
How to Scrape Capterra With Requests and BeautifulSoup
Capterra is in online site where different businesses can connect with potential customers. Capterra features a uniform interface where we can find all sorts of useful information about different companies. Along with general information for each company, we get reviews from actual people who've dealt with each company.
Today, we're going to build a Capterra scraping project that incorporates the following into the design:
- TLDR: How to Scrape Capterra
- How To Architect Our Scraper
- Understanding How To Scrape Capterra
- Setting Up Our Capterra Scraper
- Build A Capterra Search Crawler
- Build A Capterra Scraper
- Legal and Ethical Considerations
- Conclusion
- More Cool Articles
The full code for this Capterra Scraper is available on Github here.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Scrape Capterra
If you don't have time to read, use our Capterra scraper right here.
- Create a
config.jsonfile with you ScrapeOps API key,{"api_key": "your-super-secret-api-key"}. - Then, copy and paste the code below into a new Python file.
- You can run the code with
python name_of_your_python_script.py.
First, it will generate a crawl report of top sites. Then it will output a competitor report for each site that was extracted during the crawl.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
overall: float = 0.0
ease_of_use: float = 0.0
customer_service: float = 0.0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_business(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
review_cards = soup.select("div[data-test-id='review-card']")
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
name = review_card.select_one("div[data-testid='reviewer-full-name']").text
ratings_array = review_card.find_all("span", class_="sb type-40 star-rating-label")
review_data = ReviewData(
name=name,
overall=float(ratings_array[0].text),
ease_of_use=float(ratings_array[1].text),
customer_service=float(ratings_array[2].text)
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}, Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_business,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
To change your results, feel free to change any of the following:
MAX_RETRIES: Determines the number of times the script will attempt to retry a request if it fails.MAX_THREADS: Sets the maximum number of threads that will be used for concurrent scraping.PAGES: Specifies the number of pages to scrape for each keyword.LOCATION: Determines the geographic location from which the requests will appear to originate.keyword_list: A list of keywords that the script will use to perform searches.
If you choose to change the keyword_list, you need to find the endpoint for your specific search. You can view instructions on how to do that here.
If you're getting bad responses (status code 500), try changing your location.
How To Architect Our Capterra Scraper
We'll start off by brainstorming our architecture. At the highest level, our scraper needs to perform two tasks.
- We need to be able to crawl businesses based on search criteria. If I perform a search for
"cryptocurrency-exchange-software", my scraper should spit out a list of results that match this criteria. - After creating this list, the scraper should also go and scraping ratings and reviews for each company. This way, we get a list of aggregated ratings.
These two features will be handled by two separate scrapers. The first one is called a result crawler. The second will be our review scraper.
To build a decent crawler, we'll break it into smaller steps:
- Parse search results from Capterra.
- Paginate our results, this way we can parse multiple pages.
- Store the parsed data from each page inside of a CSV file.
- Concurrently run steps 1 through 3 on multiple pages.
- Integrate with the ScrapeOps Proxy Aggregator to get past anti-bots, which are quite strong with Capterra.
Here are the steps we'll follow to build the review scraper:
- Parse the reviews from a page.
- Read the CSV file so that we can feed it into the new parsing function.
- Store the parsed reviews inside a new report for each business.
- Scrape multiple businesses with concurrency.
- Integrate with the ScrapeOps Proxy Aggregator once again to bypass anti-bots.
Understanding How To Scrape Capterra
Let's take a look at exactly which information we'll be extracting from Capterra. We need know all of the following before we dive into coding:
- How to Get Capterra Pages
- How to Extract Data from Capterra
- How to Control Our Pagination
- How to Control Our Geolocation
We'll go through the steps above using a web browser before we try to implement them in our code.
Step 1: How To Request Capterra Pages
As always, when we need to fetch a page on the web, everything begins with a GET request. With Requests, we'll perform a GET, and (under the hood) our browser does this too.
When we GET a page we receive an HTML page as a response. Here is where the browser differs from a standard HTTP client. An HTTP client simply gives us an HTML page that isn't very human readable.
The browser is much fancier. Instead of just giving us the raw HTML, the browser reads the HTML and renders the page for us to view.
