-bot services provided consistent access with minimal setup by dynamically adapting strategies based on site responses. This method ensured reliable scraping operations.
The screenshot below shows the result using managed anti-bot services:
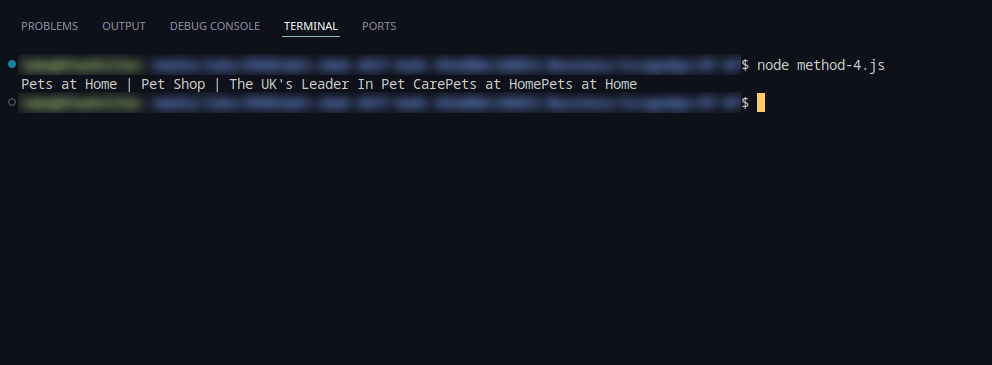
5. Solving CAPTCHAs
Integrating a CAPTCHA-solving service greatly facilitated the scraping process by overcoming CAPTCHA challenges. Although Petsathome.com did not present a CAPTCHA, this method proved successful in resolving reCAPTCHAs on other pages.
6. Scraping Google Cache Version
Accessing the Google Cache provided a fallback for retrieving static content, bypassing dynamic content challenges, and preserving historical data snapshots.
However, the attempt to scrape the Google Cache resulted in the following error:
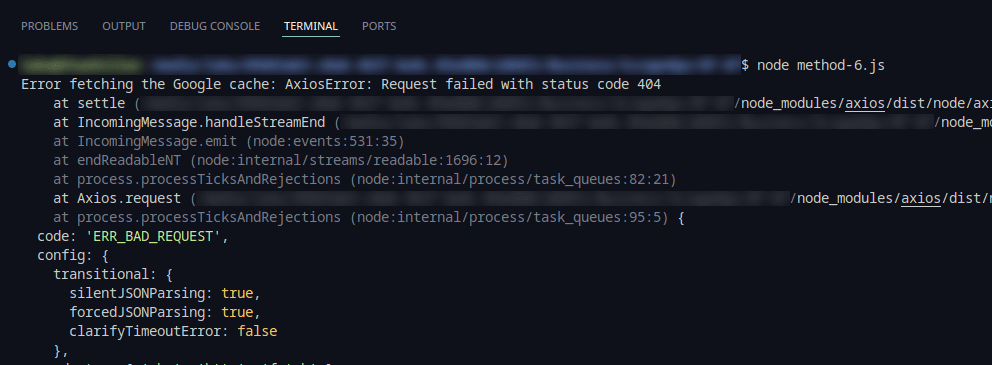
In this case, the Google Cache contained no results, making this method unusable.
7. Reverse Engineering Anti-Bot Measures
Exploring reverse engineering techniques offers a complex yet potentially effective solution. Since this approach was not implemented, it will not be covered in detail here.
Comparison of Techniques
| Method | Efficiency | Use Case | Success |
|---|---|---|---|
| Optimize Request Fingerprints | Moderate | Initial evasion, limited dynamic content | Successful |
| Use Rotating Proxy Pools | High | IP rotation, bypassing rate limits | Successful |
| Use Fortified Headless Browsers | High | Handling JavaScript, dynamic content | Successful |
| Use Managed Anti-Bot Bypasses | Moderate | Consistent access, minimal setup required | Successful |
| Solving CAPTCHAs | High | Automating CAPTCHA resolution | Successful |
| Scrape Google Cache Version | Low | Static content retrieval, historical data | Unsuccessful |
Tips for Troubleshooting Common Issues
- IP Blocking: Rotate proxies frequently to evade IP-based blocks.
- CAPTCHA Challenges: Use solving services and implement retry logic.
- Dynamic Content: Ensure headless browsers are configured to handle dynamic content and JavaScript.
- Rate Limits: Adjust scraping frequency and proxy usage to prevent rate limiting.
Conclusion
Bypassing anti-bot measures is a complex and evolving challenge that requires a combination of techniques and tools. This guide has outlined several methods for bypassing anti-bot measures using NodeJS, including optimizing request fingerprints, using rotating proxy pools, leveraging headless browsers, utilizing managed anti-bot bypasses, solving CAPTCHAs, scraping Google Cache, and reverse engineering anti-bot systems.
While each method has its advantages and limitations, a multi-faceted approach that combines several techniques is often the most effective strategy. By staying informed about the latest developments in anti-bot technologies and continually refining your approach, you can improve the success rate of your web scraping efforts.
Remember to always use these techniques responsibly and in accordance with legal and ethical standards. Bypassing anti-bot measures should be done with respect to the target website's terms of service and with a clear understanding of the potential consequences.
For further reading and advanced techniques, consider exploring the following resources:
- Puppeteer Documentation: https://pptr.dev/
- Axios Documentation: https://axios-http.com/
- 2Captcha API: https://2captcha.com/
- ScrapeOps Proxy Aggregator: https://scrapeops.io/
More NodeJS Web Scraping Guides
For more Node.JS resources, feel free to check out the NodeJS Web Scraping Playbook or some of our in-depth guides: