
How To Make Puppeteer Undetectable
Designed primarily for web developers to automate user interactions for testing purposes, Puppeteer often gets blocked when used for web scraping and data extraction. This is because it lacks built-in capabilities to bypass detection mechanisms, as stealth was not its original purpose.
In this guide, we’ll explore how to overcome this limitation by making adjustments and applying patches to render Puppeteer undetectable to bot detectors.
- TLDR: How to Make Puppeteer Undetectable
- Understanding Website Bot Detection Mechanisms
- How To Make Puppeteer Undetectable To Anti-Bots
- Strategies To Make Puppeteer Undetectable
- Testing Your Puppeteer Scraper
- Handling Errors and Captchas
- Why Make Puppeteer Undetectable
- Best Practices and Considerations
- Conclusion
- More Puppeteer Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: How to Make Puppeteer Undetectable
One of the most common method to make Puppeteer undetectable is using puppeteer-extra-plugin-stealth. This is one of the most common libraries used to enhance Puppeteer's stealth capabilities. It helps evade basic anti-bot measures but may not be sufficient for more advanced systems.
Here is an example script for using puppeteer-extra-stealth-plugin:
import puppeteer from 'puppeteer-extra';
import StealthPlugin from 'puppeteer-extra-plugin-stealth';
puppeteer.use(StealthPlugin());
(async () => {
const url = 'https://bot.sannysoft.com';
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
await page.goto(url);
await page.screenshot({ path: 'image.png', fullPage: true });
await browser.close();
})();
The script above:
- Imports the Puppeteer library and the Stealth plugin for Puppeteer from
puppeteer-extra. - Navigates the newly opened page/tab to the specified URL (
https://bot.sannysoft.com) and waits for the page to load completely before proceeding to the next step. - Takes a screenshot of the entire page and saves it as
image.pngin the current directory.
Please note that, the stealth plugin only patches the missing or incorrect variable values. It is not suitable in cases where the websites have implemented anti-bot strategies like Cloudflare or CAPTCHAs.
The remaining article covers a lot of other techniques to make Puppeteer detectable that will give you enough insights and ideas to carry on your own research.
Understanding Website Bot Detection Mechanisms
A browser is an incredibly complex piece of software that provides a wealth of information about its users to websites.
Websites employ various techniques to detect and mitigate bots and automated scripts, aiming to protect their resources, prevent spam, and maintain fair access for human users.
Let's explore various ways websites can detect whether a request is coming from a bot or a real browser.
- Browser Fingerprinting:
Browser fingerprinting involves collecting numerous technical configurations of a browser to identify its users. Typing "navigator" in the console tab of the Google Chrome reveals an extensive amount of information about the browser:
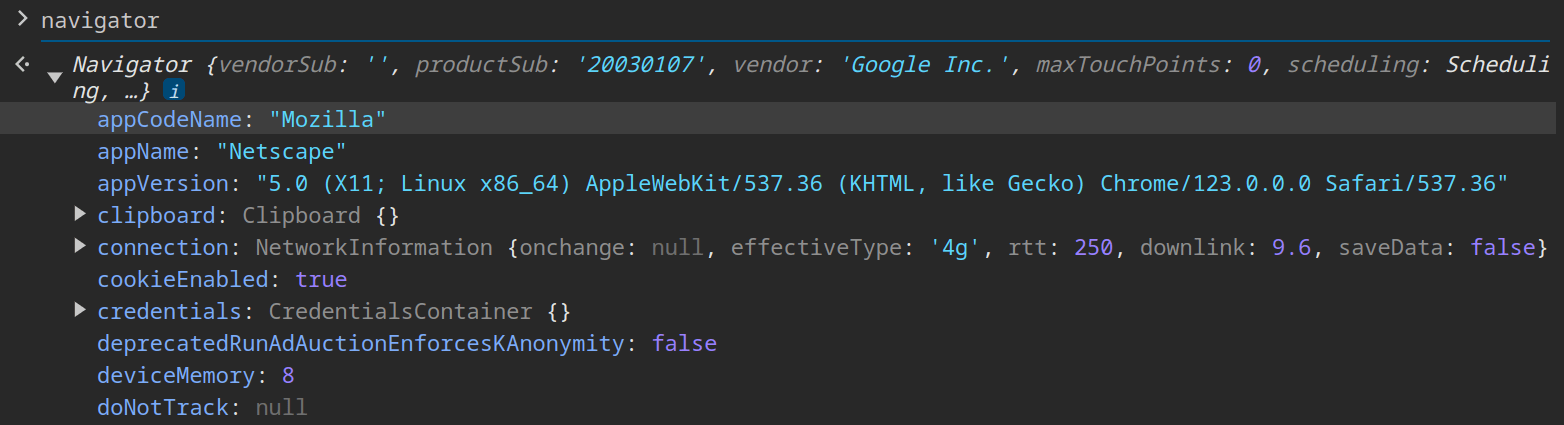
The navigator properties include several elements like languages, mimeTypes, permissions, and plugins, which are configured differently or might be absent in automated tools like Puppeteer compared to a real browser.
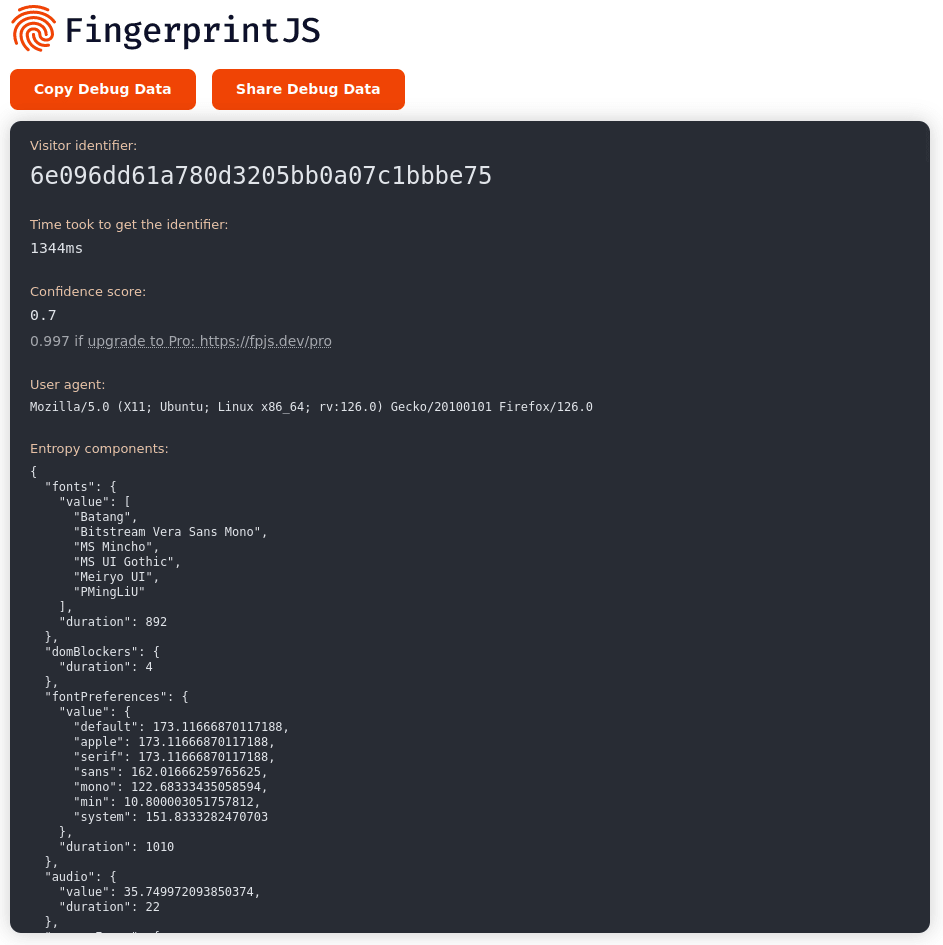
Websites can creatively use many more browser fingerprints to identify discrepancies between Puppeteer bots and real browsers. Widely used fingerprinting JavaScript libraries, such as FingerprintJS, aim to collect as many stable configuration variables as possible.
- TCP/IP Analysis:
Analyzing TCP SYN packets using tools like Nmap and p0f can reveal key characteristics about a host's operating system, aiding in the detection of bots. Consider these factors:
-
Initial TTL (Time to Live) Value: Different operating systems use different default TTL values. For example, Windows typically uses 128, Linux often uses 64, and some versions of BSD use 64 or 255.
-
TCP Sequence Number and Initial Sequence Number (ISN) Patterns: Different operating systems generate initial sequence numbers in various ways. Analyzing the ISN can sometimes determine the OS or at least its type.
-
Window Size Scale Factor: The Window Scale option in the SYN packet indicates how much the window size can be scaled. This supports larger window sizes for high-performance networks and can reveal the OS.
-
MTU Discovery Behavior: The way the OS handles Maximum Transmission Unit (MTU) discovery, particularly the use of the DF (Don't Fragment) flag, can reveal details about the OS.
When a browser fingerprint is configured to resemble an iPhone, but the TCP SYN packet signature suggests a Linux operating system, this discrepancy can indicate bot activity.
Bot detectors use tools like Nmap to analyze the TCP/IP stack and uncover such anomalies. Here is a sample Nmap command to perform OS detection:
nmap -O --osscan-guess --fuzzy <target-ip>
- Behavious Analysis:
The most effective way to distinguish bots from real users is through behavior analysis. While fingerprint differences can be masked by modifying certain properties and functions, as done by stealth plugins (which we will discuss later), replicating natural human behavior is extremely challenging.
For instance, real users often move their mouse along lines of text as a reading aid and scroll up or down depending on their reading speed—behaviors that are difficult for bots to mimic.
- Checking for Headless Browser Environments:
Detecting headless browser environments, such as those used by bots or automated scripts, is a common technique employed by websites to prevent abuse and ensure fair access for human users.
-
User-Agent String Analysis: Websites often analyze the User-Agent HTTP header to identify headless browsers. Headless browsers typically have distinct User-Agent strings that may lack certain details or contain identifiers associated with automation tools.
-
Browser Feature Detection: Websites may use JavaScript to detect features or behaviors that are absent or behave differently in headless browsers compared to standard browsers.
-
WebDriver Detection: Some websites attempt to detect the presence of WebDriver automation tools, such as Selenium or Puppeteer, by checking for specific browser extensions or JavaScript variables injected by these tools.
-
Behavioral Analysis: Websites may employ behavioral analysis to detect patterns typical of automated scripts, such as rapid and consistent navigation, minimal interaction with elements, and predictable timing between actions.
Being detected as a bot can have significant consequences, such as having your IP address blocked. This means you may need to migrate your entire production code to a new server or invest in a proxy chain, both of which incur additional costs.
Moreover, if your bot was scraping a website that requires a premium account, you could lose your access and forfeit any money spent. Therefore, it's crucial to be very cautious when using bots on websites with strong anti-bot measures, like those enforced by Cloudflare.
How To Make Puppeteer Undetectable To Anti-Bots
Making your web scraper undetectable to anti-bot mechanisms involves several steps to ensure that the bot mimics a human user.
Here are some basic approaches, such as patching common browser fingerprinting leaks, using proxies, and employing CAPTCHA solvers, that can significantly enhance the undetectability of Puppeteer bots:
Configuring Browser Options and Profiles
-
Setting User-Agent Strings: A key step is to set a user-agent string that mimics a real browser. The user-agent string can reveal if a browser is running in headless mode.
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'); -
Navigator Plugins and Languages: Modify various navigator properties to mimic a real browser environment.
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
});
Object.defineProperty(navigator, 'languages', {
get: () => ['en-US', 'en'],
});
}); -
Enabling WebGL and Hardware Acceleration: Ensure WebGL and hardware acceleration are enabled to mimic a human-like browser environment.
const browser = await puppeteer.launch({
args: [
'--enable-webgl',
'--use-gl=swiftshader'
]
});
Implementing Proxy Rotation and IP Anonymization
-
Using Residential Proxies: Use residential proxies to appear as a regular home user rather than a data center bot.
const browser = await puppeteer.launch({
args: ['--proxy-server=http://your-residential-proxy']
}); -
Rotating IP Addresses: Rotate IP addresses to avoid detection from multiple requests coming from the same IP.
const proxies = ['http://proxy1', 'http://proxy2', 'http://proxy3'];
const getRandomProxy = () => proxies[Math.floor(Math.random() * proxies.length)];
(async () => {
const browser = await puppeteer.launch({
args: [`--proxy-server=${getRandomProxy()}`]
});
const page = await browser.newPage();
// Your code here
await browser.close();
})();
Mimicking Human Behavior
-
Handling Captchas: Use third-party services ([2captcha][], [anti-captcha][] etc) to handle reCaptchas and hCaptchas automatically.
// puppeteer-extra is a drop-in replacement for puppeteer,
// it augments the installed puppeteer with plugin functionality
const puppeteer = require('puppeteer-extra')
// add recaptcha plugin and provide it your 2captcha token (= their apiKey)
// 2captcha is the builtin solution provider but others would work as well.
// Please note: You need to add funds to your 2captcha account for this to work
const RecaptchaPlugin = require('puppeteer-extra-plugin-recaptcha')
puppeteer.use(
RecaptchaPlugin({
provider: {
id: '2captcha',
token: 'XXXXXXX' // REPLACE THIS WITH YOUR OWN 2CAPTCHA API KEY ⚡
},
visualFeedback: true // colorize reCAPTCHAs (violet = detected, green = solved)
})
)
Leveraging Headless Browser Alternatives
-
Using Puppeteer with Real Browsers: By running Puppeteer in non-headless mode, you can avoid many detection mechanisms that websites can use to identify bots.
const browser = await puppeteer.launch({ headless: false });
Strategies To Make Puppeteer Undetectable
Making Puppeteer completely undetectable is challenging due to the extensive information it provides to websites, which bot detection companies analyze using machine learning models.
Although it's impossible to address all data points from Puppeteer's headless browser, several open-source solutions have emerged, continually improving.
Notable among these are Puppeteer-Real-Browser and Puppeteer Stealth Plugin, which help Puppeteer mimic a real browser. Other methods include using high-reputation proxies, fortified Puppeteer browsers on the cloud (such as BrightData's scraping browser), and simpler alternatives like the ScrapeOps Proxy Aggregator.
- Strategy #1: Use Puppeteer-Real-Browser
- Strategy #2: Use Puppeteer Stealth
- Strategy #3: Use Hosted Fortified Version of Puppeteer
- Strategy #4: Fortify Puppeteer Yourself
- Strategy #5: Leverage ScrapeOps Proxy to Bypass Anti-Bots
Let's explore these strategies.
Strategy #1: Use Puppeteer-Real-Browser
Puppeteer-Real-Browser is a nice approach to emulate a genuine browser environment within Puppeteer, enhancing anonymity and preventing detection by injecting a unique fingerprint ID into each page upon browser launch. It also automates CAPTCHA checkbox clicks.
Let’s explore its functionality, starting with a demonstration of vanilla Puppeteer attempting to capture a screenshot of nopetcha.com.
Here’s the script using vanilla Puppeteer:
import puppeteer from 'puppeteer';
(async () => {
const browser = await puppeteer.launch({
headless: "new",
defaultViewport: { width: 1080, height: 720 }
});
const page = await browser.newPage();
await page.goto('https://nopecha.com/demo/cloudflare', {
waitUntil: 'domcontentloaded'
});
await page.waitForTimeout(25000);
await page.screenshot({ path: 'nopetcha-v1.png' });
await browser.close();
})()
Executing this script reveals that vanilla Puppeteer cannot bypass the Cloudflare anti-bot captchas, resulting in detection.

