
How To Bypass PerimeterX With Selenium
PerimeterX (nowadays known as HUMAN), like Cloudflare, DDosGuard, or DataDome, is a company that provides anti-bot security. It utilizes complex front-end (client-side) and back-end (server-side) technology to prevent scraping attempts on the websites it protects, much like Cloudflare, DDosGuard, or DataDome.
While PerimeterX presents a significant challenge for web scraping efforts, this guide will provide a comprehensive approach to overcoming these defenses using Python Selenium.
- Understanding PerimeterX
- How PerimeterX Detects Web Scrapers and Prevents Automated Access
- How to Bypass PerimeterX
- How to Bypass PerimeterX with Selenium
- Case Study: Bypassing PerimeterX on Zillow.com
- More Web Scraping Resources & Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Understanding PerimeterX
PerimeterX is a cybersecurity company that specializes in protecting websites and web applications from various online threats, including automated bot attacks like DDoS (Distributed Denial-of-Service).
Its purpose is to provide robust bot mitigation solutions, preventing malicious bots from compromising the security and integrity of websites.
Websites implement PerimeterX to prevent automated access, such as web scraping, for several reasons:
-
Protect their content: Websites that have valuable content, such as news articles, product information, or research data, are often targeted by web scrapers who want to steal this content and republish it elsewhere. PerimeterX can help websites protect their content by blocking bots that are trying to scrape it.
-
Prevent spam and abuse: Websites that allow users to create accounts or submit content are often targeted by spammers and abusers. PerimeterX can help websites prevent spam and abuse by blocking bots that are trying to create fake accounts, submit spam content, or carry out other malicious activities.
-
Improve website performance: Web scrapers can generate a lot of traffic, which can slow down a website and make it difficult for real users to access it. PerimeterX can help websites improve performance by blocking bots that are generating unnecessary traffic.
-
Comply with regulations: Some industries, such as finance and healthcare, have regulations that require websites to protect sensitive data. PerimeterX can help websites comply with these regulations by blocking bots that are trying to access sensitive data.
If your access is denied, you will see something like this:

How PerimeterX Detects Web Scrapers and Prevents Automated Access
PerimeterX (and other anti-web scraping services) combines both passive and active detection techniques to create a comprehensive bot detection solution.
It continuously analyzes request data and user behavior, adapting its strategies to stay ahead of evolving bot evasion techniques.
Below is a more detailed breakdown of how PerimeterX works, categorized into Client-side and Server-side techniques:
Client-Side Techniques:
-
JavaScript Injection : PerimeterX injects JavaScript code into the website's pages. This code collects information about the browser environment, including its capabilities, fonts, and installed plugins.
-
CAPTCHA Challenges: A CAPTCHA, which stands for Completely Automated Public Turing test to tell Computers and Humans Apart, is a type of challenge-response test used in computing to determine whether or not the user is human.
CAPTCHAs are designed to be easily solvable by humans but challenging for automated scripts or bots. Our primary goal here is to avoid triggering them at all and dont make them appear.
However, this goal is not always attainable, and you can use third-services like 2captcha to solve them.
-
DNS Monitoring: PerimeterX can also identify suspicious DNS activity, such as a large number of queries for a domain in a short period of time.
-
HTTP Header Analysis: PerimeterX analyzes the request headers, cookies, and IP address when a request is made to the website. It combines this client-side information with the request data to create a comprehensive user profile.
-
Session Tracking: PerimeterX tracks user sessions to identify suspicious patterns and durations.
Server-Side Techniques:
- Behavioral Analysis: Humans are prone to chaos while robots are very predictable in the way they behave, meaning it's really easy to make the difference between them.
For example, robots will mainly try to scrape a website in the same order than the links are presented, while a human will probably click everywhere, and in every link they're interested in.
A human will also take their time reading / watching a new page while most robots spends a tenth of second before switching, and make hundreds of requests in a few minutes while a human will only make a few.
- Fingerprinting: Anti-web scraping services often calculate a trust score for every visitor to a website as part of their bot mitigation and security measures.
The trust score is a dynamic value assigned to each user based on various factors that help determine the likelihood of the user being a legitimate human visitor or a potentially malicious bot.
This score is then used to make decisions about allowing or restricting access to the website.
- IP Monitoring and Blocking:
IPs are given reputation score and if you use an IP from a datacenter, or an IP that is known for exhibiting scraping or malicious behavior, you will be blocked by all anti-bot services.
You can check your IP quality score here.
How to Bypass PerimeterX
Successfully navigating PerimeterX's defenses requires fulfilling these fundamental prerequisites:
Use Residential & Mobile IPs
-
Since datacenter IP addresses are readily identifiable and can trigger automated detection mechanisms, it's crucial to employ residential or mobile IPs of superior quality.
-
These IPs, originating from residential or mobile networks, blend seamlessly with genuine user traffic, minimizing the risk of detection and ensuring uninterrupted access to websites and services.
Rotate Real Browser Headers
-
When making HTTP requests using a library like requests, it's crucial to ensure that the provided headers align with those typically sent by a web browser.
-
This becomes particularly important when establishing secure connections using Transport Layer Security (TLS).
Use Headless Browsers
-
In today's dynamic web environment, automated browsers like Selenium, Puppeteer, and Playwright have become essential tools for web scraping, testing, and data collection.
-
However, as websites and anti-bot technologies become more sophisticated, it is increasingly important to use fortified versions of these browsers to avoid detection and maintain scraping success.
How to Bypass PerimeterX with Selenium
Selenium is really easy to detect in its unpatched version. PerimeterX being an extremely sophisticated anti-bot system, it will always detect Selenium.
For example, if PerimeterX get the navigator.webdriver value of our bot, the output will be "True" to signal that automation is in progress, while in a regular browser the output will either be "undefined" or "false".
To have any chance of doing so you need to use either Selenium Undetected Chromedriver or Selenium-stealth in combination with residential/mobile proxies and rotating user-agents.
However, it isn't guaranteed as PerimeterX can often still detect you based on the security settings set on the website.
In the following sections we will show you how to approach setting up Selenium Undetected Chromedriver and Selenium-stealth to try and bypass PerimeterX, and also show you how to use Smart Proxies like ScrapeOps Proxy Aggregator to bypass PerimeterX.
Option 1: Bypass PerimeterX Using Selenium Undetected Chromedriver
Selenium Undetected Chromedriver is a fortified headless browser, meaning most of the leaks that would reveal the nature of your bot are patched.
A basic implementation of Selenium Undetected Chromedriver would look like this:
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get('https://httpbin.org/anything')
We will improve our bot by using up-to-date and rotating user-agents, by using this list of Chrome's versions
import undetected_chromedriver as uc
import random
user_agents_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.3",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.1",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.3",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.4",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.6",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0"
]
# This allow to set a list of options for our initialization of our WebDriver
options = uc.ChromeOptions()
# Pick a random user agent in the list
options.add_argument(f'user-agent={random.choice(user_agents_list)}')
# Initialize Chrome WebDriver with the specified options
driver = uc.Chrome(options=options)
# Make a request to your target website.
driver.get('https://httpbin.org/anything')
# Close the driver
driver.quit()
You can also add proxies, with residential proxies being the best quality:
# Be careful, you need to provide proxy_address and proxy_port yourself!
options.add_argument(f'--proxy-server={proxy_address}:{proxy_port}')
Keep in mind that employing your own IP address for web scraping activities can negatively impact your IP reputation, which you can check here.
If you want to go more in-depth on how to setup Selenium Undetected Chromedriver, I suggest reading this tutorial.
Option 2: Bypass PerimeterX Using Selenium-stealth
Selenium-stealth is another fortified headless browser, using a different approach than Chromedriver.
Sometimes, one will trigger the security and the other will not, making it always worth a try. However, I would always try Chromedriver first, since it is patched more frequently.
A basic implementation of Selenium Stealth would look like this:
from selenium import webdriver
from selenium_stealth import stealth
driver = webdriver.Chrome()
stealth(driver,
languages=["en-US", "en"],
platform="Archlinux"
)
url = "https://httpbin.org/anything"
driver.get(url)
driver.save_screenshot('httpanything_stealth.png')
driver.quit()
Your screenshots should like this:

We will improve our bot by using up-to-date and rotating user-agents, by using this list of Chrome's versions
from selenium import webdriver
from selenium_stealth import stealth
import random
user_agents_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.3",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.1",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.3",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.4",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.6",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0"
]
# This allow to set a list of options for our initialization of our WebDriver
options = webdriver.ChromeOptions()
# Pick a random user agent in the list
options.add_argument(f'user-agent={random.choice(user_agents_list)}')
# Initialize Chrome WebDriver with the specified options
driver = webdriver.Chrome(options=options)
stealth(driver,
languages=["en-US", "en"],
platform="Archlinux"
)
url = "https://httpbin.org/anything"
driver.get(url)
driver.save_screenshot('httpanything_stealth.png')
driver.quit()
Your screenshots should like this:
Option 3: Bypass PerimeterX Using ScrapeOps Proxy Aggregator
While open-source pre-fortified headless browsers offer a cost-effective solution, they come with inherent drawbacks.
Anti-bot companies like PerimeterX can readily analyze these open-source bypass methods, allowing them to quickly patch the vulnerabilities exploited.
As a result, open-source PerimeterX bypasses often have a limited lifespan, becoming ineffective within a couple of months.
A more reliable alternative is to utilize smart proxies with proprietary PerimeterX bypass mechanisms. These proxies are developed and maintained by proxy companies with a financial incentive to stay ahead of PerimeterX's detection strategies.
They continuously refine their bypass methods to ensure they remain functional, even as PerimeterX introduces new countermeasures.
ScrapeOps Proxy Aggregator integrates over 20 proxy providers into a single API, automatically selecting the most suitable and cost-effective proxy for your specific target domains.
Activating ScrapeOps' PerimeterX Bypass is as simple as adding bypass=PerimeterX to your API request.
This ensures that your requests are routed through the most effective and affordable PerimeterX bypass available for your target domains.
You can get a ScrapeOps API key with 1,000 free API credits by signing up here.
It is the most time and cost efficient way to ensure consistants results.
Case Study: Bypassing PerimeterX on Zillow.com
As the most-visited real estate website in the United State, Zillow needs a top-tier technology to protect themselves from attacks and chose PerimeterX.
This is the homepage if we visit the website with our regular browser:
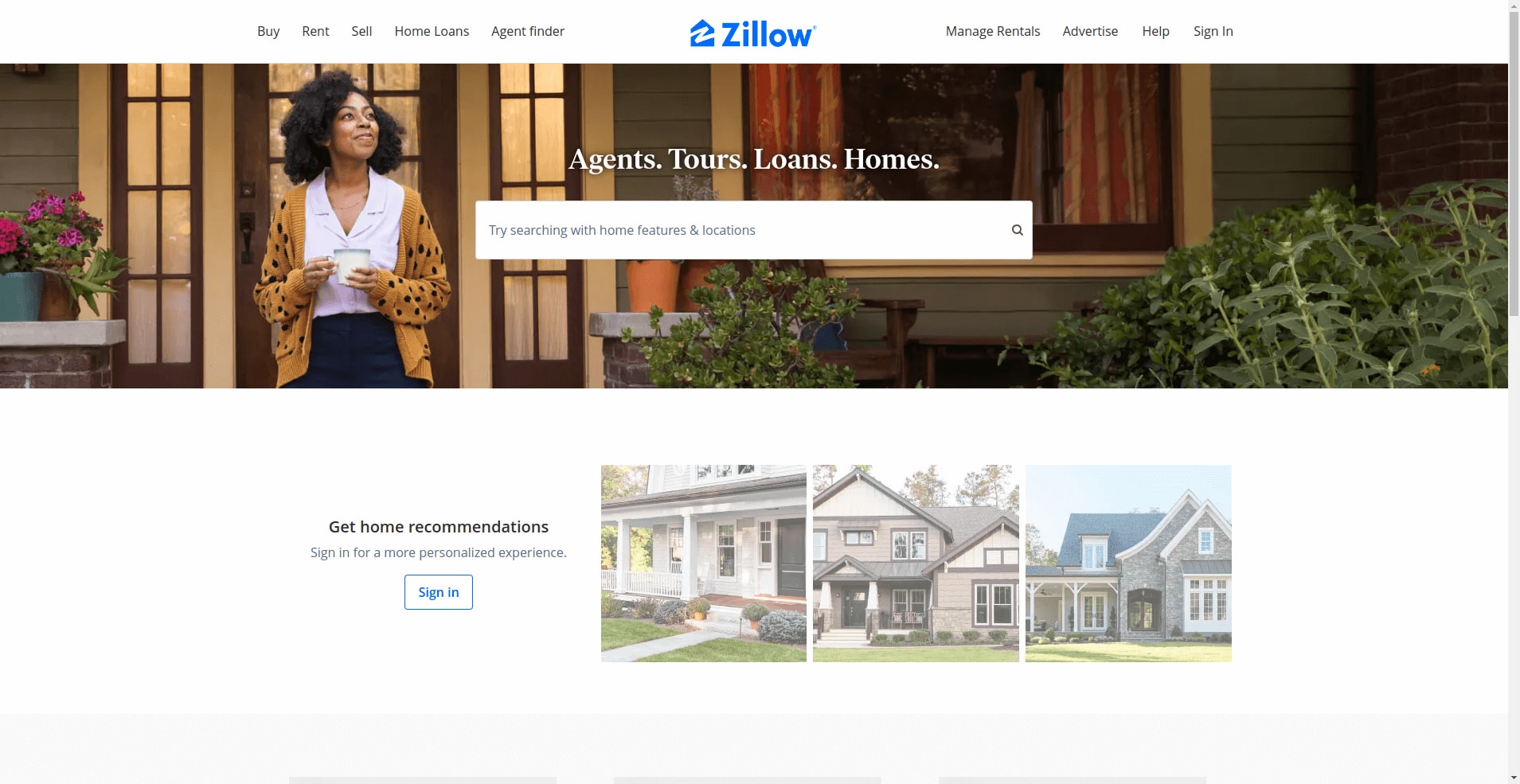
And now when we try with Selenium:
We will try both Selenium Undetected Chromedriver and ScrapeOps Proxy Aggregator to bypass their PerimeterX protection and compare the results.
Scraping Zillow With Selenium Undetected Chromedriver
We will try to scrape Zillow with Selenium Undetected Chromedriver. Here is what our starting code looks like:
import undetected_chromedriver as uc
import random
user_agents_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.3",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.1",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.3",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.4",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.6",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/118.0"
]
options = uc.ChromeOptions()
# We randomly pick one user-agent and use it throughout the scraping to stay consistant
options.add_argument('--headless')
options.add_argument(f'user-agent={random.choice(user_agents_list)}')
options.add_argument(f'--proxy-server={proxy_address}:{proxy_port}')
driver = uc.Chrome()
driver.get('https://www.zillow.com/')
driver.save_screenshot('zillow.png')
At the time I am writing this article, this worked, but I got blocked after trying to scrape more of the website. If your screenshot ressemble this:
You need to start reverse engineering the code.
Let's take a look at what the content of the response is by adding this to our code:
body = driver.page_source
print(body)
While we could attempt to reverse engineer the code shown here, this is a rather intricate process that will require a dedicated article.
Scraping Zillow With ScrapeOps Proxy Aggregator
I picked a random product page of Zillow.com and decided to use requests to implement ScrapeOps Proxy Aggregator. Without using the API my code looks like this:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.zillow.com/homedetails/xx-xxx-xx-xx-x-xxx-xx-xxxx/xxxxxx_zpid/')
driver.save_screenshot('zillow_scrapeops')
And of course, the result looks like this:
Let's try with ScrapeOps!
To implement it, I highly recommand Selenium-wire. Otherwise, it is needlessly complicated to use proxies with selenium.
from seleniumwire import webdriver
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
## Define ScrapeOps Proxy Port Endpoint
proxy_options = {
'proxy': {
'http': f'http://scrapeops.headless_browser_mode=true:{SCRAPEOPS_API_KEY}@proxy.scrapeops.io:5353',
'https': f'http://scrapeops.headless_browser_mode=true:{SCRAPEOPS_API_KEY}@proxy.scrapeops.io:5353',
'no_proxy': 'localhost:127.0.0.1'
}
}
## Set Up Selenium Chrome driver
driver = webdriver.Chrome(seleniumwire_options=proxy_options)
## Send Request Using ScrapeOps Proxy
driver.get('https://www.zillow.com/homedetails/xx-xxx-xx-xx-x-xxx-xx-xxxx/xxxxxx_zpid/')
driver.save_screenshot('zillow_with_proxy.png')
And our screenshot appears like this:

We can see it works flawlessly!
More Web Scraping Resources & Guides
In the dynamic landscape of web scraping, successfully navigating sophisticated anti-bot systems like PerimeterX requires a combination of strategic approaches.
While this guide provides insights into using Selenium Undetected Chromedriver, Selenium-stealth, and ScrapeOps Proxy Aggregator, it's essential to stay informed and explore additional resources.
For a deeper dive into Selenium and its capabilities, refer to The Selenium Documentation.
Want to learn more but don't know where to start? Check our guides below: