
How to Bypass Cloudflare with Selenium
Navigating Cloudflare's robust anti-bot measures, such as JavaScript challenges and CAPTCHA, poses a significant challenge for web scraping.
While Selenium can bypass Cloudflare's defenses by simulating real browser behavior, it requires more resources and careful handling to avoid detection and ensure ethical scraping practices.
In this article, we'll explore the challenges posed by Cloudflare and delve into a practical solution using Selenium to bypass its protections.
- Understanding Cloudflare
- How Cloudflare Detects Web Scrapers and Prevents Automated Access
- How to Bypass Cloudflare
- How to Bypass Cloudflare with Selenium
- Case Study: Bypassing Cloudflare on Zillow.com
- Conclusion
- More Web Scraping Resources & Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Understanding Cloudflare
Cloudflare is a security service widely used by websites to safeguard against malicious activities, including automated web scraping, by employing techniques like CAPTCHA challenges and JavaScript validations.
Websites implement Cloudflare to protect sensitive data and maintain website performance by preventing unauthorized automated access, proving effective in distinguishing between human users and bots.
A typical Cloudflare block page, as seen on sites like Zillow, displays a CAPTCHA or a security check message, indicating the detection of unusual traffic from the user's network.
How Cloudflare Detects Web Scrapers and Prevents Automated Access
To effectively combat web scraping, Cloudflare employs a sophisticated mix of passive and active detection methods.
- Passive techniques include scrutinizing HTTP request headers, analyzing IP address reputations, and utilizing TLS and HTTP/2 fingerprinting to identify unusual traffic patterns.
- Actively, Cloudflare challenges users with CAPTCHAs, employs canvas fingerprinting, and queries browser environments to differentiate between human and automated interactions.
This comprehensive approach, which includes monitoring for inconsistencies in browser API usage and user interaction patterns, makes Cloudflare a robust barrier against unauthorized scraping activities.
Passive Bot Detection Techniques
- Detecting botnets:
- In its passive bot detection arsenal, Cloudflare employs techniques to identify devices suspected of being part of botnets, networks of compromised computers controlled by malicious entities.
- When such a device is detected, Cloudflare either automatically blocks access or presents additional client-side challenges, such as CAPTCHAs, to verify the legitimacy of the traffic and ensure it's not originating from an automated source.
- IP address reputation:
- Cloudflare's IP address reputation system assigns a score to each user accessing a website, often referred to as a risk or fraud score.
- This score is calculated based on various factors including the user's geolocation, Internet Service Provider (ISP), and the historical reputation of the IP address, helping Cloudflare to assess the likelihood of the traffic being malicious or part of a web scraping attempt.
- HTTP request headers:
- Cloudflare analyzes HTTP request headers as a key part of its passive bot detection strategy.
- By examining these headers, which include details like the user-agent, accept-language, and cookie settings, Cloudflare can identify patterns and anomalies indicative of automated bots, as opposed to organic human traffic.
- TLS fingerprinting:
- TLS fingerprinting is a technique used by Cloudflare to enhance its bot detection capabilities.
- It involves analyzing the TLS (Transport Layer Security) configuration and characteristics of a client's connection request to the server.
- This analysis helps Cloudflare identify the specific type of client or browser being used, enabling it to detect and flag potential automated bots based on unusual or atypical TLS fingerprints that differ from those of standard web browsers.
- HTTP/2 fingerprinting:
- HTTP/2 fingerprinting is another critical technique utilized by Cloudflare in its bot detection process.
- This method involves verifying that the combination of the HTTP/2 protocol fingerprint and the user-agent string in a request matches a known, legitimate pair that is whitelisted in Cloudflare's database.
- This verification helps Cloudflare ascertain the authenticity of the request, effectively filtering out those that might be originating from automated scraping tools or malicious bots.
Active Bot Detection Techniques
- CAPTCHAs:
- Cloudflare actively employs CAPTCHAs as a method to distinguish between human users and automated bots.
- The decision to present a CAPTCHA to a user is based on various factors, including the specific configuration settings of the website and the assessed risk level of the user's behavior or IP address reputation.
- Canvas fingerprinting:
- Cloudflare utilizes canvas fingerprinting, a technique that leverages machine learning, to detect spoofing of device properties such as the user-agent, operating system, or GPU.
- This method involves analyzing the canvas fingerprint - a unique identifier generated based on how a browser renders graphical content.
- Cloudflare compares this fingerprint against expected values, looking for mismatches that could indicate the presence of a bot or scraper attempting to disguise its true nature.
- Event tracking:
- Continuing with Cloudflare's active bot detection strategies, event tracking plays a pivotal role.
- Cloudflare monitors user interactions such as mouse movements and keyboard usage.
- A consistent absence of these interactions can signal to Cloudflare that the user might be a bot, as typical human browsing involves such activities.
- Environment API querying:
- In addition to the previously discussed methods, Cloudflare employs environment API querying as a sophisticated technique in its active bot detection arsenal.
- This approach leverages the multitude of Web APIs available in a browser, which can provide insightful data for distinguishing between human users and bots.
- By analyzing how these APIs are accessed and used, Cloudflare can detect anomalies or patterns that are indicative of automated scraping tools, further fortifying its defense against unauthorized web access.
- Browser-specific APIs. Delving deeper into Cloudflare's environment API querying, one key aspect is the analysis of browser-specific APIs. Cloudflare scrutinizes the consistency between the browser's behavior and the user-agent string it presents. For instance, if the data sent to Cloudflare suggests the use of a Chrome browser, but the user-agent indicates Firefox, this discrepancy raises a red flag.
- Timestamp APIs. Cloudflare employs timestamp APIs, such as
Date.now()orwindow.performance.timing.navigationStart, to track user speed metrics. This tracking is crucial in distinguishing human users from bots, as it analyzes the timing of activities on the website. If these timestamps reveal patterns that are not consistent with typical human browsing, like actions executed too rapidly, Cloudflare may identify and block the user, suspecting automated bot activity. - Automated Browser Detection. Cloudflare has specific checks to identify the use of automated browsers commonly used in web scraping, such as Selenium and PhantomJS.
It looks for unique properties like
window.document.\__selenium_unwrappedorwindow.callPhantom, which are indicative of these tools. - Sandboxing Detection. Cloudflare implements measures to detect and prevent the use of emulated browser environments, which are often employed in attempts to bypass security challenges. This includes environments like NodeJS using JSDOM, where a simulated browser is created to automate interactions with web pages. Cloudflare's ability to identify such sandboxing techniques is crucial in its efforts to block scraping activities that attempt to mimic genuine browser behavior without actually using a real browser.
How to Bypass Cloudflare
Building on our understanding of Cloudflare's sophisticated detection methods, bypassing its anti-bot protections requires a nuanced and strategic approach. To successfully navigate through these defenses, it's essential to integrate several key principles and techniques:
Use Residential & Mobile IPs
A crucial strategy in bypassing Cloudflare's defenses involves using high-quality residential or mobile IP addresses. These IPs are less likely to be flagged by Cloudflare's security systems, as they appear as genuine user addresses, blending in with regular internet traffic.
This approach significantly reduces the risk of being detected as a bot or scraper, enhancing the effectiveness of your web scraping efforts.
Rotate Real Browser Headers
To further evade detection by Cloudflare, it's important to rotate real browser headers, including adopting HTTP/2 protocols.
This involves using headers that mimic those of actual web browsers, ensuring they are in the correct order and format as they would appear in genuine human traffic.
Regularly changing these headers helps prevent pattern recognition by Cloudflare's systems, making your scraping activities less distinguishable from normal user behavior.
Use Headless Browsers
Utilizing headless browsers is a key tactic in bypassing Cloudflare's protections.
Tools like Selenium, Puppeteer, or Playwright, when configured correctly, can automate web browsing without the overhead of a graphical user interface.
It's crucial to fortify these browsers so they don't leak identifiable fingerprints, making them resemble a regular browser as closely as possible. This approach helps in evading detection mechanisms that rely on identifying the unique characteristics of automated browsers.
How to Bypass Cloudflare with Selenium
Bypassing Cloudflare's advanced anti-bot system using Selenium is challenging due to its sophisticated detection methods.
To increase the chances of success, it's recommended to use specialized tools like Selenium Undetected Chromedriver or Selenium-stealth, combined with residential or mobile proxies and rotating user-agents.
However, success isn't guaranteed, as Cloudflare's detection can vary based on the security settings of the target website.
The upcoming sections will guide you through setting up Selenium Undetected Chromedriver and Selenium-stealth for this purpose, and introduce the use of Smart Proxies, such as ScrapeOps Proxy Aggregator, as an alternative method to bypass Cloudflare.
