Setting Up ScrapeOps n8n Node
This guide will walk you through installing and configuring the ScrapeOps node in your n8n instance.
Prerequisites
Before you begin, ensure you have:
- n8n installed and running (self-hosted or cloud)
- Admin/Owner access to install community nodes
- A ScrapeOps account (free tier available)
Enabling Community Nodes
To enable community plugins, go to your n8n Instance Settings.
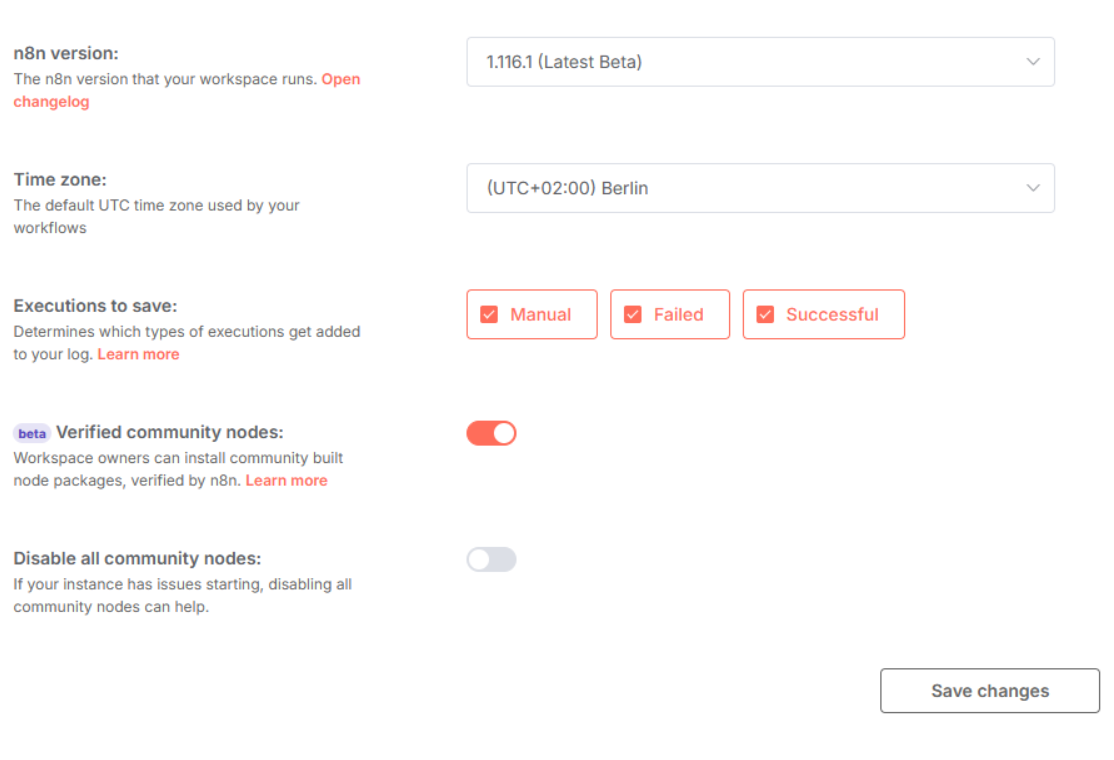
If you encounter the error message while installing the ScrapeOps n8n node: "Please contact an administrator to install this community node": this step is especially important if you're using a team account.
Currently, only the Owner of an n8n instance can enable and install community nodes, not Admins. Ask the n8n instance owner to enable community nodes and install the ScrapeOps node in their workflow. Once they do, the node will become available for everyone on the team account.
However, if you are the sole owner of the n8n instance (without a team setup), you can simply install the node directly from the Nodes Panel.
