Mastering Scrapy Item Loaders: Streamlining Data Extraction and Formatting
The goal of web scraping is to turn unstructured HTML data into clean and structured data that can be used in our applications and data pipelines.
Oftentimes, developers just yield their scraped data in the form of a dictionary when starting out with Scrapy, however there is a better way which is called Scrapy Items.
In this guide, we're going to walk through:
- What Are Scrapy Items & Why Should We Use Them?
- How To Integrate Items Into Your Spiders
- Setting Up a Basic Item Loader
- Using Input and Output Processors
- Customizing Item Loaders
- Advanced Item Loader Techniques
- Real-World Example: Scraping and Loading Data Efficiently
- Conclusion
- More Python Web Scraping Guides
What Are Scrapy Item & Why Should We Use Them?
At its core, a Scrapy Item is just a dataclass. It's a list of key-value pairs. Each item has certain characteristics we call traits or attributes depending on which camp you belong to.
Take a look at books.toscrape.com. As you can see in our screenshot below, each book has a title, a rating, author and an In stock field.
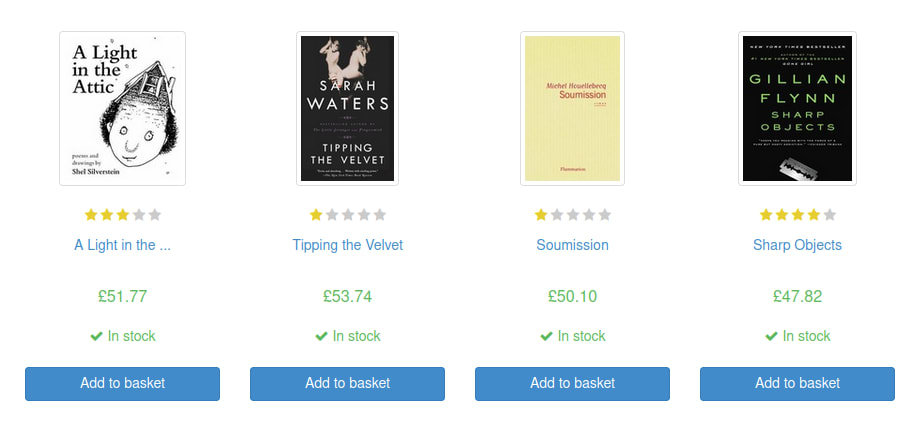
When we scrape these books, we could use a dict, but the dict type isn't made to fit our book objects.
A dict is more of a one-size-fits-all solution when you're prototyping. When scraping more difficult pages, you often won't know exactly which fields you can scrape until you've run the scrape a few times.
In our prototype code, we might use the following:
book = {
"title": "some random title",
"author": "some author name",
"rating": "5 stars",
"availability": "In stock"
}
The example above will work in most cases, but it is loosely typed. When we use the book variable with other software, it has all the traits of a dict and we might not want those. To handle these edge cases, we can use Scrapy's Item type.
Now, we'll create a custom datatype for our book.
class BookItem(scrapy.Item):
title = scrapy.Field()
price = scrapy.Field()
availability = scrapy.Field()
rating = scrapy.Field()
We have four traits, each one is Scrapy's Field type. Field() acts as a placeholder for whatever we're going to put inside the BookItem. This allows us to pass in anything for custom processing or add default values.
If we want a more tightly defined structure, we could do this. As you can see, we now have a default value for each Field in our BookItem.
This way, is something is not found during the scrape, our BookItem will use the default value to ensure that all of our data comes in a clean, uniform format.
class BookItem(scrapy.Item):
title = scrapy.Field(default="n/a")
price = scrapy.Field(default="0.00")
availability = scrapy.Field(default="")
rating = scrapy.Field(default="Zero")
Out of the box, Scrapy allows us to export these Item objects directly into a CSV or JSON file. You can create pretty much any type of custom pipeline you want with Scrapy, and we're going to use a JSON file here.
It's built into Scrapy directly so we can keep our focus on the Item type. When we're done making our scraper, we'll export it directly to a JSON file.
How To Integrate Items Into Your Spiders
Now, let's actually use this BookItem we've been droning on about.
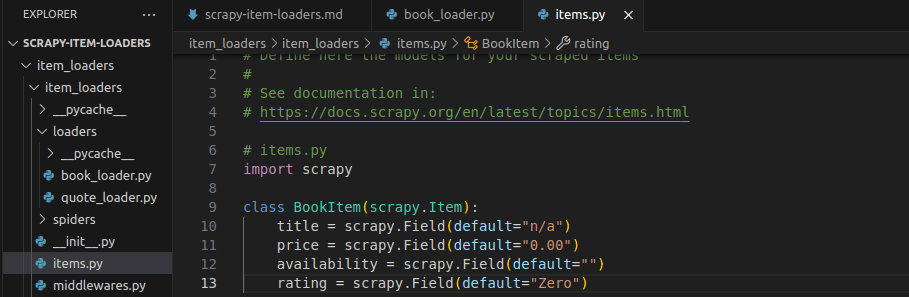
First, we'll need to create a new Scrapy project. Then, we'll add our BookItem to items.py
Once we've got our BookItem, we can create a BookLoader, which we'll use to pass our extracted data into the BookItem.
First, you need to create a new Scrapy project.
scrapy startproject item_loaders
Next, select your items file and add the BookItem to it.
You can copy and paste it from the block below.
class BookItem(scrapy.Item):
title = scrapy.Field(default="n/a")
price = scrapy.Field(default="0.00")
availability = scrapy.Field(default="")
rating = scrapy.Field(default="Zero")
We've almost got everything in place.
Now, we need to add a spider. The spider actually pings a url and performs the scrape. Inside the spiders folder, add a new file, books_spider.py. Add the following code to it.
import scrapy
from item_loaders.items import BookItem
from item_loaders.loaders.book_loader import BookLoader
class BooksSpider(scrapy.Spider):
name = "books"
start_urls = ["http://books.toscrape.com"]
def parse(self, response):
for book in response.css("article.product_pod"):
loader = BookLoader(item=BookItem(), selector=book)
loader.add_css("title", "h3 a::attr(title)")
loader.add_css("price", ".price_color::text")
loader.add_css("availability", ".instock.availability::text")
loader.add_css("rating", "p.star-rating::attr(class)")
yield loader.load_item()
This BookSpider class is what actually fetches the url and actually executes our scraping logic.
name = "books": When we run our spider, we'll use the wordbooksto invoke the scraper.
Now, let's take a look at our parse() function.
for book in response.css("article.product_pod"):Finds all the books on the page.loader = BookLoader(item=BookItem(), selector=book)tells Scrapy that we want to create aBookloaderinstance.item=BookItem()tells Scrapy that all of our data should be passed into an instance of theBookItemclass.selector=booktells Scrapy that we'll call this selector abook.- The
add_css()method allows us to add CSS from ourbookinto ourBookItemclass. We use this method to extract the following:titlepriceavailabilityrating
Basics of Scrapy Item Loaders
Here's a simple ItemLoader. We're going to use it later on in our project, but right now, we need to talk about what it does.
# loaders/book_loader.py
from itemloaders import ItemLoader
from itemloaders.processors import TakeFirst, MapCompose, Join
class BookLoader(ItemLoader):
default_output_processor = TakeFirst()
price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float)
availability_in = MapCompose(str.strip)
rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", ""))
default_output_processor = TakeFirst(): Tells Scrapy that if we take more than one piece of data for a field, we only take the first.MapCompose()is used to take a list of functions as arguments.price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float): First, we strip any whitespace. Then we replace the currency symbols, and convert the number into afloat.availability_in = MapCompose(str.strip): We strip any whitespace from the availability field.rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", "")): Strip the input and remove the"star-rating"phrase from any input.
Each Item Loader comes with add_xpath() and add_css() methods. We can use add_xpath() to extract data using its xpath and pass it directly into our Item. add_css() does the same thing, except instead of using an xpath, it uses the CSS selector to extract the data.
You can view usage examples of these methods below.
XPath
def parse(self, response):
for quote in response.xpath(".//div[@class='quote']"):
loader = QuoteLoader(item=QuoteItem(), selector=quote)
loader.add_xpath("text", ".//span[@class='text']/text()")
loader.add_xpath("author", ".//small[@class='author']/text()")
loader.add_xpath("tags", ".//a[@class='tag']/text()")
yield loader.load_item()
CSS Selector
def parse(self, response):
for book in response.css("article.product_pod"):
loader = BookLoader(item=BookItem(), selector=book)
loader.add_css("title", "h3 a::attr(title)")
loader.add_css("price", ".price_color::text")
loader.add_css("availability", ".instock.availability::text")
loader.add_css("rating", "p.star-rating::attr(class)")
yield loader.load_item()
As you can see in the examples above, the logic in these parsers is more or less the same. One of them extracts data using its XPath, and the other uses a CSS Selector.
Setting Up a Basic Item Loader
Now, we need to add our ItemLoader. If you don't already have one, create a new folder inside your Scrapy project called loaders. Inside your loaders folder, add a file called book_loader.py.
Paste the following code into it.
# loaders/book_loader.py
from itemloaders import ItemLoader
from itemloaders.processors import TakeFirst, MapCompose, Join
class BookLoader(ItemLoader):
default_output_processor = TakeFirst()
price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float)
availability_in = MapCompose(str.strip)
rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", ""))
Using Input and Output Processors
As we already know, Scrapy's Item Loaders are used to handle input and output during our data extraction process. We've already seen TakeFirst(), and MapCompose(). There are a few other input and output processors we should be aware of as well.
-
Input Processors: We've already used these. They're great for taking in data and cleaning it before it gets to our Item class.
-
Output Processors: These are used to format our data before assigning it to an item field.
Check out the table below for a more complete understanding of Scrapy's Input and Output Processors.
| Processor | Type | Description |
|---|---|---|
TakeFirst | Output | Return the first non-empty value of the data. |
Join | Output | Join all the values into a single string. |
MapCompose | Input | Run a chain of functions on the extracted value. |
Identity | Input/Output | Return the input as is, with no custom processing. |
Creating Custom Processors With MapCompose
Take a look at our BookLoader one more time. The statements using MapCompose() are actually custom processors. MapCompose() takes in an array of functions to deliver custom data into our BookItem object. We use this when creating the price_in, availability_in, and the rating_in variables.
class BookLoader(ItemLoader):
default_output_processor = TakeFirst()
price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float)
availability_in = MapCompose(str.strip)
rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", ""))
-
price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float): First, westripthe incoming string. Then, we replace any currency symbols within the string. Finally, we usefloatto convert the data into afloatpoint number. -
availability_in = MapCompose(str.strip): This one is more simple. We're only doing one thing. We strip any whitespace and newline characters from the string. -
rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", "")): Here, we once again strip the string. Then, we replace the string"star-rating "with"", effectively removing it from our string.
Customizing Item Loaders
We've already written one custom Item Loader. Now, let's write another one for quotes.toscrape.com.
This is a great example because the site is laid out very similar to the front page of a blog. We've got a bunch of posts and they're laid out just like the front page of a blog.
We'll start by creating our QuoteItem. Similar to the BookItem, contains fields that are relevant what we extract from each quote object on the site. This one contains fields for text, author, and tags.
class QuoteItem(scrapy.Item):
text = scrapy.Field(default="n/a")
author = scrapy.Field(default="n/a")
tags = scrapy.Field(default=None)
By now, your items.py file should like like this.
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
# items.py
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field(default="n/a")
price = scrapy.Field(default="0.00")
availability = scrapy.Field(default="")
rating = scrapy.Field(default="Zero")
class QuoteItem(scrapy.Item):
text = scrapy.Field(default="n/a")
author = scrapy.Field(default="n/a")
tags = scrapy.Field(default=None)
Next, we'll create our QuoteLoader. Create a new file in your loaders folder. Call it quote_loader.py.
# loaders/quote_loader.py
from itemloaders import ItemLoader
from itemloaders.processors import TakeFirst, MapCompose, Join
class QuoteLoader(ItemLoader):
default_output_processor = TakeFirst()
text_in = MapCompose(str.strip)
author_in = MapCompose(str.strip)
tags_out = Join(", ")
default_output_processor = TakeFirst(): If there are two extracted items for a single field, take the first.text_in = MapCompose(str.strip): Strip any whitespace from the incoming text.author_in = MapCompose(str.strip): Strip any whitespace from the incoming author.tags_out = Join("", ""): Join all of our tags into a list.
Best Practices for Using Item Loaders
When writing Item Loaders, it's best practice to field-specific logic separate from our spider logic. We don't want to be stripping whitespace or replacing currency symbols from inside our spider. It creates tangled logic that's harder to maintain.
We could easily, clean our data from inside the spider. Imagine using this example inside the BookSpider.
When something breaks, you need to take apart and debug the spider.
def parse(self, response):
for book in response.css("article.product_pod"):
title = book.css("h3 a::attr(title)").get().strip()
price = float(book.css(".price_color::text").get().replace("£", ""))
yield {"title": title, "price": price}
From inside our spider, we use our loader instead. If something breaks in the loader, you'll know to go straight to the BookLoader object and fix it.
class BookLoader(ItemLoader):
default_output_processor = TakeFirst()
price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float)
availability_in = MapCompose(str.strip)
rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", ""))
Advanced Item Loader Techniques
Item Loaders give us a powerful way to deal with some of the more difficult challenges in web scraping.
Let's take a look at some of the more advanced strategies we can use to handle these challenges with Scrapy's Item Loaders.
Nested Data Structures
In real life, you'll find nested data structures on websites all over the place. You can create a special loader for each type of object you want to scrape. For example, if you're scraping books initially, you can scrape their reviews with an additional ReviewItem and a ReviewItemLoader.
The example below is entirely hypothetical, but you could definitely follow this logic for nested data.
class BooksSpider(scrapy.Spider):
name = "books_with_reviews"
start_urls = ["http://books.toscrape.com"]
def parse(self, response):
for book in response.css("article.product_pod"):
book_loader = BookLoader(selector=book)
book_loader.add_css("title", "h3 a::attr(title)")
book_loader.add_css("price", ".price_color::text")
#extract nested reviews
reviews = []
for review in book.css(".reviews .review"):
review_loader = ReviewLoader(selector=review)
review_loader.add_css("reviewer", ".reviewer::text")
review_loader.add_css("comment", ".comment::text")
reviews.append(review_loader.load_item())
book_loader.add_value("reviews", reviews)
yield book_loader.load_item()
Debugging Loaders
When an Item Loader breaks, we need to know about it. Scrapy provides us with tools to inspect our data while it's getting passed into the Item class.
In the example below, we print the Loader for debugging purposes.
Take a look at our QuoteSpider if we want to use it for debugging.
import scrapy
from item_loaders.items import QuoteItem
from item_loaders.loaders.quote_loader import QuoteLoader
import pdb # Python debugger
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["http://quotes.toscrape.com"]
def parse(self, response):
for quote in response.css("div.quote"):
# Initialize the loader
loader = QuoteLoader(item=QuoteItem(), selector=quote)
# Add data to the loader
loader.add_css("text", ".text::text")
loader.add_css("author", ".author::text")
loader.add_css("tags", ".tags a.tag::text")
#debug here
pdb.set_trace()
#print the intermediate data
print("Intermediate data:", loader.get_collected_values("text"))
yield loader.load_item()
set_trace() and get_collected_values() allow us to view detailed information about our program and our ItemLoader.
Real-World Example: Scraping and Loading Data Efficiently
In this section, we'll do a quick onceover on both our QuoteScraper and our BookScraper.
We'll talk through and make sure you have all the required files to run the two scrapers you've been building throughout this tutorial.
Books
Now, let's take a look at our code for scraping books. In your items file, you should have a BookItem defined. Your BookItem should look like this.
class BookItem(scrapy.Item):
title = scrapy.Field(default="n/a")
price = scrapy.Field(default="0.00")
availability = scrapy.Field(default="")
rating = scrapy.Field(default="Zero")
In the loaders folder, you should have your BookLoader class. It should be located inside book_loader.py.
# loaders/book_loader.py
from itemloaders import ItemLoader
from itemloaders.processors import TakeFirst, MapCompose, Join
class BookLoader(ItemLoader):
default_output_processor = TakeFirst()
price_in = MapCompose(str.strip, lambda x: x.replace("£", "").replace("$", ""), float)
availability_in = MapCompose(str.strip)
rating_in = MapCompose(str.strip, lambda x: x.replace("star-rating ", ""))
Now, make sure you've got a BookSpider inside your spiders folder.
import scrapy
from item_loaders.items import BookItem
from item_loaders.loaders.book_loader import BookLoader
class BooksSpider(scrapy.Spider):
name = "books"
start_urls = ["http://books.toscrape.com"]
def parse(self, response):
for book in response.css("article.product_pod"):
loader = BookLoader(item=BookItem(), selector=book)
loader.add_css("title", "h3 a::attr(title)")
loader.add_css("price", ".price_color::text")
loader.add_css("availability", ".instock.availability::text")
loader.add_css("rating", "p.star-rating::attr(class)")
yield loader.load_item()
You can run the spider with the following command.
scrapy crawl books -o books.json
It will spit out an JSON file that looks like you see below.
[
{"title": "A Light in the Attic", "price": 51.77, "availability": "In stock", "rating": "Three"},
{"title": "Tipping the Velvet", "price": 53.74, "availability": "In stock", "rating": "One"},
{"title": "Soumission", "price": 50.1, "availability": "In stock", "rating": "One"},
{"title": "Sharp Objects", "price": 47.82, "availability": "In stock", "rating": "Four"},
{"title": "Sapiens: A Brief History of Humankind", "price": 54.23, "availability": "In stock", "rating": "Five"},
{"title": "The Requiem Red", "price": 22.65, "availability": "In stock", "rating": "One"},
{"title": "The Dirty Little Secrets of Getting Your Dream Job", "price": 33.34, "availability": "In stock", "rating": "Four"},
{"title": "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull", "price": 17.93, "availability": "In stock", "rating": "Three"},
{"title": "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics", "price": 22.6, "availability": "In stock", "rating": "Four"},
{"title": "The Black Maria", "price": 52.15, "availability": "In stock", "rating": "One"},
{"title": "Starving Hearts (Triangular Trade Trilogy, #1)", "price": 13.99, "availability": "In stock", "rating": "Two"},
{"title": "Shakespeare's Sonnets", "price": 20.66, "availability": "In stock", "rating": "Four"},
{"title": "Set Me Free", "price": 17.46, "availability": "In stock", "rating": "Five"},
{"title": "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)", "price": 52.29, "availability": "In stock", "rating": "Five"},
{"title": "Rip it Up and Start Again", "price": 35.02, "availability": "In stock", "rating": "Five"},
{"title": "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991", "price": 57.25, "availability": "In stock", "rating": "Three"},
{"title": "Olio", "price": 23.88, "availability": "In stock", "rating": "One"},
{"title": "Mesaerion: The Best Science Fiction Stories 1800-1849", "price": 37.59, "availability": "In stock", "rating": "One"},
{"title": "Libertarianism for Beginners", "price": 51.33, "availability": "In stock", "rating": "Two"},
{"title": "It's Only the Himalayas", "price": 45.17, "availability": "In stock", "rating": "Two"}
]
Quotes
Next, we'll do the same for our Quotes scraper project. We'll double check all of our components and run the code.
Once again, we'll use JSON for our output.
items.py should contain a QuoteItem.
class QuoteItem(scrapy.Item):
text = scrapy.Field(default="n/a")
author = scrapy.Field(default="n/a")
tags = scrapy.Field(default=None)
Now, take a look at your ItemLoader inside of the loaders folder.
# loaders/quote_loader.py
from itemloaders import ItemLoader
from itemloaders.processors import TakeFirst, MapCompose, Join
class QuoteLoader(ItemLoader):
default_output_processor = TakeFirst()
text_in = MapCompose(str.strip)
author_in = MapCompose(str.strip)
tags_out = Join(", ")
Finally, from inside your spiders folder, make sure you have a QuoteSpider.
# spiders/quotes_spider.py
import scrapy
from ..items import QuoteItem
from ..loaders.quote_loader import QuoteLoader
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["https://quotes.toscrape.com"]
def parse(self, response):
for quote in response.xpath(".//div[@class='quote']"):
loader = QuoteLoader(item=QuoteItem(), selector=quote)
loader.add_xpath("text", ".//span[@class='text']/text()")
loader.add_xpath("author", ".//small[@class='author']/text()")
loader.add_xpath("tags", ".//a[@class='tag']/text()")
yield loader.load_item()
You can run your scraper with this command.
scrapy crawl quotes -o quotes.json
The output file will look like this.
[
{"text": "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”", "author": "Albert Einstein", "tags": "change, deep-thoughts, thinking, world"},
{"text": "“It is our choices, Harry, that show what we truly are, far more than our abilities.”", "author": "J.K. Rowling", "tags": "abilities, choices"},
{"text": "“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”", "author": "Albert Einstein", "tags": "inspirational, life, live, miracle, miracles"},
{"text": "“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”", "author": "Jane Austen", "tags": "aliteracy, books, classic, humor"},
{"text": "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”", "author": "Marilyn Monroe", "tags": "be-yourself, inspirational"},
{"text": "“Try not to become a man of success. Rather become a man of value.”", "author": "Albert Einstein", "tags": "adulthood, success, value"},
{"text": "“It is better to be hated for what you are than to be loved for what you are not.”", "author": "André Gide", "tags": "life, love"},
{"text": "“I have not failed. I've just found 10,000 ways that won't work.”", "author": "Thomas A. Edison", "tags": "edison, failure, inspirational, paraphrased"},
{"text": "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”", "author": "Eleanor Roosevelt", "tags": "misattributed-eleanor-roosevelt"},
{"text": "“A day without sunshine is like, you know, night.”", "author": "Steve Martin", "tags": "humor, obvious, simile"}
]
Conclusion
There you have it. Scrapy's Item Loaders are an awesome side kick to have when scraping the web. They allow you to do almost anything you want with your raw data before it gets passed into your Item class and then your storage.
Go take this new knowledge and scrape the latest job postings, computer parts, or any other kind of data you wish to harvest.
With Item Loaders, you can take even the ugliest, dirtiest data and easily have it cleaned and ready to use.
If you're interested in learning more about Scrapy in general, check out their docs here.
More Python Web Scraping Guides
We love web scraping. We also love Scrapy. We love Scrapy so much that we wrote a full playbook on things you can do with it.
You can view that here.
If you want a taste of this playbook, check out the articles below.