We Use 5 Different Methods to Scrape 82 Different Sites -- Here's Who Blocked Us (and Who Didn't)
Web scraping discussions tend to focus on how to bypass anti-bot defenses, but rarely do we see hard data on what actually works.
There's plenty of theory, but where's the real-world testing?
This article isn't just another “how to bypass Cloudflare” guide. Instead, we ran a structured experiment:
- We scraped 82 websites across eCommerce, news, job boards, and social media.
- We tested 5 different request methods, from basic HTTP clients to stealth browsers.
- We used a single static residential IP per test, measuring how many requests we could send before getting blocked.
- We analyzed which anti-bot mechanisms fired CAPTCHAs, rate limits, JS challenges, ban pages, etc.
💡 The goal? To create a real, data-driven benchmark for scraper performance, so you can make smarter proxy and bot-detection evasion decisions.
The results? Some sites were surprisingly open, others locked down hard. Some bot mitigation tactics failed entirely, while others were brutally effective.
In this guide, you will see the real data behind scraper performance and bot detection evasion strategies.
- TLDR
- How We Tested These Sites
- Overview of Test Results
- The Biggest Shockers: The Web's Anti-Bot Wild West
- The Blocking Data In Detail
- Key Takeaways: What Actually Works (and What Doesn't)
- Best Practices for Smarter Web Scraping
- The Ethical and Legal Notes
- Conclusion and Open Invitation
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR
We tested 82 sites (eCommerce, news, job boards, social) with one goal...
See how long it takes websites to block requests using various request methods if we use the same IP address.
We used 5 scraping techniques:
- ✅ Plain HTTP (Naked) → Surprisingly high success rate
- ✅ Custom Headers (User Agent & Browser Agent) → Often best approach
- ❌ Headless Browsers (Vanilla Playwright & Playwright Stealth) → Blocked the most
The results challenged everything we believed about modern web scraping.
Key Surprises:
- Two titans of eCommerce, Apple and eBay, seem to give bots free rein over their site.
- Nike locks everything down tight.
- Job sites like LinkedIn and Indeed were like impenetrable fortresses.
- Social media sites like TikTok and Instagram are friendlier to obvious bots than hidden ones.
Core Finding: No single, one-size-fits-all approach to scraping. The success rate varied wildly depending on the site's anti-bot strategy (headers? JavaScript checks? IP-based throttling?).
How We Tested These Sites
The following sections detail the methods we used to test these sites and how we classified the results.
Testing Methods
Each site was evaluated using 5 different request methods ranging from standard HTTP requests to a fortified version of Google Chrome using Playwright Stealth.
- Naked: These requests were made with Python Requests. These are just simple requests made with default HTTP settings.
- User Agent: We tweaked Requests to send a custom header to the server, announcing our presence as a specific browser. If a server depends on only the User Agent headers, it should think that our HTTP client is an actual browser.
- Browser Agent: Similar to User Agent, but with additional headers to make our HTTP client appear like a real browser. This method stands up to some of the most difficult types of header analysis.
- Playwright: A testing tool for automating web browsers. While it's designed for testing, Playwright is an excellent tool for any kind of browser automation. It allows you to control an actual browser from inside a programming environment like Python.
- Playwright Stealth: A fortified version of Playwright, built with web scraping and privacy in mind. Stealth uses modified headers of its own and a variety of other techniques to make bot blocking difficult.
We made up to 100 requests per site/method with no time delay until we got definitively blocked (403, ban pages, or repeated CAPTCHAs).
Failed Response Classification
Any of the following was considered a block or bot check from the server. Each response was checked against the following:
- Non 200 Status Codes: This includes things like error codes 403, 429, 503. If it's not 200, you're being blocked or rate limited.
- JavaScript Challenges: Modern blocking tools like Cloudflare and DataDome will send a puzzle along with the web page. Without a browser to execute it, bots fail this challenge.
- Login Page: If a site prompts a bot to login and enter its data, most bots get stopped dead in their tracks.
- Ban Page: This is an actual page telling the bot (or person running it), that they've been discovered and they are banned from accessing the site.
- CAPTCHA: Most of us hate these things with a passion, however, they are among the best tools for stopping bots.
- Automated Access Denied: The site recognizes the bot and blocks it.
- Rate Limiting: When a malicious bot sends too many requests to a server, this can overwhelm it with symptoms of a DDOS attack. Rate limiting is used to protect the server from this.
- No Body: The server was either overwhelmed or refused to respond.
- 404 Page: We've all seen these. 404 indicates that the page wasn't found.
- Other: This is used to represent any other abnormalities or bot blocks found on the page.
To ensure accuracy, each result was rigorously checked and responses were even fed into ChatGPT4o for double validation.
Proxy Strategy
Instead of rotating proxies to get past blocks, we used a static residential proxy per test to emulate real user behavior.
This way we could clearly see how long it takes websites to block requests using various request methods.
We chose our categories based on a variety of reasons.
- eCommerce: The most popular target for web scraping.
- News: News sites handle millions of users every day from all over the globe. These sites tend to be high traffic and well built.
- Job Boards: These are often the biggest targets in the data extraction industry. It's a bit of a legal grey area, but data companies make huge amounts of money by crawling job boards and reposting the listings elsewhere.
- Social Media: Social media sites are built to handle long sessions of interaction from billions of people all over the world. Their high traffic and prolonged use makes them an excellent test case for bots.
Overview of Test Results
Some of the results were surprising. We expected the results to be different, but not this much.
Success Rates By Request Method
We generally had higher success rates using an HTTP client than with automated browsers. This is shocking. HTTP clients always have a developer of some kind pulling the strings. Our Browser Agent case yielded the most successful results consistently. Equally shocking, Playwright and Playwright Stealth were the most blocked clients from the test.
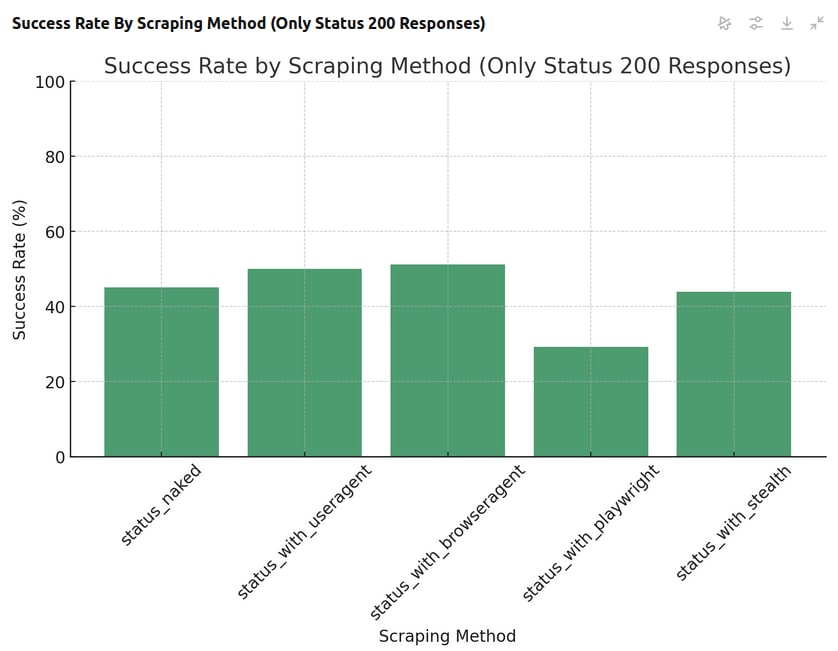
- Naked: Averaged just over 40 successful pings... about 45.1% success. An obvious bot is able to get the site almost half the time.
- User Agent: With a custom user agent, we averaged a slightly higher success rate, about 50%. This indicates that many websites are analyzing more than just the User Agent header but the User Agent can greatly increase a bot's chances of getting past blocks.
- Browser Agent: When using a full browser agent, we averaged a success rate of 51.2%. This is just a hair better than a standard User Agent. This is indicative that most sites checking headers look at only the User Agent.
- Playwright: Playwright's results were abysmal. Playwright came in dead last with a success rate of 29.3%. Considering it's designed to emulate real users, this is quite bad.
- Playwright Stealth: While Playwright Stealth was a noticeable improvement over vanilla Playwright, yielding a 43.9% success rate.
At first glance, the reasoning behind these results is perplexing and unclear. Anti-bots are more likely to block actual browsers than barebones HTTP clients.
We don't know which anti-bots these websites are using, but this appears to be a clear case of failure with anti-bot software across the board.
Success Rates By Site Category
When we look into the success rates by category, the results shed more light on how these blocking mechanisms are actually employed. Different categories tend to use different types of bot protection.
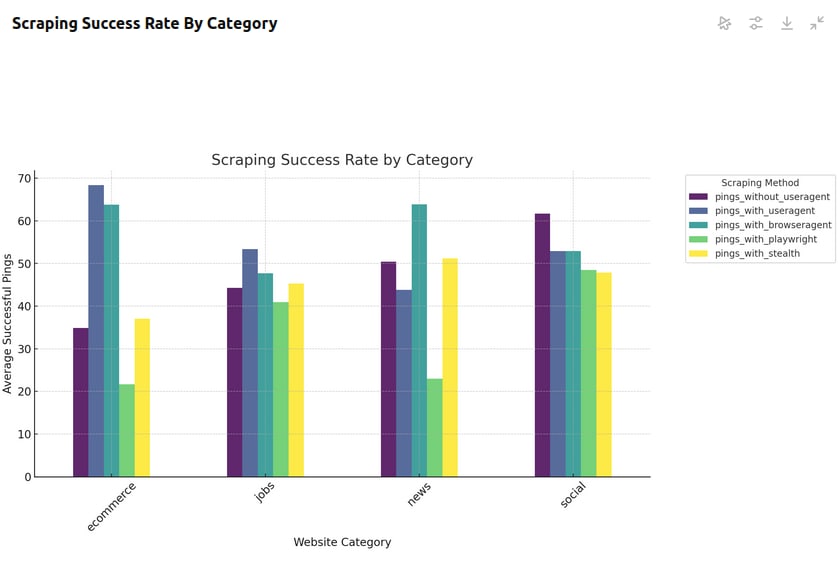
- eCommerce sites seem to employ the most header analysis: User Agent and Browser Agent had more than double the success rate of other methods. It appears that access to most eCommerce sites is based almost entirely on HTTP headers.
- Job sites are quick to wield the ban hammer: Of all our testing methods, User Agent was the only one to achieve a success rate over 50%, and it just barely broke that mark. All other methods failed more than half the time. This indicates that these sites likely use a combination of rigorous header analysis, JavaScript Challenges and CAPTCHAs.
- News sites tend to use mostly header analysis as well: In this category, Browser Agent gave about a 65% success rate. Stealth came in second with roughly 52%. These were the only results that aligned with industry wide assumptions about HTTP headers and fortified browsers.
- Social media sites break every anti-bot assumption around: When accessing social media, our naked HTTP client decisively achieved the best results with over a 60% success rate. User Agent and Browser Agent both yielded just above 50%. Playwright succeeded just under 50% of the time and Playwright Stealth came in last. The most protected scrapers are the most likely to get blocked?!
The Biggest Shockers: The Web's Anti-Bot Wild West
One of the most surprising discoveries in our experiment wasn't just who blocks scrapers, but who doesn't.
Some of the largest and most data-sensitive websites did nothing to stop scraping, while others completely shut us down after just a few requests.
Sites That Let Bots Roam Free
Some websites seem to have little or no bot detection, allowing unlimited scraping from a single IP with no restrictions:
- Apple – We sent hundreds of requests, no blocks, no CAPTCHAs, nothing.
- eBay – As if bots don't exist.
- Rakuten – No restrictions, full product listings accessible.
- Work in Startups – An open door for job listing scrapers.
🧐 Why? These sites either don't care about scrapers, have lenient bot policies, or rely on alternative ways to protect their data, such as monetized APIs.
Sites That Slammed the Door Shut
On the opposite end, some sites instantly detected and blocked our scrapers, even when using stealth tactics.
- Etsy – Immediate blocks, even with stealth browsers.
- Home Depot – Instant CAPTCHA after just a few requests.
- Temu – Flat-out denied access across all scraping methods.
- LinkedIn – A job board fortress. Everything beyond the login wall was locked down.
🚨 Why? These sites likely rely on heavy IP tracking, JavaScript challenges, and bot fingerprinting to detect automated traffic before it even loads the page.
The Weirdest Findings
Some sites completely broke common anti-bot assumptions:
Nike blocks everything… except advanced scrapers
- Simple requests? Instantly blocked.
- Stealth browsers? More successful.
- Nike seems to prioritize blocking naive scrapers over more sophisticated ones.
Social media blocks stealth more than simple bots
- You'd expect Instagram, TikTok, and Facebook to block everything.
- But oddly, plain HTTP requests worked better than stealth browsers.
Job boards are the hardest to scrape
- LinkedIn, Indeed, and Stack Overflow Jobs aggressively blocked automated access.
- 403 errors, login walls, and CAPTCHAs appeared immediately.
Takeaway: Anti-Bot Protection Is Inconsistent at Best
Some major companies don't block bots at all. Others deploy extreme anti-bot measures, but only for certain types of requests. There is no single method that works everywhere, the key to success is testing, adapting, and optimizing for each site.
💬 What's the strangest bot-blocking behavior you've seen? Share your insights below.
The Blocking Data In Detail
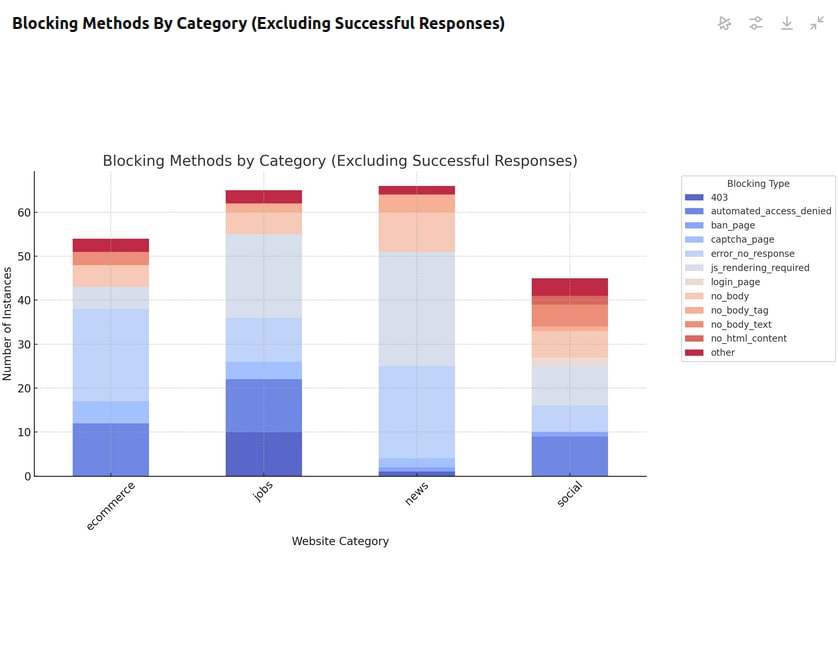
The most common blocking methods across all categories were CAPTCHAs, JavaScript Challenges, and No Response.
The key takeaway here: websites are blocking bots and still sending a 200 status code.
The following methods are commonly used to block bots even when a status 200 is sent to the HTTP client.
- Automated Access Denied: The site recognizes the the bot and responds with a page stating that they're not allowing automated access.
- Ban Page: Similar to the Automated Access response, but more vague. The server is telling the bot that it's been banned, but not necessarily telling it why.
- CAPTCHA: A bot was suspected by the server, so it sent a CAPTCHA to prevent non-human access.
- No Response: The server was either overwhelmed or spotted the bot. In either case, the bot will be unable to access the site without a response.
- JavaScript Challenge: Similar to the CAPTCHA, the server suspects that there might be a bot. It sends this type of challenge to verify that there's an actual browser behind the requests.
- No Body: The response was received but there was no body containing information.
- No
<body>HTML tag: The server sent back an HTML page without a body. Essentially just a blank document. - No Text in Response: The response didn't contain any text. Since there is no data to interpret, the bot cannot access the site.
- No HTML Content: A response was sent, but it didn't contain any HTML. There is no web page for the bot to scrape.
- Other: The page failed to validate for some reason not specified above.
All of the methods listed above are blocks that come with a status 200. Error code 403 is a commonly used standard for blocking bots on the web. However, in the wild, real sites rarely use it to block automated access. Instead, the vast majority of the time, they send a status 200 with some type of a bot blocker on the page. This contrasts with normal web development standards.
If you'd like to review our testing methods or our individual results, you can view them below.
Key Takeaways: What Actually Works (and What Doesn't)
After testing 82 websites across multiple categories, one thing is clear: there is no universal web scraping strategy.
What works for one site may completely fail on another.
But we did find some patterns that can help optimize your approach.
1. Scraping Success Is Highly Category-Dependent
Different types of websites rely on different anti-bot strategies. Understanding this can help you choose the right tools for the job:
- 🛍️ eCommerce → Headers matter most. The biggest signal sites check is your
User-Agent. A simple tweak can significantly improve success rates. Paradoxically, advanced headless browsers often trigger more scrutiny than a well-formed request. - 💼 Job Boards → The toughest to crack. Expect 403 errors, login walls, and aggressive rate limits. IP rotation, stealth browsers, and CAPTCHA-solving will be necessary.
- 📰 News → Looks like a browser? You're in. News sites heavily rely on JavaScript, so full browser headers and JavaScript execution are crucial. Playwright or Puppeteer work better here.
- 📱 Social Media → The biggest surprise. Plain HTTP requests often worked better than full browsers. Socials seem to prioritize blocking stealthy automation over basic scrapers.
2. Just Because You Get a 200 OK Doesn't Mean You're Not Blocked
A status code of 200 doesn't always mean success many sites return a fake page, an empty response, or a CAPTCHA challenge while still sending an “OK” response.
✅ Always analyze the HTML body, not just the response code.
3. Stealth Browsers Aren't Magic
Many assume that headless browsers like Playwright Stealth can bypass everything, but our tests show that basic HTTP requests often had higher success rates.
Some sites actively block headless setups, while others are lenient toward simple scrapers.
4. Rate Limiting Is a Bigger Threat Than IP Bans
Most sites don't instantly ban an IP but will start slowing requests, throwing CAPTCHAs, or serving fake content after too many hits. A good proxy rotation strategy should consider rate limits, not just bans.
5. Every Site Requires a Custom Approach
- Some sites only check headers.
- Some run heavy JavaScript challenges.
- Some will let you scrape freely for a while, then silently block.
- Some don't care at all.
A single, generic scraper won't work across multiple sites. If you're serious about data extraction, you must adapt your scraping strategy for each target.
Best Practices for Smarter Web Scraping
From our experiment scraping 82 websites, we identified key best practices that increase success rates and reduce detection risk. Whether you're scraping at scale or just experimenting, these guidelines will help optimize your approach.
1. Always Test with Multiple Request Methods
No single method works everywhere. Before building a scraper, test different techniques (plain HTTP, headers, browser-based, stealth, etc.). Some sites are more sensitive to headless browsers, while others only care about headers and IP reputation.
How to do it:
- Start with simple HTTP requests (low effort, low fingerprint).
- If blocked, try modifying headers before jumping to Playwright/Puppeteer.
- Only use stealth browsers when necessary, some sites flag them immediately.
2. Rotate IPs, but Also Vary Your Request Timing
Most scrapers focus on rotating proxies, but rate-limiting patterns can block you before your IP is blacklisted. Many sites track unusual traffic spikes rather than just IP reputation.
How to do it:
- Slow down your requests and use human-like delays.
- Avoid hitting the same endpoints too quickly, some sites will detect unnatural traffic patterns even if the IP is clean.
- Use session-based proxies when possible to maintain continuity.
3. Headers Matter More Than You Think
Many sites don't block based on IP but analyze HTTP headers to detect bot behavior. Some scrapers get blocked simply because they send incomplete or unusual headers.
How to do it:
- Mimic real browsers, use full browser headers, not just
User-Agent. - Randomize Accept-Language, Accept-Encoding, and Referer headers.
- Check how real browsers request the page using DevTools > Network in Chrome.
4. Monitor Response Bodies, Not Just Status Codes
Some sites return HTTP 200 OK while actually serving fake or incomplete content to suspected scrapers. Many bots fail because they only check if response.status == 200 instead of verifying the HTML content itself.
How to do it:
- Look for CAPTCHA challenges, "Access Denied" messages, or missing data.
- Compare responses against real browser requests, is anything missing?
- Set up response validation checks in your scraper.
5. Use Browser Automation Only When Necessary
Many assume headless browsers (Playwright/Puppeteer) are the best solution, but in our tests, simpler methods (like well-crafted HTTP requests) often worked better.
When to use headless browsers:
- When JavaScript rendering is required (e.g., dynamic content).
- When sites serve different content to real browsers vs. scrapers.
- When CAPTCHA challenges need solving.
When NOT to use headless browsers:
❌ If the site serves mostly static HTML, HTTP requests are faster and stealthier.
❌ If the site actively detects headless browsers, you'll stand out more.
The Ethical and Legal Notes
Notes on the ethical and legal gray area of web scraping:
- We tested public endpoints for research, no scraping behind logins or paywalls.
- Scraping can breach ToS or
robots.txt, depending on local laws. We're not lawyers; do your own diligence. - Overloading a site or capturing personal data crosses ethical lines. This was purely observational.
We love to talk shop. We invite anyone with an opinion to share it with us. You're here to learn and so are we. If you're a site owner, a developer, or a legal expert, we want to hear your opinion on best practices and ethical guidelines to follow.
Conclusion and Open Invitation
If you want consistent success in web scraping, assume nothing and test everything. This experiment revealed that many anti-bot defenses are weaker (or stronger) than expected, and the real winners are those who adjust their approach based on actual testing.
There's one rule: if you can't adapt, you're going to get blocked.
If you want to scrape the web with proficiency, you need to understand that every website is different and you need to be willing to use the right tool for each job.
Sometimes you might need to set custom User Agents. Other times, you might need a fortified browser to render JavaScript while spoofing your HTTP headers.
We thought stealth browsers were the best way to scrape. Our results said otherwise.
Have you run your own scraping tests? Did you find a secret trick that beats job board CAPTCHAs? Are some stealth tools better than others?
Let's compare notes, drop your insights in the comments.
At ScrapeOps, we love web scraping. If you've scraped any of these sites, or even ran a test at scale like this, let us know. We want to know what you learned and we want to share what we've learned.