Installation
Method 1: Install via n8n Cloud UI (Recommended)
If you're using n8n Cloud, you can easily install the ScrapeOps node directly from the UI:
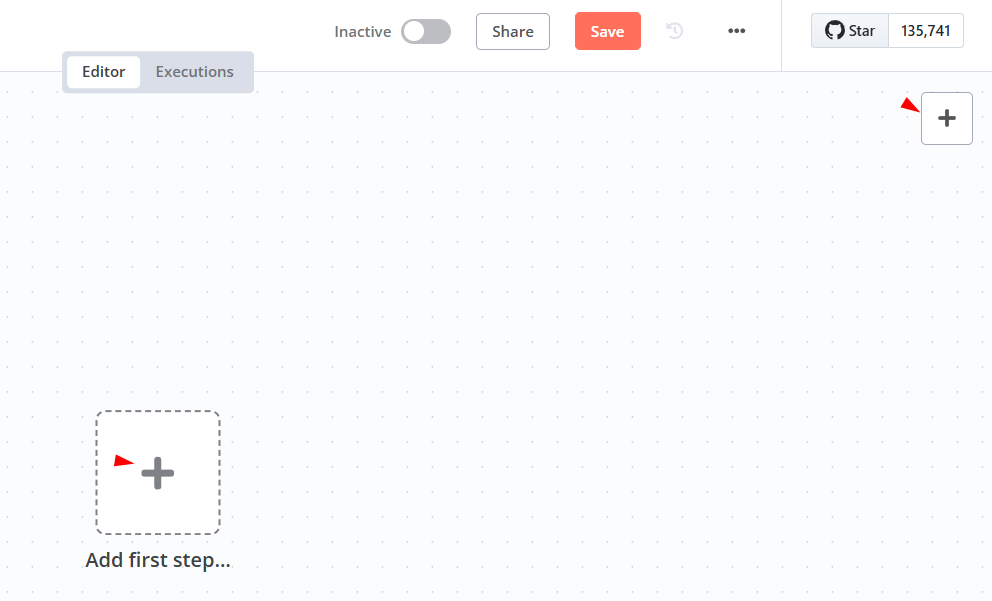
Step 1: Install the Node
- Sign in to n8n, open the editor, and click + in the top right to open the Nodes panel
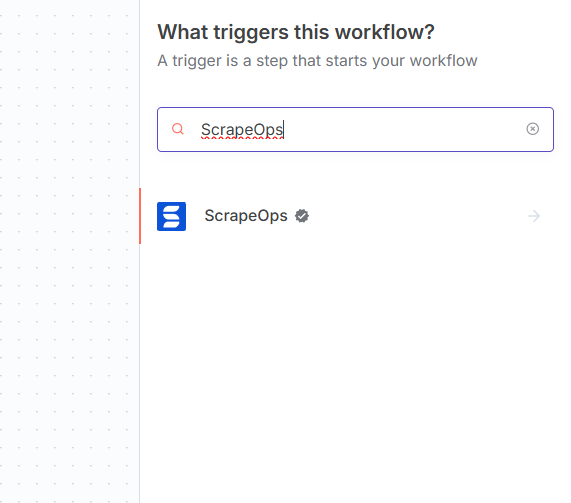
- Search for ScrapeOps node using the search bar. Look for the version marked by a badge ☑. Then, select install.
- The ScrapeOps node will be installed and appear in your node palette automatically.
If you are not on an updated n8n instance:
Follow n8n's community nodes guide:
npm install @scrapeops/n8n-nodes-scrapeops
Restart your n8n instance after installation. The "ScrapeOps" node will appear in your node palette.
Method 2: Install via n8n Settings (Self-Hosted)
For self-hosted n8n instances:
- Open your n8n instance
- Navigate to Settings → Community Nodes
- Click Install a community node
- Enter the package name:
@scrapeops/n8n-nodes-scrapeops - Click Install
- Restart your n8n instance when prompted
Method 3: Manual Installation (Self-Hosted)
If you're self-hosting n8n, you can install the node via command line:
# Navigate to your n8n installation directory
cd ~/.n8n
# Install the ScrapeOps node
npm install @scrapeops/n8n-nodes-scrapeops
# Restart n8n
n8n start
Method 4: Docker Installation
For Docker users, add the node to your docker-compose.yml:
version: '3.8'
services:
n8n:
image: n8nio/n8n
environment:
- N8N_COMMUNITY_NODES_ENABLED=true
- NODE_FUNCTION_ALLOW_EXTERNAL=n8n-nodes-scrapeops
volumes:
- ~/.n8n:/home/node/.n8n
Then install the node:
docker exec -it <container_name> npm install @scrapeops/n8n-nodes-scrapeops
docker restart <container_name>
Step 2: Set Up Credentials
Getting Your ScrapeOps API Key
To use the ScrapeOps node, you'll need a ScrapeOps API key which you can get by signing up for a free account here.
Your API key must be included with every request using the api_key parameter, otherwise the API will return a 403 Forbidden Access status code.
Steps to get your API key:
- Sign up for a free account at ScrapeOps
- Verify your email address (required to activate your API key)
- Visit your dashboard at ScrapeOps Dashboard
- Copy your API key from the dashboard

Important: You must confirm your email address to activate your API key. Check your inbox for a verification email from ScrapeOps.
Free Tier Limits
The free tier includes:
- Proxy API: 1,000 requests/month
- Parser API: 500 parses/month
- Data API: 100 requests/month
You can monitor your usage in the ScrapeOps Dashboard.
Configure Credentials in n8n
- In n8n, go to Credentials → Add Credential.
