
Scrapy Cloud: Guide to Running Spiders In The Cloud
Scrapy Cloud is a scalable cloud hosting solution for running & scheduling your Scrapy spiders, created by Zyte (formerly Scrapinghub).
Styled as a Heroku for Scrapy spiders, it makes deploying, scheduling and running your spiders in the cloud very easy.
In this guide we are going to show you how to:
- Should I Use Scrapy Cloud?
- Get Started With Scrapy Cloud
- Deploy Your Spiders To Scrapy Cloud From Command Line
- Deploy Your Spiders To Scrapy Cloud via GitHub
- Run Spiders On Scrapy Cloud
- Schedule Jobs on Scrapy Cloud
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Demo Spider
In this guide, we're going to deploy the public demo Scrapy spider booksbot. To use it simple clone it to your machine.
git clone https://github.com/scrapy/booksbot.git
cd booksbot
Should I Use Scrapy Cloud?
Scrapy Cloud is a great spider hosting solution if you are building your scrapers using the Scrapy, and don't want to deal with setting up your own servers and job scheduling system.
With Scrapy Cloud you simply need to deploy your spiders to the Scrapy Cloud platform and configure when you want them to run. From here, Scrapy Cloud takes care of running the jobs and storing the data your spiders scrape.
Scrapy Cloud boasts some pretty powerful features:
- On-demand scaling
- Easy integration with other Scrapy & Zyte products (Splash, Spidermon, Zyte Smart Proxy Manager)
- Full suite of logging & data QA tools
There are some downsides to Scrapy Cloud however:
- Ineffective Free Plan - Although Scrapy Cloud offers a free plan, you can't schedule jobs with it and can only execute 1 hour of crawl time then it can't really be used for production scraping.
- Cost - The Professional plan starts at $9 per Scrapy Unit per month (1 Scrapy Unit = 1 GB of RAM * 1 concurrent crawl), meaning that it is reasonably priced if you don't have much scraping to do and don't want to worry about setting up your own servers. However, if you are scraping at scale it can get quite expensive.
- Lacks Distributed Crawl Support - Scrapy Cloud doesn't really support distributed crawls where you can spin up multiple workers pulling URLs from a centralised queue.
Alternatively, there are free and cheaper alternatives to Scrapy Cloud that are just as simple to use and more flexible than Scrapy Cloud. Check out The 3 Best Scrapy Cloud Alternatives.
Get Started With Scrapy Cloud
Getting started with Scrapy Cloud is very simple.
First create a Free Account Scrapy Cloud Here, and then once logged in click "Start a new project".
And give your project a name.
Once your project has been created, you have two ways to deploy your Scrapy spiders to Scrapy Cloud:
- Via the Command Line
- Via Github Integration
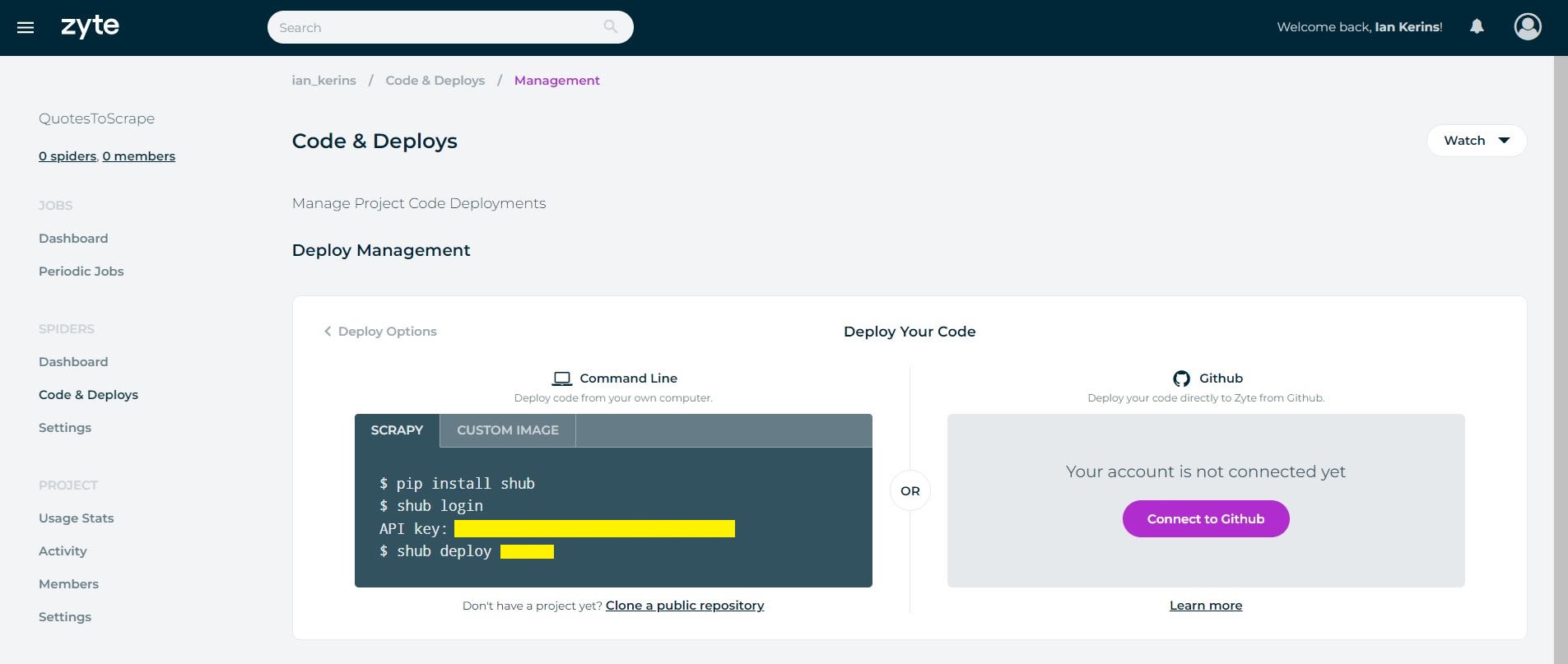
Deploy Your Spiders To Scrapy Cloud From Command Line
Using the shub command line tool we can deploy our spiders directly to Scrapy Cloud from the command line.
First install shub on your system:
pip install shub
Then link the shub client to your Scrapy Cloud project by running shub login in your command line, and when prompted enter your Scrapy Cloud API key.
shub login
API key: YOUR_API_KEY
You can find your API key on the Code & Deploys page.
Then to deploy your Scrapy project to Scrapy Cloud, run the shub deploy command followed by your project's id:
shub deploy PROJECT_ID
You can find your project's id, on the Code & Deploys page or in the project URL.
https://app.zyte.com/p/PROJECT_ID/jobs
If successful, you will see the spiders you have available in the spiders tab.
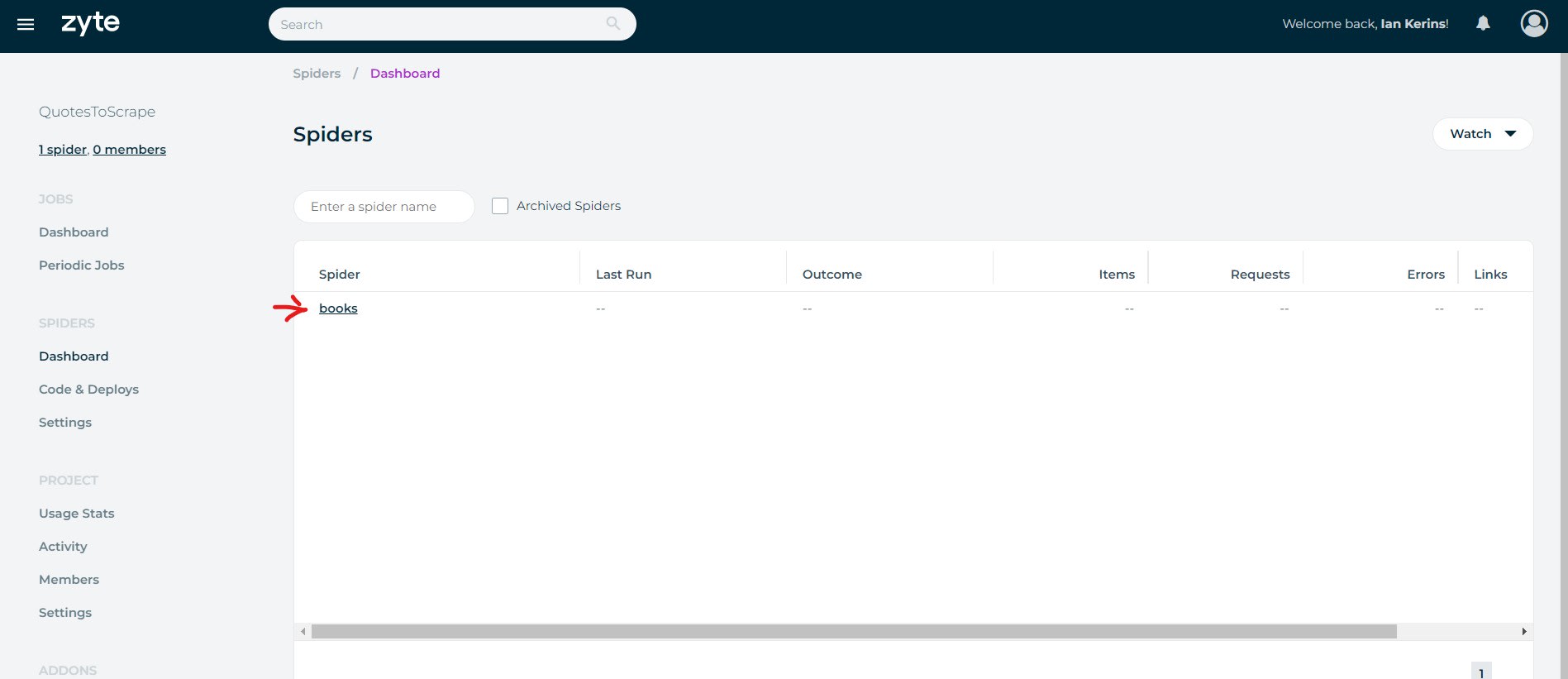
You can then run your scraping job on Scrapy Cloud directly from your command line:
$ shub schedule books
Spider books scheduled, watch it running here:
https://app.zyte.com/p/26731/job/1/8
Deploy Your Spiders To Scrapy Cloud via GitHub
The other option is to connect Scrapy Cloud directly to your GitHub account and deploy your spiders directly from the GitHub.
On the Code & Deploys page, select the option to Connect to Github and follow the instructions.
If you haven't connected Zyte to your GitHub account previously, then you might be asked to authorize Zyte to access your repositories.
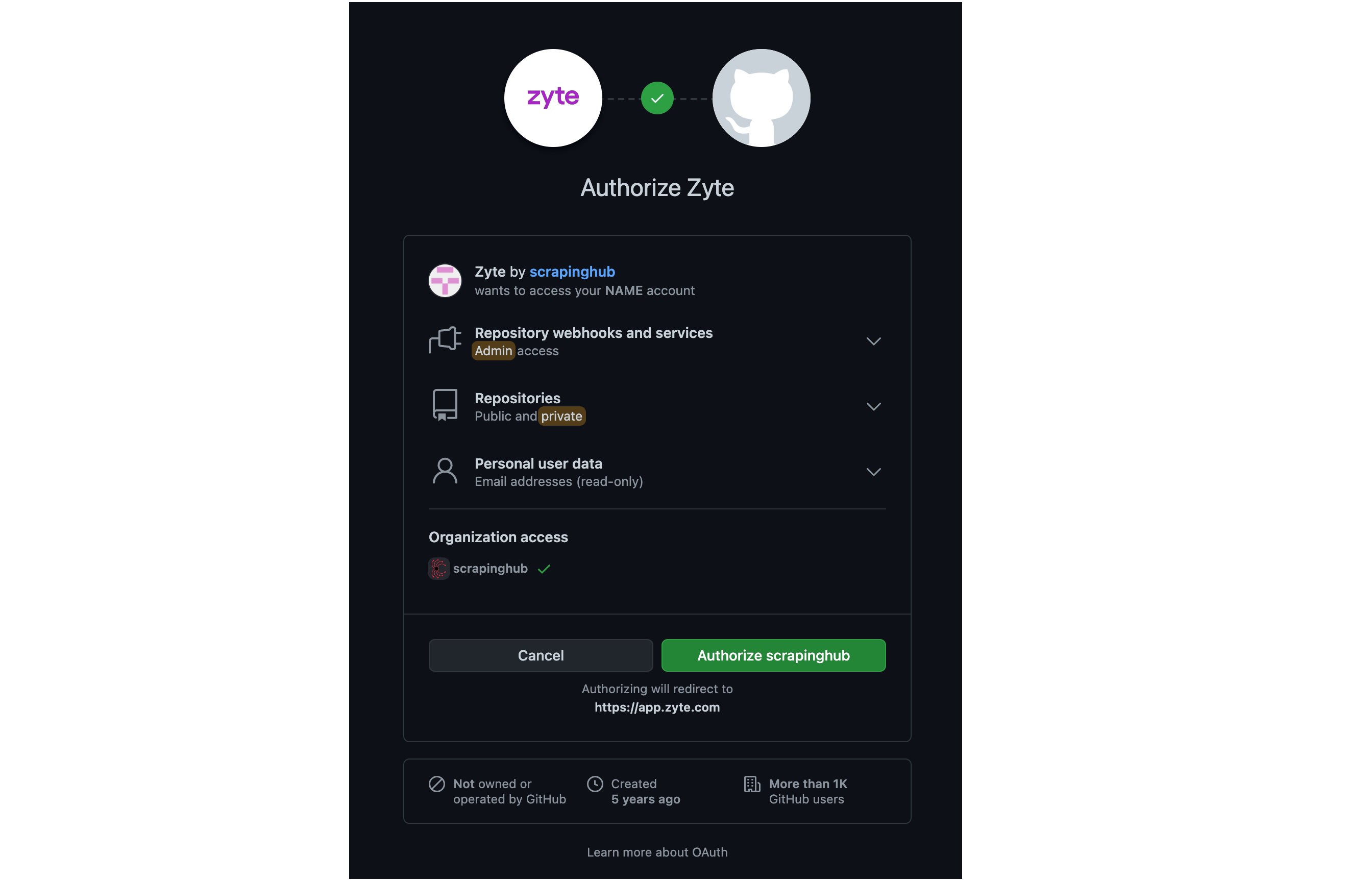
Next, you will be prompted to pick which repository you want Scrapy Cloud to connect to.
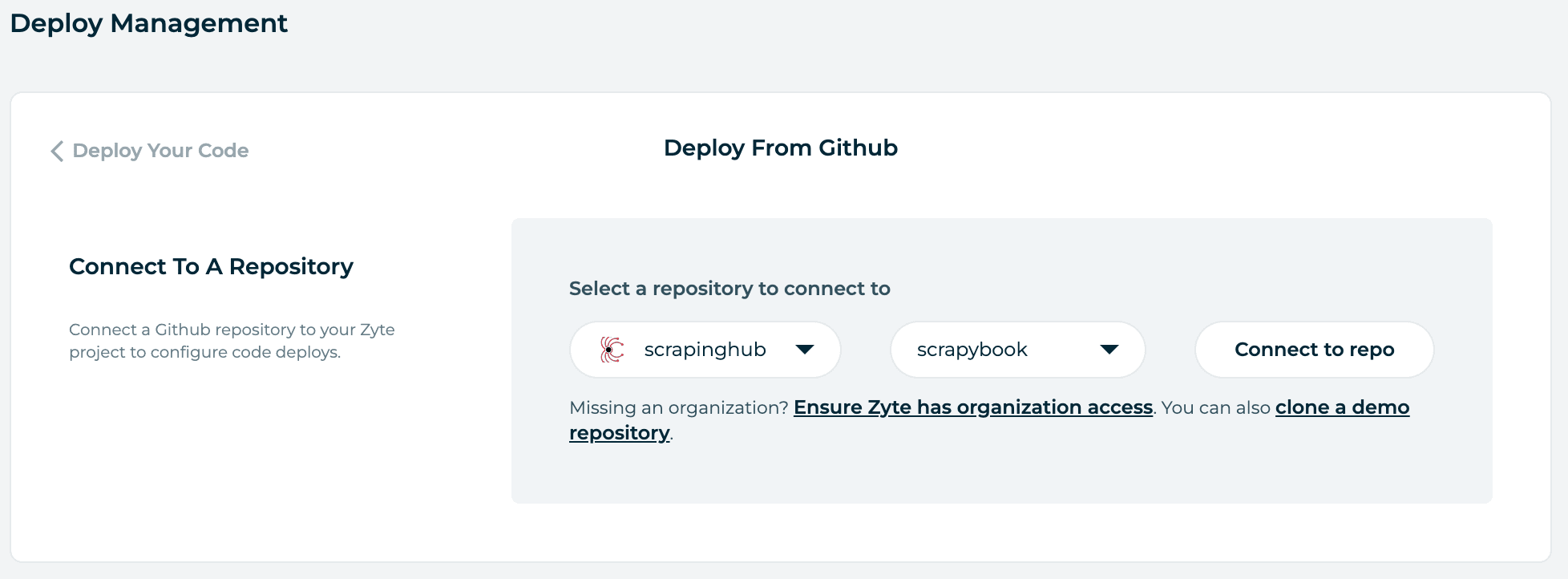
The repository you select must contain a Scrapy project at its root (i.e. the scrapy.cfg file is located in the repository root). Otherwise, the build process will fail.
By default, when you connect Scrapy Cloud to a GitHub repository it is configured to auto-deploy any changes you push to the repository. However, if you prefer you can switch it to Manual Deploy mode, and deploy changes to your spiders manually.
If you leave it in Automatic Deploy mode, then to commence the first deployment then click on the Deploy Branch button.
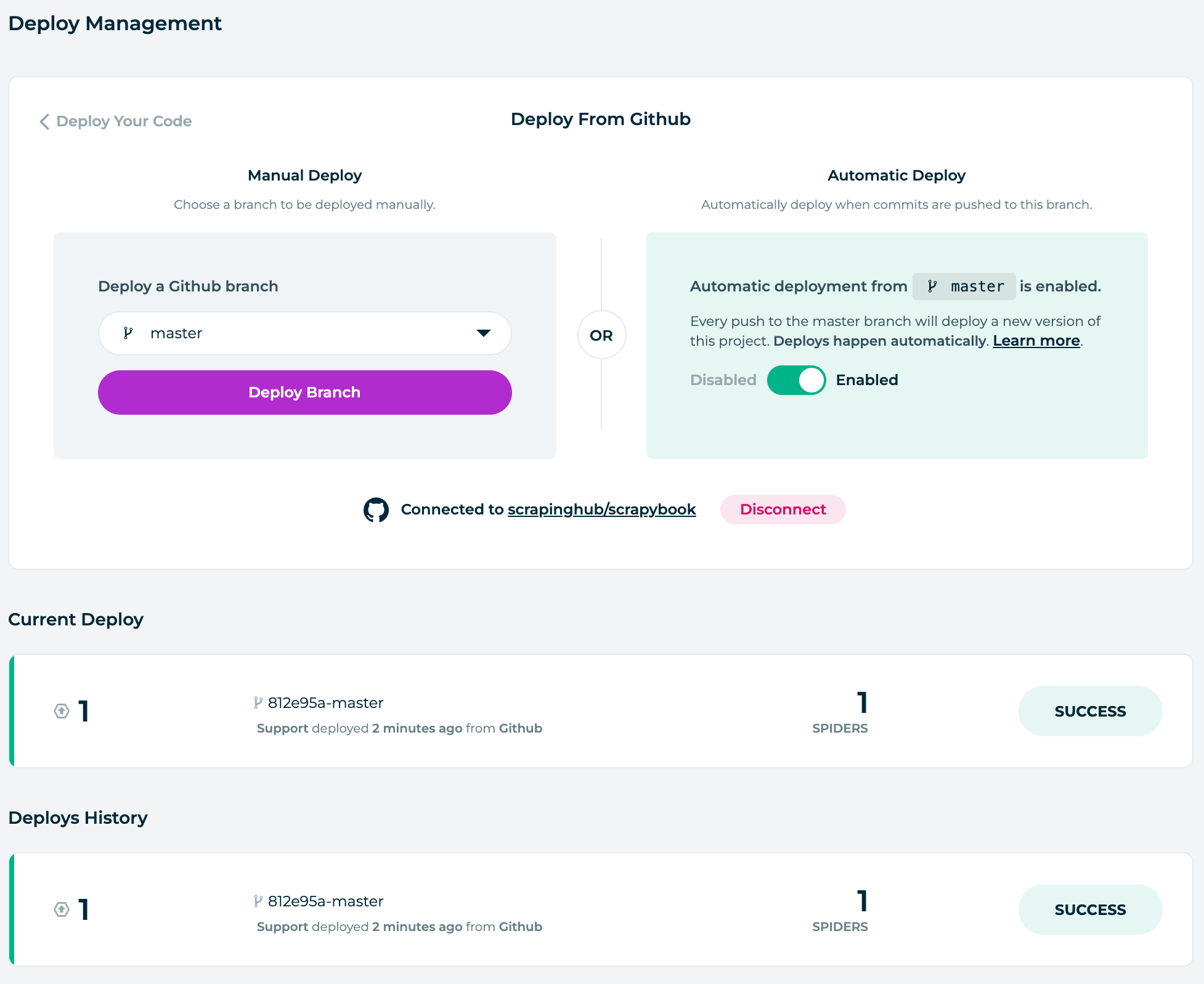
If successful, you will see the spiders you have available in the spiders tab.
Run Spiders On Scrapy Cloud
To run our scraping jobs on Scrapy Cloud once we've deployed our spider is very straightforward.
Simply go to the Spiders Dashboard, select the spider you want to run, and then click Run.
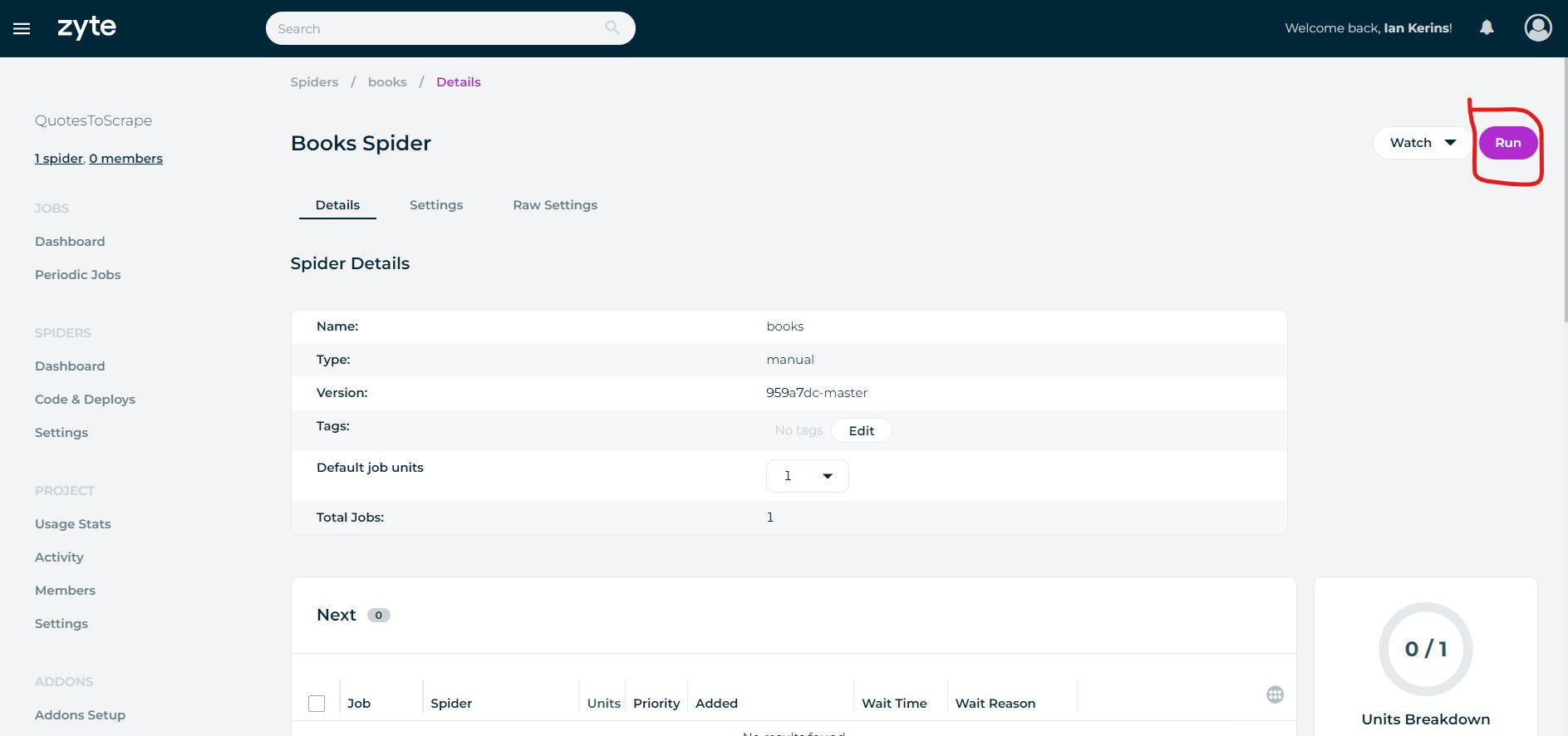
You will then be given the option to add any arguments, tags or extra Scrapy Units to the job before it is run.
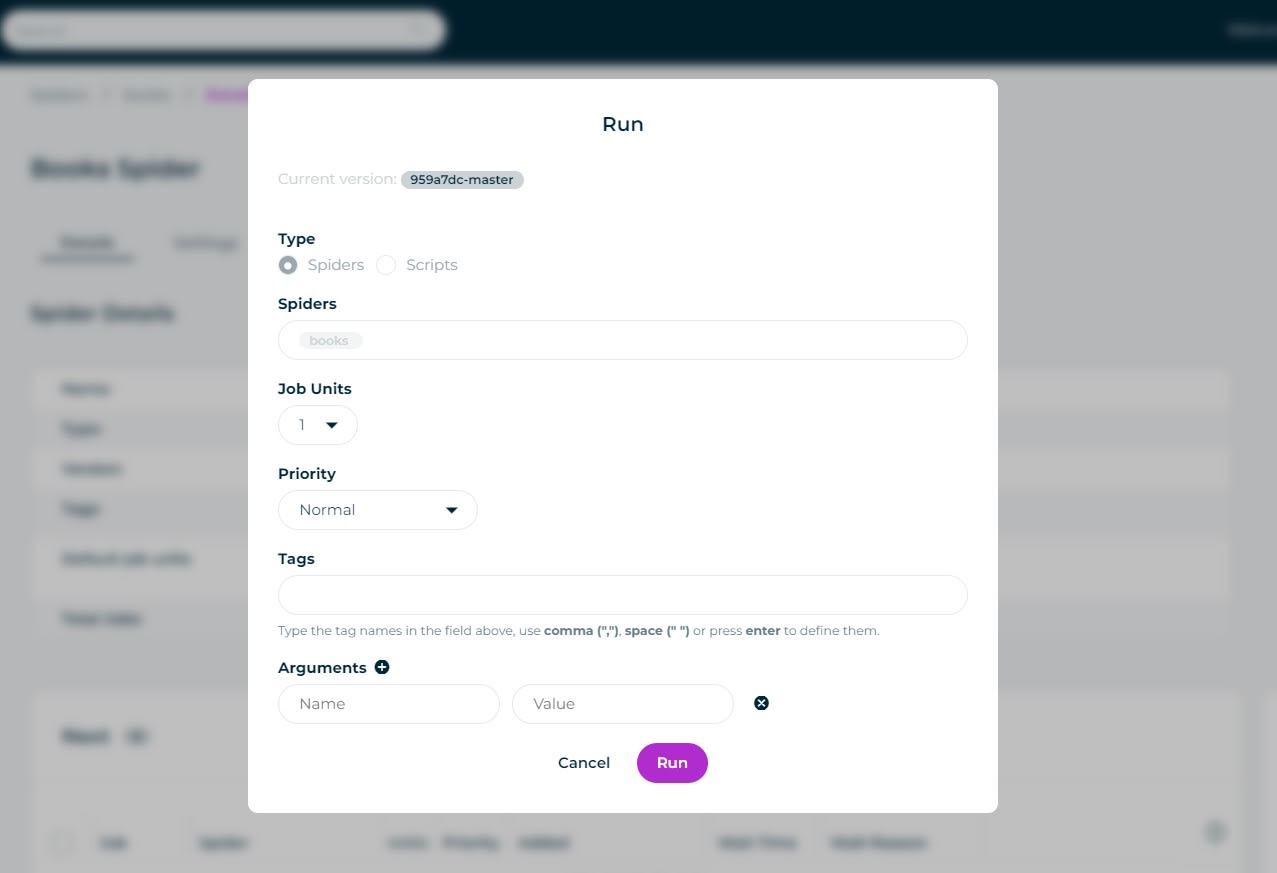
Once you are happy then click Run, and Scrapy Cloud will queue up the job to be run.
You can have certain jobs skip the queue or go to the back of the queue by giving your jobs a priority value from Lowest to Highest.
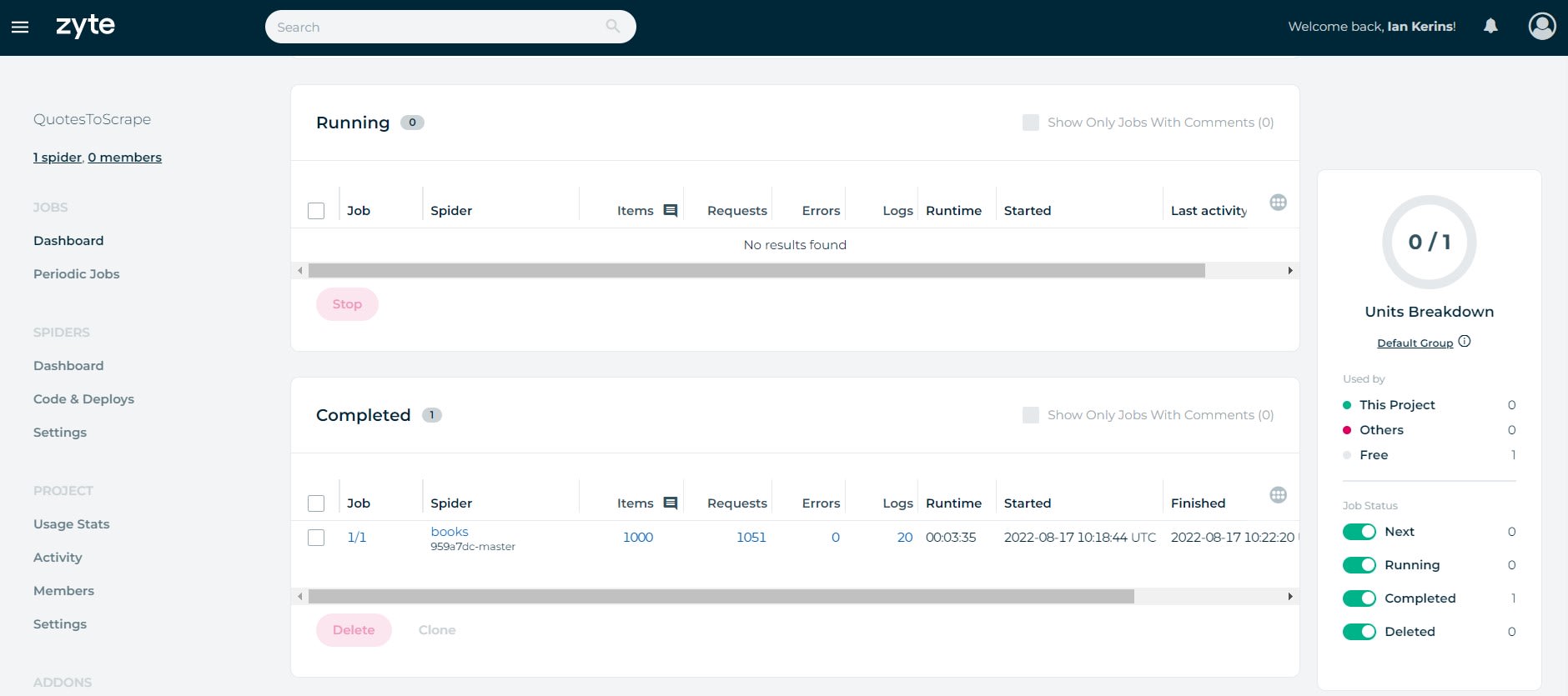
Now when you go to the Jobs Dashboard, you will see if the Job is queued, running or completed. Along with some overview stats like Runtime, Items Scraped, Errors, etc.
Schedule Jobs on Scrapy Cloud
The most useful feature of Scrapy Cloud, is the Periodic Jobs functionality that allows you to schedule your spiders to run periodically in the future.
Scrapy Cloud uses a scheduler similar to CronTabs so you can schedule your spiders to run every minute, hour, day, week or month.
To use the scheduling functionality, go to the Periodic Jobs Dashboard, and click Add Periodic Job.
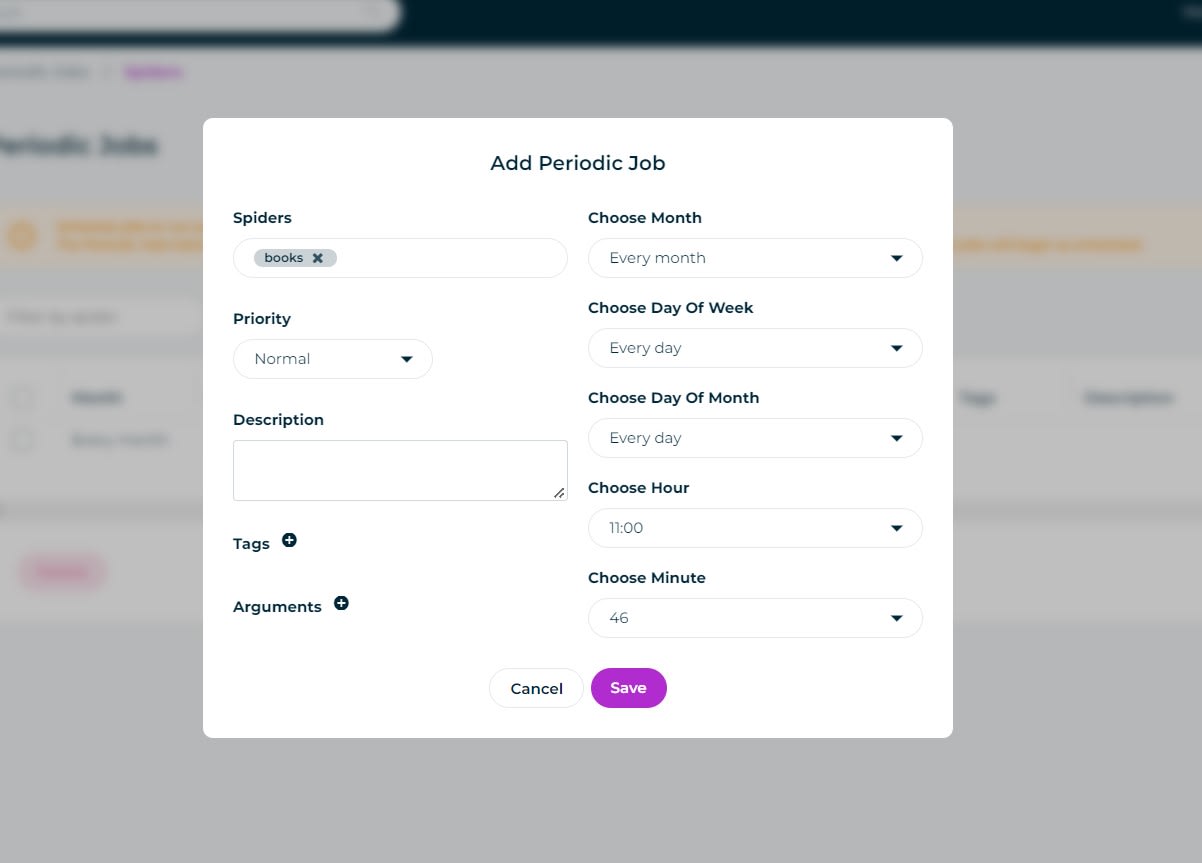
Here you are prompted to select which Spider you want to schedule, when it should run and any extra settings like Priority, Tags and Arguements.
Once saved this spider will automatically run at your selected interval.
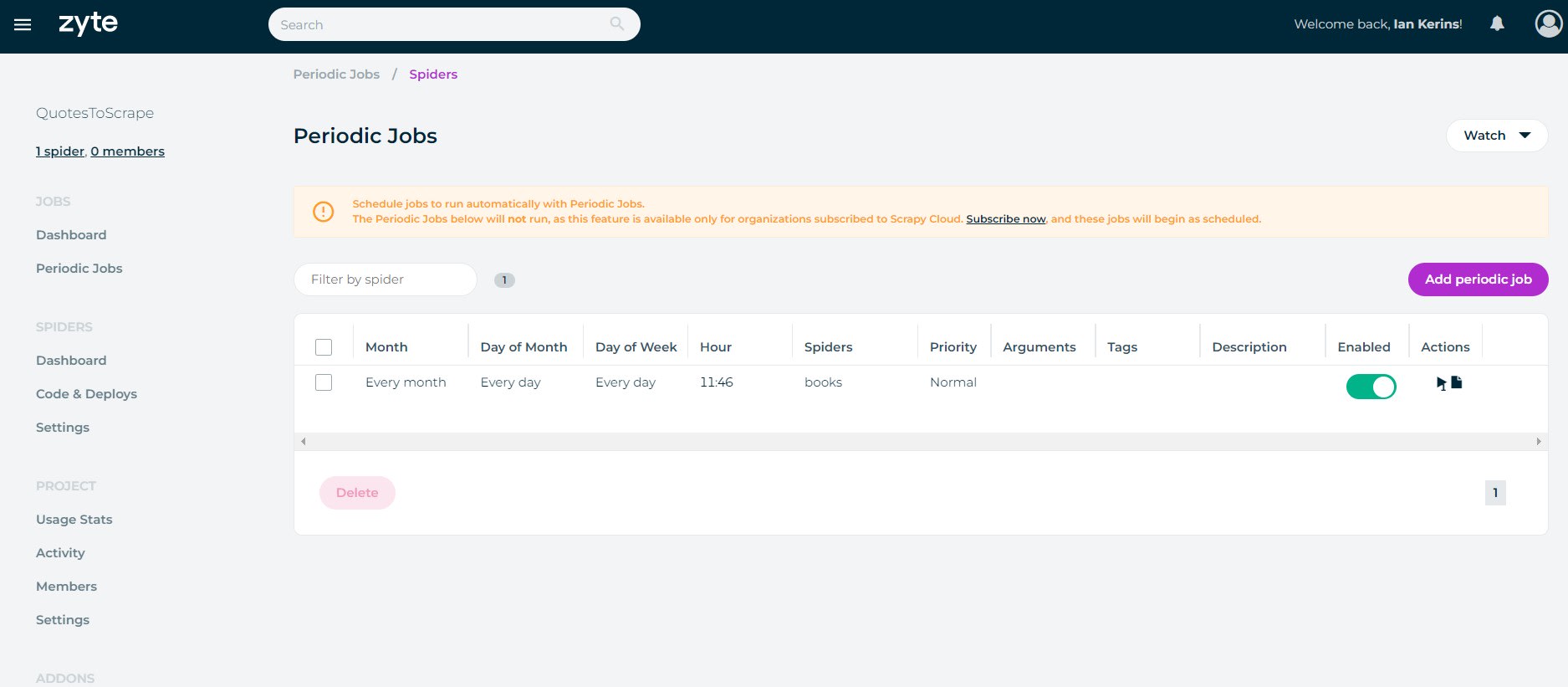
To use the Scrapy Cloud's Periodic Jobs functionality, you need to subscribe to a paid Scrapy Cloud plan (starts at $9/month). However, you can check out some free Scrapy Cloud alternatives here that don't require you to pay to schedule your jobs.
More Scrapy Tutorials
Scrapy Cloud is a great hosting solution for your Scrapy spiders, that allows you to run and schedule your spiders to run in the cloud.
If you would like to learn more about Scrapy, then be sure to check out The Scrapy Playbook.