
Scrapy Redis Guide: Scale Your Scraping With Distributed Scrapers
Scrapy-Redis is a powerful open source Scrapy extension that enables you to run distributed crawls/scrapes across multiple servers and scale up your data processing pipelines.
Scrapy Redis is a powerful tool for turning your spiders into distrubted workers for large scale and reliable scraping so in this guide we will go through:
- Why Use Scrapy Redis?
- Scrapy-Redis Scraping Architectures
- How To Setup Scrapy Redis
- How To Use Scrapy Redis In Your Spiders
- How To Use Scrapy Redis In Your Crawlers
- How To Setup Distributed Item Processing
- Enabling Advanced Scrapy-Redis Settings
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Why Use Scrapy Redis?
Scrapy-Redis enables you to build a highly scalable and reliable scraping infrastructure through the use of distrubted workers that all shared a centralised scheduling queue.
Giving you a number of huge advantages over vanilla Scrapy:
- Easy Scaling: If your scraping pipeline isn't able to scrape fast enough and is getting backlogged, then you can easily connect more workers to your central Scrapy-Redis queue and speed up your job.
- Reliability: A common issue developers run into is that if a spider crashes mid job then they often have to start the scrape again from the start. With Scrapy Redis, as the Scheduler queue is stored in Redis, if a spider crashes then you can just start a new worker who will continue where the previous one stopped.
- Seperated Data Processing: Scrapy Redis makes it very easy to seperate the data processing pipeline from the scraping process, allowing you to scale up your scraping and data processing independantly of one another.
- Syncronizing Large Crawls: Scrapy Redis is a great solution if you are doing large broad crawls that would be too slow if you could only use a single spider running on one machine.
Scrapy-Redis Scraping Architectures
One of Scrapy-Redis' biggest selling points is the powerful scraping architectures it unlocks for developers:
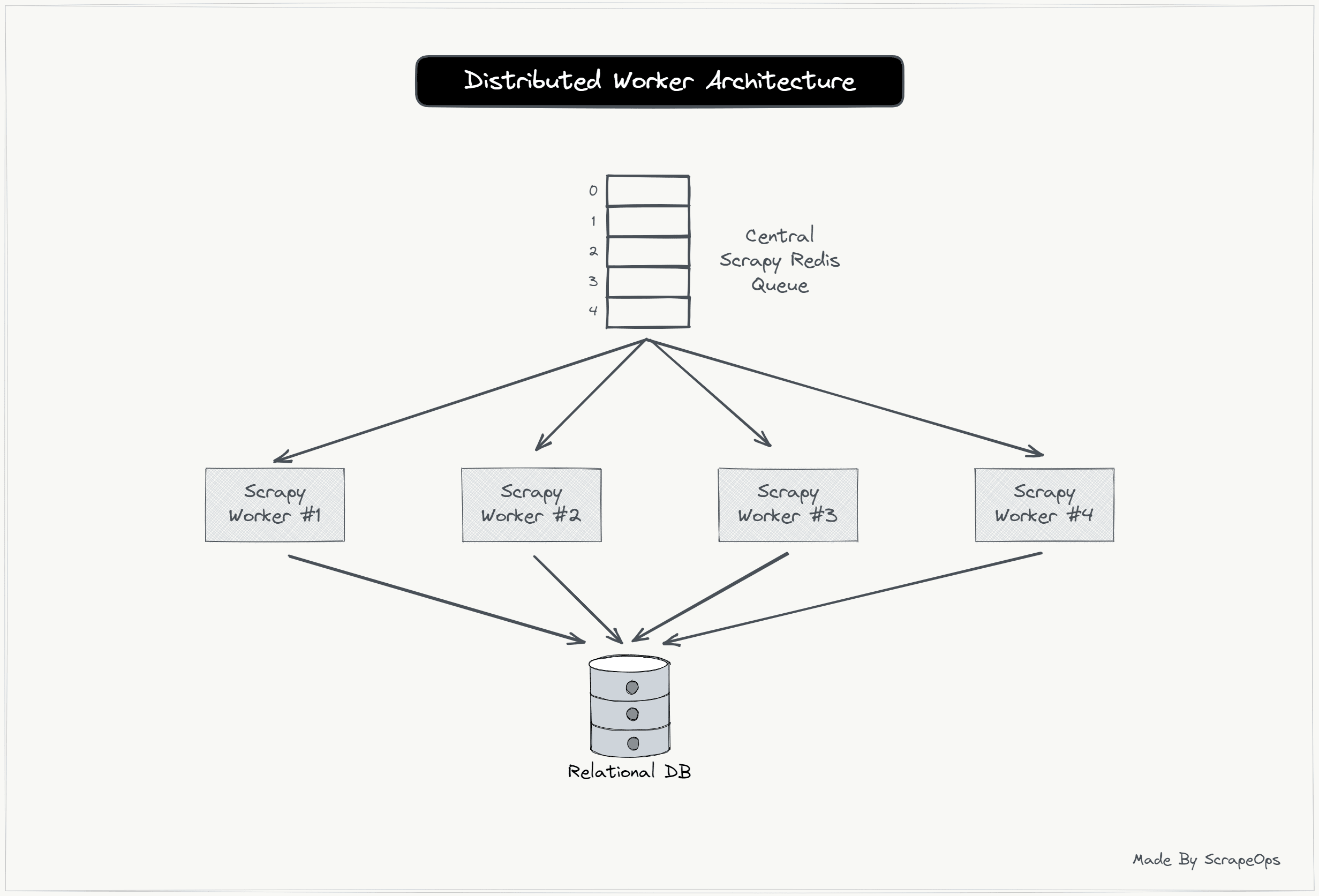
1. Distributed Worker Architecture
Scrapy-Redis enables you to spin up multiple workers that all scrape from one centralized queue and without the risk of workers sending duplicate requests.
Scrapy-Redis is very useful if you need to split a large scrape over multiple machines if a single spider running on one machine wouldn't be able to handle the entire scrape.
2. Distributed BroadCrawl Architecture
When using Scrapy's CrawlSpider or running BroadCrawls the size of the scraping job can get big and resource intensive very fast. And given the nature of Crawling it can be hard to split a crawling job up amongst numerous crawlers at the start.
Scrapy Redis can be game changer for these types of crawling jobs as Scrapy Redis makes it very easy to distribute the crawl across numerous workers whilst ensuring the same pages aren't crawled twice. And if a crawler crashes or is paused the job can resume at the same spot again.

By integrating Scrapy Redis with your Scrapy Crawlers, you are configuring all your Crawlers to use the same request scheduling queue and when a crawler discovers a new URL to scrape, that URL is added to central queue which any crawler can then take and process.
3. Seperated Data Processing Architecture
Following the principles of seperatation of concerns, when scraping at large scales, it is generally recommended to seperate the HTML retrieval process from your data parsing and data processing pipelines.
This enables you to scale your scrapers and data processing pipelines independantly of one another, and make each more fault tolerant.
Using this architecture, you could configure your scrapers to store all the HTML/scraped data in a Redis memory store, from which a single data processing worker can parse and clean the data from every scraper.

Or you could add mulitple data processing workers all pulling data from from the same the same Redis queue.

How To Setup Scrapy Redis
Getting Scrapy Redis setup is very simple.
Step 1: Redis Database
The first thing you need to use Scrapy Redis is a Redis database. Redis is a open source in-memory data store that can be used as a database, cache, message broker, and more.
You have multiple options when getting a Redis database setup:
- Install Redis on your local/virtual machine.
- Purchase a managed Redis instance from infrastructure provider like Digital Ocean, Amazon Web Services(AWS), or Redis itself.
For simplicity sake we will use Redis' 30MB free plan as it is very simple to setup and use for development purposes.
