Best NodeJS Stealth & Bypassing Solutions
Modern websites use sophisticated protective mechanisms to prevent automated access, making it essential to understand and utilize stealth techniques for effective web scraping.
This article will explore various strategies that can be used to bypass such defenses using NodeJS. Strategies will include proxy rotation, CAPTCHA-solving services, and headless browsers, with practical code examples to get you started.
- TLDR: Stealth & Bypassing Solutions
- Understanding Anti-Scraping Mechanisms
- How To Bypass Anti-Bots With NodeJs
- Method #1: Optimize Request Fingerprints
- Method #2: Use Rotating Proxy Pools
- Method #3: Use Fortified Headless Browsers
- Method #4: Use Managed Anti-Bot Bypasses
- Method #5: Solving CAPTCHAs
- Method #6: Scrape Google Cache Version
- Method #7: Reverse Engineer Anti-Bot
- Case Study - Scrape Petsathome.com
- Conclusion
- More Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: Stealth & Bypassing Solutions
For those in a rush, here's a quick solution to bypass basic anti-scraping mechanisms:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com');
// Additional stealth options and scraping code...
await browser.close();
})();
This code uses puppeteer-extra with the stealth plugin to mimic human-like behavior and bypass basic anti-bot measures.
It launches a new browser instance and opens the example page, bypassing certain prevention mechanisms.
Understanding Anti-Scraping Mechanisms
Websites employ various techniques to detect and block automated access, such as:
- Rate Limiting: Restricts the number of requests per time frame.
- IP Blocking: Blocks IP addresses with suspicious behavior.
- User-Agent Detection: Identifies requests from known bots based on user-agent strings.
- JavaScript Challenges: Requires execution of JavaScript to access content.
- Session-Based Tracking: Uses cookies and session identifiers to track users.
Such techniques are critical to understand because they serve as a protective barrier for accessing the resources of a website. Understanding how these mechanisms work can help create a better understanding of how certain problems can be mitigated.
Anti-Bot Measurement Systems
Advanced systems like PerimeterX, Datadome, and Cloudflare provide comprehensive bot detection and mitigation strategies. They analyze user behavior and other signals to differentiate between bot traffic and real humans.
CAPTCHA Challenges
CAPTCHAs require solving tasks that are easy for humans but difficult for bots. While effective, they can also inconvenience legitimate users. They can be bypassed by advanced bots or CAPTCHA-solving services.
Request Detection
IP blocking and user detection are among the most common strategies for dealing with anti-scraping systems and bots. Both mechanisms prevent unwanted access to website by analyzing the request traffic sent from a browser (or emulated browser) towards the server.
Stealth and Bypassing Solutions
Stealth solutions involve techniques to avoid detection, such as IP rotation, headless browsers, and human emulation. These methods are critical to ensure access to data without being blocked.
How To Bypass Anti-Bots With NodeJs
Bypassing anti-bot systems involves several strategies:
- Optimizing Request Fingerprints: Mimic typical user behavior by rotating headers and user-agent strings.
- Using Rotating Proxy Pools: Rotate IP addresses to avoid IP blocking.
- Fortified Headless Browsers: Use headless browsers with stealth capabilities to bypass JavaScript challenges.
- Managed Anti-Bot Bypasses: Use proxy providers with built-in anti-bot bypass solutions.
- Solving CAPTCHAs: Utilize CAPTCHA-solving services to automate CAPTCHA challenges.
- Scrape Google Cache Version: Use cached versions of pages to bypass direct scraping defenses.
- Reverse Engineer Anti-Bot: Analyze and adapt to specific anti-bot systems to find weaknesses.
Method #1: Optimize Request Fingerprints
Challenge
Websites analyze HTTP headers and user-agent strings to detect bot traffic. These headers can reveal a lot about the requester, such as the type of device, operating system, and even the browser version.
By examining these details, websites can determine if a request is likely to come from a human user or a bot. If a site notices a pattern or an anomaly, such as too many requests from a single user-agent, it can block or restrict its access.
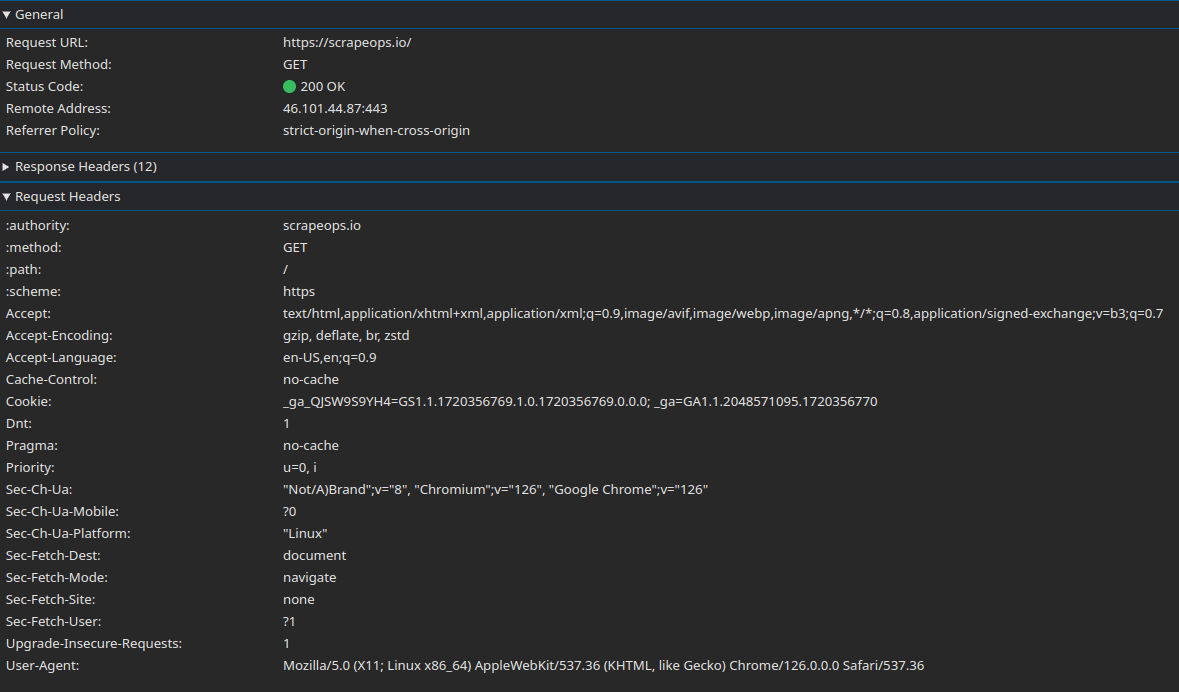
Network Tab Example
Below is a Google Chrome networking tab of Request Headers while accessing https://scrapeops.io. As you can see, there is a large number of headers being sent to the server. Each of these headers can be use to assess whether the request is coming from a human or a bot.
Solution: Header Optimization
To avoid detection, one effective strategy is to rotate your HTTP headers and user-agent strings. This means changing the headers with each request to make it look like requests are coming from different browsers, devices, and users.
This can help mimic typical user behavior and reduce the risk of getting blocked.
By using a variety of user-agent strings and customizing other headers, you make it harder for websites to identify and block your bot. Here’s a simple example using Node.js and the axios library:
Code Example:
const axios = require('axios');
const headers = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
];
const randomUserAgent = headers[Math.floor(Math.random() * headers.length)];
axios.get('https://example.com', { headers: { 'User-Agent': randomUserAgent } })
.then(response => console.log(response.data))
.catch(error => console.error(error));
In this script, we have a list of user-agent strings that we randomly select from for each request. By rotating these user-agent strings, we reduce the chance of our requests being flagged as suspicious.
This approach is useful for avoiding common blocks like 403 Forbidden (access denied) and 429 Too Many Requests (rate limiting). Note that this example is only a proof of concept and more than two headers are required for real-world applications.
Use Cases: This method is particularly effective when dealing with sites that use user-agent detection as part of their bot prevention strategy. It's a simple yet powerful technique to help maintain access to the site without being detected.
Method #2: Use Rotating Proxy Pools
Challenge
Websites block IP addresses that exhibit suspicious behavior or high request rates. When multiple requests come from the same IP address in a short period, it raises red flags. This often results in IP blocks, which can severely hinder your scraping efforts.
Solution: IP Rotation Using Proxy
IP rotation involves using multiple IP addresses to distribute requests, making it appear as though they are coming from different users around the world. By doing this, you can avoid detection and blocks that target specific IP addresses.
Code Example Using ScrapeOps API:
const playwright = require("playwright");
const cheerio = require("cheerio");
// ScrapeOps proxy configuration
PROXY_USERNAME = "scrapeops.headless_browser_mode=true";
PROXY_PASSWORD = "SCRAPE_OPS_API_KEY";
PROXY_SERVER = "proxy.scrapeops.io";
PROXY_SERVER_PORT = "5353";
(async () => {
const browser = await playwright.chromium.launch({
headless: true,
proxy: {
server: `http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`,
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
},
});
const context = await browser.newContext({ ignoreHTTPSErrors: true });
const page = await context.newPage();
try {
await page.goto("https://www.example.com", { timeout: 180000 });
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
let $ = cheerio.load(bodyHTML);
// do additional scraping logic...
} catch (err) {
console.log(err);
}
await browser.close();
})();
Explanation: This script configures axios to use the ScrapeOps proxy server for requests. By rotating through a pool of proxies, you can distribute your requests across multiple IP addresses, reducing the risk of being blocked. The proxy details (username, password, host, and port) are configured to authenticate and route your request through a different IP.
Importance of Paid Proxies: While free or public proxies may be tempting, they often come with significant drawbacks such as slow speeds, unreliability, and high chances of being blacklisted. Paid proxy services offer better performance, reliability, and are less likely to be blocked, making them a better choice for serious web scraping operations.
Use Cases: This technique is essential for bypassing IP-based blocks and handling JavaScript challenges. By rotating IP addresses, you can keep scraping without getting flagged for suspicious activity.
Method #3: Use Fortified Headless Browsers
Websites use JavaScript challenges to detect bots, requiring user interaction or script execution. These challenges can include tasks like clicking buttons, filling forms, or running specific JavaScript code that only real browsers can handle.
Solution: Dynamic Rendering Using Headless Browser
A headless browser is a web browser without a graphical user interface (GUI). It allows you to interact with web pages programmatically, just like a regular browser, but without the overhead of rendering the UI. This makes it perfect for automated tasks such as web scraping, especially when dealing with dynamic content.
Code Example Using Puppeteer Stealth:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
// Default Chrome location on Linux. Change as needed.
const executablePath = '/usr/bin/google-chrome';
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://example.com');
// Additional scraping logic here ...
await browser.close();
})();
Explanation: This script uses Puppeteer, a popular Node.js library for controlling headless Chrome or Chromium, with the Stealth plugin. The Stealth plugin helps bypass detection by mimicking real user interactions and behaviors. This makes it harder for websites to identify and block bots. You can add more scraping logic after navigating to the desired page, such as interacting with elements, extracting data, etc.
Fortified Browsers: Options include Puppeteer Stealth, Puppeteer Real Browser, and Playwright Stealth. These tools provide advanced features for bypassing detection mechanisms and handling complex web pages.
Use Cases: This method is ideal for bypassing sophisticated anti-bot systems like Cloudflare, DataDome, and others that rely heavily on JavaScript-based detection techniques. Using a fortified headless browser, you can interact with the page just like a real user, making it nearly impossible for anti-bot systems to differentiate between your bot and a human user.
Method #4: Use Managed Anti-Bot Bypasses
Challenge
Advanced anti-bot systems require highly fortified browsers, residential proxies, and optimized headers/cookies. These sophisticated systems can still detect and block many traditional scraping methods, making it difficult to bypass them without extensive effort and resources.
Solution: Use Proxy Providers with Managed Anti-Bot Bypasses
Instead of building your own anti-bot bypass solutions, you can leverage proxy providers that offer managed anti-bot bypasses. These services are specifically designed to handle the complexities of modern anti-bot systems, providing you with a simpler and more effective way to scrape data.
Proxy Providers and Their Solutions:
| Proxy Provider | Anti-Bot Solution | Pricing Method |
|---|---|---|
| ScrapeOps | Anti-Bot Bypasses | Pay per successful request |
| BrightData | Web Unlocker | Pay per successful request |
| Oxylabs | Web Unblocker | Pay per GB |
| Smartproxy | Site Unblocker | Pay per GB |
| Zyte | Zyte API | Pay per successful request |
| ScraperAPI | Ultra Premium | Pay per successful request |
| ScrapingBee | Stealth Proxy | Pay per successful request |
| Scrapfly | Anti-Scraping Protection | Pay per successful request |
Cost: These solutions can be expensive, ranging from $1,000 to $5,000 per one million pages per month. However, the cost can be justified by the reliability and effectiveness they offer, especially for large-scale scraping operations.
ScrapeOps Proxy Aggregator aggregates these solutions to find the best and cheapest option for your use case. This service can help you optimize costs while ensuring high success rates.
For example, you can activate the Cloudflare Bypass by simply adding bypass=cloudflare_level_1 to the API request, and the ScrapeOps proxy will use the best and cheapest Cloudflare bypass available for your target domain.
Code Example:
Here we are using axios and ScrapeOps in sync to bypass Cloudflare. Simply add your API key and the URL to scrape and pass this to axios. ScrapeOps will take care of the rest, giving you a smooth website access.
const axios = require('axios');
const apiKey = 'YOUR_API_KEY';
const urlToScrape = 'http://example.com/';
const scrapeOpsUrl = `https://proxy.scrapeops.io/v1/?api_key=${apiKey}&url=${encodeURIComponent(urlToScrape)}&bypass=cloudflare_level_1`;
axios.get(scrapeOpsUrl)
.then(response => {
console.log('Response:', response.data);
})
.catch(error => {
console.error('Error:', error);
});
Available Bypasses:
Here is a list of available bypasses:
| Bypass | Description |
|---|---|
cloudflare_level_1 | Use to bypass Cloudflare protected sites with low security settings. |
cloudflare_level_2 | Use to bypass Cloudflare protected sites with medium security settings. |
cloudflare_level_3 | Use to bypass Cloudflare protected sites with high security settings. |
incapsula | Use to bypass Incapsula protected sites. |
perimeterx | Use to bypass PerimeterX protected sites. |
datadome | Use to bypass DataDome protected sites. |
Method #5: Solving CAPTCHAs
Challenge
CAPTCHA challenges present images, text, or puzzles that are difficult for bots to solve. These challenges are designed to be easy for humans but tricky for automated systems, effectively blocking many bots from accessing content.
Solution: Utilize CAPTCHA-Solving Services
Integrating with services like 2Captcha and Anti-Captcha allows you to programmatically solve CAPTCHA challenges. These services employ human workers or advanced algorithms to solve CAPTCHAs and return the solution to your bot, allowing it to continue scraping without interruption.
Code Example Using 2Captcha:
const Captcha = require("2captcha");
const solver = new Captcha.Solver("TWO_CAPTCHA_API_KEY");
solver
.recaptcha("RECAPTCHA_ID", "RECAPTCHA_URL")
.then((res) => {
console.log("reCAPTCHA passed successfully.");
})
.catch((err) => {
console.error(err.message);
});
Explanation: By utilizing service 2captcha, and by passing the CAPTCHA ID and the url appropriately, the service is able to effectively resolve any presented CAPTCHA challenge.
Use Cases: This method is effective for automating the process of solving CAPTCHAs, ensuring that your scraping operations remain uninterrupted. It's particularly useful for websites that frequently use CAPTCHA challenges to deter bots.
Method #6: Scrape Google Cache Version
Challenge
Using Google's cached version of a webpage can bypass direct scraping defenses. When Google crawls and indexes a page, it creates a cached version that is accessible through a special URL. Scraping this cached version can help you avoid many of the direct anti-bot measures implemented on the original site.
Advantages and Disadvantages
Advantages:
- Bypasses direct anti-bot measures: Google is often allowed to crawl sites that block other scrapers.
- Accessible via Google's cache URL: The cache is usually easier to scrape because it lacks real-time defenses of the live site.
Disadvantages:
- Cached version may not be up-to-date: The frequency of Google’s cache updates varies, and it may not reflect the most recent changes on the original site.
- Limited to pages cached by Google: Not all pages are cached by Google. Some websites (like LinkedIn) prevent Google from caching their content or have low crawl frequencies, making this method ineffective for those sites.
Solution: Scrape the Google Cache
Depending on how fresh your data needs to be, scraping the Google Cache can be a viable alternative to directly scraping a website. This method is particularly useful when the target site employs stringent anti-bot measures like Cloudflare protection.
To scrape the Google cache, you simply prepend https://webcache.googleusercontent.com/search?q=cache: to the URL you wish to scrape.
Code Example:
const axios = require('axios');
const urlToScrape = 'https://www.example.com/';
const cachedUrl = `http://webcache.googleusercontent.com/search?q=cache:${urlToScrape}`;
axios.get(cachedUrl)
.then(response => console.log(response.data))
.catch(error => console.error(error));
Explanation: This script fetches the cached version of a webpage from Google's servers. By accessing the cached page, you can avoid the anti-bot measures on the original site. This method relies on Google’s frequent crawls to ensure that the cached data is relatively up-to-date.
Use Cases: This method is useful for bypassing sites with strict anti-bot measures, especially when the freshness of the data is not critical. It's a simple and effective way to access content without triggering anti-bot defenses.
Practical Considerations
When using this method, it's essential to keep in mind a few practical considerations:
- Data Freshness: Assess how often the content on the target site changes and how frequently Google caches it. If the data is highly dynamic, this method might not be suitable.
- Cache Availability: Verify if the page is cached by Google before relying on this method. Some pages might not be cached due to the website's settings or Google’s crawl schedule.
By leveraging Google's cache, you can streamline your scraping efforts and reduce the complexity involved in bypassing sophisticated anti-bot systems. However, it's crucial to balance the need for data freshness with the convenience and ease of scraping cached versions.
Method #7: Reverse Engineer Anti-Bot
This method involves deeply understanding and bypassing the anti-bot mechanisms directly at a low level. By reverse engineering the anti-bot system, you can develop a custom solution that efficiently bypasses the defenses without needing a full headless browser instance. The developer can dissect the anti-bot systems designed to identify and block automated requests, and then craft a bypass that circumvents these defenses without the need for heavy browser resources.
Advantages:
- Resource Efficiency: Unlike using multiple headless browser instances, a custom bypass can be tailored to minimize resource usage, making it cost-effective for large-scale scraping operations.
- Customization: By understanding and manipulating the inner workings of anti-bot systems, developers gain precise control over how requests are perceived, enhancing bypass success rates.
- Long-term Viability: Once developed, a well-maintained custom bypass can adapt to updates in anti-bot technologies, providing consistent access to target websites.
Disadvantages:
- Technical Complexity: Reverse engineering requires in-depth knowledge of network protocols, JavaScript obfuscation, and browser behavior, which can be daunting and time-consuming.
- Maintenance: As anti-bot systems evolve, maintaining the bypass to keep pace with updates and new challenges becomes an ongoing commitment.
- Legal and Ethical Considerations: Developing custom bypass solutions may potentially violate terms of service agreements of targeted websites, warranting careful consideration of legal implications.
Suitability:
This method is ideal for:
- Developers with a keen interest in cybersecurity and reverse engineering challenges.
- Enterprises or proxy services operating at massive scale where efficiency and cost-effectiveness are paramount.
For most developers and smaller-scale operations, employing simpler bypass techniques is generally more practical and efficient.
Technical Overview:
To effectively bypass anti-bot protections, you must comprehend both server-side and client-side verification techniques employed by the target system.
Server-side Techniques:
- IP Reputation: Ensuring proxies have high reputation scores to evade IP-based blocks.
- HTTP Headers: Crafting headers that mimic legitimate browsers to bypass browser integrity checks.
- TLS & HTTP/2 Fingerprints: Manipulating client fingerprints to match legitimate browser profiles.
Client-side Techniques:
- Browser Web APIs: Emulating browser environments to bypass checks based on browser-specific APIs.
- Canvas Fingerprinting: Generating and matching device fingerprints to evade detection based on hardware configurations.
- Event Tracking: Simulating user interactions to appear as a legitimate user rather than an automated script.
