
How to Scrape Nordstrom With Requests and BeautifulSoup
Nordstrom is a luxury fashion store that's been around since 1901. Nordstrom can be an extremely difficult site to scrape, even if you are using a proxy! If you attempt to scrape Nordstrom, and you take a screenshot, you're most likely get blocked.
In today's project, we're going scrape Nordstrom in detail.
- TLDR How to Scrape Nordstrom
- How To Architect Our Scraper
- Understanding How To Scrape Nordstrom
- Setting Up Our Nordstrom Scraper
- Build A Nordstrom Search Crawler
- Build A Nordstrom Scraper
- Legal and Ethical Considerations
- Conclusion
- More Cool Articles
The full code for this Nordstrom Scraper is available on Github here.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Scrape Nordstrom
If you're looking to scrape Nordstrom, we've got a Nordstrom scraper right here... already integrated with the ScrapeOps proxy as well!
- Simply create a new project folder and add a
config.jsonfile. - Add your ScrapeOps Proxy API key to the config file:
{"api_key": "your-super-secret-api-key"}. - Then create a new Python file inside the same folder and copy/paste the code below into it.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3",
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
incentivized: bool = False
verified: bool = False
rating: float = 0.0
date: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code != 200:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
reviews_container = soup.select_one("div[id='reviews-container']")
review_cards = reviews_container.find_all("div", recursive=False)
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
subsections = review_card.find_all("div", recursive=False)
user_section = subsections[0]
name = user_section.select_one("div div").text
incentivized = "Incentivized" in user_section.text
verified = "Verified" in user_section.text
review_body = subsections[1]
spans = review_body.find_all("span")
rating_string = spans[0].get("aria-label").replace("Rated ", "").replace(" out of 5 stars.", "")
rating = float(rating_string)
date = spans[1].text
review_data = ReviewData(
name=name,
incentivized=incentivized,
verified=verified,
rating=rating,
date=date
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
To tweak your results, feel free to change any of the following:
MAX_RETRIES: Maximum number of retry attempts for failed HTTP requests.MAX_THREADS: Maximum number of threads that will run concurrently during the scraping process.PAGES: How many pages of search results to scrape for each keyword.LOCATION: The geographic location or country code for the scraping process.keyword_list: A list of product keywords for which the script will perform searches and scrape product information.
How To Architect Our Nordstrom Scraper
WARNING: Nordstrom explicitly prohibits bot traffic as you can see in the screenshot below. If you decide to scrape Nordstrom, you could get banned from the website!
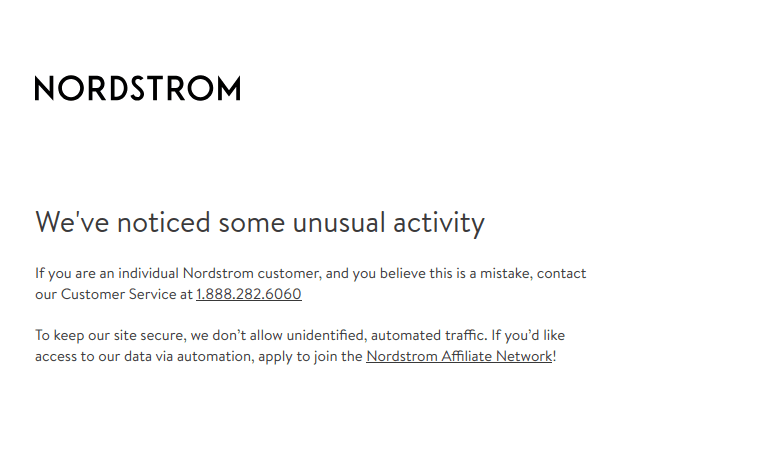
Similar to many other pieces from our "How to Scrape" series, our Nordstrom scraper will consist of both a crawler and a scraper.
- Our crawler will perform a search on Nordstrom and save the results.
- The scraper will then read the CSV that the crawler created. After reading the CSV, the scraper will go through and scrape reviews from each item in the crawler's report.
Our crawler will perform the following steps:
- Perform a search and parse the results.
- Use pagination for better control over our results.
- Store the extracted data neatly in a CSV file.
- Concurrently run steps 1 through 3 on multiple pages.