If you take a look at the screenshot below, you'll see our URL. Our URL is:
https://www.capterra.com/cryptocurrency-exchange-software/
From this we can figure out how the URL is constructed:
https://www.capterra.com/{KEYWORD}/
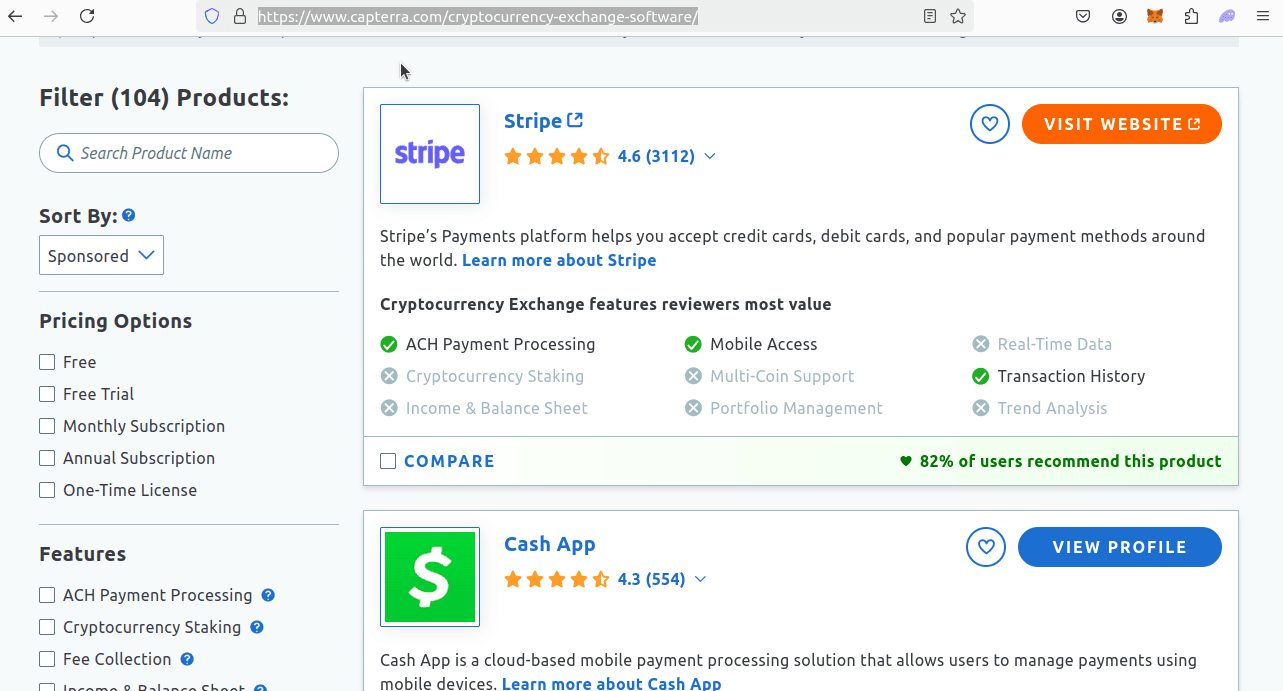
But as you can see, this isn't a traditional keyword. A standard keyword search goes as follows.
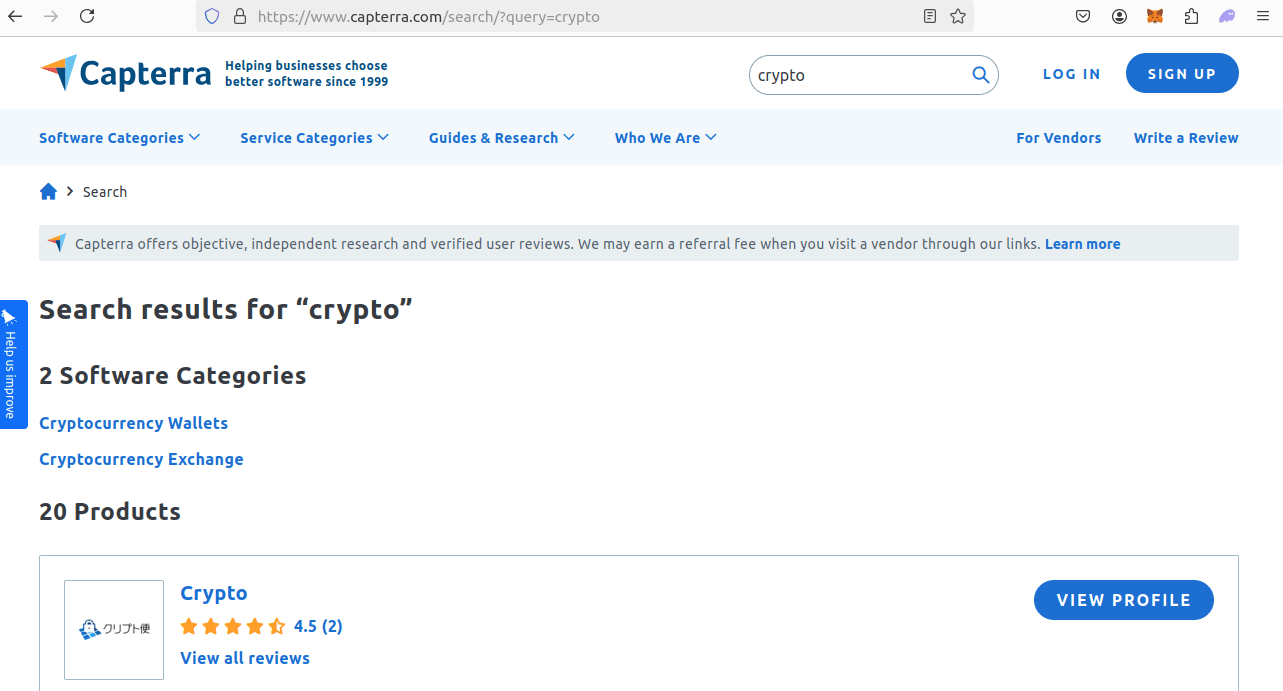
If you click on Cryptocurrency Exchange, it takes us back to the original search results page you saw earlier.
To get your actual keyword, you need to click this button and take the endpoint (in this case cryptocurrency-exchange-software) so you can add it to your url.
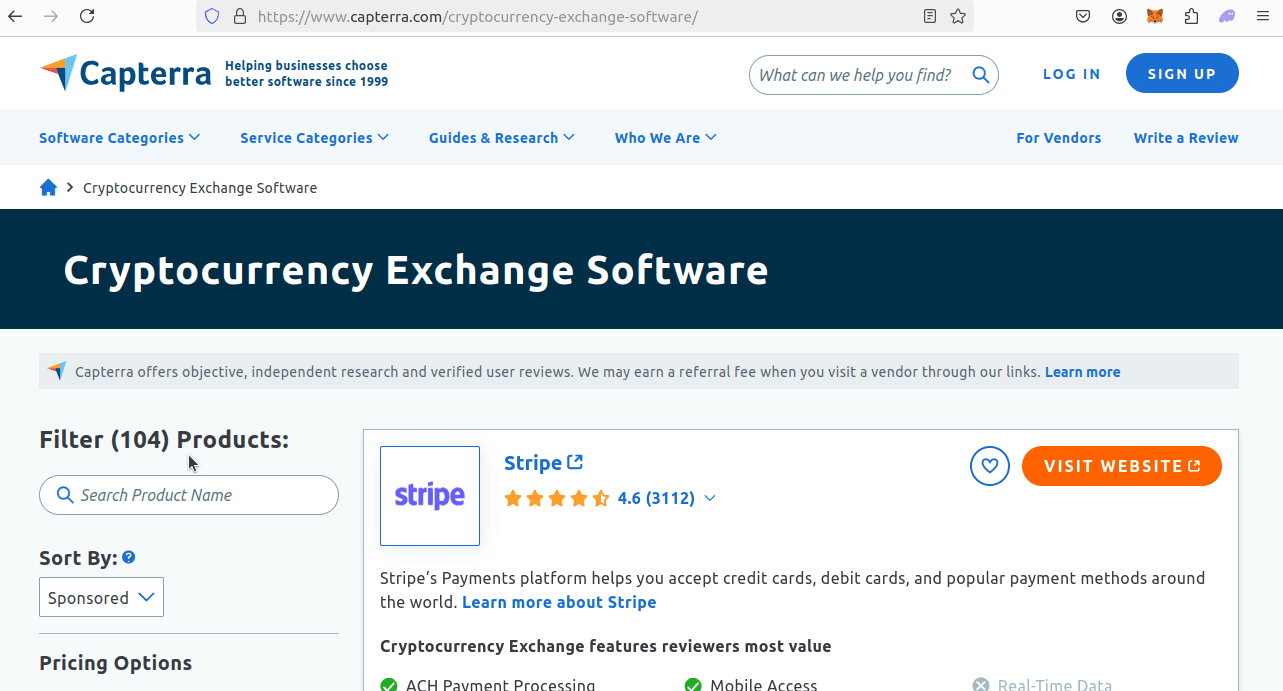
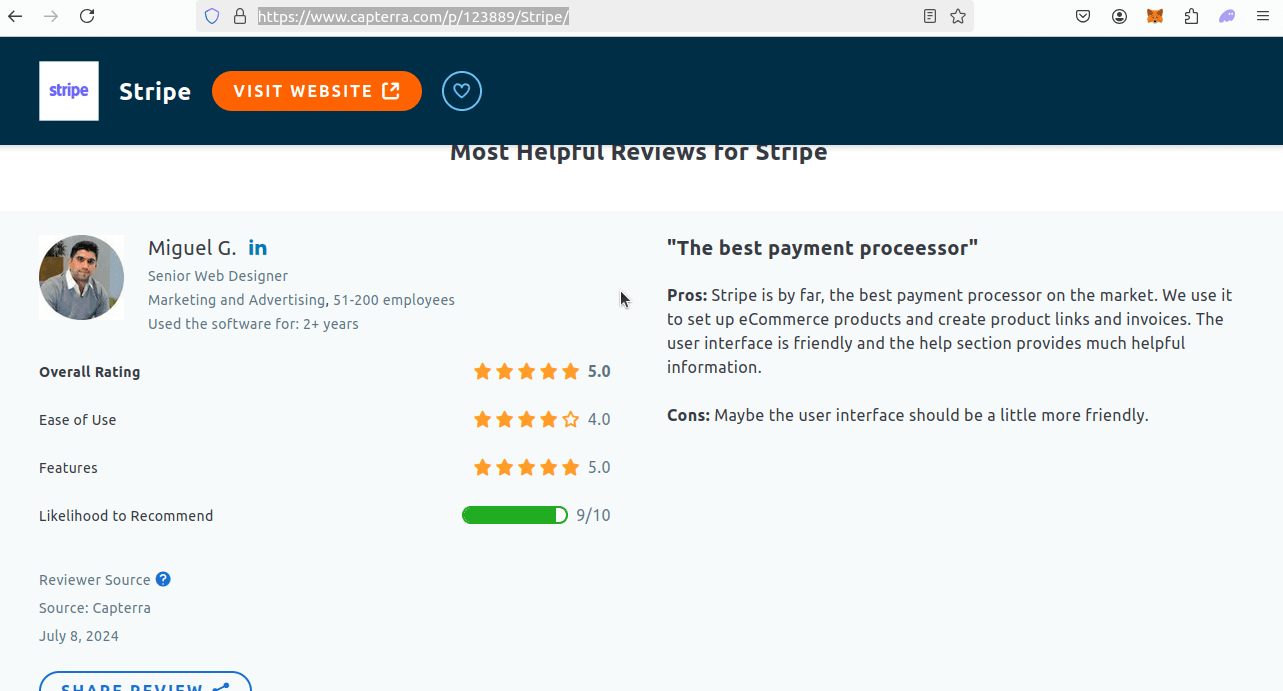
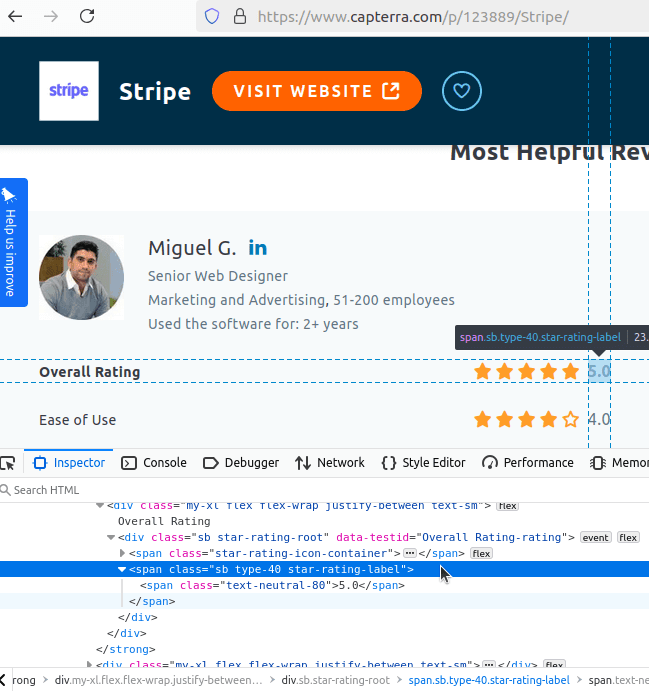
Finding our reviews is much easier. We'll be saving links to each business during the crawl.
In the screenshot below, you can see a review. You can also see the link to Stripe's Capterra page, https://www.capterra.com/p/123889/Stripe/. If you scroll far enough on this page, you'll run into the reviews.
Step 2: How To Extract Data From Capterra Results and Pages
Now that we know how to GET our pages, we need to figure out where their data is and how to extract it. When I say where, I don't mean its location on the page in front of us, but its location inside the HTML. Here, we'll inspect these pages to see where our data is nested.
