
Something's breaking in web scraping.
Success rates are slipping. Costs are spiralling. Teams are struggling to keep up.
The proxies are cheaper. The infrastructure is more sophisticated.
But the math no longer works.
Proxies that once cost $30 per GB now go for $1.
Yet the cost of a successful scrape, one clean, validated payload, has doubled or tripled or 10X.
Web scraping hasn't gotten harder because of access.
It's gotten harder because of economics.
Retries, JS rendering, and anti-bot bypasses now consume more budget than bandwidth.
Every website is still technically scrapable, but fewer make financial sense to scrape at scale.
The barrier isn't access anymore. It's affordability.
This is Scraping Shock, the moment cheap access collides with expensive success.
In this article, we will dive deep into the most important trend affecting web scraping today:
- The Illusion of Progress
- The Anti-Bot Escalation Curve
- Scraping Shock Defined
- The Scraping Squeeze
- Efficiency as the New Competitive Edge
- The Repricing of the Open Web
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: How Scraping Shock Is Reshaping Web Scraping Economics
Web scraping is no longer a technical problem, it’s an economic one.
Proxies are cheaper. Infrastructure is better. But the cost of a successful scrape, one clean, validated payload, has exploded.
As anti-bot system usage has grown 10X in the last 5 years. Scraping costs can spike 5X, 10X, even 20X overnight when a site tightens its defenses.
That’s Scraping Shock, the moment when scraping stops making financial sense.
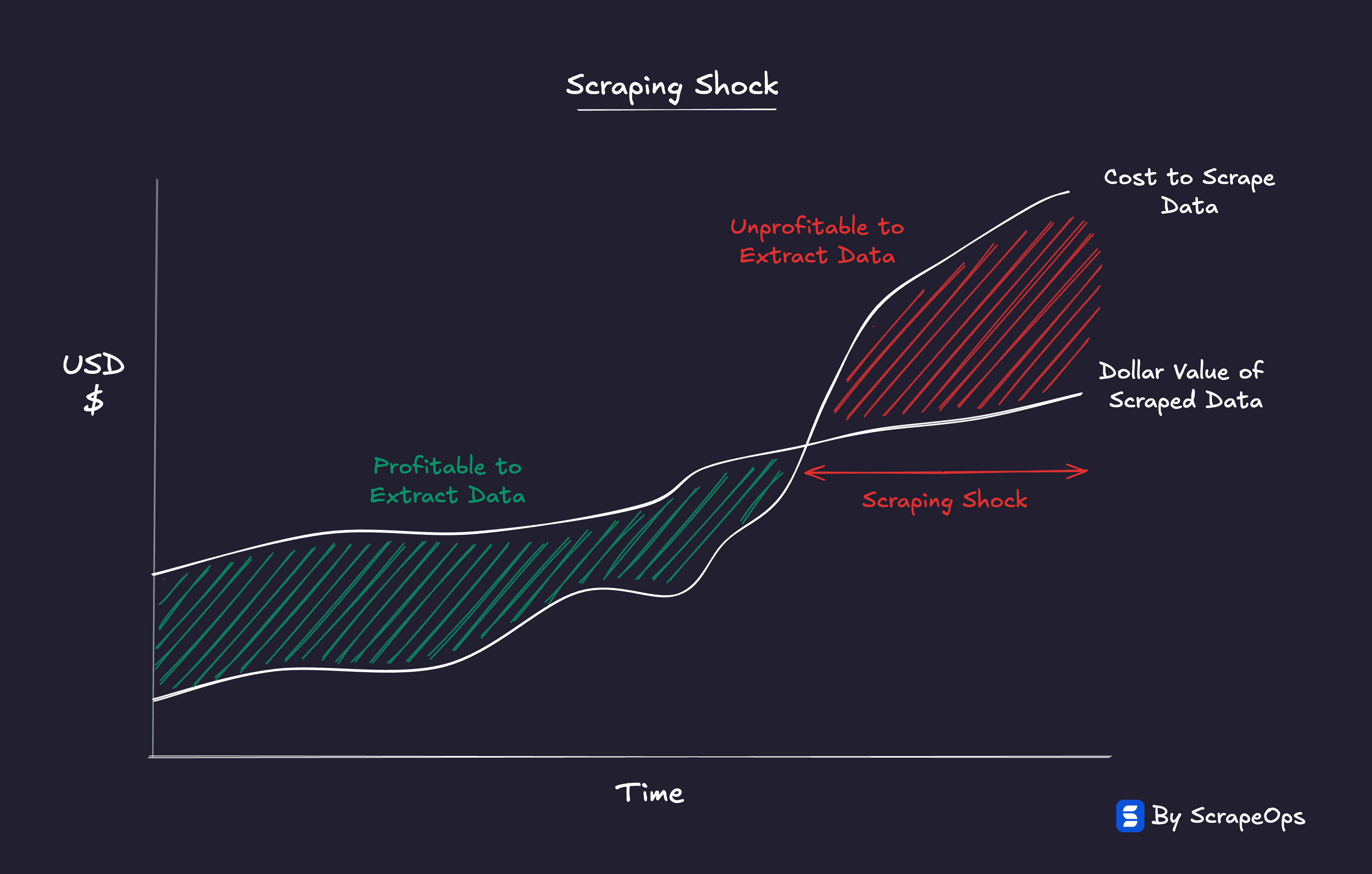
Every dataset now has a price tag, a point where the cost of extraction outweighs the value of the data itself.
The bottleneck has shifted from getting data to getting it profitably.
In this new market reality:
-
Websites are spending more to defend their data.
-
Scrapers are spending more to access it.
-
And the web is quietly repricing itself — discovering what data is truly worth.
The future of scraping won’t be defined by who can scrape the most, but by who can scrape most efficiently.
The new moat isn’t scale or speed, it’s cost-per-success-per-domain.
“The web isn’t closing, it’s repricing.
And in that new reality, efficiency isn’t just an advantage, it’s survival.”
The Illusion of Progress

Over the past decade, the web scraping stack has evolved beyond recognition.
Proxies that once dropped connections or returned 403s are now engineered platforms. Resilient, feature-rich, and globally distributed.
Modern "smart proxies" handle rotation, retries, fingerprint spoofing, CAPTCHA solving, headless rendering, and precise geo-targeting out of the box.
Open-source libraries like Puppeteer Stealth, Playwright Stealth, and Selenium undetected-chromedriver have baked advanced evasion directly into developer workflows.
Giving every developer access to scraping tooling that was once reserved for the most experienced scraping teams. A simple API call away.
It's never been easier to start scraping.
That's the illusion.
Yes, the infrastructure is more powerful.
But the easier these tools became to use, the faster websites evolved to stop them.
Browser fingerprints, TLS signatures, mouse telemetry, and behavioral tracking turned simple GET requests into multi-stage challenges.
As proxy sophistication increased, anti-bot systems responded in kind.
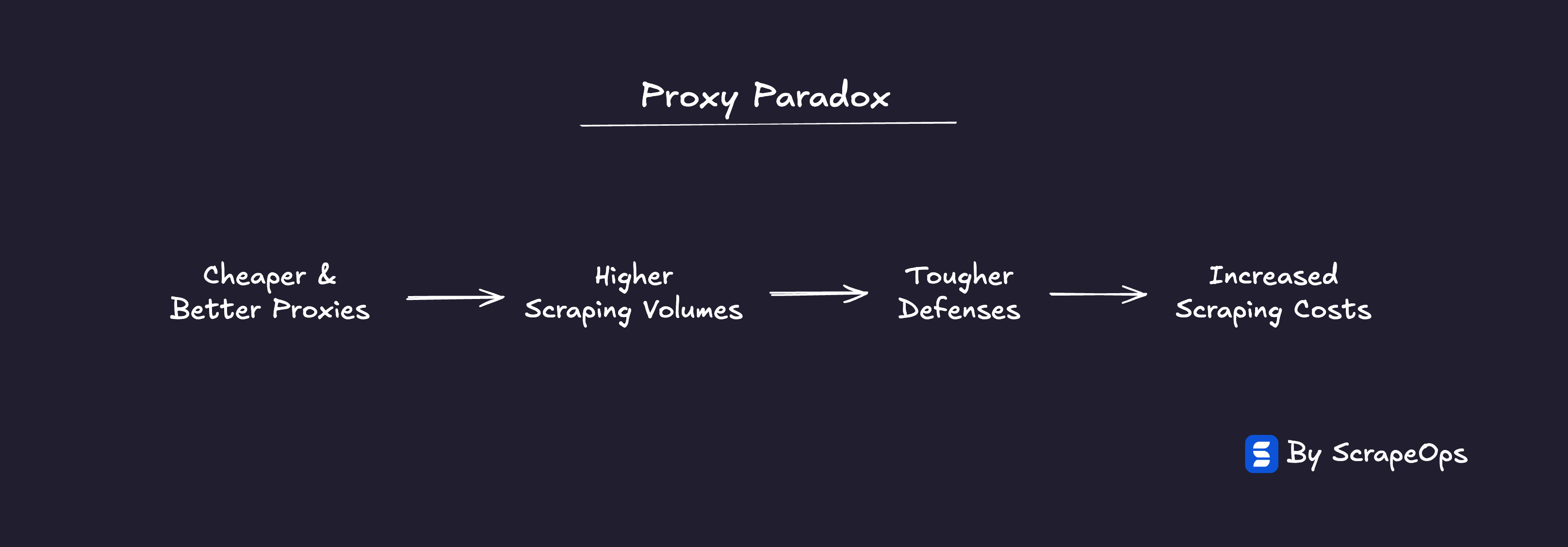
The result is a feedback loop that keeps tightening:
Cheaper proxies → More scrapers → Stronger defenses → Higher costs
This is the Proxy Paradox, the phenomenon where cheaper proxies make successful scraping more expensive.
(Read more → The Proxy Paradox: Why Cheaper Proxies Are Making Web Scraping More Expensive)
Across the industry, ScrapeOps data shows this paradox in motion.
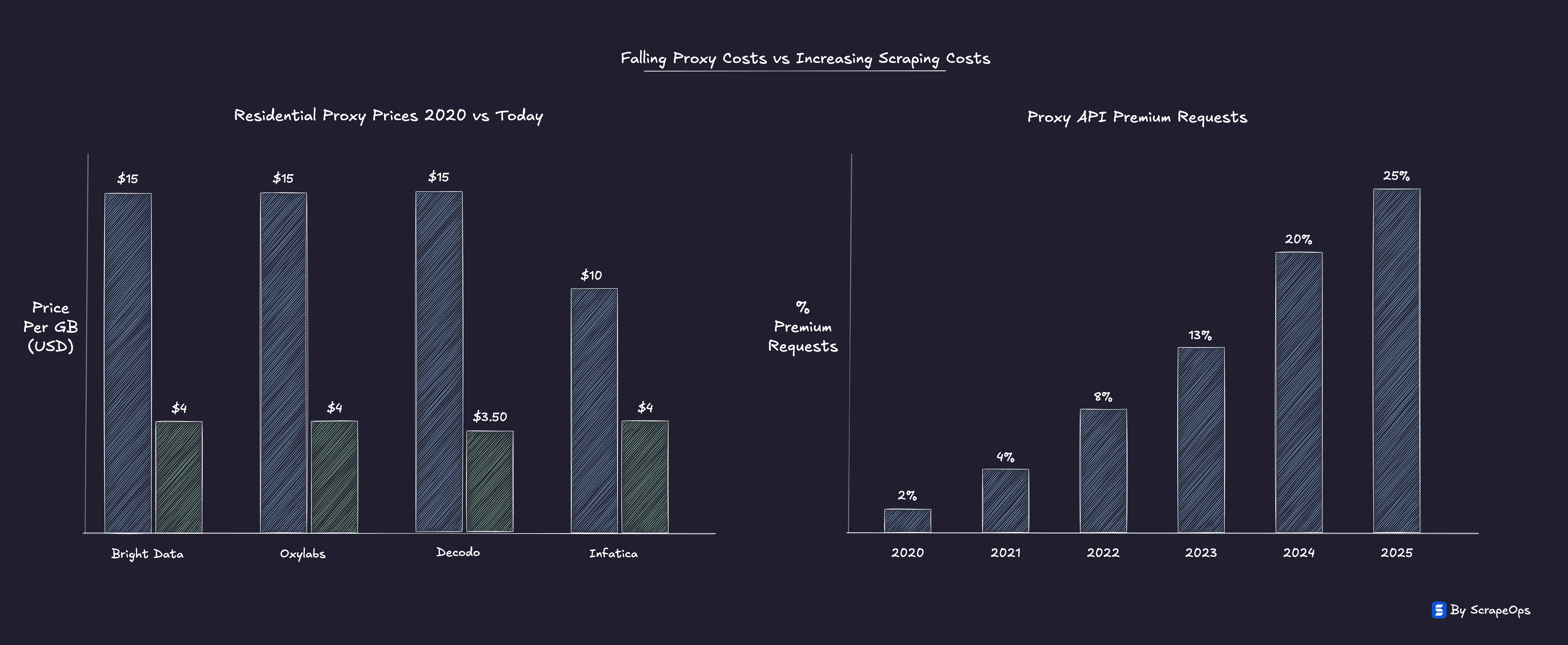
Proxy prices are down by as much as 70-80% since 2018, yet the share of requests requiring residential IPs, rendering, or anti-bot bypasses has climbed from 2% to nearly 25%.
Five years ago, 9 of the top 10 e-commerce sites could be scraped with simple datacenter proxies.
Today, less than half can.
The same pattern repeats across social media, travel, and real estate.
| Category | Scrapable With DC Proxies (2020) | Scrapable With DC Proxies Today |
|---|---|---|
| E-Commerce | 9/10 | 4/10 |
| Social Media | 4/5 | 0/5 |
| Travel | 8/10 | 3/10 |
| Real-Estate | 10/10 | 3/10 |
While the cost of underlying proxies keeps falling, everything wrapped around them: retries, fingerprint spoofing, browser rendering, and post-processing; keeps inflating.
The total cost of a successful payload is rising, even as the cost per gigabyte falls.
That's the illusion of progress:
Scraping has never been easier to start, but it's never been harder to scale economically.
The hidden truth is that technical progress has turned scraping from a skill problem into an economic problem, and that's what's driving Scraping Shock.
The Anti-Bot Escalation Curve

Scraping costs don't rise gradually.
They jump, violently.
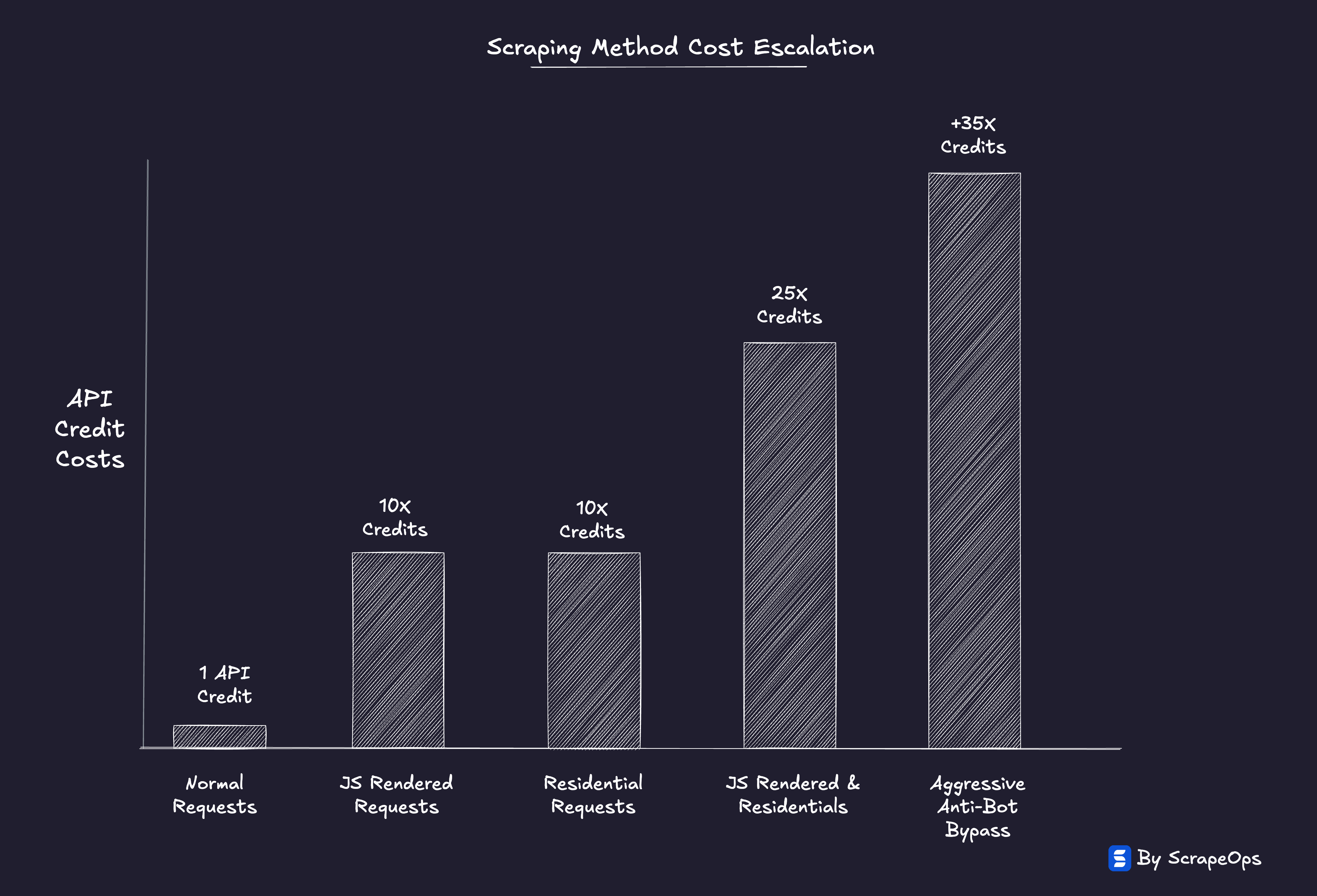
When a website upgrades its anti-bot system, it doesn't just make scraping slightly harder. It can make it 5X, 10X, or even 50X more expensive overnight.
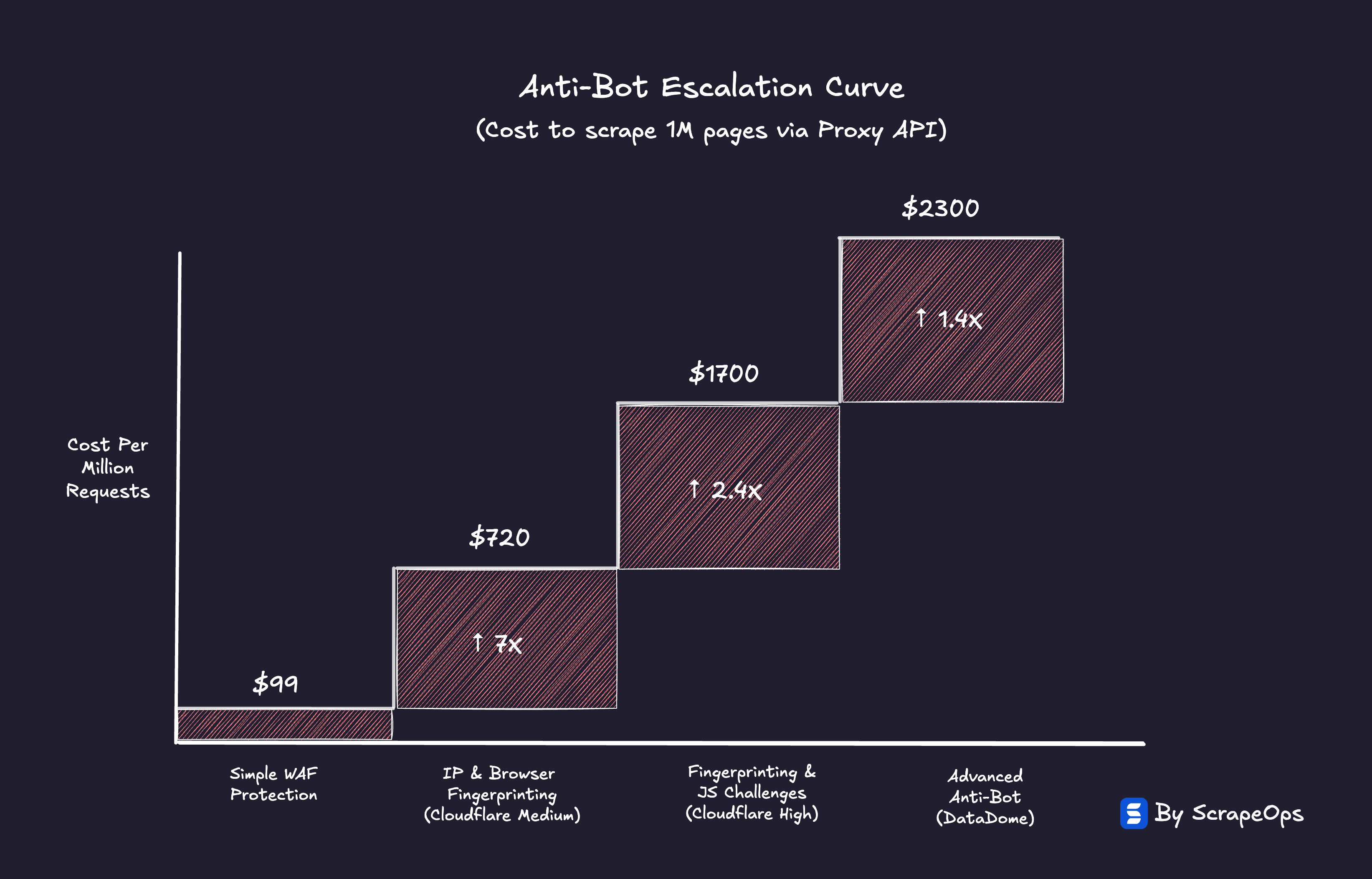
Each new defense layer forces scrapers into a higher-cost regime.
The reason...
There's no smooth cost slope between datacenter proxies and residential ones, or between HTTP requests and full browser rendering, etc.
A basic HTML scraper running on datacenter IPs might cost fractions of a cent per thousand requests.
Once that same domain adds behavioral tracking or dynamic rendering, it now demands:
-
Residential proxies → 10X jump
-
Headless browsers or JS rendering → 10X jump
-
Headless browsers & Residential proxies → 25X jump
-
Anti-bot bypasses → 30-50X jump
Each shift compounds infrastructure overhead: CPU, bandwidth, retries, validation, CAPTCHA solving, post-processing.
It's not a smooth curve, it's a staircase.
Between steps, scraping feels stable and predictable.
Then a single protection upgrade triggers a cost explosion.
This is the hidden physics of Scraping Shock.
Proxy prices can fall 20-30%, but once a domain crosses a protection threshold, you're in a new economic regime, one that falling bandwidth prices can't offset.
Scraping economics don't degrade slowly.
They break in steps.
The Escalation Curve explains how costs spike. Scraping Shock explains what happens when they do.
Scraping Shock Defined

Scraping Shock isn't a technical problem. It's an economic one.
It's the point where the underlying model of scraping breaks.
For most of the past decade, the assumption was simple: as proxies got cheaper and infrastructure got better, data would get cheaper to collect.
That assumption no longer holds.
The cost of a successful scrape is now rising faster than the cost of access is falling.
Across billions of requests tracked by ScrapeOps, the economics tell a consistent story:
| Metric | 2020 | 2025 | Δ (5 yrs) |
|---|---|---|---|
| Avg proxy price ($/GB) | $15 | $5 | -67% |
| Requests needing residential IPs / rendering | 2% | 25% | +1,150% |
| Avg cost per successful payload (API Credits) | 1.2 | 2.8 | +133% |
Proxy prices ↓ Scraping costs ↑ Success flat.
A $500 budget that once yielded 10 million rows might now deliver only 3 million validated results depending on the website being scraped.
That's scraping inflation, rising success costs hidden behind falling infrastructure prices.
The Affordability Ceiling
Every use case has an economic ceiling, a point where the marginal cost of extraction exceeds the value of the data itself.
"Every use case now has an economic reality baked in, a point where scraping stops making financial sense."
Below that line, scraping scales profitably.
Beyond it, the model collapses.
Scraping Shock is that tipping point, when data remains technically reachable, but economically out of reach.
Every scraped dataset now carries a price tag.
And the question for many teams is no longer "Can we scrape it?", but "Can we afford to?"
And that rising cost doesn't stay contained to scraping infrastructure.
It travels downstream into every product, API, and dashboard that depends on web data.
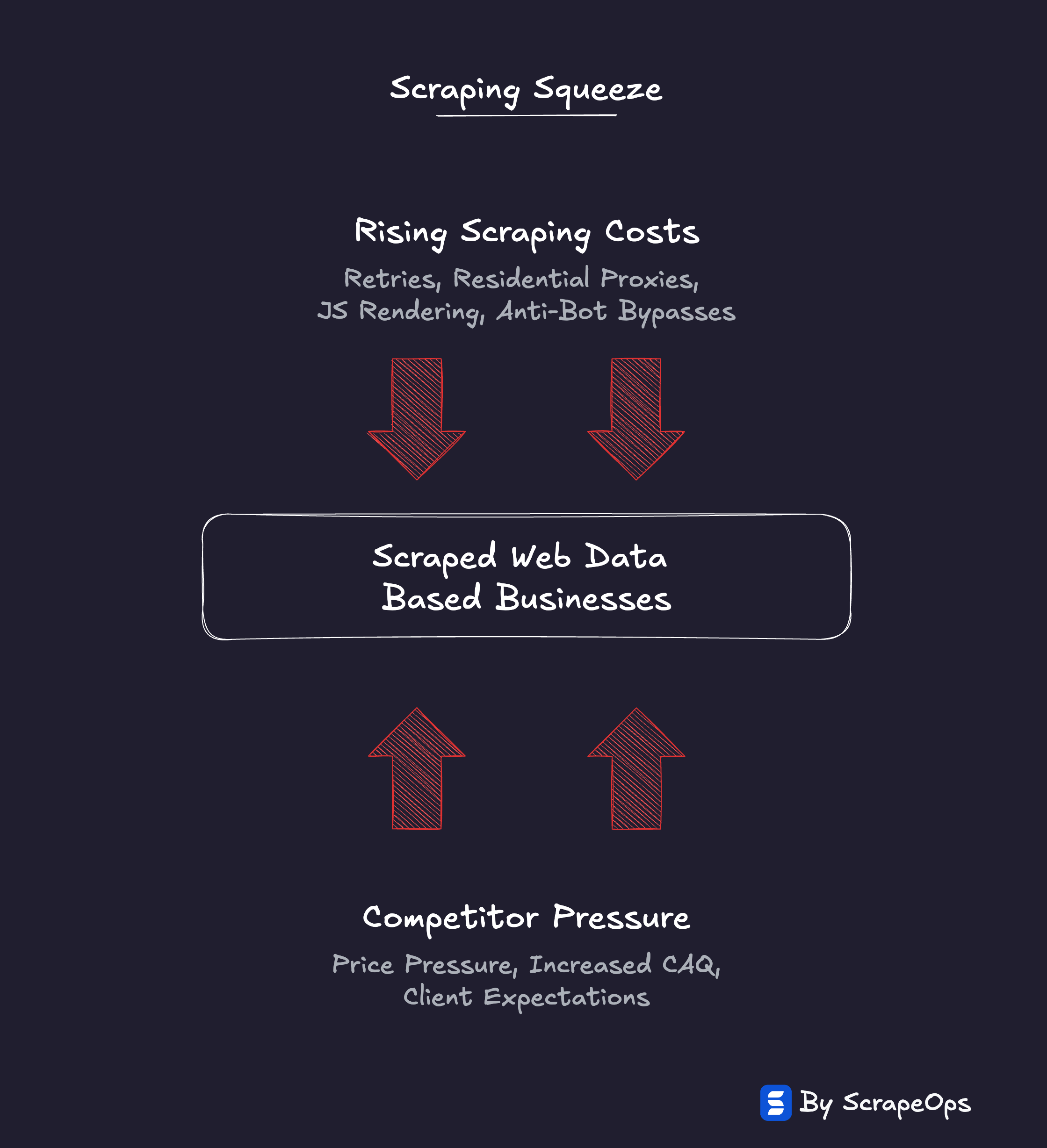
The Scraping Squeeze

Scraping Shock doesn't just affect scrapers.
It ripples downstream into every business that depends on scraped data.
Price-monitoring platforms, market-intelligence tools, SEO trackers, brand-reputation dashboards are all built on the same assumption: that the marginal cost of acquiring web data would remain roughly the same (or maybe fall).
But this assumption is failing…
Scraping costs are rising, and they're rising in ways these companies can't fully control.
Proxy prices are only a small part of the total equation.
The real costs, anti-bot bypasses, rendering, retries, and validation, keep inflating in the background, invisible until margins start to thin.
At the same time, competition in the end markets has never been higher.
Price-monitoring startups compete on freshness, coverage, and accuracy, the exact qualities that are getting more expensive to maintain.
But in crowded categories, many struggle to raise prices without losing customers.
The result is an industry-wide squeeze.
Rising costs on one side.
Price pressure on the other.
Companies face hard choices:
- Accept degraded performance. Accept lower success rates, longer latencies, and more unstable data feeds as increasing costs 10X isn't worth the benefits.
- Lower scraping costs. Experiment with cheaper proxies, simplified setups, or partial rendering pipelines.
- Reduce frequency. Scrape daily instead of hourly, or only refresh high-value SKUs.
- Reduce coverage. Monitor fewer domains or categories to contain costs.
- Accept thinner margins. Eat the difference to stay competitive.
None of these options are attractive, but they are increasingly becoming unavoidable.
Increasingly, scraping economics are starting to dictate product strategy.
The frequency, scope, and quality of a dataset are no longer just technical parameters, they're business decisions with real P&L consequences.
Scraping Shock is forcing every data-driven company to confront the same question:
"What's the true value of the data we're collecting, and how much can we really afford to pay for it?"
Efficiency as the New Competitive Edge

Scraping Shock has redrawn the competitive landscape of web data.
The advantage no longer belongs to whoever can scrape the most, it belongs to whoever can scrape most efficiently.
In an environment where scraping is easy but getting successful responses are expensive, efficiency becomes the new differentiator.
The smartest scraping teams aren't chasing scale. They're chasing success-per-dollar.
Every request, every retry, every render has a measurable cost.
The teams that thrive are the ones who treat scraping not as a technical problem, but as an economic one.
They're adapting fast:
-
Tracking cost-per-success per domain instead of just aggregate success rate.
-
Running continuous A/B tests across proxy providers to optimize price-performance balance.
-
Automating failure classification, so they can cut wasted retries before they scale.
-
Treating proxies, unlockers, and renderers as modular economic inputs, not fixed vendors.
Scraping used to be about coverage, how much data you could extract.
Now it's about efficiency, who can extract the most valuable data profitably.
That shift sounds subtle, but it changes everything: how pipelines are designed, how scraping budgets are measured, and how product pricing downstream is set.
Scraping Shock isn't just testing technical systems, it's testing business models.
And the winners will be the ones who can run leaner, smarter, and more economically sustainable pipelines than the rest.
"In the age of Scraping Shock, efficiency isn't an optimization. It's survival."
The Repricing of the Open Web

What's happening in web scraping right now isn't just a technical arms race.
It's a repricing of the open web.
For years, the web operated under a silent assumption: data was there for the taking.
Access was cheap, and scraping tools kept getting better.
Now, that equation is being rewritten.
Websites are spending more to protect their data.
Scrapers are spending more to access it.
And somewhere in between, a new equilibrium is forming, a market discovering what web data is actually worth.
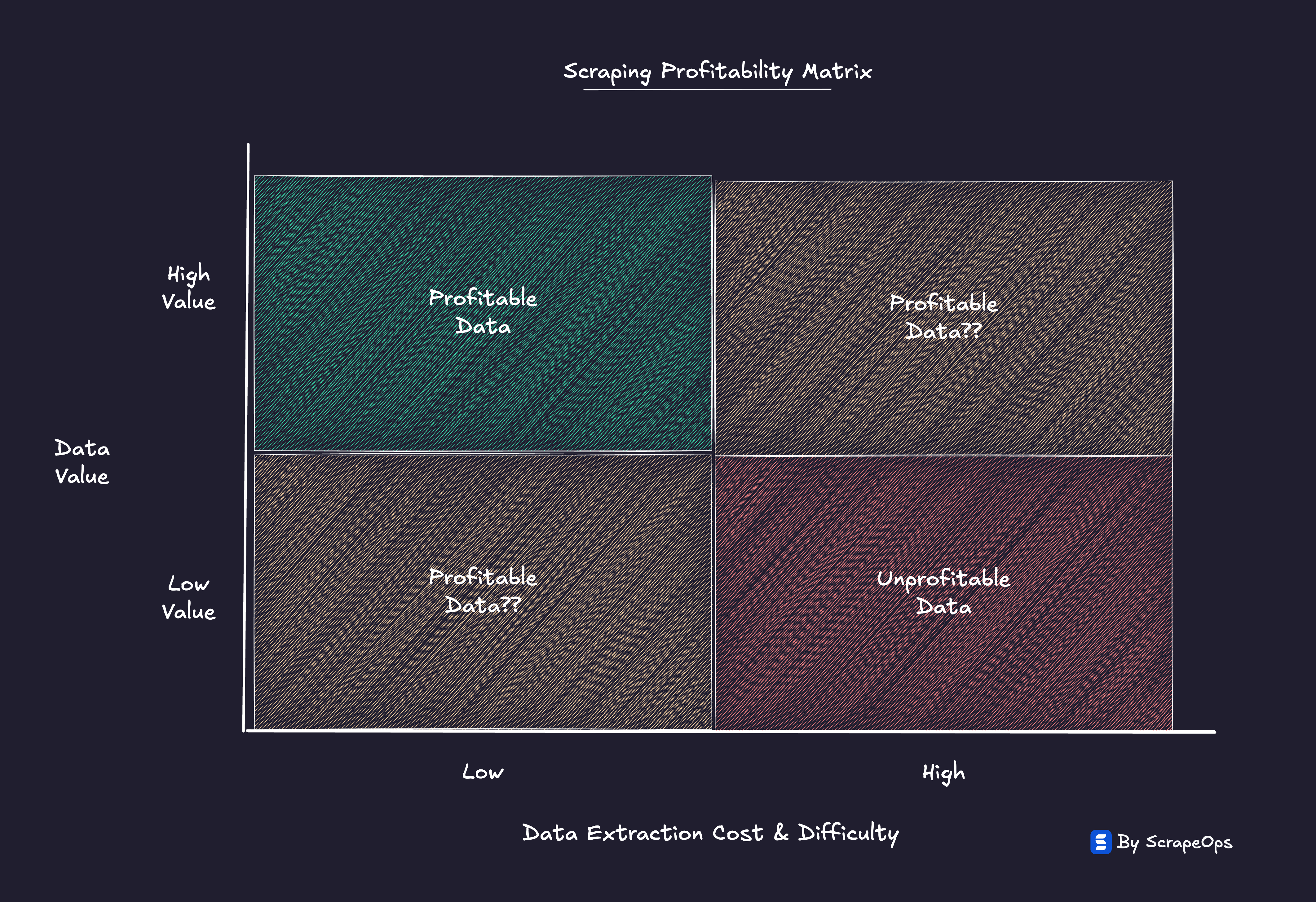
As scraping costs climb, weaker use cases are being priced out.
Only the datasets with real economic value, where the ROI of extraction outweighs the rising cost, will survive.
The rest will quietly fade as the economics stop making sense.
That doesn't mean scraping is ending. It means the web is finding its price floor.
The open web is maturing from an unpriced free for all into an efficient economic ecosystem.
A silent tug of war between, how much websites are willing to spend to defend their data and how much companies are willing to spend to acquire it.
This shift will not only continue to shape how proxy providers and companies who rely on scraped data will think about their businesses.
It will likely spark new approaches and models to how we acquire web data. Something we're already starting to see emerge:
-
Centralized data cooperatives: Services like DataBoutique which reduce redundant scraping across companies by scraping data once and then selling it to multiple customers.
-
Website Data Monetization: Instead of paying ever increasing costs to block scrapers, websites might choose to monetize their data through APIs or Cloudflares Pay For Crawl intiative. Charing fair values on the data they are willing to share.
-
Proxy Aggregators: Services like ScrapeOps which aggregate proxies from multiple providers and manage find the best/cheapest proxy provider for users target domains.
Scraping Shock is the correction before that transition, the point where abundance meets scarcity, and the market resets.
"The web didn't close its doors. It just started charging rent."
In time, the industry will adapt.
But for now, we're witnessing the repricing of the open web, a new era where the cost of data reflects its true value, and efficiency decides who gets to keep playing the game.
Conclusion
Scraping Shock isn’t a crisis, it’s a correction.
The web isn’t breaking. It’s repricing.
As the cost of access falls and the cost of success rises, the open web is discovering its true market value.
Every layer of the stack, proxies, renderers, unlockers, validation, etc. is being forced to justify its cost. Every dataset is being tested for its economic worth.
The question is no longer “Can we extract the data?” It’s “Is the data worth extracting?”
This is the new reality of the open web:
Websites spending more to defend.
Scrapers spending more to access.
Markets deciding what data is truly worth the effort.
Not every dataset will survive that correction, and that’s the point. What’s left will be the data that matters, the data that justifies its price.
“Scraping Shock is how the web resets its economy,
when abundance meets scarcity, and the market finds balance.”
In that balance, efficiency becomes more than an advantage. It becomes the currency of survival.
Want to learn more about web scraping? Take a look at the links below!