- Proxy Integration will help us get through Nordstrom's very sophistocated anti-bot protections.
After our crawl, the scraper is going to perform these steps:
- Read our CSV file into an array.
- Parse reviews for each item in the CSV.
- Store the parsed review data.
- Concurrently run steps 2 and 3.
- Again, integrate with a strong proxy to get past anti-bots.
Understanding How To Scrape Nordstrom
We can't just plunge straight into coding. We need to look at how this is done from a user standpoint first. We need to understand how to request these pages and how to extract data from them. We also need to see how pagination works and we need to know how to control our location.
Step 1: How To Request Nordstrom Pages
Whenever you fetch a website (with your browser or with plain old HTTP requests), you are performing a GET request. To get our pages, we'll perform an HTTP GET request to the proper URL.
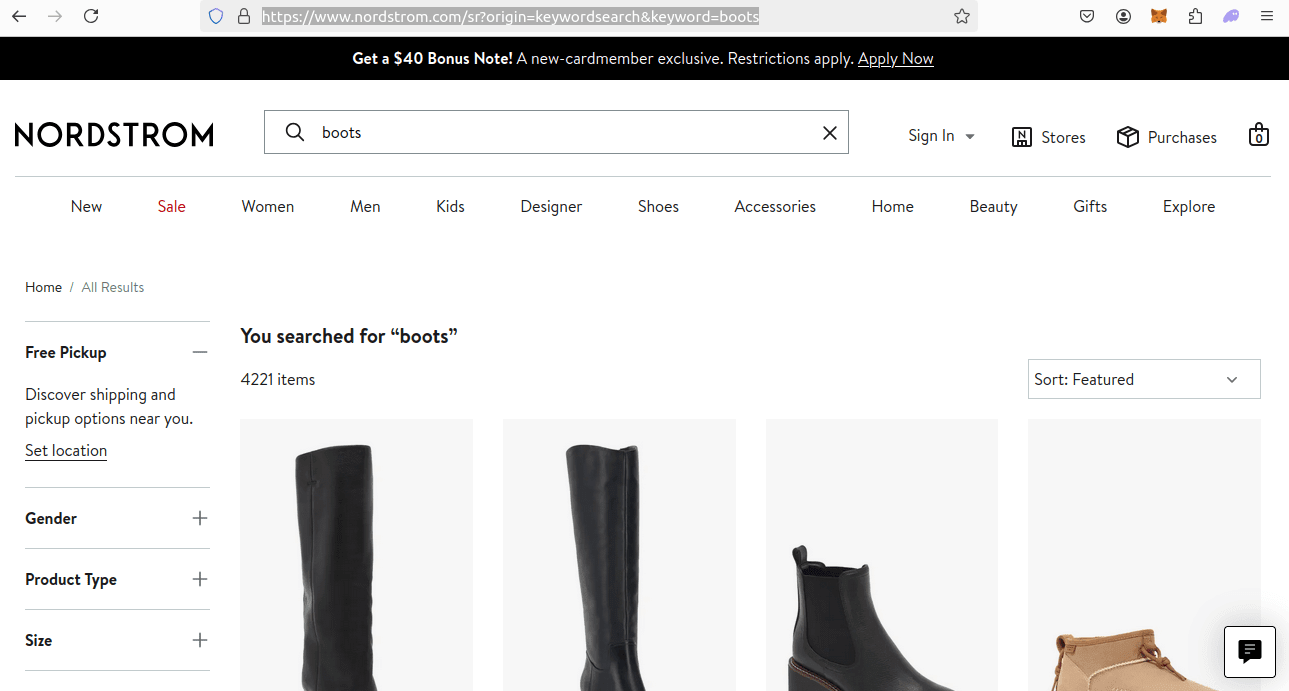
If we want to search for boots, we'll use the following URL:
https://www.nordstrom.com/sr?origin=keywordsearch&keyword=boots
The param you really need to pay attention to here is &keyword=boots. If we wanted to shop for sandals, we could pass &keyword=sandals.
Our full URL will always be constructed to look like this:
https://www.nordstrom.com/sr?origin=keywordsearch&keyword={KEYWORD}
You can see a screenshot of this below.
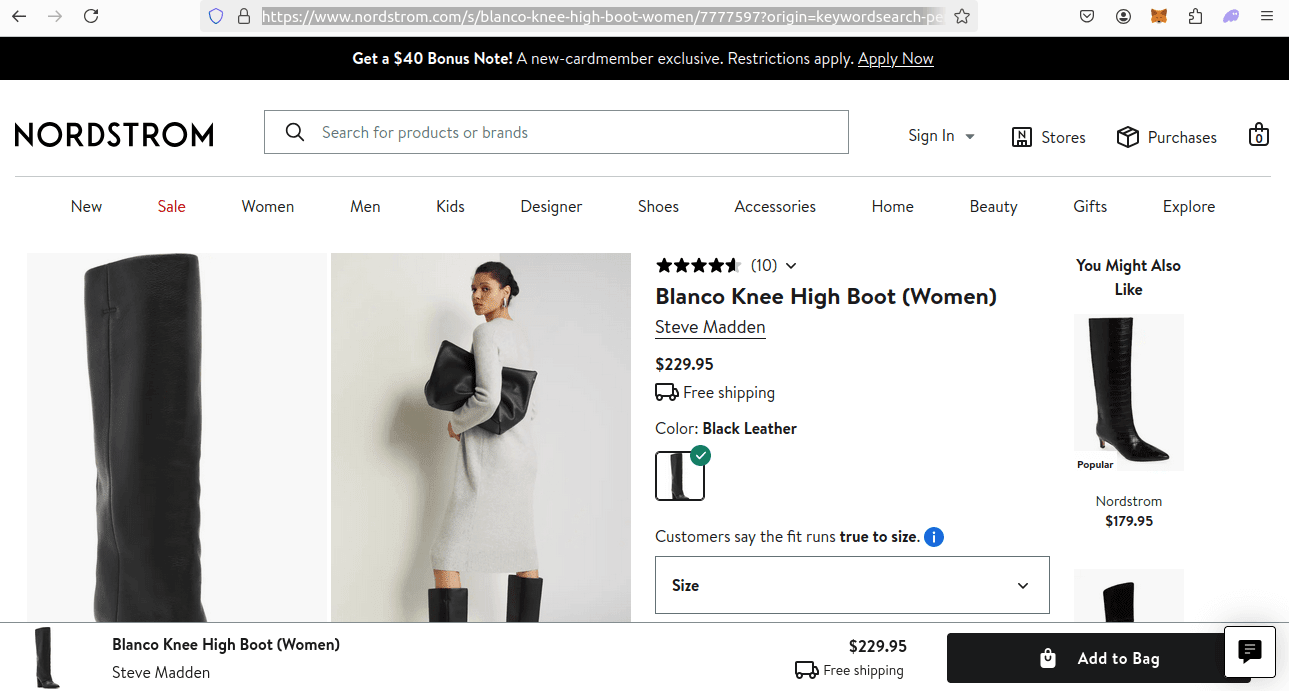
Individual items on Nordstrom also have their own naming conventions which are much harder to reproduce. The full URL of the screenshot below is:
https://www.nordstrom.com/s/blanco-knee-high-boot-women/7777597?origin=keywordsearch-personalizedsort&breadcrumb=Home%2FAll%20Results&color=001
As you can see, it still follows a standard, but it's much more intricate. We'll be picking these URLs out of the search page, so we don't need to fully reconstruct them.
