
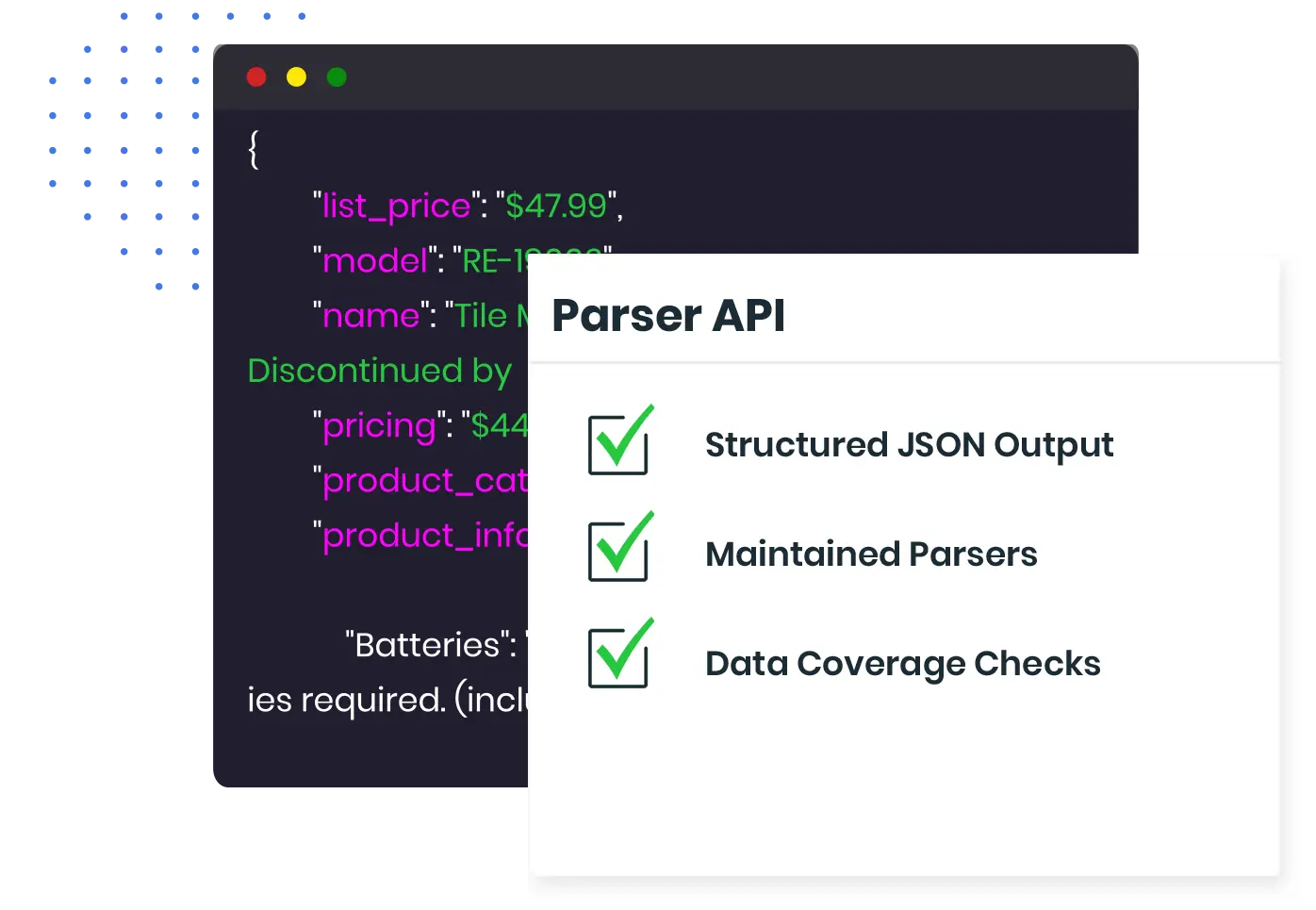
What Is The ScrapeOps Parser API?
Simply send the HTML of the page you want to extract data from to our Parser API, and we return clean data in JSON format.

1. Send HTML
Integrate the Parser API into your scraper or bot, so it sends the HTML to the Parser API endpoint.
2. Auto Data Extraction
The Parser API will automatically extract the high value data from the HTML using our maintained parsers.
3. Receive JSON Data
The Parser API will return clean data extracted from the page in JSON format
Parsers For Every Use Case
We maintain parsers for the most popular websites so you don't have to. Get the data you need without the hassle of maintaining parsers.

Amazon

Walmart

Redfin

Indeed

eBay
We are adding new parsers every week.
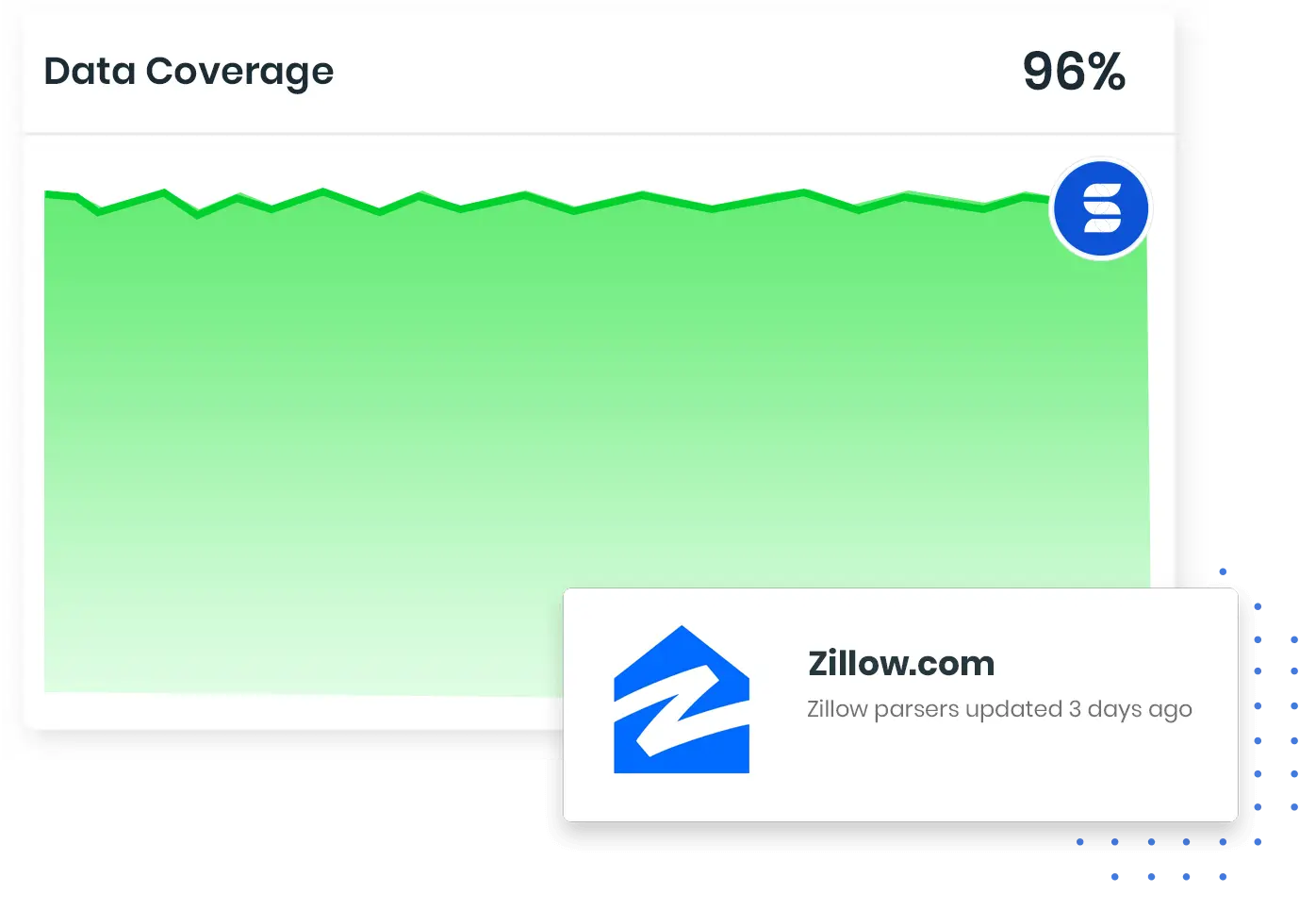
Automatic Data Coverage Monitoring
Unbeatable Data Coverage
We continuously monitor the data coverage performance of all our parsers to ensure you always get the data you need.
Never worry about page structure changes again. If a page structure changes our team will update the parsers to maintain data coverage.
Integration
Get Setup In 30 Seconds
Simply send the HTML you want to extract data from to the appropriate Parser API endpoint, and our system will automatically parse all the data from the HTML.
Easily integrate into any scraper that can make HTTP API calls.
## python example
import requests
response = requests.get('https://www.amazon.com/dp/B08WM3LMJF')
if response.status_code == 200:
html = response.text
data = {
'url': 'https://www.amazon.com/dp/B08WM3LMJF',
'html': html,
}
response = requests.post(
url='https://parser.scrapeops.io/v1/amazon',
params={'api_key': 'YOUR_API_KEY'},
json=data
)
print(response.json())
Integrate With Your Favourite Languages
Simple & Flexible Pricing
Only pay for successful parse requests and cancel your subscription anytime. Get started with 1,000 free API credits.
Need a bigger plan? Contact us here.
Frequently Asked Questions
Everything you need to know about the ScrapeOps Parser API.
The ScrapeOps Parser API is a service that converts raw HTML into clean, structured JSON data. You send HTML from pages you've scraped, and the API extracts and returns the relevant data fields in a consistent JSON format. No need to write or maintain your own parsing code.
Web scraping APIs fetch pages and return HTML (or handle proxies/anti-bot for you). The Parser API is specifically for parsing: you provide the HTML, and we extract the structured data. This means you can use any scraping method or proxy provider you prefer, then send the HTML to our Parser API for extraction.
We currently have managed parsers for Amazon, Walmart, eBay, Indeed, Redfin, and more. We're continuously adding new parsers based on user demand. Each parser is maintained by our team to ensure consistent data extraction even when page structures change.
Our team continuously monitors data coverage for all parsers. When a website updates its page structure, we update our parsers to maintain data coverage. You don't need to do anything. The Parser API continues to return consistent data without any changes on your end.
Yes! The Parser API works independently of your scraping infrastructure. Use any proxy provider, any scraping framework (Scrapy, Puppeteer, Selenium, etc.), and any programming language. Simply POST the HTML to our API endpoint and receive JSON data in response.
Each parser extracts the most relevant data fields for that page type. For example, Amazon product pages return title, price, rating, reviews, images, specifications, and more. Check our documentation for the complete schema for each supported website.
Yes! Get started with 1,000 free API credits. No credit card required. This gives you enough credits to test the Parser API with your target websites before committing to a paid plan.
Yes! If you're using our Proxy API Aggregator, you can enable Auto Extract functionality which automatically parses supported pages and returns JSON data at no extra cost. This combines fetching and parsing in a single API call.