Simply sign up here, and follow the instructions until you recieve your Redis databases connection details which will look like this:
"redis://<username>:<password>@redis-18905.c12.us-east-1-4.ec2.cloud.redislabs.com:18905"
Step 2: Install Scrapy-Redis
Next step is to install Scrapy-Redis in your virtual environment:
pip install scrapy-redis
Step 3: Integrate Scrapy-Redis Into Our Scrapy Project
Finally, we need to integrate Scrapy-Redis into our Scrapy Project by updating our settings.py file (or our custom_settings in our spider):
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Redis Connection URL
REDIS_URL = 'redis://<username>:<password>@redis-18905.c12.us-east-1-4.ec2.cloud.redislabs.com:18905'
The above is the most basic integration that just uses Redis as a central scheduler, however, later in this guide we will look at other Scrapy-Redis configurations, including how to create a distrubuted data processing pipeline with Scrapy-Redis.
How To Use Scrapy Redis With Your Spiders
Reconfiguring your normal spiders to use Scrapy Redis is very straightforward.
First, we need to import RedisSpider from scrapy_redis.spiders, and set our spider to inherit from this Spider class.
In the below example, we will build a QuotesToScrape spider that uses Scrapy Redis.
import scrapy
from scrapy_redis.spiders import RedisSpider
class QuotesSpider(RedisSpider):
name = "quotes"
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
By default, Scrapy Redis will use '<spider_name>:start_urls' as the Redis queue name it uses to manage requests. However, you can override this in the settings.py file by defining a global naming convention:
## settings.py
REDIS_START_URLS_KEY = '%(name)s:start_urls'
Or on a per spider basis by defining a redis_key attribute to our QuotesSpider along with the Redis key that will contain the URLs we want to scrape:
import scrapy
from scrapy_redis.spiders import RedisSpider
class QuotesSpider(RedisSpider):
name = "quotes"
redis_key = 'quotes_queue:start_urls'
# Number of url to fetch from redis on each attempt
# Update this as needed - this will be 16 by default (like the concurrency default)
redis_batch_size = 1
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
Now when we run our QuotesSpider using scrapy crawl quotes, our Spider will start polling the quotes_queue:start_urls list in our Redis database.
Then if there are any URLs in the queue, our spider will remove that URL from the queue and scrape the page.
With the above setup, your spider won't close until you shutdown the spider from the command line. It will remain continuously in idle mode, polling your URL queue and scraping any URLs that are added to the queue.
To add URLs to the queue you just need to push URLs to the Redis list using lpush. Here is an example Redis command:
lpush quotes_queue:start_urls https://quotes.toscrape.com/
During development you can use a Redis GUI like RedisInsight to view and push data to your Redis Queue, however, in production you will want to have another script that pushes URLs to the queue.
You can do this with the Python Redis library.
import redis
from redis import from_url
# Create a redis client
redisClient = redis.from_url('redis://<username>:<password>@<redis-connection-url>:<redis-port-number>')
# Push URLs to Redis Queue
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/1/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/2/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/3/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/4/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/5/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/6/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/7/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/8/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/9/")
redisClient.lpush('quotes_queue:start_urls', "https://quotes.toscrape.com/page/10/")
Here is another spider integration example provided by Scrapy-Redis.
Close Spider Once Queue Is Empty
Depending on your use case, you mightn't want your Spider to idle indefinetly checking the queue for new URLs and never shutting down.
In a lot of cases, you might want to start up a couple of spider workers who all pull from the same queue but who automatically close down when the queue is empty.
We can accomplish this by using the max_idle_time value which as you might guess is the max amount of time that the spider will idle for before it shuts itself down. Since the spider will idle for 0.5-1 second before checking redis each time for another url to scrape(or batch of URLs (modify this with redis_batch_size)) a max_idle time of greater than 2 seconds is recommended:
import scrapy
from scrapy_redis.spiders import RedisSpider
class QuotesSpider(RedisSpider):
name = "quotes"
redis_key = 'quotes_queue:start_urls'
redis_batch_size = 1
# Max idle time(in seconds) before the spider stops checking redis and shuts down
max_idle_time = 7
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
How To Use Scrapy Redis In Your Crawlers
If you are using a Scrapy Crawler like CrawlSpider then the Scrapy-Redis integration is slightly different.
