
How web scraping got harder, even as proxies got cheaper…
Proxies have never been cheaper. Scraping has never been more expensive.
That's the Proxy Paradox, a quiet contradiction reshaping the economics of web scraping.
Over the past few years, the cost of proxies has fallen dramatically. Residential bandwidth that once cost $30 per GB can now be found for $1. Datacenter proxies are cheaper than coffee.
On paper, this should have ushered in a golden age for web scraping; faster, cheaper, easier access to public data.
But that's not what's happening.
At ScrapeOps, we see billions of requests every month across thousands of domains. And the trend is undeniable…
While proxies keep getting cheaper, the cost of successful scraping is exploding.
In today's scraping market, proxies have become a commodity.
But scraping success is now at a premium.
This is the paradox at the heart of modern web scraping.
And it's redefining how companies measure, optimize, and compete in the data economy.
In this article, we will walk through:
- The Illusion of Cheaper Proxies
- The Reality Check: Scraping Costs Are Rising
- The Hidden Forces Behind the Proxy Paradox
- Is the Proxy Paradox a Law?
- How the Proxy Paradox Is Reshaping the Proxy Market
- Enter Scraping Shock
- Efficiency as a Superpower
- Conclusion
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: The Proxy Paradox
Proxy prices have collapsed, 70–90% cheaper than just a few years ago.
Proxy platforms are smarter, faster, and more reliable than ever.
Yet the cost of successful scraping keeps rising.
That’s the Proxy Paradox.
Every leap forward in proxy accessibility triggers an equal counter-move from the web:
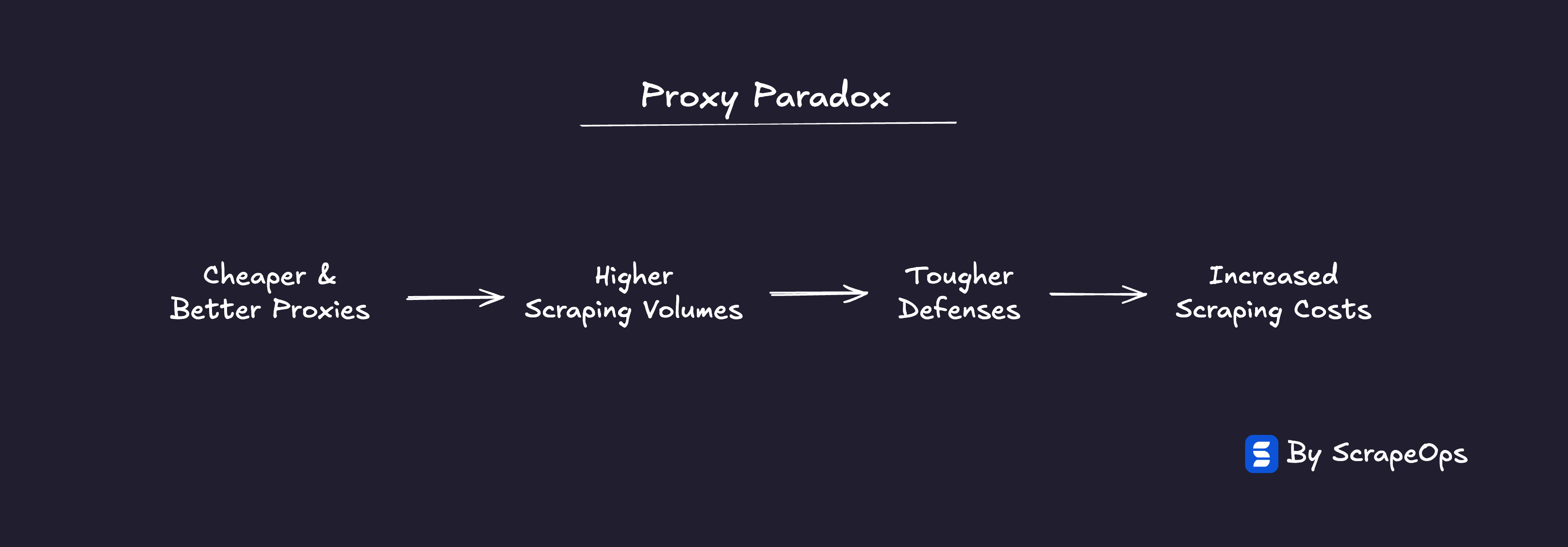
Cheaper & better proxies → more scraping → tougher defences → higher costs.
The result is a zero-sum system where everyone spends more just to stand still.
- ✅ Winners: proxy providers & anti-bot vendors who profit from the friction.
- ❌ Losers: scrapers & website owners who pay the price.
What used to be a technical problem is now an economic one.
Access isn’t the issue, affordability is.
For scraping teams, the new competitive edge isn’t scale or sophistication, it’s efficiency: cost per successful response.
The Proxy Paradox is how the web keeps its balance: cheaper access, costlier success, endless motion.
We're entering an era of web scraping where...
-
Proxy providers are splitting into low-margin resellers and outcome-driven platforms.
-
Scraping teams face "Scraping Shock," where access is easy but affordability vanishes. (Read more about Scraping Shock)
-
Efficiency, not scale, becomes the real competitive advantage.
The Illusion of Cheaper Proxies

Every technology follows a familiar curve.
In the early days, it’s expensive, niche, and unreliable. Then competition, scale, and innovation drive prices down and quality up.
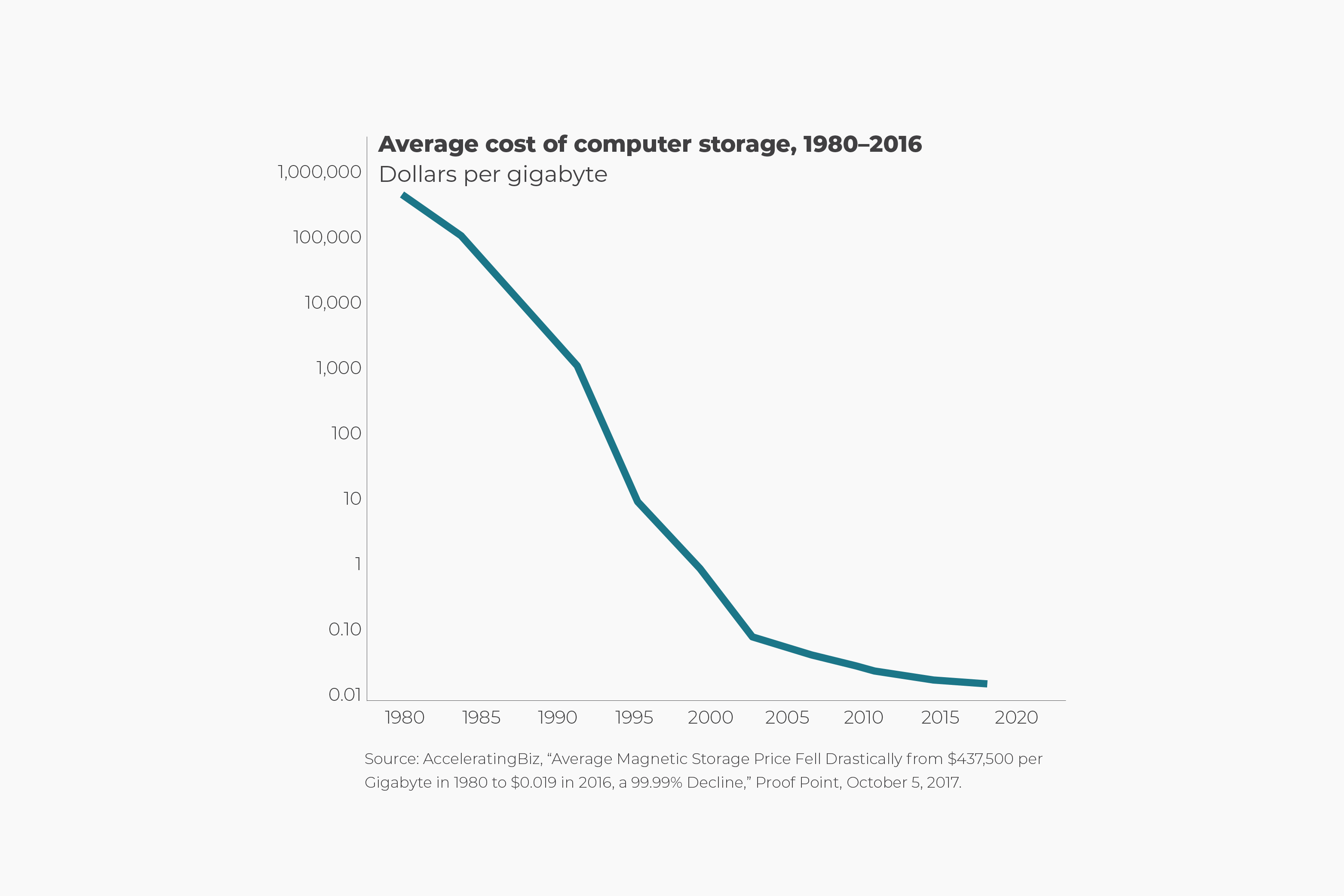
| Then | Now | |
|---|---|---|
| Storage | In the 1980s, a single gigabyte of hard drive storage cost over $400,000. | You can buy a 1TB SSD for under $50, a million-fold price drop with vastly better reliability and speed. |
| Compute | In the 1970s, supercomputers filled entire rooms and cost millions. | A $0.10/hour cloud instance can outperform them — and you can spin up thousands in seconds. |
| Solar Power | In 1976, solar energy cost $106 per watt. | It’s under $0.30 per watt and one of the cheapest energy sources on Earth. |
On paper, the proxy market looks like it is following a similar success story.
Prices are down across the board.
Over the last 5 years…
- Datacenter proxies (originally priced per IP) have dropped from $1.00-2.50 per IP, to $0.10-$0.50 per IP, and pay-per-GB plans give users even more flexibility and budget options.
- Residential proxy prices have dropped 60-75% over the last 5 years. With the big residential proxy providers cutting prices by 20-50% in the last year alone.
- Smart Proxy API providers have emerged, offering residential proxy success rates at a fraction of the cost.
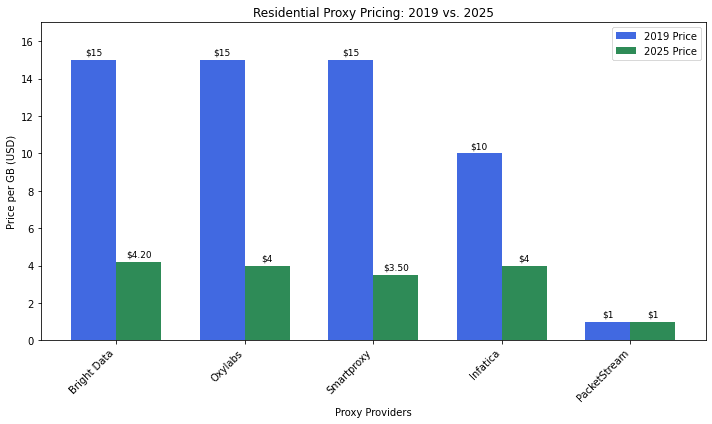
For anyone glancing at their proxy dashboard, it feels like progress.
Bigger pools. More stable systems. Lower bills.
But here’s the illusion: while proxy costs have plummeted, the real cost of a successful scrape has soared.
You might be spending half as much per GB, yet paying three times as much per usable response.
We’re paying less for bandwidth, but more for success.
The Reality Check: Scraping Costs Are Rising

If cheaper proxies really made scraping cheaper, total scraping costs should be falling.
They’re not.
Across the industry, and in ScrapeOps’ own data from billions of requests, the trend is unmistakable: proxy costs are dropping, but the cost per successful payload is climbing fast.
Five years ago, virtually all major websites could be scraped cheaply with datacenter proxies and normal HTTP requests.
Today, more and more websites are using sophisticated anti-bot countermeasures that require scrapers to use residential proxies, headless browsers and every more sophisticated session management systems to access the data they need.
| Industry | 5 Years Ago | Today |
|---|---|---|
| Ecommerce | 9 of top 10 e-commerce websites were scrapable with datacenter proxies and simple header rotation | Only 4 of top 10 remain scrapable with datacenter proxies. Most (walmart.com, googleshopping.com, and lazada.com), now require residential or headless browsers due to anti-bot protections. |
| Social Media | 4 of the top 10 social media websites (except linkedin.com) was scrapable with datacenter proxies and basic HTTP requests. | Facebook.com, instagram.com, twitter.com, linkedin.com, tiktok.com all now use anti-bot systems that prevent most scraping. |
| Real Estate | All of the top 10 real estate listing sites (zillow.com, realtor.com, and rightmove.co.uk) could be scraped with datacenter IPs and simple header rotation. | Only 3 real estate websites are easily scrapable without the use of residential proxies or browser fingerprints. |
This can be clearly seen in ScrapeOps’ own data.
When we look at what percentage of our request volume was able to be processed at the 1 API credit per request level (i.e. using datacenter proxies with no JS rendering).
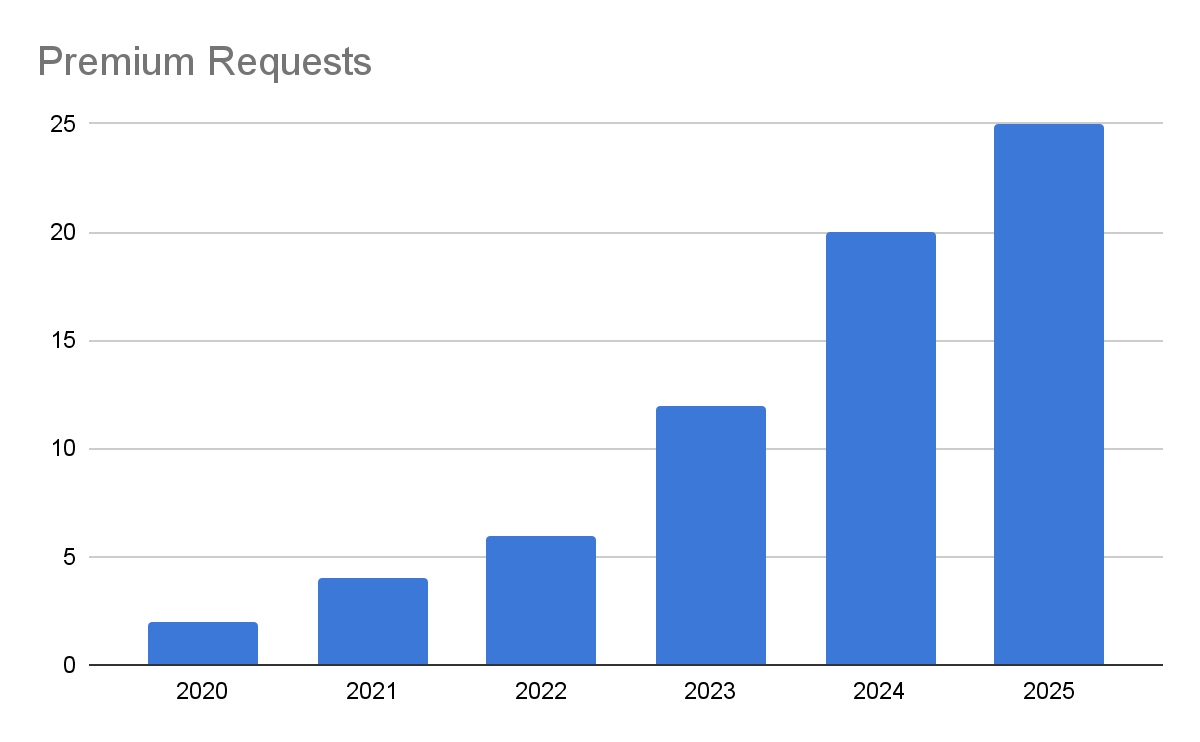
Whereas five years ago, it was rare for a user to have to use residential proxies or JS rendering to successfully scrape a website, typically < 2% of requests.
Today, nearly 25% of the billions of requests we process every month have to use some combination of residential proxies, JS rendering or anti-bot bypasses to retrieve a successful response.
The proxy line item may be shrinking, but everything wrapped around it: retries, CAPTCHAs, headless browsers, verification, post-processing, is inflating.
Proxy prices ↓ · Scraping costs ↑ · Success flat (maybe even down).
What used to be a $500 scraping budget that fetched 10 million records now only delivers a fraction of that, even with cheaper proxies.
This is scraping inflation in action: the rising cost of achieving real success, hidden behind falling infrastructure prices.
The illusion of progress breaks here.
The data proves the paradox, and if you’ve been in the scraping game for a while your own experience will likely confirm this too.
And the question now is, why?
The Hidden Forces Behind the Proxy Paradox

Scraping costs aren't rising by accident.
They’re rising because every improvement in proxy accessibility triggers a counter-reaction from the web itself.
This is a textbook Red Queen Effect, a system where both sides must run faster just to stay in place.
Named after the Red Queen in Alice in Wonderland, it describes systems that must keep evolving just to avoid falling behind.
Every adaptation triggers a counter-adaptation, locking both sides in perpetual motion.
In nature, it’s seen in the co-evolution of predators and prey, in technology, it shows up anywhere two forces are optimizing against each other, from algorithms to markets to security systems.
In biology, it explains why predators and prey evolve together.
In tech, it explains why spam filters, malware detectors, and ad blockers never "win."
Web scraping is caught in the same loop.
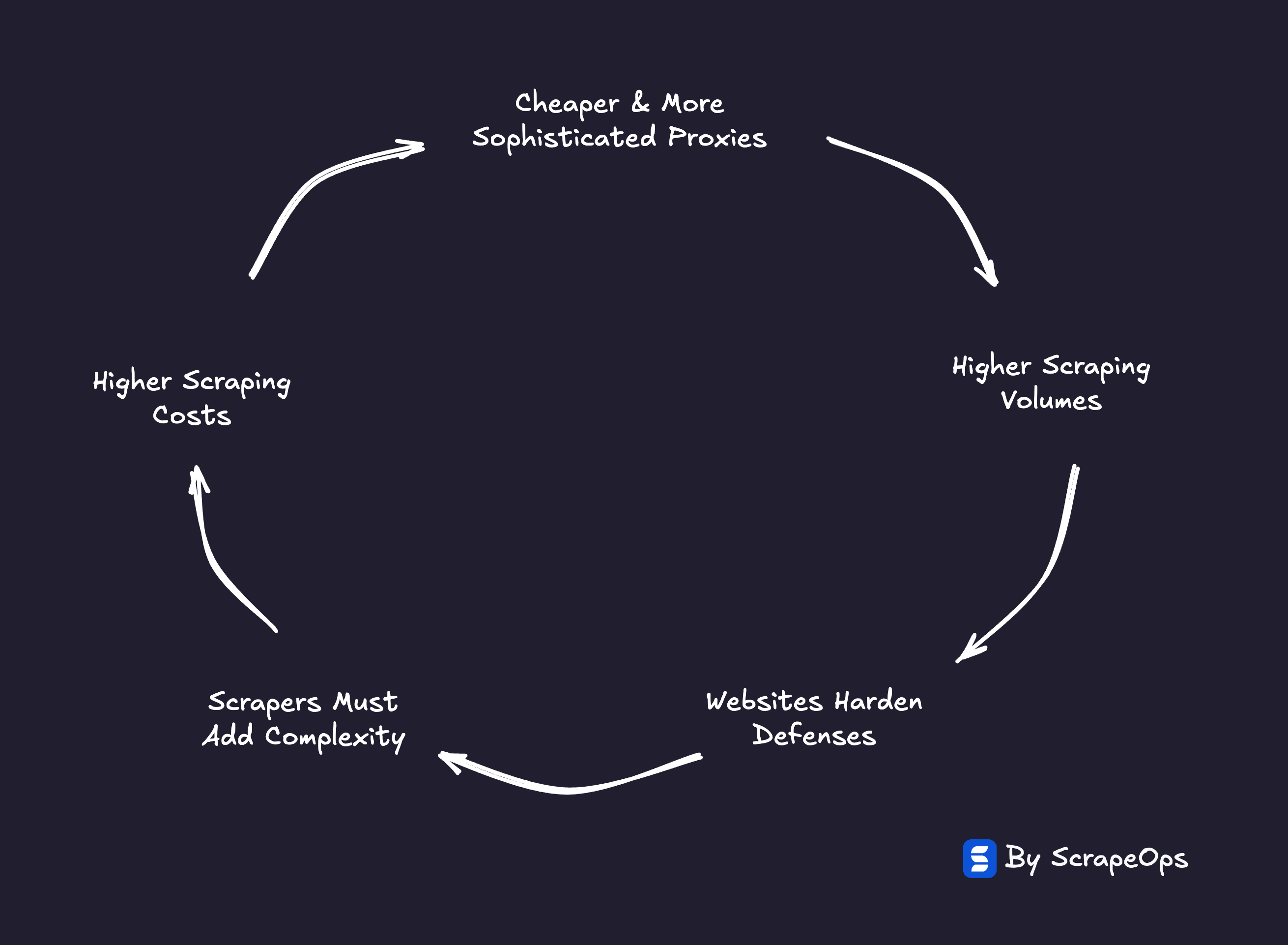
1. Escalation → Counter-Escalation
As proxies became cheaper, more feature-rich, and robust, new use cases became viable, resulting in scraping volume exploding.
That surge triggered websites to deploy new waves of anti-bot defences:
- IP fingerprinting
- CAPTCHAs
- JavaScript challenges
- TLS fingerprinting
- Behavioural analysis
In turn, proxy providers and scrapers responded with:
- Smarter proxy rotation
- Headless browsers
- Cookie harvesting
- Session emulation
- Higher-quality residential/mobile IPs
Each side runs faster just to stay in place.
The result: escalating complexity, rising costs, and no real equilibrium.
Every efficiency gain at the proxy & infrastructure layer is quickly neutralised by an equal increase in defensive sophistication.
The total system consumes more resources to maintain the same success rate.
"The proxy market didn’t mature, it militarized."
2. The Shadow Costs of Data Protection
Not every defence is an obvious anti-bot measure.
Some of the most effective tactics are subtle, structural changes that make large-scale data extraction slower, noisier, and more expensive.
Increasingly, websites are complicating the data extraction process by changing how their pages return the data itself:
-
Response Size Reduction: Reducing response sizes so pages reveal only partial content at once.
-
Data Fragmentation: Moving key data into dynamic pop-outs or separate API endpoints, requiring extra requests and session management to get the data.
-
Dynamic Content: Requiring browser-like behavior to deliver complete data payloads.
-
Shadow Banning: Returning shadow ban pages that require scrapers to validate responses and retry requests.
The result is simple: more requests per dataset.
What used to be a single HTML page might now require multiple calls to extract the same information.
Even if the proxies are perfect, the cost of collecting a complete dataset has risen dramatically.
Take Google as an example.
Recent design changes have quietly multiplied scraping costs:
| Shadow Cost | Explanation | Effect |
|---|---|---|
| Dynamic Content | Search result pages now require rendering to extract listings. | ~10X cost increase |
| Response Size Reduction | The num=100 parameter was removed. To extract the same data, you now need to make 10 requests instead of 1. | 10X cost increase |
| Data Fragmentation | Key data, like Google Shopping offers, has been moved into pop-outs and separate endpoints that require session management. | ~2-3X cost increase |
Each change looks minor in isolation, but together they act as economic rate-limiters, forcing scrapers to spend more to collect the same data.
In an era where every website understands its data is valuable training fuel for LLMs, these subtle design decisions act as hidden cost multipliers on the open web.
This is the shadow front of the Proxy Paradox, invisible friction that inflates costs without ever tripping a firewall.
3. The Commoditization Trap
Meanwhile, proxy supply and sophistication has exploded.
Hundreds of proxy providers, most reselling the same IP ranges, with ever more inbuilt sophistication, compete in an increasingly undifferentiated market.
Prices fall, legal and technical moats collapse, and marketing language converges on the same claims:
-
"millions of IPs"
-
"99 % success"
-
"the best proxy provider"
Abundance becomes its own problem.
Cheap, interchangeable proxies lower the barrier to entry for everyone, flooding websites with more traffic and driving another turn in the defensive spiral.
"The better proxies become and the easier proxies are to buy, the harder they become to win with."
Where once advanced scraping methods (fake browser fingerprinting, session management, etc.) were the domain of a few experts, they’re now baked into almost every proxy platform.
Turning capabilities that were once reserved for the few experts into commodities.
As a result, the entire market must adapt:
When everyone has the same power tools, those tools stop being an advantage.
It’s like the arms race unfolding in content generation…
When only a few had access to GPT models, the ability to produce articles and videos with AI was a hugh advantage.
However, as AI content generation tools became widespread, the internet is flooded with AI slop, and content platforms start building systems to detect and moderate it.
The same dynamic is emerging in web scraping:
As advanced tooling becomes ubiquitous, success shifts from having the tools to how you use them.
4. The System’s Equilibrium
Taken together, these forces don’t describe a broken market, they describe a self-balancing one.
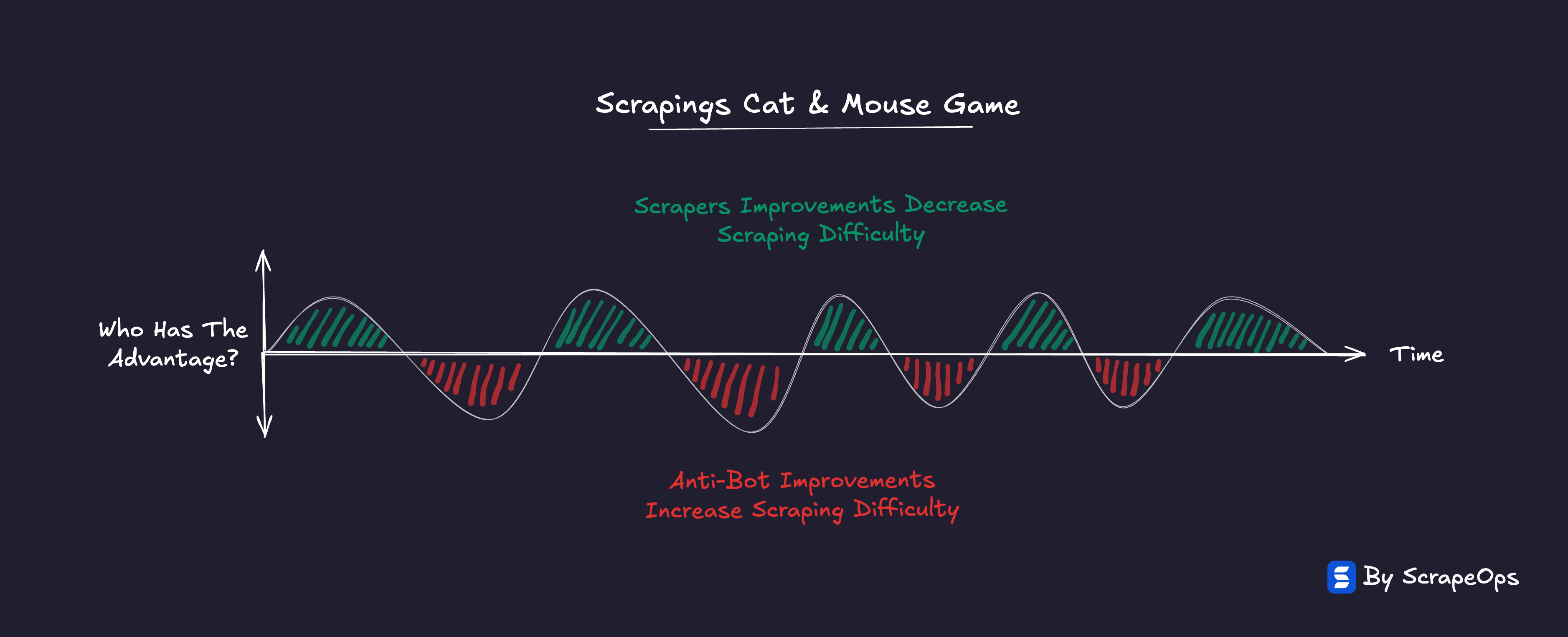
Every gain in proxy efficiency or accessibility creates new friction elsewhere in the system.
Anti-bot escalation, data fragmentation, and market commoditization all absorb the savings proxies create.
The ecosystem burns more total energy just to stay level.
That’s the Proxy Paradox in motion:
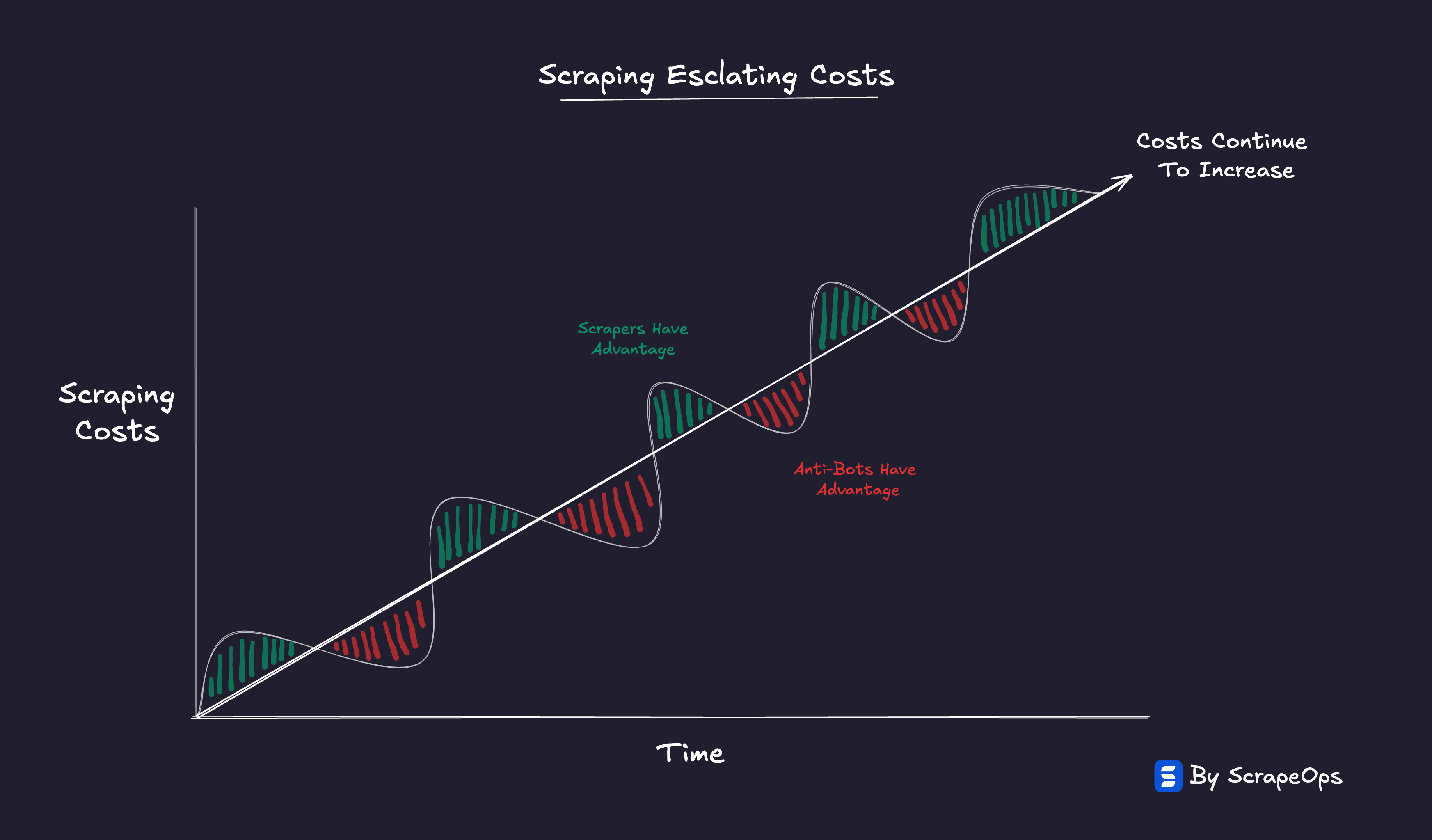
Cheaper access doesn’t lower the cost of scraping, it merely shifts where that cost is paid.
Progress at the proxy layer introduces complexity at every other layer.
And in doing so, it keeps the entire system locked in perpetual motion.
Is the Proxy Paradox a Law?

Is the Proxy Paradox a law?
Not quite. It isn't a law like Moore's Law, it's a pattern, closer to Jevons' Paradox.
In the 1800s, economist William Jevons noticed that when coal engines became more efficient, people didn’t use less coal, they used more. Efficiency lowered costs, which increased demand, which drove total consumption up.
The same thing happens in web scraping.
Cheaper, more efficient proxies make large-scale scraping accessible to everyone, which drives up total scraping volume, triggers stronger anti-bot defenses, and raises overall costs.
It’s not cause and effect.
It’s co-evolution, a system where both sides keep adapting to the other.
Cheaper access → more scraping → stronger defences → higher costs.
That’s the Red Queen at work: everyone running faster just to stay in place.
How the Proxy Paradox Is Reshaping the Proxy Market

While scraping has become harder and more expensive, the proxy market itself is evolving just as quickly.
Cheaper bandwidth, collapsing margins, and rising complexity have forced proxy providers to reinvent what they sell, and how they compete.
1. The Flood of Supply
The number of proxy providers has exploded.
Launching a "new" proxy service is easier than ever. In a matter of a few weeks anyone can build a proxy service reselling other providers IPs then focus on sales and marketing.
Legal barriers have also weakened. When Bright Data’s patents were struck down in its case against Oxylabs, one of the last structural moats in the industry disappeared.
The result is predictable:
- More competition.
- Lower costs ($ per IP, $ per GB, $ per successful response).
- Little differentiation.
Proxies has become a commodity resource, cheap, abundant, and interchangeable.
As proxies themselves become a commodity resource, the market is forced to split into two camps:
- Commodity IP Resellers: cheap, undifferentiated, high churn.
- Scraping Outcome Providers: integrated, intelligent, higher margin.

2. The Commodity Sellers
At one end sit commodity sellers, traditional proxy vendors competing purely on price, pool size, and bandwidth.
They sell access, not outcomes. Their margins come under pressure with every new proxy provider that enters the scene.
Forcing them to double down on claims of:
-
"50 million IPs"
-
"40 countries covered"
-
"100% uptime"
Unique selling propositions that quickly lose there significance when every competitor is making the same claims.
Forcing commoditiy proxy providers to double down on marketing and compete on price.
Proxy Resellers intensify the squeeze.
By prioritising niche marketing and branding, whilst using the same underlying IP pools, Proxy Resellers multiply supply, accelerate price erosion, and amplify the perception of abundance. Pushing true infrastructure providers further down the margin curve.
"In the Proxy Paradox, resellers spread abundance. Core proxy providers pay for it."
3. The Outcome Driven Providers
At the other end are outcome-driven providers.
To avoid commoditization and maintain margins, proxy providers are being forced to move up the value chain.
Selling raw IPs is no longer enough, they now need to sell outcomes.
Proxy products that promise outcomes need to give end users what they really want successful payloads, and even parse the data for them, not just raw IPs.
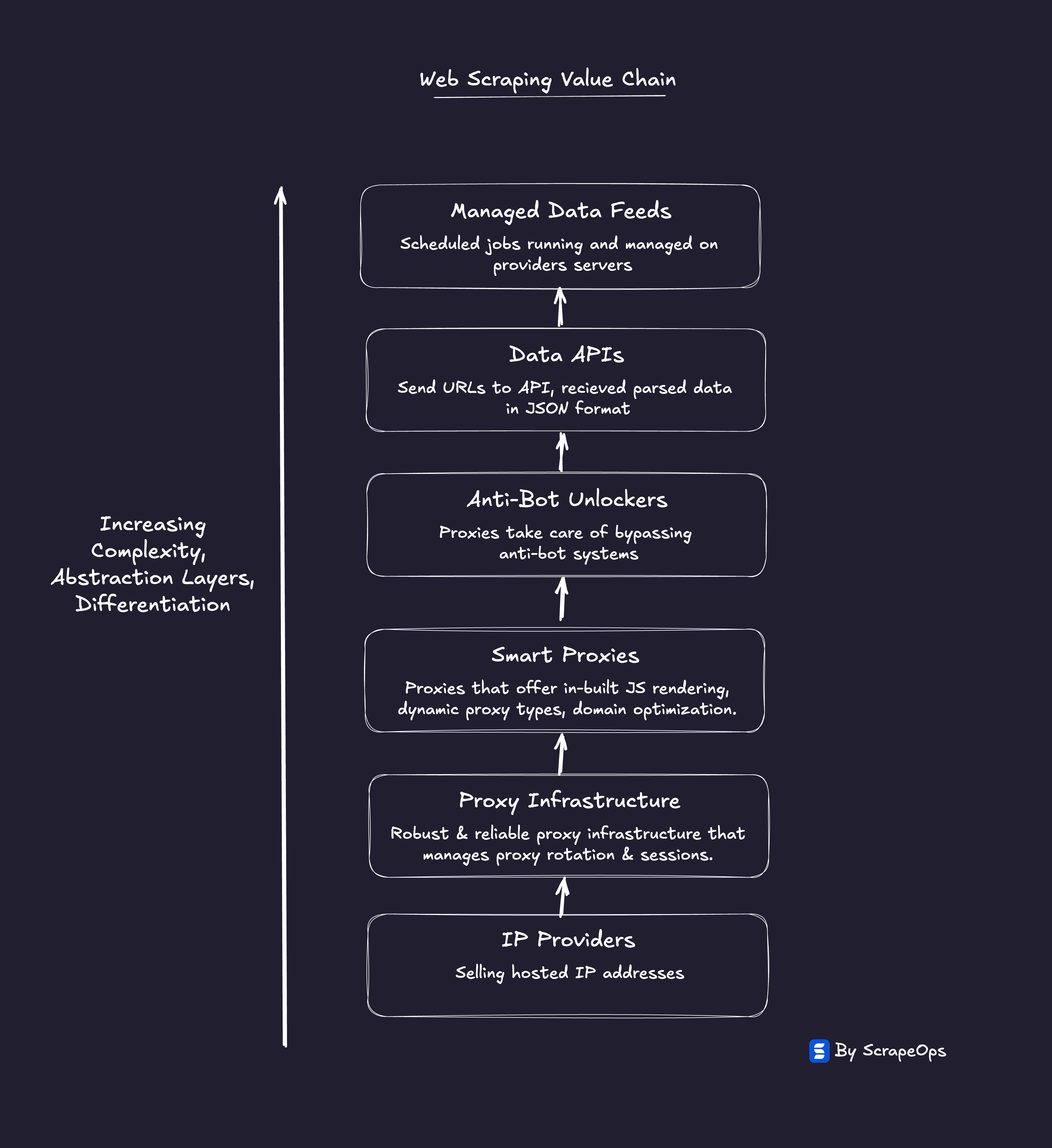
This shift has given rise to:
- Web Scraper APIs that bundle all of it, proxies, headless browsers, and anti-bot logic, into a single endpoint that delivers clean HTML and abstract away all the proxy management.
- Unlockers that promise the bypass the hardest anti-bot systems by handling browser & TLS fingerprints, TLS fingerprints, and JavaScript challenges.
- Data APIs that abstract away the parsing layer turning whole websites into clean data feeds.
They charge for success, not usage.
"Bandwidth became cheap; success became the product."
As providers climb the stack, their incentives change.
The metric that matters is no longer $/GB or $/IP, it’s cost per successful payload.
The old sales pitch was about scale: "We have 50 million IPs."
The new one is about certainty: "We’ll get you through Cloudflare."
Providers that master efficent proxy management, fingerprint tuning, and domain-specific success tracking can charge a premium.
Those still competing on price are caught in a race to the bottom.
In short, proxy providers are becoming scraping infrastructure companies.
"Proxy providers need to stop being IP resellers, they need to become scraping success providers."
To do this, they are absorbing the complexity scrapers used to manage themselves and charging for success instead of traffic.
4. The Paradox Comes Full Circle
The proxy market is fragmenting into two camps:
- Commodity IP Resellers: cheap, undifferentiated, high churn.
- Scraping Outcome Providers: integrated, intelligent, higher margin.
Ironically, both of these strategies only serve to accelerate the Proxy Paradox.
Commodity IP Resellers
Proxy providers compete on price → scraping volumes increase → websites harden defenses → providers must innovate faster → costs rise.
Scraping Outcome Providers
Providers create better scraping solutions → scraping volumes increase → websites harden defenses → providers must innovate faster → costs rise.
Outcome platforms increase costs with more sophistication, commodity sellers race to the bottom on price, and the cycle continues.
The end result is a vicious cycle of cheaper and more sophisticated proxies, but higher and higher scraping costs for end users.
Increasing competition and costs for proxy providers, but a scraping shock for end users where access is abundant but affordable success is vanishing.

Enter Scraping Shock
If the Proxy Paradox explains the proxy provider side of the market, Scraping Shock describes how it feels for the user.
Whilst all websites remain technically scrapeable (in fact, new proxy products are making it easier), the changing economics are making scraping some websites uneconomical to scrape.
As the use of anti-bot systems, rendering, and data fragmentation increase, the cost to scrape at scale keeps rising.
The question is no longer "Can you scrape it?"
It’s "How much are you willing to pay to scrape it?"
Every use case has an economic ceiling, a point where the cost of reliable extraction exceeds the value of the data it provides.
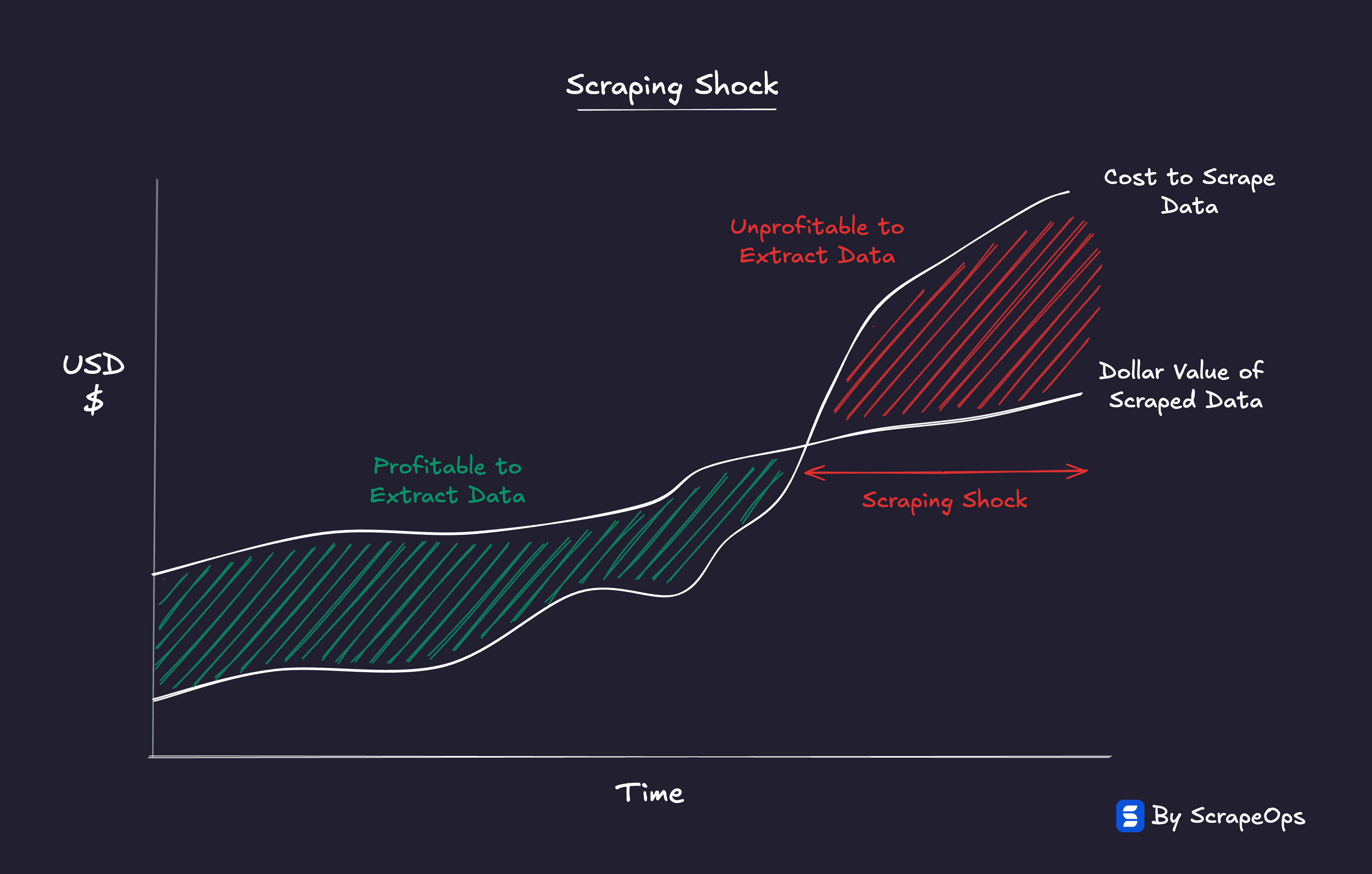
"Every dataset is still accessible, but each has a price point where extraction stops making economic sense."
Some industries are hitting that wall slowly, others, like e-commerce, travel, or social media data, are already feeling it.
When scraping becomes too expensive for the underlying business model, the use case collapses.
This is Scraping Shock, the realization that the constraint isn't access, but affordability.
It’s forcing every data-driven company to re-evaluate the economics of their pipelines.
"The web’s data didn’t disappear, it just got priced out of reach for some use cases."
The new competitive frontier is efficiency.
For the companies whose core products depend on scraped web data, their ability to acquire this web data at cheaper rates than their competitors can create real competitive advantages and moats.
One company being able to acquire their web data 50% cheaper than the market average enables them to have:
- Better margins
- Fresher data
- Broader coverage
The ability to acquire and refresh web data more economically than competitors will define market leaders in the next era of the data economy.
(We explore this in depth in our piece on Scraping Shock — the demand-side consequence of the Proxy Paradox.)
Efficiency as a Superpower

The Proxy Paradox isn't coming, it's already here.
Cheaper proxies, higher scraping costs, and growing complexity are now the default conditions of the web.
In this environment, efficiency isn’t an advantage, it’s survival.
For proxy providers…
The winners are those who obsess over success-per-dollar.
They measure relentlessly, focus on delivering validated responses at the lowest possible cost, and let that metric guide everything from infrastructure to pricing.
Their mission isn’t to own the most IPs, it’s to deliver the most successful payloads at the lowest possible cost to end users.
For scraping teams…
Efficiency means flipping the mindset.
Treat proxy and unlocker vendors as commodities, not partners to believe, but inputs to benchmark.
Let them compete. Test them continuously.
Track cost-per-success per domain, not per GB.
Swap out underperformers.
Automate the testing and optimization loops that align performance with economics.
The teams that win will be those who can:
- measure what's working and what's not,
- adapt to domain-level defenses quickly, and
- optimize their cost curves faster than the market moves.
In the age of the Proxy Paradox, scale doesn’t win, adaptability does.
"The Proxy Paradox isn’t an emerging trend, it’s the system we already operate in.
The winners are those who measure ruthlessly, adapt constantly, and let efficiency do the talking."
Conclusion
The Proxy Paradox isn’t a glitch in the system, it is the system.
Every time proxy access gets cheaper or easier, scraping costs rise somewhere else.
Efficiency at one layer breeds complexity at another.
Web scraping hasn’t become impossible, just more expensive to do well.
The question is no longer "Can you scrape it?" but "Can you afford to?"
This equilibrium defines the new economics of the web:
- Proxy providers chasing cheaper success.
- Scraping teams optimizing per-domain efficiency.
- Websites adapting to defend their data.
The cycle will keep turning not because anyone’s losing, but because everyone’s adapting.
"The Proxy Paradox is how the web balances itself.
Cheaper access. Costlier success. Endless motion."
And in that motion lies the only real advantage left, efficiency as a superpower.
Want to learn more about web scraping? Take a look at the links below!