
How to Scrape Walmart With Selenium
Walmart, established in 1962, is the world's biggest retailer. It ranks as the second-largest online retailer worldwide, just behind Amazon. By scraping Walmart, we can access a wide range of products from around the world.
In this guide, we will first crawl Walmart search pages and then proceed to scrape product reviews.
- TLDR How to Scrape Walmart
- How To Architect Our Scraper
- Understanding How To Scrape Walmart
- Setting Up Our Walmart Scraper
- Build A Walmart Search Crawler
- Build A Walmart Scraper
- Legal and Ethical Considerations
- Conclusion
- More Python Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Scrape Walmart
If you require a pre-built Walmart scraper, consider trying this one.
- First, create a new project folder.
- Next, make a
config.jsonfile containing your ScrapeOps API key. - After that, copy and paste the code provided below into a new Python file within the same folder.
- You can then execute it by running python
name_of_your_file.py.
import os
import csv
import json
import logging
import time
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
from urllib.parse import urlencode
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
author_id: int = 0
rating: float = 0.0
date: str = ""
review: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get(scrapeops_proxy_url)
logger.info(f"Received page: {url}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
driver.quit() # Close the WebDriver
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver on error
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row.get("url")
tries = 0
success = False
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
logger.info(f"Attempting to access URL: {scrapeops_proxy_url}")
driver.get(scrapeops_proxy_url)
logger.info(f"Status: {driver.title}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
review_list = json_data["props"]["pageProps"]["initialData"]["data"]["reviews"]["customerReviews"]
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review in review_list:
name = review["userNickname"]
author_id = review["authorId"]
rating = review["rating"]
date = review["reviewSubmissionTime"]
review_text = review["reviewText"]
review_data = ReviewData(
name=name,
author_id=author_id,
rating=rating,
date=date,
review=review_text
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {url}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads, retries=3):
logger.info(f"Processing {csv_file}")
with open(csv_file, newline="", encoding="utf-8") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader, # Pass each row in the CSV as the first argument to process_item
[location] * len(reader), # Location as second argument for all rows
[retries] * len(reader) # Retries as third argument for all rows
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION,max_threads=MAX_THREADS, retries=MAX_RETRIES)
To adjust your results, you can modify the following:
MAX_RETRIES: Sets the maximum number of retries if a request fails. This can happen due to network timeouts or non-200 HTTP responses.MAX_THREADSDefines how many threads will run at the same time during scraping.PAGESThe number of search result pages to scrape for each keyword.LOCATIONThe location or country code for scraping products or reviews.keyword_listA list of product keywords to search on Walmart’s website (e.g., ["laptop"])
How To Architect Our Walmart Scraper
If you check the screenshot below, this is the page you'll see. It appears when Walmart isn't scraped correctly.
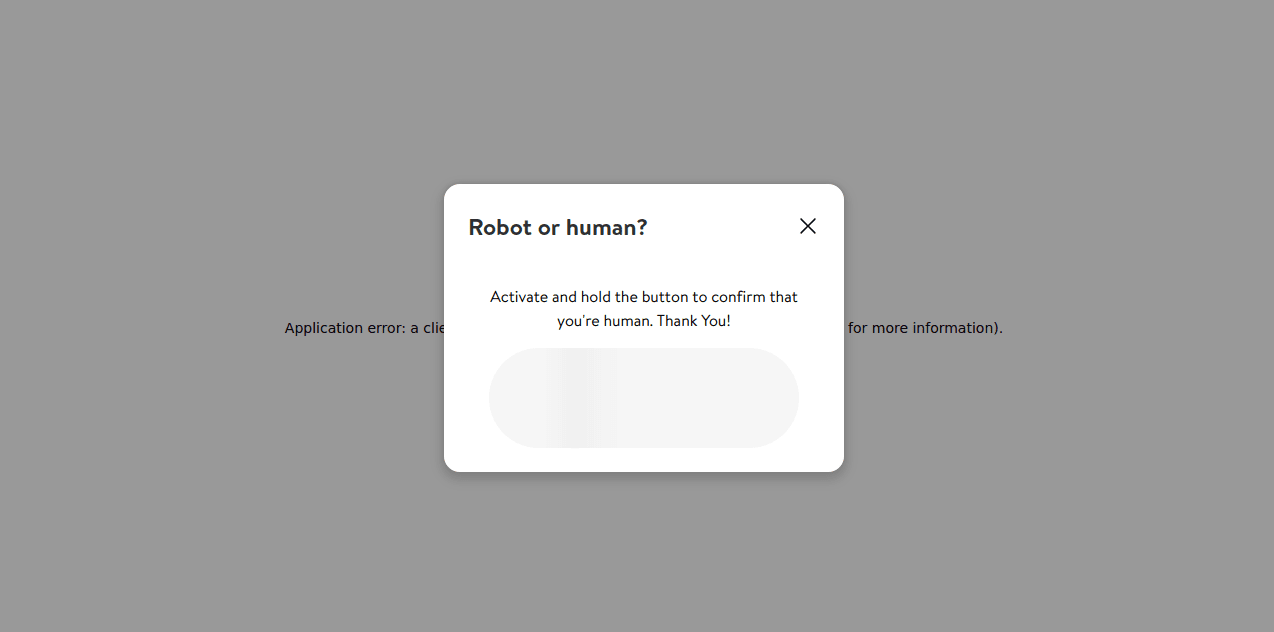
- The result crawler will generate a report of items matching a keyword. For instance, if we search for laptops, it will create a detailed report on laptops.
- The review scraper will then gather reviews for each laptop in the report.
Here are the steps for the result crawler:
- Parse Walmart search data.
- Paginate results to control the data.
- Store the scraped data.
- Run steps 1 through 3 on multiple pages concurrently.
- Add proxy integration to bypass anti-bots and avoid block screens.
For the review scraper:
- Read the CSV file into an array.
- Parse reviews for each item in the array.
- Store the extracted review data.
- Run steps 2 and 3 on multiple pages using concurrency.
- Integrate ScrapeOps Proxy to bypass anti-bots again.
Understanding How To Scrape Walmart
We'll start by getting a high-level view of Walmart’s structure. We will examine different Walmart pages and their layout.
Next, we’ll see how to extract data and improve control over results.
Step 1: How To Request Walmart Pages
Like other websites, we first need to make a GET request. Walmart's server will respond with an HTML page. We'll focus first on the search result pages and then move on to the review pages.
Search URLs follow this pattern:
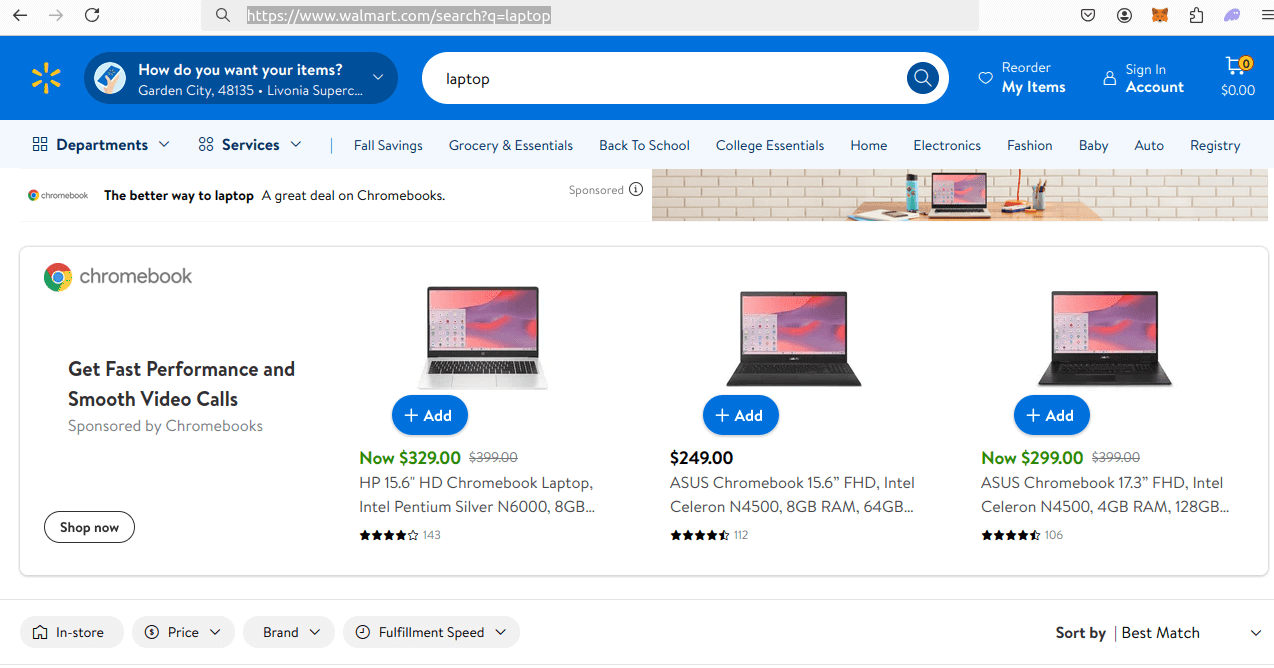
https://www.walmart.com/search?q={formatted_keyword}
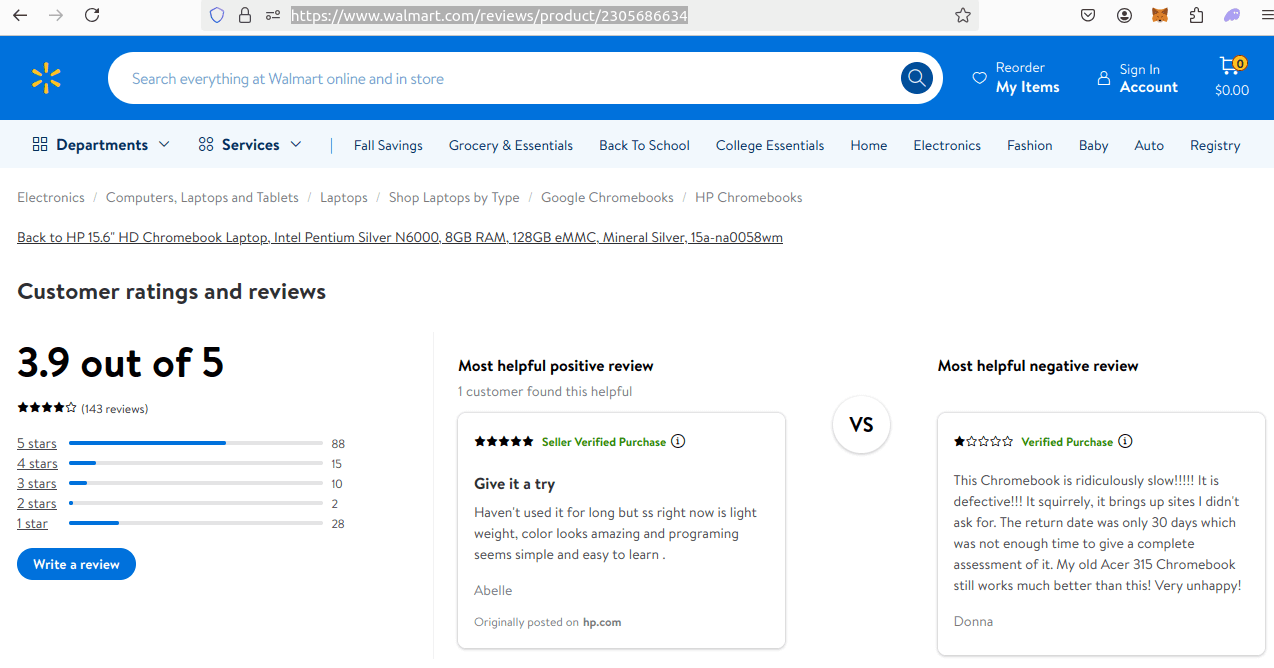
Our review pages are structured like this:
https://www.walmart.com/reviews/product/{product_id}
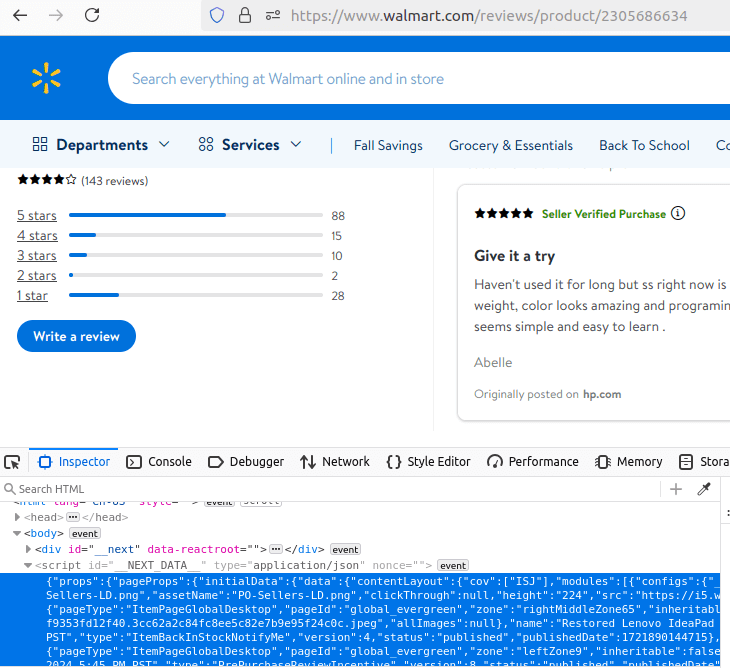
Check out the example page below.
Step 2: How To Extract Data From Walmart Results and Pages
Let's take a closer look at the specific data we'll be extracting. Fortunately, both the results page and the review page store all their information inside a JSON blob.
You can see the search result JSON below.
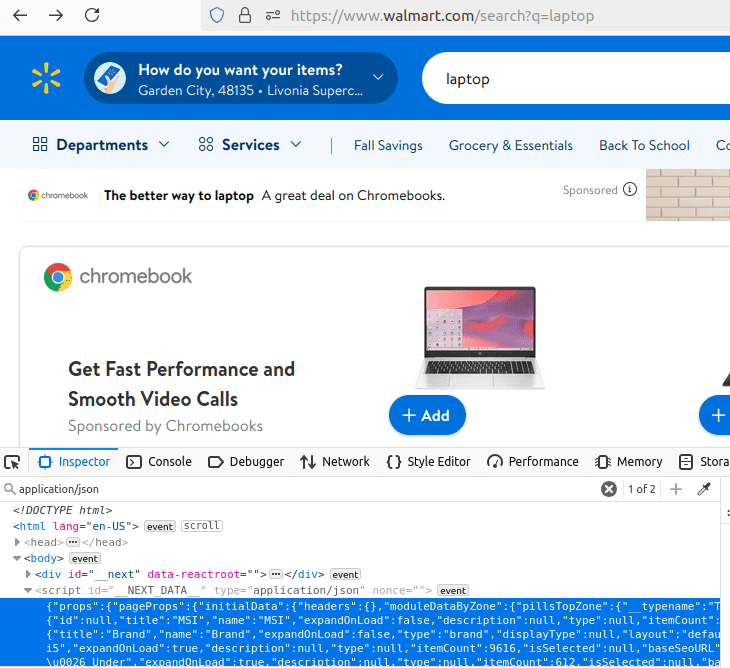
Here is the JSON blob for the reviews page.
Step 3: How To Control Pagination
Like many other websites, we can control pagination by adding a query parameter, page. To view page 1, the URL will have page=1.
The full paginated URL will be:
https://www.walmart.com/search?q={formatted_keyword}&page={page_number+1}
We use page_number+1 because Python’s range() function starts counting at 0.
Step 4: Geolocated Data
For geolocation, we’ll use the country parameter with the ScrapeOps Proxy API. This parameter allows us to choose the country.
- If we want to appear in the US, we pass
"country": "us". - For the UK, we pass
"country": "uk".
Setting Up Our Walmart Scraper Project
Let’s begin by setting up the project. Run these commands to get started:
Create a New Project Folder
mkdir walmart-scraper
Navigate to the Folder
cd walmart-scraper
Create a New Virtual Environment
python -m venv venv
Activate the Environment
source venv/bin/activate
Install Our Dependencies
pip install selenium
pip install webdriver-manager
Build A Walmart Search Crawler
Now, we’ll start building our search crawler. This will be the foundation of the project. The key features we’ll add include:
- Parsing
- Pagination
- Data storage
- Concurrency
- Proxy integration
Step 1: Create Simple Search Data Parser
We�’ll start by building a parser. The parser will search Walmart using keywords and extract data from the results.
In the code below, we add basic structure, error handling, retry logic, and the base parsing function. Focus on the parsing function, scrape_search_results().
Here’s the code we’ll start with:
import os
import json
import logging
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}"
tries = 0
success = False
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
while tries < retries and not success:
try:
driver.get(url)
logger.info(f"Received page from: {url}")
# Wait for the necessary elements to load
time.sleep(3) # Adjust sleep time as necessary
# Retrieve the JSON data from the page
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute('innerText'))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = {
"name": name,
"stars": rating,
"url": link,
"sponsored": sponsored,
"price": price,
"product_id": product_id
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries - tries - 1}")
tries += 1
driver.quit() # Ensure to close the browser
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
scrape_search_results(keyword, LOCATION, retries=MAX_RETRIES)
logger.info(f"Crawl complete.")
All of our data is embedded in a JSON blob. Here's how we handle it:
- Find the JSON: We use
soup.select_one("script[id='__NEXT_DATA__'][type='application/json']")to locate the JSON. - Convert to JSON Object: We use
json.loads()to turn the text into a JSON object. - Access Item List: To get our list of items, we access it through
json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"].
We then go through each item in the list and extract the following:
- "name": The product's name.
- "stars": The product's overall rating.
- "url": The link to the product's reviews.
- "sponsored": Whether it's a sponsored item (an ad).
- "price": The product's price.
- "product_id": The unique ID assigned to the product on the site.
Step 2: Add Pagination
We can parse the results, but we only get the first page. To solve this, we need to add pagination. This allows us to request specific pages.
To do this, we add a page parameter to our URL. Now, the URLs will look like this:
https://www.walmart.com/search?q={formatted_keyword}&page={page_number+1}
We use page_number+1 because Walmart pages start at 1, while Python's range() starts from 0.
Next, we create a start_scrape() function. This function takes a list of pages and runs scrape_search_results() on each one.
def start_scrape(keyword, pages, location, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, retries=retries)
You can find the updated code below.
import os
import json
import logging
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, page_number, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number + 1}"
tries = 0
success = False
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
while tries < retries and not success:
try:
driver.get(url)
logger.info(f"Received page from: {url}")
# Wait for the necessary elements to load
time.sleep(3) # Adjust sleep time as necessary
# Retrieve the JSON data from the page
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute('innerText'))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = {
"name": name,
"stars": rating,
"url": link,
"sponsored": sponsored,
"price": price,
"product_id": product_id
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries - tries - 1}")
tries += 1
driver.quit() # Ensure to close the browser
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 2
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
start_scrape(keyword, PAGES, LOCATION, retries=MAX_RETRIES)
logger.info(f"Crawl complete.")
We included a page argument in both our parsing function and our URL. The function start_scrape() enables us to scrape multiple pages.
Step 3: Storing the Scraped Data
Saving the Scraped Data Once we have extracted the data, it is necessary to store it.
Without storage, web scraping would be useless! We will save the data in a CSV file.
The CSV format is very handy since it allows humans to open it easily and view the results in a spreadsheet. Additionally, a CSV is simply a collection of key-value pairs.
Later, we will write Python code to read the CSV file and scrape product reviews from it. But first, we need a dataclass. We'll name it SearchData, as it will represent objects from our search results.
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
At this point, we require a DataPipeline. This class establishes a connection to a CSV file. In addition, it performs a few other crucial tasks.
If the file isn’t already present, the class creates it. If the CSV file exists, it appends to it instead.
The DataPipeline also utilizes the name attribute to eliminate duplicate entries.
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.csv_file_open:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
In our complete code, we now open a DataPipeline and provide it to our crawling functions.
Rather than printing our data, we convert it into SearchData and then pass it through the DataPipeline.
import os
import csv
import json
import logging
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.csv_file_open:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number + 1}"
tries = 0
success = False
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
while tries < retries and not success:
try:
driver.get(url)
logger.info(f"Received page from: {url}")
# Wait for the necessary elements to load
time.sleep(3) # Adjust sleep time as necessary
# Retrieve the JSON data from the page
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute('innerText'))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries - tries - 1}")
tries += 1
driver.quit() # Ensure to close the browser
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, data_pipeline=data_pipeline, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
- SearchData is an object that represents search results.
- DataPipeline is responsible for piping dataclass objects, specifically SearchData, into a CSV format.
Step 4: Adding Concurrency
At this point, we will introduce concurrency. We'll be utilizing ThreadPoolExecutor to enable multithreading. By opening a new threadpool, we can parse a single page on each available thread.
Below is a rewritten version of start_scrape(), where the for loop has been eliminated.
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
Here is the complete updated code:
import os
import csv
import json
import logging
import time
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.csv_file_open:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number + 1}"
tries = 0
success = False
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
driver.get(url)
time.sleep(3) # Allow time for the page to load
# Find and parse the script tag with the JSON data
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries - tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
driver.quit() # Close the WebDriver
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
keyword_list = ["laptop"]
aggregate_files = []
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
In executor.map(), pay attention to our arguments: scrape_search_results, which is the function for parsing. All other arguments are passed as arrays, and then the executor passes these array elements as arguments into each call to scrape_search_results.
Step 5: Bypassing Anti-Bots
Remember the screen at the top of the page that was blocked? Anti-bots help us bypass it.
In this part, we will write a basic function that harnesses the potential of a proxy. It will receive a URL, a ScrapeOps Proxy API key, along with some additional parameters, and return a completely proxied URL.
Below is our proxy function.
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
Look at the payload closely: "api_key": ScrapeOps API key. "url": the URL to be scraped. "country": the location we want to appear in.
Now our crawler is ready for production.
import os
import csv
import json
import logging
import time
from urllib.parse import urlencode
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.csv_file_open:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number + 1}"
tries = 0
success = False
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
driver.get(scrapeops_proxy_url) # Use Selenium to load the page
time.sleep(3) # Allow time for the page to load
# Find and parse the script tag with the JSON data
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries - tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
driver.quit() # Close the WebDriver
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
keyword_list = ["laptop"]
aggregate_files = []
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 6: Production Run
Let's put this into production now!
Here's the main part we'll be using.
We'll be crawling 4 pages with 3 threads. You can modify any of these to adjust your results:
MAX_RETRIES: Specifies the maximum attempts the script will make to retrieve a webpage if a request fails due to network issues or non-200 HTTP status codes.MAX_THREADS: Determines the highest number of threads that will be run simultaneously during the scraping process.PAGES: The total number of result pages to scrape for every keyword.LOCATION: Indicates the region or country code from which products or reviews will be scraped.keyword_list: Contains a list of product keywords to search on Walmart's website (for example, ["laptop"]).
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 4
LOCATION = "us"
logger.info(f"Crawl starting...")
keyword_list = ["laptop"]
aggregate_files = []
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
We scraped 4 pages in 49.06 seconds. 49.06 seconds / 4 pages = 12.265 seconds per page.
Our crawl generated a report with 160 different laptop items.
Build A Walmart Scraper
When we construct our scraper, we will adhere to a plan similar to the one used with the crawler. The steps our scraper will take are as follows, in this order:
- An array will be created by reading the CSV file.
- The items within the array will be parsed individually.
- The data obtained from the parse will be stored.
- Concurrency will be employed to scrape multiple webpages simultaneously.
- Once again, we will bypass anti-bots by utilizing the ScrapeOps Proxy API.
Step 1: Create Simple Business Data Parser
Just like before, we’ll begin with our basic parsing function. We’ll incorporate the basic structure, which includes retry logic and error handling.
Again, focus carefully on the parsing in the function. This is where the magic takes place.
def process_item(row,location, retries=3):
url = row["url"]
tries = 0
success = False
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
driver.get(url)
time.sleep(3) # Allow time for the page to load
# Find and parse the script tag with the JSON data
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
review_list = json_data["props"]["pageProps"]["initialData"]["data"]["reviews"]["customerReviews"]
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review in review_list:
name = review["userNickname"]
author_id = review["authorId"]
rating = review["rating"]
date = review["reviewSubmissionTime"]
review_text = review["reviewText"]
review_data = ReviewData(
name=name,
author_id=author_id,
rating=rating,
date=date,
review=review_text
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
logger.info(f"Successfully parsed: {url}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries - tries}")
tries += 1
driver.quit() # Close the WebDriver
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
- We locate our JSON in the same manner as before:
driver.find_element(By.CSS_SELECTOR, "script[id='**NEXT_DATA**'][type='application/json']"). - The list of customer reviews is accessed via
json_data["props"]["pageProps"]["initialData"]["data"]["reviews"]["customerReviews"].
We then loop through the reviews and extract the following details:
name: the reviewer's name.author_id: a unique ID for the reviewer, similar to the product_id mentioned previously.rating: the score given by the reviewer.date: the date on which the review was posted.review: the review text, such as "It was good. I really liked [x] about this laptop."
Step 2: Loading URLs To Scrape
To scrape these reviews, we need to input URLs into our parsing function. To do this, we must read the report that the crawler generated.
Now, we will write another function, which is similar to start_scrape() from before.
def process_results(csv_file, location, retries=3):
logger.info(f"Processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_item(row, location, retries=retries)
After reading the CSV, we use a for loop to call process_item() on every row from the file. We will remove the for loop later when we incorporate concurrency.
The fully updated code is shown below.
import os
import csv
import json
import logging
import time
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
from urllib.parse import urlencode
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get(scrapeops_proxy_url)
logger.info(f"Received page: {url}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
driver.quit() # Close the WebDriver
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver on error
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row.get("url")
tries = 0
success = False
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
driver.get(url)
logger.info(f"Status: {driver.title}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
review_list = json_data["props"]["pageProps"]["initialData"]["data"]["reviews"]["customerReviews"]
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review in review_list:
name = review["userNickname"]
author_id = review["authorId"]
rating = review["rating"]
date = review["reviewSubmissionTime"]
review = review["reviewText"]
review_data = {
"name": name,
"author_id": author_id,
"rating": rating,
"date": date,
"review": review
}
print(review_data)
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {url}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, retries=3):
logger.info(f"Processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_item(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, retries=MAX_RETRIES)
The function process_results() reads our CSV file into an array and iterates over it. During each iteration, we call process_item() on the individual items from the array to scrape their reviews.
Step 3: Storing the Scraped Data
As stated previously, scraping data without saving it is pointless. We already have a DataPipeline that can accept a dataclass, but so far, we only have SearchData.
To solve this, we will introduce another one called ReviewData. Then, inside our parsing function, we will create a new DataPipeline and send ReviewData objects to it as we parse.
Here’s a look at ReviewData.
@dataclass
class ReviewData:
name: str = ""
author_id: int = 0
rating: float = 0.0
date: str = ""
review: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
All of the data we extracted during the parse is held by ReviewData. The full code below shows how everything functions.
import os
import csv
import json
import logging
import time
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
from urllib.parse import urlencode
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
author_id: int = 0
rating: float = 0.0
date: str = ""
review: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get(scrapeops_proxy_url)
logger.info(f"Received page: {url}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
driver.quit() # Close the WebDriver
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver on error
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row.get("url")
tries = 0
success = False
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
driver.get(url)
logger.info(f"Status: {driver.title}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
review_list = json_data["props"]["pageProps"]["initialData"]["data"]["reviews"]["customerReviews"]
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review in review_list:
name = review["userNickname"]
author_id = review["authorId"]
rating = review["rating"]
date = review["reviewSubmissionTime"]
review = review["reviewText"]
review_data = ReviewData(
name=name,
author_id=author_id,
rating=rating,
date=date,
review=review
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {url}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, retries=3):
logger.info(f"Processing {csv_file}")
with open(csv_file, newline="", encoding="utf-8") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_item(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, retries=MAX_RETRIES)
Within our parsing function, we now:
- Open a DataPipeline.
- As we parse them, pass ReviewData objects into the pipeline.
- Once parsing is finished, close the pipeline.
Step 4: Adding Concurrency
We will add concurrency in nearly the same manner as before. A new pool of threads will be opened by ThreadPoolExecutor. Our parsing function will be passed as the first argument, and everything else will be passed in as an array to be sent into our parser.
Here is the final process_results().
def process_results(csv_file, location, max_threads, retries=3):
logger.info(f"Processing {csv_file}")
with open(csv_file, newline="", encoding="utf-8") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader, # Pass each row in the CSV as the first argument to process_item
[location] * len(reader), # Location as second argument for all rows
[retries] * len(reader) # Retries as third argument for all rows
)
The logic for reading our CSV remains the same, but now the parsing is running concurrently on multiple threads.
Step 5: Bypassing Anti-Bots
We'll bypass anti-bots in the exact same way we did previously. From within our parser, we'll call get_scrapeops_url(), and now, for each request made during our review scrape, we have a custom proxy.
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
driver.get(scrapeops_proxy_url)
Here is the complete code ready for production:
import os
import csv
import json
import logging
import time
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
from urllib.parse import urlencode
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
# Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
stars: float = 0
url: str = ""
sponsored: bool = False
price: float = 0.0
product_id: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
author_id: int = 0
rating: float = 0.0
date: str = ""
review: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.walmart.com/search?q={formatted_keyword}&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
# Set up Selenium WebDriver
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get(scrapeops_proxy_url)
logger.info(f"Received page: {url}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
item_list = json_data["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]
for item in item_list:
if item["__typename"] != "Product":
continue
name = item.get("name")
product_id = item["usItemId"]
if not name:
continue
link = f"https://www.walmart.com/reviews/product/{product_id}"
price = item["price"]
sponsored = item["isSponsoredFlag"]
rating = item["averageRating"]
search_data = SearchData(
name=name,
stars=rating,
url=link,
sponsored=sponsored,
price=price,
product_id=product_id
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
driver.quit() # Close the WebDriver
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver on error
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row.get("url")
tries = 0
success = False
options = Options()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
logger.info(f"Attempting to access URL: {scrapeops_proxy_url}")
driver.get(scrapeops_proxy_url)
logger.info(f"Status: {driver.title}")
# Wait for the page to load and get the script tag
time.sleep(3) # Adjust the sleep time as needed
script_tag = driver.find_element(By.CSS_SELECTOR, "script[id='__NEXT_DATA__'][type='application/json']")
json_data = json.loads(script_tag.get_attribute("innerHTML"))
review_list = json_data["props"]["pageProps"]["initialData"]["data"]["reviews"]["customerReviews"]
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review in review_list:
name = review["userNickname"]
author_id = review["authorId"]
rating = review["rating"]
date = review["reviewSubmissionTime"]
review_text = review["reviewText"]
review_data = ReviewData(
name=name,
author_id=author_id,
rating=rating,
date=date,
review=review_text
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {url}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
driver.quit() # Close the WebDriver
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads, retries=3):
logger.info(f"Processing {csv_file}")
with open(csv_file, newline="", encoding="utf-8") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader, # Pass each row in the CSV as the first argument to process_item
[location] * len(reader), # Location as second argument for all rows
[retries] * len(reader) # Retries as third argument for all rows
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION,max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 6: Production Run
For our production run, we will use the same settings as previously. We'll conduct a 4-page crawl with 3 threads.
Keep in mind that you can adjust your results by modifying the constants.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
# INPUT ---> List of keywords to scrape
keyword_list = ["laptop"]
aggregate_files = []
# Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION,max_threads=MAX_THREADS, retries=MAX_RETRIES)
Here are the final results from a full crawl and scrape.
- The full process finished in 939.41 seconds.
- Our crawl spat out a CSV with 160 laptop items and if you remember from earlier, a 4 page crawl was 49.06 seconds.
- 939.41 - 49.06 = 890.35 seconds scraping.
- 890.35 seconds / 160 pages = 5.56 seconds per page. This is even faster than our crawler.
Proxied scrapes often take between 7 and 10 seconds per page, and in some cases, they take even longer.
Legal and Ethical Considerations
Scraping data from Walmart is generally considered legal (depending on the country you reside in and their individual laws). Public data is generally considered fair to use.
Data behind a login page is different—it’s private and protected by privacy and intellectual property laws. If you're unsure whether your scraper is legal, it's best to consult an attorney.
However, when we scrape Walmart, we are subject to both their Terms of Service and their robots.txt. Violating their policies can lead to suspension and even deletion of your account.
You can view their terms here.
Walmart's robots.txt is available here.
Conclusion
You've made it to the end!
Along the way, you learned how to use Python's Selenium library. You’ve also covered key topics like parsing, pagination, storing data, concurrency, and working with proxies. Use these skills to build your next project!
If you'd like to learn more about the tech stack used in this site, take a look at the links below.
More Python Web Scraping Guides
At ScrapeOps, we've got tons of learning resources. We've got content for both new and experienced devs. Take a look at our Selenium Web Scraping Playbook.
If you want to read more from our "How To Scrape" series, check out the articles below.