Here we will need to import RedisCrawlSpider from scrapy_redis.spiders, and set our crawler to inherit from this Crawler class.
import scrapy
from scrapy.spiders import Rule
from scrapy_redis.spiders import RedisCrawlSpider
from scrapy.linkextractors import LinkExtractor
class QuotesSpider(RedisCrawlSpider):
name = "quotes_crawler"
allowed_domains = ["quotes.toscrape.com"]
redis_key = 'quotes_crawler:start_urls'
rules = (
Rule(LinkExtractor(allow = 'page/', deny='tag/'), callback='parse', follow=True),
)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
Here is another crawler example provided by Scrapy-Redis.
How To Setup Distributed Item Processing
So far we have just looked at how to use Scrapy-Redis to build a distributed scraping architecture by using Scrapy-Redis as a centralised queue from which all our scrapers can use to manage which requests they should send.
However, Scrapy-Redis also enables you to seperate the data processing pipeline from the scraping process by having your scrapers push the scraped html/items to a centralised item pipeline.
From which you can have other workers pull items from and process the data.
To enable the Scrapy-Redis Item pipeline, we just need to update our settings.py file to include the following:
# settings.py
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
By default, Scrapy Redis will push your scraped Items into a Redis queue called spider_name:items, however, you can change this using the REDIS_ITEMS_KEY vallue in your settings.py file.
# settings.py
REDIS_ITEMS_KEY = '%(spider)s:items'
Depending on your use case, you can have Scrapy preprocess your scraped data in other pipelines before pushing it to the Redis queue by giving the RedisPipeline as higher value than your other pipelines. For example:
# settings.py
ITEM_PIPELINES = {
'demo.pipelines.MyPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 500
}
Now, once your spider has extracted the data from the page and processed it through all the preceeding Item pipelines it will push the Item to your Redis queue.
From here, you can build other workers to pull the Items from the queue one-by-one or in batches, and process, validate and store them in other databases.
From testing, it looks like the Scrapy-Redis Item Pipeline doesn't work well with Scrapy Items as the data can get corrupted. Instead, you should yield dictionaries/JSON objects within your scrapers.
Enabling Advanced Scrapy-Redis Settings
We've covered a lot of the basics you need to get Scrapy-Redis setup and running with your spiders, however, Scrapy-Redis does offer further customizations that you may want to enable based on your usecase.
You can check out the offical documentation for a full list of customization options, however, in this guide we're going to walk through some of the most useful options.
Scheduler Queue Types
By default, Scrapy Redis uses a Priority Queue like how Scrapy's own scheduler works. However, Scrapy-Redis also allows you to use First-In-First-Out (FIFO) Queues and Last-In-Last-Out (LILO) Queues.
You can enable them in your settings.py file by setting the SCHEDULER_QUEUE_CLASS to your desired queue type.
# settings.py
# First-In-First-Out (FIFO) Queue
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
# Last-In-Last-Out (LILO) Queue
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
Scheduler Persistance
Another valuable option Scrapy Redis gives you is the ability to enable persistant Scheduler Queues. With this option enabled you can resume crawls after you've paused a job or a spider crashed and not have to begin the job at the start again.
This is particularly valuable when doing large scrapes or broadcrawls as starting from the start again can be a nuisance and costly in terms of increased infrastructure and proxy costs.
To enable persistant Scheduler Queues simply set SCHEDULER_PERSIST = True in your settings.py file and Scrapy-Redis won't clean up the queue when a job is paused or crashes.
# settings.py
# Don't cleanup redis queues, allows to pause/resume crawls.
SCHEDULER_PERSIST = True
Stats Collector
By default, when you use Scrapy-Redis with your scrapers they will all log their own stats as normal for each individual job.
However, Scrapy-Redis gives you an option to use a centralized stats object for every worker pulling from the same queue. This way you can have a combined stats object for the entire job.
To enable this, you simple need to update the STATS_CLASS and define a STATS_KEY for where the stats will be stored in Redis in your settings.py file:
# settings.py
STATS_KEY = '%(spider)s:stats'
STATS_CLASS = 'scrapy_redis.stats.RedisStatsCollector'
More Scrapy Tutorials
Scrapy-Redis is a powerful extension that every serious Scrapy developer should be aware of, as it can really take your scraping infrastructure to the next level.
If you would like to learn more about Scrapy in general, then be sure to check out The Scrapy Playbook.