- CAPTCHAs: Developing algorithms or utilizing human-based solving services to overcome interactive challenges.
Ethical Challenges
Reverse engineering of a service might be prohibited according to their Terms of Use and other legal documents. Always make sure to learn whether a platform or a service allows such use cases, and whether you're allowed to perform such exploits.
Conclusion and Side Note
Reverse engineering anti-bot protections offers a powerful alternative to conventional scraping methods, albeit with substantial technical challenges and ongoing maintenance requirements. It's a strategy best suited for those with the expertise and resources to navigate complex security measures effectively.
By deeply understanding and mimicking the behavior of a real browser, you can develop a robust system that bypasses anti-bot measures efficiently.
However, as this method is complex and requires a significant investment in both time and technical resources, it won’t be attempted here. The user is encouraged to research and explore such topics that go beyond this article.
For further exploration on this topic, consider diving into resources on network protocols, JavaScript deobfuscation, and browser fingerprinting techniques.
Case Study - Scrape Petsathome.com
In this chapter, we'll perform a case study of the above methods and techniques on an example website.
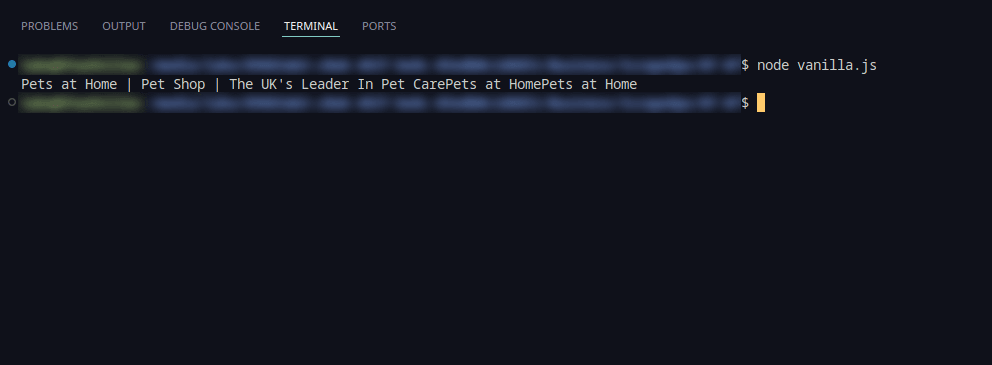
Attempt with Vanilla NodeJs Code
Attempting to scrape Petsathome.com using vanilla NodeJs code results in a regular page loading. There was no block while attempting to scrape the page using axios and cheerio. The code below outputs the title of the page:
const axios = require('axios');
const cheerio = require('cheerio');
const url = 'https://www.petsathome.com/';
axios.get(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
const pageTitle = $('title').text();
console.log(pageTitle);
})
.catch(error => {
console.error('Error fetching the webpage:', error);
});
The screenshot below displays the result:
Implementing Anti-Bot Bypass Methods
The following sections will implement the code provided in the previous chapters for the web page petsathome.com. Each section will contain the result of running the NodeJS code.
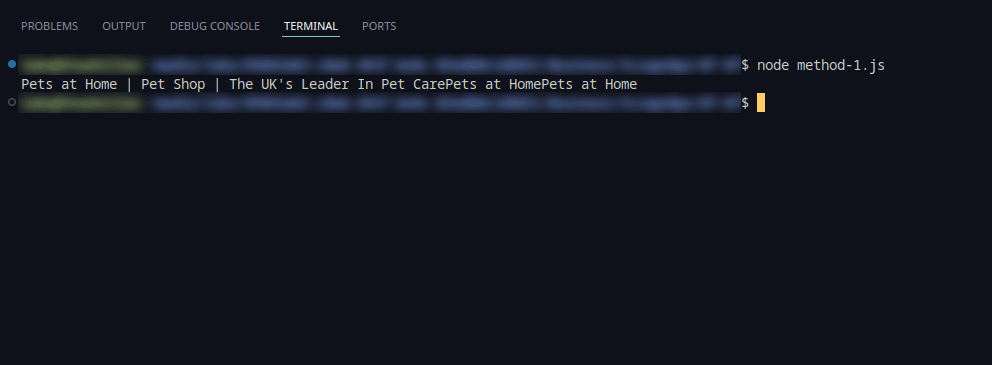
1. Optimize Request Fingerprints
Initially, optimizing request fingerprints involved modifying headers to mimic legitimate browser requests.
Here's the result:
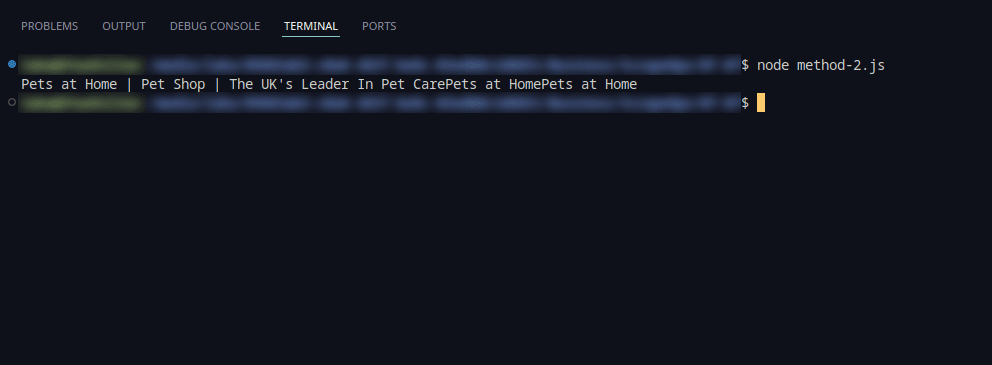
2. Use Rotating Proxy Pools
Incorporating rotating proxy pools significantly enhanced access by cycling through diverse IP addresses. This approach effectively reduced blocks and mitigated IP-based rate limiting.
Using ScrapeOps's proxy server allows to fetch the same result:
3. Use Fortified Headless Browsers
Deploying headless browsers, configured to emulate human-like behavior, proved highly effective. By rendering JavaScript and handling dynamic content, this method successfully bypassed Cloudflare's initial challenges.
Using Puppeteer Stealth results in the same title output:
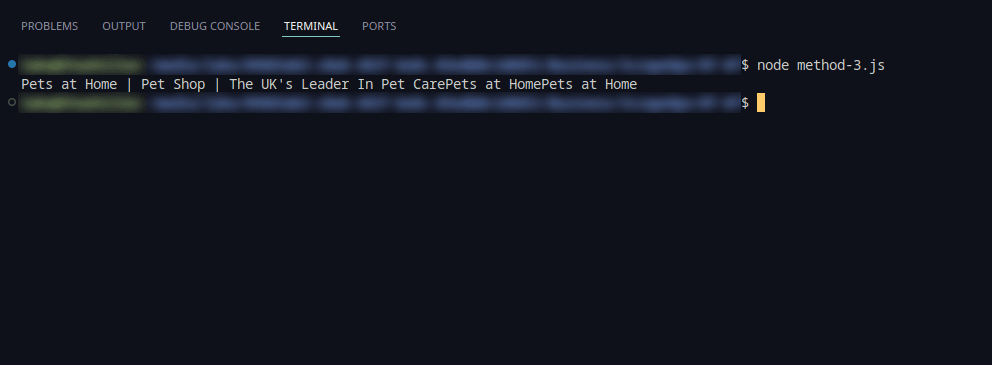
4. Use Managed Anti-Bot Bypasses
Utilizing managed anti-bot bypass services provided consistent access with minimal configuration. These services dynamically adjusted strategies based on site responses, ensuring reliable scraping operations.
This solution works great as well, providing requested website results while bypassing any potential Cloudflare blocks. The screenshot below displays the result:
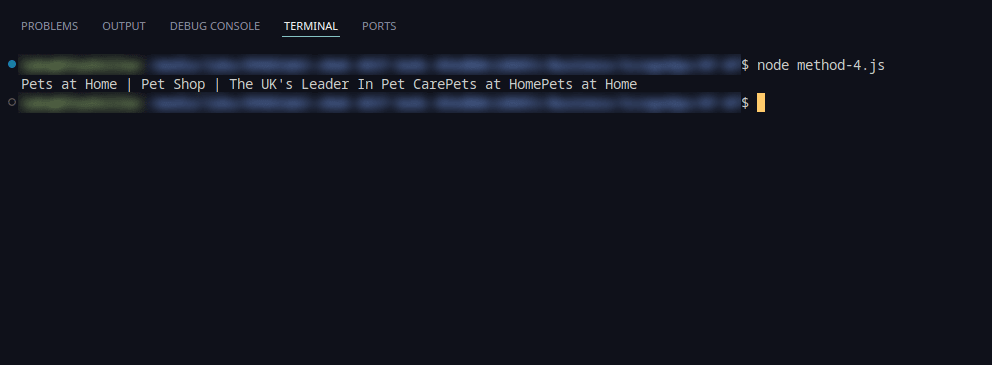
5. Solving CAPTCHAs
Integrating a CAPTCHA solving service helps immensely with the scraping process by allowing easy access to the blocked contents.
Although the https://www.petsathome.com/ website contains no CAPTCHA, we were able to utilize an example from the previous chapters and resolve an existing reCAPTCHA challenge on a different page, which proves this method to be a successful one.
6. Scrape Google Cache Version
Accessing the Google Cache version provided a reliable fallback for static content retrieval. This method circumvented dynamic content challenges and maintained access to historical data snapshots.
Running the Google Cache resulted in the following error:
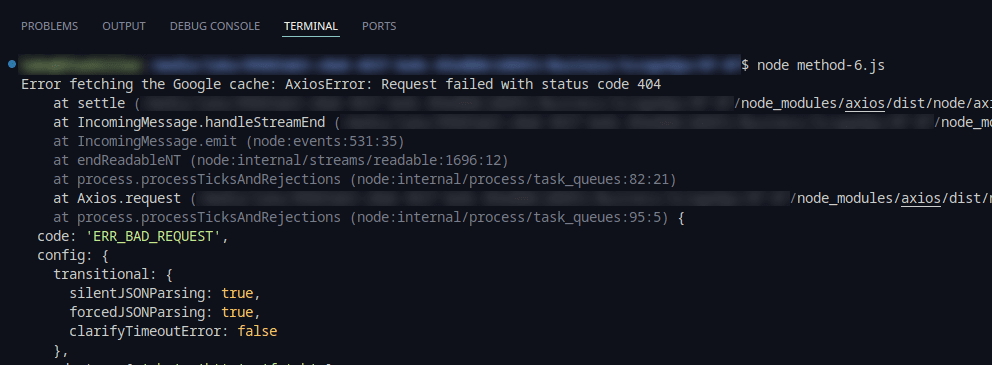
For this particular example, the Google Cache contained no result so we weren't able to utilize this method.
7. Reverse Engineer Anti-Bot
Exploring reverse engineering techniques proves complex yet rewarding. As we didn't implement this solution, it will be left out of the subsequent table.
Comparison of Tactics
| Method | Efficiency | Use Case | Success |
|---|---|---|---|
| Optimize Request Fingerprints | Moderate | Initial evasion, limited dynamic content | Successful |
| Use Rotating Proxy Pools | High | IP rotation, bypassing rate limits | Successful |
| Use Fortified Headless Browsers | High | Handling JavaScript, dynamic content | Successful |
| Use Managed Anti-Bot Bypasses | Moderate | Consistent access, minimal setup required | Successful |
| Solving CAPTCHAs | High | Automating CAPTCHA resolution | Successful |
| Scrape Google Cache Version | Low | Static content retrieval, historical data | Unsuccessful |
Conclusion
Throughout this guide, we explored various techniques to bypass anti-scraping mechanisms, ranging from optimizing request fingerprints and using rotating proxy pools to employing fortified headless browsers and managed anti-bot bypasses. Each method addresses different challenges posed by websites employing anti-bot measures, showcasing the diversity of approaches available to scrape data effectively.
These techniques are invaluable for data extraction tasks across industries such as e-commerce, market research, and competitive analysis. By implementing these strategies, businesses can automate data collection processes, gain competitive insights, and enhance decision-making capabilities.
Further Reading is available on the following links:
More Web Scraping Guides
For more Node.JS resources, feel free to check out the NodeJS Web Scraping Playbook or some of our in-depth guides: