
Why Y Combinator's Web Scraping Investments Reveal the Future of AI-Powered Data
Web scraping, once a niche solution used mostly by bootstrappers—has quietly become the backbone for AI-driven products.
From market intelligence to fueling large language models (LLMs), scraping is evolving from a hacky workaround into a mainstream data pipeline.
Y Combinator (YC) has increasingly been investing in companies that focus on web data extraction.
This shift isn't random. YC has a history of funding "picks-and-shovels" infrastructure that, over time, becomes critical to modern businesses. Think Stripe for payments or Twilio for communications.
So what does YC's increasing involvement mean for web scraping?
Let's break down the changing market for web data, the role AI is playing, where the opportunities are, and how the ecosystem might look in the next five to ten years.
- Shifting Perceptions of Web Data
- AI as the Catalyst for Scraping's Growth
- YC's Picks-and-Shovels Playbook
- Viewing the Web Scraping Market Through YC's Lens
- Where Are the Opportunities?
- Peeking 5–10 Years Into the Future
- Conclusion: Scraping as Tomorrow's Data Pipeline
- More Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: YC's Bet on Web Data Infrastructure
We tracked YC batches from 2019–2024 and found 7–8 startups focusing on web scraping, browser automation, or data extraction:
- Why It Matters: YC is investing in web scraping because it's a core piece of modern data infrastructure, especially for AI.
- Key Drivers: AI tools need massive, up-to-date information. Scraping provides that data when an official API doesn't exist.
- Opportunities: From automated scraping pipelines to specialized data services, there are many gaps to fill in this fast-growing market.
- Future Outlook: Expect more integrated, AI-driven scraping solutions that become as routine as using a standard API.
The Data: 5 Years Of YC Scraping Investments
We compiled data from various YC batch lists between 2019 and 2024, focusing on any startup whose core product involves:
- Web data extraction and crawling
- Browser automation / RPA for data collection
- Proxy management or advanced scraping infrastructure
Here's a quick summary:
| Year/Batches | Scraping Startups | Examples |
|---|---|---|
| 2019 (W19/S19) | ~0 | None Identified |
| 2020 (W20) | 1 | WebScraping.AI |
| 2021 (W21/S21) | 2 | Axiom.ai, Parsagon |
| 2022 (W22/S22) | 2 | Intuned, Firecrawl |
| 2023 (W23/S23) | 1 | Reworkd |
| 2024 (W24/S24) | 2 | Asteroid, Bytebot |
The headline: YC has funded 7–8 dedicated scraping startups across these batches.
This isn't a tidal wave, but the fact that they reliably back 1–2 every year suggests it's not a fluke.
YC seems to believe that data extraction is ripe for innovation and commercialization, especially as AI and compliance concerns grow.
Shifting Perceptions of Web Scraping
For years, web scraping was either:
- A quick hack to grab data from unstructured websites, or
- A gray-area practice that some businesses wanted to keep quiet.
This perception has changed. Web scraping is quickly becoming a mainstream data pipeline for many companies.
In the Web Scraping Market Report 2025, we saw how the web scraping market is growing at a ~15% CAGR, and is expected to be worth +$13B by 2033.
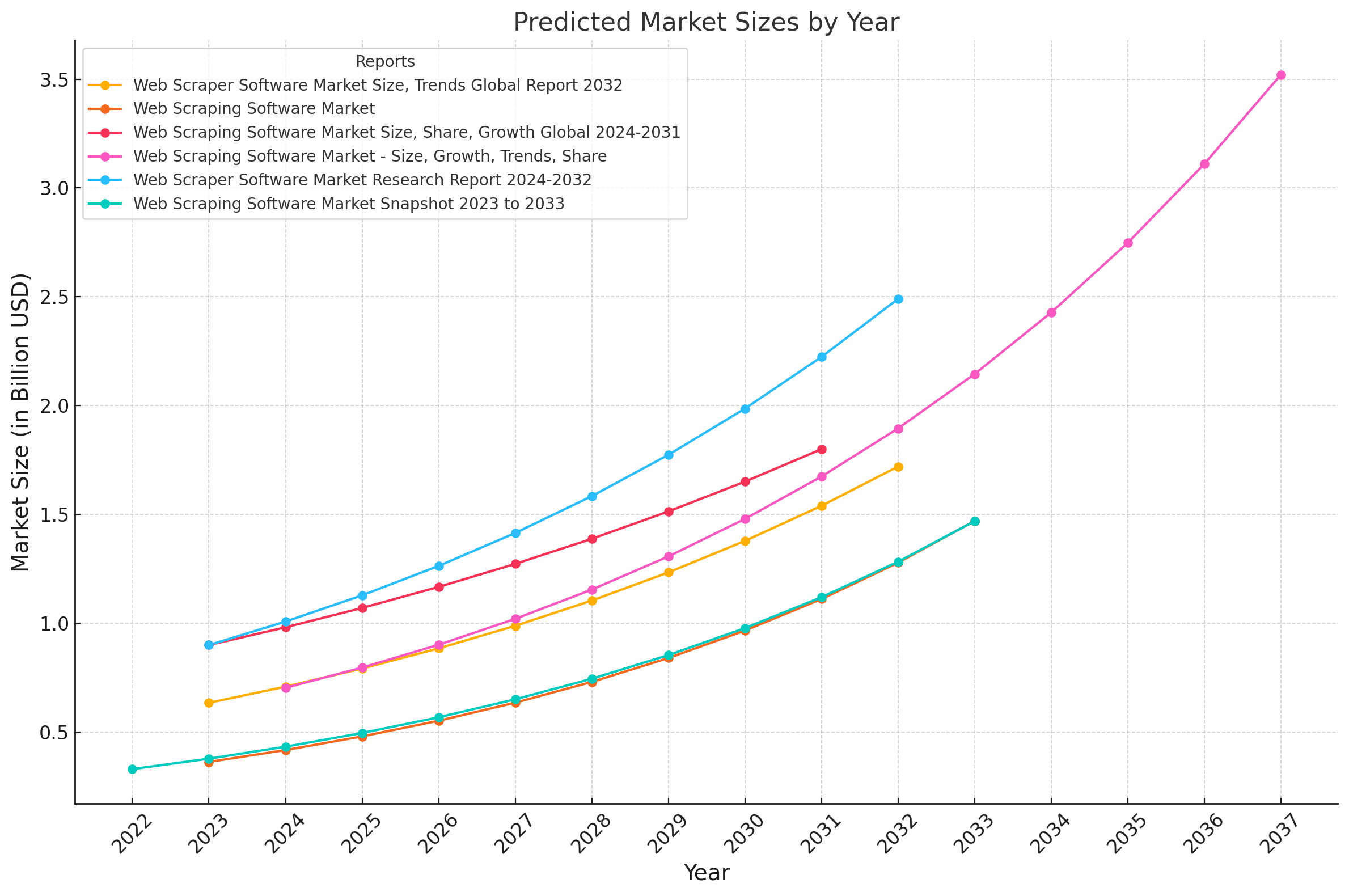
Now, web data isn't just for a small corner of growth hackers; it's becoming integral to business intelligence, machine learning, and real-time decision-making.
From Niche to Necessity
Web scraping is no longer a niche solution used by bootstrappers. It's a core function of modern data ops:
- Mainstream Demand: Companies need competitor pricing, sentiment analysis, or real-time content aggregation.
- APIs Not Always Available: Many sites still don't offer official APIs, or they limit the data you can access.
- Data Quality and Frequency: Today, decisions often rely on fresh data, so scrapers have to run reliably and continuously.
As a result, venture capital firms see the massive potential in tools that streamline extraction, transform data, and package it in enterprise-friendly ways.
AI as the Catalyst for Scraping's Growth
Artificial Intelligence has exploded in popularity, but for AI models to be useful, they need data, and lots of it.

This demand has made web scraping invaluable.
- Data for Large Language Models (LLMs): GPT-like models thrive on diverse text. Public websites are a goldmine.
- Real-Time Updates: Some AI-driven tools, like chatbots and analytics dashboards, need up-to-the-minute data. APIs often lag or don't exist, so scraping becomes the fallback.
- Automated Agents and RPA: Robotic Process Automation (RPA) software integrates with websites to automate repetitive tasks. Modern no-code or low-code scrapers help businesses scale these automations quickly.
As AI adoption grows, the appetite for web data grows with it. This synergistic relationship is at the heart of why new scraping startups are popping up—and why YC sees them as a solid investment.
YC's Picks-and-Shovels Playbook
Y Combinator has a history of betting on essential "infrastructure" that powers major trends in what they call the "picks and shovels" playbook.
Here are the core ideas behind YC's "picks and shovels" approach:
-
Invest in Foundational Infrastructure: YC loves startups building fundamental platforms, APIs, or technical services that other businesses rely on (e.g. payments, analytics, developer tools). By investing in the "plumbing" behind emerging markets, YC gains exposure to broad trends rather than being tied to one specific end use case.
-
Enable Other Startups to Scale: Many YC-funded "picks and shovels" startups provide tools or platforms that help new ventures spin up quickly, handle growth, or manage complex processes—from cloud infrastructure and SaaS management to AI/ML development tools.
-
Benefit from Ecosystem Growth: As startups across many industries expand, the companies supplying them with essential services grow in tandem. This diversified demand can lead to more stable, long-term returns compared to a single niche product.
-
Accelerator Synergy: YC's batch model creates natural synergy for "picks and shovels" companies: they can rapidly find early adopters within each cohort of YC startups, refine their product in-house, and expand to a wider market with proof points already in place.
Numerous of YC's best investments have been in the "picks and shovels" space.
| Startup | Industry | Picks & Shovels Strategy |
|---|---|---|
| Stripe | Payments | When e-commerce took off, Stripe made payment integration trivial. |
| Twilio | Communications | As apps proliferated, Twilio provided easy SMS, voice, and messaging APIs. |
| Heroku | Cloud Hosting | As cloud adoption surged, Heroku made deploying and scaling web apps seamless. |
| Segment | Analytics Infrastructure | As companies became more data-driven, Segment standardized how businesses collect and route customer data. |
| Gusto | HR/Payroll | As remote and flexible work models grew, Gusto simplified payroll and benefits management for small businesses. |
| Checkr | Background Checks | As the gig economy expanded, Checkr made background checks fast and API-friendly for on-demand hiring platforms. |
| Flexport | Global Logistics | As global trade became more complex, Flexport modernized freight forwarding with data-driven logistics. |
| Docker | Containerization | As software development scaled, Docker standardized application deployment across any infrastructure. |
| Shippo | Shipping & Logistics | As online shopping exploded, Shippo made shipping logistics easy with a simple API and dashboard. |
| Algolia | Search-as-a-Service | As user expectations for fast, relevant search grew, Algolia delivered instant, customizable search for websites. |
YC recognized that focusing on building blocks rather than just end-user applications, using its picks and shovels approach, YC could:
- Get exposurer to emerging gold rushes (e.g., e-commerce, app-based communication, cloud apps)
- Ride multiple waves of innovation
- Foster rapid product iteration for its own portfolio, and
- Ultimately derive more stable growth across different technology cycles.
One HackerNews commenter summarized YC's approach brilliantly:
Selling shovels in a gold rush not only makes you rich, it also isolates you from the greatest part of the risk.
Web Scraping Through YC's Picks-and-Shovels Lens
YC doesn't typically invest in "one-off" solutions. They look for startups with potential to redefine or dominate a category.
Web scraping, the pipeline that delivers precious raw material—unstructured web data—into analytics or AI workflows, nicely fits YC's picks and shovels model.
- Solve a crucial, widespread problem.
- Become the default infrastructure for an emerging market.
- Gain a strong competitive moat as more businesses rely on that service.
Looking at the data:
| Startup | Problem | Solution |
|---|---|---|
| Axiom.ai (W21) | Complex browser tasks require coding skills | No-code tool enabling users to automate browser actions without programming |
| Parsagon (W21) (looks dead) | Extracting structured data from websites is challenging | AI-driven platform that aimed to simplify data extraction from web pages |
| Intuned (W22) | Monitoring and interacting with web applications is labor-intensive | AI-powered tool for automating monitoring and interactions with web apps |
| Firecrawl (S22) | Difficulty in obtaining AI-ready data from the web | Open-source API that converts web data into clean, LLM-ready formats |
| Reworkd (W23) | Building and maintaining web scrapers is time-consuming | End-to-end platform that automates the entire web data pipeline |
| Asteroid (S24) | Browser automation is complex and costly | Browser agents as a service, allowing both technical and non-technical teams to automate tasks |
| Bytebot (S24) | Web data extraction and form filling are time-consuming | AI-driven platform that translates natural language prompts into web automation tasks |
When looking at YC-backed web scraping ventures, we can see some common themes:
- AI-Assisted Scraper Generation: Tools that automatically build and maintain scrapers, reducing maintenance headaches.
- No-Code / Low-Code: Platforms that let non-developers record and automate browser tasks.
- Open-Source: Some startups are building communities around open-source crawling frameworks, leading to widespread adoption.
- Enterprise-Grade Pipelines: Features like compliance, scheduling, robust proxy management, and post-scrape data refinement.
Growth Factors
Not only do these web scraping startups fit YC's picks and shovels model, but they also have the following growth factors:
- Huge TAM (Total Addressable Market): Almost every company in plays a role in data analytics or AIs growing need up-to-date web data.
- Repeatable Revenue: Scraping as a service can become a subscription model with high customer retention.
- Flywheel Effects: More users = more data collected = better machine learning models = higher value for existing clients.
All going well, these companies are well positioned to grow into picks and shovels for the web scraping market.
Where Are the Opportunities?
Web scraping isn't just about the moment of extracting data. It's an end-to-end process that can include:
-
Discovery & Selection
Finding which sites or data points matter. Tools that help users identify relevant sources have a foothold here. -
Crawling & Extraction
Automating the data-gathering process, dealing with dynamic pages, captchas, and site changes. -
Proxy Management & Anti-Blocking
Ensuring consistent access at scale. Providers like the ScrapeOps Proxy Aggregator unify multiple proxy networks into one interface to reduce friction. -
Post-Processing & Cleaning
Converting raw HTML or JSON into structured, reliable datasets. This might involve AI for classification or deduplication. -
Integration & Analytics
Feeding that data into analytics dashboards or machine learning pipelines. Monitoring success rates, scheduling, and error handling with custom web scraping Monitoring Solutions or similar tools.
Each segment is a potential business opportunity. Some players focus on a single stage, while others aim to be full-stack solutions.
YC typically supports companies that lock down a core layer (like Stripe's payments layer) or deliver a seamless suite of solutions.
Peeking 5–10 Years Into the Future
Given the growth of AI and the increasing demand for web data, it's interesting to speculate on what the future might look like for the web scraping industry:
-
Ubiquity of AI Agents
Imagine advanced GPT-like bots that constantly read and interpret the web, responding in real-time. Scraping infrastructure will be the invisible backbone enabling these updates. -
Standardization & Protocols
Just as APIs became standardized, we might see universal scraping protocols, or regulated channels for public data. Some websites could adopt "scraping-friendly" data endpoints. -
Heavier Automation & Self-Healing
Future scrapers may automatically adapt to site changes, identify new data points, or even negotiate access with site owners for deeper data feeds. -
Industry Consolidation
A handful of large scraping providers could emerge, offering end-to-end solutions with near-100% uptime. Smaller players will either find niche specialties or focus on open-source communities. -
Seamless Integration With ML Ops
As machine learning pipelines become standard, scraping will integrate seamlessly with data cleaning, labeling, model training, and continuous deployment. Data extraction might be as trivial as pressing a few buttons in a universal "data platform."
This trajectory suggests that by 2030 or so, we may no longer view "scraping" as a distinct practice.
Web scraping could become an embedded, unremarkable part of how software is built, much like calling an HTTP API is today.
Conclusion: Scraping as Tomorrow's Data Pipeline
Web scraping is transforming from a patched-together hack into a cornerstone of modern, AI-driven business. Y Combinator's recent investments offer a strong signal that reliable web data, at scale, is poised to become as essential to startups and enterprises as cloud hosting or integrated payment APIs.
By dissecting the scraping market—discovery, crawling, proxy management, data cleaning, and analytics—we see enormous opportunity for new players to innovate. AI's appetite for real-time data only accelerates this trend.
In a future where data is the primary fuel for smart solutions, scraping will remain central. And if YC's history in fueling industry disruptions holds true, we can expect to see web data extraction become a standard tool in every company's kit.
More Scraping Guides
- Scraping JavaScript-Heavy Sites: 5 Approaches
- How To Handle CAPTCHAs In Web Scraping with Python
- Building Resilient Web Scrapers With Python & ScrapeOps Monitoring
Ready to take your scraping game to the next level? Check out the ScrapeOps Proxy API Aggregator for seamless proxy switching, or streamline your workflow with the ScrapeOps Scraper Scheduler.
Happy data hunting!