Web Scraping Part 5 - Using Fake User-Agents and Browser Headers
Modern websites don’t just check what you request - they scrutinize who’s asking. After scaling your scraper with retries and concurrency in Part 4, the next roadblock you’ll hit is aggressive bot‑detection based on HTTP fingerprints. User‑agents and browser headers are the two biggest tells: if they look synthetic or repetitive, your requests go straight to the ban list.
In Part 5 you’ll learn how to cloak your scraper so it blends in with ordinary traffic. We’ll cover why sites flag default headers, how to rotate realistic user‑agents, and how to send complete browser‑header sets that pass heuristic checks. By the end, you’ll know exactly how to make every request look like it came from a real person - laying the groundwork for the proxy strategies we tackle in Part 6.
- Python Requests + BeautifulSoup
- Node.js Axios + Cheerio
- Node.js Puppeteer
- Node.js Playwright

Python Requests/BS4 Beginners Series Part 5: Using Fake User-Agents and Browser Headers
So far in this Python Requests/BeautifulSoup 6-Part Beginner Series, we have learned how to build a basic web scraper Part 1, scrape data from a website in Part 2, clean it up, save it to a file or database in Part 3, and make our scraper more robust and scalable by handling failed requests and using concurrency in Part 4.
In Part 5, we’ll explore how to use fake user-agents and browser headers to bypass restrictions on sites trying to prevent scraping.
- Getting Blocked and Banned While Web Scraping
- Using Fake User-Agents When Scraping
- Using Fake Browser Headers When Scraping
- Next Steps
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Python Requests/BeautifulSoup 6-Part Beginner Series
-
Part 1: Basic Python Requests/BeautifulSoup Scraper - We'll go over the basics of scraping with Python, and build our first Python scraper. (Part 1)
-
Part 2: Cleaning Dirty Data & Dealing With Edge Cases - Web data can be messy, unstructured, and have lots of edge cases. In this tutorial we'll make our scraper robust to these edge cases, using data classes and data cleaning pipelines. (Part 2)
-
Part 3: Storing Data in AWS S3, MySQL & Postgres DBs - There are many different ways we can store the data that we scrape from databases, CSV files to JSON format, and S3 buckets. We'll explore several different ways we can store the data and talk about their pros, and cons and in which situations you would use them. (Part 3)
-
Part 4: Managing Retries & Concurrency - Make our scraper more robust and scalable by handling failed requests and using concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Make our scraper production ready by using fake user agents & browser headers to make our scrapers look more like real users. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Explore how to use proxies to bypass anti-bot systems by hiding your real IP address and location. (Part 6)
The code for this project is available on GitHub.
Getting Blocked and Banned While Web Scraping
When you start scraping large volumes of data, you'll find that building and running scrapers is easy. The true difficulty lies in reliably retrieving HTML responses from the pages you want. While scraping a couple hundred pages with your local machine is easy, websites will quickly block your requests when you need to scrape thousands or millions.
Large websites like Amazon monitor visitors by tracking IP addresses and user-agents, detecting unusual behavior with sophisticated anti-bot measures. If you identify as a scraper, your request will be blocked.
However, by properly managing user-agents and browser headers during scraping, you can counter these anti-bot techniques. While these advanced techniques would be optional for our beginner project on scraping chocolate.co.uk.
In this guide, we're still going to look at how to use fake user-agents and browser headers so that you can apply these techniques if you ever need to scrape a more difficult website like Amazon.
Using Fake User-Agents When Scraping
One of the most common reasons for getting blocked while web scraping is using bad User-Agent headers. When scraping data from websites, the site often doesn't want you to extract their information, so you need to appear like a legitimate user.
To do this, you must manage the User-Agent headers you send along with your HTTP requests.
What are User-Agents
User-Agent (UA) is a string sent by the user's web browser to a server. It's located in the HTTP header and helps websites identify the following information about the user sending a request:
- Operating system: The user's operating system (e.g., Windows, macOS, Linux, Android,� iOS)
- Browser: The specific browser being used (e.g., Chrome, Firefox, Safari, Edge)
- Browser version: The version of the browser
Here's an example of a user-agent string that might be sent when you visit a website using Chrome:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36
The user-agent string indicates that you are using Chrome version 109.0.0.0 on a 64-bit Windows 10 computer.
- The browser is Chrome
- The version of Chrome is 109.0.0.0
- The operating system is Windows 10
- The device is a 64-bit computer
Note that using an incorrectly formed user-agent can lead to your data extraction script being blocked. Most web browsers tend to follow the below format:
Mozilla/5.0 (<system-information>) <platform> (<platform-details>) <extensions>
Check our Python Requests: Setting Fake User-Agents to get more information about using Fake-User Agents in Python Requests.
Why Use Fake User-Agents in Web Scraping
To avoid detection during web scraping, you can use a fake user-agent to mimic a real user's browser. This replaces your default user-agent, making your scraper appear legitimate and reducing the risk of being blocked as a bot.
You must set a unique user-agent for each request. Websites can detect repeated requests from the same user-agent and identify them as potential bots.
With most Python HTTP clients like Requests, the default user-agent string reveals that your request is coming from Python. To bypass this, you can manually set a different user-agent before sending each request.
'User-Agent': 'python-requests/2.31.0'
This user-agent will identify your requests are being made by the Python Requests library, so the website can easily block you from scraping the site. Therefore, it's crucial to manage your user-agents when sending requests with Python Requests.
How to Set a Fake User-Agent in Python Requests
Using Python Requests, setting a fake user-agent is straightforward. Define your desired user-agent string in a dictionary, then pass this dictionary to the headers parameter of your request.
import requests
head = {
"User-Agent": "Mozilla/5.0 (iPad; CPU OS 12_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148"}
r = requests.get('http://httpbin.org/headers', headers=head)
print(r.json())
Here’s the result:

You can see that the user-agent we provided is included in the response and its value is reflected as the answer to our request.
How to Rotate User-Agents
You can easily rotate user-agents by including a list of user-agents in your scraper and randomly selecting one for each request.
import requests
import random
user_agent_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
]
head = {
"User-Agent": user_agent_list[random.randint(0, len(user_agent_list)-1)]}
r = requests.get('http://httpbin.org/headers', headers=head)
print(r.json())
Each request has a unique user-agent, ensuring the random selection of user-agents. Here’s the result:

How to Create a Custom Fake User-Agent Middleware
Let's see how to create fake user-agent middleware that can effectively manage thousands of fake user-agents. This middleware can then be seamlessly integrated into your final scraper code.
The optimal approach is to use a free user-agent API, such as the ScrapeOps Fake User-Agent API. This API enables you to use a current and comprehensive user-agent list when your scraper starts up and then pick a random user-agent for each request.
To use the ScrapeOps Fake User-Agents API, you simply need to send a request to the API endpoint to fetch a list of user-agents.
http://headers.scrapeops.io/v1/user-agents?api_key=YOUR_API_KEY
To use the ScrapeOps Fake User-Agent API, you first need an API key which you can get by signing up for a free account here.
Here’s a response from the API that shows an up-to-date list of user-agents that you can use for each request.
{
"result": [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36"
]
}
To integrate the Fake User-Agent API, you should configure your scraper to retrieve a batch of the most up-to-date user-agents from the ScrapeOps Fake User-Agent API when the scraper starts. Then, configure your scraper to pick a random user-agent from this list for each request.
Now, what if the retrieved list of user-agents from the ScrapeOps Fake User-Agent API is empty? In such cases, you can use the fallback user-agent list, which we will define in a separate method.
Here’s the step-by-step explanation of building custom user-agent middleware:
Create a UserAgentMiddleware instance with a ScrapeOps API key and the number of user-agents to fetch. Then, create a dictionary with the User-Agent set to a random user-agent by calling the get_random_user_agent method. Finally, send an HTTP GET request to the URL using the headers containing the random user-agent.
# Get Fake User-Agents
user_agent_middleware = UserAgentMiddleware(
scrapeops_api_key='YOUR_API_KEY', num_user_agents=20)
head = {'User-Agent': user_agent_middleware.get_random_user_agent()}
# Make Request
response = requests.get(
'https://www.chocolate.co.uk/collections/all', headers=head)
Let's explore the UserAgentMiddleware class and its important methods. The class constructor (__init__) initializes instance variables (user_agent_list, scrapeops_api_key) and calls the get_user_agents method to fetch user-agent strings.
class UserAgentMiddleware:
def __init__(self, scrapeops_api_key='', num_user_agents=10):
self.user_agent_list = []
self.scrapeops_api_key = scrapeops_api_key
self.get_user_agents(num_user_agents)
Now, the get_user_agents() method takes only the number of user-agents to fetch. First, it requests the ScrapeOps API to get the specified number of user-agents. If the response status code is 200, it parses the JSON response and extracts the user-agents.
If the list is empty or the status code is not 200, it prints a warning and uses a fallback user-agent list by calling the use_fallback_user_agent_list() method. The fallback user-agent list is a predefined list of user-agents to be used in case of API failure.
# This method is a part of the UserAgentMiddleware class.
def get_user_agents(self, num_user_agents):
response = requests.get('http://headers.scrapeops.io/v1/user-agents?api_key=' +
self.scrapeops_api_key + '&num_results=' + str(num_user_agents))
if response.status_code == 200:
json_response = response.json()
self.user_agent_list = json_response.get('result', [])
if len(self.user_agent_list) == 0:
print('WARNING: ScrapeOps user-agent list is empty.')
self.user_agent_list = self.use_fallback_user_agent_list()
else:
print(
f'WARNING: ScrapeOps Status Code is {response.status_code}, error message is:', response.text)
self.user_agent_list = self.use_fallback_user_agent_list()
The use_fallback_user_agent_list() method returns a list of user-agents in case of an API failure.
# This method is a part of the UserAgentMiddleware class.
def use_fallback_user_agent_list(self):
print('WARNING: Using fallback user-agent list.')
return [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
]
Finally, we have defined a method that returns a random user-agent from the finalized list of user-agents. This list is prepared either by fetching user-agents from the ScrapeOps API or by calling the use_fallback_user_agent_list() method.
# This method is a part of the UserAgentMiddleware class.
def get_random_user_agent(self):
random_index = randint(0, len(self.user_agent_list) - 1)
return self.user_agent_list[random_index]
Here's the complete code for the User-Agent Middleware.
import requests
from random import randint
class UserAgentMiddleware:
def __init__(self, scrapeops_api_key='', num_user_agents=10):
self.user_agent_list = []
self.scrapeops_api_key = scrapeops_api_key
self.get_user_agents(num_user_agents)
def get_user_agents(self, num_user_agents):
response = requests.get('http://headers.scrapeops.io/v1/user-agents?api_key=' +
self.scrapeops_api_key + '&num_results=' + str(num_user_agents))
if response.status_code == 200:
json_response = response.json()
self.user_agent_list = json_response.get('result', [])
if len(self.user_agent_list) == 0:
print('WARNING: ScrapeOps user-agent list is empty.')
self.user_agent_list = self.use_fallback_user_agent_list()
else:
print(
f'WARNING: ScrapeOps Status Code is {response.status_code}, error message is:', response.text)
self.user_agent_list = self.use_fallback_user_agent_list()
def use_fallback_user_agent_list(self):
print('WARNING: Using fallback user-agent list.')
return [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
]
def get_random_user_agent(self):
random_index = randint(0, len(self.user_agent_list) - 1)
return self.user_agent_list[random_index]
# Get Fake User-Agents
user_agent_middleware = UserAgentMiddleware(
scrapeops_api_key='YOUR_API_KEY', num_user_agents=20)
head = {'User-Agent': user_agent_middleware.get_random_user_agent()}
# Make Request
response = requests.get(
'https://www.chocolate.co.uk/collections/all', headers=head)
print(user_agent_middleware.get_random_user_agent())
print(user_agent_middleware.get_random_user_agent())
print(user_agent_middleware.get_random_user_agent())
Here’s the result:

When you call the get_random_user_agent method, it returns different user agents without any additional messages. This indicates that these user agents are successfully fetched directly from the ScrapeOps Fake User-Agent API.
Integrating User-Agent Middleware in a Scraper
Integration of user agent middleware into our scraper is very easy. You just need to make some minor changes while making requests to the URL in the retry logic.
Here's the code for the retry logic, which was already discussed in Part 4 of this series.
class RetryLogic:
def __init__(self, retry_limit=5, anti_bot_check=False, use_fake_user_agents=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
self.use_fake_user_agents = use_fake_user_agents
def make_request(self, url, method='GET', **kwargs):
kwargs.setdefault('allow_redirects', True)
## Use Fake User-Agents
head = kwargs.get('headers', {})
if self.use_fake_user_agents:
head['User-Agent'] = user_agent_middleware.get_random_user_agent()
## Retry Logic
for _ in range(self.retry_limit):
try:
response = requests.request(method, url, headers=head, **kwargs)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print('Error', e)
return False, None
def passed_anti_bot_check(self, response):
## Example Anti-Bot Check
if '<title>Robot or human?</title>' in response.text:
return False
## Passed All Tests
return True
Now, let's highlight the additions to this class:
use_fake_user_agentsParameter: We've added an extra parameter,use_fake_user_agents. When set toTrue, it modifies the request headers to include a randomly chosen user agent.- Modified
make_requestMethod: In themake_requestmethod, for every request, the new user agent is set by calling theget_random_user_agent()method.
Here's the complete code after integrating user-agent middleware into our scraper.
import os
import time
import csv
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass, field, fields, InitVar, asdict
import concurrent.futures
from random import randint
@dataclass
class Product:
name: str = ''
price_string: InitVar[str] = ''
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ''
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == '':
return 'missing'
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace('Sale price£', '')
price_string = price_string.replace('Sale priceFrom £', '')
if price_string == '':
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == '':
return 'missing'
return 'https://www.chocolate.co.uk' + self.url
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = os.path.isfile(
self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode='a', newline='', encoding='utf-8') as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get('name', ''),
price_string=scraped_data.get('price', ''),
url=scraped_data.get('url', '')
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
class RetryLogic:
def __init__(self, retry_limit=5, anti_bot_check=False, use_fake_user_agents=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
self.use_fake_user_agents = use_fake_user_agents
def make_request(self, url, method='GET', **kwargs):
kwargs.setdefault('allow_redirects', True)
# Use Fake User-Agents
head = kwargs.get('headers', {})
if self.use_fake_user_agents:
head['User-Agent'] = user_agent_middleware.get_random_user_agent()
# Retry Logic
for _ in range(self.retry_limit):
try:
response = requests.request(
method, url, headers=head, **kwargs)
print(response)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print('Error', e)
return False, None
def passed_anti_bot_check(self, response):
# Example Anti-Bot Check
if '<title>Robot or human?</title>' in response.text:
return False
# Passed All Tests
return True
class UserAgentMiddleware:
def __init__(self, scrapeops_api_key='', num_user_agents=10):
self.user_agent_list = []
self.scrapeops_api_key = scrapeops_api_key
self.get_user_agents(num_user_agents)
def get_user_agents(self, num_user_agents):
response = requests.get('http://headers.scrapeops.io/v1/user-agents?api_key=' +
self.scrapeops_api_key + '&num_results=' + str(num_user_agents))
if response.status_code == 200:
json_response = response.json()
self.user_agent_list = json_response.get('result', [])
if len(self.user_agent_list) == 0:
print('WARNING: ScrapeOps user-agent list is empty.')
self.user_agent_list = self.use_fallback_user_agent_list()
else:
print(
f'WARNING: ScrapeOps Status Code is {response.status_code}, error message is:', response.text)
self.user_agent_list = self.use_fallback_user_agent_list()
def use_fallback_user_agent_list(self):
print('WARNING: Using fallback user-agent list.')
return [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
]
def get_random_user_agent(self):
random_index = randint(0, len(self.user_agent_list) - 1)
return self.user_agent_list[random_index]
def scrape_page(url):
list_of_urls.remove(url)
valid, response = retry_request.make_request(url)
if valid and response.status_code == 200:
# Parse Data
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('product-item')
for product in products:
name = product.select('a.product-item-meta__title')[0].get_text()
price = product.select('span.price')[
0].get_text().replace('\nSale price£', '')
url = product.select('div.product-item-meta a')[0]['href']
# Add To Data Pipeline
data_pipeline.add_product({
'name': name,
'price': price,
'url': url
})
# Next Page
next_page = soup.select('a[rel="next"]')
if len(next_page) > 0:
list_of_urls.append(
'https://www.chocolate.co.uk' + next_page[0]['href'])
# Scraping Function
def start_concurrent_scrape(num_threads=5):
while len(list_of_urls) > 0:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(scrape_page, list_of_urls)
list_of_urls = [
'https://www.chocolate.co.uk/collections/all',
]
if __name__ == "__main__":
data_pipeline = ProductDataPipeline(csv_filename='product_data.csv')
user_agent_middleware = UserAgentMiddleware(
scrapeops_api_key='YOUR_API_KEY', num_user_agents=20)
retry_request = RetryLogic(
retry_limit=3, anti_bot_check=False, use_fake_user_agents=True)
start_concurrent_scrape(num_threads=10)
data_pipeline.close_pipeline()
Using Fake Browser Headers When Scraping
For simple websites, simply setting an up-to-date user-agent would allow you to scrape data reliably. However, many popular websites are increasingly using sophisticated anti-bot technologies to prevent data scraping. These solutions analyze not only your request's user-agent but also the other headers a real browser normally sends.
Why Choose Fake Browser Headers Instead of User-Agents
Using a full set of browser headers, not just a fake user-agent, makes your requests appear more like those of real users, making them harder to detect.
Here is an example header when using a Chrome browser on a MacOS machine:
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.83 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
As we can see, real browsers send not only User-Agent strings but also several other headers to identify and customize their requests. So, to improve the reliability of our scrapers, we should also include these headers when scraping.
How to Set Fake Browser Headers in Python Requests
Before setting fake browser headers, let's see what headers are sent by my Brave browser running on Windows 11.
import requests
response = requests.get('https://httpbin.org/headers')
print(response.json()['headers'])
Here’s the result:

My browser sends some other important information along with the user-agent. When scraping thousands of pages from a website with anti-bot features, this data can lead to detection and blocking. To avoid such obstacles, we'll explore the use of fake browser headers as a potential solution.
Setting fake browser headers is similar to setting user agents. Define your desired browser headers as key-value pairs in a dictionary, and then pass this dictionary to the headers parameter of your request.
import requests
import random
headers_list = [{
'authority': 'httpbin.org',
'cache-control': 'max-age=0',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'en-US,en;q=0.9',
}
]
head = random.choice(headers_list)
response = requests.get('https://httpbin.org/headers', headers=head)
print(response.json()['headers'])
We’re sending a request to httpbin.org with fake browser headers and retrieving the response. This is what we expect to see...

How to Create a Custom Fake Browser Agent Middleware
Creating custom fake browser agent middleware is very similar to creating custom fake user-agent middleware. You have two options: either build a list of fake browser headers manually or use the ScrapeOps Fake Browser Headers API to fetch an up-to-date list each time your scraper starts.
The ScrapeOps Fake Browser Headers API is a free API that returns a list of optimized fake browser headers, helping you evade blocks/bans and enhance the reliability of your web scrapers.
API Endpoint:
http://headers.scrapeops.io/v1/browser-headers?api_key=YOUR_API_KEY
Response:
{
"result": [
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7"
},
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Linux\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
]
}
To use the ScrapeOps Fake Browser Headers API, you first need an API key which you can get by signing up for a free account here.
To integrate the Fake Browser Headers API, you should configure your scraper to retrieve a batch of the most up-to-date headers upon startup. Then, configure it to pick a random header from this list for each request. Now, what if the retrieved list of headers from the ScrapeOps Fake Browser Headers API is empty? In such cases, you can use the fallback headers list.
The code closely resembles the user-agent middleware, with a few minor changes. The get_browser_headers() method sends a request to the ScrapeOps Fake Browser Headers API to retrieve browser headers. If the request is successful, it extracts the headers and stores them. If the request fails or in case of any error, it displays a warning message and uses a fallback headers list.
import requests
from random import randint
class BrowserHeadersMiddleware:
def __init__(self, scrapeops_api_key='', num_headers=10):
self.browser_headers_list = []
self.scrapeops_api_key = scrapeops_api_key
self.get_browser_headers(num_headers)
def get_browser_headers(self, num_headers):
response = requests.get('http://headers.scrapeops.io/v1/browser-headers?api_key=' +
self.scrapeops_api_key + '&num_results=' + str(num_headers))
if response.status_code == 200:
json_response = response.json()
self.browser_headers_list = json_response.get('result', [])
if len(self.browser_headers_list) == 0:
print('WARNING: ScrapeOps headers list is empty.')
self.browser_headers_list = self.use_fallback_headers_list()
else:
print(
f'WARNING: ScrapeOps Status Code is {response.status_code}, error message is:', response.text)
self.browser_headers_list = self.use_fallback_headers_list()
def use_fallback_headers_list(self):
print('WARNING: Using fallback headers list.')
return [
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7"
},
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Linux\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
]
def get_random_browser_headers(self):
random_index = randint(0, len(self.browser_headers_list) - 1)
return self.browser_headers_list[random_index]
browser_headers_middleware = BrowserHeadersMiddleware(
scrapeops_api_key='YOUR_API_KEY', num_headers=20)
headers = browser_headers_middleware.get_random_browser_headers()
# Make Request
response = requests.get(
'https://www.chocolate.co.uk/collections/all', headers=headers)
print(browser_headers_middleware.get_random_browser_headers())
print(browser_headers_middleware.get_random_browser_headers())
print(browser_headers_middleware.get_random_browser_headers())
Here’s the result:

When you call the get_browser_headers method, it returns different headers without any additional messages. This indicates that these headers are successfully fetched directly from the ScrapeOps Fake Browser Headers API.
Integrating Fake Browser Headers Middleware
Integration of fake browser middleware into our scraper is very easy. You just need to make some minor changes while making requests to the URL in the retry logic.
Here's the code for the retry logic, which was already discussed in Part 4 of this series
class RetryLogic:
def __init__(self, retry_limit=5, anti_bot_check=False, use_fake_browser_headers=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
self.use_fake_browser_headers = use_fake_browser_headers
def make_request(self, url, method='GET', **kwargs):
kwargs.setdefault('allow_redirects', True)
# Use Fake Browser Headers
headers = kwargs.get('headers', {})
if self.use_fake_browser_headers:
fake_browser_headers = browser_headers_middleware.get_random_browser_headers()
for key, value in fake_browser_headers.items():
headers[key] = value
# Retry Logic
for _ in range(self.retry_limit):
try:
response = requests.request(
method, url, headers=headers, **kwargs)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print('Error', e)
return False, None
def passed_anti_bot_check(self, response):
# Example Anti-Bot Check
if '<title>Robot or human?</title>' in response.text:
return False
# Passed All Tests
return True
Now, let's highlight the additions to this class:
use_fake_browser_headersParameter: When set toTrue, automatically modifies randomly chosen browser headers into the request headers.- Modified
make_requestMethod: For each request within this method, a random browser header is fetched using theget_random_browser_headersmethod. The generated fake browser headers typically contain multiple key-value pairs. So, iterate through each key-value pair within the browser headers and append the corresponding key-value pair to theheadersdictionary.
Here's the complete code after integrating browser headers middleware into our scraper.
import os
import time
import csv
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass, field, fields, InitVar, asdict
import concurrent.futures
from random import randint
@dataclass
class Product:
name: str = ''
price_string: InitVar[str] = ''
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ''
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == '':
return 'missing'
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace('Sale price£', '')
price_string = price_string.replace('Sale priceFrom £', '')
if price_string == '':
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == '':
return 'missing'
return 'https://www.chocolate.co.uk' + self.url
class ProductDataPipeline:
def __init__(self, csv_filename='', storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = os.path.isfile(
self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode='a', newline='', encoding='utf-8') as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get('name', ''),
price_string=scraped_data.get('price', ''),
url=scraped_data.get('url', '')
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
class RetryLogic:
def __init__(self, retry_limit=5, anti_bot_check=False, use_fake_browser_headers=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
self.use_fake_browser_headers = use_fake_browser_headers
def make_request(self, url, method='GET', **kwargs):
kwargs.setdefault('allow_redirects', True)
# Use Fake Browser Headers
headers = kwargs.get('headers', {})
if self.use_fake_browser_headers:
fake_browser_headers = browser_headers_middleware.get_random_browser_headers()
for key, value in fake_browser_headers.items():
headers[key] = value
# Retry Logic
for _ in range(self.retry_limit):
try:
response = requests.request(
method, url, headers=headers, **kwargs)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print('Error', e)
return False, None
def passed_anti_bot_check(self, response):
# Example Anti-Bot Check
if '<title>Robot or human?</title>' in response.text:
return False
# Passed All Tests
return True
class BrowserHeadersMiddleware:
def __init__(self, scrapeops_api_key='', num_headers=10):
self.browser_headers_list = []
self.scrapeops_api_key = scrapeops_api_key
self.get_browser_headers(num_headers)
def get_browser_headers(self, num_headers):
response = requests.get('http://headers.scrapeops.io/v1/browser-headers?api_key=' +
self.scrapeops_api_key + '&num_results=' + str(num_headers))
if response.status_code == 200:
json_response = response.json()
self.browser_headers_list = json_response.get('result', [])
if len(self.browser_headers_list) == 0:
print('WARNING: ScrapeOps headers list is empty.')
self.browser_headers_list = self.use_fallback_headers_list()
else:
print(
f'WARNING: ScrapeOps Status Code is {response.status_code}, error message is:', response.text)
self.browser_headers_list = self.use_fallback_headers_list()
def use_fallback_headers_list(self):
print('WARNING: Using fallback headers list.')
return [
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7"
},
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Linux\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
]
def get_random_browser_headers(self):
random_index = randint(0, len(self.browser_headers_list) - 1)
return self.browser_headers_list[random_index]
def scrape_page(url):
list_of_urls.remove(url)
valid, response = retry_request.make_request(url)
if valid and response.status_code == 200:
# Parse Data
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('product-item')
for product in products:
name = product.select('a.product-item-meta__title')[0].get_text()
price = product.select('span.price')[
0].get_text().replace('\nSale price£', '')
url = product.select('div.product-item-meta a')[0]['href']
# Add To Data Pipeline
data_pipeline.add_product({
'name': name,
'price': price,
'url': url
})
# Next Page
next_page = soup.select('a[rel="next"]')
if len(next_page) > 0:
list_of_urls.append(
'https://www.chocolate.co.uk' + next_page[0]['href'])
# Scraping Function
def start_concurrent_scrape(num_threads=5):
while len(list_of_urls) > 0:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(scrape_page, list_of_urls)
list_of_urls = [
'https://www.chocolate.co.uk/collections/all',
]
if __name__ == "__main__":
data_pipeline = ProductDataPipeline(csv_filename='product_data.csv')
browser_headers_middleware = BrowserHeadersMiddleware(
scrapeops_api_key='YOUR_API_KEY', num_headers=20)
retry_request = RetryLogic(
retry_limit=3, anti_bot_check=False, use_fake_browser_headers=True)
start_concurrent_scrape(num_threads=10)
data_pipeline.close_pipeline()

Node.js Axios/CheerioJS Beginners Series Part 5: Using Fake User-Agents and Browser Headers
So far in this Node.js Cheerio Beginners Series, we have learned how to build a basic web scraper in Part 1, scrape data from a website in Part 2, clean it up, save it to a file or database in Part 3, and make our scraper more robust and scalable by handling failed requests and using concurrency in Part 4.
In Part 5, we’ll explore how to use fake user-agents and browser headers to bypass restrictions on sites trying to prevent scraping.
- Getting Blocked and Banned While Web Scraping
- Using Fake User-Agents When Scraping
- Using Fake Browser Headers When Scraping
- Next Steps
Node.js Axios/CheerioJS 6-Part Beginner Series
This 6-part Node.js Axios/CheerioJS Beginner Series will walk you through building a web scraping project from scratch, covering everything from creating the scraper to deployment and scheduling.
- Part 1: Basic Node.js Cheerio Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
- Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
- Part 3: Storing Scraped Data - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
- Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
- Part 5: Mimicking User Behavior - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (This article)
- Part 6: Avoiding Detection with Proxies - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
The code for this project is available on Github.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Getting Blocked and Banned While Web Scraping
When you start scraping large volumes of data, you'll find that building and running scrapers is easy. The true difficulty lies in reliably retrieving HTML responses from the pages you want. While scraping a couple hundred pages with your local machine is easy, websites will quickly block your requests when you need to scrape thousands or millions.
Large websites like Amazon monitor visitors by tracking IP addresses and user-agents, detecting unusual behavior with sophisticated anti-bot measures. If you identify as a scraper, your request will be blocked.
However, by properly managing user-agents and browser headers during scraping, you can counter these anti-bot techniques. While these advanced techniques would be optional for our beginner project on scraping chocolate.co.uk.
In this guide, we're still going to look at how to use fake user-agents and browser headers so that you can apply these techniques if you ever need to scrape a more difficult website like Amazon.
Using Fake User-Agents When Scraping
One of the most common reasons for getting blocked while web scraping is using bad User-Agent headers. When scraping data from websites, the site often doesn't want you to extract their information, so you need to appear like a legitimate user.
To do this, you must manage the User-Agent headers you send along with your HTTP requests.
What are User-Agents
User-Agent (UA) is a string sent by the user's web browser to a server. It's located in the HTTP header and helps websites identify the following information about the user sending a request:
- Operating system: The user's operating system (e.g., Windows, macOS, Linux, Android, iOS)
- Browser: The specific browser being used (e.g., Chrome, Firefox, Safari, Edge)
- Browser version: The version of the browser
Here's an example of a user-agent string that might be sent when you visit a website using Chrome:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36
The user-agent string indicates that you are using Chrome version 109.0.0.0 on a 64-bit Windows 10 computer.
- The browser is Chrome
- The version of Chrome is 109.0.0.0
- The operating system is Windows 10
- The device is a 64-bit computer
Note that using an incorrectly formed user-agent can lead to your data extraction script being blocked. Most web browsers tend to follow the below format:
Mozilla/5.0 (<system-information>) <platform> (<platform-details>) <extensions>
Using Fake Browser Headers When Scraping
To avoid detection during web scraping, you can use a fake user-agent to mimic a real user's browser. This replaces your default user-agent, making your scraper appear legitimate and reducing the risk of being blocked as a bot.
You must set a unique user-agent for each request. Websites can detect repeated requests from the same user-agent and identify them as potential bots.
With most NodeJS HTTP clients, like Axios, the default user-agent string reveals that your string is coming from NodeJS. To hide this, you can manually set a different user agent before sending the request.
'User-Agent': 'axios/1.6.7'
This user-agent will identify your requests are being made by the NodeJS Axios library, so the website can easily block you from scraping the site. Therefore, it's crucial to manage your user-agents when sending requests with NodeJS Axios.
How to Set a Fake User-Agent in Node with Axios
For Axios, setting a fake user-agent is pretty simple. You can define the User-Agent header before the request like this:
const axios = require("axios");
const headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
};
axios.get("http://httpbin.org/headers", { headers }).then((response) => {
console.log(response.data);
});
Here's the result of that code:

You can see that the user-agent we provided is included in the response and its value is reflected as the answer to our request.
How to Rotate User-Agents
You can easily rotate user-agents by including a list of user-agents in your scraper and randomly selecting one for each request.
const axios = require("axios");
const userAgents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1",
"Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363",
];
const headers = {
"User-Agent": userAgents[Math.floor(Math.random() * userAgents.length)],
};
axios.get("http://httpbin.org/headers", { headers }).then((response) => {
console.log(response.data);
});
Each request has a unique user-agent, ensuring the random selection of user-agents. Here’s the results of running it twice:


How to Create a Custom Fake User-Agent Middleware
Let's see how to create fake user-agent middleware that can effectively manage thousands of fake user-agents. This middleware can then be seamlessly integrated into your final scraper code.
The optimal approach is to use a free user-agent API, such as the ScrapeOps Fake User-Agent API. This API enables you to use a current and comprehensive user-agent list when your scraper starts up and then pick a random user-agent for each request.
To use the ScrapeOps Fake User-Agents API, you simply need to send a request to the API endpoint to fetch a list of user-agents.
http://headers.scrapeops.io/v1/user-agents?api_key=YOUR_API_KEY
To use the ScrapeOps Fake User-Agent API, you first need an API key which you can get by signing up for a free account here
Here’s a response from the API that shows an up-to-date list of user-agents that you can use for each request.
{
"result": [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36"
]
}
To integrate the Fake User-Agent API, you should configure your scraper to retrieve a batch of the most up-to-date user-agents from the ScrapeOps Fake User-Agent API when the scraper starts. Then, configure your scraper to pick a random user-agent from this list for each request.
Now, what if the retrieved list of user-agents from the ScrapeOps Fake User-Agent API is empty? In such cases, you can use the fallback user-agent list, which we will define in a separate method.
Here’s the step-by-step explanation of building custom user-agent middleware:
Create your getHeaders method that contains your Scrape Ops API Key and fallback headers. We will also take in an argument numHeaders to specify the number of results we want from the API. If the list is empty or the status code is not 200, it prints a warning and uses the fall back headers we defined. Otherwise, we parse and return the API's response.
async function getHeaders(numHeaders) {
const fallbackHeaders = [
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
];
const scrapeOpsKey = "<YOUR_SCRAPE_OPS_KEY>";
try {
const response = await axios.get(
`http://headers.scrapeops.io/v1/user-agents?api_key=${scrapeOpsKey}&num_results=${numHeaders}`
);
if (response.data.result.length > 0) {
return response.data.result;
} else {
console.error("No headers from ScrapeOps, using fallback headers");
return fallbackHeaders;
}
} catch (error) {
console.error(
"Failed to fetch headers from ScrapeOps, using fallback headers"
);
return fallbackHeaders;
}
}
Now with that method added, we can call it during our scraper startup to fetch the user agents, then we can pass the user agents to subsequent calls to the scrape method where they can be used during the request. This is where we will add the randomization.
Using Math.random we can select a random index from the user-agent list and pass it to scrape to be used as header options:
if (isMainThread) {
// ...
} else {
// Perform work
const { startUrl } = workerData;
let headers = [];
const handleWork = async (workUrl) => {
if (headers.length == 0) {
headers = await getHeaders(2);
}
const { nextUrl, products } = await scrape(workUrl, {
"User-Agent": headers[Math.floor(Math.random() * headers.length)],
});
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
Integrating User-Agent Middleware in a Scraper
Integration of user agent middleware into our scraper is very easy. You just need to make some minor changes while making requests to the URL in the retry logic.
In Part 4 of the series, we made this makeRequest function that is responsible for the retry logic. We need to add an extra argument now to allow us to pass the random header to this function.
It should look something like this:
async function makeRequest(
url,
retries = 3,
antiBotCheck = false,
headers = {}
) {
for (let i = 0; i < retries; i++) {
try {
const response = await axios.get(url, {
headers: headers,
});
if ([200, 404].includes(response.status)) {
if (antiBotCheck && response.status == 200) {
if (response.data.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
You can see our function doesn't change much. We add the headers argument (which defaults to an empty object) and then we pass that argument onto the axios.get(...) call as the headers option.
Using Fake Browser Headers When Scraping
For simple websites, simply setting an up-to-date user-agent would allow you to scrape data reliably. However, many popular websites are increasingly using sophisticated anti-bot technologies to prevent data scraping.
These solutions analyze not only your request's user-agent but also the other headers a real browser normally sends.
Why Choose Fake Browser Headers Instead of User-Agents
Using a full set of browser headers, not just a fake user-agent, makes your requests appear more like those of real users, making them harder to detect.
Here is an example header when using a Chrome browser on a MacOS machine:
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.83 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
As we can see, real browsers send not only User-Agent strings but also several other headers to identify and customize their requests. So, to improve the reliability of our scrapers, we should also include these headers when scraping.
How to Set Fake Browser Headers in Node.js Axios
Before setting any fake headers, let's take a look at what is sent by default with Axios
axios.get("http://httpbin.org/headers").then((response) => {
console.log(response.data);
});
Returns:

As you can tell, we're missing a lot when comparing to the real browser output above. This lack of headers can lead to detection and request blocking when trying to scrape a large number of pages. To avoid that problem, we will show you how to use fake browser headers (which includes User Agents).
Setting fake browser headers is similar to setting user agents. Define your desired browser headers as key-value pairs in a dictionary, and then pass this dictionary to the headers parameter of your request.
const axios = require("axios");
const headers = {
authority: "httpbin.org",
"cache-control": "max-age=0",
"sec-ch-ua":
'"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
"sec-ch-ua-mobile": "?0",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-language": "en-US,en;q=0.9",
};
axios.get("http://httpbin.org/headers", { headers }).then((response) => {
console.log(response.data);
});
This sends a request to an httpbin.org endpoint. We should expect to see all our fake headers:

How to Create a Custom Fake Browser Agent Middleware
Creating custom fake browser agent middleware is very similar to creating custom fake user-agent middleware. You have two options: either build a list of fake browser headers manually or use the ScrapeOps Fake Browser Headers API to fetch an up-to-date list each time your scraper starts.
The ScrapeOps Fake Browser Headers API is a free API that returns a list of optimized fake browser headers, helping you evade blocks/bans and enhance the reliability of your web scrapers.
API Endpoint:
http://headers.scrapeops.io/v1/browser-headers?api_key=YOUR_API_KEY
Response:
{
"result": [
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7"
},
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Linux\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
]
}
To use the ScrapeOps Fake Browser Headers API, you first need an API key which you can get by signing up for a free account here.
- To integrate the Fake Browser Headers API, you should configure your scraper to retrieve a batch of the most up-to-date headers upon startup.
- Then, configure it to pick a random header from this list for each request.
Now, what if the retrieved list of headers from the ScrapeOps Fake Browser Headers API is empty? In such cases, you can use the fallback headers list.
The code closely resembles the user-agent middleware, with a few minor changes. The getHeaders method instead sends a request to the ScrapeOps Fake Browser Headers API rather than User Agents API. If the request is successful, it extracts the headers and stores them.
If the request fails or in case of any error, it displays a warning message and uses a fallback headers list.
Finally, our scrape call can now use the headers directly because we are no longer setting just the User Agent header.
const { nextUrl, products } = await scrape(
workUrl,
headers[Math.floor(Math.random() * headers.length)]
);
Here's the complete code that utilizes the browser headers API:
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
const {
Worker,
isMainThread,
parentPort,
workerData,
} = require("worker_threads");
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function getHeaders(numHeaders) {
const fallbackHeaders = [
{
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua":
'".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7",
},
{
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua":
'".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Linux"',
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7",
},
];
const scrapeOpsKey = "<YOUR_SCRAPE_OPS_KEY>";
try {
const response = await axios.get(
`http://headers.scrapeops.io/v1/browser-headers?api_key=${scrapeOpsKey}&num_results=${numHeaders}`
);
if (response.data.result.length > 0) {
return response.data.result;
} else {
console.error("No headers from ScrapeOps, using fallback headers");
return fallbackHeaders;
}
} catch (error) {
console.error(
"Failed to fetch headers from ScrapeOps, using fallback headers"
);
return fallbackHeaders;
}
}
async function makeRequest(
url,
retries = 3,
antiBotCheck = false,
headers = {}
) {
for (let i = 0; i < retries; i++) {
try {
const response = await axios.get(url, {
headers: headers,
});
if ([200, 404].includes(response.status)) {
if (antiBotCheck && response.status == 200) {
if (response.data.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
async function scrape(url, headers) {
const response = await makeRequest(url, 3, false, headers);
if (!response) {
throw new Error(`Failed to fetch ${url}`);
}
const html = response.data;
const $ = cheerio.load(html);
const productItems = $("product-item");
const products = [];
for (const productItem of productItems) {
const title = $(productItem).find(".product-item-meta__title").text();
const price = $(productItem).find(".price").first().text();
const url = $(productItem).find(".product-item-meta__title").attr("href");
products.push({ name: title, price: price, url: url });
}
const nextPage = $("a[rel='next']").attr("href");
return {
nextUrl: nextPage ? "https://www.chocolate.co.uk" + nextPage : null,
products: products,
};
}
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url },
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
// Perform work
const { startUrl } = workerData;
let headers = [];
const handleWork = async (workUrl) => {
if (headers.length == 0) {
headers = await getHeaders(2);
}
const { nextUrl, products } = await scrape(
workUrl,
headers[Math.floor(Math.random() * headers.length)]
);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}

NodeJS Puppeteer Beginners Series Part 5 - Faking User-Agents & Browser Headers
So far in this NodeJS Puppeteer 6-Part Beginner Series, we have learned how to build a basic web scraper Part 1, scrape data from a website in Part 2, clean it up, save it to a file or database in Part 3, and make our scraper more robust and scalable by handling failed requests and using concurrency in Part 4.
In Part 5, we’ll explore how to use fake user-agents and browser headers to bypass restrictions on sites trying to prevent scraping.
- Getting Blocked and Banned While Web Scraping
- Using Fake User-Agents When Scraping
- Using Fake Browser Headers When Scraping
- Creating Custom Middleware for User-Agents and Headers
- Integrating Middlewares in a Scraper
- Next Steps
Node.js Puppeteer 6-Part Beginner Series
-
Part 1: Basic Node.js Puppeteer Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using NpdeJS Puppeteer. (Part 1)
-
Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
-
Part 3: Storing Scraped Data in AWS S3, MySQL & Postgres DBs - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
-
Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (This article)
-
Part 6: Using Proxies To Avoid Getting Blocked - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Getting Blocked and Banned While Web Scraping
Web scraping large volumes of data can be challenging, especially when dealing with sophisticated anti-bot mechanisms. While it is easy to build and run scrapers, ensuring reliable retrieval of HTML responses from target pages is often difficult.
Websites like Amazon employ advanced techniques to detect and block scraping activities. This guide will show you how to use Puppeteer to mimic real browser interactions, thereby avoiding detection and blocks.
However, by properly managing user-agents and browser headers during scraping, you can counter these anti-bot techniques. While these advanced techniques would be optional for our beginner project on scraping chocolate.co.uk.
In this guide, we're still going to look at how to use fake user-agents and browser headers so that you can apply these techniques if you ever need to scrape a more difficult website like Amazon.
Using Fake User-Agents When Scraping
User-agents are pieces of information that your browser sends to a website, telling it what type of device and browser you're using. Many websites use this data to detect bots and block scraping attempts. To avoid this, you can rotate or fake user-agents to make your scraping activities look like they’re coming from different browsers or devices.
By simulating various user-agents, you can reduce the chances of being flagged as a bot and increase your scraping success on websites with anti-bot mechanisms.
What are User-Agents?
A user-agent is a string of text sent by your browser to a web server when you visit a website.
It's located in the HTTP header and contains details about your browser, operating system, and device, allowing the website to customize the content based on this information.
- Operating system: The user's operating system (e.g., Windows, macOS, Linux, Android, iOS)
- Browser: The specific browser being used (e.g., Chrome, Firefox, Safari, Edge)
- Browser version: The version of the browser
Here's an example of a user-agent string that might be sent when you visit a website using Chrome:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36
The user-agent string indicates that you are using Chrome version 109.0.0.0 on a 64-bit Windows 10 computer.
- The browser is Chrome
- The version of Chrome is 109.0.0.0
- The operating system is Windows 10
- The device is a 64-bit computer
Check our Puppeteer Guide: Using Fake User Agents to get more information about using Fake-User Agents in Python Requests.
Why Use Fake User-Agents in Web Scraping
Websites often use user-agents to identify the type of browser, device, or bot making a request. If a site detects that multiple requests are coming from a bot or the same user-agent, it may block or throttle the requests to prevent scraping.
Using fake or rotating user-agents helps overcome these blocks by mimicking different browsers and devices, making the scraper appear as legitimate traffic.
This technique improves the likelihood of bypassing anti-scraping measures, allowing scrapers to access and collect data from websites that might otherwise restrict or block their efforts.
How to Set a Fake User-Agent in NodeJS Puppeteer
Just like with other scraping tools, using appropriate user-agents is crucial. Puppeteer allows you to easily set and rotate user-agents to avoid detection.
To set a user-agent in Puppeteer, you can use the setUserAgent method:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
await page.goto('https://www.chocolate.co.uk');
const content = await page.content();
console.log(content);
await browser.close();
})();
How to Rotate User-Agents
You can rotate user-agents by creating a list of user-agents and selecting a random one for each request:
const puppeteer = require('puppeteer');
const userAgentList = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
];
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const randomUserAgent = userAgentList[Math.floor(Math.random() * userAgentList.length)];
await page.setUserAgent(randomUserAgent);
await page.goto('https://www.chocolate.co.uk');
const content = await page.content();
console.log(content);
await browser.close();
})();
Using Fake Browser Headers When Scraping
In addition to user-agents, setting other browser headers can make your scraping activities appear more legitimate.
Browser headers are key pieces of information that your browser sends to a website with each request. They include details like the user-agent, cookies, referrer, and accepted content types, helping the server understand the request and respond appropriately. Some websites use these headers to detect bots or scraping activity.
By faking or customizing browser headers, scrapers can disguise their requests to look like they’re coming from a regular user, not a bot. This helps avoid detection and allows scrapers to bypass security measures that block automated requests, improving the success of your web scraping.
Why Choose Fake Browser Headers Instead of User-Agents
While user-agents help disguise the type of browser and device making a request, websites often look at more than just the user-agent string to detect bots. Fake browser headers offer a broader and more convincing disguise by imitating a real browser's full request, including additional information like cookies, referrers, and accepted content types.
Here is an example header when using a Chrome browser on a MacOS machine:
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.83 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
As we can see, real browsers send not only User-Agent strings but also several other headers to identify and customize their requests. So, to improve the reliability of our scrapers, we should also include these headers when scraping.
How to Set Fake Browser Headers in NodeJS Puppeteer
To set custom headers in Puppeteer, use the setExtraHTTPHeaders method:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
'Accept-Language': 'en-US,en;q=0.9',
'Upgrade-Insecure-Requests': '1',
});
await page.goto('https://www.chocolate.co.uk');
const content = await page.content();
console.log(content);
await browser.close();
})();
Rotating Browser Headers
Similar to user-agents, you can rotate headers to avoid detection:
const puppeteer = require('puppeteer');
const headersList = [
{
'Accept-Language': 'en-US,en;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
{
'Accept-Language': 'fr-FR,fr;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
{
'Accept-Language': 'es-ES,es;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
];
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const randomHeaders = headersList[Math.floor(Math.random() * headersList.length)];
await page.setExtraHTTPHeaders(randomHeaders);
await page.goto('https://www.chocolate.co.uk');
const content = await page.content();
console.log(content);
await browser.close();
})();
Creating Custom Middleware for User-Agents and Headers
To efficiently manage user-agents and headers, you can create a middleware that sets these values dynamically.
User-Agent Middleware
class UserAgentMiddleware {
constructor(userAgents) {
this.userAgents = userAgents;
}
getRandomUserAgent() {
const randomIndex = Math.floor(Math.random() * this.userAgents.length);
return this.userAgents[randomIndex];
}
}
const userAgentMiddleware = new UserAgentMiddleware([
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
]);
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent(userAgentMiddleware.getRandomUserAgent());
await page.goto('https://www.chocolate.co.uk');
const content = await page.content();
console.log(content);
await browser.close();
})();
Browser Headers Middleware
class BrowserHeadersMiddleware {
constructor(headersList) {
this.headersList = headersList;
}
getRandomHeaders() {
const randomIndex = Math.floor(Math.random() * this.headersList.length);
return this.headersList[randomIndex];
}
}
const headersMiddleware = new BrowserHeadersMiddleware([
{
'Accept-Language': 'en-US,en;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
{
'Accept-Language': 'fr-FR,fr;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
]);
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setExtraHTTPHeaders(headersMiddleware.getRandomHeaders());
await page.goto('https://www.chocolate.co.uk');
const content = await page.content();
console.log(content);
await browser.close();
})();
Integrating Middlewares in a Scraper
Integrating the custom middlewares into a scraper is straightforward. Ensure the middleware is called before each page navigation.
const puppeteer = require('puppeteer');
class UserAgentMiddleware {
constructor(userAgents) {
this.userAgents = userAgents;
}
getRandomUserAgent() {
const randomIndex = Math.floor(Math.random() * this.userAgents.length);
return this.userAgents[randomIndex];
}
}
class BrowserHeadersMiddleware {
constructor(headersList) {
this.headersList = headersList;
}
getRandomHeaders() {
const randomIndex = Math.floor(Math.random() * this.headersList.length);
return this.headersList[randomIndex];
}
}
class Scraper {
constructor(userAgentMiddleware, headersMiddleware) {
this.userAgentMiddleware = userAgentMiddleware;
this.headersMiddleware = headersMiddleware;
}
async scrape(url) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent(this.userAgentMiddleware.getRandomUserAgent());
await page.setExtraHTTPHeaders(this.headersMiddleware.getRandomHeaders());
await page.goto(url);
const content = await page.content();
await browser.close();
return content;
}
}
const userAgentMiddleware = new UserAgentMiddleware([
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
]);
const headersMiddleware = new BrowserHeadersMiddleware([
{
'Accept-Language': 'en-US,en;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
{
'Accept-Language': 'fr-FR,fr;q=0.9',
'Upgrade-Insecure-Requests': '1',
},
]);
const scraper = new Scraper(userAgentMiddleware, headersMiddleware);
(async () => {
const content = await scraper.scrape('https://www.chocolate.co.uk');
console.log(content);
})();

Node.js Playwright Beginners Series Part 5: Using Fake User-Agents and Browser Headers
Welcome to Part 5 of our Node.js Playwright Beginner Series!
So far in this series, we learned how to build a basic web scraper in Part 1, get it to scrape some data from a website in Part 2, clean up the data as it was being scraped and then save the data to a file or database in Part 3, and make our scraper more robust and scalable by handling failed requests and using concurrency in Part 4.
In this guide, we’ll walk through how to customize User-Agent strings and Browser Headers to make your scraper behave like a real user, rather than a headless browser like Playwright.
Many websites use advanced bot detection techniques to block scrapers. By making your scraper appear more like a legitimate user, you can minimize the risk of detection and ensure smoother scraping operations.
- Getting Blocked and Banned While Web Scraping
- Using Fake User-Agents When Scraping
- Using Fake Browser Headers When Scraping
- Next Steps
Node.js Playwright 6-Part Beginner Series
-
Part 1: Basic Node.js Playwright Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
-
Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
-
Part 3: Storing Scraped Data in AWS S3, MySQL & Postgres DBs - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
-
Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (This Article)
-
Part 6: Using Proxies To Avoid Getting Blocked - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Getting Blocked and Banned While Web Scraping
When scraping large volumes of data, you’ll quickly realize that building and running scrapers is the easy part-the real challenge is consistently retrieving HTML responses from the pages you want.
While scraping a few hundred pages on your local machine is manageable, websites will block your requests once you scale up to thousands or millions.
Major sites like Amazon monitor traffic using IP addresses and user-agents, employing advanced anti-bot systems to detect suspicious behavior. If your scraper is identified, your requests will be blocked.
Playwright scrapers are easily detected because their default settings signal bot-like behavior. Here’s why:
-
User-Agent Strings: When Playwright runs in headless mode, it includes
Headlessin the User-Agent string, which makes it an easy target for websites monitoring for bots. -
Headers: Playwright's default headers differ from those sent by real browsers. Headers such as
Accept-Language,Accept-Encoding, andUser-Agentneed to match typical browser requests. Any discrepancy can trigger bot detection mechanisms.
In this guide, we're still going to look at how to use fake user-agents and browser headers so that you can apply these techniques if you ever need to scrape a more difficult website like Amazon.
Using Fake User-Agents When Scraping
A common reason for getting blocked while web scraping is using bad User-Agent headers. Many websites are protective of their data and don’t want it scraped, so it's important to make your scraper appear as a legitimate user.
To achieve this, you need to carefully manage the User-Agent headers that are sent with your HTTP requests.
What are User-Agents?
A User-Agent is a string sent to the server via HTTP headers, allowing the server to identify the client making the request. This string typically contains information such as:
- Browser: The name and version of the browser (e.g., Chrome, Firefox).
- Operating System: The OS and its version (e.g., Windows 10, macOS).
- Rendering Engine: The engine used to display the content (e.g., WebKit, Gecko).
In Playwright, the default User-Agent string can expose that a request is coming from a headless browser, which is often flagged by websites.
Let's check the default User-Agent in Playwright by sending a request to httpbin.io/user-agent endpoint:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://httpbin.io/user-agent');
const content = await page.content();
console.log(content);
await browser.close();
})();
This outputs the following User-Agent string:
<html><head><meta name="color-scheme" content="light dark"><meta charset="utf-8"></head><body><pre>{
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/128.0.6613.18 Safari/537.36"
}
</pre><div class="json-formatter-container"></div></body></html>
The user-agent string indicates that you are using Mozilla version 5.0 on a 64-bit Linux computer.
- The browser is Mozilla
- The version of Mozilla is 5.0
- The operating system is Linux
- The device is a 64-bit computer
You can see the User-Agent contains the string HeadlessChrome, indicating that this request comes from a headless browser—a key signal for websites to detect bots.
Check our Playwright: Using Fake User Agents to get more information about using Fake-User Agents in NodeJS Playwright.
Why Use Fake User-Agents in Web Scraping
Fake User-Agents are used in web scraping to make requests appear as though they are coming from a real browser and a legitimate user rather than a bot.
You must set a unique user-agent for each request. Websites can detect repeated requests from the same user-agent and identify them as potential bots.
In Node.js, using Playwright for web scraping, the default User-Agent string may reveal that your requests are being made by an automated tool, which websites can detect and block. To avoid this, you should manually set a custom User-Agent before making each request to mimic a real browser.
For example, Playwright's default user-agent might look like this:
'User-Agent': 'Playwright/1.18.0'
This makes it obvious that your requests are coming from Playwright, which could lead to blocking. Therefore, it's crucial to manage your user-agents when sending requests with Playwright.
How to Set a Fake User-Agent in Playwright
You can choose a genuine user agent from UserAgents.io for use in your code. For example, we've selected this user agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
To use a specific User-Agent and override the default one in Playwright, you need to pass it to the newContext() method under the userAgent name. Check out the code below:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext({
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
});
const page = await context.newPage();
await page.goto('https://httpbin.org/user-agent');
const content = await page.content();
console.log(content);
await browser.close();
})();
// <html><head><meta name="color-scheme" content="light dark"><meta charset="utf-8"></head><body><pre>{
// "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
// }
// </pre><div class="json-formatter-container"></div></body></html>
Our code has successfully overridden the default User-Agent, which previously contained a "Headless" string. It now resembles a genuine User-Agent without any such strings.
How to Rotate User-Agents
Using the same User-Agent for all requests isn't ideal. It can make your scraper appear suspicious since scrapers typically send a high volume of requests compared to regular users.
To mitigate this, you should rotate user agents and headers to simulate different profiles with each request.
Here's how you can do it:
const { chromium } = require('playwright');
const userAgents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1",
"Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363",
];
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext({
userAgent: userAgents[Math.floor(Math.random() * userAgents.length)]
});
const page = await context.newPage();
await page.goto('http://httpbin.org/user-agent');
const content = await page.content();
console.log(content);
await browser.close();
})();
// <html><head><meta name="color-scheme" content="light dark"><meta charset="utf-8"></head><body><pre>{
// "headers": {
// "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
// "Accept-Encoding": "gzip, deflate",
// "Host": "httpbin.org",
- Start by compiling a list of user agents and storing them in an array called
userAgents. - Each time you create a new context, randomly select a user agent from the array and pass it to the
userAgentoption innewContext().
Alternatively, you can use the npm package user-agents to get a larger dataset of user agents instead of manually listing them.
How to Create a Custom Fake User-Agent Middleware
Let's dive into creating a custom middleware that manages thousands of fake user agents efficiently. This middleware can be easily integrated into your scraper.
The best approach is to leverage a free user-agent API, like the ScrapeOps Fake User-Agent API. This API provides an up-to-date list of user agents, allowing your scraper to select a different one for each request.
To use the ScrapeOps Fake User-Agent API, you'll need to request a list of user agents from their endpoint:
http://headers.scrapeops.io/v1/user-agents?api_key=YOUR_API_KEY
To access this API, sign up for a free account and obtain an API key.
Here’s an example of the API response containing a list of user agents:
{
"result": [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36"
]
}
To integrate the Fake User-Agent API into your scraper:
- Configure it to fetch a list of user agents when the scraper starts.
- Then, randomly select a user agent from this list for each request.
In case the list from the API is empty or unavailable, you can use a fallback list of user agents.
Here’s how to build the custom user-agent middleware:
- Create a Method to Fetch User Agents
Define a method getHeaders() to retrieve user agents from the ScrapeOps API and use fallback headers if needed:
const axios = require('axios');
async function getHeaders(numHeaders) {
const fallbackHeaders = [
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
];
const scrapeOpsKey = "<YOUR_SCRAPE_OPS_KEY>";
try {
const response = await axios.get(
`http://headers.scrapeops.io/v1/user-agents?api_key=${scrapeOpsKey}&num_results=${numHeaders}`
);
if (response.data.result.length > 0) {
return response.data.result;
} else {
console.error("No headers from ScrapeOps, using fallback headers");
return fallbackHeaders;
}
} catch (error) {
console.error(
"Failed to fetch headers from ScrapeOps, using fallback headers"
);
return fallbackHeaders;
}
}
- Use Random User Agents:
Call getHeaders() during the startup of your scraper to fetch user agents. Use these agents for each request by selecting a random one:
if (isMainThread) {
// ...
} else {
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
if (headers.length == 0) {
headers = await getHeaders(2);
}
const { nextUrl, products } = await scrape(
workUrl,
headers[Math.floor(Math.random() * headers.length)]
);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
This setup ensures your scraper uses diverse user agents, making it less detectable and more effective.
Integrating User-Agent Middleware in a Scraper
Now that we’ve developed the getHeaders() middleware to fetch user agents from ScrapeOps using an Axios request, it's time to integrate it into our scraper.
To do this, we'll update our scrape() method from Part 4 to accept an additional parameter for headers. We'll then pass these headers as extraHTTPHeaders to the newPage() method.
Here's how you can implement it:
async function scrape(url, headers) {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage({
extraHTTPHeaders: headers
});
const response = await makeRequest(page, url);
if (!response) {
await browser.close();
return { nextUrl: null, products: [] };
}
const productItems = await page.$$eval("product-item", items =>
items.map(item => {
const titleElement = item.querySelector(".product-item-meta__title");
const priceElement = item.querySelector(".price");
return {
name: titleElement ? titleElement.textContent.trim() : null,
price: priceElement ? priceElement.textContent.trim() : null,
url: titleElement ? titleElement.getAttribute("href") : null
};
})
);
const nextUrl = await nextPage(page);
await browser.close();
return {
nextUrl: nextUrl,
products: productItems.filter(item => item.name && item.price && item.url)
};
}
Using Fake Browser Headers When Scraping
For basic websites, setting an up-to-date User-Agent may be sufficient for reliable data scraping. However, many popular sites now employ advanced anti-bot technologies that look beyond the user-agent to detect scraping activities.
These technologies analyze additional headers that a real browser typically sends along with the user-agent.
Why Choose Fake Browser Headers Instead of User-Agents
Incorporating a full set of browser headers, rather than just a fake user-agent, makes your requests more similar to those of genuine users. This approach helps your requests blend in better and reduces the likelihood of detection.
Here’s an example of the headers a Chrome browser on macOS might use:
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.83 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
As shown, real browsers send not only a User-Agent string but also several additional headers to identify and customize their requests.
To enhance the reliability of your scrapers, you should include these headers along with your user-agent.
How to Set Fake Browser Headers in Node.js Playwright
Before we set custom headers, let’s examine the default headers sent by Playwright:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://httpbin.org/headers');
const content = await page.content();
console.log(content);
await browser.close();
})();
The above code displays:
<html><head><meta name="color-scheme" content="light dark"><meta charset="utf-8"></head><body><pre>{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Host": "httpbin.org",
"Priority": "u=0, i",
"Sec-Ch-Ua": "\"Chromium\";v=\"128\", \"Not;A=Brand\";v=\"24\", \"HeadlessChrome\";v=\"128\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "\"Linux\"",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/128.0.6613.18 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-66e343d9-5b9187420b8de5f2661f4a73"
}
}
</pre><div class="json-formatter-container"></div></body></html>
As observed, the default headers are not as comprehensive as those sent by a real browser. This discrepancy can lead to detection and blocking when scraping numerous pages. To mitigate this, you should use a full set of fake browser headers.
To simulate a real browser, you'll need to set a full range of headers, not just the user-agent. Define these headers as key-value pairs and pass them to the extraHTTPHeaders parameter of the newPage() method. Here’s an example:
const { chromium } = require('playwright');
const headers = {
authority: "httpbin.org",
"cache-control": "max-age=0",
"sec-ch-ua":
'"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
"sec-ch-ua-mobile": "?0",
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-language": "en-US,en;q=0.9",
};
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage({
extraHTTPHeaders: headers
});
await page.goto('https://httpbin.org/headers');
const content = await page.content();
console.log(content);
await browser.close();
})();
In this code, we send a request to the httpbin.org/headers endpoint. You should see all the custom headers included in the request, making your scraping activity less detectable.
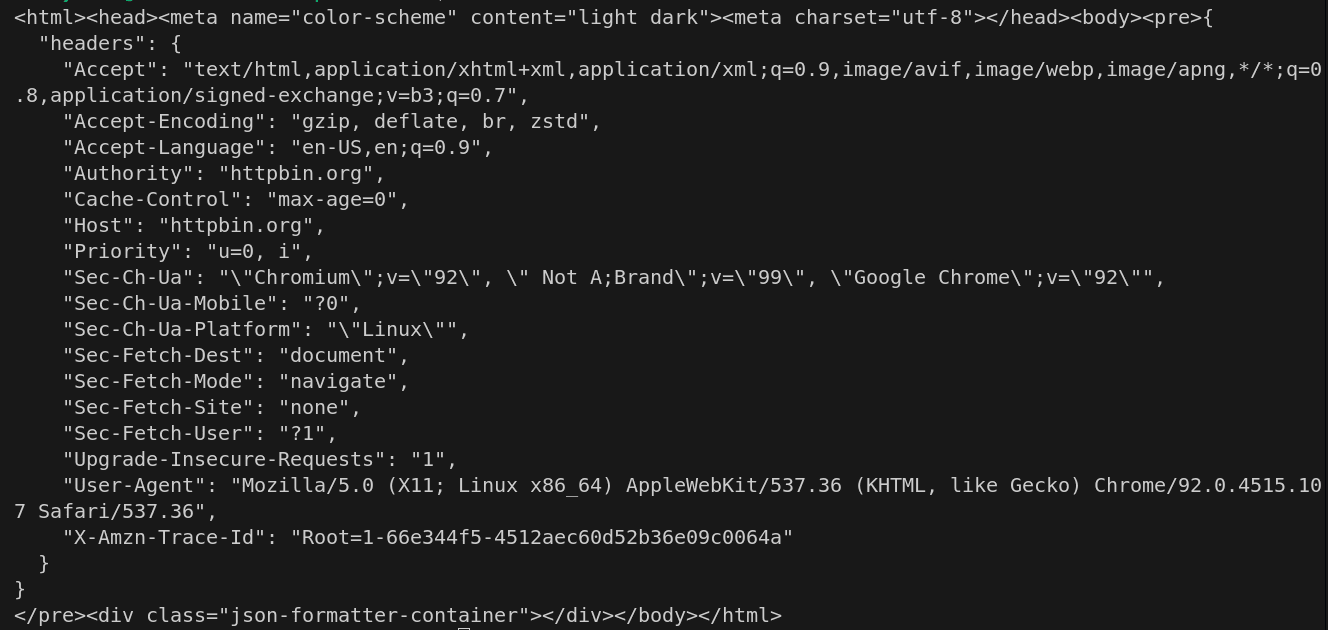
How to Create a Custom Fake Browser Headers Middleware
Creating custom fake browser agent middleware is quite similar to setting up custom fake user-agent middleware.
