Top 7 AI Web Scraping Tools of 2026: Overhyped or Revolutionary?
AI has disrupted nearly every global industry circa 2026. Over the last 10 years, AI has become increasingly embedded in our everyday lives. Whether it's exciting or terrifying, AI is making its way into large-scale data collection.
AI powered web scraping has long been considered the Holy Grail of data extraction. This technology promises accurate, efficient extraction with minimal code. Do these tools actually deliver?
We tested the top 7 AI scraping tools to see if they're really worth it. Read on to see which tools are worth your time. Ideally, AI scraping tools should require zero coding and shouldn't be limited to a single programming language.
Key Features and Takeaways
Things You Need To Know
- AI is still evolving. New tools arise every day, but the open-source world is still adapting. Most tools are unreliable or overly complex.
- Paid tools work. Write a prompt and get your data. No coding required, just talk to the model and get your data.
- Open source tools currently aren't worth it. crawl4ai is very promising but most alternatives are just over-engineered HTTP wrappers. You're not scraping with AI, you're scraping a page and feeding it into an external LLM.
- Code-free scraping hasn't completely arrived. Proprietary tools can make it happen, but open source tools are limited to a single environment like Python or JavaScript or even a single framework like Scrapy or Playwright.
- Most open source options aren't actually free. They require an API key to an external paid service.
- AI scraping tools are not created equal. The open source community seems more focused on marketing buzz than real usability. Paid tools offer an interesting alternative for non-techies, but traditional data extraction isn't going anywhere...yet.
Price Comparison of all Tools
Open Souce Models
It's impossible to get a true price for open source options since their cost is API dependent. This can range from free (for locally hosted LLMs) to almost $200,000 per million pages for GPT 4.5. We're going to use GPT o3-mini to estimate our open source pricing. We'll estimate the cost of each page at 750 tokens of input and 500 tokens of output.
| Model | Input Tokens/Page | Output Tokens/Page | Cost Per Page | Cost Per Million |
|---|---|---|---|---|
| GPT o3-mini | 750 | 500 | $0.0030 | $3,025 |
General Pricing Comparison
Firecrawl gives us the best rate per million pages. With Firecrawl, you get over triple the value of ScrapeGraphAI and almost 7 times the value of Skrape.ai. If you're looking to scrape at scale, the paid options don't just perform better, Firecrawl and ScrapeGraphAI actually cost less than the open source "free to use" models due to API cost.
| Tool | Cost Per Million Pages |
|---|---|
| Firecrawl | $666 |
| ScrapeGraphAI | $2,000 |
| Skrape.ai | $5,000 |
| Open Source | $3,025 |
The Contenders
Most of these tools actually have some variation of a Hacker News scraper either on their front page or in their documentation. Naturally, I used this as a simple test. Each tool needs to scrape the top 5 articles from Hacker News. I can use this process to clearly analyze each tool without testing on a mountain of data.
Open Source Options
-
LLM Scraper: A TypeScript library with local and API support for a variety of LLMs. Full Playwright support and code generation make it one of the most popular choices around.
-
Scrapy-LLM: Scrapy is one of the most powerful scraping tools around. With scalability and modularity in mind, this library brings the power of OpenAI models straight into your Scrapy project.
-
Crawl4AI: Crawl4AI openly boasts about being the best AI web scraping tool around. It's built on top of Playwright with performance in mind. Using Crawl4AI, you don't even need API access for AI powered scraping. Your model runs locally.
-
AutoScraper: Simplicity and speed are the key features here. Define a list of wanted items and then simply run the scraper on your target site. Like Crawl4AI, this library utilizes smaller, local models to save on compute cost and maximize efficiency.
Proprietary Options
-
Firecrawl: Our first enterprise grade tool on this list. Firecrawl offers an intuitive developer experience while keeping your boilerplate code at a minimum. They offer a free trial and their paid plans range from $16/month to $333/month. You can scrape up to 500,000 pages per month on their highest tier.
-
Skrape.ai: Similar to Firecrawl. They offer a variety of paid plans ranging from $15/month to $250/month. It also allows you to combine traditional methods with LLM powered parsing. These features make it a great tool for developers.
-
ScrapeGraphAI: The highest priced option on our list. ScrapeGraphAI allows the users to scrape the web using natural language. Talk to the machine, get your data and get on with the day.
We'll test all of these options and see if they truly deliver on these promises.
--
1. Firecrawl 10/10
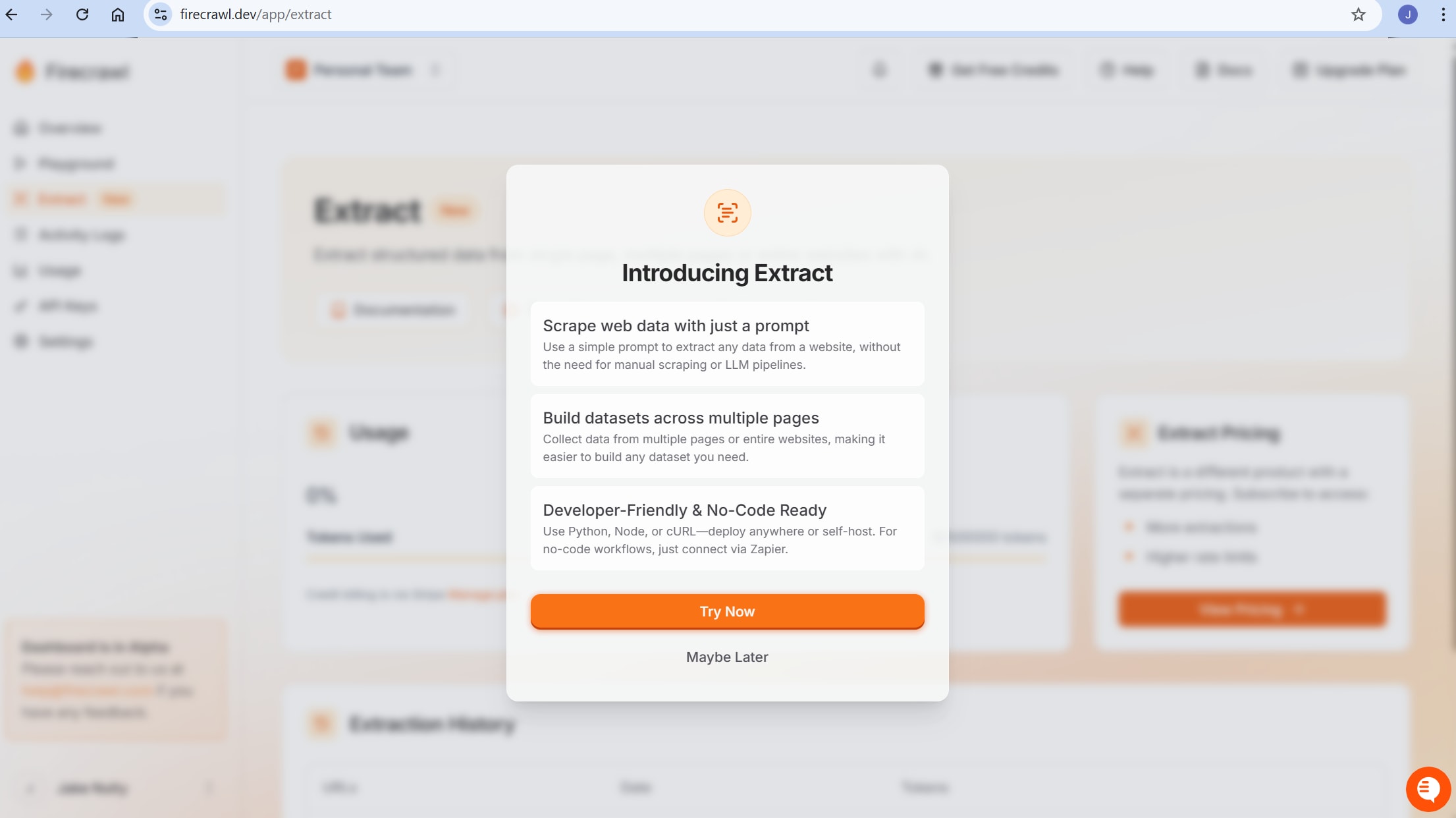
Firecrawl is the best tool you can get. It features an extract tool that allows you to input plain English and scrape your target. You write a simple prompt, hit "Run" and get your data--no coding required.
-
Installation: No installation necessary! Head over to their website and create an account. Once you've done this, you're all set to use their "Extract" tool.
-
Ease of Use: Usage couldn't possibly be easier. Write a prompt, and follow the on-screen instructions. Just click the "Run" button and wait for your data to appear. Here's our prompt:
Extract the top 5 articles with their title, link, points, author, and comments URL. -
Compatibility: Firecrawl is compatible with everything. To use "Extract", all you need is a web browser.
-
✅ HP Omibook X Windows 11 (arm64): COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
Scraper Quality: They extracted our top 5 articles in about a minute. The data was perfect. No complaints here.
Here's our data. It came out perfect in less than a minute. All previous examples in this article took 1-3 hours of tinkering.
[
{
"articles": [
{
"link": "https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world/",
"title": "Gemini Robotics brings AI into the physical world",
"author": "meetpateltech",
"points": 197,
"comments_url": "https://news.ycombinator.com/item?id=43344082"
},
{
"link": "https://duckdb.org/2025/03/12/duckdb-ui.html",
"title": "The DuckDB Local UI",
"author": "xnx",
"points": 381,
"comments_url": "https://news.ycombinator.com/item?id=43342712"
},
{
"link": "https://twitter.com/benswerd/status/1899853533761200300",
"title": "Reverse Engineering OpenAI Code Execution to make it run C and JavaScript",
"author": "benswerd",
"points": 72,
"comments_url": "https://news.ycombinator.com/item?id=43344673"
},
{
"link": "https://wulinshu.com/2025/03/11/reverse-engineering-adventures-3-bug-or-not-bug/",
"title": "Shenmue (1999) Reverse Engineering Reveals Possible Sun Position Oversight",
"author": "BafS",
"points": 20,
"comments_url": "https://news.ycombinator.com/item?id=43345285"
},
{
"link": "https://sugaku.net/content/understanding-the-cultural-divide-between-mathematics-and-ai/",
"title": "The Cultural Divide Between Mathematics and AI",
"author": "rfurmani",
"points": 41,
"comments_url": "https://news.ycombinator.com/item?id=43344703"
}
]
}
]
Firecrawl is undoubtedly the best tool we tested. Built to scale with decent pricing, Firecrawl can fulfill most of your scraping needs right now.
Pricing
| Plan | Monthly Cost | Pages | Cost per Million |
|---|---|---|---|
| Free | $0 | 500 | $0 |
| Hobby | $16 | 3,000 | $5,333.33 |
| Standard | $83 | 100,000 | $830 |
| Growth | $333 | 500,000 | $666 |
- ✅ No installation required
- ✅ Write a prompt in plain English
- ✅ Free and paid plans available
- ✅ On-screen instructions are the best documentation so far
- ✅ Compatible with any web browser
- ✅ Extracted data comes perfectly structured, clean and ready to use
--
2. ScrapeGraphAI 10/10
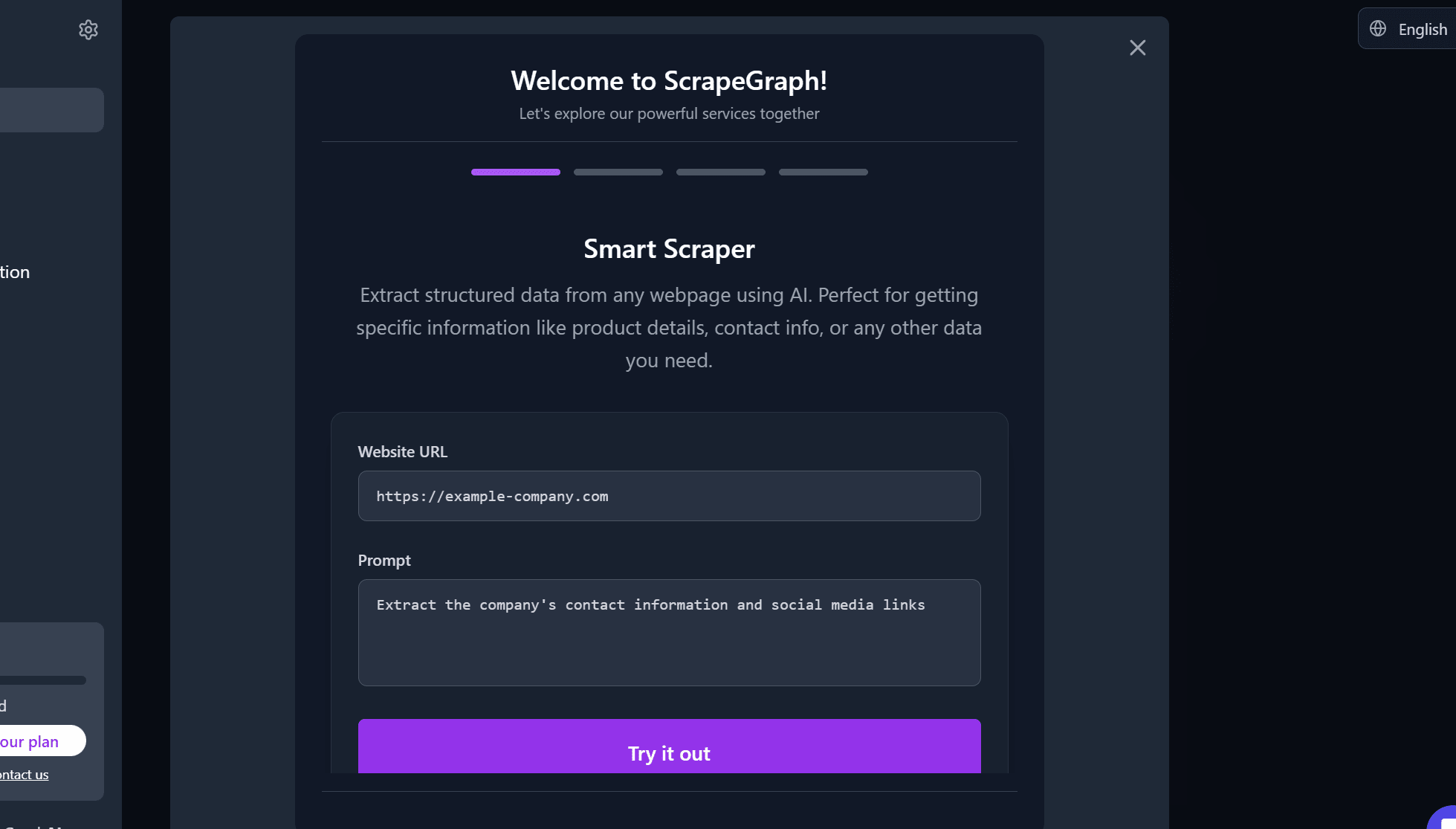
ScrapeGraphAI is just as powerful as Firecrawl. Like Firecrawl, it's proprietary but comes with a free trial and a variety of paid plans. As you can see in the image above, you just need a url and a prompt.
-
Installation: No installation required. Just create an account, follow their tutorial and you're ready to go.
-
Ease of Use: Usage is 100% on par with Firecrawl. Write a prompt, hit a button. Get your data. We actually reused the prompt we used with Firecrawl.
-
Compatibility: All modern web browsers. If you've got a web browser, you're good to go.
-
✅ HP Omibook X Windows 11 (arm64): COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
Scraper Quality: The data was once again perfect. The LLM pulled the top articles and extracted the metadata we wanted. I couldn't ask for more.
Here's the data. No fuss, no hours of setup. Just write your prompt and go.
{
"articles": [
{
"title": "Gemini Robotics brings AI into the physical world",
"link": "https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world/",
"points": 263,
"author": "meetpateltech",
"comments_url": "https://news.ycombinator.com/item?id=43344082"
},
{
"title": "The DuckDB Local UI",
"link": "https://duckdb.org/2025/03/12/duckdb-ui.html",
"points": 411,
"author": "xnx",
"comments_url": "https://news.ycombinator.com/item?id=43342712"
},
{
"title": "Reverse Engineering OpenAI Code Execution to make it run C and JavaScript",
"link": "https://twitter.com/benswerd/status/1899853533761200300",
"points": 86,
"author": "benswerd",
"comments_url": "https://news.ycombinator.com/item?id=43344673"
},
{
"title": "Shenmue (1999) Reverse Engineering Reveals Possible Sun Position Oversight",
"link": "https://wulinshu.com/2025/03/11/reverse-engineering-adventures-3-bug-or-not-bug/",
"points": 38,
"author": "BafS",
"comments_url": "https://news.ycombinator.com/item?id=43345285"
},
{
"title": "The Future Is Niri",
"link": "https://ersei.net/en/blog/niri",
"points": 215,
"author": "mattjhall",
"comments_url": "https://news.ycombinator.com/item?id=43342178"
}
]
}
ScrapeGraphAI is just as good as Firecrawl. Its higher prices are the only reason we ranked it at second. At scale, Firecrawl just offers more value.
Pricing
| Plan | Monthly Cost | Pages | Cost per Million |
|---|---|---|---|
| Free | $0 | 50 | $0 |
| Starter | $20 | 5,000 | $4,000 |
| Growth | $100 | 40,000 | $2,500 |
| Pro | $500 | 250,000 | $2,000 |
- ✅ No installation required
- ✅ Write a schema for your data and watch it work
- ✅ Free and paid plans available
- ✅ On-screen instructions are excellent
- ✅ Compatible with all web browsers
- ✅ Write a prompt and get your data.
- ❌ More expensive than Firecrawl at higher usage levels
--
3. Skrape.ai 9.5/10
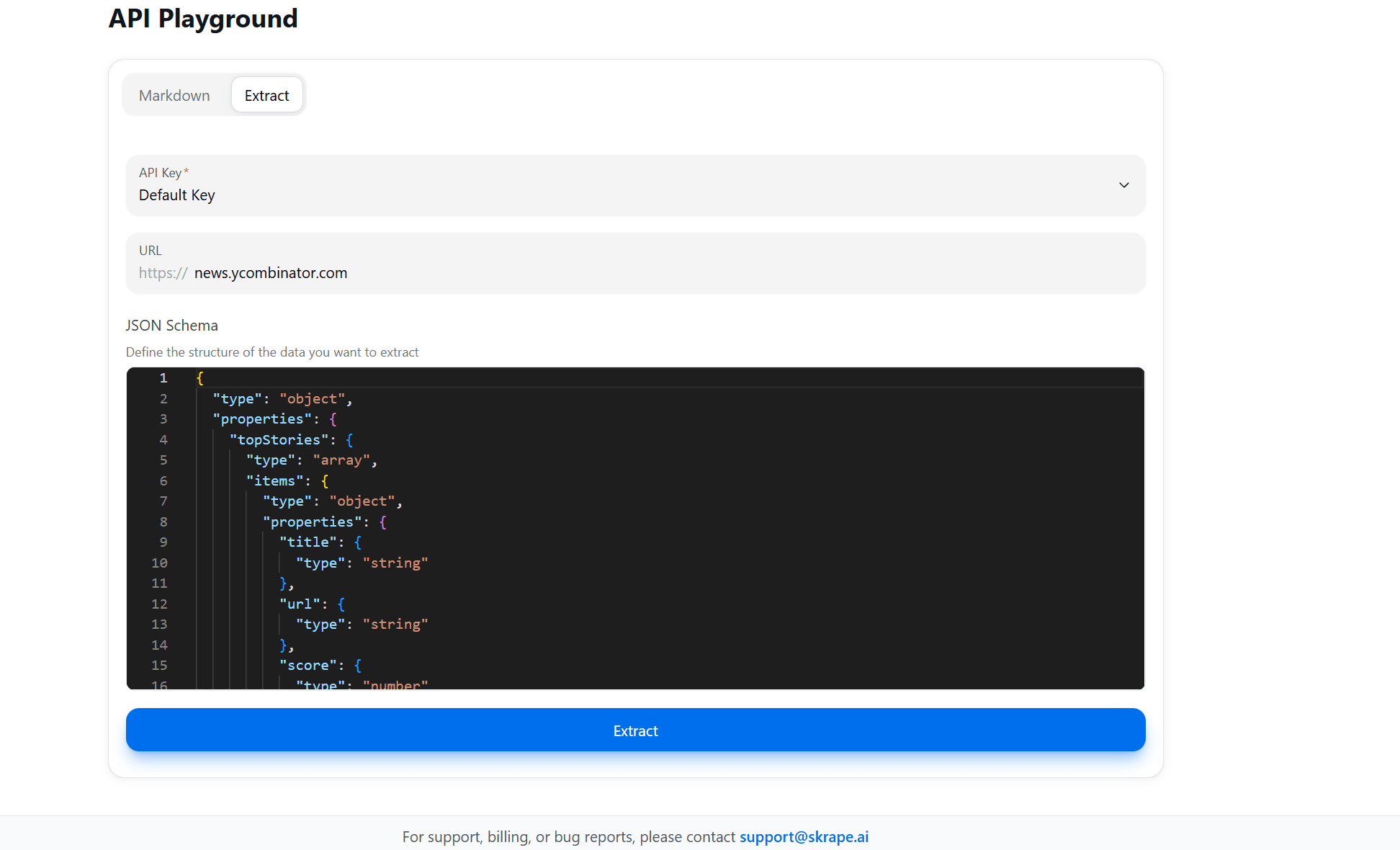
Skrape.ai is a major competitor to Firecrawl and ScrapeGraphAI. Instead of a genuine prompt, you set up your scrape from their playground. As you can see in the image above, you define the JSON schema that you'd like to extract from the page.
-
Installation: Once again, no installation necessary. All you need is an account and a browser.
-
Ease of Use: Usage is slightly more difficult than Firecrawl, but still great! Instead of writing a prompt, you create a pre-defined schema for the objects you'd like to scrape. Their LLM then goes through and scrapes the data.
-
Compatibility: Once again, this tool is compatible with everything. The only requirement is a web browser.
-
✅ HP Omibook X Windows 11 (arm64): COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
Scraper Quality: Our data came out with a slightly different, this is because I followed their pre-built schema. All in all, the data was excellent. This is a really good tool.
Here's our nearly perfect data. Like Firecrawl, it took under a minute to scrape.
{
"result": {
"topStories": [
{
"title": "Gemini Robotics brings AI into the physical world",
"url": "https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world/",
"score": 234,
"author": "meetpateltech",
"commentCount": 141
},
{
"title": "The DuckDB Local UI",
"url": "https://duckdb.org/2025/03/12/duckdb-ui.html",
"score": 402,
"author": "xnx",
"commentCount": 101
},
{
"title": "Reverse Engineering OpenAI Code Execution to make it run C and JavaScript",
"url": "https://twitter.com/benswerd/status/1899853533761200300",
"score": 81,
"author": "benswerd",
"commentCount": 29
},
{
"title": "Shenmue (1999) Reverse Engineering Reveals Possible Sun Position Oversight",
"url": "https://wulinshu.com/2025/03/11/reverse-engineering-adventures-3-bug-or-not-bug/",
"score": 30,
"author": "BafS",
"commentCount": 9
},
{
"title": "The Cultural Divide Between Mathematics and AI",
"url": "https://sugaku.net/content/understanding-the-cultural-divide-between-mathematics-and-ai/",
"score": 47,
"author": "rfurmani",
"commentCount": 26
}
]
},
"usage": {
"remaining": 50,
"rateLimit": {
"remaining": 4,
"baseLimit": 5,
"burstLimit": 5,
"reset": 1741803758175
}
}
}
Skrape.ai offers a viable alternative to Firecrawl and ScrapeGraphAI. It requires a little more setup, and its prices don't scale nearly as well, but this tool can still meet your scraping needs right now.
Pricing
| Plan | Monthly Cost | Pages | Cost per Million |
|---|---|---|---|
| Starter | $15 | 3,000 | $5,000 |
| Growth | $50 | 10,000 | $5,000 |
| Pro | $250 | 50,000 | $5,000 |
- ✅ No installation required
- ✅ Write a schema for your data and watch it work
- ✅ Free and paid plans available
- ✅ On-screen instructions
- ✅ Compatible with all web browsers
- ❌ You still need to plan out your schema. This increases your workload from nothing to almost nothing.
--
4. Crawl4AI 7/10--Best Open Source

Crawl4ai is easily best open source tool available. While limited to a Python environment, crawl4ai offers smaller local models for simple extraction and it also allows you to hook into paid LLMs through API integration. It's ready to compete with paid products yet, but it's got the bones. With a proper frontend, crawl4ai could one day offer top notch user experience like the tools above.
-
Installation: Installation was a cinch. Simple
pip install crawl4aiand runcrawl4ai-setup. This was extremely refreshing. It was finished in just a couple minutes and no time spent blindly troubleshooting. -
Ease of Use: It requires some limited knowledge of CSS or XPath Selectors but the tradeoff is well worth it. NO API KEYS REQUIRED! You pass in a schema and a light, local model finds the data for you.
-
Compatibility: Only compatible using WSL. Perhaps on an x86_64 machine, this would work, but we're in 2026 and arm chips aren't just the future--they're the present.
-
❌ HP Omibook X Windows 11 (arm64): NOT COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
Scraper Quality: With some basic scraping knowledge you can get the same quality data at zero cost. This is huge. You don't need a full power, all-knowing LLM to parse HTML data into JSON.
Our data's correct and the local model took less than a second to parse the JSON!
[
{
"title": "Happy 20th Birthday, Y Combinator",
"link": "https://twitter.com/garrytan/status/1899092996702048709",
"points": 1016,
"by": "btilly",
"commentsUrl": "https://news.ycombinator.com/item?id=43332658"
},
{
"title": "Show HN: VSC \u2013 An open source 3D Rendering Engine in C++",
"link": "https://github.com/WW92030-STORAGE/VSC",
"points": 21,
"by": "NormalExisting",
"commentsUrl": "https://news.ycombinator.com/item?id=43339584"
},
{
"title": "Beyond Diffusion: Inductive Moment Matching",
"link": "https://lumalabs.ai/news/inductive-moment-matching",
"points": 21,
"by": "outrun86",
"commentsUrl": "https://news.ycombinator.com/item?id=43339563"
},
{
"title": "Happy 10k Day",
"link": "https://blog.comma.ai/happy10kday/",
"points": 79,
"by": "LorenDB",
"commentsUrl": "https://news.ycombinator.com/item?id=43339158"
},
{
"title": "A look at the creative process behind Bluey and Cocomelon",
"link": "https://www.readtrung.com/p/why-i-love-bluey-and-hate-cocomelon",
"points": 48,
"by": "gmays",
"commentsUrl": "https://news.ycombinator.com/item?id=43339206"
}
]
crawl4ai represents the potential of open source tools in AI scraping. It's currently limited to Python, but it's got the right architecture--and an Apache license. With a day or two of software development, a fullstack developer could have an MVP up and running to compete with the paid options.
- ✅ Blazing-fast performance (sub-second parsing)
- ✅ Schema-based approach is flexible and powerful
- ✅ No API keys or paid plans needed
- ✅ Fantastic documentation
- ❌ Windows (arm64) compatibility is non-existent
- ❌ Requires some knowledge of CSS/XPath selectors
5. Scrapy-LLM 4/10--Best (and only) AI Tool For Scrapy
After a somewhat difficult setup (this is expected when working with Scrapy), Scrapy-LLM managed to scrape and parse the content well enough. Compatibility isn't just limited to Python, it's limited to Scrapy--a standalone Python framework. It seems over-engineered from the start--why was this thing even built?
-
Installation: The installation here was rough, but not unexpected. Scrapy is its own beast. On Windows (arm64), I kept receiving an obscure subprocess error that didn't really say much of anything. After a full hour of playing Russian roulette with dependencies, I gave up. With WSL, I was able to install it without too much headache.
-
Ease of Use: Scrapy-LLM's documentation isn't much better but you can piece it together if you know Scrapy. Scrapy-LLM's real failure comes from the actual performance. A single parse of the Hacker News Top 5 took almost 2 minutes. LLM-Scraper completed this part instantly.
-
Compatibility: This package is compatible using WSL. In all fairness, vanilla Scrapy on Windows game me the same subprocess error.
-
❌ HP Omibook X Windows 11 (arm64): NOT COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
Scraper Quality: The extracted data is what we'd expect from a high quality LLM. No complaints here.
Here's our output. It's correct, but it took way too long to produce.
[
{
"title": "Happy 20th Birthday, Y Combinator",
"points": 928,
"by": "btilly",
"commentsUrl": "https://news.ycombinator.com/item?id=1"
},
{
"title": "Fastplotlib: GPU-accelerated, fast, and interactive plotting library",
"points": 344,
"by": "rossant",
"commentsUrl": "https://news.ycombinator.com/item?id=2"
},
{
"title": "Sorting algorithms with CUDA",
"points": 38,
"by": "ashwani-rathee",
"commentsUrl": "https://news.ycombinator.com/item?id=3"
},
{
"title": "New tools for building agents",
"points": 273,
"by": "meetpateltech",
"commentsUrl": "https://news.ycombinator.com/item?id=4"
},
{
"title": "Show HN: Factorio Learning Environment – Agents Build Factories",
"points": 616,
"by": "noddybear",
"commentsUrl": "https://news.ycombinator.com/item?id=5"
}
]
Scrapy is an acquired taste and that severely limits the userbase here. Scrapy-LLM is the best and only AI tool for Scrapy. Documentation is a bit choppy, but if you're familiar with Scrapy, you can get it running. The parsing itself wasn't all that bad, but I'm continuing to wonder why it was even built in the first place. A general purpose LLM plugin is a better approach than locking into Scrapy. This is the software embodiment of a hipster--niche for no reason and temperamental toward its boss (you).
- ✅ Correct data extraction
- ✅ Works (if you use WSL).
- ❌ Niche for the sake of being niche.
- ❌ No Windows compatibility
- ❌ Documentation is choppy.
- ❌ Performance is painfully slow.
--
6. LLM-Scraper 3/10--Best For Masochists
This package is a lesson in frustration. Our simple Hacker News test took hours from my life that I will never get back. It's built from pieces that all run natively on Windows arm64. However, this package completely failed to run at all on Windows arm64. Using WSL and Ubuntu 24.04 on the same machine, I was able to get it running with some minor tweaks. To double-check and make sure I wasn't crazy, I tested it on my Ubuntu 22.04 x86_64 laptop. Even on the native laptop with legacy architecture, it required unexpected tweaks in order to run.
-
Installation: Pain is an understatement here. For starters, their documentation is weak and this package is completely incompatible with arm64 on Windows. However, with some dependency issues, it was installable in Ubuntu 24.04 WSL and Ubuntu 22.04 Native x86_64.
-
Ease of Use: By default, JavaScript programs use
CommonJSsyntax. Instead of following industry standards, their docs hold a single example script usingECMAScriptfor modules instead. You can fix this by changing yourpackage.jsonfile, but nowhere do they mention that. Whether it was an honest mistake, or intentionally left out, this is bad. -
Compatibility: This package depends on Playwright (fully compatible with Windows arm64) and some SDKs (basically just wrappers for HTTP requests). There should be no compatibility issues here whatsoever but somehow it still doesn't work.
-
❌ HP Omibook X Windows 11 (arm64): NOT COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
✅ Lenovo Ideapad 1i (x86_64 Ubuntu 22.04 Native Desktop): COMPATIBLE
-
Scraper Quality: After the setup headache, we were able to get the package to run. Here is the output from the Hacker News test.
nultinator@LEELaptop:~/llm-scraper-tester$ node index.js
[
{
title: 'Show HN: Factorio Learning Environment – Agents Build Factories',
points: 376,
by: 'noddybear',
commentsURL: 'https://news.ycombinator.com/item?id=43331582'
},
{
title: 'Fastplotlib: Driving scientific discovery through data visualization',
points: 12,
by: 'rossant',
commentsURL: 'https://news.ycombinator.com/item?id=43334190'
},
{
title: "Mapping the University of Chicago's 135-Year Expansion into Hyde Park and Beyond",
points: 113,
by: 'speckx',
commentsURL: 'https://news.ycombinator.com/item?id=43332424'
},
{
title: 'A 10x Faster TypeScript',
points: 593,
by: 'DanRosenwasser',
commentsURL: 'https://news.ycombinator.com/item?id=43332830'
},
{
title: 'NIST Selects HQC as Fifth Algorithm for Post-Quantum Encryption',
points: 42,
by: 'gnabgib',
commentsURL: 'https://news.ycombinator.com/item?id=43332944'
}
]
nultinator@LEELaptop:~/llm-scraper-tester$
This package is the dysfunctional child of Playwright and OpenAI's API. It's built from pieces that run on Windows arm64, but somehow, it still fails to work. Their documentation (or lack thereof) leaves new users completely clueless as to why the package won't work.
- ✅ Works with multiple LLMs (after fixing it yourself)
- ✅ Scraping quality is solid (if you ever get it running)
- ⚠️ Kind of Works (if you use WSL and know how to edit NodeJS settings).
- ❌ Windows compatibility is a disaster.
- ❌ Documentation is incomplete and painfully slow.
- ❌ Performance is painfully slow.
--
7. AutoScraper 1/10--Best For Inspiring You To Use a Different Package
AutoScraper sounded very promising. Like crawl4ai, it includes a local model for parsing. Unlike other libraries, you train the model yourself by hardcoding your training data directly into your Python script. This new architecture had me pretty excited.
-
Installation:
pip install autoscraperand you're good to go. No additional setup command, tweaking environment settings or Scrapy settings. Clean, clear, and easy to understand. -
Ease of Use: AutoScraper is easy to run, but the results are less than stellar. You'll learn more soon.
-
Compatibility: Still only compatible with WSL. Maybe we'll find our unicorn soon!
-
❌ HP Omibook X Windows 11 (arm64): NOT COMPATIBLE
-
✅ HP Omibook X Windows 11 (arm64 Ubuntu 24.04 WSL): COMPATIBLE
-
Scraper Quality: I ran our Hacker News test and received zero results. To double check my usage, I ran their copy/paste examples from their docs and also received zero results.
Here's our empty data. This occurred on every attempt, no matter the site.
[]
I absolutely love the idea behind AutoScraper and I was legitimately excited to try it. I hope that I can one day write a better review of this tool because the concept is perfect--efficient model that does only what it's supposed to do. This could really uncomplicate the AI powered parsing process. Hopefully they can address whatever is wrong and I can try it on a day when it's working.
- ✅ Easy installation
- ✅ Pass training data straight into your code
- ✅ No API keys or paid plans needed
- ❌ Results in documentation differ from real life
- ❌ Windows (arm64) compatibility is non-existent
- ❌ Fails to find any data at all
--
Winners
Best Open Source
crawl4ai was leaps and bounds ahead of all the other open source tools. Their documentation was nearly perfect. They offer tools to integrate with a local model (like we used) or to plug into an LLM when required.
This tool has a very bright future and as AI evolves, so will crawl4ai. It's not a drop-in replacement for the proprietary AI scrapers, but this is the only open source tool I would even bother recommending. In time, I strongly expect crawl4ai to eat up more of the developer market. If they build a frontend with Electron (or something similar), they could even compete with the proprietary market.
Best Proprietary
Our best proprietary tool goes to Firecrawl. ScrapeGraphAI tied with a 10/10 but the pricing plans were our tiebreaker. Firecrawl offers a better free trial and their paid plans cover up to 500,000 pages at the top tier ($333/month) vs 250,000 pages from ScrapeGraphAI ($500/month).
Firecrawl is our winner today, but as these companies continue their price discovery phase, I would expect Skrape.ai and ScrapeGraphAI to offer more competitive plans and I think we'll also see a swath of new competitors in 2025 and 2026.
Best Overall
Firecrawl hands down. The proprietary tools are lightyears ahead of the open source ones right now. All the proprietary tools are in a completely different class than the open source ones.
--
Conclusion
AI web scraping has come a very long way. That being said, most of the open source tools flat out suck. The purpose of AI scraping is to eliminate the need to code. As a professional in web scraping and data extraction, I can honestly say that *almost all of the open source tools are a complete waste of time and effort. crawl4ai has shown some promise, but it still won't replace Requests and BeautifulSoup or Playwright.
When Should You Use AI Scraping Tools?
AI web scraping tools are supposed replace code in our scrapers. If you don't want to code, use Firecrawl, Skrape.ai, or ScrapeGraphAI. These three tools are excellent and they will eliminate your need to code today.
Open source scraping tools are pretty much a joke. crawl4ai is the only open source tool I would even consider using at this point. It's still a work in progress, but it shows real promise.
If you're not a developer, proprietary AI scraping tools will get the job done right now--as is.
When Shouldn't You Use AI Scraping Tools?
If you already know how to scrape, and don't want to pay the hefty price tag, don't use the proprietary tools. They might eliminate the need to write your scraper, but they make you dependent on them.
As far as the open source tools go, use them never! Not only do you still have to code, you need to spend valuable time doing extra setup and writing boilerplate to pass into an LLM. I strongly support the open source movement and almost all my software is open source, but open source AI scrapers absolutely suck. They are overcomplicated HTTP wrappers and you probably can't convince me otherwise.
If you know how to code, you're better off scraping the web on your own. The paid tools are amazing, but you can do it yourself for zero cost and full control of your data.
We Want Your Opinion
Have you used an AI related scraping tool? Tell us about it. Are there any good ones we didn't cover? Was I too mean to the open source community? Tell me!