In our search results, each business is located in a div card. This div card is a direct descendant of our main container, which has a data-testid of product-card-stack.
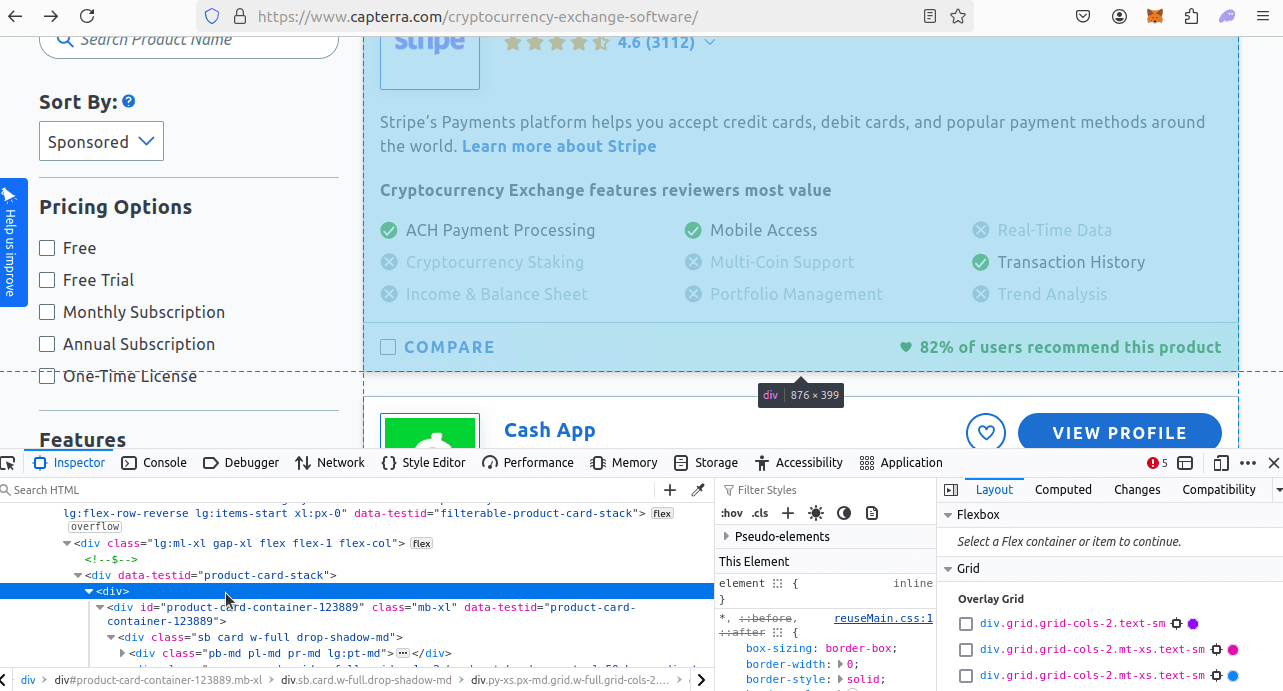
In each review card, customers leave ratings for each business using several different categories. Each rating element is a span with class of sb type-40 star-rating-label. We can actually scrape all of these into an array, which makes the scrape much easier.
Step 3: How To Control Pagination
Our pagination is very simple. We just need to add the page parameter to our URL. We can do this by adding the following onto the end, ?page=2.
Our fully paginated URLs are laid out like this:
https://www.capterra.com/{keyword}/?page={page_number+1}
?tells the server that we'd like to perform a query.pageis the query parameter we'd like to include, and2, is the value we want to assign to thepageparameter.
Step 4: Geolocated Data
To scrape Capterra, we don't actually need to add geolocation support, but we can do this using the ScrapeOps Proxy Aggregator.
ScrapeOps allows us to send a country param. When it receives this parameter, we get routed through the country of our choosing.
- For instance, if we wish to show up in the US, we would pass
"country": "us". - If we wish to show up in the UK, we would pass
"country": "uk".
The list of supported countries is available here.
Setting Up Our Capterra Scraper Project
Let's get started. You can run the following commands to get setup.
Create a New Project Folder
mkdir capterra-scraper
cd capterra-scraper
Create a New Virtual Environment
python -m venv venv
Activate the Environment
source venv/bin/activate
Install Our Dependencies
pip install requests
pip install beautifulsoup4
Build A Capterra Search Crawler
Now that we know exactly what we want to do, let's get start by building our crawler. We'll add features in the following order.
- Parsing
- Pagination
- Data Storage
- Concurrency
- Proxy Integration
Step 1: Create Simple Search Data Parser
Let's set up a basic skeleton. Here, we'll start with just some basic error handling, retry logic and our initial parsing function.
While the overall structure is important, if you're here to learn web scraping, you should pay special attention to scrape_search_results(). That function is where everything is actually happeneing.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, retries=3):
url = f"https://www.capterra.com/{keyword}/"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = {
"name": name,
"url": link,
"rating": rating,
"review_count": review_count
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
scrape_search_results(keyword, LOCATION, retries=retries)
logger.info(f"Crawl complete.")
- First, we find our content holder:
soup.select_one("div[data-testid='product-card-stack']") - Then, we find all the
divelements directly descended from thecard_stack,card_stack.find_all("div", recursive=False). Each of these represents a different business on the page. div_card.find("h2").textfinds the name of each company.- We pull the link with
div_card.find("a").get("href"). - We then find the element holding our
rating_infoand extract its text. - Basic string splitting is used to extract both the
ratingandreview_count.
Step 2: Add Pagination
As we discussed earlier, to add pagination, we need to add a parameter to our URL. Particularly, we need to add the page param. Our new url looks like this:
https://www.capterra.com/{keyword}/?page={page_number+1}
We use page_number+1 because Python's builtin range() function begins counting at 0, but our pages start at 1.
Along with our new url format, we need a function that will go through and run our parser on a list of pages. We're also going to write a function that does this, start_scrape().
def start_scrape(keyword, pages, location, retries=3):
for page in range(pages):
scrape_search_results(keyword, page, retries=retries)
Our full code now looks like this.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, page_number, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = {
"name": name,
"url": link,
"rating": rating,
"review_count": review_count
}
print(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, retries=3):
for page in range(pages):
scrape_search_results(keyword, page, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
start_scrape(keyword, PAGES, LOCATION, retries=MAX_RETRIES)
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
- The
pageparam allows us to select which page to parse. start_scrape()creates a list of pages and feeds them all intoscrape_search_results().
Step 3: Storing the Scraped Data
Storing our data is vital to our project. Later on, we can't do anything with our data if we don't store it. In this section, we're going to create a dataclass to represent search results on the page.
Along with our dataclass, we need a safe and efficient way to store this data via CSV file. This is where our DataPipeline comes in.
Here is our SearchData class.
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
Here is the DataPipeline. It opens a pipe to a CSV file and takes in dataclass objects. It filters out duplicates via their name and then it sends all other results into the CSV file.
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
Now, let's piece it all together.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, retries=3):
for page in range(pages):
scrape_search_results(keyword, page, data_pipeline=data_pipeline, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
- Inside of our
main, we open up aDataPipeline. - We pass the pipeline into
start_scrape(), which in turn passes it into our parsing function. - From inside
scrape_search_results(), our extracted data gets converted intoSearchDataand then passed into theDataPipeline. - Once the crawl has completed, we close the pipeline.
Step 4: Adding Concurrency
Next, we need to add concurrency. This will give us the ability to crawl multiple pages simultaneously. We'll replace a for loop with ThreadPoolExecutor to accomplish this. We just need to rewrite start_scrape().
Here is our new start_scrape() function.
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
scrape_search_resultsis the function we wish to run on available threads.- All other arguments to
scrape_search_resultsget passed intoexecutor.map()as arrays. They are then passed intoscrape_search_resultson each thread that gets run.
You can see the fully updated code below:
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 5: Bypassing Anti-Bots
One last thing before our crawler is complete, ScrapeOps Proxy Integration. This will get us past Capterra's anti-bot system. It is extremely strict, so it's imperative that we use a proxy.
The function below gives us the ability to convert a regular url into a ScrapeOps Proxied URL.
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
Other than the string formatting, pay attention to the payload here:
"api_key": you ScrapeOps API key."url": the url you'd like to scrape."country": the country you'd like to be routed through.
Here is our completed crawler:
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 6: Production Run
Time to run the crawler in production. We'll be scraping 3 pages on 5 threads. Only 3 threads will get used, but we'll use all 5 threads later on when we build the review scraper.
Take a look at the main if you need a refresher.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 3
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Feel free to change any of the following to tweak your results:
MAX_RETRIES: Determines the number of times the script will attempt to retry a request if it fails.MAX_THREADS: Sets the maximum number of threads that will be used for concurrent scraping.PAGES: Specifies the number of pages to scrape for each keyword.LOCATION: Determines the geographic location from which the requests will appear to originate.keyword_list: A list of keywords that the script will use to perform searches.
Here are the results from our 3 page crawl. It took 111.395 seconds to crawl 3 pages. As you can see, we received quite a few 500 status codes. We receive a 500 when ScrapeOps is unable to retrieve the site (we're not charged API credits for unsuccessful attempts). Our retry logic handled the unsuccessful tries.
In total, we crawled at a speed of 37.132 seconds per page.

Build A Capterra Scraper
Now that we're crawling and saving results, we need to scrape reviews for each of the businesses in our crawl report. In these coming sections, we'll build the following features.
- Add a basic parsing function.
- Read our crawl results into a CSV file and pass them into the new parsing function.
- Store the parsed review data.
- Concurrently parse and store each row from the file.
- Integrate with the ScrapeOps Proxy Aggregator to once again avoid being blocked.
Step 1: Create Simple Business Data Parser�
Let's get started again by building a parsing function. As before, it has error handling and retry logic. Take a look at the parsing logic to see exactly what's happening with the data.
def process_business(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
review_cards = soup.select("div[data-test-id='review-card']")
for review_card in review_cards:
name = review_card.select_one("div[data-testid='reviewer-full-name']").text
ratings_array = review_card.find_all("span", class_="sb type-40 star-rating-label")
review_data = {
"name": name,
"overall": float(ratings_array[0].text),
"ease_of_use": float(ratings_array[1].text),
"customer_service": float(ratings_array[2].text)
}
print(review_data)
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}, Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
review_cards = soup.select("div[data-test-id='review-card']")finds ourreview_cards.review_card.select_one("div[data-testid='reviewer-full-name']").textfinds the reviewer's name.review_card.find_all("span", class_="sb type-40 star-rating-label")finds all of our ratings and returns them in an array.
Step 2: Loading URLs To Scrape
Now, we need to read our CSV file. Once we read our CSV file, we need to pass each row from the CSV into our parsing function. In this section, we're going to write another function (similar to start_scrape()) that does exactly this.
Here is our new function, process_results().
def process_results(csv_file, location, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_business(row, location, retries=retries)
- First, we read our CSV into an array of
dictobjects,reader = list(csv.DictReader(file)). - As we iterate through the array, we run
process_business()on each row from the array.
Our fully updated script is available below.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_business(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
review_cards = soup.select("div[data-test-id='review-card']")
for review_card in review_cards:
name = review_card.select_one("div[data-testid='reviewer-full-name']").text
ratings_array = review_card.find_all("span", class_="sb type-40 star-rating-label")
review_data = {
"name": name,
"overall": float(ratings_array[0].text),
"ease_of_use": float(ratings_array[1].text),
"customer_service": float(ratings_array[2].text)
}
print(review_data)
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}, Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_business(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, retries=MAX_RETRIES)
Step 3: Storing the Scraped Data
Storing our extracted data will be pretty easy at this point. We already have our DataPipeline, we just need another dataclass. Let's create one! We'll call this one ReviewData.
Here is our new dataclass.
@dataclass
class ReviewData:
name: str = ""
overall: float = 0.0
ease_of_use: float = 0.0
customer_service: float = 0.0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
In the code below, we open a new DataPipeline inside of our parsing function. As we parse our ReviewData objects, we pass them into the pipeline.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
overall: float = 0.0
ease_of_use: float = 0.0
customer_service: float = 0.0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_business(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url, location=location)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
review_cards = soup.select("div[data-test-id='review-card']")
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
name = review_card.select_one("div[data-testid='reviewer-full-name']").text
ratings_array = review_card.find_all("span", class_="sb type-40 star-rating-label")
review_data = ReviewData(
name=name,
overall=float(ratings_array[0].text),
ease_of_use=float(ratings_array[1].text),
customer_service=float(ratings_array[2].text)
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}, Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_business(row, location, retries=retries)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, retries=MAX_RETRIES)
- From within our parsing function we open a
DataPipeline. - As we parse data into
ReviewData, we pass it into theDataPipeline. - When we're finished parsing the
ReviewData, we close theDataPipeline.
Step 4: Adding Concurrency
Adding concurrency will seem familiar at this point. Once again, we'll use ThreadPoolExecutor to add multithreading and use multiple threads to control our concurrency.
Take a look at our rewritten version of process_results().
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_business,
reader,
[location] * len(reader),
[retries] * len(reader)
)
- The
process_businessarg is the function we want to call on each thread. - All other arguments get passed in as arrays.
