
How to Scrape Zillow With Requests and BeautifulSoup
When you're looking to buy a house in the US, Zillow is perhaps the most well known place to look. On Zillow, we can find listings for houses with all sorts of details about them and we can even take virtual tours of them. However, Zillow is notoriously difficult to scrape because of their use of anti-bots.
In this article, we're going to scrape tons of important data from Zillow.
- TLDR How to Scrape Zillow
- How To Architect Our Scraper
- Understanding How To Scrape zillow
- Setting Up Our Zillow Scraper
- Build A Zillow Search Crawler
- Build A Zillow Scraper
- Legal and Ethical Considerations
- Conclusion
- More Cool Articles
The full code for this Zillow Scraper is available on Github here.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Scrape Zillow
Need to scrape Zillow? We've got you covered.
- Create a new project folder.
- Inside that project folder, add a
config.jsonfile with your API key and then add this script. - Run it and you're good to go!
First, it will generate CSV file based on your search. If you searched for houses in "pr" (Puerto Rico), it spits out a file called pr.csv.
It then reads this file and creates an individual report on each house from pr.csv.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class PropertyData:
name: str = ""
price: int = 0
time_on_zillow: str = ""
views: int = 0
saves: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] != "BreadcrumbList":
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_property(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
price_holder = soup.select_one("span[data-testid='price']")
price = int(price_holder.text.replace("$", "").replace(",", ""))
info_holders = soup.select("dt")
time_listed = info_holders[0].text
views = int(info_holders[2].text.replace(",", ""))
saves = info_holders[4].text
property_pipeline = DataPipeline(csv_filename=f"{row['name']}.csv")
property_data = PropertyData(
name=row["name"],
price=price,
time_on_zillow=time_listed,
views=views,
saves=saves
)
property_pipeline.add_data(property_data)
property_pipeline.close_pipeline()
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_property,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Feel free to change any of the following from main:
MAX_THREADS: Determines the maximum number of threads used for concurrent scraping and processing.MAX_RETRIES: Sets the maximum number of retries for each request in case of failure (e.g., network issues, server errors).PAGES: Specifies the number of pages to scrape for each keyword. Each page contains multiple property listings.LOCATION: Defines the geographical location for the scraping. This parameter is used to adjust the proxy location to simulate requests from a specific country.keyword_list: A list of keywords representing different geographical areas or search terms on Zillow. Each keyword triggers a separate scraping job. ("pr"is Puerto Ricto, if you want to do Michigan, add"mi")
How To How To Architect Our Zillow Scraper
Like many other scrapers from our "How To Scrape" series, our Zillow project will consist of two scrapers:
-
a crawler: Our crawler will perform a search for houses in a specific area and spit out a CSV report on all the properties it finds.
-
a parser: The scraper will then read the CSV file, and run an individual scrape on each property from the list.
Throughout the development process we'll use the following concepts in our design:
- Parsing to extract valuable data from webpages.
- Pagination to get our results in batches.
- Data Storage to generate CSV reports from that data.
- Concurrency to handle all the above steps on multiple pages simultaneously.
- Proxy Integration to get past anti-bot systems and anything else that might get in the way of our scraper.
Understanding How To Scrape Zillow
Before we dive head first into coding, we need to get a better understanding of Zillow at a high level. In the following sections, we're going to discuss how to request pages, how to extract data, how to control pagination, and how to handle geolocation.
Step 1: How To Request Zillow Pages
We can't get very far if we can't request pages. We can request pages on Zillow with a simple GET request. A GET request does exactly what it sounds like, it gets information. When you lookup a site in your browser, you're actually performing a GET request.
Take a look at the image below, specifically our address bar. Here is our URL:
https://www.zillow.com/pr/2_p/
pr is our location.

When we look at a specific home, we get a pop-up about the home information, but no worries, we still get a URL that we can work with.
For the house below, our URL is
https://www.zillow.com/homedetails/459-Carr-Km-7-2-Int-Bo-Arenales-Aguadilla-PR-00603/363559698_zpid/
Building these URLs from scratch would be pretty difficult, luckily for us, we can scrape them on our initial crawl.