Now, let’s see how puppeteer-real-browser handles the same task. First, install it using this command:
npm i puppeteer-real-browser
For Linux users, ensure xvfb is installed:
sudo apt-get install xvfb
Here’s the script using Puppeteer-Real-Browser:
import { connect } from 'puppeteer-real-browser';
(async () => {
const { page } = await connect({
headless: 'auto',
fingerprint: true,
turnstile: true,
});
await page.goto('https://nopecha.com/demo/cloudflare', {
waitUntil: "domcontentloaded"
});
await page.waitForTimeout(25000);
await page.screenshot({ path: 'nopetcha-v2.png' });
await page.close();
})();
Running this script, puppeteer-real-browser adeptly resolves the CAPTCHA, seamlessly guiding us to the main page without detection.
puppeteer-real-browser is primarily focused on bypassing Cloudflare and CAPTCHAs. However, its ability to rectify several fingerprint discrepancies between headless Puppeteer and real browsers makes it a versatile tool.
In this script, setting both fingerprint and turnstile to true enhanced its effectiveness. Here’s a breakdown of its other key parameters and their functionalities:
- headless: Can be set to true, false, or auto. If set to auto, it uses the option that is stable on the operating system in use.
- args: Allows additional flags to be added when starting Chromium.
- customConfig: Adds variables when launching, such as specifying the browser path with executablePath.
- skipTarget: Uses target filter to avoid detection. You can specify allowed targets. This feature is in beta and its use is not recommended.
- fingerprint: If set to
true, injects a unique fingerprint ID into each page upon browser launch to prevent detection. Use only if necessary, as it may still cause detection. This runs the puppeteer-afp library. - turnstile: Automatically clicks on Captchas if set to true.
- connectOption: Adds variables when connecting to Chromium created with
puppeteer.connect. - fpconfig: Allows reuse of fingerprint values previously saved in the
puppeteer-afplibrary. Refer to the puppeteer-afp library documentation for details.
If you would like to deep dive into bypassing Cloudflare using Puppeteer, check our How To Bypass Cloudflare with Puppeteer guide.
Strategy #2: Use Puppeteer Stealth
Puppeteer has a substitute, developed by the open-source community to increase its extensibility with Plugins functionality.
One of its standout plugins is the puppeteer-extra-plugin-stealth, which is designed specifically to mitigate browser fingerprint disparities. With its 17 evasion modules, this plugin aims to address various fingerprinting discrepancies that can lead to bot detection.
To employ this plugin, first install puppeteer-extra along with the puppeteer-extra-plugin-stealth plugin using:
npm i puppeteer-extra puppeteer-extra-stealth-plugin
In our example script, we'll first visit this website and capture a fullPage screenshot without incorporating the Stealth Plugin.
Then, we'll repeat the process, this time using the Stealth Plugin via puppeteer-extra's use() method.
import puppeteer from 'puppeteer-extra';
import StealthPlugin from 'puppeteer-extra-plugin-stealth';
const takeScreenshot = async (url, filePath, useStealth) => {
if (useStealth) puppeteer.use(StealthPlugin());
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
await page.goto(url);
await page.screenshot({ path: filePath, fullPage: true });
await browser.close();
};
(async () => {
const url = 'https://bot.sannysoft.com';
await takeScreenshot(url, 'screenshot_without_stealth.png', false);
await takeScreenshot(url, 'screenshot_with_stealth.png', true);
})();
Upon comparing the screenshots taken with and without the Stealth Plugin, you'll observe a notable contrast. The screenshots without the plugin showcase red bars on the left side, indicating detected bot fingerprints or missing elements. Conversely, the screenshots with the Stealth Plugin demonstrate these fingerprint differences patched, as depicted on the right side.

If you would like to bypass anti-bots with ease, check our Puppeteer-Extra-Stealth Guide
Some websites may employ IP-based detection methods, monitor unusual traffic patterns, or require CAPTCHA solving. To counter these challenges, consider integrating high-quality residential proxies, such as those offered by Bright Data (formerly Luminati) or ScrapeOps, to emulate real user IP addresses.
Strategy #3: Use Hosted Fortified Version of Puppeteer
When it comes to bypassing anti-bot measures and integrating residential proxies seamlessly, leveraging a hosted and fortified version of Puppeteer can be an efficient solution. In this strategy, we'll explore how to integrate your Puppeteer scraper with BrightData's Scraping Browser, a powerful tool optimized for such purposes.
BrightData's Scraping Browser offers a robust solution for web scraping, equipped with features tailored to handle anti-bot measures and ensure seamless proxy integration. Let's delve into the steps to integrate it into your scraping workflow:
-
Sign Up for BrightData's Scraping Browser: Start by signing up for BrightData's Scraping Browser service here.
-
Obtain API Key: After signing up, obtain your API key from BrightData's dashboard.
-
Installation and Configuration: Install BrightData's SDK for Node.js using npm:
npm install @brightdata/sdk
- Initialize BrightData SDK: Initialize the SDK with your API key:
const BrightData = require('@brightdata/sdk');
const brightDataClient = new BrightData.Client('YOUR_API_KEY');
- Integrate with Puppeteer: Utilize Puppeteer along with BrightData's SDK to handle dynamic content and proxy integration seamlessly.
Here's a code example demonstrating the integration:
const puppeteer = require('puppeteer');
const BrightData = require('@brightdata/sdk');
(async () => {
// Initialize Bright Data SDK with your API key
const brightDataClient = new BrightData.Client('YOUR_API_KEY');
const browser = await puppeteer.launch({
args: [`--proxy-server=${brightDataClient.getProxyUrl()}`]
});
const page = await browser.newPage();
// Set Bright Data session using the Bright Data SDK
await page.authenticate({
username: brightDataClient.getProxyUsername(),
password: brightDataClient.getProxyPassword()
});
await page.goto('https://books.toscrape.com/');
const element = await page.$("li.col-xs-6:nth-child(2)");
await element.screenshot({ path: 'element.png' });
await browser.close();
})();
BrightData's services, including the Scraping Browser, can be costly depending on your usage and requirements. It's crucial to evaluate the cost implications and ensure that it aligns with your budget.
Strategy #4: Fortify Puppeteer Yourself
Custom fortification of Puppeteer provides the greatest control but is also the most challenging approach. This method requires addressing common fingerprint leaks and emulating human behavior.
If you decide to fortify Puppeteer yourself, you’ll need to delve deeply into bot detection mechanisms specific to Puppeteer. Tools like Bot Incolumitas and BrowserScan can help you evaluate the strength of your fortifications.
Here are some ideas to consider:
- Setting User-Agent Strings: The user-agent string is a key identifier for browsers. When running in headless mode, the default user-agent reveals the headless nature of the browser. To avoid detection, set a user-agent string that mimics a real browser:
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36');
- Modifying Navigator Properties: Browsers expose various properties like navigator.plugins and navigator.languages which can indicate a headless environment. Modify these properties to mimic a real browser:
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
});
Object.defineProperty(navigator, 'languages', {
get: () => ['en-US', 'en'],
});
});
- Enabling WebGL and Hardware Acceleration: WebGL and hardware acceleration settings can reveal a headless browser. Ensure these are enabled to mimic a real browser environment:
const browser = await puppeteer.launch({
args: [
'--enable-webgl',
'--use-gl=swiftshader'
]
});
- Overriding WebGL Vendor and Renderer: Modify the WebGL context to return values consistent with non-headless browsers:
await page.evaluateOnNewDocument(() => {
const getParameter = WebGLRenderingContext.prototype.getParameter;
WebGLRenderingContext.prototype.getParameter = function(parameter) {
if (parameter === 37445) { // UNMASKED_VENDOR_WEBGL
return 'Intel Open Source Technology Center';
}
if (parameter === 37446) { // UNMASKED_RENDERER_WEBGL
return 'Mesa DRI Intel(R) Ivybridge Mobile ';
}
return getParameter(parameter);
};
});
- Disabling WebDriver Flag: Webdriver flag is often used to detect if the browser is controlled by automation scripts like Puppeteer. Disabling this flag can help avoid detection.
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'webdriver', { get: () => false });
});
- Patching WebRTC Configuration: WebRTC configuration can reveal details about the real browser environment. Patching it helps in mimicking a real browser.
await page.evaluateOnNewDocument(() => {
const patchedRTCConfig = { iceServers: [{ urls: 'stun:stun.example.org' }] };
Object.defineProperty(window, 'RTCConfiguration', { writable: false, value: patchedRTCConfig });
});
- Handling Broken Image Dimensions: Override properties of HTMLImageElement to handle broken images correctly:
await page.evaluateOnNewDocument(() => {
const imageDescriptor = Object.getOwnPropertyDescriptor(HTMLImageElement.prototype, 'height');
Object.defineProperty(HTMLImageElement.prototype, 'height', {
...imageDescriptor,
get: function() {
if (this.complete && this.naturalHeight === 0) {
return 20; // Non-zero value
}
return imageDescriptor.get.apply(this);
},
});
});
- Modifying Retina/HiDPI Detection: Ensure the test for retina hairlines passes:
await page.evaluateOnNewDocument(() => {
const elementDescriptor = Object.getOwnPropertyDescriptor(HTMLElement.prototype, 'offsetHeight');
Object.defineProperty(HTMLDivElement.prototype, 'offsetHeight', {
...elementDescriptor,
get: function() {
if (this.id === 'modernizr') {
return 1;
}
return elementDescriptor.get.apply(this);
},
});
});
- Modifying Canvas Fingerprinting: Canvas fingerprinting is a common technique to track users. By overriding the toDataURL method, you can prevent this tracking.
await page.evaluateOnNewDocument(() => {
HTMLCanvasElement.prototype.toDataURL = () => 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAAEklEQVR42mP8/vYtDwMUMCJzAGRcB+4mB+AAAAABJRU5ErkJggg==';
});
- Faking Screen Resolution: The screen resolution can be used to detect headless browsers. Setting it to a common resolution helps avoid detection.
await page.evaluateOnNewDocument(() => {
Object.defineProperty(window.screen, 'width', { value: 1920 });
Object.defineProperty(window.screen, 'height', { value: 1080 });
});
- Faking Timezone: The browser's timezone can be a giveaway for automated scripts. Setting it to a common timezone can help avoid detection.
await page.evaluateOnNewDocument(() => {
Object.defineProperty(Intl.DateTimeFormat.prototype, 'resolvedOptions', {
value: function () {
return { timeZone: 'America/New_York' };
}
});
});
- Disabling WebRTC Leak: WebRTC can leak the real IP address even if you're using a proxy. Disabling WebRTC can prevent this.
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'mediaDevices', {
value: {
getUserMedia: () => Promise.reject(new Error('Not allowed')),
enumerateDevices: () => Promise.resolve([]),
}
});
});
- Overriding Audio Fingerprinting: AudioContext fingerprinting can be used to track users. Overriding AudioContext methods can help avoid detection.
await page.evaluateOnNewDocument(() => {
const originalGetChannelData = AudioBuffer.prototype.getChannelData;
AudioBuffer.prototype.getChannelData = function() {
const data = originalGetChannelData.apply(this, arguments);
for (let i = 0; i < data.length; i++) {
data[i] = data[i] * (1 + Math.random() * 0.0000001);
}
return data;
};
});
Strategy #5: Leverage ScrapeOps Proxy to Bypass Anti-Bots
ScrapeOps Proxy Aggregator is another proxy solution to make Puppeteer undetectable to bot detectors even complex one's like cloudflare.
-
Sign Up for ScrapeOps Proxy Aggregator: Start by signing up for ScrapeOps Proxy Aggregator and obtain your API key.
-
Installation and Configuration: Install Puppeteer and set up your scraping environment. Ensure that SSL certificate verification errors are ignored by configuring Puppeteer with
ignoreHTTPSErrors: true. -
Initialize Puppeteer with ScrapeOps Proxy: Set up Puppeteer to use ScrapeOps Proxy Aggregator by providing the proxy URL and authentication credentials.
Here's a code example demonstrating the integration:
const puppeteer = require('puppeteer');
// ScrapeOps Residential Proxy Credentials
const SCRAPEOPS_API_KEY = 'YOUR_API_KEY'; // Replace with actual API key
const PROXY_HOST = 'residential-proxy.scrapeops.io';
const PROXY_PORT = 8181;
(async () => {
const browser = await puppeteer.launch({
args: [`--proxy-server=http://${PROXY_HOST}:${PROXY_PORT}`]
});
const page = await browser.newPage();
// Authenticate with ScrapeOps Residential Proxy
await page.authenticate({
username: 'scrapeops',
password: SCRAPEOPS_API_KEY
});
// Navigate to httpbin to check the IP address
await page.goto('https://httpbin.org/ip');
const pageContent = await page.evaluate(() => document.body.innerText);
console.log(pageContent);
await browser.close();
})();
// {
// "origin": "37.111.275.77"
// }
By integrating your Puppeteer scraper with ScrapeOps Proxy Aggregator, you can streamline your scraping workflow, bypass anti-bot measures effectively, and focus on extracting valuable data without worrying about detection.
Testing Your Puppeteer Scraper
In this guide, we explored various strategies, each with its own pros and cons, aimed at making Puppeteer less detectable to bots.
But how can we determine if our efforts have improved Puppeteer's stealth capabilities against bots?
Test Against Anti-Bot Services
One approach is to test your enhanced bot against anti-bot services like Cloudflare or PerimeterX to see if it gets blocked or encounters any issues.
However, this method requires a spare IP address or a Premium Account for testing purposes. A simpler alternative is to use free websites specifically designed to evaluate the stealth capabilities of bots.
Two such websites are Incolumitas and BrowserScan. For our testing, we will use Incolumitas.
-
Incolumitas checks various aspects of the incoming request and provides valuable insights into factors that can affect the detectability of your bot.
-
As of now, it checks around 16 types of data points, including HTTPS headers, TCP/IP, TLS, Browser, Canvas, and WebGL fingerprints, and many others.
-
The best feature is its Behavioral Bot Classification test, which is a top-notch method for detecting bots.
-
Let's see how we can use this tool to measure the Behavioral Score of our Puppeteer bot. For this demo, I will use a combination of the Stealth Plugin and a small utility,
mouseHelper.js, designed to visually track and display the mouse cursor movements in headless Puppeteer.
Here is the code for this utility script:
// mouseHelper.js
export async function installMouseHelper(page) {
await page.evaluate(() => {
if (!window.__mouseHelperInstalled__) {
window.__mouseHelperInstalled__ = true;
const box = document.createElement('div');
box.style.position = 'absolute';
box.style.background = 'red';
box.style.border = '1px solid black';
box.style.borderRadius = '50%';
box.style.width = '10px';
box.style.height = '10px';
box.style.zIndex = '10000';
document.body.appendChild(box);
document.addEventListener('mousemove', event => {
box.style.left = `${event.pageX - 5}px`;
box.style.top = `${event.pageY - 5}px`;
}, true);
}
});
}
We will integrate this script with the code provided by Incolumitas, adding our Stealth Plugin and mouseHelper.js utility.
Here is the combined script:
import puppeteer from 'puppeteer-extra';
import StealthPlugin from 'puppeteer-extra-plugin-stealth';
import { installMouseHelper } from './mouseHelper.js';
puppeteer.use(StealthPlugin());
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
function randomDelay(min, max) {
return Math.floor(Math.random() * (max - min + 1) + min);
}
async function humanType(element, text) {
for (const char of text) {
await element.type(char);
await sleep(randomDelay(100, 300));
}
}
async function randomMouseMove(page) {
const width = await page.evaluate(() => window.innerWidth);
const height = await page.evaluate(() => window.innerHeight);
for (let i = 0; i < 5; i++) {
await page.mouse.move(
Math.floor(Math.random() * width),
Math.floor(Math.random() * height),
{ steps: randomDelay(5, 20) }
);
await sleep(randomDelay(200, 500));
}
}
async function randomScroll(page) {
const maxScroll = await page.evaluate(() => document.body.scrollHeight - window.innerHeight);
const scrollPosition = Math.floor(Math.random() * maxScroll);
await page.evaluate(`window.scrollTo(0, ${scrollPosition})`);
await sleep(randomDelay(500, 1500));
}
async function solveChallenge(page) {
await page.waitForSelector('#formStuff');
await randomMouseMove(page);
await randomScroll(page);
const userNameInput = await page.$('[name="userName"]');
await userNameInput.click({ clickCount: 3 });
await sleep(randomDelay(500, 1000));
await humanType(userNameInput, "bot3000");
await randomMouseMove(page);
await randomScroll(page);
const emailInput = await page.$('[name="eMail"]');
await emailInput.click({ clickCount: 3 });
await sleep(randomDelay(500, 1000));
await humanType(emailInput, "bot3000@gmail.com");
await randomMouseMove(page);
await randomScroll(page);
await page.select('[name="cookies"]', 'I want all the Cookies');
await page.click('#smolCat');
await sleep(randomDelay(500, 1000));
await page.click('#bigCat');
await sleep(randomDelay(500, 1000));
await page.click('#submit');
page.on('dialog', async dialog => {
console.log(dialog.message());
await dialog.accept();
});
await page.waitForSelector('#tableStuff tbody tr .url');
await sleep(randomDelay(1000, 2000));
await randomMouseMove(page);
await randomScroll(page);
await page.waitForSelector('#updatePrice0');
await page.click('#updatePrice0');
await page.waitForFunction('!!document.getElementById("price0").getAttribute("data-last-update")');
await page.waitForSelector('#updatePrice1');
await page.click('#updatePrice1');
await page.waitForFunction('!!document.getElementById("price1").getAttribute("data-last-update")');
let data = await page.evaluate(() => {
let results = [];
document.querySelectorAll('#tableStuff tbody tr').forEach((row) => {
results.push({
name: row.querySelector('.name').innerText,
price: row.querySelector('.price').innerText,
url: row.querySelector('.url').innerText,
});
});
return results;
});
console.log(data);
}
(async () => {
const browser = await puppeteer.launch({
headless: false,
args: ['--start-maximized'],
defaultViewport: null
});
const page = await browser.newPage();
await installMouseHelper(page);
await page.goto('https://bot.incolumitas.com/');
await solveChallenge(page);
await sleep(5000);
const new_tests = JSON.parse(await page.$eval('#new-tests', el => el.textContent));
const old_tests = JSON.parse(await page.$eval('#detection-tests', el => el.textContent));
console.log(new_tests);
console.log(old_tests);
await page.close();
await browser.close();
})();
// behavioralClassificationScore: 0.73
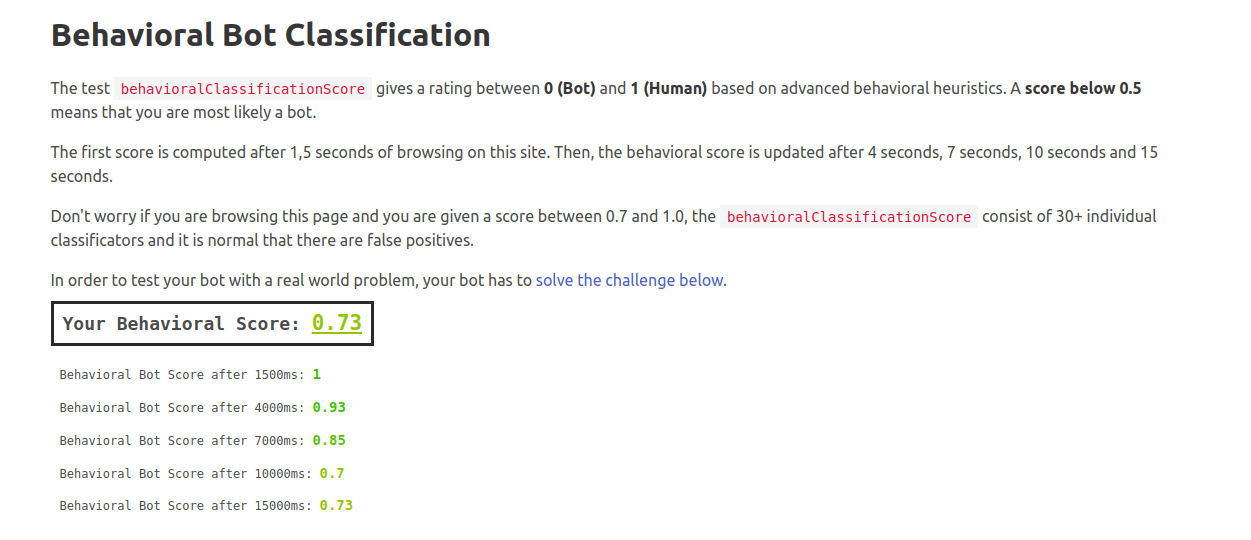
This script will solve the bot challenge in a way to mimic human behavior. In our case, our behavioralClassificationScore comes out to be 73% human, which is quite good considering the simplicity of our script.
In headless mode though, this score got reduced to 55% human, which shows that it is more difficult to maintain stealth in this mode.
Handling Errors and Captchas
The approach that you should consider when designing your bot must be to ensure that the scraper can adapt and recover from various issues like being detected and blocked. Here's a guide on how to handle these scenarios:
- Detecting CAPTCHAs: To detect if a webpage has incorporated captchas, you can look for common elements associated with captchas. For instance, Google's reCAPTCHA often includes elements with classes like g-recaptcha or iFrame elements pointing to reCAPTCHA.
Here's an example function to detect captchas:
async function detectCaptcha(page) {
// Check for the presence of common captcha elements
const captchaDetected = await page.evaluate(() => {
return document.querySelector('.g-recaptcha') ||
document.querySelector('iframe[src*="google.com/recaptcha/"]') ||
document.querySelector('iframe[src*="hcaptcha.com"]');
});
return captchaDetected;
}
if (await detectCaptcha(page)) {
// Implement solveCaptcha using 2captcha or similar
await solveCaptcha(page);
}
- Handling Errors: To handle errors, you can set up Puppeteer to catch various errors such as network timeouts, blocked requests, and unexpected responses. Common Error Handling:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(60000); // 60 seconds
try {
await page.goto('https://example.com', { waitUntil: 'networkidle2' });
} catch (error) {
console.error('Navigation error:', error);
// Handle the error, e.g., retry the navigation
}
page.on('requestfailed', request => {
console.error('Request failed:', request.url(), request.failure().errorText);
});
// Detect and handle captchas
if (await detectCaptcha(page)) {
await solveCaptcha(page);
}
// Your scraping logic here
await browser.close();
})();
- Retry Mechanism for Failed Tasks: A while loop can be used to retry failed scraping tasks:
async function scrapeWithRetries(url, retries = 3) {
let attempts = 0;
while (attempts < retries) {
try {
await page.goto(url, { waitUntil: 'networkidle2' });
// Your scraping logic here
// If successful, break out of the loop
break;
} catch (error) {
attempts++;
console.error(`Attempt ${attempts} failed:`, error);
if (attempts >= retries) {
throw new Error('Max retries reached');
}
}
}
}
await scrapeWithRetries('https://example.com');
- Logging: Implement logging to keep track of your scraping session, requests, and errors.
const fs = require('fs');
function log(message) {
fs.appendFileSync('scraper.log', `${new Date().toISOString()} - ${message}\n`);
}
page.on('request', request => {
log(`Request: ${request.url()}`);
});
page.on('requestfailed', request => {
log(`Request failed: ${request.url()} - ${request.failure().errorText}`);
});
page.on('error', error => {
log(`Page error: ${error.message}`);
});
Why Make Puppeteer Undetectable
Making Puppeteer undetectable is crucial for several reasons:
-
Automation Resistance:
-
Mechanisms to Block Automated Traffic: Many websites implement sophisticated techniques to detect and block automated traffic. These mechanisms include CAPTCHAs, IP blocking, rate limiting, and browser fingerprinting. By making Puppeteer undetectable, you can bypass these restrictions, ensuring that your automation tasks can run without interruption.
-
Access Continuity: In environments where uninterrupted access is crucial, such as for long-running data collection or interaction scripts, undetectable automation ensures that the bot doesn't get blocked mid-operation.
-
-
Data Collection
-
Restricted Access: Websites often restrict access to certain data to prevent scraping. This could be for proprietary reasons, to protect user privacy, or to control how their data is used. Making Puppeteer undetectable helps in accessing this data without triggering these restrictions.
-
Monitored Scraping: Some websites actively monitor and analyze incoming traffic for scraping patterns. By ensuring your automation is stealthy, you reduce the risk of being detected and potentially banned, allowing for more reliable data collection over time.
-
-
Testing:
-
Accurate Simulation of User Behavior: In testing scenarios, especially for web applications, it's essential to simulate real user behavior accurately. This includes load testing, user experience testing, and functional testing. Using undetectable Puppeteer ensures that the test results reflect real-world conditions without being skewed by automation detection mechanisms.
-
Avoiding Automation Flags: Some tests require validating that a web application behaves correctly under normal use conditions. Automation flags can alter the behavior of the application, leading to inaccurate test results. Undetectable Puppeteer ensures that the application treats the automated interactions as genuine, providing more accurate insights.
-
By fortifying Puppeteer against detection, you enhance the reliability and effectiveness of your automation tasks, ensuring that they can operate seamlessly and without interference.
Best Practices and Considerations
When making Puppeteer undetectable, consider the following best practices and additional considerations:
- Regular Updates: Ensure Puppeteer and its plugins are regularly updated to counter new detection methods.
- Use Reliable Proxies: Opt for high-quality residential proxies to minimize the risk of detection.
- Monitor Detection: Continuously monitor for detection signs and adapt your strategies accordingly.
- Ethical Scraping: Always adhere to legal and ethical standards when scraping websites to avoid legal repercussions.
- Load Balancing: Distribute your scraping tasks across multiple IP addresses and machines to avoid overloading any single IP.
- Respect Rate Limits: Abide by the target website’s rate limits to reduce the chances of being blocked.
Conclusion
Puppeteer is a powerful tool for web scraping and automation, but its detectability poses a significant challenge. By applying the strategies and best practices outlined in this guide, you can make Puppeteer undetectable and ensure your scraping activities remain uninterrupted.
Remember to stay updated with the latest developments in bot detection and continuously refine your methods to stay ahead of anti-bot mechanisms and check the official documentation of Puppeteer.
More Puppeteer Web Scraping Guides
If you would like to learn more about Puppeteer, check our extensive The Puppeteer Web Scraping Playbook or explore more guides to enhance your web scraping techniques with Puppeteer:
ScrapeOps Anti-Bot Bypasses
Puppeteer-Extra-Stealth Guide
How to Bypass Cloudflare