
Python Scrapy Login Forms: How To Log Into Any Website
Logging into websites to scrape the data you need can be a tricky business.
You need to worry about filling out forms, managing headers, session/browser authenication, managing IP addresses.
Luckily for us Scrapy developers, Scrapy provides us a whole suite of tools and extensions we can use to log into any website.
In this guide we will look how the most popular methods to log into websites and other best practices:
- First Step: Analyse Login Process
- Login Method #1: Simple FormRequest
- Login Method #2: FormRequest With Hidden Data
- Login Method #3: Using Headless Browser To Login
- Not Getting Blocked After Logging In
- Risks Of Scraping Behind Logins
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
First Step: Analyse Login Process
The first step in building a scraper that can login and scrape data behind a websites login page is understanding how their login process works.
To do this, first make sure you are logged out, then go to the Login page of the website you want to scrape.
Open the Network Tab of your Developer Tools, which we will use to analyze the network traffic and see how the websites login process works.
Then go through the login process in your browser.
Here you will want to look out for:
- The URL the website uses to login.
- The payload the login process sends.
- Any headers or cookies the login request needs.
After looking through the network tab your goal is to identify which login method will work best for your target website.
We will go through each of the 3 main login methods in detail below, however, here is a quick summary of when to use each method:
- Login Method #1: Simple FormRequest - Rare to see websites where this works anymore, however, if the website only requires you to send a username/email and password, and not security tokens then just send a simple FormRequest with the required data.
- Login Method #2: FormRequest With Hidden Data - Most websites require hidden data to log into a website that you must extract from the login page. If all the hidden data can be found on the login pages initial HTML response then you can extract them and add them to your FormRequest.
- Login Method #3: Headless Browser Logins - Some websites dynamically generate the hidden data needed to login in the browser or just have very complicated login processes. In cases like these we can login using a headless browser which will simplify our login process and then either continue scraping with the headless browser or pass the session cookies to our normal Scrapy requests.
Login Method #1: Simple FormRequest
At its simplest, logging into a website is just submiting data to a form.
Luckily for us, Scrapy makes it pretty easy to submit form data using Scrapy's inbuilt FormRequest class.
In this very simplistic example, we're going to use the FormRequest class to submit a login form that just takes the users email and password as inputs.
from scrapy import Spider
from scrapy.http import FormRequest
class SimpleLoginSpider(Spider):
name = 'simple_login'
def start_requests(self):
login_url = 'http://example.com/login'
return FormRequest(login_url,
formdata={'email': 'example@gmail.com', 'password': 'foobar'},
callback=self.start_scraping)
def start_scraping(self, response):
## Insert code to start scraping pages once logged in
pass
Here, we are simply configuring our scraper to POST our form data to the forms URL endpoint using the FormRequest class to log into the website, and once complete it will start scraping pages as defined in the start_scraping() method.
Scrapy will then handle the session cookies, etc. so that every page you request will be returned by the website as if you were logged in.
This is an overly simplistic example, as today very few websites just have simple forms for login pages. Most have some form of security feature that you need to factor in when making designing your scraper.
In the next section we will look at a more realistic example.
Login Method #2: FormRequest With Hidden Data
Most signup and login forms these days use some form of hidden data to authenticate your request when you are logging into a website.
In cases like these, we first need to request the page with the login form itself and then extract this hidden data so we can then add it to our FormRequest.
For this example, we will use the QuotesToScrape login page, as the page won't change in the future so you can follow along with it.
First things first, we go through the login process in our browser with the Network tab of our Developer Tools open.
Whilst having the Network tab open and logged out, go to http://quotes.toscrape.com/login and enter foobar as both the username & password (anything works here). Then click login.
You should see the following network calls in your network tab. The two network calls we care about at the first two.

The first is a POST request that is used to send the form data to the server, which returns a 302 status code which means our request gets redirected to the main quotes.toscrape.com page after logging in.
If we click on the Payload tab of the login POST request, we can see the data that is needed to successfully login.

Here, we can see the username and password that we entered into the boxes, however there is also a field called csrf_token.
A CSRF token is a unique, secret, unpredictable value that is generated by the server-side application and transmitted to the client so that it can be included in a subsequent HTTP request made by the client, like logging into to a website.
In this case, the csrf_token is generated by the QuotesToScrape server and added to the initial HTML response in a hidden <input> field.
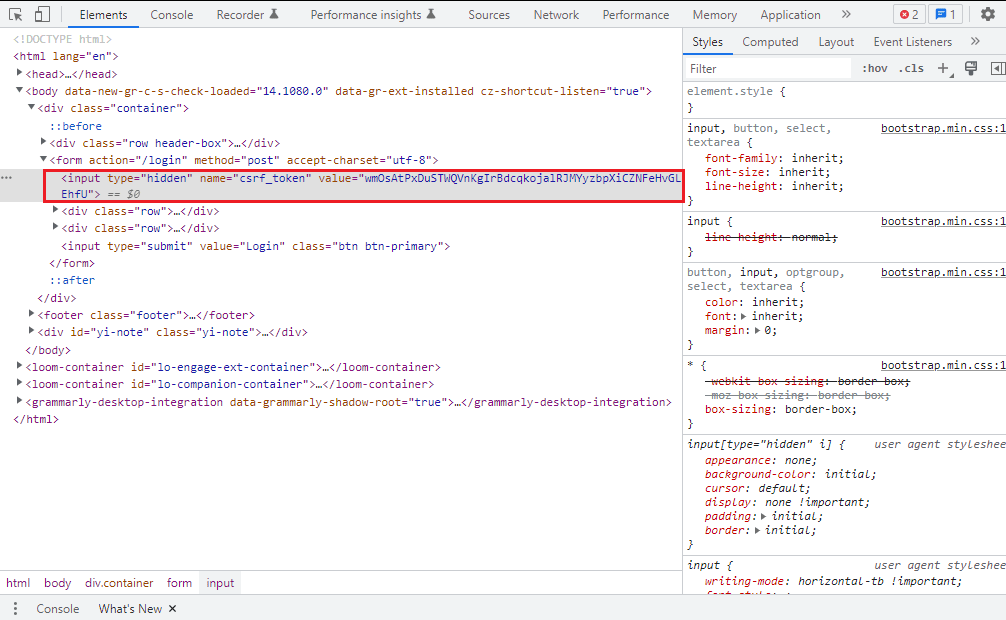
Everytime we refresh the page the csrf_token will change, so we will need to first request the login page, extract the csrf_token from the hidden input field and then add that to our FormRequest.
import scrapy
from scrapy import Spider
from scrapy.http import FormRequest
class HiddenDataLoginSpider(Spider):
name = 'hidden_data_login'
def start_requests(self):
login_url = 'http://quotes.toscrape.com/login'
return scrapy.Request(login_url, callback=self.login)
def login(self, response):
token = response.css("form input[name=csrf_token]::attr(value)").extract_first()
return FormRequest.from_response(response,
formdata={'csrf_token': token,
'password': 'foobar',
'username': 'foobar'},
callback=self.start_scraping)
def start_scraping(self, response):
## Insert code to start scraping pages once logged in
pass
Now when you run this code, Scrapy will login into the QuotesToScrape website and then you can start scraping as if you were logged in.
Login Method #3: Using Headless Browser To Login
The above example will work for a lot of simple real-world websites that you will find today. However, it is still too simplistic compared to the login process of most modern websites.
So to give us a more realistic example, we're going to look at how to log into Amazon.com and then scrape product pages whilst logged in.
Amazon uses a 2-step login process with a username/email page and a password page, and as we will see from the Payloads it requires a lot more data to successfully log in.

To get started we will go through the login process like before with the Network Tab open.
From looking at the Payload Tab, we can see that Amazon sends a lot more data to the server than QuotesToScrape during Step 1 (enter username/email):
appActionToken: o35S9FuQrkaFvid5z3ZU9fGB1loj3D
appAction: SIGNIN_PWD_COLLECT
subPageType: SignInClaimCollect
openid.return_to: ape:aHR0cHM6Ly93d3cuYW1hem9uLmNvbS9ncC95b3Vyc3RvcmUvaG9tZT9wYXRoPSUyRmdwJTJGeW91cnN0b3JlJTJGaG9tZSZzaWduSW49MSZ1c2VSZWRpcmVjdE9uU3VjY2Vzcz0xJmFjdGlvbj1zaWduLW91dCZyZWZfPW5hdl9BY2NvdW50Rmx5b3V0X3NpZ25vdXQ=
prevRID: ape:OEcyQjFIUUJTVloxVDdCQVc3V1E=
workflowState: eyJ6aXAiOiJERUYiLCJlbmMiOiJBMjU2R0NNIiwiYWxnIjoiQTI1NktXIn0.nuZBJK-5HRwIApef7T-QyLZlJe6PLKz_4pynIiBbrr13JiHhEAsXYA.BLNtWH7PyvbYMp_U.uhMXTy6V7C7QwLT0syP6asf0d9ZgpQ_QfbLB3MwtCo2DTuiVDiiiRFuMolJioYqJkkBCNXqs-_dz3F9ozJVuXi_g7MTKgaxmVGaEOCJ7k2UrD7l3OMO_54ocnWk3Q1EjlOSVWVryzLn6Lj3FE4yDHQ85OlXyh9dq54fwCqzMopAi_ZO-w4Sw6gVYt9n9vSTrDpTn9OKb7Ep0_0w2Rd18R1w1tuyY6HibY0tTd0Wknorwm1WKdQhIBSkR4dVKnlmcw4MjpB2MeCYppgePMd8KdCiCABTAWgsm43W7XKYlIpQ9j5OrxXzJBCpJrAAXxxH9ssE.V2IAWZe-QK4twYM6V5zKfw
email: myemail@gmail.com
password:
create: 0
metadata1: ECdITeCs:tj/Z1TGgzan7hZN7Vk4eDMcg3XuvZ2s6PKY9bZweg1RoA7PNkL0gCD427ebNlcUWgU/sMzmg27eCbzP+GR5E0MJv05Hdg4VA1cDbv50n9G35wYGllmoGzlucgo5M5YhXb72oWG+6CT1w43r/MCiYrCqfqlB7A0UxTuv+f6UpqjNtFYFZeJ5BJjkmn5P1QRuG5TZfoQ8uFikZj7MSoXBdRsTNZ98xyV6PzPLSDuj10jXbfQadoX1ak7Gcw9jEFyNRRHAxlMMWMF1YzSlLEuFqIDKH32ZU7Wd4O1Ek+jyd4aSkGW+QKL4MShqZoYSrVe2gfAfUZyB0c/rELjcS39mobAnHamOfH6TDPz2WFECnqCQzm9azg+ptZWGtClHMY70aBK6tamtlw9mMIExGLEjx9Dc5oHjrSXf0hnRfQTkFS1YTN1AXGh21Ok2PtdPdK4lHxDqshZjBDXnYLMgAXaoLhMhKO/N0f2Irt4YMNFF5sXG/kWrDFA1z8Zi3gtnT2crJY1tERAfHiogMHHq6viaBakraGDak11UGGbuf1H9sgbFO91O2ho6CCdEM1gnl0LKPYluW6QzIBCW8W9Xium63WYEoP9dbL1mpiwDNA/SEavjCncGy7OJtI7gPU3uj0fpz/rfZYtsUu249sWTWmgoaj9vdYroYzATlQGc8Fqy/qjhvkS/QY4UlOc7Xroi+ZmtjIlVSY9kzDZ1+kuLgvBXw79UVOu+Pn8bZzFYU/VujJ+tA55b48FZfQ7LZUsloQsJISwk8dMi+SuhiHw6PUACATz8XRJb4lnflcsS4b1lyeJKS9RVyQIOVLPewh218UWhkY5ZsUX6LakZDU9SmksI6jeAGboXeiKZ+U3iQW76LOMKMQawp99mdju/zdoS3GsywrzLuMezgwc71T+nhTiBM7t0nb3FG6TXtTvOQE7h8v73p3K75Hs3HXz/qekYcs863XHDIpbvMl3fINwrT8P1bJ33W8lAylI6jDK6Hf4oxgby4vfIf7WzcPyWfp6qiqlFU75zXoFvwfQ1F0Nu81lp0Neui4Z0G8PEMc1HiOCPwLX7dDCZLlqJWw3Sr+Q92q4bUs6I4nq9duHLLBMay3c4c1+U8m+s70dzxorgiPT8yrYyNDMQUsxkDfPC6emB+NTuFJFunFRCBO9GyapAPkQNUEbicO00o0tZp9ASvgiLEFezV8kA9xjQHrisXY+SrIbJ5nZqx8sxondFt5Q9hfs6/nM9i0qtCVZd2P91v0FTbEMYjEN3dUKAaMbRFV3KfOnro+vo2A1PCpnRK7dct+xrgFVtCoYVht1pZR6jG/ZGPG1xYEx92//cYztGVF5siireNE0ZVmbV/GyrcgSh4HgiPq0aGQd5n5LWb7IWhId84q6gbCcZovx1H2Xl9dKXzbLIE+nr+wM07VFRG7Pjqi0SXv83QAiPebwubtA4nHMSOypwDKVQnvCSpfJ/buC9SEesPWuSlVGHvsxLneL8tATs+QgLIspU/xkZSsmLocB6YGbDv3QyrL9vfI2FsFTYMBM5X+qLzcRRKfN0hu6nK3E9czd8BJVB06XQ1oMD5X9qj+/FTbPz7jwSVWJB/cCN+rZ/fkbQvtYL/1a+ZMNyOJ03PUm2WvaQmpPa9WHo7oRDh+qIB00QwxXHGOucGLSaQh7n4kKJ7+bjP9stIOgb8N/Y2977zg0p1OpvuogCahYGAXKXtXQag61oquasblL5GQKMgZDZHFeVO8DJ+Nf+k2OdIRFIeDzYdTtoI2C76xlVmgDir+yaA89S01xGN94TtmxWVaiUM4zpWOvlcMkzb70SZbOb0yC7mVVsEKFpUqTIy19hYzT2MeuN3mrrXMT6IghL8eR2xFHQt+zV9+KK363iCQlHiiYuE9ZejRImlFJDzhrQpkN1NwcrQGsrA0w4HPLIiftFy3DxziR16kyeNyOiwTYFGNp6ahcbSEeJP1UjcO3/6FbOA8wfhh1wkX3bFd5isqNajhAd2hI9vflZRv6A2UsUYXoQaKniSxcWzJ+ROykUXsrOmjU/FHMBvk7hIpeaKpbNA5tCnnUE5znOuDeqEmdfUEdjkdnvatLVutb39cwBQMfz2wcr97OR9CHZFaghp1krNYHTIfjMeF4XJuzngXP+Fau7l0B8gNCWlo4AElWRZotL+R3hueUDSfUV2nsFmj+2ILB/7bqYJrlqvfMenhPzxmfw4GK13lQ9/4KlGjPFMh1lCX3dFhE8GuODXPS1ovHsiIKHN21I1fwMnBbvuHuBgQ4yLqSEFDkMalLJsK6HjOTlLRKq/6W7C5KFyWsjFvbyZyaM2ajsQ0BtspNKd4vF+SPXRvyUNpgdoPOlcDV9ilpvcw7tOfLLIXVcuXbedEA2aVstuYRU3IKaiuGUGuaPFhEORBgv8QAulXTusVY3cstDNi66uKXeLNzpdu6lBJwKUn8spMqivKAEfmwzsie2qUwc0G5JBhhPs4atV79qUN5Ruz71UaJgrWZ8XjgE4QT6vaCsLQpur0EWHae2j3808yGg88IeVcBqpky9UAeP1rmjLn2DyhzKJakRroI6DyLtgmAP6/vwf9CjN7RUIbiNlPjk4+UDSTiKzR0BZlW0qF7G/5eYSbyB3CDt7+XBoavRkSSDmDuXi40uLz+BjgE//x/hVeybLHdE6Bxw1Uu0m3aWi313EPSPkZqsK4YoB78TAD4haF+uX0mdIFTaS1HHEC9k7BWz1YW0LvDcpPCLTWYaKWJbO9kuVBRyDN/C/fRgBTABJPynMeNG+DC5s4/rf2j4gRE29oh1ruWslXyfxT9Z2IwSUKD6ikJm1XZwXtIteb5YJUP9MSWGRNcoifu8sjym6ZybZQGY8xjYASC/VUNgcg5yP9QnBdQ+E8hTXZFg64fVwPnoQyrulTePhBna+Y+KtKYIQPJAxK8R+Y0Wun8v/VAU0OQPLXV9LtEbfrb6AmmxvDtq+2cuAcrro7NyAOXS4GON6CE+ogvEdCOciYtC2IHvl8exEGTM6by5I1HjHDpO1kQUT7OknHeOvTz8itbiSo8hjPUK36wuRXqGZA7UtIZJhg8wPHa9fDWs/wjWFypvFAwnTkb2GhZ4E82P3BDY6r+82RiMFbiPXRhhTau4L/Kbg0pU6Gf/GtxOFpqFur2tLjPdictgDZdf7Vfq7D0lOfx2OpSacCduX6+uVfdXKbq+lDVZiUNZ1i4StyELd8dl90uwlqZxaSATltRv9g3Q9DFoEqOjCrINYh8mkBJBjWgvc1O0KHJMx3hajEeBUKwkQPYf6xUJu0PzZzgPwAd4/kQRkzgiYmbBH2dMCR9ctZryQcCeScyQI6K5InDA6cfaP/pYjZWpUOT/72KLn/bi5fSDFD8gFl8+jW7oLzmU/QPZyfzDZ5jezwnR46GtMb1p478mVdGvitW14u2pKAtHGaXBsPVy6srLkc45HRfQtVvOFQAlkm6LYVyn01J2QKK+1F6ZMm7/j/wzOtkDWXTN+idWvQMvxYCcBBFBD31JbvrjUQD7mUYd+5sEYvV4B1yo7uBslp4N1d1hCNBIkwQz4imJyo1wsoibQKWf6hgGk75Mvhg/Fb6c+GVlfgAwYAvrxCUud8UW5b8TDHQyNyngQIP78w+n/N9dwVjkeJli2DtJjSXImX0llCE+TQpwXXyNmKDcjnW0yFSrf9EYAwAMuqzVjnMLt0vP2axo7UMucJ3VLlcHNG43exT77nBGb/f7Bh7skuVLZxQAdi6ovarNa6cE5Ap5BTB4pnfROJ+CaugqkTZrY75tvnPSP1CguU5FDq5xAzguIyFc7u66IIYaDBfTDA9Ue/lK1yCYdKFL388jRpd7QTsmSz3Flt1ZhqcTFuuG185SKBas0qo61u4NpqUYfos9qgwGCIUQWUcWRk9L/IiLrLJ/VHRXhaMPTsfl9OzQekPNs1BOF/daCkpk+1gTW+fk76B7x+i5BUsSY3/CxifqCRuvSua5VDikGm77Qac+/FjNtF/9FX+XIKEPvNnMNyCG8K5XrZFKrZi5mAYnS6SjLfEl21380OEUB+1CGEJBVqIKUNjRH+X8L2xWPhf1vBQwBIhOOqKlsDOZg2GT920F4kxuPEzRQObdvQFxoakiU3v9bgGX0Eu+ehknsJOzlo0Djv+ADRRFC47/cWk017KZkNuBEuZeTOOiID4a1kJ/RDk813O6jXLEv9y+V/omSSsNCrlGKgwvC9JWYZRBmsLQSELPWl5X6O84rdL3aAfhUZyQYtbm2IZfiomngRWDylcTHV0gf2+YrtGQ6SJfqluOWTxWjo6cRZMHQ+zFWCD6W7+c8STyF+FX+E9jUweoe07i6PN/qZvsyOf0Ra7TU06hwrC9/iisbsLSYxPsYZa2mJLGP8Dl8tdoQd4QkDW9XkDvrugP27KdD7dbaBwIAaaWkpk9Fs3oG86UsQSjj0Q4w+ves354v7ivUPQ+nabQfvBNqzxDOSyqti1UV0U/KChvZp1heS7Sgr9JIz32sksiWXC4fvPs9Jk9FS5JjIZJOIz1ujaT/33wjTObhu+bXE1HRP/ORBePmcBa1fX2NmLiyHWbnXdro7f6oK3SX8J8QNwQSCO9hFL1YS+8GpZ8wxR1oLInkYVjZBszgOunG1D0qM0K6REqziouE0cJ+kVFlCtv11YAyhw9bDCFaGLKIX00U48JgMKkFvt2mleH12jLzIZty4wk9Mo5J9HCsUW8fIh48S8vt9Xb4EqL2ZtRZAw+yKTGaAm6PyFQVZyXaPAY6sUf17VQSmajgl6XlPwc52yO4FjxA868S293RQszv7cClfBn/O47PxDBXJSUyv6UBp60JYu+sbuNF7/Ux28/dbdSJreDIfiFWZkLqvDwIDFlccc5zTRZYGJCz3W2blH5ngoQVc/nLNFlP+bMbIRLM/oTt4/DkQYN67urwKAQzCS3UfIesrRGEGfiGK95yttCPo0dXqGH6doqkJnoorppE6KLKwmNUvH1MS61wODR9cAMWrmtuxEkZgn1N+3nP7QzAzKB7gcOaI5h7u7yGifraxU54snZyS8FEPi3Kmb6yID1F0AH6clpeFy1Pc+vhlEY/ArmgE54WdVlTUaFj67k1zk7MEOA+XMg7HtFiCLCmEh41iBNw5G3CMGmJIwrI7+6DgW1l7w9JXGrBDuYbkbDYTAN8vzJWxKrDLPLyTYK06zo6lmMLQNz1THO+0Btj/NRkdxLg58wtLoeZYNXqXTIY3dSB3TiOk8MH8/feX4A+WJc7Ei7ie0+iXiK/pmlMLSKapp/JvLGFzkpuFzfcjZoaCFoCfjs0vytaZGKUZu6kTbxOrP+7r/nxmFGyZvxTEOHX45hNeVPhmXQE3eNybGldlBGRSRsiTYjPOCcijhLMxSO5Xyu50fxD2mz/8IV+n27vRJTzofA7dQ7G6A1SeQPucJv51AOl6YwZ76U3VYo1cyEo7drJCkpe3KfJX6e6OBTo1HfPWVRvyXeIUbCuYKf4maDn4GvDi2tqlkJkSIIc2pKfHHjCoVYqiFpW+6+PH9yUxk1P76daohMWP0KENpcI1xFLogBNfgpwXQcU74WOPV7GwBBzYnEu1AL7EmnEd0sliguCiHu3Hfm45EqUNi7ZnC31PSECWBhTq9JjlWAq0koM82Ox52Thg+7zoo7x5wC5yKQusTHoQmM+eD0YIR43bNUK113SEyGM56Kcvl5z41qgF822+DEkqZWBdZNNeyZ9kaVmNPW3y67bC1MeijvjergoXQqAueBvKKJRGj1by+vMtz1QW4whQReX9pjBFs/w3vaOd4eidW6dbFxT/Rd134KS9sUGRW08HrLCWS+gxzeBbllsmY/3nwHs3yj7Hafm40zcmEmAtEeRNvnjmiLdaLwRkSowaP/t+96RxbMAQnweBpEwdrZBZZMh4Pkk96jQmCI4PASqV7xTwksU64gVX0B7Z3+gidRx0yHbCWlyFx4cW5RSHnd6ruillcXxMK8S8YbsLfV//eUJQYqT0nDUUNUBm9m45oDw7thu204AkZHipFGaP2ozXPCExzgr57vJM6S9ybRKR9v1VVmgG8DknSAxQPQj/bqTysKtcuQZe/b9DKjUEGQ6ysMulZoXNICMKIQX2G42T/dRAfKUBOnw2uyxx5Rra7pR2NF7B68J31ByMsBSgC7CHsE4nUS1/SK0kLPlxLfLGRmlV8obUboyRWjUb6T2F4Cqbb8amaADdxkjiR69n7OmUlxQjpIlFIY1X94+WQeWcLuoDzGGD7AcJkcx0LWR1R6Q5W9Eg+raZPakg1k5z1nr0E+nRzPCnL/HV9LAizN2yTk2EvxA2Re0/G2px45Dix1yUJWU/98QwJBQ1kidjE6B5GqOhBGTPphvPQS0g8eUWDMhEu49LWC+2oa3ElNZiyUXc8QPD340znATJM0QNH29CgJ4vypq8y+FWa/oOYklodKI2WnK08BUCgrCFeyw5s6SnY4FOGdIUxQ30ODnCQm1sQB9aovsH2Fyrxpa/FgYpcxxJALOIm/MthFlNIYSEBJh98u+zoHhrKX1IIGUQYQ0ORwxcjVTQQcnTBt2AxCdiIx5V/fylUC5S6++mYLDhjqGFzzltSCIbx9/W6k3hJzEfpUlrVRw2pvXThZ/dwD+l4ESdFsc1juArmMIUSO3dIF3JQPrEi1dRRhX8V/vmGyHK4oHV3DUFykVQPZkAMYovjAeoFW0ixCKideSTIBNVR8xADOi0Blry9QIVGAeqFmA3r4k36GDtEGHO7Bf/2yZ2pU0ZjvphR8xqXYAk8Mu136CNzExGUmcBp9/10gY4mwfkMx5c2biePPh7IApPiKzlQL3lJHXoyHZp58QEuqPowhZ4eHTMGtVGOGPyKOKoMuxFDJHyRgr9gxKwa0zJW2N6C7o/qwOSFaFae3+GfvfOYBCJBnqkpPK+/DbJSekgkvWvGVNBbXWUVynivd9CYWg5GtSGm/hGRSniQqn9WM320/rBpGGqfh0mBGlncn7GKD/w0/SCDjFRq8orodPYh7qyPL/o7kFh7jeqFJu+Qg1NOrlIdl7HdgsT73CeCx6boxcV7PTXZaydNBFwou6OGYiuAOPGpGGUi+J2avg46HSVoYrOJN6utNVPiyLc0MOMqaJrFptnfjIm4RxtAjhYBQMgi6U2YAqQqXa9Yg3vi8ii5OEtK/37aGYhmdtk/icsHcKLwF0RmEwKgwb6W5qM6NlijIPZakD5g5thf4ZCj0kkjYZCI1/C1SYN6pHFI7XcUnVWKgkzmSbzhpkRP27TqHuQHFuz/ZbPrG40x3rga2btWUzFFyBh2sZ+7Wm835oB53ZF2r4Jg39LTCYBXsvthIeIRbCPtsTfze1TP+d4CwEsXqZ6ppDzol/TEnVsU5BNakFo//8/1iP7Vsq6piNQtqn/xE7Fxa3T73S3WEUHc4LJdm11JTZqTfdkxvNgPWubQ+n4Z3Uou8KKEGqco2S/KBoL2yFfWqqs5ccuX4+G2u+syzVAfqeqOOHSK+Iw4Dtt/fj/QZO7hU086SqFQFCjLt7Hg6gEWS8P4QG+fuka/Kg/oGHBewxD1pHxOQqd91I4Sk0bfVHrD4oKAJdvr0qzYP/jd7y2pzQX33ARw8YZXwRAPY2Bv2HfuJMC2+gpf3tcQxnYf0IWv2we+F7p4ee8lapvUe82lgvE/V1PzF05owgZv2XlDIoGtCvKXEagTU2mSoMmthrIJiir8bup6GwamVOcqI00Ee28D9DrJ964oe6+F8nwZZqpFxqshWHo276xBkKlxhTws0yzaLf/jeIrcabE4X+iAinQy/EvH1sFfcX1WduLHhtGHdMcMPPbkWNmvkQQJO659QrMvnJyU/0YQk6WORmXOc/uLF2hZJl/0R6YaE4NTbiBh9LrcH1xCS/HsKNF4YXkeD7Qdy2sFMxyeivCOnp6GHEW4e8BaiQ+sAYRrEr0XsWB6SqX1/DT0y75KNx++v1tAUPA5k4KBHMZ60IheJ3UpAiQU//Xh01OlzG1Q5ejxtVI6Pkyd2TlZCNewMe17JmPj8gDNUNZebsUhIlvFogPi0eEGzmH0sfjLEhfYLy1/iHVLS2a1rlOrIBpKC6NcJUbA7Z1/vLDnJpjPyrXWyIkxOaOfzOWV2fgEpUa88BhNBotB1mew5PFRZhsayGat837RdQ7Vt0ILuICL9BtB/6JUo5f+/lWl0PAy8noGrPUBSOdb99agqQKBSHZYvA7rSHhzDLJqEstsN7f3EwhmgoqMVKEe/OiXnDjfmWsMw3Ga1EP3WG/tnao5lWOXB7k5dP3DKEraIm2cY4pF9/JArL9oT9yM+8Rsf/Sg+dX0nzhsPiNSnWWzerNvxdyEc3qjmNB/Y5X8xh/RBuT75E9vAoPkWxW6O/PbGM17kEgXAvxIhxsUe1sp0Yd8kOECrRz/WqAj9WwjtOqSh7c7IJG4NwJfk/g9WZJMA9qYIEk4XgyurswyXt3kcc9XEbFTZg19VjrFnfT3z1VxJb7Phg54d1EDb33hgHugt9+KRX76k1leRgIbgXxarYUCy9Nl3/I2m776J1izucXUCvkdpNDx6yP6twaIPNQj4jWnsTRveSiDTOOjINAfsfpdRpse/E6SdZh6ELp4YnaNFgm8Yn9PaDTWOaD9bgJpYoXB9HI7n2qTMZg2GZkrEOcfz3d4tA/6ubt0rS0b2docfGn6k2akxV89VbabU0LkakCXEyskGf/e9jI9PvzodoZuRpWpiYG1QgDSZVnMMRgkehCpjlt11lm9df5TE3wDZokJN9J7h4tczQns1YeP38n00WhDcFUwYRxWTFPi7CFUosDKHDtFyDDrGzcDj/B5Eixxp+OIrNU+T6GPI6EwnvzAyg7M40
aaToken: {"uniqueValidationId":"c7566eee-84f5-4e9a-8178-1bd9de6a1ff6"}
Most of this extra data is very easy to get as appActionToken, appAction, subPageType, openid.return_to, ape, prevRID and workflowState, are all sent in the initial HTML response by the Amazon server and stored in hidden <input> fields.
However, the metadata1 and aaToken values are actually generated on the client side so they aren't available in the initial HTML response.
Secondly, when you go through Step 2 of the login process (enter password), you will see even more data is added to the login payload.
appActionToken: o35S9FuQrkaFvid5z3ZU9fGB1loj3D
appAction: SIGNIN_PWD_COLLECT
metadata1: ECdITeCs:py9Beb4zBnanaB40FHo1SXuwSkRkdQFh4boLE8kOJxSPSZPKULOp/9I2LsLP9ORBVFWnbjWnmecMO/hDCcTk+f0rE722qPSTwcQyh8ROGslw1CidnTRDpr1yIxa6mSVfOqEmpHVt+ElDHxdxs8KIugxzbGG/M3TqejhT3TaD+xut+uCyFphaOTX2WbBB49+K/H+tB6AyyPIcjfo6+AIvKbuw+E+OuyWKpxgkv+/ocbFOLQkfJNzKP8RUUEGfexwVVKe9O4nzJu70JZIiK24W+5n46hIhPGvHyYp0El8LAvjlRp8TcE3/VsdxIyyKrVmyiJbkfU1mYIyy2Ru4TcgiP+jUILdQUnIRo0XubtFMMhxj73nK5DQUSR7a5u8dHRjENQl4+0+CSFpqHjP1iOyYMZnan/KEgccuCmuc6uyqW7uqzGxPnqV/f/kLJgsRfWjv2CXmP9xpTRDOTmk7tsV1bkpjkMz9d6Awen4/UHDxSsUa9TfuSqqmmFOmAIBALduRXxLSoK8u7XEMAxvHE8wIiXrhN64AeoqQLg4RndO3ZMseED/grOwylHMAqRsPzIbIjrj4F5zgPzITsmfr81uWJTAj7qGANVylWFzFd8hnBdmGhKY2MV/o2RLtC40l69/DRqkWSYrPjMp4GCd8vwQg6xzrY/SnZVOGrwfJvVh3Zxg4UaOIScVMyEzkWyJ1GeT7o9XH+zswVM31rkdaiT1RxFIe3y2uN+tb25FNKGPHijv5v4TqEkbkIwmDv1c/EZKgfpLddXJPa3HkYJtVDZSFYhDDVVfEiwEno33Md8PKKtjFw2328hD9pYKXCxKlUBHNtNGF9drdmkNxl9AZAS1u8xp/nbixk1NEzkHEokjIsIQFn4gZbJU77gShbJQFCmLpiYMbP5eQMsPJ7NX6UIZr8mQ3mQJQeJDEV3KIvHjo83adD1yNbzQ4VnAKTu75vV1ie/2oFcJ9R7h6eYu+gMnsy+jhO9FDh45qfi27CiQKJzpJ1pUzhg0Kgo7FuNtsHRx+enJVcF062yg7lx2LtuGmWylh4d2xx3+R6i/LR83xJbMGfsuw4VwVBQdojkamx+ljptUnjCWyFrtw9A8WLZDA8M0uu1Vjnu4yKjzl1lZAmLPneRNoP8xLrV+W4CHDDQ4W9fe+Gqwfwvof0OUMgvqZQ9sb08j5mU3UvmIDx72gH3Q1VNBsjQoMrvhodSCdXXYzqSr/9yNg3mefiP6d48Ti3hfTs2sg5S++GrLv2UnfV3shBLVznU3foCkycw4RS1xZ6VrIyXqa8KG9Tg7jcoS/DTxHk4IUhVpR0aEPwZUbPX84R8Hp4zzDhk3Tq15CfumU4/96PzOFnaMHBtBYkb6KWWR/u5GDHrFlZSRg43AMaqMNFqJ8LhjKayOT97gelUbQiNo9ze0XTrTmnA64y3LosxKV4eWt3ngn4HwLdJiEou7aXKz7SijfaxGe2MQ4UDykOtEdauag5i3Ws0eeARHCqYOIrh1xyl6cPncj0hNdq4C8Awgv2c8mwGECrMpR4jL7Z4NSIGzi8pk6ixFsLF07FHwcuxeAlt0zC7K14HVEOmBD60wW0nVzyUop67CvDYbFzcXTvM5gizHHdFFgENFuMDmKkUbh+5QUgs4KlEW9NCSNmho8ZML5DtmFitcce9kV4Itk/NMKL2ITwZs3FkpRq3+c5eeUcdUjjdv9VIIiZVHl3FtKcs+vbe4RS3vbC2ayti6dQgSALxW9yIfYcpBaug+0A2s/4QMTYeKztBjx/JudUUFvPYDyOP9kgwl/Eqt6R5SIkTo4bgl6z+Kx6JAADQKomZWfI3GJzuQmA1ozSF2kjqIEat8IkpHXj4sZUYdG+NpXQIkn09Gal3XbAoUGdZf3Xti5a2iQ51BLTAxMiTtFtl1YOOVIJSf60pqykatzfBOqGFP7b8plrH4OrBDEvJDAwrlNuoixrUkpILuYMyjxae7HLwR1cPz0wUguMvvik3fETkL0/HpNvEJUeadcdxYAaNRseaffeLvIdhwYzqnTYMGN55J6IVD2LztO5njH1jJ7za34/eTK8hdmdnqTUAF0lifne7GnExBFuiIEN3PknTfI/6OFy/2ntiC7pqmw1gFlxqGnpoRDagJDVT6E7dYcSf6DQArTVGTIFyRa/RT12SvDDAffIMp2dvXDPOwdKaWKVvj7COCp5SlyoZYxClF1EP8pMzNYWZiMV9KSI/FhTkArRzOTg1E1fA83uLGrogAIsGvzecEJFT4B8qhAaSYDHWJskANeXhwk3Y45uZ4xMztQjKIXYr4CJBGudJ7M7TUcjj2XiAC+ge24Qo7iHmKsGk/XPQ7JYzhQgbOF5nr+hHE3C4dZzbVlJw77sEbmq9ejRhJBPLXlwDQcjLJXNKMGIKHmbgS+RAaOc8kIDGJ+NkHQCNauNVxKVmX/ooxEggKvm7rLa1sNaUrUMeZMI/SNUp6oa4bieOE3cfDORPswGDkk3tTDbqQ11lGnwpG85Mvry5VfAKgpM9ENRa22XqmJcrpOebwvFPt+nzpfAwvVLrAuJKMN6GoQzKvB8fkRVM8bWb9RsSZxNT0QxCuybkKAmh9+kot4qO+p17BUabzgY49SwqrGVtkHSlGDpivGyeCtjeO5/Mle0jfLy7rKr/o+V2OHtYV9+zr/a0303+v3Zwp4uyISLFCRz48oejpi4CSmldcvYE/1de5W9j+fselNn7PendseDvbYQ/CLeIvvg9+Ip8CPdGmDJ3pwSs3cTvxIxkXTeLo/o+yrjjHoQkFp7hAhglXMEt3pNH4el+QaLc/imm0NspweJ0qASHYMNoLPBolxeeUqPGnBdHwI6dcKxO8DFmK9vFFqiiuxyOuqNOzDsaJ2WdGUcaoM03ZVOs4ea4kBtta73BJf2DJmg8GmnSikIzc7K9WmJlNhBmdWB348cs7hbx8Ti1urzMLz8nnYfkLjmGi8+XYRuxUAnIK0yArZ9bkY6p2rXzjpn4DRwVn43B+6zPBOLClTYmjDBKBVX85YjnjCkyfJOE3VqlTtfDVn4Yb8X02dmkdrhQa5UD+ckTiHA20SOg7jX7YOs7yZX3l0+rg+ea046BGAxdMSmeJdFRYDwiSyD1u/+zTL0SSkmM1+/nAg/W2aAnl6ZOhad1aSegRDApUl7Sc3RdbQ8F6O+FI1oDpqblM7QsKwY9qX6sKYGzsdQWcn0lXVF5WyvbKeDzFG9+hydJ76qyB0nSINS8bO/5kgJPkxH4eAFpY0br6s4HJOphFlFptvizACmeZE4PMnRllVjQhU4SLjxg0dSENNgpU2ItXQme245lY33amvf6vkoq5qGVL5c1bnrhh+e8UBy6/g9+E3gP6Lon4AVrSTsDDmMjIBSdnnTFRb9wDKV5sHU40VWFeO4rtBB1BXyBj1tgfZ3zRSfzJi5eQvG1kamGM1Qq5rTngzDDRgPDQjsu7hasumcdUa9SNcHK5SPVUy/Yhy8zJtGml+aBZLI659NPAAPulTo864u1WN3BFvR+DF3dRRPyxqyW+8K8/lQd5WwEyjANA5/rLhY2G3yvC0OjlrnCx+yxg1lNKVCmj5pKy3yQJkgHOk9VtMEbSWaHgcl22PxNFQ6mLZWXNf+ytIC8FR3WWEHesBMxsm+E5EHTFZ0OVRSMcQLCRJ+f5zB/rFuolrO4DC394i/Djs3SGxQ0M8m4OzFBVlZx+fI0ldh67qOeGHi0qoxgJjaiUrwAdhrF+EjQGKh4/+JWket1W3r2GKfkOHAFoYvc4PQfBUeqzvogf3huoA+LI32/7Ub9zksmNVgOOs7kmYxtPBoct6o/tsMpWHr/3mgy91ccQdUcw9SypWulK4y3TXhRL+fq4Belfbw+4lVqFDgKGPsGzzM/lYJ4tC3K/DZwGS5htJbpC7Py+LtZoilRmDci2LvJFU04t7D7WNJtK0Lt25bIvtNdiqysqkidGSQtr8bkqoKjobF/q8Ze+yevsfB7aGQd9yo0t0uNiVner1hT5T7TU36qE76u9klPnx0IGGBJE/f3nF8nD5JQp4XDsjtAIhOPxra4ISV/SZ0CnmBvJkcj2yGTOBmLDnVO+JQw0PEXQQ4qUXURl98fm5tYCBzQZJT2WMS2Od/qMSN5tZVQGTiqLxoOerj0QHkEXdw9/Z3oxgd/AxY6YpWBFuw0qhgUgcWxt/ipJYtlNF7EZJ2NKzowlUwJfguW8fqJlnL/l2i5hxeKif/jjpYzH5JKsoTPCM0k3ctc/618oNvhpnqhuGymEC4nlSeiwH9dsmP3y8r6W/x4px0oiAn/Ed2LPM9iFSIMVkQDZQjQTRQUmmA1lF+Sp/l8yvf7wfLcYcui/aKYaojErRAQBysO7AygeEJohcBRyXp3BONoqiV4v4anh1pXdk9BZAPtiJC5mBXSzDGj57pB14G/B7vXQJwW9O8lRpaH4zH76SkjalHsZKBQYYr1fHZUrgD30gbQ2XUI4U0G0YKIAMK0SCT/6uBIhN778UlDG1z3jr/+nrY7/zYEMlsqfeU3Uhoq8eoL5Z2BWMjv2bLHoBTf7PbDnR5bvexw8lPNC/JOi4C88EZVqAoOI2SoS8boKwcwmjenUFLPgxGvB1GnqYlvwKX4auyU4owtttrc77a9MSF4tIusPkChLt4SXPk4X1e0+TgYZpyBdRuR/wvV5H5hdme1AeK9mS8xGGXmtPGgvcZC4wWwodXNAGl+8wr/d8jP2Gbdki0us/ylJhC32TG6XF31Ck2mVzF9k5u/9r9qQiiFS7N6wNz4q7OEOP+/IKaM/4aNWbcKcVlan8By5r/kbbAisc+Ag9tBIa9VgNtOiOCt6iH7XFpn7Krc6Ly+A822Fe7gpG6NIKF7Dkjh/6M10VBeJ1uyueS67Sc2l1n6d2LpwQLAM+BDJZ7IK5uyMVk/qXiyGtgBBrXx/6hSmZNptxxROo78y7Gy2XZjmHF9dvd+K4mBoYEa3QFBzTxx1O38ZWUEtSdMw4byUjz+3gA/EilWLJw8bqJcn+GLXk4p5e+8RYtzhUDRBUB2TJpdZmszLrGRDAlHdzCf+GicrsB6323lhvyrEtZ7j7YRu5IgFGYg1+FdMUqDQEeiC7BkvjHpQEtlZOzGc7/B9xwyBalMHoDspeaDoF42bDMhZc5BUhtek8+oWhkTYBLQE7t4FlszUp7R3AAwe4ELSZ4Cl5hdRzZqM8jyTY6OoNuyD+SPZSGXkWh82SazAYm6yL0u8+pXR/yXeP9fChzSXvgp9abh4FunGmBm4WlAKQCi2lbUlOam+KrG/gm/9evNV4YRWsVODT7MNLMz2AIHSnKj7d5yRntkb4omlbwwjTPz+MsH2Tf+VkgAoe9Q2Vg9yBLRssfzViI+H91Y9HIBsXN8w8B+p0EFdFFK2JtJ71KZg/mb0LdSVaiozNLFavKphTQ1CKFLLg0BW16dKnbx6KxE1hiwm4cboEA8iWsq5biMBRZpayNkfktxwBdTOQDCLyaKgY6bDuCYNWvktHK25B2i8vrtHV57Bei6p2aXRv5WNpyfLAgQL5Xujy+aHD+yFE9KHJRj0+IuZdNrveqH5/KAEglxY+oy54vvC36C8YAsjteMdZuqGJkY45AxDrCxl5i559dUNw9cbcXGIZAaTn4ku2HawOlCrtnpz9oCYIVpwD5SZvupDZP5LqE8IC3llD/oVOVW/zT6aMM4qTg3y+XV1tdSyxq1/8mMQ9wbul966TDl+KmC/1jpAJQisRZmmtqI3fbue87RBOywMqDGLYjpO/WWj5ijATkXGIp6v52yD2pPHLZdZfZGaiUSMh6rqFmUNAAd/B/VUDNMa2ENNhECAoc1EWcz8+7GoBbSqTf3lW8ABzDL1t93e6Uv1C59bwsskh/lkfNWOj5emTOTiZJ2o48gurKP4Up3i88HXEAQbvrdUga55wWF3IkwwXh3IF+H9XWmXU3WO7xl2LQGwe+C7/bOkZY4W6PC9W0cNs2g8khKHNJLOddDTP5T8mHLUm1OFjU67pYXIecNDjm/b+6c3qbmbiz9E0IifK6K4Fco0Zh6g5pq5/sjXAJfpg8n9Ri0XyaFQF5qi7l491rIBfY9Wn1zentk/W+mY6aX/HW+eqrxCN2qRut34CCMXJb6L1P2I0N08aiaTx9pLpgrb/oaVYtbc/V/c9od4/oTrA4sPkchZsNIgWI+FiKIs2xKvznxhO80x3O7S3Mqsr7MnDbFUXSbri8KB1opkNgKsAs5NU7BmdhqTjY7vtwxDNCSKFa2WUvPIf0DCCMpkFChq7T9A+EVkE9tWQ8WWDB6OPn2C1kIX7OnhQUxGK1HnX1OR8AUNLVJJB0BkcnlwtskMC/31pWxZqAKQSKEOFBvU2GHYuLjonXlStAgJdKGW8MOHwpe2+cFuNSCdqrSQ072FGSa824H/qydW6t4zW/+Yd3H9G19H8g5dK3XimHN/mviWnL2UBn5RubtMGp5HDg1pvN1sGsTQMMhWyfrdNlqbYIBOp27SqfXwzaKU4awKNpUJ+RSaGObsdFF8STmR7SSnVCg/WIDWnDFVZD2SaqEyyH55J6TBCabG3mXnJWR6JbUIQ2Ig2X5Q6HN8kjSsLLMejHy1jRaOB0fq9bKqF8CwUnSR2RqIMO7NHfurUwMTFUy9zFmrYPKpXMS1JBpbCDku7enhshdSdK6yIPcCJMTOiq2HU5VBv3TX6yaUC7VPRVArBFm8axh42MErdi+B9dXDRZCHAkr4ChK4yXICIv2fjotJk9eNjtRNwiJsNvBtlYTJHnOch8CzpjeXotW+tIMk1q4tLEnc6hNe6MrtPP1NiCHM1D6muM6Q56FaDqR7jsI8NQNz8JbuX4fR6YVwYSrxUEScFApTrekK28O5nYIewBV4Sm/hGFAufSU584l1ZnnM2TykGuQurMrjysi/SGDdKXBFAsYt+DcYz+7rIXOT9cF/Trsegcgvad2mHv2Jfrf6yyIgZ+Ni6zIXhpt/EGWekMy1feO2IuD3Aniqt9X9rrdvvHpNQWaQ2Y68hhYCD/P1VijeEJg8+UHHpgLh+RssrQl19LMQMy8yDn8ISVygd3JYeB9LBWGmFVB3SZCxsnEGx7ArmLQc3VFVN+BZVk0FkVllSadZzVPfKONKmr5totHjDSiLq5+oiOi0yYLMlR+AL98QXQa9uTp5ZAD9d0NWaRzO6oKAbBfBuR4Ya3qcKyYoMuAH9zEIQpTKkPBzOG+fc+XfKx3YBga9/qNonTYX/RHaMflWduaMQtBr2nrX2j6pIZdEWXG4RyO9np11A+Ih7ob3qzq0zb4SAjV7qvwY8q8SYO6BaCudkkAOWqqD4OSZkloEgg9Idh/4FYLtdxF2paI3BgwcSt+nsqEdudb+W9HiZSWQzbzeZRlPxtqta