You can either manually build a list of fake browser headers or use the ScrapeOps Fake Browser Headers API to get an updated list each time your scraper runs.
The ScrapeOps Fake Browser Headers API is a free service that provides a set of optimized fake browser headers. This can help you avoid blocks and bans, enhancing the reliability of your web scrapers.
The API endpoint you’ll use is:
http://headers.scrapeops.io/v1/browser-headers?api_key=YOUR_API_KEY
Here is an example response:
{
"result": [
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7"
},
{
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Linux\"",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
]
}
Steps to Integrate the API:
- Obtain an API Key: Sign up for a free account at ScrapeOps to get your API key.
- Configure Your Scraper: Set up your scraper to fetch a batch of updated headers from the API when it starts.
- Randomize Headers: For each request, select a random header from the list retrieved.
- Handle Empty or Failed Requests: If the header list is empty or the API request fails, use a predefined fallback header list.
Here is the complete code:
const { chromium } = require('playwright');
const fs = require('fs');
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const axios = require('axios');
class Product {
constructor(name, priceStr, url, conversionRate = 1.32) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb, conversionRate);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
return name?.trim() || "missing";
}
cleanPrice(priceStr) {
if (!priceStr?.trim()) {
return 0.0;
}
const cleanedPrice = priceStr
.replace(/Sale priceFrom £|Sale price£/g, "")
.trim();
return cleanedPrice ? parseFloat(cleanedPrice) : 0.0;
}
convertPriceToUsd(priceGb, conversionRate) {
return priceGb * conversionRate;
}
createAbsoluteUrl(url) {
return (url?.trim()) ? `https://www.chocolate.co.uk${url.trim()}` : "missing";
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 1000));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
const scrapeOpsKey = "<YOUR_SCRAPE_OPS_KEY>";
async function makeRequest(page, url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await page.goto(url);
const status = response.status();
if ([200, 404].includes(status)) {
if (antiBotCheck && status == 200) {
const content = await page.content();
if (content.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
async function getHeaders(numHeaders) {
const fallbackHeaders = [
{
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua":
'".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7",
},
{
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua":
'".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Linux"',
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7",
},
];
try {
const response = await axios.get(
`http://headers.scrapeops.io/v1/browser-headers?api_key=${scrapeOpsKey}&num_results=${numHeaders}`
);
if (response.data.result.length > 0) {
return response.data.result;
} else {
console.error("No headers from ScrapeOps, using fallback headers");
return fallbackHeaders;
}
} catch (error) {
console.error(
"Failed to fetch headers from ScrapeOps, using fallback headers"
);
return fallbackHeaders;
}
}
async function scrape(url, headers) {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage({
extraHTTPHeaders: headers
});
const response = await makeRequest(page, url);
if (!response) {
await browser.close();
return { nextUrl: null, products: [] };
}
const productItems = await page.$$eval("product-item", items =>
items.map(item => {
const titleElement = item.querySelector(".product-item-meta__title");
const priceElement = item.querySelector(".price");
return {
name: titleElement ? titleElement.textContent.trim() : null,
price: priceElement ? priceElement.textContent.trim() : null,
url: titleElement ? titleElement.getAttribute("href") : null
};
})
);
const nextUrl = await nextPage(page);
await browser.close();
return {
nextUrl: nextUrl,
products: productItems.filter(item => item.name && item.price && item.url)
};
}
async function nextPage(page) {
let nextUrl = null;
try {
nextUrl = await page.$eval("a.pagination__nav-item:nth-child(4)", item => item.href);
} catch (error) {
console.log('Last Page Reached');
}
return nextUrl;
}
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url }
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
const { startUrl } = workerData;
let headers = [];
const handleWork = async (workUrl) => {
if (headers.length == 0) {
headers = await getHeaders(2);
}
const { nextUrl, products } = await scrape(
workUrl,
headers[Math.floor(Math.random() * headers.length)]
);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
// Worker created 1 https://www.chocolate.co.uk/collections/all
// Worker working on https://www.chocolate.co.uk/collections/all?page=2
// Worker working on https://www.chocolate.co.uk/collections/all?page=3
// Last Page Reached
// Worker finished
// Worker exited
// Pipeline closed
Integrating Fake Browser Headers Middleware
Integrating the headers middleware is straightforward. We'll just make a few minor changes to the getHeaders() method that we previously created for fetching user agents. In this updated method:
-
We'll send a request to "http://headers.scrapeops.io/v1/browser-headers" with the necessary query parameters and fetch the headers using Axios.
-
If the request fails, we’ll return the
fallbackHeadersthat we manually added to the script.
After adding the browser headers middleware, here’s what the entire code will look like:
const { chromium } = require('playwright');
const fs = require('fs');
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const axios = require('axios');
class Product {
constructor(name, priceStr, url, conversionRate = 1.32) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb, conversionRate);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
return name?.trim() || "missing";
}
cleanPrice(priceStr) {
if (!priceStr?.trim()) {
return 0.0;
}
const cleanedPrice = priceStr
.replace(/Sale priceFrom £|Sale price£/g, "")
.trim();
return cleanedPrice ? parseFloat(cleanedPrice) : 0.0;
}
convertPriceToUsd(priceGb, conversionRate) {
return priceGb * conversionRate;
}
createAbsoluteUrl(url) {
return (url?.trim()) ? `https://www.chocolate.co.uk${url.trim()}` : "missing";
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 1000));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
const scrapeOpsKey = "<YOUR_SCRAPE_OPS_KEY>";
async function makeRequest(page, url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await page.goto(url);
const status = response.status();
if ([200, 404].includes(status)) {
if (antiBotCheck && status == 200) {
const content = await page.content();
if (content.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
async function getHeaders(numHeaders) {
const fallbackHeaders = [
{
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; Windows; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua":
'".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "bg-BG,bg;q=0.9,en-US;q=0.8,en;q=0.7",
},
{
"upgrade-insecure-requests": "1",
"user-agent":
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua":
'".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Linux"',
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7",
},
];
try {
const response = await axios.get(
`http://headers.scrapeops.io/v1/browser-headers?api_key=${scrapeOpsKey}&num_results=${numHeaders}`
);
if (response.data.result.length > 0) {
return response.data.result;
} else {
console.error("No headers from ScrapeOps, using fallback headers");
return fallbackHeaders;
}
} catch (error) {
console.error(
"Failed to fetch headers from ScrapeOps, using fallback headers"
);
return fallbackHeaders;
}
}
async function scrape(url, headers) {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage({
extraHTTPHeaders: headers
});
const response = await makeRequest(page, url);
if (!response) {
await browser.close();
return { nextUrl: null, products: [] };
}
const productItems = await page.$$eval("product-item", items =>
items.map(item => {
const titleElement = item.querySelector(".product-item-meta__title");
const priceElement = item.querySelector(".price");
return {
name: titleElement ? titleElement.textContent.trim() : null,
price: priceElement ? priceElement.textContent.trim() : null,
url: titleElement ? titleElement.getAttribute("href") : null
};
})
);
const nextUrl = await nextPage(page);
await browser.close();
return {
nextUrl: nextUrl,
products: productItems.filter(item => item.name && item.price && item.url)
};
}
async function nextPage(page) {
let nextUrl = null;
try {
nextUrl = await page.$eval("a.pagination__nav-item:nth-child(4)", item => item.href);
} catch (error) {
console.log('Last Page Reached');
}
return nextUrl;
}
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url }
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
const { startUrl } = workerData;
let headers = [];
const handleWork = async (workUrl) => {
if (headers.length == 0) {
headers = await getHeaders(2);
}
const { nextUrl, products } = await scrape(
workUrl,
headers[Math.floor(Math.random() * headers.length)]
);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
// Worker created 1 https://www.chocolate.co.uk/collections/all
// Worker working on https://www.chocolate.co.uk/collections/all?page=2
// Worker working on https://www.chocolate.co.uk/collections/all?page=3
// Last Page Reached
// Worker finished
// Worker exited
// Pipeline closed
Next Steps
Now that you understand how to use User Agents and Browser Headers to overcome blocks and restrictions, you're ready to tackle more advanced scraping techniques.
We hope you now have a good grasp of cloaking your requests so they look like genuine browser traffic, letting you scrape even the most protective sites without tripping anti‑bot alarms. If you run into any issues or have questions, drop them in the comments below and we'll jump in to help.
Want to dig into the code?
- Python Requests/BS4 version: grab the repository on GitHub here.
- Node.js implementations: see the full examples on GitHub here.
The next tutorial shows you how to layer in proxies - spreading requests across IP addresses to stay under the radar and unlock true production‑grade scale.