Web Scraping Guide Part 4: Handing Failed Requests and Using Concurrency
Welcome back to the 6-Part Web Scraping Guide! In this installment, we’ll supercharge your scrapers by making them both robust and high-throughput. Real-world scraping often stumbles on intermittent network errors, server hiccups, rate limits, or simple timeouts. Here, you’ll learn how to:
- Implement retry logic to gracefully recover from failed requests and transient server errors
- Detect basic anti-bot pages and loop until genuine content is returned
- Leverage concurrency (threads in Python, worker threads or
Promise.allin Node.js) to parallelize your workload and cut overall runtime - Apply these patterns across Python Requests/BS4, Selenium, as well as Puppeteer, Playwright, and Axios/Cheerio in Node.js
Whether you’re building a small proof-of-concept or a production-grade scraper, this guide will show you how to handle failures and scale out your crawl - let’s dive in!
- Python Requests + BeautifulSoup
- Python Selenium
- Node.js Axios + Cheerio
- Node.js Puppeteer
- Node.js Playwright

Python Requests/BS4 Beginners Series Part 4: Retries & Concurrency
So far in this Python Requests/BeautifulSoup 6-Part Beginner Series, we learned how to build a basic web scraper in Part 1, get it to scrape some data from a website in Part 2, clean up the data as it was being scraped and then save the data to a file or database in Part 3.
In Part 4, we'll explore how to make our scraper more robust and scalable by handling failed requests and using concurrency.
- Understanding Scraper Performance Bottlenecks
- Retry Requests and Concurrency Importance
- Retry Logic Mechanism
- Concurrency Management
- Complete Code
- Next Steps
If you prefer to follow along with a video then check out the video tutorial version here:
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Python Requests/BeautifulSoup 6-Part Beginner Series
-
Part 1: Basic Python Requests/BeautifulSoup Scraper - We'll go over the basics of scraping with Python, and build our first Python scraper. (Part 1)
-
Part 2: Cleaning Dirty Data & Dealing With Edge Cases - Web data can be messy, unstructured, and have lots of edge cases. In this tutorial we'll make our scraper robust to these edge cases, using data classes and data cleaning pipelines. (Part 2)
-
Part 3: Storing Data in AWS S3, MySQL & Postgres DBs - There are many different ways we can store the data that we scrape from databases, CSV files to JSON format, and S3 buckets. We'll explore several different ways we can store the data and talk about their pros, and cons and in which situations you would use them. (Part 3)
-
Part 4: Managing Retries & Concurrency - Make our scraper more robust and scalable by handling failed requests and using concurrency. (Part 4)
-
Part 5: Faking User-Agents & Browser Headers - Make our scraper production ready by using fake user agents & browser headers to make our scrapers look more like real users. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Explore how to use proxies to bypass anti-bot systems by hiding your real IP address and location. (Part 6)
The code for this project is available on GitHub.
Understanding Scraper Performance Bottlenecks
In any web scraping project, the network delay acts as the initial bottleneck. Scraping requires sending numerous requests to a website and processing their responses. Even though each request and response travel over the network in mere fractions of a second, these small delays accumulate and significantly impact scraping speed when many pages are involved (say, 5,000).
Although humans visiting just a few pages wouldn't notice such minor delays, scraping tools sending hundreds or thousands of requests can face delays that stretch into hours. Furthermore, network delay is just one-factor impacting scraping speed.
The scraper does not only send and receive requests, but also parses the extracted data, identifies the relevant information, and potentially stores or processes it. While network delays may be minimal, these additional steps are CPU-intensive and can significantly slow down scraping.
Retry Requests and Concurrency Importance
When web scraping, retrying requests, and using concurrency are important for several reasons. Retrying requests helps handle temporary network glitches, server errors, rate limits, or connection timeouts, increasing the chances of a successful response.
Common status codes that indicate a retry is worth trying include:
- 429: Too many requests
- 500: Internal server error
- 502: Bad gateway
- 503: Service unavailable
- 504: Gateway timeout
Websites often implement rate limits to control traffic. Retrying with delays can help you stay within these limits and avoid getting blocked. While scraping, you might encounter pages with dynamically loaded content. This may require multiple attempts and retries at intervals to retrieve all the elements.
Now let’s talk about concurrency. When you make sequential requests to websites, you make one at a time, wait for the response, and then make the next one.
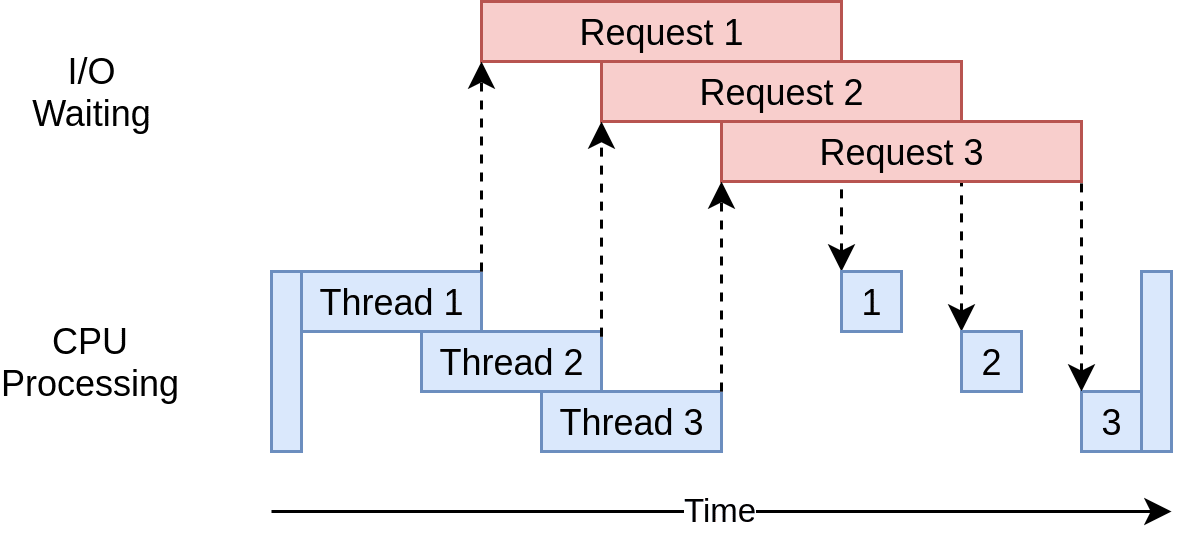
In the diagram below, the blue boxes show the time when your program is actively working, while the red boxes show when it's paused waiting for an I/O operation, such as downloading data from the website, reading data from files, or writing data to files, to complete.

Source: Real Python
However, concurrency allows your program to handle multiple open requests to websites simultaneously, significantly improving performance and efficiency, particularly for time-consuming tasks.
By concurrently sending these requests, your program overlaps the waiting times for responses, reducing the overall waiting time and getting the final results faster.
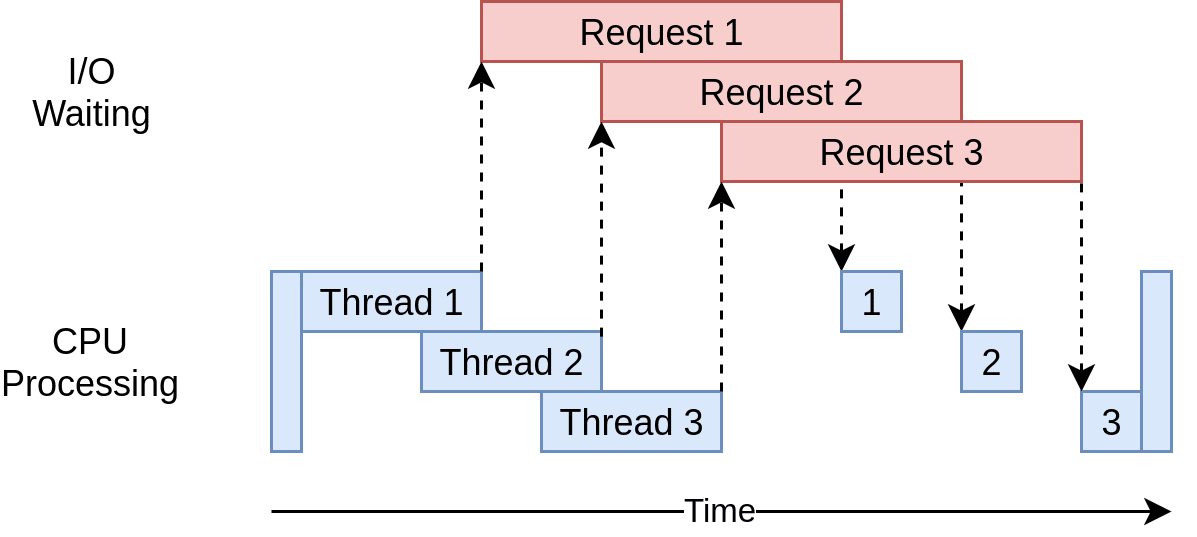
Source: Real Python
Retry Logic Mechanism
Let's examine how we'll implement retry login functionality within our scraper. Please review the start_scrape function from the previous parts of this series where we iterated through a list of URLs, made requests to them, and checked for a 200 status code.
for url in list_of_urls:
response = requests.get(url)
if response.status_code == 200:
To implement the retry mechanism, we’ll first call the make_request method defined in the RetryLogic class. Then, we'll check the returned status code.
valid, response = **retry_request.make_request(endpoint)**
if valid and response.status_code == 200:
pass
Before we delve into the make_request method, which includes the core retry logic, let's briefly examine the __init__ method to understand the variables it defines. Within __init__, two instance variables are initialized: retry_limit with a default value of 5, and anti_bot_check with a default value of False.
def __init__(self, retry_limit=5, anti_bot_check=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
The make_request method takes a URL, an HTTP method (defaulting to "GET"), and additional keyword arguments (kwargs) for configuring the request.
It sets the default value of allow_redirects to True in the kwargs dictionary. It runs a loop for the specified retry_limit times. Inside the loop, it tries to make the HTTP request using the requests.request method. If the response status code is either 200 or 404, it checks for an anti-bot check, if enabled (self.anti_bot_check == True).
def make_request(self, url, method="GET", **kwargs):
kwargs.setdefault("allow_redirects", True)
for _ in range(self.retry_limit):
try:
response = requests.request(method, url, **kwargs)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print("Error", e)
return False, None
If the anti-bot check is enabled and the status code is 200, it checks whether the anti-bot check has passed. If not, it returns False and the response. Otherwise, it returns True and the response.
If an exception occurs during the request (handled by the except block), it prints an error message. If the loop completes without a successful response, it returns False and None.
The passed_anti_bot_check method accepts a response object (presumably an HTTP response) as its argument. It determines whether an anti-bot check has been passed by searching for the specific string ("
False; otherwise, it returns True.def passed_anti_bot_check(self, response):
if "<title>Robot or human?</title>" in response.text:
return False
return True
Complete Code for the Retry Logic:
class RetryLogic:
def __init__(self, retry_limit=5, anti_bot_check=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
def make_request(self, url, method="GET", **kwargs):
kwargs.setdefault("allow_redirects", True)
for _ in range(self.retry_limit):
try:
response = requests.request(method, url, **kwargs)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print("Error", e)
return False, None
def passed_anti_bot_check(self, response):
if "<title>Robot or human?</title>" in response.text:
return False
return True
Concurrency Management
Concurrency refers to the ability to execute multiple tasks or processes concurrently. Concurrency enables efficient utilization of system resources and can often speed up program execution. Python provides several methods and modules to achieve this. One common technique to achieve concurrency is multi-threading.
As the name implies, multi-threading refers to the ability of a processor to execute multiple threads concurrently. Operating systems usually create and manage hundreds of threads, switching CPU time between them rapidly.
Switching between tasks occurs so quickly that the illusion of multitasking is created. It's important to note that the CPU controls thread switching, and developers cannot control it.
Using the concurrent.futures module in Python, you can customize the number of threads you want to create to optimize your code. ThreadPoolExecutor is a popular class within this module that enables you to easily execute tasks concurrently using threads. ThreadPoolExecutor is ideal for I/O-bound tasks, where tasks frequently involve waiting for external resources, such as reading files or downloading data.
Here’s a simple code for adding concurrency to your scraper:
def start_concurrent_scrape(num_threads=5):
while len(list_of_urls) > 0:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(scrape_page, list_of_urls)
Let’s understand the above code. The statement with concurrent.futures.ThreadPoolExecutor() creates a ThreadPoolExecutor object, which manages a pool of worker threads. The max_workers parameter of the executor is set to the provided num_threads value. The map method of the ThreadPoolExecutor is then used to apply the scrape_page function concurrently to each URL in the list_of_urls list.
Complete Code
Run the code below and see how your scraper becomes more robust and scalable by handling failed requests and using concurrency.
import os
import time
import csv
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass, field, fields, InitVar, asdict
import concurrent.futures
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price£", "")
price_string = price_string.replace("Sale priceFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
def convert_price_to_usd(self):
return self.price_gb * 1.21
def create_absolute_url(self):
if self.url == "":
return "missing"
return "https://www.chocolate.co.uk" + self.url
class ProductDataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
)
with open(
self.csv_filename, mode="a", newline="", encoding="utf-8"
) as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found: {product_data.name}. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if self.is_duplicate(product) == False:
self.storage_queue.append(product)
if (
len(self.storage_queue) >= self.storage_queue_limit
and self.csv_file_open == False
):
self.save_to_csv()
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
class RetryLogic:
def __init__(self, retry_limit=5, anti_bot_check=False):
self.retry_limit = retry_limit
self.anti_bot_check = anti_bot_check
def make_request(self, url, method="GET", **kwargs):
kwargs.setdefault("allow_redirects", True)
for _ in range(self.retry_limit):
try:
response = requests.request(method, url, **kwargs)
if response.status_code in [200, 404]:
if self.anti_bot_check and response.status_code == 200:
if self.passed_anti_bot_check == False:
return False, response
return True, response
except Exception as e:
print("Error", e)
return False, None
def passed_anti_bot_check(self, response):
# Example Anti-Bot Check
if "<title>Robot or human?</title>" in response.text:
return False
# Passed All Tests
return True
def scrape_page(url):
list_of_urls.remove(url)
valid, response = retry_request.make_request(url)
if valid and response.status_code == 200:
# Parse Data
soup = BeautifulSoup(response.content, "html.parser")
products = soup.select("product-item")
for product in products:
name = product.select("a.product-item-meta__title")[0].get_text()
price = product.select("span.price")[0].get_text()
url = product.select("div.product-item-meta a")[0]["href"]
# Add To Data Pipeline
data_pipeline.add_product({"name": name, "price": price, "url": url})
# Next Page
next_page = soup.select('a[rel="next"]')
if len(next_page) > 0:
list_of_urls.append("https://www.chocolate.co.uk" + next_page[0]["href"])
# Scraping Function
def start_concurrent_scrape(num_threads=5):
while len(list_of_urls) > 0:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(scrape_page, list_of_urls)
list_of_urls = [
"https://www.chocolate.co.uk/collections/all",
]
if __name__ == "__main__":
data_pipeline = ProductDataPipeline(csv_filename="product_data.csv")
retry_request = RetryLogic(retry_limit=3, anti_bot_check=False)
start_concurrent_scrape(num_threads=10)
data_pipeline.close_pipeline()

Python Selenium Beginners Series Part 4: Retries & Concurrency
So far in this Python Selenium 6-Part Beginner Series, you learned how to build a basic web scraper in Part 1, get it to scrape some data from a website in Part 2, clean up the data as it was being scraped, and then save the data to a file or database in Part 3.
In Part 4, you’ll learn how to make our scraper more robust and scalable by handling failed requests and using concurrency.
- Understanding Scraper Performance Bottlenecks
- Retry Requests and Concurrency Importance
- Retry Logic Mechanism
- Concurrency Management
- Next Steps
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Python Selenium 6-Part Beginner Series
-
Part 1: Basic Python Selenium Scraper - We'll go over the basics of scraping with Python, and build our first Python scraper. Part 1
-
Part 2: Cleaning Dirty Data & Dealing With Edge Cases - Web data can be messy, unstructured, and have lots of edge cases. In this tutorial we'll make our scraper robust to these edge cases, using data classes and data cleaning pipelines. Part 2
-
Part 3: Storing Data in AWS S3, MySQL & Postgres DBs - There are many different ways we can store the data that we scrape from databases, CSV files to JSON format, and S3 buckets. We'll explore several different ways we can store the data and talk about their pros, and cons and in which situations you would use them. Part 3
-
Part 4: Managing Retries & Concurrency - Make our scraper more robust and scalable by handling failed requests and using concurrency. Part 4
-
Part 5: Faking User-Agents & Browser Headers - Make our scraper production ready by using fake user agents & browser headers to make our scrapers look more like real users. (Coming Soon)
-
Part 6: Using Proxies To Avoid Getting Blocked - Explore how to use proxies to bypass anti-bot systems by hiding your real IP address and location. (Coming Soon)
Understanding Scraper Performance Bottlenecks
In any web scraping project, the network delay acts as the initial bottleneck. Scraping requires sending numerous requests to a website and processing their responses. Even though each request and response travel over the network in mere fractions of a second, these small delays accumulate and significantly impact scraping speed when many pages are involved (say, 5,000).
Although humans visiting just a few pages wouldn't notice such minor delays, scraping tools sending hundreds or thousands of requests can face delays that stretch into hours. Furthermore, network delay is just one factor impacting scraping speed.
The scraper does not only send and receive requests, but also analyses extracted data, identifies the relevant information, and potentially stores or processes it. While network delays may be minimal, these additional steps are CPU-intensive and can significantly slow down scraping.
Retry Requests and Concurrency Importance
When web scraping, retrying requests, and using concurrency are important for several reasons. Retrying requests helps handle temporary network glitches, server errors, rate limits, or connection timeouts, increasing the chances of a successful response.
Common status codes that indicate a retry is worth trying include:
- 429: Too many requests
- 500: Internal server error
- 502: Bad gateway
- 503: Service unavailable
- 504: Gateway timeout
Websites often implement rate limits to control traffic. Retrying with delays can help you stay within these limits and avoid getting blocked. While scraping, you might encounter pages with dynamically loaded content. This may require multiple attempts and retries at intervals to retrieve all the elements.
Now let’s talk about concurrency. When you make sequential requests to websites, you make one at a time, wait for the response, and then make the next one.
In the diagram below, the blue boxes show the time when your program is actively working, while the red boxes show when it's paused waiting for an I/O operation, such as downloading data from the website, reading data from files, or writing data to files, to complete.

Source: Real Python
However, concurrency allows your program to handle multiple open requests to websites simultaneously, significantly improving performance and efficiency, particularly for time-consuming tasks.
By concurrently sending these requests, your program overlaps the waiting times for responses, reducing the overall waiting time and getting the final results faster.
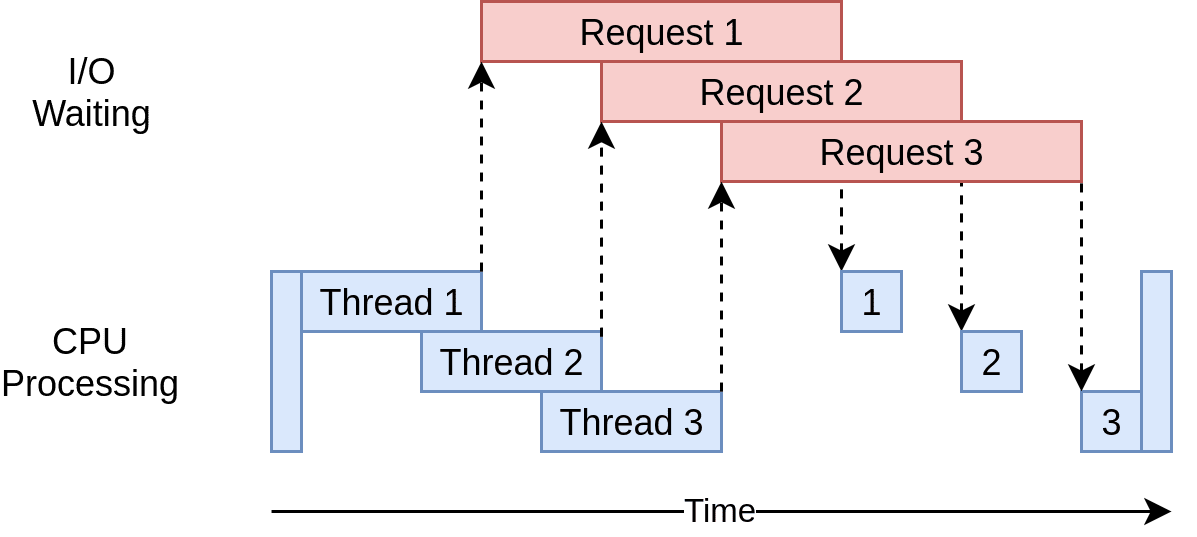
Source: Real Python
Retry Logic Mechanism
Let's see how to implement retry logic functionality within our scraper. In part 3 of this series, the start_scrape() function iterated through a list of URLs and extracted data from each. Here, we'll enhance it to make multiple attempts at retrieving data from a webpage.
To implement the retry mechanism, first define the retry limit, which is the maximum number of attempts to scrape a particular URL before giving up.
The function will enter a while loop that continues until one of three conditions is met:
- Scraping is successful.
- The maximum number of retries (retry_limit) is reached.
- An exception occurs that prevents further retries.
Inside the loop, there are several steps to perform:
- Navigate to the specified URL: Use
driver.get(url)to open the webpage in the Selenium-controlled browser. - Get the response status code (indirectly): Retrieving the response status code directly in Selenium isn't straightforward. Here's how you can achieve it:
- Retrieve the performance logs using
driver.get_log('performance'). These logs contain browser performance data, including network requests and timing information. - Pass the retrieved logs to a function called
get_status(). This function will analyze the logs to extract the HTTP response status code for the page request.
- Retrieve the performance logs using
Here's the code for the get_status() function:
def get_status(logs):
for log in logs:
if log["message"]:
d = json.loads(log["message"])
try:
content_type = (
"text/html"
in d["message"]["params"]["response"]["headers"]["content-type"]
)
response_received = d["message"]["method"] == "Network.responseReceived"
if content_type and response_received:
return d["message"]["params"]["response"]["status"]
except:
pass
Here's the code that runs the loop and extracts the response status code. You can see that we call the get_status() function, passing the performance logs as an argument.
retry_count = 0
while retry_count < retry_limit:
driver.get(url)
logs = driver.get_log("performance")
response = get_status(logs)
response_text = driver.page_source
Continuing with the code, a response code of 200 indicates a successful request to load the webpage. We then check if anti-bot checks are enabled and whether the webpage detects our scraper failing the check. If anti-bot checks are enabled and our scraper bypasses them successfully, we proceed with normal scraping. Otherwise, we need to retry the request.
if response == 200:
if anti_bot_check and not passed_anti_bot_check(response_text):
print("Anti-bot check failed. Retrying...")
continue
The passed_anti_bot_check method accepts a response text as its argument. It determines whether an anti-bot check has been passed by searching for the specific string ("") within the response text. If the string is present, the method returns False; otherwise, it returns True.
def passed_anti_bot_check(self, response):
if "<title>Robot or human?</title>" in response:
return False
return True
Once the webpage loads successfully and anti-bot checks are bypassed (if present), we proceed with scraping the products as described in the previous parts of this series. This involves finding links to the next pages of products, if available, and adding them to the list of URLs for further scraping.
Here's the complete code for the start_scrape() function:
def start_scrape(url, retry_limit=3, anti_bot_check=False):
list_of_urls.remove(url)
print(f"Scraping URL: {url}")
retry_count = 0
while retry_count < retry_limit:
try:
driver.get(url)
logs = driver.get_log("performance")
response = get_status(logs)
response_text = driver.page_source
if response == 200:
if anti_bot_check and not passed_anti_bot_check(response_text):
print("Anti-bot check failed. Retrying...")
time.sleep(2) # Add a small delay before retrying
continue
products = driver.find_elements(By.CLASS_NAME, "product-item")
for product in products:
name = product.find_element(
By.CLASS_NAME, "product-item-meta__title"
).text
price = product.find_element(By.CLASS_NAME, "price").text
url = product.find_element(
By.CLASS_NAME, "product-item-meta__title"
).get_attribute("href")
data_pipeline.add_product(
{"name": name, "price": price, "url": url}
)
try:
next_page = driver.find_element(By.CSS_SELECTOR, "a[rel='next']")
url = next_page.get_attribute("href")
list_of_urls.append(url)
except:
print("No more pages found. Exiting...")
return
return
else:
print(f"Received status code: {response.status_code}. Retrying...")
except Exception as e:
print("Error occurred:", e)
retry_count += 1
time.sleep(2) # Add a small delay before retrying
print("Failed to scrape:", url)
Concurrency Management
Concurrency refers to the ability to execute multiple tasks or processes concurrently. Concurrency enables efficient utilization of system resources and can often speed up program execution. Python provides several methods and modules to achieve this. One common technique to achieve concurrency is multi-threading.
As the name implies, multi-threading refers to the ability of a processor to execute multiple threads concurrently. Operating systems usually create and manage hundreds of threads, switching CPU time between them rapidly.
Switching between tasks occurs so quickly that the illusion of multitasking is created. It's important to note that the CPU controls thread switching, and developers cannot control it.
Using the concurrent.futures module in Python, you can customize the number of threads you want to create to optimize your code. ThreadPoolExecutor is a popular class within this module that enables you to easily execute tasks concurrently using threads. ThreadPoolExecutor is ideal for I/O-bound tasks, where tasks frequently involve waiting for external resources, such as reading files or downloading data.
Here’s a simple code for adding concurrency to your scraper:
def concurrent_scrape(list_of_urls, num_threads=5, retry_limit=3, anti_bot_check=True):
while len(list_of_urls) > 0:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(
lambda url: start_scrape(url, retry_limit, anti_bot_check), list_of_urls
)
The statement with concurrent.futures.ThreadPoolExecutor() as executor: creates a ThreadPoolExecutor object named executor that manages a pool of worker threads. The max_workers parameter is set to the provided num_threads value, controlling the maximum number of threads in the pool.
The code then uses the executor.map method to apply the start_scrape function concurrently to each URL in the list_of_urls. This means the function will be executed for multiple URLs at the same time.
Inside the map function, a lambda function takes a URL as input and calls the start_scrape function with the URL, retry_limit, and anti_bot_check as arguments.
The loop continues iterating until all URLs in the list_of_urls have been processed.
Complete Code
Run the code below and see how your scraper becomes more robust and scalable by handling failed requests and using concurrency.
import os
import time
import csv
import json
from dataclasses import dataclass, field, fields, InitVar, asdict
import concurrent.futures
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
# Define dataclass for Product
@dataclass
class Product:
name: str = ""
price_string: InitVar[str] = ""
price_gb: float = field(init=False)
price_usd: float = field(init=False)
url: str = ""
def __post_init__(self, price_string):
self.name = self.clean_name()
self.price_gb = self.clean_price(price_string)
self.price_usd = self.convert_price_to_usd()
self.url = self.create_absolute_url()
# Clean product name
def clean_name(self):
if self.name == "":
return "missing"
return self.name.strip()
# Clean price string and convert to float
def clean_price(self, price_string):
price_string = price_string.strip()
price_string = price_string.replace("Sale price\n£", "")
price_string = price_string.replace("Sale price\nFrom £", "")
if price_string == "":
return 0.0
return float(price_string)
# Convert price from GBP to USD
def convert_price_to_usd(self):
return round(self.price_gb * 1.21, 2)
# Create absolute URL
def create_absolute_url(self):
if self.url == "":
return "missing"
return self.url
# Class for managing product data pipeline
class ProductDataPipeline:
def __init__(self, csv_filename="", storage_queue_limit=5):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.csv_filename = csv_filename
self.csv_file_open = False
# Save product data to CSV
def save_to_csv(self):
self.csv_file_open = True
products_to_save = []
products_to_save.extend(self.storage_queue)
self.storage_queue.clear()
if not products_to_save:
return
keys = [field.name for field in fields(products_to_save[0])]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(
self.csv_filename) > 0
)
with open(
self.csv_filename, mode="a", newline="", encoding="utf-8"
) as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for product in products_to_save:
writer.writerow(asdict(product))
self.csv_file_open = False
# Clean raw product data
def clean_raw_product(self, scraped_data):
return Product(
name=scraped_data.get("name", ""),
price_string=scraped_data.get("price", ""),
url=scraped_data.get("url", ""),
)
# Check for duplicate products
def is_duplicate(self, product_data):
if product_data.name in self.names_seen:
print(f"Duplicate item found. Item dropped.")
return True
self.names_seen.append(product_data.name)
return False
# Add product to storage queue
def add_product(self, scraped_data):
product = self.clean_raw_product(scraped_data)
if not self.is_duplicate(product):
self.storage_queue.append(product)
if (
len(self.storage_queue) >= self.storage_queue_limit
and self.csv_file_open == False
):
self.save_to_csv()
# Close pipeline and save remaining data to CSV
def close_pipeline(self):
if self.csv_file_open:
time.sleep(3)
if len(self.storage_queue) > 0:
self.save_to_csv()
# Start scraping a URL
def start_scrape(url, retry_limit=3, anti_bot_check=False):
list_of_urls.remove(url)
print(f"Scraping URL: {url}")
retry_count = 0
while retry_count < retry_limit:
try:
driver.get(url)
logs = driver.get_log('performance')
response = get_status(logs)
response_text = driver.page_source
if response == 200:
if anti_bot_check and not passed_anti_bot_check(response_text):
print("Anti-bot check failed. Retrying...")
time.sleep(2) # Add a small delay before retrying
continue
products = driver.find_elements(By.CLASS_NAME, "product-item")
for product in products:
name = product.find_element(
By.CLASS_NAME, "product-item-meta__title").text
price = product.find_element(By.CLASS_NAME, "price").text
url = product.find_element(
By.CLASS_NAME, "product-item-meta__title").get_attribute("href")
data_pipeline.add_product(
{"name": name, "price": price, "url": url})
try:
next_page = driver.find_element(
By.CSS_SELECTOR, "a[rel='next']")
url = next_page.get_attribute("href")
list_of_urls.append(url)
except:
print("No more pages found. Exiting...")
return
return
else:
print(f"Received status code: {
response.status_code}. Retrying...")
except Exception as e:
print("Error occurred:", e)
retry_count += 1
time.sleep(2) # Add a small delay before retrying
print("Failed to scrape:", url)
# Get status code from performance logs
def get_status(logs):
for log in logs:
if log['message']:
d = json.loads(log['message'])
try:
content_type = 'text/html' in d['message']['params']['response']['headers']['content-type']
response_received = d['message']['method'] == 'Network.responseReceived'
if content_type and response_received:
return d['message']['params']['response']['status']
except:
pass
# Check if anti-bot check passed
def passed_anti_bot_check(response):
if "<title>Robot or human?</title>" in response:
return False
return True
# Scrape URLs concurrently
def concurrent_scrape(list_of_urls, num_threads=5, retry_limit=3, anti_bot_check=True):
while len(list_of_urls) > 0:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(lambda url: start_scrape(
url, retry_limit, anti_bot_check), list_of_urls)
# Main execution
if __name__ == "__main__":
chrome_options = webdriver.ChromeOptions()
service = Service(ChromeDriverManager().install())
chrome_options.set_capability('goog:loggingPrefs', {'performance': 'ALL'})
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(service=service, options=chrome_options)
data_pipeline = ProductDataPipeline(csv_filename="product_data.csv")
list_of_urls = [
"https://www.chocolate.co.uk/collections/all",
]
concurrent_scrape(list_of_urls, num_threads=5)
data_pipeline.close_pipeline()
driver.quit()
The final result is:


Node.js Axios/CheerioJS Beginners Series Part 4: Retries and Concurrency
In Part 1 and Part 2 of this Node.js Axios/CheerioJS Beginners Series, we learned how to build a basic web scraper and extract data from websites, as well as how to clean the scraped data. Then in Part 3 we learned how to save the data in a variety of ways.
In Part 4, we'll explore how to make our scraper more robust and scalable by handling failed requests and using concurrency.
- Understanding Scraper Performance Bottlenecks
- Retry Requests and Concurrency Importance
- Retry Logic Mechanism
- Concurrency Management
- Complete Code
- Next Steps
Node.js Cheerio 6-Part Beginner Series
This 6-part Node.js Axios/CheerioJS Beginner Series will walk you through building a web scraping project from scratch, covering everything from creating the scraper to deployment and scheduling.
- Part 1: Basic Node.js Cheerio Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
- Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
- Part 3: Storing Scraped Data - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
- Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (This article)
- Part 5: Mimicking User Behavior - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
- Part 6: Avoiding Detection with Proxies - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
The code for this project is available on Github.
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Understanding Scraper Performance Bottlenecks
In any web scraping project, the network delay acts as the initial bottleneck. Scraping requires sending numerous requests to a website and processing their responses.
Even though each request and response travel over the network in mere fractions of a second, these small delays accumulate and significantly impact scraping speed when many pages are involved (say, 5,000).
Although humans visiting just a few pages wouldn't notice such minor delays, scraping tools sending hundreds or thousands of requests can face delays that stretch into hours. Furthermore, network delay is just one-factor impacting scraping speed.
The scraper does not only send and receive requests, but also parses the extracted data, identifies the relevant information, and potentially stores or processes it. While network delays may be minimal, these additional steps are CPU-intensive and can significantly slow down scraping.
Retry Requests and Concurrency Importance
When web scraping, retrying requests, and using concurrency are important for several reasons. Retrying requests helps handle temporary network glitches, server errors, rate limits, or connection timeouts, increasing the chances of a successful response.
Common status codes that indicate a retry is worth trying include:
- 429: Too many requests
- 500: Internal server error
- 502: Bad gateway
- 503: Service unavailable
- 504: Gateway timeout
Websites often implement rate limits to control traffic. Retrying with delays can help you stay within these limits and avoid getting blocked. While scraping, you might encounter pages with dynamically loaded content. This may require multiple attempts and retries at intervals to retrieve all the elements.
Now let’s talk about concurrency. When you make sequential requests to websites, you make one at a time, wait for the response, and then make the next one.
In the diagram below, the blue boxes show the time when your program is actively working, while the red boxes show when it's paused waiting for an I/O operation, such as downloading data from the website, reading data from files, or writing data to files, to complete.

Source: Real Python
However, concurrency allows your program to handle multiple open requests to websites simultaneously, significantly improving performance and efficiency, particularly for time-consuming tasks.
By concurrently sending these requests, your program overlaps the waiting times for responses, reducing the overall waiting time and getting the final results faster.
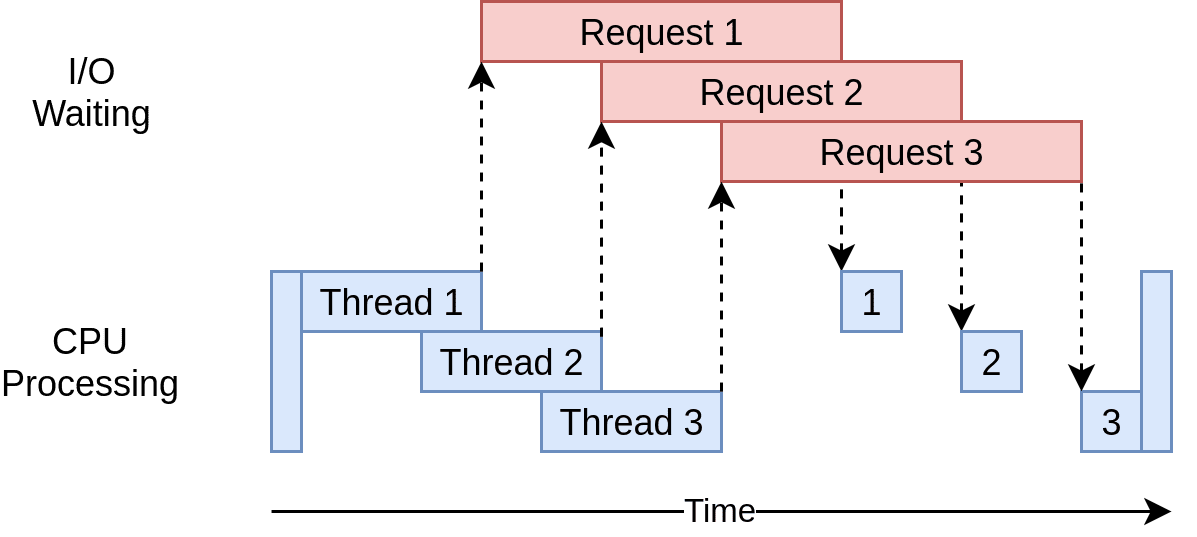 Source: Real Python
Source: Real Python
Retry Logic Mechanism
Let's examine how we'll implement retry login functionality within our scraper. Please review the scrape function from the previous parts of this series where we iterated through a list of URLs, made requests to them, and checked for a 200 status code.
for (const url of listOfUrls) {
const response = await axios.get(url);
if (response.status == 200) {
// ...
}
}
To implement the retry mechanism, we’ll first call a new makeRequest method. Then, we'll check that that a response was actually returned
const response = await makeRequest(url, 3, false);
if (!response) {
throw new Error(`Failed to fetch ${url}`);
}
The makeRequest method takes an argument for URL, number of retries, and whether or not to check for a bot response. This method then loops for the number of retries. If the request succeeds within that number, the response is returned. Otherwise we continue trying until we are out of retries and then return null.
async function makeRequest(url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await axios.get(url);
if ([200, 404].includes(response.status)) {
if (antiBotCheck && response.status == 200) {
if (response.data.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
If the anti-bot check is set to true and a valid status code is returned, the code performs some rudimentary checks to make sure the returned page is not a page for bots. With that, our method is completely ready to handle retry requests and bot checks.
Concurrency Management
Concurrency refers to the ability to execute multiple tasks or processes concurrently. Concurrency enables efficient utilization of system resources and can often speed up program execution.
In NodeJS, concurrency looks a bit different from traditional multi-threaded or multi-process concurrency due to its single-threaded event-driven architecture.
Node.js operates on a single thread, using non-blocking I/O calls, allowing it to support tens of thousands of concurrent connections without incurring the cost of thread context switching.
However, for CPU-intensive tasks, NodeJS provides the worker_threads module. This module enables the use of threads that execute JavaScript in parallel. To avoid race conditions and make thread-safe calls, data is passed between threads using MessageChannel.
A popular alternative for concurrency in NodeJS is the cluster module that allows you to create multiple child processes to take advantage of multi-core systems. We will use worker_threads in this guide because it is more suited to the work.
Here is what our entrypoint code looks like to now support worker_threads:
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url },
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
// Perform work
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
const { nextUrl, products } = await scrape(workUrl);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
This may look complicated compared to threading in languages like Python, but it is simple to understand.
- We first have to use
isMainThreadto determine if the code is being executed in the main thread or a worker thread. - If it is the main thread, we perform the logic to start worker threads. We create a promise for each worker thread so that we can wait for them to finish from our main thread.
- We assign a URL from the
listOfUrlsto each worker as astartUrl. Then we set up some event listeners. - The worker threads will use the
messageevent to send back products it found, so we add them to the pipeline then. If the worker thread has an error, we just call our promise reject. - Lastly when the worker thread exits successfully, we call out promise resolve.
- Once we've created all these workers and added them to an array, we wait for all promises in the array to to complete.
- If the code is running in a worker thread instead, we grab the
startUrlfromworkerDatathen we define ahandleWorkfunction so we can use async/await and recursion. - The
handleWorkfunction scrapes the url and posts all products found to theMessageChannel(parentPort). - Afterwards, if another page URL was found, we recursively scrape it as well to repeat the same process.
Complete Code
With all that work done, our scraper has become more scalable and robust. It is now better equipped to handle errors and perform concurrent requests.
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
const {
Worker,
isMainThread,
parentPort,
workerData,
} = require("worker_threads");
class Product {
constructor(name, priceStr, url) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
if (name == " " || name == "" || name == null) {
return "missing";
}
return name.trim();
}
cleanPrice(priceStr) {
priceStr = priceStr.trim();
priceStr = priceStr.replace("Sale price£", "");
priceStr = priceStr.replace("Sale priceFrom £", "");
if (priceStr == "") {
return 0.0;
}
return parseFloat(priceStr);
}
convertPriceToUsd(priceGb) {
return priceGb * 1.29;
}
createAbsoluteUrl(url) {
if (url == "" || url == null) {
return "missing";
}
return "https://www.chocolate.co.uk" + url;
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 100));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function makeRequest(url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await axios.get(url);
if ([200, 404].includes(response.status)) {
if (antiBotCheck && response.status == 200) {
if (response.data.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
async function scrape(url) {
const response = await makeRequest(url, 3, false);
if (!response) {
throw new Error(`Failed to fetch ${url}`);
}
const html = response.data;
const $ = cheerio.load(html);
const productItems = $("product-item");
const products = [];
for (const productItem of productItems) {
const title = $(productItem).find(".product-item-meta__title").text();
const price = $(productItem).find(".price").first().text();
const url = $(productItem).find(".product-item-meta__title").attr("href");
products.push({ name: title, price: price, url: url });
}
const nextPage = $("a[rel='next']").attr("href");
return {
nextUrl: nextPage ? "https://www.chocolate.co.uk" + nextPage : null,
products: products,
};
}
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.csv", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url },
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
// Perform work
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
const { nextUrl, products } = await scrape(workUrl);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}

NodeJS Puppeteer Beginners Series Part 4 - Managing Retries & Concurrency
So far in this Node.js Puppeteer 6-Part Beginner Series, we learned how to build a basic web scraper in Part 1, get it to scrape some data from a website in Part 2, clean up the data as it was being scraped and then save the data to a file or database in Part 3.
In this tutorial, we will dive into strategies for optimizing your web scraping process by implementing retry logic and concurrency. These techniques will make your scraper more robust and efficient, especially when dealing with large datasets.
- Understanding Scraper Performance Bottlenecks
- Retry Requests and Concurrency Importance
- Retry Logic Mechanism
- Concurrency Management
- Complete Code
- Next Steps
Node.js Puppeteer 6-Part Beginner Series
-
Part 1: Basic Node.js Puppeteer Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using NpdeJS Puppeteer. (Part 1)
-
Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
-
Part 3: Storing Scraped Data in AWS S3, MySQL & Postgres DBs - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
-
Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. (This article)
-
Part 5: Faking User-Agents & Browser Headers - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Understanding Scraper Performance Bottlenecks
In web scraping projects, network delays are often the main bottleneck. Scraping requires sending multiple requests to a website and handling their responses. While each request and response only takes a fraction of a second, these delays add up, significantly slowing down the process, especially when scraping a large number of pages (e.g., 5,000 pages).
While human users visiting a few pages wouldn't notice such minor delays, scraping tools sending hundreds or thousands of requests can face delays that stretch into hours. Additionally, network delay is just one factor affecting scraping speed.
The scraper must not only send and receive requests but also parse the extracted data, identify relevant information, and store or process it. These additional steps are CPU-intensive and can significantly slow down scraping.
Retry Requests and Concurrency Importance
When web scraping, retrying requests and using concurrency are crucial for several reasons. Retrying requests helps handle temporary network glitches, server errors, rate limits, or connection timeouts, increasing the chances of a successful response.
Common Status Codes Indicating Retry:
- 429: Too many requests
- 500: Internal server error
- 502: Bad gateway
- 503: Service unavailable
- 504: Gateway timeout
Websites often implement rate limits to control traffic. Retrying with delays can help you stay within these limits and avoid getting blocked. Additionally, pages with dynamically loaded content may require multiple attempts and retries at intervals to retrieve all elements.
Now let’s talk about concurrency. When making sequential requests, you make one request at a time, wait for the response, and then make the next one. This approach is inefficient for scraping large datasets because it involves a lot of waiting.
In the diagram below, the blue boxes show the time when your program is actively working, while the red boxes show when it's paused waiting for an I/O operation, such as downloading data from the website, reading data from files, or writing data to files, to complete.
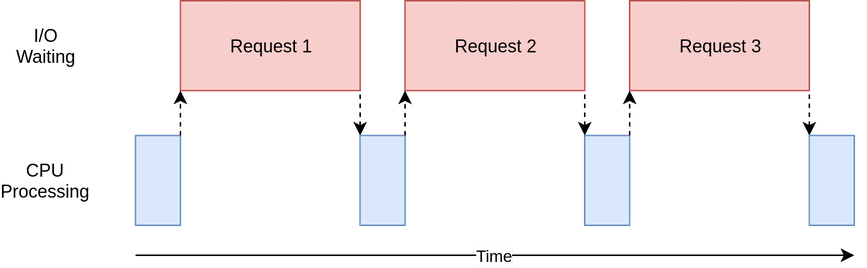
Source: Real Python
Concurrency allows your program to handle multiple open requests to websites simultaneously, significantly improving performance and efficiency, particularly for time-consuming tasks.
By concurrently sending these requests, your program overlaps the waiting times for responses, reducing the overall waiting time and getting the final results faster.
Source: Real Python
Retry Logic Mechanism
Let's examine how we'll implement retry logic within our scraper. This involves modifying the startScrape function to include retry logic for handling failed requests.
Implementing Retry Logic
We will first create a retryRequest function that attempts to make the HTTP request multiple times.
The RetryLogic Class
The RetryLogic class will handle the retry functionality. Here’s an overview of how it works:
- Initialization: The constructor initializes instance variables like
retryLimitandantiBotCheck. - Making Requests: The
makeRequestmethod attempts to make the HTTP request up toretryLimittimes. - Anti-Bot Check: If enabled, checks for anti-bot mechanisms in the response.
Initialization
class RetryLogic {
constructor(retryLimit = 5, antiBotCheck = false) {
this.retryLimit = retryLimit;
this.antiBotCheck = antiBotCheck;
}
}
Making Requests
async makeRequest(page, url) {
for (let i = 0; i < this.retryLimit; i++) {
try {
const response = await page.goto(url, { waitUntil: 'networkidle2' });
const status = response.status();
if (status === 200 || status === 404) {
if (this.antiBotCheck && status === 200 && !this.passedAntiBotCheck(page)) {
return { success: false, response };
}
return { success: true, response };
}
} catch (error) {
console.error(`Attempt ${i + 1} failed: ${error}`);
}
}
return { success: false, response: null };
}
Anti-Bot Check
async passedAntiBotCheck(page) {
const content = await page.content();
return !content.includes('<title>Robot or human?</title>');
}
Complete Code for the Retry Logic
class RetryLogic {
constructor(retryLimit = 5, antiBotCheck = false) {
this.retryLimit = retryLimit;
this.antiBotCheck = antiBotCheck;
}
async makeRequest(page, url) {
for (let i = 0; i < this.retryLimit; i++) {
try {
const response = await page.goto(url, { waitUntil: 'networkidle2' });
const status = response.status();
if (status === 200 || status === 404) {
if (this.antiBotCheck && status === 200 && !await this.passedAntiBotCheck(page)) {
return { success: false, response };
}
return { success: true, response };
}
} catch (error) {
console.error(`Attempt ${i + 1} failed: ${error}`);
}
}
return { success: false, response: null };
}
async passedAntiBotCheck(page) {
const content = await page.content();
return !content.includes('<title>Robot or human?</title>');
}
}
Concurrency Management
Concurrency refers to the ability to execute multiple tasks or processes concurrently. Concurrency enables efficient utilization of system resources and can significantly speed up program execution. Node.js provides several methods and modules to achieve concurrency, such as multi-threading.
Multi-threading refers to the ability of a processor to execute multiple threads concurrently. Using the Promise.all method in Node.js, you can handle multiple asynchronous operations concurrently.
Here’s a simple code snippet to add concurrency to your scraper:
async function startConcurrentScrape(urls, numThreads = 5) {
while (urls.length > 0) {
const tasks = [];
for (let i = 0; i < numThreads && urls.length > 0; i++) {
const url = urls.shift();
tasks.push(scrapePage(url));
}
await Promise.all(tasks);
}
}
- The
startConcurrentScrapefunction processes the URLs concurrently. - It creates an array of promises (
tasks) for scraping pages and usesPromise.allto wait for all of them to complete before moving to the next batch of URLs.
Complete Code
Here's the complete code for implementing retry logic and concurrency in your Puppeteer scraper:
const puppeteer = require('puppeteer');
const fs = require('fs');
class RetryLogic {
constructor(retryLimit = 5, antiBotCheck = false) {
this.retryLimit = retryLimit;
this.antiBotCheck = antiBotCheck;
}
async makeRequest(page, url) {
for (let i = 0; i < this.retryLimit; i++) {
try {
const response = await page.goto(url, { waitUntil: 'networkidle2' });
const status = response.status();
if (status === 200 || status === 404) {
if (this.antiBotCheck && status === 200 && !await this.passedAntiBotCheck(page)) {
return { success: false, response };
}
return { success: true, response };
}
} catch (error) {
console.error(`Attempt ${i + 1} failed: ${error}`);
}
}
return { success: false, response: null };
}
async passedAntiBotCheck(page) {
const content = await page.content();
return !content.includes('<title>Robot or human?</title>');
}
}
async function scrapePage(url) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const retryLogic = new RetryLogic(3, true);
const { success, response } = await retryLogic.makeRequest(page, url);
if (success) {
const data = await extractData(page);
await saveData(data);
}
await browser.close();
}
async function extractData(page) {
return await page.evaluate(() => {
const items = document.querySelectorAll('.product-item');
return Array.from(items).map(item => ({
name: item.querySelector('.product-item-meta__title').innerText.trim(),
price: item.querySelector('.price').innerText.trim().replace(/[^0-9\.]+/g, ''),
url: item.querySelector('.product-item-meta a').getAttribute('href')
}));
});
}
async function saveData(data) {
fs.appendFileSync('data.json', JSON.stringify(data, null, 2));
}
async function startConcurrentScrape(urls, numThreads = 5) {
while (urls.length > 0) {
const tasks = [];
for (let i = 0;
i < numThreads && urls.length > 0; i++) {
const url = urls.shift();
tasks.push(scrapePage(url));
}
await Promise.all(tasks);
}
}
const urls = [
'https://www.chocolate.co.uk/collections/all'
];
startConcurrentScrape(urls, 10);

Node.js Playwright Beginners Series Part 4: Retries and Concurrency
So far in this Node.js Playwright Beginner Series, we learned how to build a basic web scraper in Part 1, get it to scrape some data from a website in Part 2, clean up the data as it was being scraped and then save the data to a file or database in Part 3.
In the Part 4 of our Node.js Playwright Beginner Series, we’ll focus on making our scraper more robust, scalable, and faster.
Let’s dive into it!
- Understanding Scraper Performance Bottlenecks
- Retry Requests and Concurrency Importance
- Retry Logic Mechanism
- Concurrency Management
- Complete Code
- Next Steps
Node.js Playwright 6-Part Beginner Series
-
Part 1: Basic Node.js Playwright Scraper - We'll learn the fundamentals of web scraping with Node.js and build your first scraper using Cheerio. (Part 1)
-
Part 2: Cleaning Unruly Data & Handling Edge Cases - Web data can be messy and unpredictable. In this part, we'll create a robust scraper using data structures and cleaning techniques to handle these challenges. (Part 2)
-
Part 3: Storing Scraped Data in AWS S3, MySQL & Postgres DBs - Explore various options for storing your scraped data, including databases like MySQL or Postgres, cloud storage like AWS S3, and file formats like CSV and JSON. We'll discuss their pros, cons, and suitable use cases. (Part 3)
-
Part 4: Managing Retries & Concurrency - Enhance your scraper's reliability and scalability by handling failed requests and utilizing concurrency. Part 4
-
Part 5: Faking User-Agents & Browser Headers - Learn how to create a production-ready scraper by simulating real users through user-agent and browser header manipulation. (Part 5)
-
Part 6: Using Proxies To Avoid Getting Blocked - Discover how to use proxies to bypass anti-bot systems by disguising your real IP address and location. (Part 6)
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
Understanding Scraper Performance Bottlenecks
In web scraping projects, network delays are a primary bottleneck. While each request and response only takes a fraction of a second, these delays accumulate when scraping large numbers of pages (e.g., 5,000), leading to significant slowdowns.
Though humans may not notice delays on a few pages, scraping tools handling thousands of requests can experience delays stretching into hours.
In addition to network delays, other factors like parsing the data, identifying relevant information, and storing or processing it also impact performance. These CPU-intensive tasks can further slow down the overall scraping process.
Retry Requests and Concurrency Importance
The retry mechanism in web scraping helps tackle several common problems, ensuring the scraper doesn't break or miss out on data due to temporary issues.
Here are some key problems it can solve:
- Network Issues:
- Timeouts (Error Code: ETIMEDOUT): The server takes too long to respond, which can happen due to network congestion or server overload. Retrying gives the server another chance to respond.
- Connection Resets (Error Code: ECONNRESET): The connection drops unexpectedly. A retry can reestablish the connection and continue scraping without data loss.
- Server-Side Errors:
- 500 Internal Server Error: Indicates that the server encountered a problem. Retrying after a short delay can help if the issue is temporary.
- 502 Bad Gateway: This error suggests a problem with the server's upstream or proxy. Retrying might allow you to connect after the issue clears up.
- 503 Service Unavailable: Often means the server is overloaded or undergoing maintenance. Retrying after a delay can give the server time to recover.
- 504 Gateway Timeout: This happens when the server is taking too long to respond, but it might work on retry.
- Client-Side Errors:
- 408 Request Timeout: The request took too long to complete. A retry gives you a chance to succeed without adjusting the timeout manually.
- 429 Too Many Requests: Indicates that you've hit the rate limit. Retrying with some delay gives you a chance to stay within limits while still scraping data.
Websites often use rate limits to manage traffic, and introducing delays between requests can help you stay within those limits and avoid being blocked. When scraping, you may come across pages with dynamically loaded content. In such cases, multiple attempts with timed retries might be needed to capture all the elements correctly.
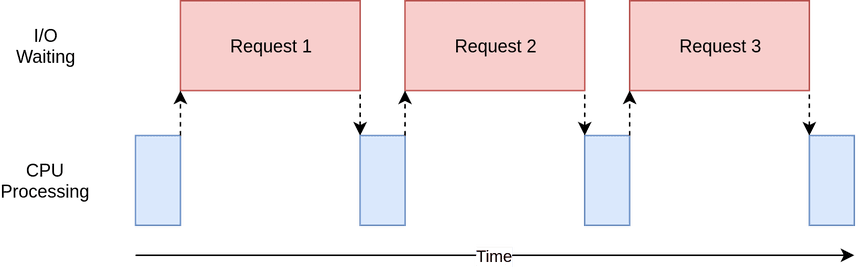
Without concurrency, a scraper sends one request at a time, waits for the response, and then sends the next one. This leads to unnecessary idle time when the scraper is just waiting for a server response.
Here’s how sequential execution looks:
Source - RealPython
In the sequential execution model:
- Active Time (Blue boxes): This is when your scraper is actively processing data or sending requests.
- Waiting Time (Red boxes): This is when your scraper is paused, waiting for responses or I/O operations, such as downloading data or saving files.
With concurrency, your scraper sends multiple requests at the same time. Instead of waiting for each request to complete before starting the next, your program overlaps the waiting periods, significantly reducing overall runtime.

Source - RealPython
In the concurrent execution model:
- Active Time (Blue boxes): Multiple requests are processed simultaneously, maximizing the use of available resources.
- Waiting Time (Red boxes): Overlapped waiting periods for different requests reduce overall downtime, making the process more efficient.
By handling multiple open requests simultaneously, concurrency makes your scraper more efficient, especially when dealing with time-consuming tasks like I/O operations (network requests, reading/writing files). This leads to faster scraping and better performance, even with high-volume data extraction.
Retry Logic Mechanism
Let's refine our scraper to include retry functionality. Previously, our scraper looped through URLs and made requests without checking the response status:
for (const url of listOfUrls) {
const response = await page.goto(url);
// Further processing...
}
We’ll enhance this by adding a retry mechanism. We’ll create a makeRequest() method to handle retries and confirm a valid response.
Here’s the updated approach:
const response = await makeRequest(url, 3, false);
if (!response) {
throw new Error(`Failed to fetch ${url}`);
}
The makeRequest() method takes three parameters:
- the URL,
- the number of retries, and
- an optional flag to check for bot detection.
It attempts to load the URL multiple times based on the retry count.
- If the request is successful within the allowed attempts, it returns the response.
- Otherwise, it retries until the limit is reached, and then returns
null.
Here’s how it works:
async function makeRequest(page, url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
console.log({ url })
const response = await page.goto(url);
const status = response.status();
if ([200, 404].includes(status)) {
if (antiBotCheck && status == 200) {
const content = await page.content();
if (content.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
Concurrency Management
Concurrency is the ability to execute multiple tasks simultaneously, making efficient use of system resources and often speeding up execution. In Node.js, concurrency differs from traditional multi-threaded or multi-process approaches due to its single-threaded, event-driven architecture.
Node.js runs on a single thread, leveraging non-blocking I/O calls. This design allows it to handle thousands of concurrent connections efficiently without the overhead of thread context switching.
For CPU-intensive tasks, Node.js provides the worker_threads module, which allows parallel execution of JavaScript using threads. To manage data safely between threads and avoid race conditions, Node.js uses MessageChannel for communication.
An alternative for concurrency in Node.js is the cluster module, which creates multiple child processes to utilize multi-core systems. For this guide, we'll focus on worker_threads as it's better suited for our needs.
Here’s how we adapt our entry point code to support worker_threads:
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.json", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url }
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
const { nextUrl, products } = await scrape(workUrl);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
- We used
isMainThreadto determine if the code is running in the main thread or a worker thread. - For each URL, a worker thread is created and associated with a Promise.
- Workers send found products back to the pipeline. Errors are handled by rejecting the
Promise, and successful exits resolve thePromise. - Then, we wait for all worker Promises to complete and then close the pipeline.
- The
handleWorkfunction recursively scrapes URLs and sends products back to the main thread usingparentPort. - If additional URLs are found, they are recursively processed.
This approach may seem complex compared to threading in languages like Python, but it's straightforward once you grasp the concepts.
Complete Code
With all these improvements, our scraper is now more scalable and robust. It’s better at handling errors and can efficiently manage concurrent requests. Here is the complete code:
const { chromium } = require('playwright');
const fs = require('fs');
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
class Product {
constructor(name, priceStr, url, conversionRate = 1.32) {
this.name = this.cleanName(name);
this.priceGb = this.cleanPrice(priceStr);
this.priceUsd = this.convertPriceToUsd(this.priceGb, conversionRate);
this.url = this.createAbsoluteUrl(url);
}
cleanName(name) {
return name?.trim() || "missing";
}
cleanPrice(priceStr) {
if (!priceStr?.trim()) {
return 0.0;
}
const cleanedPrice = priceStr
.replace(/Sale priceFrom £|Sale price£/g, "")
.trim();
return cleanedPrice ? parseFloat(cleanedPrice) : 0.0;
}
convertPriceToUsd(priceGb, conversionRate) {
return priceGb * conversionRate;
}
createAbsoluteUrl(url) {
return (url?.trim()) ? `https://www.chocolate.co.uk${url.trim()}` : "missing";
}
}
class ProductDataPipeline {
constructor(csvFilename = "", storageQueueLimit = 5) {
this.seenProducts = new Set();
this.storageQueue = [];
this.csvFilename = csvFilename;
this.csvFileOpen = false;
this.storageQueueLimit = storageQueueLimit;
}
saveToCsv() {
this.csvFileOpen = true;
const fileExists = fs.existsSync(this.csvFilename);
const file = fs.createWriteStream(this.csvFilename, { flags: "a" });
if (!fileExists) {
file.write("name,priceGb,priceUsd,url\n");
}
for (const product of this.storageQueue) {
file.write(
`${product.name},${product.priceGb},${product.priceUsd},${product.url}\n`
);
}
file.end();
this.storageQueue = [];
this.csvFileOpen = false;
}
cleanRawProduct(rawProduct) {
return new Product(rawProduct.name, rawProduct.price, rawProduct.url);
}
isDuplicateProduct(product) {
if (!this.seenProducts.has(product.url)) {
this.seenProducts.add(product.url);
return false;
}
return true;
}
addProduct(rawProduct) {
const product = this.cleanRawProduct(rawProduct);
if (!this.isDuplicateProduct(product)) {
this.storageQueue.push(product);
if (
this.storageQueue.length >= this.storageQueueLimit &&
!this.csvFileOpen
) {
this.saveToCsv();
}
}
}
async close() {
while (this.csvFileOpen) {
// Wait for the file to be written
await new Promise((resolve) => setTimeout(resolve, 1000));
}
if (this.storageQueue.length > 0) {
this.saveToCsv();
}
}
}
const listOfUrls = ["https://www.chocolate.co.uk/collections/all"];
async function makeRequest(page, url, retries = 3, antiBotCheck = false) {
for (let i = 0; i < retries; i++) {
try {
const response = await page.goto(url);
const status = response.status();
if ([200, 404].includes(status)) {
if (antiBotCheck && status == 200) {
const content = await page.content();
if (content.includes("<title>Robot or human?</title>")) {
return null;
}
}
return response;
}
} catch (e) {
console.log(`Failed to fetch ${url}, retrying...`);
}
}
return null;
}
async function scrape(url) {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage();
const response = await makeRequest(page, url);
if (!response) {
await browser.close();
return { nextUrl: null, products: [] };
}
const productItems = await page.$$eval("product-item", items =>
items.map(item => {
const titleElement = item.querySelector(".product-item-meta__title");
const priceElement = item.querySelector(".price");
return {
name: titleElement ? titleElement.textContent.trim() : null,
price: priceElement ? priceElement.textContent.trim() : null,
url: titleElement ? titleElement.getAttribute("href") : null
};
})
);
const nextUrl = await nextPage(page);
await browser.close();
return {
nextUrl: nextUrl,
products: productItems.filter(item => item.name && item.price && item.url)
};
}
async function nextPage(page) {
let nextUrl = null;
try {
nextUrl = await page.$eval("a.pagination__nav-item:nth-child(4)", item => item.href);
} catch (error) {
console.log('Last Page Reached');
}
return nextUrl;
}
if (isMainThread) {
const pipeline = new ProductDataPipeline("chocolate.json", 5);
const workers = [];
for (const url of listOfUrls) {
workers.push(
new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: { startUrl: url }
});
console.log("Worker created", worker.threadId, url);
worker.on("message", (product) => {
pipeline.addProduct(product);
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
} else {
console.log("Worker exited");
resolve();
}
});
})
);
}
Promise.all(workers)
.then(() => pipeline.close())
.then(() => console.log("Pipeline closed"));
} else {
const { startUrl } = workerData;
const handleWork = async (workUrl) => {
const { nextUrl, products } = await scrape(workUrl);
for (const product of products) {
parentPort.postMessage(product);
}
if (nextUrl) {
console.log("Worker working on", nextUrl);
await handleWork(nextUrl);
}
};
handleWork(startUrl).then(() => console.log("Worker finished"));
}
// Worker created 1 https://www.chocolate.co.uk/collections/all
// Worker working on https://www.chocolate.co.uk/collections/all?page=2
// Worker working on https://www.chocolate.co.uk/collections/all?page=3
// Last Page Reached
// Worker finished
// Worker exited
// Pipeline closed
Next Steps
We hope you now have a good understanding of why you need to retry requests and use concurrency when web scraping. This includes how the retry logic works, how to check for anti-bots, and how the concurrency management works.
If you would like the code from this example please check out on Github here or on The Node.js Web Scraping Playbook repo!
The next tutorial covers how to make our spider production-ready by managing our user agents and IPs to avoid getting blocked. (Part 5)