Step 5: Bypassing Anti-Bots
We already have our proxy function. We just need to put it in the correct place. To bypass anti-bots and unlock the power of proxy, we'll change a single line of the parsing function.
response = requests.get(get_scrapeops_url(url, location=location))
Our code is finally ready for production.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us"):
payload = {
"api_key": API_KEY,
"url": url,
"country": location
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
url: str = ""
rating: float = 0.0
review_count: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class ReviewData:
name: str = ""
overall: float = 0.0
ease_of_use: float = 0.0
customer_service: float = 0.0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
# Check string fields
if isinstance(getattr(self, field.name), str):
# If empty set default text
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
# Strip any trailing spaces, etc.
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=50):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
data_to_save = []
data_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.csv_file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if self.is_duplicate(scraped_data) == False:
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and self.csv_file_open == False:
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
def scrape_search_results(keyword, location, page_number, data_pipeline=None, retries=3):
url = f"https://www.capterra.com/{keyword}/?page={page_number+1}"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Recieved [{response.status_code}] from: {url}")
if response.status_code != 200:
raise Exception(f"Failed request, Status Code {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
card_stack = soup.select_one("div[data-testid='product-card-stack']")
div_cards = card_stack.find_all("div", recursive=False)
for div_card in div_cards:
name = div_card.find("h2").text
href = div_card.find("a").get("href")
link = f"https://www.capterra.com{href}"
rating_info = div_card.find("span", class_="sb type-40 star-rating-label").text.split("(")
rating = float(rating_info[0])
review_count = int(rating_info[1].replace(")", ""))
search_data = SearchData(
name=name,
url=link,
rating=rating,
review_count=review_count
)
data_pipeline.add_data(search_data)
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}, retries left {retries-tries}")
tries+=1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def start_scrape(keyword, pages, location, data_pipeline=None, max_threads=5, retries=3):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
scrape_search_results,
[keyword] * pages,
[location] * pages,
range(pages),
[data_pipeline] * pages,
[retries] * pages
)
def process_business(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
review_cards = soup.select("div[data-test-id='review-card']")
review_pipeline = DataPipeline(csv_filename=f"{row['name'].replace(' ', '-')}.csv")
for review_card in review_cards:
name = review_card.select_one("div[data-testid='reviewer-full-name']").text
ratings_array = review_card.find_all("span", class_="sb type-40 star-rating-label")
review_data = ReviewData(
name=name,
overall=float(ratings_array[0].text),
ease_of_use=float(ratings_array[1].text),
customer_service=float(ratings_array[2].text)
)
review_pipeline.add_data(review_data)
review_pipeline.close_pipeline()
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}, Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_business,
reader,
[location] * len(reader),
[retries] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 6: Production Run
Now, it's time to test our scraper in production. If you need a refresher, you can view our updated main below. As always, feel free to change the constants to tweak your results. This time, we'll only crawl one page.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
PAGES = 1
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["cryptocurrency-exchange-software"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(csv_filename=f"{filename}.csv")
start_scrape(keyword, PAGES, LOCATION, data_pipeline=crawl_pipeline, max_threads=MAX_THREADS, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
This time, our crawl completed and spat out the CSV file in about 5 seconds and gave us 25 results. The total crawl and scrape took 87.457 seconds. 87.457 - 5 = 82.457 seconds. 82.547 seconds / 25 results = 2.298 seconds per result.

Legal and Ethical Considerations
Scraping public data on the web is typically considered legal. In this tutorial, all the data we scraped was public. Public data is any data that hasn't been gated behind a login page.
If you scrape private data, you are subject to a whole slew of intellectual property laws and privacy regulations around the globe.
Although scraping Capterra was completely legal, they do have a set of Terms of Use and a robots.txt that they expect people to abide by. Failure to comply with these can result in suspension or even a permanent ban.
If you're unsure of your scraper, you should talk to an attorney.
Conclusion
In conclusion, Capterra is an extremely difficult site to scrape, not because of its layout, but because of their anti-bot systems.
ScrapeOps Proxy Aggregator gets us through this with relative ease. We do occasionally receive status 500, but the retry logic takes care of this. If you'd like faster results, you could even use a residential proxy by adding "residential": True to get_scrapeops_url(), but this will be more expensive.
You should have a solid understanding of iterative building. You should also understand parsing, pagination, data storage, concurrency, and proxy integration. If you'd like to understand more about the tech stack used in this article, take a look at the links below.
More Python Web Scraping Guides
At ScrapeOps, we love web scraping! We've got all sorts of learning materials for brand new and experienced developers. We even wrote the Python Web Scraping Playbook!
To read more of our "How to Scrape" series, check out the links below!