What Type of Solution Do You Need?
No matter your web scraping requirements are we have got you covered.
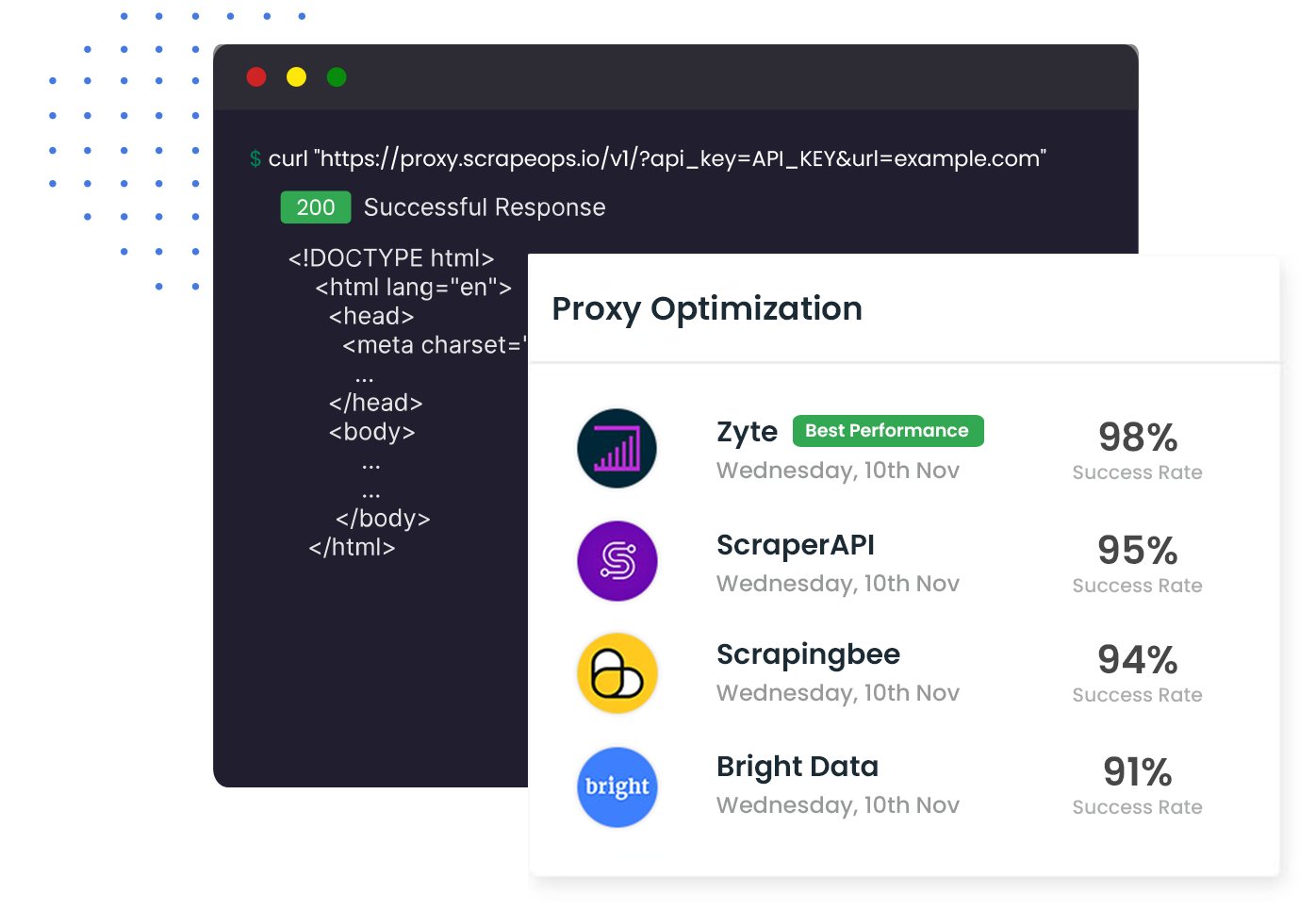
ScrapeOps Proxy Aggregator
The All-In-One Proxy Solution
Use over +20 proxy providers with our all-in-one proxy aggregator. We find the proxy providers with the best performance & price for every domain so you don't have too.
Never have to worry about rotating a proxy, CAPTCHAs or setting up headless browsers again.
ScrapeOps Monitoring
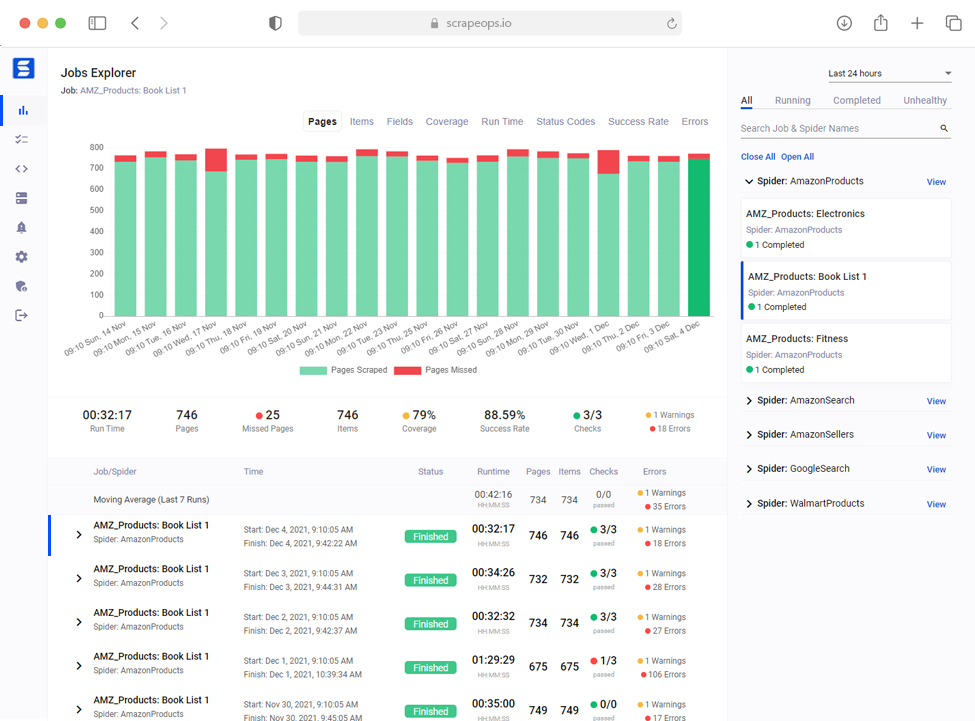
Real-Time Job Monitoring
Using the ScrapeOps SDK you can easily monitor your scrapers, log errors and get alerts from a single dashboard.
Effortlessly compare pages & items scraped, runtimes, status codes, success rates and errors versus previous job runs to identify potential issues with your scrapers.
Why Use ScrapeOps?
If web scraped data is mission critical for your business, then ScrapeOps has the features to make your life a whole lot easier.
Real-Time & Historical Job Stats
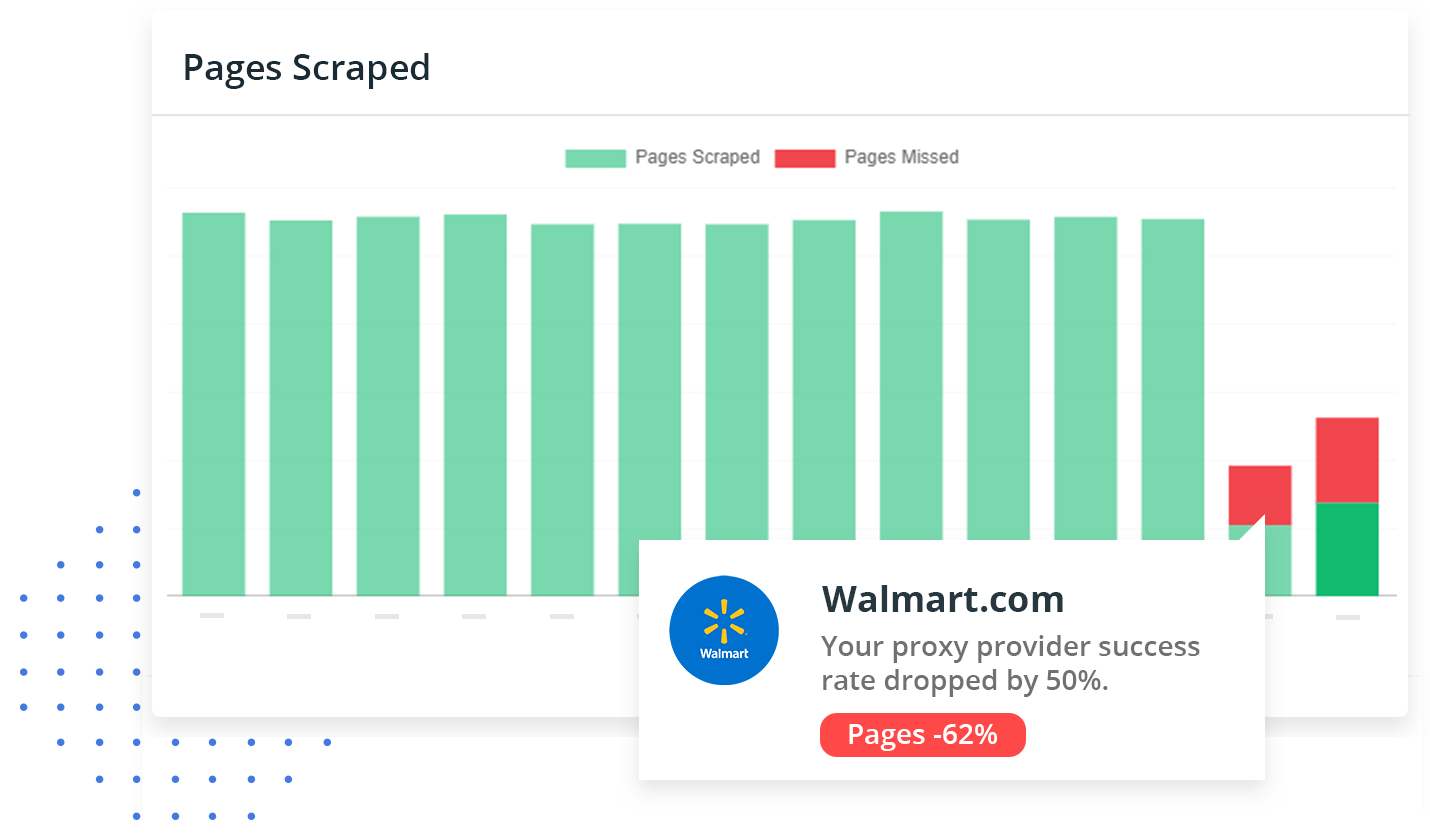
Easily monitor jobs in real-time, compare jobs to previous jobs run, spot trends forming and catch problems early before your data feeds go down.
Item & Page Vaildation
ScrapeOps checks pages for CAPTCHAs & bans, and the data quality of every item scraped so you can detect broken parsers without having to query your DB.
Error Monitoring
The ScrapeOps SDK logs any Warnings or Errors raised in your jobs and aggregates them on your dashboard, so you can see your errors without having to check your logs.
Server Provisioning
Directly link your hosting provider with ScrapeOps, then provision and setup new servers from the ScrapeOps dashboard.
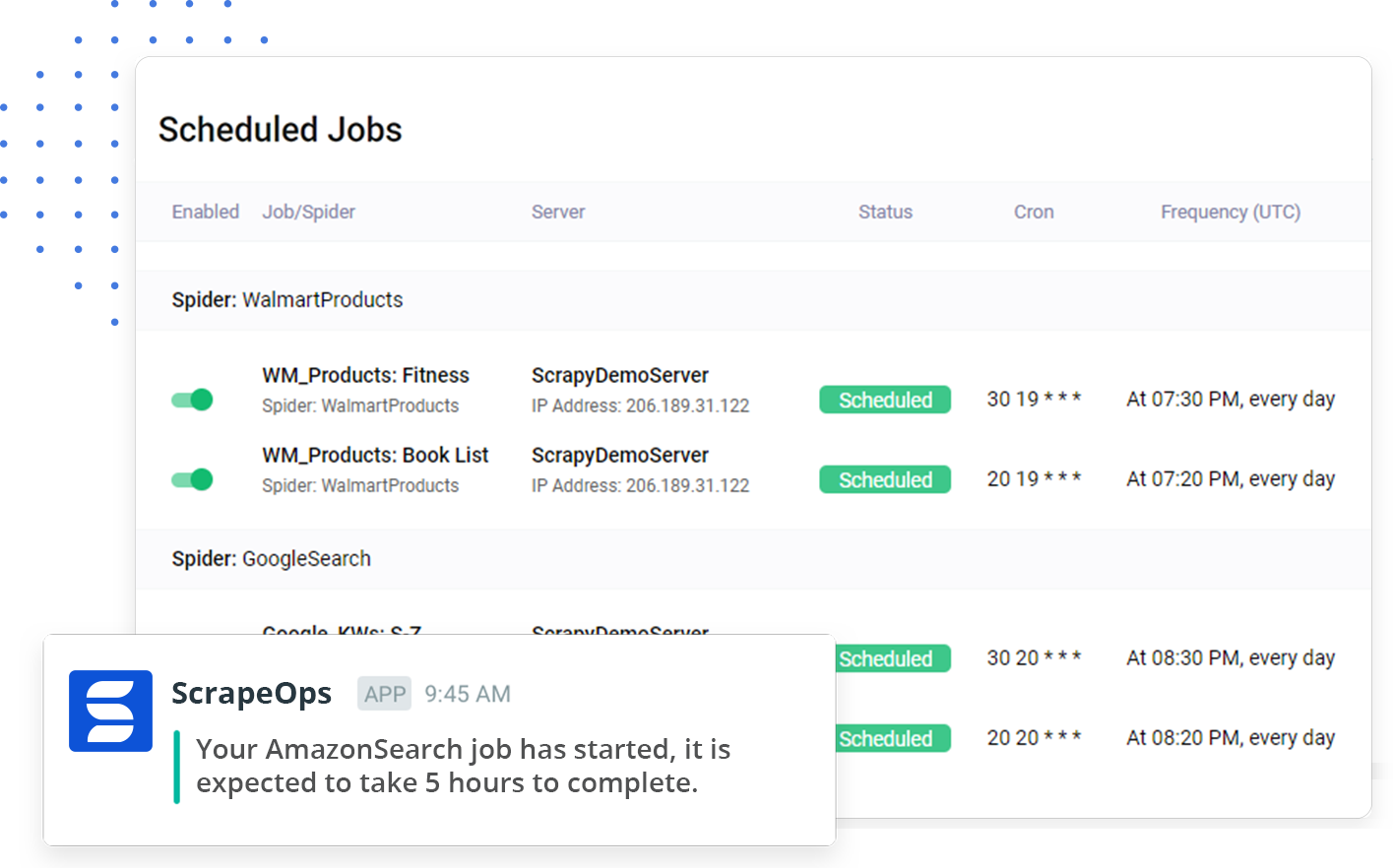
Job Scheduling
Give ScrapeOps SSH access to your servers, and you will be able to schedule and run any type of scraper from the dashboard.
Code Deployment
Link your Github repos to ScrapeOps and deploy new scrapers to your servers directly from the ScrapeOps dashboard.
Custom Health Checks & Alerts
Create custom real-time scraper health checks for all your scrapers so you detect unhealthy jobs straight away.
Custom Periodic Reports
Automate your daily scraping checks by scheduling ScrapeOps to check your spiders & jobs every couple hours and send you a report if any issues are detected.
Proxy Aggregator
Never have to worry about finding proxy providers, rotatings IPs, dealing with CAPTCHAs or bans again when you use our All-In-One Proxy Aggregator.