000hwz1c0DymZUOCNxooew6vQW2+Tzhq4pknayrd6esVov+NjDLQSK9uYx6T1eNDBaeW4dRyWCc7Md/N+0GkyDiueSAhjbglF6L9JaVe2z2mWjPVjkqYlBmcZ0cYCA5ujuMuAu7fvhHakiDdUFS0ZnsQD6LQqtyykeQhqiWiKPWKgNi3equGuHXydTiwH+DeHc0Qgu0VJ1wZH+DaWp80j/xi6ecYTqF7FVAyQ+oYQd9ljObnrJdzXwa/m5fi0jtvWz2HKgrNVjjE8ypmXoqtwOV//s1DKG55oOwQG4w4JDn9csdyTIeyp+F2gdgfdRmE6dpkjtXyuqv3bNS5tPQgg8eUM74z3e8Um2aHIDeXYrCPxqA7JsY37tengc/mq7MUIGwow++frjjpJWafwR4gh7VfMG+xxfMf0C/3M83Dy/q1/u9Xy9BUmihXPQEI1kc886X1Scr4/gqMgmDNgA1sLFD7uS2pcriGrKFJekL+ZNyY6IViCgATO+Y1dIHH3LBldFRcfisDnMgcJas2witpZqmFWF18W2Uhd3D84u9iNRUbJqlTAG3hrBBOO7MymJvKn8OaOwbfndkg8QAf62IjebppHzXIe2ebH2jGDppFJ3NEq5Lpvfo/TYkTmebl99storh1iuCFs4LjCia0TPVBE1vGuhNKfSSq+seejJhfr3Xkohih/muldHfWZnplISmB2A94zHWjcNnDvVpqvLKO1N0EQhNPbiVkJjFCps9xpDMeI384qqMBG6//4q8urS+5+rKTaM+wCcj3Qz7t+H+Mxj4LNH4b5CaXlt/R8/yjXea7tyDq+vc2eF83B3QKLPWgh/UfK3zjhRQby/D47sUyi/qLl4GYIFWmKOoBpvfUaU3j3Qx/3rU1faKX6BtAQuO+7rmc5WxCzWhvz1VEtvVpaxU/BG9053U1zbWlxWbc37fzDNe8DOPOBhopZZfm4t5VCHUIk3Azq6jOcHsyBU3tYwoQn4NYHaoLIqqxgSkRhTn+/js739K5GIkCk/r23FKvza9DsACOIqTabEE1rFqdFtLj++PhtgdHwNJSLpoeQLzTSFlKlJVJWWt1LRXxXV1XWqKUGvKsSrch42QwrQLXviZRqfI4gFAmrEZdayaydsOdo9NofHgJZ5QBtHqc3g==
openid.return_to: ape:aHR0cHM6Ly93d3cuYW1hem9uLmNvbS9ncC95b3Vyc3RvcmUvaG9tZT9wYXRoPSUyRmdwJTJGeW91cnN0b3JlJTJGaG9tZSZzaWduSW49MSZ1c2VSZWRpcmVjdE9uU3VjY2Vzcz0xJmFjdGlvbj1zaWduLW91dCZyZWZfPW5hdl9BY2NvdW50Rmx5b3V0X3NpZ25vdXQ=
prevRID: ape:NzFGSFIzV0hCRVlXQjVRSjdUMjg=
workflowState: eyJ6aXAiOiJERUYiLCJlbmMiOiJBMjU2R0NNIiwiYWxnIjoiQTI1NktXIn0.LxE2vt3LKyJqEu8OaauC-IRqGSzP-wcscPfxIjMZwI_J6KhdZmfkbg.98wjDMZi9osGneKA.ETZvxBiNMDtF23jyrYgNf9e0p_photgQVYELkLZQx19dqSSyit94U0S1IJH-pvEKofUbcbBtySKSVjD2Y2XxcGr87BvIMTJxW-YPxaLVGzyoipuuyZT76sgI_zH4ji8c94ACO6IWyKTzfAz9uXaVNJkj_athErc3fbg6pejO0GeoHYE0BTT6AjVHvu4Xr1YeG9BE2Sn5tlebu4hIgaNhxYZB5bnajgUcD_NvGuQwi9bTrGzcWCkDaOoDvihZi4hqeEATDYBfOw9h6IFUMlGEE9FG4E6VpjboTKwE-qkErtjjxUBnifHeDi6H8khA09lpYH_i1CApbL2NyYMCotPRW5hOn24s8PW-9q1b_fQzF57TtDvPn2CyvAvfRWnn57-X69CYJaDPgJ1ccqrDDS0IDkphSqrjJeTp1Sb7-p6AN3J3rDFf-wwBbgARfsvfAZDTXcBOCt2ce6CDN3R07GBShKS627Ex-2D2_B8.7ZnRgS-szSdtj6FIS6W5bg
email: myemail@gmail.com
email: myemail@gmail.com
encryptedPwd: AYAAFK1kFz5NS47OZNL1Eeq7gM8AAAABAAZzaTptZDUAIDU2ZDE0ZWRjZThlMmNiNmM2ODQyYzU5ZGRhZWU0MjZlAQBibYPoa9X8jyg+3loR7ZK2pajeyQ5rlzCRYU9Wg1SjDZ3DPjsEhhcl8Z7AeWP/Q1xUN3yl8hvNIuMnXotq4vxaT4QgkC7Z2DWCL+4Nb3WBR8WgMXVNgYoQwRjl3WQPnN8InQkB2Dd18IAnS0cy0UAtujP5kpy9gllCzPKl8E0rUAhTB8kndCzxs+dPfHTagjJu9UBd/w7ZZ+MWIUF9kP3nZrn2UmY1F6Cj0MCOnGTUQk9IaLHW4V+lZ5M5tr7zyTqqvjz/kgdms4vPMLC5QpPSQVLNCb/J3kJoIeXChIVBRGoIIqVG2CP3fiBxpJwMizapojR+5ANuzFR8yEqnGeEwAgAAAAAMAAAACQAAAAAAAAAAAAAAAIJPPTOSc5LmyccqNTzUwPT/////AAAAAQAAAAAAAAAAAAAAAQAAAAhZ5OIjCsVccq9xgMqPL+zUCK2gHlT+WAE=
encryptedPasswordExpected:
aaToken: {"uniqueValidationId":"ccfd1cad-66da-4195-9f9e-41c6ef794d67"}
Here a lot of things have changed:
- The
prevRIDandworkflowStatehave recieved new values from the server - The
metadata1andaaTokenvalues have been generated on the client side again - The password is encrypted in the client and stored in
encryptedPwd.
Because Amazon is generating the metadata1, aaToken and encryptedPwd on the client side which our normal Scrapy requests can't replicate, we are faced with two options. Either:
- Option 1: Reverse engineer the JS code Amazon is using to generate the
metadata1,aaTokenandencryptedPwdvalues on the client side, or, - Option 2: Use a headless browser to login, and leave it generate the
metadata1,aaTokenandencryptedPwdvalues for us. Then extract the session cookies and use them with our normal Scrapy requests.
Option 1 could be very time consuming to implement and unreliable over the longterm, so the best and easiest option is to go with Option 2. Use a headless browser for the login process and then continue with normal Scrapy requests after being logged in.