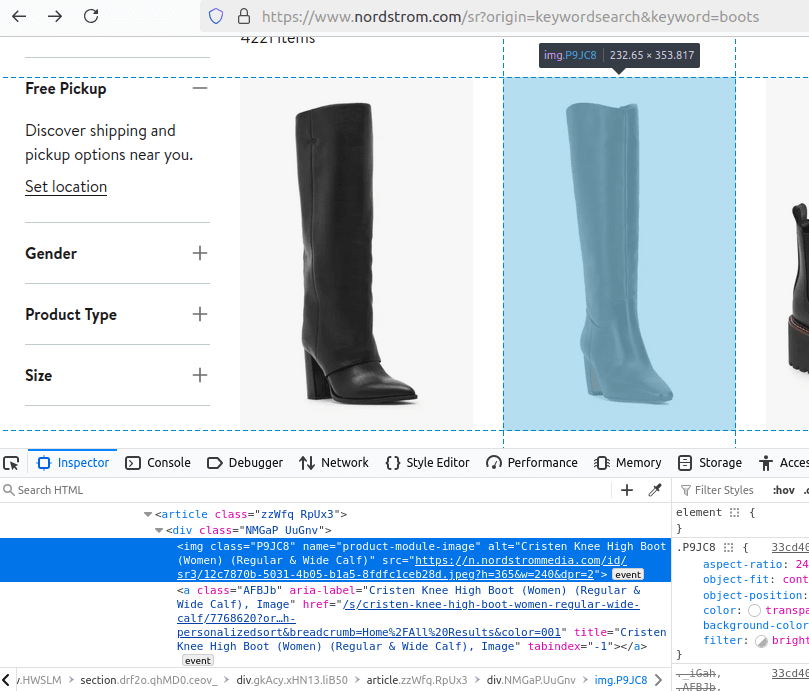
Step 2: How To Extract Data From Nordstrom Results and Pages
Extracting Nordstrom's data isn't too difficult. Getting to the data is the difficult process. Nordstrom data gets embedded within the HTML of the site and it's really not much more nested than what you would find at Quotes To Scrape.
In the search results, each item is embedded in an article tag. This article holds a div, which holds an img with the name of product-module-image. Because of the name involved here, it's very easy to identify the individual img tags and then find their parents (the div holding all of our information) from there.
When we're scraping item reviews, we follow a pretty similar process. Our review is split into two subsections, the user information and a review body. You can see them both below.
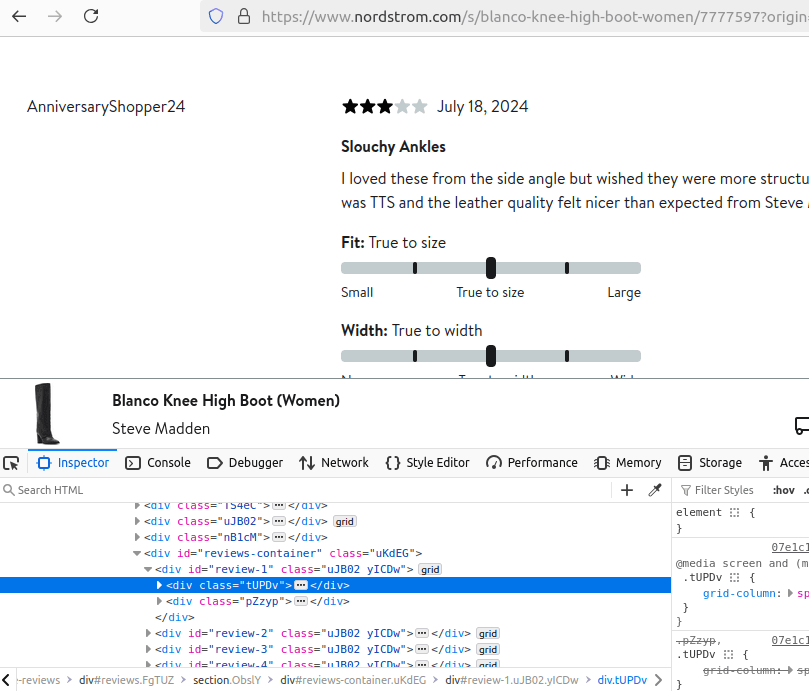
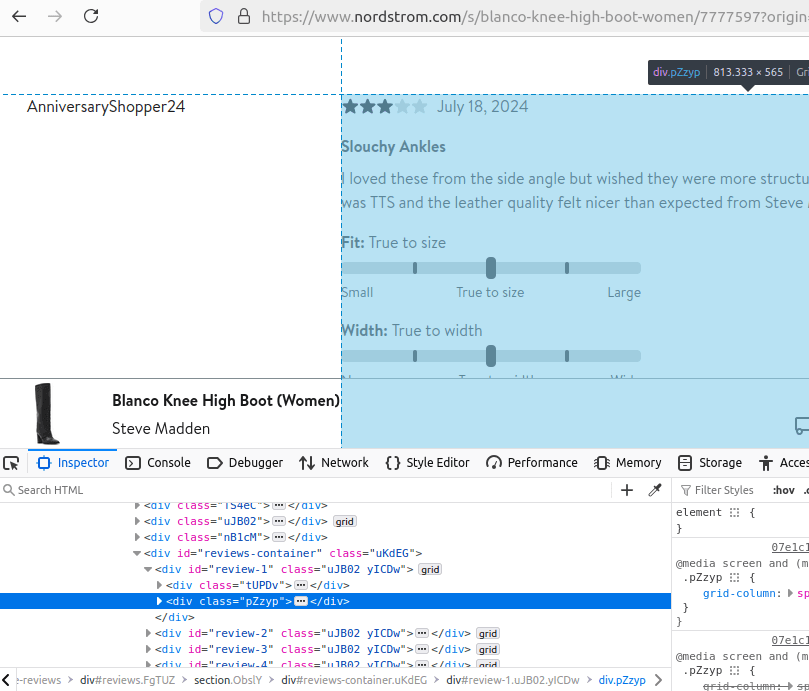
Step 3: How To Control Pagination
To control our pagination, we just need to add a page parameter to our URL. Our finalized URL will look like this:
https://www.nordstrom.com/sr?origin=keywordsearch&keyword=boots&&offset=6&page=2
&page=2 tells the Nordstrom server that we want to look at page 2 of the search results. With pagination added in, here is how our full URLs are constructed:
https://www.nordstrom.com/sr?origin=keywordsearch&keyword={KEYWORD}&&offset=6&page={PAGE_NUMBER}
Step 4: Geolocated Data
To handle geolocated data, we'll be using the ScrapeOps Proxy API. We can pass a country into the ScrapeOps Proxy Aggregator and it will route us through that country.
- If we want to appear in the US, we can pass
"country": "us". - If we want to appear in the UK, we can pass
"country": "uk".
You can view a full list of our supported countries here.
Setting Up Our Nordstrom Scraper Project
Let's get started. You can run the following commands to get setup.
Create a New Project Folder
mkdir nordstrom-scraper
cd nordstrom-scraper
Create a New Virtual Environment
python -m venv venv
Activate the Environment
source venv/bin/activate
Install Our Dependencies
pip install requests
pip install beautifulsoup4
Build A Nordstrom Search Crawler
Every large scale project should start off with a decent crawler. If you're looking to scrape a bunch of reviews, first, you need to scrape a bunch of items. The search results contain links to the item pages which hold the reviews.
We're going to break our build process down into some simple steps:
- Writing a parser
- Adding pagination
- Adding data storage
- Adding concurrency
- Integration with a proxy
Step 1: Create Simple Search Data Parser
We'll start by creating a simple parser. The goal of our parser is simple: perform a search and extract data from the results. In this section, we're going to add our basic structure, error handling, retry logic, and our parsing function.
In the code below, we have a basic parser that we can easily build off of for the rest of our project.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = {
"name": name,
"img": img,
"url": link,
"price": price
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
scrape_search_results(keyword, LOCATION, retries=MAX_RETRIES)
logger.info(f"Crawl complete.")
In our parsing function, we do the following things:
- Find all the
imgcards withimg_cards = soup.select("img[name='product-module-image']"). - Iterate through the cards:
- Get the
nameandimgwith thealtandsrcattributes. - Find each parent element with
base_card = div_card.parent. - Extract the
priceand item'surlfrom thespanandaelements in thebase_card.
- Get the
Step 2: Add Pagination
It's really simple to paginate Nordstrom URLs. We only need to add one param to the URL. If you remember from earlier, paginated URLs are laid out similar this:
"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
We use page_number+1 because our range() function begins counting at 0. However, our Nordsrom results begin with page 1.
Here is our updated parsing function.
def scrape_search_results(keyword, location, page_number, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = {
"name": name,
"img": img,
"url": link,
"price": price
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
We're also going to add a start_scrape() function that allows us to iterate through a list and call scrape_search_results() on each item from the list.
def start_scrape(keyword, pages, location, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, retries=retries)
After adding these in, your full code should look like this.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, page_number, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = {
"name": name,
"img": img,
"url": link,
"price": price
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
start_scrape(keyword, PAGES, LOCATION, retries=MAX_RETRIES)
logger.info(f"Crawl complete.")
With pagination, we get the ability to control our results.
Step 3: Storing the Scraped Data
Data storage is vital to any scraping project. When we store our data, our crawler generates reports. We'll build these reports in CSV format.
With a CSV, any human can open it up and review the data very easily. On top of that, at it's most basic, a CSV is an array of key-value pairs (dict objects in Python). Because of its simplicity, it's really simple to read the file and then do stuff based on the data.
Here, we'll create a SearchData class to represent an individual search result. Then we'll make a DataPipeline. We pass SearchData into the DataPipeline and then the pipeline filters out duplicate data while passing everything else into a CSV file.
Here is our SearchData:
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
Here is the DataPipeline we pass it into.
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
In our full code below, we'll create a DataPipeline instance and then pass it into start_scrape(). It then gets passed into scrape_search_results() each time it gets called.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, retries=3):
for page in range(pages):
scrape_search_results(keyword, location, page, data_pipeline=data_pipeline, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
- We create a new
DataPipeline:crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv"). - Next, we pass it into
start_scrape():start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES). - From within our parsing function, we pass a
SearchDataobject into the pipeline:data_pipeline.add_data(search_data). - After we've finished parsing the data, we close our pipeline with
crawl_pipeline.close_pipeline().
Step 4: Adding Concurrency
Time to add concurrency. When we parse pages concurrently, we'll perform our parse on multiple pages simultaneously.
To do this, we're going to use ThreadPoolExecutor. ThreadPoolExecutor opens up a pool of threads. From within that pool, we run processes on all available threads.
Here is start_scrape() refactored to use multithreading for concurrency.
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader,
[location] * len(reader),
[retries] * len(reader)
)
You can see our fully updated code below.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3"
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
incentivized: bool = False
verified: bool = False
rating: float = 0.0
date: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code != 200:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
reviews_container = soup.select_one("div[id='reviews-container']")
review_cards = reviews_container.find_all("div", recursive=False)
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
subsections = review_card.find_all("div", recursive=False)
user_section = subsections[0]
name = user_section.select_one("div div").text
incentivized = "Incentivized" in user_section.text
verified = "Verified" in user_section.text
review_body = subsections[1]
spans = review_body.find_all("span")
rating_string = spans[0].get("aria-label").replace("Rated ", "").replace(" out of 5 stars.", "")
rating = float(rating_string)
date = spans[1].text
review_data = ReviewData(
name=name,
incentivized=incentivized,
verified=verified,
rating=rating,
date=date
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 5: Bypassing Anti-Bots
Bypassing anti-bots on Nordstrom is quite difficult. Take another look at the screenshot you saw at the beginning of this article. This screenshot was generated using the standard proxy function you see below.
We're going to change this function a bit so we can get through without getting detected.
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
Here is our proxy function for Nordstrom.
- We pass
"wait": 5000to tell ScrapeOps to wait 5 seconds before giving our response back to us. "bypass": "generic_level_3"tells ScrapeOps we want to bypass anti-bots with a difficulty level of 3.- In our initial testing, levels 1 and 2 weren't sufficient to get through consistently.
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3"
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
You can view our production level crawler below.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3"
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 6: Production Run
Let's test this out in production. We're going to scrape 4 pages of Nordstrom results and see how long it takes.
You can feel free to change MAX_RETRIES, MAX_THREADS, LOCATION, keyword_list and PAGES to alter your results.
Here is our updated main function.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 4
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
You can view our final results below.

We crawled 4 pages in 64.699 seconds. This comes out to an average of 16.17 seconds per page.
Build A Nordstrom Scraper
Now, we need to build our item scraper. We're creating a CSV report when we run our crawler. Our scraper needs to read this CSV file and then it needs to parse each row from the CSV. You can take a look at the overall process that our scraper is going to run below.
- Read the CSV file into an array.
- Parse items from the CSV.
- Store data from each parsed item.
- Concurrently run steps 2 and 3 on multiple pages at once.
- Use a proxy to once again past Nordstrom's anti-bots.
Step 1: Create Simple Business Data Parser
We're going to start this half of our project with a parser, just like we did before.
Take a look at the code below. We add error handling, retries, and basic code structure. process_item() goes through and finds all of our review items from within the page.
def process_item(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code != 200:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
reviews_container = soup.select_one("div[id='reviews-container']")
review_cards = reviews_container.find_all("div", recursive=False)
for review_card in review_cards:
subsections = review_card.find_all("div", recursive=False)
user_section = subsections[0]
name = user_section.select_one("div div").text
incentivized = "Incentivized" in user_section.text
verified = "Verified" in user_section.text
review_body = subsections[1]
spans = review_body.find_all("span")
rating_string = spans[0].get("aria-label").replace("Rated ", "").replace(" out of 5 stars.", "")
rating = float(rating_string)
date = spans[1].text
review_data = {
"name": name,
"incentivized": incentivized,
"verified": verified,
"rating": rating,
"date": date
}
print(review_data)
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
reviews_container = soup.select_one("div[id='reviews-container']")gets the container holding all of our reviews.- Next, we go and find our reviews from the container,
review_cards = reviews_container.find_all("div", recursive=False). - Then, we find our
user_sectionandreview_bodywithsubsections = review_card.find_all("div", recursive=False). - Finally, we pull the
spanelements to get ourdateandrating.
Step 2: Loading URLs To Scrape
To parse our items, we need a list of urls. In this section, we're going to make a function that reads our CSV into an array. We'll call this one process_results().
This function needs to iterate through the rows of the CSV file and run process_item() on each of them.
def process_results(csv_file, location, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_item(row, location, retries=retries)
Here is our full code at this point.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3"
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code != 200:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
reviews_container = soup.select_one("div[id='reviews-container']")
review_cards = reviews_container.find_all("div", recursive=False)
for review_card in review_cards:
subsections = review_card.find_all("div", recursive=False)
user_section = subsections[0]
name = user_section.select_one("div div").text
incentivized = "Incentivized" in user_section.text
verified = "Verified" in user_section.text
review_body = subsections[1]
spans = review_body.find_all("span")
rating_string = spans[0].get("aria-label").replace("Rated ", "").replace(" out of 5 stars.", "")
rating = float(rating_string)
date = spans[1].text
review_data = {
"name": name,
"incentivized": incentivized,
"verified": verified,
"rating": rating,
"date": date
}
print(review_data)
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_item(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, retries=MAX_RETRIES)
Step 3: Storing the Scraped Data
To store our data, wee need to build another dataclass like the SearchData class we made earlier. we'll call this one ReviewData. ReviewData is will hold all of the following fields:
name: the name of the reviewer.incentivized: whether or not the reviewer received an incentive for the review.verified: whether or not the purchase was verified.rating: the rating left by the reviewer.date: the date the review was left.
Here is our ReviewData class.
@dataclass
class ReviewData:
name: str = ""
incentivized: bool = False
verified: bool = False
rating: float = 0.0
date: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
With this new storage added in, here is our full code.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3"
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
incentivized: bool = False
verified: bool = False
rating: float = 0.0
date: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code != 200:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
reviews_container = soup.select_one("div[id='reviews-container']")
review_cards = reviews_container.find_all("div", recursive=False)
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
subsections = review_card.find_all("div", recursive=False)
user_section = subsections[0]
name = user_section.select_one("div div").text
incentivized = "Incentivized" in user_section.text
verified = "Verified" in user_section.text
review_body = subsections[1]
spans = review_body.find_all("span")
rating_string = spans[0].get("aria-label").replace("Rated ", "").replace(" out of 5 stars.", "")
rating = float(rating_string)
date = spans[1].text
review_data = ReviewData(
name=name,
incentivized=incentivized,
verified=verified,
rating=rating,
date=date
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_item(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, retries=MAX_RETRIES)
- We now open a new
DataPipelinefrom inside our parsing function. - We create a
ReviewDataobject from each of review that gets scraped from the site.
Step 4: Adding Concurrency
We're going to add concurrency exactly the same way we did earlier. process_results() already does what we want it to do, we're just going to replace our for loop with ThreadPoolExecutor. Take a look at it below.
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader,
[location] * len(reader),
[retries] * len(reader)
)
Here are the arguments to executor.map():
process_itemis the function we want to call on each thread.readeris the array we're callingprocess_itemon.locationandretriesboth get passed in as arrays as well.
Step 5: Bypassing Anti-Bots
Everything is now in place, all we need to do is add a proxy to our parsing function. We need to add the residential proxy argument to our scraper. Afterward, this takes a simple change on one line.
Here is our updated proxy function.
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3",
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
Here is the line we need to change in the parser.
response = requests.get(get_scrapeops_url(url, location=location))
Below, you can view our full code with both the crawler and the scraper.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
"wait": 5000,
"bypass": "generic_level_3",
"residential": True
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
img: str = ""
url: str = ""
price: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
incentivized: bool = False
verified: bool = False
rating: float = 0.0
date: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
url = f"https://www.nordstrom.com/sr?origin=keywordsearch&keyword={formatted_keyword}&offset=6&page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
img_cards = soup.select("img[name='product-module-image']")
for img_card in img_cards:
name = img_card.get("alt")
div_card = img_card.parent
img = img_card.get("src")
base_card = div_card.parent
price = base_card.find("span").text
href = base_card.find("a").get("href")
link = f"https://www.nordstrom.com{href}"
search_data = SearchData(
name=name,
img=img,
url=link,
price=price
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_item(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code != 200:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
reviews_container = soup.select_one("div[id='reviews-container']")
review_cards = reviews_container.find_all("div", recursive=False)
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
subsections = review_card.find_all("div", recursive=False)
user_section = subsections[0]
name = user_section.select_one("div div").text
incentivized = "Incentivized" in user_section.text
verified = "Verified" in user_section.text
review_body = subsections[1]
spans = review_body.find_all("span")
rating_string = spans[0].get("aria-label").replace("Rated ", "").replace(" out of 5 stars.", "")
rating = float(rating_string)
date = spans[1].text
review_data = ReviewData(
name=name,
incentivized=incentivized,
verified=verified,
rating=rating,
date=date
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_item,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 6: Production Run
Finally, it's time to run everything in production. For the sake of brevity, we're going to run on one page. This will give us more than 60 individual items to scrape. Feel free to change any of the following:
MAX_RETRIES: Maximum number of retry attempts for failed HTTP requests.MAX_THREADS: Maximum number of threads that will run concurrently during the scraping process.PAGES: How many pages of search results to scrape for each keyword.LOCATION: The geographic location or country code for the scraping process.keyword_list: A list of product keywords for which the script will perform searches and scrape product information.
You can view our updated main below.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 3
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["boots"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)

If you remember from earlier, our initial crawl took 16.17 seconds per page. The crawl on this run generated a report with 64 items in 946.737 seconds. 946.737 - 16.17 = 930.567 seconds. 930.567 seconds / 64 items = 14.54 seconds per item.
While this may seem slow, most of this time is spent waiting for responses. ScrapeOps is bypassing antibots and waiting for content to render, this part is a lot of work for them... especially when they're bypassing Nordstrom for us!
Legal and Ethical Considerations
When you scrape Nordstom, you are subject to their terms of service. If you read the screenshot from their blocked screen, bots are a violation of their policy.
You can be temporarily or even permanently banned for accessing their site with a bot. Also, you are subject to their robots.txt. Their terms are availabe here and their robots.txt is available to read here.
Scraping the web is generally legal as long as the data is publicly available. Our Nordstrom scraper does violate Nordstrom's terms, but it is only scraping public data and therefore legal.
If you are scraping data behind a login, you and your scraper are subject to the same privacy and intellectual property laws that the site is subject to.
If you don't know that your scraper is legal, consult an attorney.
Conclusion
You've made it to the end. You've scraped one of the most difficult sites on the web!
In our Nordstrom scraping project, you've gotten a great feel for parsing, pagination, data storage, concurrency, and especially proxy integration. You've been introduced to ScrapeOps' anti-bot technology and our residential proxy as well.
If you're interested in the tech stack from this article, check out the links below!
More Python Web Scraping Guides
Here at ScrapeOps, we've got loads of learning materials. If you're scraping with Python, we even wrote the playbook!
If you'd like to to read more from our "How To Scrape" series, check out the links below!