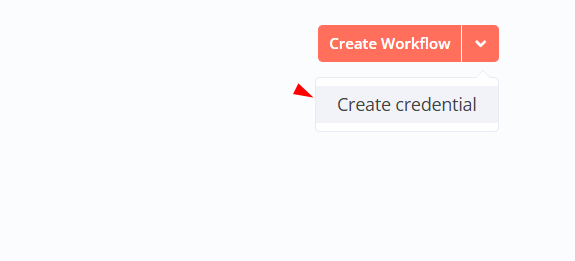
- Search for "ScrapeOps API" and enter your API key.
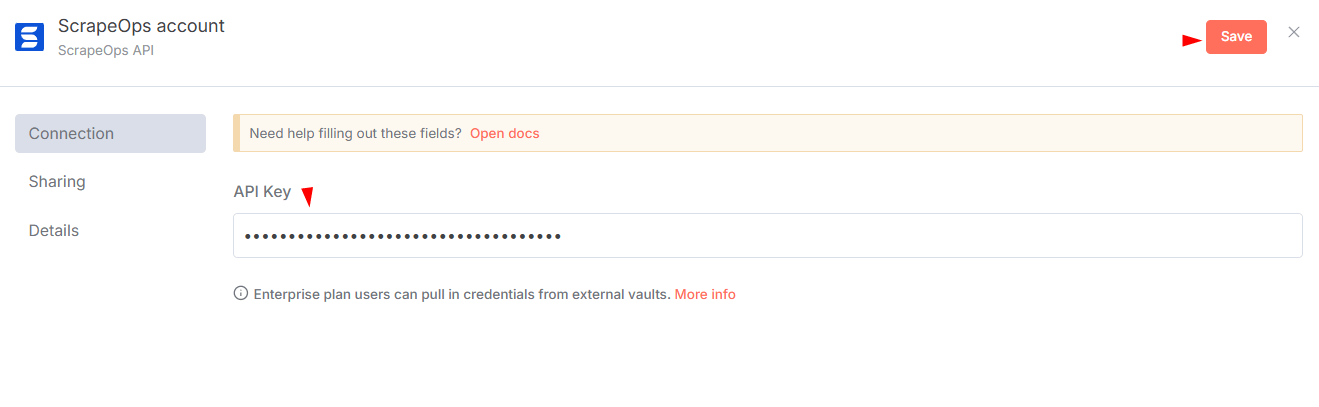
- Save and test the credentials.
Note: Make sure to confirm your email to activate the API key.
Step 3: Add the Node to a Workflow
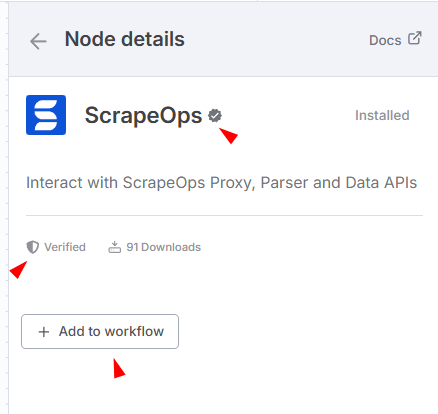
- Create a new workflow in n8n.
- Click Add to Workflow "ScrapeOps" node from the palette.
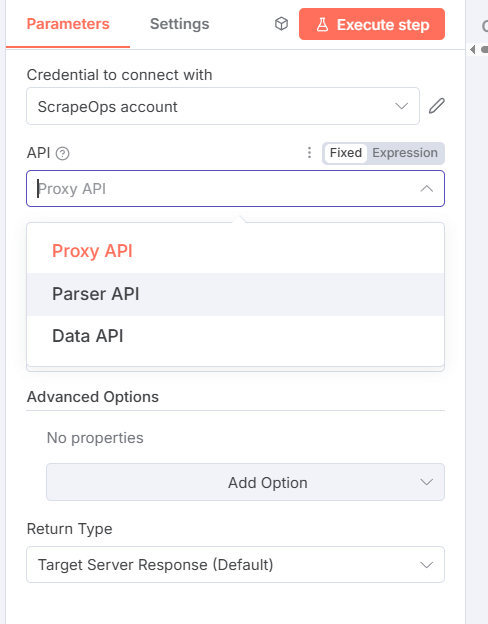
- Select an API (Proxy, Parser, or Data) and configure parameters.
How to Use the ScrapeOps Node
The node supports three APIs, each with tailored parameters. Outputs are JSON for easy chaining into other nodes.
Core Parameters
- API: Choose Proxy API, Parser API, or Data API (required)
- All APIs require ScrapeOps credentials
Proxy API Features and Fields
Route GET/POST requests through proxies to scrape blocked sites.
Basic Parameters:
- URL: Target URL to scrape (required)
- Method: GET or POST (default: GET)
- Return Type: Default (raw response) or JSON
Advanced Options (Collection):
| Option | Type | Description | Default | Example Values |
|---|---|---|---|---|
| Follow Redirects | Boolean | Follow HTTP redirects | true | true, false |
| Keep Headers | Boolean | Use your custom headers | false | true, false |
| Initial Status Code | Boolean | Return initial status code | false | true, false |
| Final Status Code | Boolean | Return final status code | false | true, false |
| Optimize Request | Boolean | Auto-optimize settings | false | true, false |
| Max Request Cost | Number | Max credits to use (with optimize) | 0 | 10, 50, 100 |
| Render JavaScript | Boolean | Enable headless browser | false | true, false |
| Wait Time | Number | Wait before capture (ms) | 0 | 3000, 5000 |
| Wait For | String | CSS selector to wait for | - | .product-title, #content |
| Scroll | Number | Scroll pixels before capture | 0 | 1000, 2000 |
| Screenshot | Boolean | Return base64 screenshot | false | true, false |
| Device Type | String | Device emulation | desktop | desktop, mobile |
| Premium Proxies | String | Premium level | level_1 | level_1, level_2 |
| Residential Proxies | Boolean | Use residential IPs | false | true, false |
| Mobile Proxies | Boolean | Use mobile IPs | false | true, false |
| Session Number | Number | Sticky session ID | 0 | 12345, 67890 |
| Country | String | Geo-targeting country | - | us, gb, de, fr, ca, au, jp, in |
| Bypass | String | Anti-bot bypass level | - | cloudflare_level_1, cloudflare_level_2, cloudflare_level_3, datadome, perimeterx, incapsula, generic_level_1 to generic_level_4 |
Full Documentation: Proxy API Aggregator
Important Points:
- For POST, input data comes from upstream nodes
- Optimize Request: Let ScrapeOps auto-tune for cost/success
- Error Handling: Node includes suggestions for common issues like blocks
Parser API Features and Fields
Parse HTML into structured JSON for supported domains.
Parameters:
- Domain: Amazon, eBay, Walmart, Indeed, Redfin
- Page Type: Varies by domain (e.g., Product, Search for Amazon)
- URL: Page URL (required)
- HTML Content: Raw HTML to parse (required)
Full Documentation: Parser API
Important Points:
- Outputs structured data like products, reviews, or jobs
- No custom rules needed - uses ScrapeOps' pre-built parsers
- Combine with Proxy API for fetching + parsing in one flow
Data API Features and Fields
Access pre-scraped datasets, focused on Amazon.
Parameters:
- Domain: Amazon (more coming soon)
- Amazon API Type: Product or Search
- Input Type: ASIN/URL for Product; Query/URL for Search
Amazon API Options:
- Country: e.g., US, UK
- TLD: e.g., .com, .co.uk
Full Documentation: Data APIs
Important Points:
- Returns JSON datasets without scraping yourself
- Ideal for quick queries or large-scale data pulls
Output Handling: All APIs return JSON. Use n8n's Set or Function nodes to transform data.
Verifying Installation
To verify everything is working correctly:
- Create a new workflow and add a ScrapeOps node
- Configure it with a simple test:
- API Type: Proxy API
- URL:
http://httpbin.org/ip - Method: GET
- Execute the node - you should see your proxy IP in the response
Monitoring Usage
- Check your usage in the ScrapeOps Dashboard
- Set up usage alerts to avoid exceeding limits
- Usage resets monthly
Common Setup Issues
Node Not Appearing
Problem: ScrapeOps node doesn't show up after installation
Solution:
- Ensure n8n was restarted after installation
- Check that community nodes are enabled
- Verify the installation with:
npm list @scrapeops/n8n-nodes-scrapeops
"Please contact an administrator" Error
Problem: Error message "Please contact an administrator to install this community node"
Solution:
- For team accounts: Only the n8n instance Owner can enable and install community nodes, not Admins
- Ask the n8n instance owner to:
- Go to n8n Instance Settings
- Enable community nodes
- Install the ScrapeOps node
- Once installed by the owner, the node becomes available for all team members
- For sole owners: You can install directly from the Nodes Panel after enabling community nodes
Authentication Failures
Problem: "Invalid API Key" error
Solution:
- Verify API key is copied correctly (no extra spaces)
- Check if API key is active in ScrapeOps dashboard
- Ensure you're using the correct credential in the node
Connection Timeouts
Problem: Requests timing out
Solution:
- Check your firewall settings
- Verify n8n can make external HTTP requests
- Test with a simple URL first (like httpbin.org)
Next Steps
Now that you have ScrapeOps configured:
- Learn about the Proxy API for general web scraping
- Explore the Parser API for extracting structured data
- Discover the Data API for direct data access
- Check out practical examples to get started quickly
Getting Help
- n8n Community Forum: community.n8n.io
- ScrapeOps Support: support@scrapeops.io
- Documentation: ScrapeOps Docs
Ready to start scraping? Continue to learn about the Proxy API!