Step 2: How To Extract Data From Zillow Results and Pages
Extracting data from Zillow can be a bit tricky. For search results, our data is actually embedded in a JSON blob. For individual property pages, it's nested within the HTML elements. Let's take a closer look at exactly which data we'll be extracting.
Here is the search page and the JSON blob inside it.

Here is a look at some the HTML we want to parse for an individual property page.
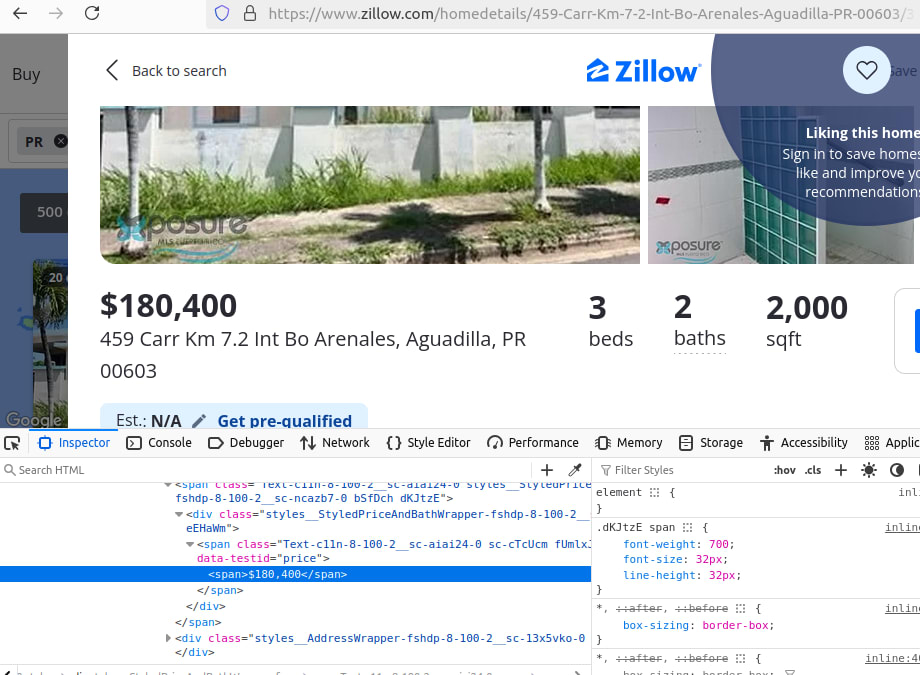
Step 3: How To Control Pagination
Pagination might seem a bit cryptic, but take a closer look at our URL from before:
https://www.zillow.com/pr/2_p/
2_p actually denotes our page number, 2.
If we want to search for page 1, our URL is
https://www.zillow.com/pr/1_p/
If we want page 3, we would end the url with 3_p.
Step 4: Geolocated Data
For geolocated data, we'll be using the ScrapeOps API and our keyword_list. In the keyword_list, we'll hold the locations we'd like to scrape.
When interacting with the ScrapeOps API, we'll pass in a country param as well. country will not have any effect on our actual search results, but instead it will route us through a server in whichever country we specify.
For instance, if we want to appear in the US, we'd pass us in as our country.
Setting Up Our Zillow Scraper Project
Let's get started. You can run the following commands to get setup.
Create a New Project Folder
mkdir zillow-scraper
cd zillow-scraper
Create a New Virtual Environment
python -m venv venv
Activate the Environment
source venv/bin/activate
Install Our Dependencies
pip install requests
pip install beautifulsoup4
Build A Zillow Search Crawler
Step 1: Create Simple Search Data Parser
We'll start off by building a simple parser. The job of the parser is relatively straightforward. Our parser needs to perform a search and extract data from the search results. This is the bedrock of everything else we'll add into our script.
While the script below adds some basic structure (logging, error handling, retry logic), what you should pay attention to is the parsing logic inside of our scrape_search_results() function.
Take a look at the script so far.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] != "BreadcrumbList":
search_data = {
"name": json_data["name"],
"property_type": json_data["@type"],
"street_address": json_data["address"]["streetAddress"],
"locality": json_data["address"]["addressLocality"],
"region": json_data["address"]["addressRegion"],
"postal_code": json_data["address"]["postalCode"],
"url": json_data["url"]
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
scrape_search_results(keyword, LOCATION, retries=retries)
logger.info(f"Crawl complete.")
In our parsing function, we do the following things.
- Find all of our JSON blobs with
script_tags = soup.select("script[type='application/ld+json']") - Iterate through the blobs.
- For each blob that does not have a
"@type"of"BreadcrumbList", we parse its data:nameproperty_typestreet_addresslocalityregionpostal_codeurl
Step 2: Add Pagination
As we discussed earlier, we can add pagination with the following string by constructin our URL like so:
https://www.zillow.com/{keyword}/{page_number+1}_p/
- As you know,
keywordis the location we'd like to search. {page_number+1}_p, denotes our page number. We usepage_number+1because we'll be using Python'srange()function to create our page list.range()starts counting at zero and Zillow starts our pages at 1. So, we add 1 to our page when we pass it into the URL.
We also added a start_scrape() function to support the pagination we just added.
def start_scrape(keyword, pages, location, max_threads=5, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, retries=retries)
Here is our updated code. We added a start_scrape() function to support multiple pages, but all in all, our code isn't all that different.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, page_number, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] != "BreadcrumbList":
search_data = {
"name": json_data["name"],
"property_type": json_data["@type"],
"street_address": json_data["address"]["streetAddress"],
"locality": json_data["address"]["addressLocality"],
"region": json_data["address"]["addressRegion"],
"postal_code": json_data["address"]["postalCode"],
"url": json_data["url"]
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, max_threads=5, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
start_scrape(keyword, PAGES, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
logger.info(f"Crawl complete.")
Step 3: Storing the Scraped Data
When we scrape our data, we need to store it. If we didn't, there wouldn't be a point in scraping it to begin with. When we store our data, we can review it and we can also allow other functions or programs to read it.
This lays the groundwork for our scraper, which will read the stored CSV file and then lookup individual data about the properties from the CSV file.
First, we need a SearchData class. This class simply holds data.
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
Here is our DataPipeline. It takes in a dataclass (such as SearchData) and pipes it to a CSV file. This pipeline then filters out our duplicates and then saves the data to a CSV file.
Additionally, our pipeline writes the file safely. If the CSV exists, we append it, otherwise the pipeline creates it.
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
Here is our code now that it's been fully updated for storage.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] != "BreadcrumbList":
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, data_pipeline=data_pipeline, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 4: Adding Concurrency
To add concurrency, we'll use ThreadPoolExecutor. We'll also add a max_threads argument to start_scrape(). Take a look at the snippet below.
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
Pay close attention to the arguments we pass into executor.map():
scrape_search_resultsis the function we'd like to run on each thread.- All other arguments are the arguments that we pass into
scrape_search_results() - Each argument after the first gets passed in as an array.
Here is our full code as of now.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] != "BreadcrumbList":
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 5: Bypassing Anti-Bots
When we scrape the web, we tend to run into anti-bots. Anti-bots are software designed to detect malware and block it from accessing a site. Our scraper isn't malware, but it doesn't look human at all and anti-bots tend to flag this.
Take a look at the snippet below, this unleashes the power of the ScrapeOps Proxy API.
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
Arguments we pass into the ScrapeOps API:
"api_key": our ScrapeOps API key."url": the url of the site we'd like to scrape."country": the country we'd like to be routed through."residential": a boolean value. If we set this toTrue, we're telling ScrapeOps to give us a residential IP address which decreases our likelihood of getting blocked.
Here is our production ready code.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
excluded_types = ["BreadcrumbList", "Event"]
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] not in excluded_types:
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 6: Production Run
We're now ready for a production run. Take a look at our main.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
We'll change PAGES to 5, and LOCATION to "us". Feel free to change any of these constants in the main to tweak your results.
Here are our results.

Our crawler parsed the results at approximately one second per page. This is great!
Build A Zillow Scraper
Our crawler is now performing searches, parsing results and saving the data. Now, it's time to build the scraper. Our scraper is going to do the following:
- Read a CSV file.
- Parse all properties from the CSV file.
- Save their data.
- Perform the actions above concurrently.
- Integrate with a proxy.
Step 1: Create Simple Business Data Parser
Like before, we'll start with a basic parsing function. The overall structure looks alot like our first parsing function, but there are some key differences.
Mainly, instead of finding JSON data nested within the page, we're going to find our data from different elements on the page.
Take a look at the function below.
def process_property(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
price_holder = soup.select_one("span[data-testid='price']")
price = int(price_holder.text.replace("$", "").replace(",", ""))
info_holders = soup.select("dt")
time_listed = info_holders[0].text
views = int(info_holders[2].text.replace(",", ""))
saves = info_holders[4].text
property_data = {
"name": row["name"],
"price": price,
"time_on_zillow": time_listed,
"views": views,
"saves": saves
}
print(property_data)
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
Things you need to pay attention to here:
"span[data-testid='price']"is the CSS selector of ourprice_holder.int(price_holder.text.replace("$", "").replace(",", ""))gives us our actual price and converts it to an integer.- We find all of our
info_holderswithsoup.select("dt") - We pull
time_listed,views, andsavesfrom theinfo_holdersarray.
Step 2: Loading URLs To Scrape
In order to use our parsing function, we need to be able to feed urls into it. for each row in the file, we run process_property() on that row. Later, we'll add concurrency to this function just like we did eariler.
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_property(row, location, retries=retries)
Here is our fully updated code.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
excluded_types = ["BreadcrumbList", "Event"]
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] not in excluded_types:
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_property(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
price_holder = soup.select_one("span[data-testid='price']")
price = int(price_holder.text.replace("$", "").replace(",", ""))
info_holders = soup.select("dt")
time_listed = info_holders[0].text
views = int(info_holders[2].text.replace(",", ""))
saves = info_holders[4].text
property_data = {
"name": row["name"],
"price": price,
"time_on_zillow": time_listed,
"views": views,
"saves": saves
}
print(property_data)
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_property(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Our code now reads the CSV file generated by the crawler and runs process_post() on each row from the file.
Step 3: Storing the Scraped Data
As you already know at this point, we need to store the data we scrape. For the most part, we've already got everything in place to do this.
We simply need to add a PropertyData class. This class will act much like the SearchData class from before and it will also get passed into a DataPipeline.
Here is our SearchData class.
@dataclass
class PropertyData:
name: str = ""
price: int = 0
time_on_zillow: str = ""
views: int = 0
saves: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
In our full code below, instead of printing the data, we instantiate a PropertyData object and then pass it into a DataPipeline.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class PropertyData:
name: str = ""
price: int = 0
time_on_zillow: str = ""
views: int = 0
saves: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
excluded_types = ["BreadcrumbList", "Event"]
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] not in excluded_types:
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_property(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
price_holder = soup.select_one("span[data-testid='price']")
price = int(price_holder.text.replace("$", "").replace(",", ""))
info_holders = soup.select("dt")
time_listed = info_holders[0].text
views = int(info_holders[2].text.replace(",", ""))
saves = info_holders[4].text
property_pipeline = DataPipeline(csv_filename=f"{row['name']}.csv")
property_data = PropertyData(
name=row["name"],
price=price,
time_on_zillow=time_listed,
views=views,
saves=saves
)
property_pipeline.add_data(property_data)
property_pipeline.close_pipeline()
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_property(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 4: Adding Concurrency
With a small refactor, we can now add concurrency. Once again, we'll replace our for loop with ThreadPoolExecutor. Take a look at the new function.
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_property,
reader,
[location] * len(reader),
[retries] * len(reader)
)
Quite similar to when we added concurrency earlier, executor.map() takes the following arguments.
process_propertyis the function we want to run on each thread.readeris the array of property from our CSV file.- All other arguments are passed in as arrays, just like before.
Step 5: Bypassing Anti-Bots
Once again, we want to get past anti-bots and anything else that might block us. We only need to change one line.
response = requests.get(get_scrapeops_url(url, location=location))
Here is our finalized code, ready for production.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
property_type: str = ""
street_address: str = ""
locality: str = ""
region: str = ""
postal_code: str = ""
url: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class PropertyData:
name: str = ""
price: int = 0
time_on_zillow: str = ""
views: int = 0
saves: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.zillow.com/{keyword}/{page_number+1}_p/"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
script_tags = soup.select("script[type='application/ld+json']")
excluded_types = ["BreadcrumbList", "Events"]
for script_tag in script_tags:
json_data = json.loads(script_tag.text)
if json_data["@type"] not in excluded_types:
search_data = SearchData(
name=json_data["name"],
property_type=json_data["@type"],
street_address=json_data["address"]["streetAddress"],
locality=json_data["address"]["addressLocality"],
region=json_data["address"]["addressRegion"],
postal_code=json_data["address"]["postalCode"],
url=json_data["url"]
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_property(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
price_holder = soup.select_one("span[data-testid='price']")
price = int(price_holder.text.replace("$", "").replace(",", ""))
info_holders = soup.select("dt")
time_listed = info_holders[0].text
views = int(info_holders[2].text.replace(",", ""))
saves = info_holders[4].text
property_pipeline = DataPipeline(csv_filename=f"{row['name']}.csv")
property_data = PropertyData(
name=row["name"],
price=price,
time_on_zillow=time_listed,
views=views,
saves=saves
)
property_pipeline.add_data(property_data)
property_pipeline.close_pipeline()
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_property,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "uk"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 6: Production Run
We're now ready to test this thing out in production. Once again, I've set PAGES to 5 and our LOCATION to "us".
Feel free to change any of the constants within main to tweak your results.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["pr"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
The full code ran and exited in 42.8 seconds.
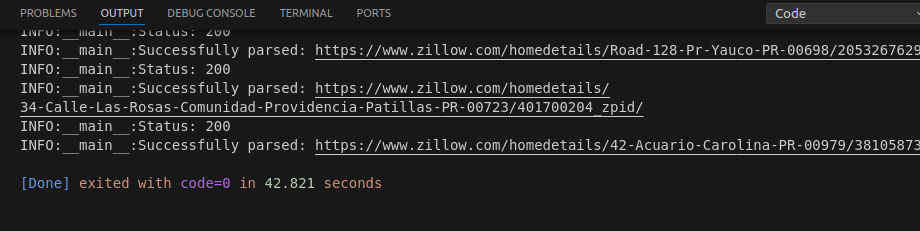
In total, there were 45 properties in the CSV file generated from the crawler. If you recall, the crawler took roughly 5 seconds. 42.8 - 5 = 37.8 seconds spent parsing properties. 37.8 seconds / 45 properties = 0.84 seconds per property.
Legal and Ethical Considerations
As with any website, when you access Zillow, you are subject to their Terms of Use. You can view those terms here.
It's also important to pay attention to their robots.txt which you can view here. It's important to note that violation of these Terms could result in your account getting blocked or even permanently removed from the site.
When scraping, public data is generally considered legal throughout the world. Private data is any data that is gated behind a login or some other form of authentication.
If you're not sure your scraper is legal, it's best to consult with an attorney who handles the jurisdiction of the site you're scraping.
Conclusion
You've finished our tutorial and you've now got another skill for your scraping toolbox. You understand parsing, pagination, data storage, concurrency, and proxy integration. Go out and build something!
If you're interested in the tech stack used in this article, take a look at the links below.
More Python Web Scraping Guides
Here at ScrapeOps, we've got tons of learning resources. Whether you're brand new to scraping or you're a seasoned vet, we've got something for you.
If you're in the mood to learn more, check our Python Web Scraping Playbook or take a look at the articles below: