
How to Bypass PerimeterX with Puppeteer
There are all sorts of anti-bot services out there that aim to block our scrapers. The most common ones are Cloudflare, DataDome, and PerimeterX. PerimeterX, a leading provider of security solutions, offers robust protection against automated threats such as bots, scrapers, and other malicious activities.
In this article, we'll explore how Puppeteer can be utilized to bypass PerimeterX's security defenses.
- TLDR: How to Bypass PerimeterX with Puppeteer
- Understanding PerimeterX
- How PerimeterX Detects Web Scrapers and Prevents Automated Access
- How To Bypass PerimeterX
- How To Bypass PerimeterX With Puppeteer
- Case Study: Bypassing PerimeterX on Zillow
- Conclusion
- More Puppeteer Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR - How to Bypass PerimeterX with Puppeteer
There are several techniques we can use to bypass PerimeterX. Let's try to scrape Zillow which is protected by PerimeterX.
As you can see in the shot below, when we scrape using normal Puppeteer, we can easily get blocked by PerimeterX.

The provided code demonstrates a basic workflow for bypassing PerimeterX security measures using Puppeteer in conjunction with the ScrapeOps proxy service.
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
// ScrapeOps Residential Proxy Credentials
const PROXY_HOST = "residential-proxy.scrapeops.io";
const PROXY_PORT = 8181;
const PROXY_USERNAME = "scrapeops";
const PROXY_PASSWORD = "YOUR_API_KEY";
// Async function to scrape data
async function main() {
// Launch Puppeteer with Residential Proxy
const browser = await puppeteer.launch({
headless: true,
args: [`--proxy-server=${PROXY_HOST}:${PROXY_PORT}`],
});
// Open a new browser page
const page = await browser.newPage();
// Authenticate the proxy
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
// Go to Zillow using the residential proxy
await page.goto("https://www.zillow.com", { waitUntil: "load", timeout: 60000 });
// Take a screenshot
await page.screenshot({ path: "zillow-residential-proxied.png" });
// Close the browser
await browser.close();
console.log("Scraping completed, check the screenshot.");
}
// Run the function
main().catch(console.error);
- First, we imported the Puppeteer library using the
require()function. - Next, we set up ScrapeOps proxy service. This API key is crucial for utilizing ScrapeOps.
- We defined a function called
thegetScrapeOpsUrl. This function takes a regular URL and transforms it into a special "proxied" URL using the ScrapeOps service. - After, we created
main()function. Inside this function, we launched Puppeteer in headless mode, and then navigated to the webpage and took a screenshot.
You should be able to view the Zillow.com homepage.
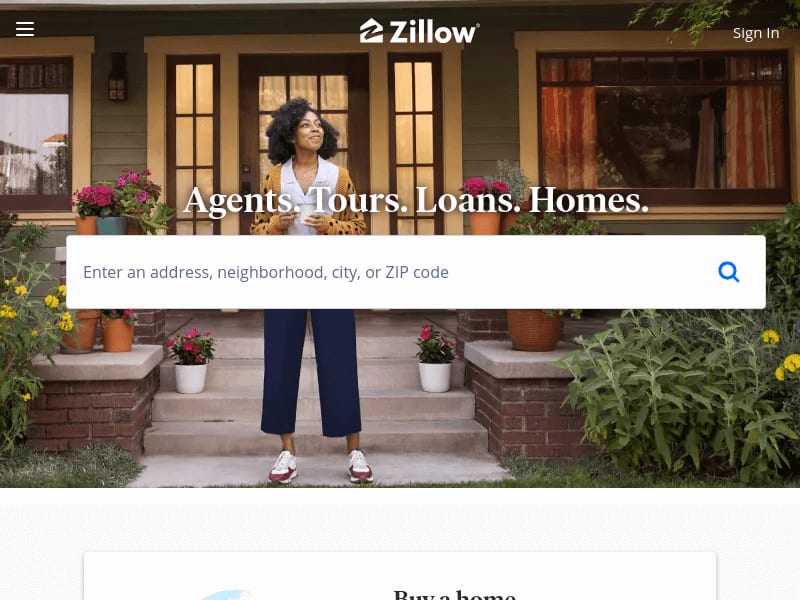
Understanding PerimeterX
PerimeterX is designed to protect websites from malicious software. PerimeterX succeeds with this by successfully recognizing and blocking automated visitors (bots and scrapers). While PerimeterX is closed source, we can assume that they employ numerous strategies to identify, quarantine, and block bot traffic.
To identify malicious activity, we can assume that PerimeterX relies on the following methods:
- Behavioral Analysis
- Fingerprinting
- CAPTCHA challenges
- IP Monitoring
- Header Analysis
- Session Tracking
- DNS Monitoring
In the next section, we'll take a more in-depth look and find out just exactly what these methods are and how they work. This way, we can hopefully come up with a working strategy to beat PerimeterX.
How Perimeterx Detects Web Scrapers and Prevents Automated Access
Anti-bot services such as PerimeterX employ a variety of server side and client side tactics in order to block bot traffic. Let's take a detailed look at the most common techniques used by services like PerimeterX.
Server Side Techniques
- Behavioral Analysis: On the server side, sites will actually track and analyze the behavior of their visitors. If a user visits 20 different pages in a minute, they're most likely a bot. If a user clicks every button on the site with no pauses between clicks, they're most likely a bot.
- IP Monitoring: PerimeterX most likely monitors the IP addresses of their visitors. If too many requests come too quickly from one location, it is a common technique to simply block that location entirely. This is a common method of protecting against DDOS attacks.
- Header Analysis: When we visit a website, our browser sends a GET request to the site's server. This HTTP request also contains headers which share small amounts of information about who we are and the information that we're seeking. Most browsers identify themselves within their headers, so it is important that our headers resemble those of a normal browser.
- DNS Monitoring: Sites will also often monitor the domains that requests are coming from. If a domain is recognized as a potentially malicious one, it will usually be blocked right away.
Client Side Techniques
- CAPTCHA Challenges: These are a 100% client side challenge. They are embedded inside the frontend and need to be solved from the frontend. Most modern anti-bot sites only employ the CAPTCHA if they suspect a bot... If your scraper receives CAPTCHAs, you should already consider your attempt to be a failure because you're already suspected of being a bot.
- Fingerprinting: In order to track our behavior, when we visit a site, our browser is given a unique fingerprint. When an action is taken (clicking a button), it can be tracked through the fingerprint of our browser. While fingerprints are left from the client side, they are analyzed by the server.
- Session Tracking: This technique goes hand in hand with fingerprinting. Many sites will place a cookie in your browser. The cookie is then tracked along with your actions on the site. This assists greatly in the behavioral analysis mentioned above. While the cookie is added on the client side, it is the server that needs to analyze the behavior.
How to Bypass PerimeterX
Because PerimeterX tracks and analyzes IP addresses, it's imperative that we use IPs that show up as either residential or mobile. This is easy if your scraper is running on your personal machine at home, but in production, scrapers often run on a schedule... from a server. They fetch the information needed to update the server and they shut off.
In a scenario like the one mentioned above, if the scraper isn't configured correctly, the website you're scraping will see that your scraper is running from a datacenter and BOOM, you get blocked.
An ideal scraper will also rotate real browser headers. We can get proper browser headers by either using a browser with a head (GUI) or we can set up fake user agents to be sent in our headers.
You're actually more likely to get detected when using a headless browser. When you run in headless mode, your scraper will most likely send that information inside of a header. This means that your automated browser is more likely to give itself away when running in headless mode.
Use Residential & Mobile IPs
As mentioned previously, the best scrapers will use either a residential or mobile IP address. We can get the best IP addresses by using proxies. The ScrapeOps Proxy Aggregator rotates through all the best proxies in the industry to get you a good IP address with every request you make. A simple Google search will also yield tons of results for VPNs that will provide you with a mobile or residtential IP address.
Rotate Real Browser Headers
If you choose to run your scraper in headless mode, you should absolutely use normal browser headers. More specifically, you should choose user agents that match the browser you're automating.
If your scraper is using Google Chrome 122.0.6261.69, your headers should reflect this information. If your scraper is using Chromium, and you're sending headers that say you're on Safari, you are more likely to get detected because PerimeterX will most likely detect that your browser looks like Chrome, but broadcasts itself as Safari... This sort of thing could definitely be perceived as a potential threat to the site.
Browser headers will often contain information about your OS as well. Depending on how stringent the header analysis is, you might even want to choose headers that match your operating system.
Use Headless Browsers With Fake User Agents or Headed Browsers
If we use a headless browser, it is imperative that we set user agents that match. If we choose to run using a browser with a head, our traffic looks much more legitimate because normal users are not going to be using headless browsers.
If we use a headless browser without a fake user agent, it will give itself away. As previously mentioned in this article, always set custom user agents when scraping with a headless browser.
How to Bypass PerimeterX with Puppeteer
PerimeterX is a very sophisticated system. here are several techniques we can use and we're going to see which ones actually work. We're going to spend the rest of this article trying to get past the screen you see above.
We're going to try the following tactics:
- Fortified Scraper
- Puppeteer Extra Stealth
- ScrapeOps Proxy Aggregator
To bypass PerimeterX in production we're going to attempt all three of the methods we just went over. In production, if you're still having difficulty, you can always combine any of these methods together.
Each of these methods takes a different approach and we'll look at them in further detail later on in this article.
Option 1: Bypass Perimeterx By Fortifying The Browser
Anti-bots can detect vanilla Puppeteer primarily through your browser headers and your actions. When using headless Puppeteer, your scraper will advertise itself as headless unless you tell it to do otherwise by setting a different user agent.
Other anti-bot challenges you'll need to overcome might be:
- CAPTCHA challenges
- JavaScript challenges (if you have a real browser, these are handled automatically)
The example below shows a fortified browser in Puppeteer:
//import puppeteer
const puppeteer = require("puppeteer");
const userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
];
const randomIndex = Math.floor(Math.random() * userAgents.length);
//async main function
async function main() {
//open a new browser
const browser = await puppeteer.launch({headless: true});
//create a new page
const page = await browser.newPage();
//set the user agent
await page.setUserAgent(userAgents[randomIndex]);
//go to the site
await page.goto("https://www.whatismybrowser.com");
//take a screenshot
await page.screenshot({path: "what-is-fortified.png"});
//close the browser
await browser.close();
}
main();
In the code above, we:
- Launch Puppeteer in headless mode,
headless: true - Before visting a page, we use
await page.setUserAgent(userAgents[randomIndex]);to set a random user agent from our list. - We then use
page.goto()to navigate to the website. await page.screenshot({path: "what-is-fortified.png"});takes a screenshot so we can view the result of our attempt.
When we run it, we receive the following screenshot:
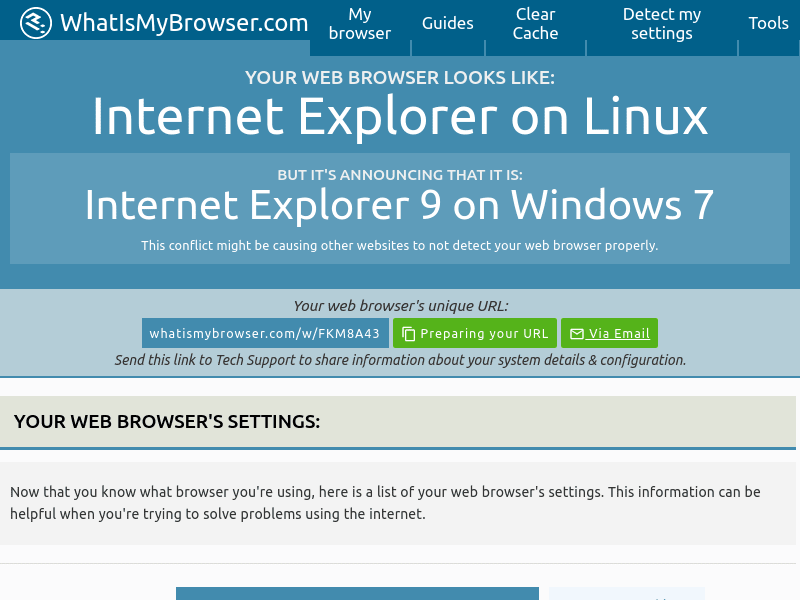
This code is meant to run from a machine using a residential IP. If you choose to use this method, it is best to run either from your personal machine at home, or to use a VPN that gives you access to a residential IP. A simple web search will yield tons of providers.
Option 2: Bypass Perimeterx Using puppeteer-extra-plugin-stealth
When using Puppeteer, we can actually use Puppeteer with the Stealth plugin to automate much of the behavior we coded in the previous example and more. The Stealth plugin makes your scraper far less likely to expose itself. While still not as strong as we can get, this method is considered to be effective.
WARNING: Most anti-bot services are actively developing software to detect the Stealth plugin. While this method still may work at the moment, it will be obsolete in the near future.
To install this plugin, run the following command:
npm install puppeteer-extra puppeteer-extra-plugin-stealth
Below is an example that uses Puppeteer with the Stealth plugin:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
//define async function to scrape the data
async function main() {
//set puppeteer to use the stealth plugin
puppeteer.use(StealthPlugin());
//launch puppeteer without a head
const browser = await puppeteer.launch({headless: true});
//open a new browser page
const page = await browser.newPage();
//go to the site
await page.goto("https://www.whatismybrowser.com");
await page.screenshot({path: "what-is-stealth.png"});
//close the browser
await browser.close();
}
main();
The example above does the following:
const puppeteer = require('puppeteer-extra');imports Puppeteer Extra.const StealthPlugin = require('puppeteer-extra-plugin-stealth');imports the Stealth plugin.puppeteer.use(StealthPlugin());sets Puppeteer to use the Stealth plugin.- We then launch a headless browser with
const browser = await puppeteer.launch({headless: true});. await page.goto()takes us to the website.- We
await page.screenshot()to take a picture of the page. - Finally, we use
await browser.close()to close the browser.
While it may not always be successful, this is never a bad method to try when attempting to access a site behind PerimeterX.
Here is our result when using Stealth:
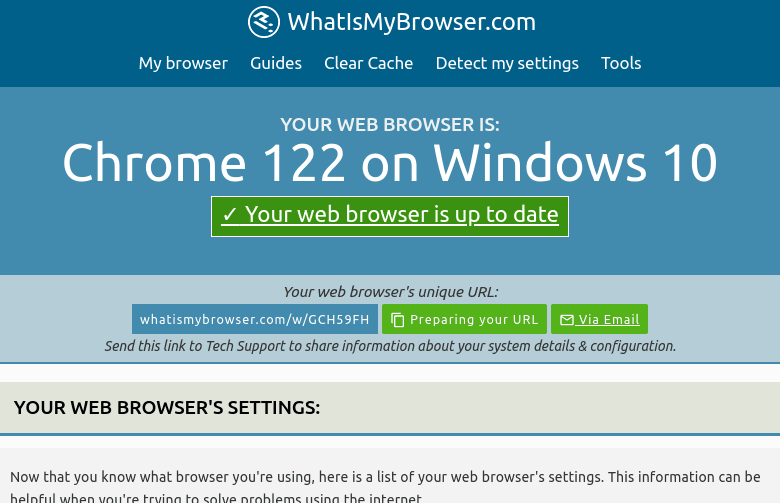
As you probably noticed in the screenshot, whatismybrowser was unable to detect any abnormalities with the browser. Stealth tends to do a far better job at covering up our browser leaks.
If you would like to learn more about this plugin, check our Puppeteer-Extra-Stealth Guide - Bypass Anti-Bots With Ease article.
Option 3: Bypass Perimeterx Using ScrapeOps Proxy Aggregator
The easiest way to bypass PerimeterX (or any anti-bot for that matter) is to use a good proxy. The ScrapeOps Proxy Aggregator rotates through all the best proxies in the industry to guaruntee that you're always using the best possible IP address.
On top of that, ScrapeOps is the one that talks to the actual website so you don't have to. With this method, the ScrapeOps API takes care of all the difficult stuff and all we need to worry about is our code.
The example below uses the ScrapeOps Proxy Aggregator:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
// ScrapeOps Residential Proxy Credentials
const PROXY_HOST = "residential-proxy.scrapeops.io";
const PROXY_PORT = 8181;
const PROXY_USERNAME = "scrapeops";
const PROXY_PASSWORD = "YOUR_API_KEY";
// Async function to scrape data
async function main() {
// Launch Puppeteer with Residential Proxy
const browser = await puppeteer.launch({
headless: true,
args: [`--proxy-server=${PROXY_HOST}:${PROXY_PORT}`],
});
// Open a new browser page
const page = await browser.newPage();
// Authenticate the proxy
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
// Go to "What Is My Browser" using the residential proxy
await page.goto("https://www.whatismybrowser.com", { waitUntil: "load", timeout: 60000 });
// Take a screenshot
await page.screenshot({ path: "what-is-residential-proxied.png" });
// Close the browser
await browser.close();
console.log("Scraping completed, check the screenshot.");
}
// Run the function
main().catch(console.error);
The example above is far more simple than the two previous examples:
const puppeteer = require("puppeteer");imports Puppeteer.getScrapeOpsUrl()takes in a regular url and converts it to a url using the ScrapeOps Proxy.const browser = await puppeteer.launch({headless: true});launches Puppeteer as normal.const page = await browser.newPage();opens a new page within the browser.await page.goto(getScrapeOpsUrl("https://www.whatismybrowser.com"));sends us to the proxied url.- We take a screenshot with
await page.screenshot({path: "what-is-proxied.png"});. - Finally, we close our browser with
await browser.close();
When using this method, we make one function and we don't have to mess with anything else. We just write our code with vanilla Puppeteer.
Here is the result from whatismybrowser
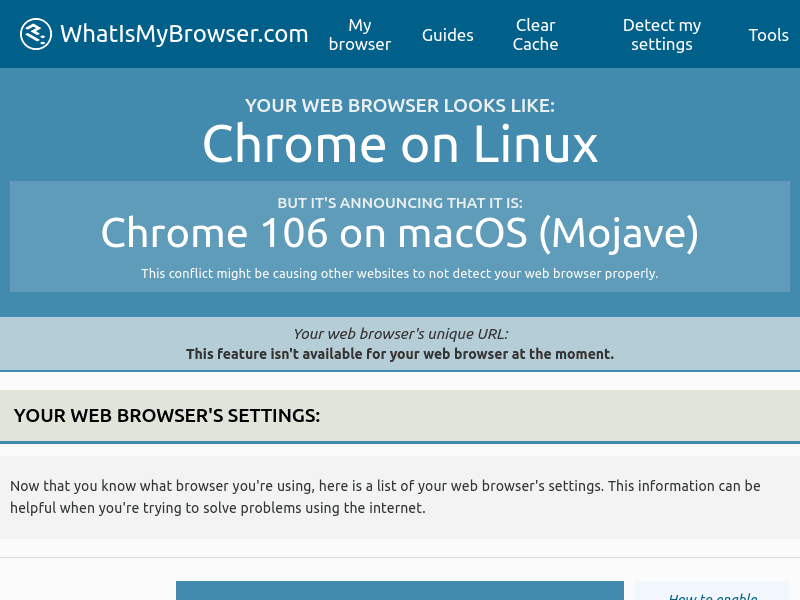
Case Study: Bypassing Perimeterx on Zillow.com
Now we come to the fun part. Zillow uses PerimeterX to protect itself from malicious activity. We're going to try scraping Zillow with all three of these methods to see which ones actually work.
Below is a shot of Zillow's front page. If any of these methods return a screenshot like this one, they will be considered successful.
This is what it looks like when you get blocked by Zillow. Any method that yields this result will be considered a failure.
Scraping Zillow.com with a Fortified Browser
While this method is most likely to fail, we took the time to code it in Option 1, so we took the time to test it out.
If you need to see the code again, here it is updated for Zillow:
//import puppeteer
const puppeteer = require("puppeteer");
const userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
];
const randomIndex = Math.floor(Math.random() * userAgents.length);
//async main function
async function main() {
//open a new browser
const browser = await puppeteer.launch({headless: true});
//create a new page
const page = await browser.newPage();
//set the user agent
await page.setUserAgent(userAgents[randomIndex]);
//go to the site
await page.goto("https://www.zillow.com");
//take a screenshot
await page.screenshot({path: "zillow-fortified.png"});
//close the browser
await browser.close();
}
main();
Here is the result:
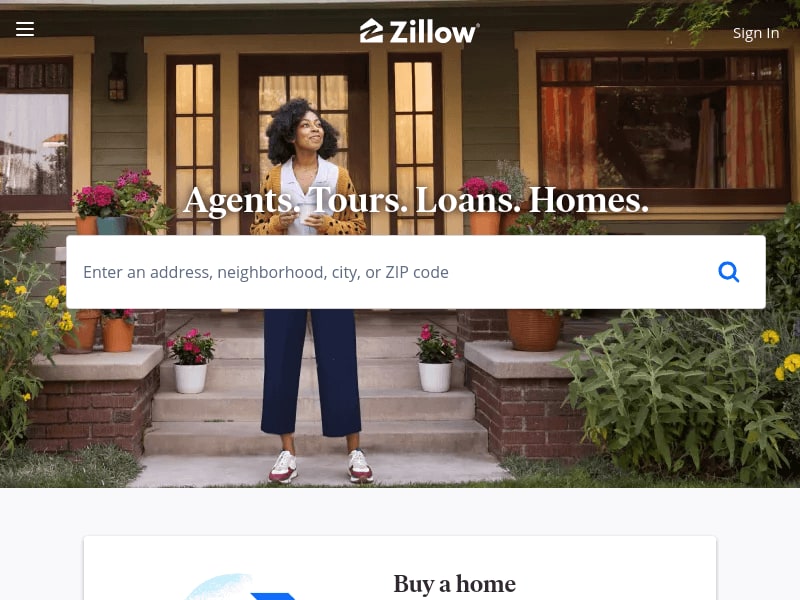
Much to our surprise, this method did succeed repeatedly in testing. Despite the repeated success, when scraping like this, it is only a matter of time before you get detected so don't be surprised when this option fails you.
Result: Success
Scraping Zillow.com With puppeteer-extra-plugin-stealth
Initially, we thought this method would most likely fail. Not only did the first method succeed, this one did too. We wrote the code in Option 2.
Here is the Stealth code, but altered for Zillow:
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
//define async function to scrape the data
async function main() {
//set puppeteer to use the stealth plugin
puppeteer.use(StealthPlugin());
//launch puppeteer without a head
const browser = await puppeteer.launch({headless: true});
//open a new browser page
const page = await browser.newPage();
//go to the site
await page.goto("https://www.zillow.com");
await page.screenshot({path: "zillow-stealth.png"});
//close the browser
await browser.close();
}
main();
Here is the resulting screenshot:

While it does prevent browser leaks, whenever an open source stealth solution is released, it is only a matter of time before it becomes obsolete. PerimeterX detected our scraper and we got blocked.
Result: Fail
Scraping Zillow.com With ScrapeOps Proxy Aggregator
Now, we'll be scraping Zillow with the ScrapeOps Proxy. We wrote this code in Option 3.
Below is a refresher on the code for the proxied example as well. As you probably guessed, it has been changed to Zillow.
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
// ScrapeOps Residential Proxy Credentials
const PROXY_HOST = "residential-proxy.scrapeops.io";
const PROXY_PORT = 8181;
const PROXY_USERNAME = "scrapeops";
const PROXY_PASSWORD = "YOUR_API_KEY";
// Async function to scrape data
async function main() {
// Launch Puppeteer with Residential Proxy
const browser = await puppeteer.launch({
headless: true,
args: [`--proxy-server=${PROXY_HOST}:${PROXY_PORT}`],
});
// Open a new browser page
const page = await browser.newPage();
// Authenticate the proxy
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
// Go to Zillow using the residential proxy
await page.goto("https://www.zillow.com", { waitUntil: "load", timeout: 60000 });
// Take a screenshot
await page.screenshot({ path: "zillow-residential-proxied-2.png" });
// Close the browser
await browser.close();
console.log("Scraping completed, check the screenshot.");
}
// Run the function
main().catch(console.error);
Here are the results:
Unsurprisingly, ScrapeOps passed the test as well.
Result: Success
Conclusion
In conclusion, PerimeterX is best bypassed by using a good proxy. Both the Fortified Browser and our Proxied Scraper were able to pass the test. It is always best practice to use a proxy and don't let the results of this case study fool you.
If you'd like to learn more about Puppeteer check the links below:
More Puppeteer Web Scraping Guides
Take a look at some of our other case studies here on ScrapeOps and you'll see that the only way to consistently make it through anti-bot software is to use a good proxy.