You could use any headless browser Scrapy integration for this, however, for this example I'm going to use Scrapy Splash as it integrates well with Scrapy.
I'm not going to explain too much how Scrapy Splash works, but if you are new to Splash then check out our Scrapy Splash guide here if you want to learn how to setup and use Splash.
In this script we will use our Scrapy Splash headless browser to:
- Go to Amazon's login page
- Enter our email address, and click Continue
- Enter our password, and click Login
- Once logged in, extract the session cookies from Scrapy Splash
- Start scraping the pages we want to scrape, by making normal Scrapy requests and adding the session cookies to each request.
import scrapy
from scrapy_splash import SplashRequest
lua_script = """
function main(splash, args)
splash:init_cookies(splash.args.cookies)
assert(splash:go(args.url))
assert(splash:wait(1))
splash:set_viewport_full()
local email_input = splash:select('input[name=email]')
email_input:send_text("EMAIL@GMAIL.COM")
assert(splash:wait(1))
local email_submit = splash:select('input[id=continue]')
email_submit:click()
assert(splash:wait(3))
local password_input = splash:select('input[name=password]')
password_input:send_text("PASSWORD")
assert(splash:wait(1))
local password_submit = splash:select('input[id=signInSubmit]')
password_submit:click()
assert(splash:wait(3))
return {
html=splash:html(),
url = splash:url(),
cookies = splash:get_cookies(),
}
end
"""
class AmazonLoginSpider(scrapy.Spider):
name = "amazon_login"
def start_requests(self):
signin_url = 'https://www.amazon.com/ap/signin?openid.pape.max_auth_age=0&openid.return_to=https%3A%2F%2Fwww.amazon.com%2F%3Fref_%3Dnav_custrec_signin&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.assoc_handle=usflex&openid.mode=checkid_setup&openid.claimed_id=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0&'
yield SplashRequest(
url=signin_url,
callback=self.start_scrapping,
endpoint='execute',
args={
'width': 1000,
'lua_source': lua_script,
'ua': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36"
},
)
def start_scrapping(self,response):
cookies_dict = {cookie['name']: cookie['value'] for cookie in response.data['cookies']}
url_list = ['https://www.amazon.com/']
for url in url_list:
yield scrapy.Request(url=url, cookies=cookies_dict, callback=self.parse)
def parse(self, response):
with open('response.html', 'wb') as f:
f.write(response.body)
To use this code, we also need to update our Scrapy projects settings.py file to activate Scrapy Splash.
# settings.py
# Splash Server Endpoint
SPLASH_URL = 'http://localhost:8050'
# Enable Splash downloader middleware and change HttpCompressionMiddleware priority
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# Enable Splash Deduplicate Args Filter
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# Define the Splash DupeFilter
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
Using this headless browser method we can bypass the complexities of trying to reverse engineer a websites login process and just let the headless browser do the hard work.
Not Getting Blocked After Logging In
So we've covered how to actually login into a website and scrape data behind the login. However, that isn't the end of the problem.
When scraping whilst logged into a website, it is much easier for the website to identify you as a scraper as every request you make can be pinned back to your account.
Not only is it easier for the website to detect you as a scraper, the consequences of getting caught are a lot higher too as the website might have personal information about you (name, email, credit card info, etc.) and you have explicitedly agreed to their terms & conditions. More on this later.
As a result, you should always take extra steps to ensure your scrapers don't get detected when scraping whilst logged in.
Here is a list of steps you should consider taking:
- Use Multiple Accounts
- Static IP Addresses
- Browser Profiles & User-Agents
- Use A Single Thread
- Delays Between Requests
- Realistic Request Patterns
Depending on the sophistication of a websites anti-bot countermeasures, all of these mightn't be necessary. However, in all cases they will reduce your chances of getting blocked.
Use Multiple Accounts
This isn't always possible (if you need paid accounts or KYC for each account), however, if it is possible you should use multiple different accounts when scraping behind a login.
If you can spread your scraping across tens or hundreds of accounts then it is much easier for you to scrape undetected as you can ensure you never send a unrealistic number of requests through a single account.
Static IP Addresses
You should use the same static IP address for each account you use to scrape a website behind the login.
If your IP address changes with each request, or everytime you login you use a different IP address then it can make it easier for the website to see that you are a scraper. Especially, if you use a IP address in a different location with every request.
Also, to increase security, a lot of websites are now requiring you to validate your identify with a text message, email, or authenticator app everytime they detect you logging in using a new IP address.
As a result, if you aren't using a static IP address with each account then you will have to build a entire system to validate these security prompts everytime you login which just adds unnecessary complexity to your scraping.
Residential IPs are better than datacenter IPs, but depending on the website a static datacenter proxy might work just fine.
Browser Profiles & User-Agents
By default, Scrapy sends the following user-agent with every request:
user-agent: Scrapy/VERSION (+https://scrapy.org)
This user-agent clearly identifies your scraper as bot, so it is highly likely to get blocked.
As a result, you should make sure that you are using realistic user-agents (better yet full browser profiles) when sending your requests, and that the user-agent should remain constant for the entirety of the scrape once logged in.
For more information about setting fake user-agents in Scrapy then check out our user-agent guide here.
If you should like to get an up to date user-agent or browser profile then check out our free Fake Headers API.
Use A Single Thread
A real user is highly unlikely to be making more than 1 page request at a time to a websites servers.
So to decrease the chances of your scrapers being detected you should set your CONCURRENT_REQUESTS to 1 in your settings.py file or in the scraper itself.
## settings.py
CONCURRENT_REQUESTS = 1
Delays Between Requests
When a human browses a website, they take their time and can spend anywhere from 1 to 120 seconds on each page. However, if your scraper sends requests one after another with no delay between requests then this is a clear sign that you are in fact a scraper.
Therefore, you should use Scrapy's DOWNLOAD_DELAY. In your settings.py file or in the scraper itself you should set your DOWNLOAD_DELAY to at least 10 which will use a random delay of between 5 and 15 seconds with each request.
## settings.py
DOWNLOAD_DELAY = 10
For more info, on DOWNLOAD_DELAYS you can check out our guide here.
Realistic Request Patterns
Another way that your scraper could be detected is if you are requests URLs in a order/pattern that a normal user would never do.
For example, a normal user once logged into a e-commerce store for example would search a product say 'iPads' then click the product links that appeared in the search results.
However, if your scraper never visits the search page and uses slimmed down URLs that the website normally doesn't show to users then a website might detect this and ban your account.
Risks Of Scraping Behind Logins
Compared to scraping publically available web pages, scraping behind logins carries with it a lot more risks for you as a developer and company:
Risk 1: Personal Information
When you created the account, you most likely had to give the website personal information (name, email, telephone, credit card, etc.) that the website can tie back to your scraper.
Risk 2: Account Bans
Another risk, is if the website is detects your scraper then they could block/delete your account and ban you from creating any new accounts.
Sometimes, losing an account mightn't be a big deal. However, if your Facebook, Instagram, etc. account got banned then you could lose all your photos, messages, Facebook Ads account and never be able to create another account again.
Or if you were using a paid account, then you could be locked out of your account with no refund.
Risk 3: Lawsuits
Scraping public web pages is a bit of legal grey area, however, when it comes to scraping behind a websites login then the law and legal precendants are much clearer.
When you create an account with a website, you explicitedly agree to a websites Terms & Conditions which can forbid the scraping of their content. So if you create an account with a website than forbids web scraping and you scrape their website anyway then you do open yourself up to potential lawsuits.
Nearly all successful web scraping lawsuits have been when a user scraped behind a login, and some websites can be very aggresive enforcing this and can look to make an example out of users caught scraping behind logins.
So before scraping behind a websites login, you should first review their Terms & Conditions and then make an informed decision on whether the data you would obtain from scraping behind a login is worth the legal risks involved.
More Scrapy Tutorials
So theres an overview on how to login to websites using Scrapy and scrape non-public data.
If you would like to learn more about Scrapy, then be sure to check out The Scrapy Playbook.