Option 1: Bypass Cloudflare Using Selenium Undetected Chromedriver
Selenium Undetected Chromedriver is a specialized version of ChromeDriver, designed specifically to avoid detection by sophisticated anti-bot systems like Cloudflare.
This tool is particularly useful for web scraping tasks, as it can effectively mimic human-like interactions with web pages, thereby reducing the likelihood of triggering security measures that typically block automated scraping activities.
Step 1: Installation
To begin using Selenium Undetected Chromedriver, you first need to install the package. This can be done easily using pip, Python's package installer. Run the following command in your terminal or command prompt to install:
pip install undetected-chromedriver
Step 2: Setting Up the Driver
Once installed, you can set up the undetected ChromeDriver in your Python script. Start by importing the necessary module and setting up Chrome options to customize the browser's behavior. Here's how you can do it:
import seleniumwire.undetected_chromedriver as uc
## Set chrome Options
chrome_options = uc.ChromeOptions()
## Disable loading images for faster crawling
chrome_options.add_argument('--blink-settings=imagesEnabled=false')
Step 3: Configuring Proxies
To further enhance the ability to bypass Cloudflare, you can configure proxies with Selenium Undetected Chromedriver.
Here are two options for setting up proxies:
1. Using Proxy Options
In this method, you define a dictionary of proxy settings and then create the Chrome driver with these settings:
chrome_options = uc.ChromeOptions()
## Proxy Options
proxy_options = {
'proxy': {
'http': 'http://user:pass@ip:port',
'https': 'https://user:pass@ip:port',
'no_proxy': 'localhost,127.0.0.1'
}
}
## Create Undetected Chromedriver with Proxy
driver = uc.Chrome(
options=chrome_options,
seleniumwire_options=proxy_options
)
2. Direct Proxy Setting
Since Selenium does not natively support proxy authentication, you can use a custom Chrome extension to handle authenticated proxies. This method dynamically creates an extension that configures the proxy settings and injects authentication credentials, allowing seamless integration with Selenium. Here's how to implement it:
import os
import shutil
import tempfile
import undetected_chromedriver as webdriver
import time
class ProxyExtension:
"""Class to create and manage a Chrome proxy extension."""
manifest_json = """
{
"version": "1.0.0",
"manifest_version": 2,
"name": "Chrome Proxy",
"permissions": [
"proxy",
"tabs",
"unlimitedStorage",
"storage",
"<all_urls>",
"webRequest",
"webRequestBlocking"
],
"background": {"scripts": ["background.js"]},
"minimum_chrome_version": "76.0.0"
}
"""
background_js = """
var config = {
mode: "fixed_servers",
rules: {
singleProxy: {
scheme: "http",
host: "%s",
port: %d
},
bypassList: ["localhost"]
}
};
chrome.proxy.settings.set({value: config, scope: "regular"}, function() {});
function callbackFn(details) {
return {
authCredentials: {
username: "%s",
password: "%s"
}
};
}
chrome.webRequest.onAuthRequired.addListener(
callbackFn,
{ urls: ["<all_urls>"] },
['blocking']
);
"""
def __init__(self, host, port, user, password):
"""Initialize the proxy extension with the given proxy details."""
self._dir = os.path.normpath(tempfile.mkdtemp())
self._create_extension_files(host, port, user, password)
def _create_extension_files(self, host, port, user, password):
"""Create the manifest.json and background.js files for the extension."""
manifest_file = os.path.join(self._dir, "manifest.json")
with open(manifest_file, mode="w") as f:
f.write(self.manifest_json)
background_js = self.background_js % (host, port, user, password)
background_file = os.path.join(self._dir, "background.js")
with open(background_file, mode="w") as f:
f.write(background_js)
@property
def directory(self):
"""Return the directory where the extension files are stored."""
return self._dir
def cleanup(self):
"""Clean up the temporary directory."""
if os.path.exists(self._dir):
shutil.rmtree(self._dir)
def setup_driver_with_proxy(proxy_details):
"""
Set up undetected_chromedriver with a proxy extension.
Args:
proxy_details (tuple): A tuple containing (host, port, username, password).
Returns:
webdriver.Chrome: A Chrome driver instance configured with the proxy.
"""
proxy_extension = ProxyExtension(*proxy_details)
options = webdriver.ChromeOptions()
options.add_argument(f"--load-extension={proxy_extension.directory}")
driver = webdriver.Chrome(options=options)
return driver, proxy_extension
if __name__ == "__main__":
# Define your proxy details
proxy = ("HOST", 00000, "USERNAME", "PASSWORD") # Host,Port,Username,Password
# Set up the driver with the proxy
driver, proxy_extension = setup_driver_with_proxy(proxy)
try:
# Visit a URL to test the proxy
driver.get("https://api64.ipify.org")
time.sleep(5)
print("IP Address:", driver.find_element("tag name", "body").text)
finally:
# Clean up the driver and extension
driver.quit()
proxy_extension.cleanup()
Step 4: Implement User-Agent Rotation
To implement user-agent rotation in your web scraping script. Here's how you can set it up in your Python script using Selenium Undetected Chromedriver:
user_agents = [
# Add your list of user agents here
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 13_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
]
# select random user agent
user_agent = random.choice(user_agents)
# pass in selected user agent as an argument
options.add_argument(f'--user-agent={user_agent}')
# Initialize the WebDriver
driver = uc.Chrome(options=options)
For a more comprehensive understanding and additional details on using Selenium Undetected Chromedriver, you can check our to the extensive guide Selenium Undetected Chromedriver guide
Option 2: Bypass Cloudflare Using Selenium-stealth
Selenium-stealth is a Python library designed to make Selenium-driven browsers appear as regular, non-automated browsers.
This is particularly useful for bypassing sophisticated anti-bot measures like those implemented by Cloudflare.
Selenium-stealth applies various techniques to mask Selenium's automation traits, such as modifying JavaScript navigator properties, removing known Selenium traces, and more, to prevent detection.
To use Selenium-stealth for bypassing Cloudflare, follow these steps:
Step 1: Install Selenium-stealth
First, you need to install the Selenium-stealth package. You can do this using pip:
pip install selenium-stealth
Step 2: Import Necessary Modules
In your Python script, import Selenium, Selenium-stealth, and other necessary modules:
from selenium import webdriver
from selenium_stealth import stealth
import random
Step 3: Initialize WebDriver with Selenium-stealth
Create an instance of the WebDriver and apply Selenium-stealth settings to it:
options = webdriver.ChromeOptions()
# Add user-agent rotation
user_agents = [
# Your list of user agents goes here
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)...',
# More user agents
]
user_agent = random.choice(user_agents)
options.add_argument(f"user-agent={user_agent}")
# Initialize the WebDriver with options
driver = webdriver.Chrome(options=options)
# Apply stealth settings to the driver
stealth(driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
Step 4: Use Residential Proxies
To further enhance the chances of bypassing Cloudflare, use residential proxies. Here's how you can integrate them into your setup:
from seleniumwire import webdriver
proxy = "user:pass:host:port"
user, password, host, port= proxy.split(":")
# Set up Selenium Wire with proxy authentication
seleniumwire_options = {
'proxy': {
'http': f'http://{user}:{password}@{host}:{port}',
'https': f'https://{user}:{password}@{host}:{port}',
'no_proxy': 'localhost,127.0.0.1'
}
}
options = webdriver.ChromeOptions()
options.add_argument("--blink-settings=imagesEnabled=false")
options.add_argument("--ignore-certificate-errors")
# Set a random user-agent
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
]
options.add_argument(f"--user-agent={random.choice(user_agents)}")
# Initialize WebDriver
driver = webdriver.Chrome(options=options, seleniumwire_options=seleniumwire_options)
Step 5: Navigate and Scrape
Now, you can use the driver to navigate and scrape websites:
driver.get("https://quotes.toscrape.com/")
# Your scraping code goes here, e.g.:
quotes = driver.find_elements(By.CSS_SELECTOR, ".quote .text")
authors = driver.find_elements(By.CSS_SELECTOR, ".quote .author")
for quote, author in zip(quotes, authors):
print(f"{quote.text} - {author.text}")
driver.quit()
Option 3: Bypass Cloudflare Using ScrapeOps Proxy Aggregator
ScrapeOps Proxy Aggregator is a sophisticated proxy management solution designed for web scraping projects. It aggregates numerous proxy providers into a single, streamlined service, offering a vast pool of residential, mobile, and datacenter IPs.
This aggregation allows users to access a diverse range of IP addresses, which is crucial for bypassing IP-based blocking mechanisms commonly employed by websites.
Advantages Over Selenium for Bypassing Cloudflare
- While Selenium is a powerful tool for automating and mimicking human interactions on web browsers, it primarily focuses on browser automation and does not inherently provide IP rotation or proxy management features.
- This is where ScrapeOps Proxy Aggregator stands out, because it allow you to use your normal HTTP client and you don't have to worry about:
- Finding origin servers
- Fortifying headless browsers
- Managing numerous headless browser instances & dealing with memory issues
- Reverse engineering the Cloudflare anti-bot protection
How It Works
- To use ScrapeOps Proxy Aggregator, you simply need to add
bypass=cloudflare_level_1to your API request. - This instructs the ScrapeOps proxy to employ the best available Cloudflare bypass technique for your target domain. The process is straightforward:
- Send a GET request to the ScrapeOps Proxy API Aggregator.
- Include your API key and the target URL in the request parameters.
- Specify
bypass=cloudflare_level_1to activate the Cloudflare bypass feature.
Here's a basic example in Python using the requests library:
import requests
response = requests.get(
'https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'https://quotes.toscrape.com/', # Cloudflare protected website
'bypass': 'cloudflare_level_1'
}
)
print('Body: ', response.content)
Cloudflare is the most common anti-bot system being used by websites today, and bypassing it depends on which security settings the website has enabled.
To combat this, we offer 3 different Cloudflare bypasses designed to solve the Cloudflare challenges at each security level.
| Security Level | Bypass | API Credits | Description |
|---|---|---|---|
| Low | cloudflare_level_1 | 10 | Use to bypass Cloudflare protected sites with low security settings enabled. |
| Medium | cloudflare_level_2 | 35 | Use to bypass Cloudflare protected sites with medium security settings enabled. On large plans the credit multiple will be increased to maintain a flat rate of $3.50 per thousand requests. |
| High | cloudflare_level_3 | 50 | Use to bypass Cloudflare protected sites with high security settings enabled. On large plans the credit multiple will be increased to maintain a flat rate of $4 per thousand requests. |
For more detailed information and guidance on using ScrapeOps Proxy Aggregator, you can check the official document.
Case Study: Bypassing Cloudflare on PetsAtHome
PetaAtHome is a one stop shop for pet goods. They use Cloudflare to prevent malicious activity and prevent bots from gaining access to their site. In this section, we'll attempt to access the site with using Selenium Stealth and also attempt to gain access using the ScrapeOps Proxy.
- Cloudflare helps safeguard PetsAtHome against various online threats, including DDoS attacks, which can overwhelm a website with traffic, causing it to slow down or become inaccessible.
- Cloudflare's Content Delivery Network (CDN) improves the loading times of PetsAtHome's web pages, ensuring a faster and more efficient user experience.
- Cloudflare provides robust bot management solutions that help PetsAtHome distinguish between legitimate users and automated scripts or bots.
- PetsAtHome needs to ensure compliance with data privacy regulations. Cloudflare's security measures aid in protecting sensitive user data.
Scraping PetsAtHome With Selenium Stealth Chromedriver
In this section, we'll explore a practical example of using Selenium Stealth Chromedriver to access petsathome.com, demonstrating how to navigate Cloudflare's protections and extract data effectively.
from selenium import webdriver
from selenium_stealth import stealth
from selenium.webdriver.common.by import By
import random
#create an instance of ChromeOptions
options = webdriver.ChromeOptions()
#user-agent rotation
user_agents = [
#add your list of user agents here
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
]
user_agent = random.choice(user_agents)
options.add_argument(f"user-agent={user_agent}")
#initialize the WebDriver with options
driver = webdriver.Chrome(options=options)
#apply stealth settings to the driver
stealth(
driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
#navigate to the site
driver.get("https://www.petsathome.com")
#take a screenshot of the result
driver.save_screenshot("stealth-example.png")
#close browser
driver.quit()
In the code above, we:
-
Imported necessary modules, including
webdriverfrom Selenium,stealthfromselenium_stealth, andByfor element locating. -
Defined a list of user agents (
user_agents) and randomly selected one to simulate different browser fingerprints. -
Added the selected user agent to Chrome options to enable user-agent rotation during scraping.
-
Created a Chrome WebDriver instance with the specified options.
-
Utilized the
selenium_stealthlibrary to apply stealth settings to the WebDriver, including language, vendor, platform, WebGL details, and other settings to mimic a more natural browsing environment and avoid detection. -
Quit the WebDriver to close the browser.
As you can see in the screenshot below, we were able to access the website. We have a screenshot of the same homepage you get when accessing the site through your normal browser. While we got lucky this time, this method will not always give us access!
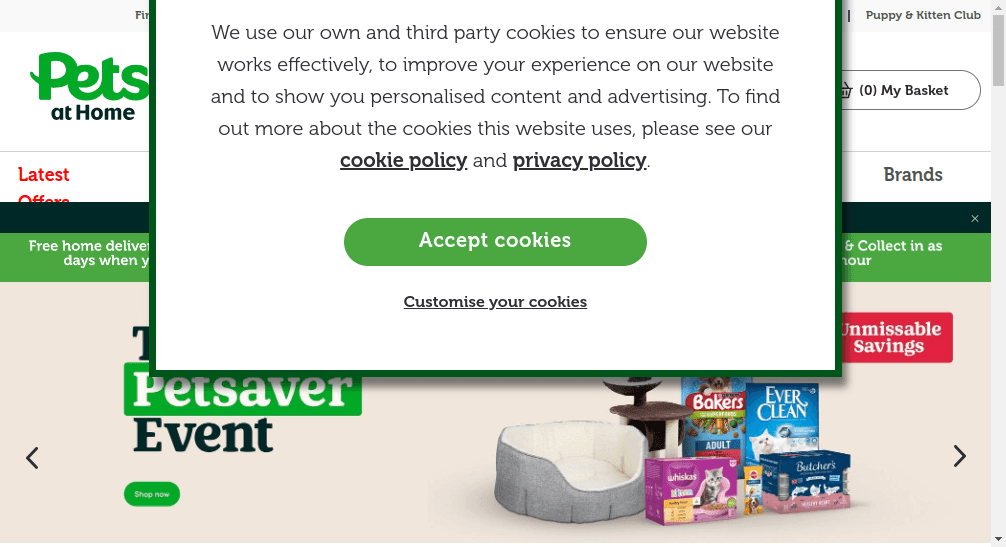
Scraping PetsAtHome With ScrapeOps Proxy Aggregator
In contrast to the challenges often faced when using Selenium, this section will demonstrate how the ScrapeOps Proxy Aggregator can be effectively utilized to scrape PetsAtHome, significantly reducing the likelihood of encountering Cloudflare's bot detection and blocking mechanisms.
To integrate our proxy with your Selenium scraper we recommend that you use the Selenium Wire extension which makes it very easy to use proxies with Selenium.
First, you need to install Selenium Wire using pip:
pip install selenium-wire
Then update your scraper to use seleniumwire's webdriver instead of the default selenium webdriver.
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
import random
#create an instance of ChromeOptions
options = webdriver.ChromeOptions()
#api key
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
#user-agent rotation
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
]
#random user agent
user_agent = random.choice(user_agents)
#add the user agent
options.add_argument(f"user-agent={user_agent}")
#set up proxy
proxy_options = {
"proxy": {
"http": f"http://scrapeops.headless_browser_mode=true:{SCRAPEOPS_API_KEY}@proxy.scrapeops.io:5353",
"https": f"http://scrapeops.headless_browser_mode=true:{SCRAPEOPS_API_KEY}@proxy.scrapeops.io:5353",
"no_proxy": "localhost:127.0.0.1",
}
}
#disable loading images for faster crawling
options.add_argument("--blink-settings=imagesEnabled=false")
#initialize the WebDriver with options
driver = webdriver.Chrome(options=options, seleniumwire_options=proxy_options)
#navigate to the site
driver.get("https://www.petsathome.com/")
#take a screenshot
driver.save_screenshot("scrapeops-example.png")
#close the browser
driver.quit()
As you can see, by adding the ScrapeOps Proxy to our code, we also were able to gain access to this Cloudflare protected site. When scraping in production, it is always best practice to use a proxy. When using a proxy, the proxy takes care of the tedious and difficult stuff and we can focus on the important data that we need to extract!

Conclusion
In wrapping up our discussion, it's clear that navigating Cloudflare's sophisticated anti-bot measures is a nuanced and evolving challenge in the field of web scraping.
Our exploration revealed the depth and complexity of strategies required to effectively bypass these protections, from leveraging the capabilities of tools like Selenium and its variants to employing advanced solutions like ScrapeOps Proxy Aggregator.
The practical insights gained from the Zillow.com case study further illuminated the real-world application of these techniques.
More Web Scraping Resources & Guides
If you would like to learn more about Web Scraping with Selenium, then be sure to check out The Selenium Web Scraping Playbook.
Or check out one of our more in-depth guides: