
How to Bypass DataDome with Selenium
Web scraping has become an essential tool for extracting valuable information from websites. However, many websites are equipped with anti-scraping measures, such as DataDome, to protect their data and resources.
In this article, we'll explore the challenges posed by DataDome and delve into a practical solution using Selenium to bypass its protections.
- What is DataDome
- Why Websites Implement DataDome
- How DataDome Detects Web Scrapers and Prevents Automated Access
- Datadome Block Page Examples
- How to Bypass DataDome
- How to Bypass DataDome Using Selenium
- Case Study: Bypassing DataDome on Zillow.com
- More Web Scraping Tutorials
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
What is DataDome
DataDome is a web security platform designed to detect and prevent automated traffic, including web scraping bots.
Its primary purpose is to safeguard websites from data theft, unauthorized access, and other malicious activities.
Why Websites Implement DataDome
Now, you might be wondering, why do websites bother implementing something like DataDome?
Well, imagine you have a treasure trove of data on your website. That could include product listings, user reviews, or any other valuable information.
You want real, engaged users to access and interact with this content. However, there are bots out there that could scrape and misuse your data for various purposes.
Websites implement DataDome as a defense mechanism to safeguard their valuable resources from the intrusive actions of automated bots.
This protective measure serves multiple purposes.
- For example, it prevents competitors from automatically harvesting data.
- It plays a vital role in maintaining a fair user experience by curtailing data overuse, ensuring that genuine users can access and interact with the website without facing disruptions caused by automated activities.
Furthermore, DataDome acts as a shield to protect sensitive information from being collected inappropriately, reinforcing the overall security and integrity of the website's content and user data
How DataDome Detects Web Scrapers and Prevents Automated Access
DataDome is like a guardian standing at the entrance of a website, equipped with tools to protect against unwanted intruders, especially automated ones like web scrapers.
DataDome utilizes a combination of sophisticated techniques to identify and block web scrapers. One key concept is the trust score assigned to each visitor. The trust score is a measure of how likely a visitor is to be a human user rather than an automated bot.
DataDome calculates a trust score for every visitor based on their behavior and characteristics. This score is influenced by various factors, including:
Behavioral Analysis
Behavioral analysis, in simple terms, involves examining how people interact with a website and looking for patterns that distinguish human behavior from automated actions.
For example, if you typically move your mouse in a certain way, click on specific buttons, and scroll down the page when using a website, behavioral analysis would detect if a program is behaving differently.
This could include instances where a script is moving the mouse unnaturally fast or interacting with the website in an automated, non-human manner.
Fingerprinting
Fingerprinting is akin to creating a unique ID for your device based on various characteristics such as your browser type, operating system, and installed plugins. It's like giving your device a digital fingerprint.
For instance, if you visit a website using Chrome on Windows with certain plugins installed, the website can create a "fingerprint" of your system.
If this fingerprint is repeatedly seen in a short time, it might indicate automated activity, like a bot attempting to scrape data.
CAPTCHA Challenges
CAPTCHA challenges are those familiar puzzles or tests that websites present to users to confirm they're human. These challenges are designed to distinguish between humans and automated bots.
For example, when signing up for a new account or performing certain actions on a website, you might encounter a CAPTCHA asking you to select all images containing a car. This ensures that you're a real person and not a script or bot.
IP Monitoring
IP monitoring involves keeping an eye on the Internet Protocol (IP) addresses that connect to a website. If certain IPs show suspicious behavior, they might be blocked.
For instance, if a website notices a large number of requests coming from a single IP address within a short period, it might interpret this as scraping behavior and respond by blocking or limiting access from that specific IP.
HTTP Header Analysis
HTTP header analysis involves examining the information contained in the headers of a user's request, such as the browser type, language, and referring website. Analyzing these headers helps identify automated requests.
For example, when your browser sends a request to a website, it includes headers with information about your browser and system.
If these headers appear unusual, such as a non-standard user agent, it might trigger suspicion of automated activity.
Session Tracking
Session tracking involves monitoring a user's interactions with a website over a period. Unusual patterns or prolonged sessions may indicate automated behavior.
For example, normal user sessions involve navigating through a few pages and then logging out.
If a program keeps interacting with a site for an extended period without typical breaks or logging out, it might trigger suspicion through session tracking.
DNS Monitoring
DNS monitoring involves observing Domain Name System (DNS) requests made by a user. Scraping bots may exhibit recognizable patterns in DNS requests.
For example, when you access a website, your computer translates the domain name into an IP address using DNS. Monitoring these translations can reveal patterns; for instance, a high frequency of DNS requests in a short time may indicate automated scraping activities.
Datadome Block Page Examples
To give you a more tangible idea, imagine you're trying to access a popular e-commerce site, say Leboncoin, Vinted, or Deezer, with a scraping bot.
DataDome might intercept your request and redirect you to a block page. This page is like a digital "stop sign" telling you, "Hey, we know you're up to something automated, and you're not welcome here."
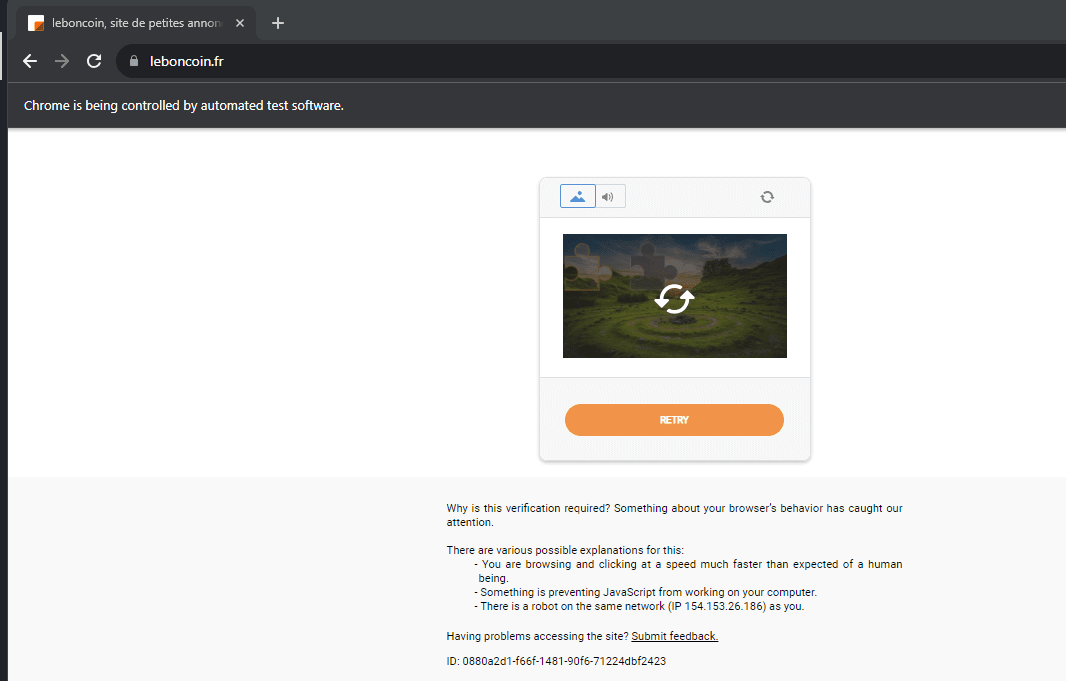
For example, in the above screenshot, DataDome has detected that a bot is controlling the browser accessing the Leboncoin website. So, it blocks the access.
How to Bypass DataDome
1. Use Residential & Mobile IPs:
Residential IP addresses are assigned by Internet Service Providers (ISPs) to homeowners. Mobile IPs, on the other hand, are the IP addresses assigned to mobile devices when they connect to the internet through a cellular network.
Using residential or mobile IPs is essential for web scraping to mimic human behavior and avoid getting blocked by websites.
DataDome is more likely to block requests from data center IPs, which are commonly associated with bots and scrapers.
You can use a service that provides residential or mobile proxies, and integrate them into your web scraping code.
Here's an example using the popular requests library in Python:
Install requirements
pip install requests
Use
import requests
# Set the proxy to a residential or mobile IP
proxy = {
"http": "http://your_residential_ip:port",
"https": "https://your_residential_ip:port",
}
# Make a request using the proxy
response = requests.get("https://example.com", proxies=proxy)
print(response.text)
2. Use Rotate Real Browser Headers
Rotating real browser headers involves periodically changing the HTTP headers in your requests to mimic the behavior of a real web browser.
Headers include information like user-agent, which identifies the browser and operating system.
DataDome can detect automated requests based on headers. By rotating real browser headers, you make your requests look more like genuine user traffic, reducing the chances of being detected as a scraper.
Here's an example using the requests library in Python with headers rotation:
Install requirements
pip install fake-useragent
Use
import requests
from fake_useragent import UserAgent
import time
# Function to get a random user agent
def get_random_user_agent():
ua = UserAgent()
return ua.random
# Make a request with a rotated user agent
for _ in range(5): # rotate headers 5 times
headers = {'User-Agent': get_random_user_agent()}
response = requests.get('https://example.com', headers=headers)
print(response.text)
time.sleep(2) # Add a delay between requests
3. Use Headless Browsers
Headless browsers are web browsers without a graphical user interface. They run in the background, allowing automation of browser actions. Examples include Selenium, Puppeteer, and Playwright.
Headless browsers enable you to interact with websites like a real user, rendering JavaScript and handling dynamic content. They are crucial for scraping modern websites that heavily rely on client-side rendering.
Here's an example using Selenium to scrape data from Deezer:
Install requirements
pip install selenium
pip install webdriver-manager
Use
# Import necessary modules for Selenium and ChromeDriver setup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Import modules for Selenium WebDriverWait and expected conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Initialize the ChromeDriver with the appropriate service and options
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# Navigate to the specified URL
driver.get('https://www.deezer.com/en/channels/explore/')
# Maximize the browser window for better visibility
driver.maximize_window()
# Wait for the privacy 'Accept' pop-up button to be visible
wait = WebDriverWait(driver, 10)
wait.until(EC.visibility_of_element_located((By.ID, "gdpr-btn-accept-all")))
# Find and click the 'Accept' button on the privacy pop-up
agree_button = driver.find_element(By.XPATH, "//button[text()='Accept']")
agree_button.click()
# Scrape channel categories
categories = driver.find_elements(By.CLASS_NAME, 'picture-img')
# Print the text of each non-empty category
[print(category.text) for category in categories if category.text]
How to Bypass DataDome Using Selenium
DataDome is an extremely sophisticated anti-bot system meaning it is hard to bypass with Selenium. To have any chance of doing so you need to use either Selenium Undetected Chromedriver or Selenium-stealth in combination with residential/mobile proxies and rotating user-agents. However, it isn't guarenteed as DataDome can often still detect you based on the security settings set on the website.
In the following sections we will show you how to approach setting up Selenium Undetected Chromedriver and Selenium-stealth to try and bypass DataDome, and also show you how to use Smart Proxies like ScrapeOps Proxy Aggregator to bypass DataDome.
Option 1: Bypass DataDome Using Selenium Undetected Chromedriver
Selenium Undetected Chromedriver is a modified version of the ChromeDriver that aims to make automated browser interactions less detectable by anti-bot mechanisms. It incorporates various techniques to mimic human-like behavior, reducing the likelihood of being identified as a bot by services like DataDome.
Install Required Packages:
pip install undetected-chromedriver
Import and Initialize UndetectedChromedriver
from undetected_chromedriver import ChromeOptions, Chrome
import random
# Import modules for Selenium WebDriverWait and expected conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
options = ChromeOptions()
# Customize options as needed
options.add_argument("--headless")
driver = Chrome(options=options)
The ChromeOptions class helps you customize the settings of the Chrome browser, and the Chrome class is used to create an instance of the Chrome browser with the specified options. These classes provide flexibility in configuring the browser for different scenarios, such as headless mode, disabling extensions, and more.
Set Up Proxy and User-agents:
proxies = [
"187.95.229.112:8080",
"181.177.93.3:30309",
]
proxy = random.choice(proxies)
options.add_argument(f"--proxy-server={proxy}")
user_agents = [
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
]
user_agent = random.choice(user_agents)
options.add_argument(f"user-agent={user_agent}")
We have set up our web scraping tool to utilize proxies and mimic various user agents. First, we have defined a list of proxies, each representing different IP addresses and ports. Then, we randomly select one proxy from the list and update the ChromeOptions for our web browser by including this proxy using the --proxy-server argument.
Additionally, we have created a list of user agents to simulate different browsers and platforms. We randomly choose one user agent from this list, and we further modify the browser's configuration by adding the user-agent argument.
These steps are designed to enhance our anonymity and disguise our web scraping tool, making it appear as if we are accessing the website from different locations and devices.
Navigate and Scrape:
# Navigate to Deezer website
driver.get('https://www.deezer.com/en/channels/explore/')
# Wait for the privacy 'Accept' pop-up button to be visible
wait = WebDriverWait(driver, 10)
wait.until(EC.visibility_of_element_located((By.ID, "gdpr-btn-accept-all")))
# Find and click the 'Accept' button on the privacy pop-up
agree_button = driver.find_element(By.XPATH, "//button[text()='Accept']")
agree_button.click()
# Scrape channel categories
categories = driver.find_elements(By.CLASS_NAME, 'picture-img')
# Print the text of each non-empty category
[print(category.text) for category in categories if category.text]
# Close the browser window after scraping
driver.quit()
Lastly, we have navigated to the target website and scraped channel categories before closing the browser window.

Option 2: Bypass DataDome Using Selenium-stealth
Selenium-stealth refers to a browser automation tool that is an extension or a module built on top of the Selenium WebDriver framework. It enhances the capabilities of Selenium WebDriver by adding features that help users avoid detection or blocking by websites that employ various anti-automation techniques.
-
Install Required Packages:
pip install selenium webdriver-manager selenium-stealth -
Import Necessary Modules:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium_stealth import stealth
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random -
Set Up ChromeOptions: Customize ChromeOptions based on your requirements, such as adding options for residential proxies and rotating user agents.
# Create a ChromeOptions object
custom_options = webdriver.ChromeOptions()
# Run in headless mode
custom_options.add_argument("--headless")
# Disable the AutomationControlled feature of Blink rendering engine
custom_options.add_argument('--disable-blink-features=AutomationControlled')
# Disable pop-up blocking
custom_options.add_argument('--disable-popup-blocking')
# Start the browser window in maximized mode
custom_options.add_argument('--start-maximized')
# Disable extensions
custom_options.add_argument('--disable-extensions')
# Disable sandbox mode
custom_options.add_argument('--no-sandbox')
# Disable shared memory usage
custom_options.add_argument('--disable-dev-shm-usage')
# Initialize the ChromeDriver with the appropriate service and custom options
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=custom_options)
# Change the property value of the navigator for webdriver to undefined
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
# Step 3: Rotate user agents
custom_user_agents = [
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
]
# Select a random user agent
custom_user_agent = random.choice(custom_user_agents)
# Pass in the selected user agent as an argument
custom_options.add_argument(f'user-agent={custom_user_agent}')
# Set user agent using execute_cpd_cmd
driver.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent": custom_user_agent}) -
Initialize Selenium-stealth:
stealth(driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)The
stealthfunction helps your scraping script act more like a regular person's web browser to avoid getting caught.Here's what each part of the
stealthfunction does:driver(required):- This is just the web browser that your scraping script is using. The
stealthfunction tweaks the browser's settings to make it act less robot-like.
languages(optional, default=["en-US", "en"]):- It tells the browser which languages it prefers. The default values are set to English, so it looks like a regular English-speaking person is using the browser.
vendor(optional, default="Google Inc."):- This is like telling the website that your browser is made by a big company—Google, in this case.
platform(optional, default="Win32"):- It's like saying your computer is running on Windows 32-bit, which is a common setup for regular users.
webgl_vendor(optional, default="Intel Inc."):- This part deals with how the browser handles 3D graphics on the web. It's set to "Intel Inc." to match what a regular computer might have.
renderer(optional, default="Intel Iris OpenGL Engine"):- This is related to how the graphics are shown in the browser. It's set to something that sounds like a typical graphics engine you'd find in a computer.
fix_hairline(optional, default=True):- This is like a little fix for the browser to make sure thin lines on a webpage are displayed properly. It's set to True to avoid any issues.
- This is just the web browser that your scraping script is using. The
-
Navigate and Scrape: Navigate to the target website and implement your scraping logic within the opened browser window.
# Navigate to Deezer website
driver.get('https://www.deezer.com/en/channels/explore/')
# Wait for the privacy 'Accept' pop-up button to be visible
wait = WebDriverWait(driver, 10)
wait.until(EC.visibility_of_element_located((By.ID, "gdpr-btn-accept-all")))
# Find and click the 'Accept' button on the privacy pop-up
agree_button = driver.find_element(By.XPATH, "//button[text()='Accept']")
agree_button.click()
# Scrape channel categories
categories = driver.find_elements(By.CLASS_NAME, 'picture-img')
# Print the text of each non-empty category
[print(category.text) for category in categories if category.text] -
Close the Browser: Ensure you close the browser window using
driver.quit()after scraping.
driver.quit()
Option 3: Bypass DataDome Using ScrapeOps Proxy Aggregator
ScrapeOps Proxy Aggregator is an All-in-One API that is dedicated to avail to you more that 20 proxy providers from a single API. While Undetected Chromedriver and Selenium Stealth focus mainly on mimicking browser environments, ScrapeOps Proxy Aggregator specializes in making traffic appear more human-like.
The additional benefits include:
- Large, Diverse Proxy Pool: ScrapeOps offers access to millions of residential IPs from diverse subnets, allowing you to smoothly rotate IPs and mimic human browsing behavior. This is more effective than just rotating a handful of static proxies.
- Reliable Proxies: The proxies are continuously checked for reliability, speed, anonymity level, and other metrics. This helps avoid issues with dead or banned proxies which can break scripts.
- Quick IP Rotation: You can configure a proxy to rotate for every request, maintaining session continuity while presenting a new IP constantly. This level of rotation is hard to achieve with free or public proxies.
- Bandwidth Throttling: The proxies can simulate a variety of real-world connection speeds and device types. This better mimics human users.
- Works Alongside Other Tools: Using ScrapeOps complements solutions like Undetected Chromedriver rather than replacing them. The tools work together to enhance stealth.
As a result, it would be best to use ScrapeOps Proxy Aggregator if you prioritize convenience and reliability when bypassing DataDome with Selenium. Here is an example.
Case Study: Bypassing DataDome on Zillow.com
Assume we want to scrape services of Zillow. Let's write a Selenium Undetected Chromedriver that accesses the landing page then clicks on the navigation menu to Loans page.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
options = Options()
options.add_experimental_option('detach', True)
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get('https://www.zillow.com/')
driver.maximize_window()
loans_button = driver.find_element(By.XPATH, '//*[@id="page-header-container"]/header/nav/div[2]/ul[1]/li[4]/a/span')
loans_button.click()
What did you notice?
On clicking the link, Zillow detects we are accessing it using an automated bot and blocks further access. The bot gets blocked even if we use Selenium Undetected Chromedriver.

Can ScrapeOps Proxy Aggregator bypass the restriction?
Scraping Zillow.com With ScrapeOps Proxy Aggregator
To use the ScrapeOps Proxy Aggregator, you need to create an account, which lets you use an API key. Start by clicking the signup link. Next, enter your details, verify your email and access the homepage, that displays your API key.
After that, you can crawl and access the pages as follows:
# from selenium import webdriver # If using selenium instead of seleniumwire
from seleniumwire import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# from api_config import API_KEY
SCRAPEOPS_API_KEY = 'YOUR_SCRAPEOPS_API_KEY'
# Define ScrapeOps Proxy Port Endpoint
seleniumwire_options = {
'proxy': {
'http': f'http://scrapeops.headless_browser_mode=true:{SCRAPEOPS_API_KEY}@proxy.scrapeops.io:5353',
'https': f'https://scrapeops.headless_browser_mode=true:{SCRAPEOPS_API_KEY}@proxy.scrapeops.io:5353',
'no_proxy': 'localhost,127.0.0.1',
}
}
# Set up Selenium Chrome options with proxy
chrome_options = Options()
chrome_options.add_argument('--ignore-certificate-errors')
# Set up Selenium Chrome driver with seleniumwire_options
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=chrome_options,
seleniumwire_options=seleniumwire_options
)
# Send Request Using ScrapeOps Proxy
driver.get('https://www.zillow.com/')
# # Example interaction with the webpage
loans_button = driver.find_element(By.XPATH, '//*[@id="page-header-container"]/header/nav/div[2]/ul[1]/li[4]/a/span')
loans_button.click()
More Selenium Web Scraping Guides
In this guide, we presented practical solutions to bypass DataDome using Selenium, a popular web automation tool. We advocated three options:
- Leverage Residential & Mobile IPs
- Rotate Real Browser Headers
- Use Headless Browsers
If you would like to learn more about Web Scraping with Selenium, then be sure to check out The Selenium Web Scraping Playbook.
Or check out one of our more in-depth guides: