
How to Scrape Indeed With Puppeteer
Looking for a job online can be a daunting task, especially when navigating through extensive platforms like Indeed. Since its launch in 2004, Indeed has grown into one of the world’s largest job search engines, featuring thousands of listings from companies across the globe. However, manually browsing through its vast database can be time-consuming and overwhelming.
In this guide, we’ll walk you through creating a web scraper for Indeed that can efficiently gather job data and generate insightful reports.
- TLDR: How to Scrape Indeed
- How To Architect Our Scraper
- Understanding How To Scrape Indeed
- Setting Up Our Indeed Scraper Project
- Building an Indeed Search Crawler
- Build An Indeed Scraper
- Legal and Ethical Considerations
- Conclusion
- More NodeJS Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
TLDR: How to Scrape Indeed
Need to scrape Indeed without diving into the details? Use the pre-built scraper below.
To get started:
- Set up a project folder,
- Install Node.js and required dependencies:
npm install puppeteer json2csv
- Add the provided Node.js script below.
- Create a
config.jsonfile with your ScrapeOps API key.
{
"api_key": "YOUR_SCRAPEOPS_API_KEY"
}
- Run the script:
node your_script_name.js
The output will include a jobs directory containing CSV reports for each job and a comprehensive indeed_jobs.json file consolidating all the scraped data.
const fs = require('fs');
const path = require('path');
const { parse } = require('json2csv');
const puppeteer = require('puppeteer');
const querystring = require('querystring');
const config = JSON.parse(fs.readFileSync('config.json', 'utf-8'));
const jobsDir = './jobs';
function cleanJobsFolder() {
if (fs.existsSync(jobsDir)) {
const files = fs.readdirSync(jobsDir);
for (const file of files) {
const filePath = path.join(jobsDir, file);
fs.rmSync(filePath, { recursive: true, force: true });
}
}
}
function getScrapeOpsUrl(url, location = "us") {
const payload = {
api_key: config.api_key,
url: url,
country: location,
residential: true
};
return "https://proxy.scrapeops.io/v1/?" + querystring.stringify(payload);
}
async function crawlPage(browser, url) {
const page = await browser.newPage();
await page.goto(url);
const jobListings = await page.$$('[data-testid="slider_item"]');
const jobs = [];
for (const job of jobListings) {
const jobTitle = await job.$eval('h2', el => el.innerText.trim());
const company = await job.$eval('[data-testid="company-name"]', el => el.innerText.trim());
const jobLocation = await job.$eval('[data-testid="text-location"]', el => el.innerText.trim());
const jobAnchor = await job.$('a');
const href = await page.evaluate(anchor => anchor?.getAttribute('href') || '', jobAnchor);
const urlObj = new URL(href, 'https://www.indeed.com');
const jobKey = urlObj.searchParams.get('jk');
let jobUrl = '';
if (jobKey) {
jobUrl = `https://www.indeed.com/viewjob?jk=${jobKey}`;
console.log(`Found job listing at: ${jobUrl}`);
jobs.push({ jobTitle, company, jobLocation, jobUrl });
const proxyJobUrl = getScrapeOpsUrl(jobUrl);
await scrapeJobDetails(browser, proxyJobUrl, jobTitle);
}
}
await page.close();
return jobs;
}
async function retryPageGoto(page, url, retries = 3) {
for (let attempt = 1; attempt <= retries; attempt++) {
try {
console.log(`Attempt ${attempt} to navigate to: ${url}`);
await page.goto(url, { timeout: 10000 });
return true; // Return true if successful
} catch (error) {
if (error.name === 'TimeoutError') {
console.error(`Timeout error during navigation (Attempt ${attempt}): ${error.message}`);
} else {
console.error(`Error navigating to ${url} (Attempt ${attempt}): ${error.message}`);
}
if (attempt === retries) {
console.log(`Failed to navigate to ${url} after ${retries} attempts. Skipping...`);
return false; // Return false after final failure
}
}
}
}
async function scrapeJobDetails(browser, jobUrl, jobTitle) {
const page = await browser.newPage();
const success = await retryPageGoto(page, jobUrl);
if (!success) {
console.log(`Failed to load job details for: ${jobTitle}. Skipping.`);
await page.close();
return;
}
const salary = await page.$eval("div[id='salaryInfoAndJobContainer']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const description = await page.$eval("div[id='jobDescriptionText']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const benefits = await page.$eval("div[id='benefits']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const jobData = { jobTitle, salary, description, benefits };
const csv = parse([jobData]);
const sanitizedTitle = jobTitle.replace(/[<>:"\/\\|?*]+/g, '');
const filePath = path.join(jobsDir, `${sanitizedTitle}.csv`);
fs.writeFileSync(filePath, csv);
console.log(`Saved job details to ${filePath}`);
await page.close();
}
(async () => {
const browser = await puppeteer.launch({ headless: true });
const keyword = 'writer';
const location = 'Westland, MI';
const totalPages = 1;
const results = [];
console.log(`Crawl starting...`);
cleanJobsFolder();
const pagePromises = [];
for (let pageNum = 0; pageNum < totalPages; pageNum++) {
const url = `https://www.indeed.com/jobs?q=${encodeURIComponent(keyword)}&l=${encodeURIComponent(location)}&start=${pageNum * 10}`;
const proxyUrl = getScrapeOpsUrl(url);
console.log(`Navigating to page ${pageNum + 1}: ${url}`);
pagePromises.push(crawlPage(browser, proxyUrl));
}
const allResults = await Promise.all(pagePromises);
allResults.forEach(jobList => results.push(...jobList));
fs.writeFileSync('indeed_jobs.json', JSON.stringify(results, null, 2));
console.log('Crawling complete.');
console.log('Saving results to indeed_jobs.json');
await browser.close();
})();
You can adjust the following constants for customization:
keyword: Your desired job title or keyword (e.g., "writer").location: The city or area you’re targeting (e.g., "Westland, MI").totalPages: Number of pages to scrape, with each page showing around 10 jobs.retries: Maximum retry attempts for failed page navigation in theretryPageGotofunction.jobsDir: Directory path to save the scraped job data in CSV format.config.json: Contains your ScrapeOps API key for using proxies and avoiding blocks.
How To Architect Our Scraper
Creating a scraper for Indeed involves a two-step process: crawling job listings and scraping detailed job information. Here's how we structure it:
Phase 1: Crawling
This phase is dedicated to collecting job listing links. The crawler will:
- Search for Keywords: Start by searching for jobs using a keyword or job title.
- Navigate Through Pages: Retrieve results spread across multiple pages.
- Save Extracted Listings: Store collected data in a structured JSON file.
- Run Concurrently: Perform all tasks simultaneously to maximize efficiency.
- Employ Proxies: Use proxy servers to bypass anti-bot defenses.
Phase 2: Scraping
The second phase focuses on extracting detailed information from the jobs collected:
- Access Job Pages: Use the URLs collected during the crawling phase.
- Extract Job Details: Collect data such as job descriptions, salaries, and benefits.
- Save Reports: Generate separate files for each job or consolidate the data into a detailed report.
- Process in Parallel: Scrape multiple jobs at the same time to save time.
- Stay Behind Proxies: Keep using proxies to avoid blocks or slowdowns.
This architecture ensures a streamlined process, dividing tasks into manageable phases while optimizing for speed and reliability.
Understanding How to Scrape Indeed
Before we build this project, we need a better understanding of the data we need to get from Indeed.
Step 1: Retrieving Pages from Indeed
The first step in scraping data from Indeed involves sending a GET request to its job search page. This allows us to fetch the HTML content for processing.
Here’s a typical Indeed job search URL:
https://www.indeed.com/jobs?q=writer&l=Westland%2C+MI&start=10&vjk=a88c42edb7b19c5d
Let’s break this URL into its components to understand its structure:
- Base URL:
https://www.indeed.com/jobsis the endpoint for job listings. - Query Parameters: The section after the
?customizes the search results. Key elements include:q=writer: Filters job postings based on the keyword “writer.”l=Westland%2C+MI: Restricts results to a specific location (in this case, Westland, MI).
To perform a broader search that includes jobs from all locations, you can simplify the URL by removing the location parameter:
https://www.indeed.com/jobs?q=writer
Indeed’s search URLs are highly customizable, allowing you to adjust keywords, locations, and result pages. Each search page is a gateway to valuable job data, making it a key resource for web scraping projects.
This is a sample Indeed search page we will use.
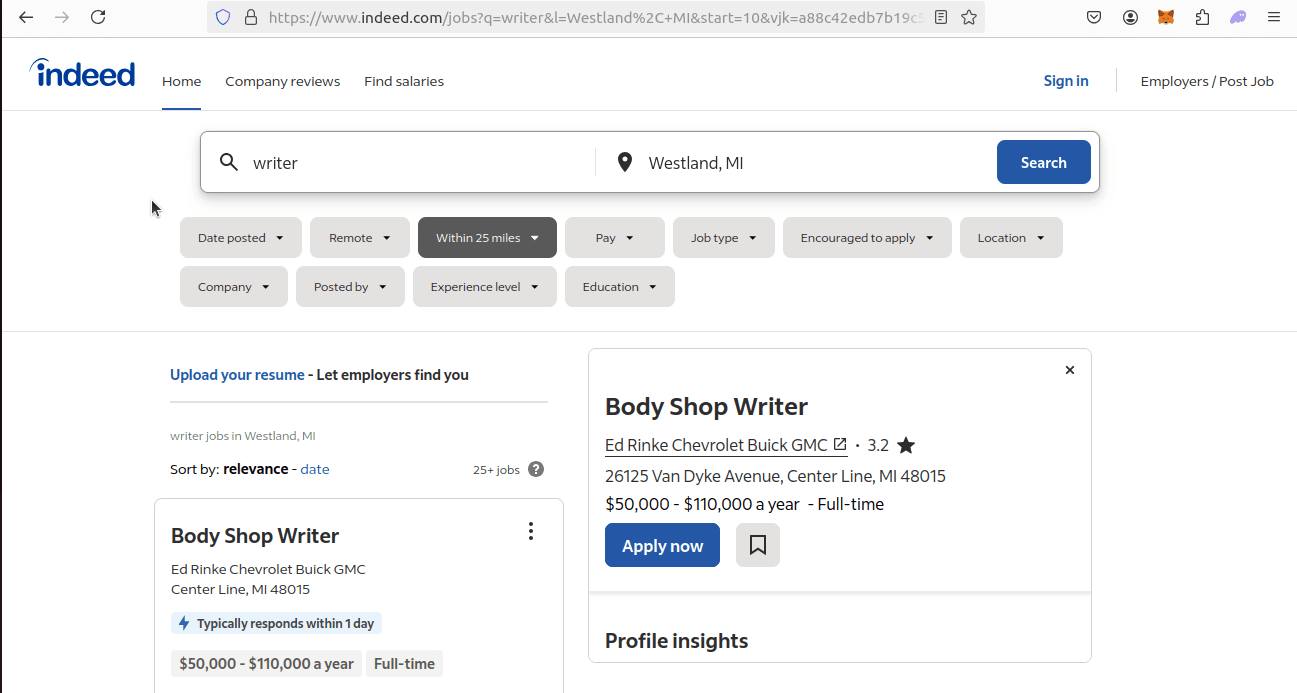
After gaining access to the search results page, the next step involves pinpointing individual job postings. Here we can see individual job postings:

Step 2: How To Extract Data From Indeed Results and Pages
Each job listing on Indeed is encapsulated within a unique HTML element, specifically a <div> tag with the attribute data-testid="slider_item".
By honing in on this specific attribute, you can extract critical job information such as:
- Job Titles
- Company Names
- Locations
- Short Job Descriptions
Each of these details is typically nested within the slider_item div, making it easier to parse and process the data programmatically.
This attribute acts as a reliable identifier for isolating each job card from the rest of the page's content.
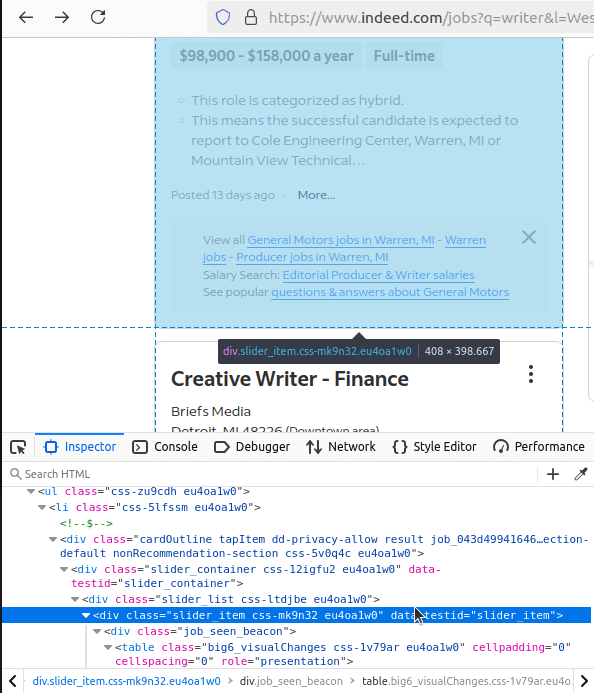
To gather more comprehensive information, you’ll need to access the specific page for each job.
On these detailed pages, Indeed uses a <div> element with the id="jobDescriptionText" to house the full job description.
This is the key container where additional insights such as responsibilities, qualifications, and benefits are stored and ready for extraction.
As seen here:
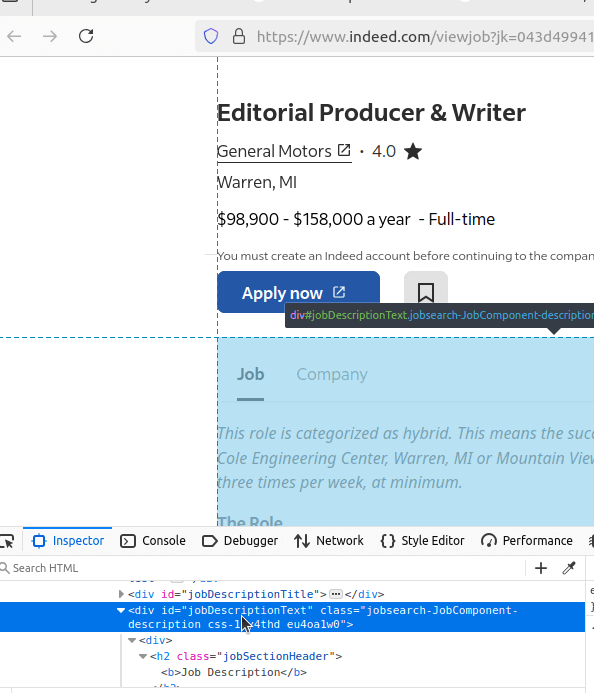
By combining data from the search results and individual job pages, you can create a well-rounded dataset for analysis or reporting.
Step 3: How To Control Pagination
To extract a comprehensive list of job postings, it’s crucial to handle pagination effectively.
Indeed organizes search results across multiple pages, controlled by the start parameter in the URL.
Let’s revisit the URL example:
https://www.indeed.com/jobs?q=writer&l=Westland%2C+MI&start=10&vjk=a88c42edb7b19c5d
The start parameter determines which set of results is displayed:
start=0: Displays the first page of results.start=10: Moves to the second page.start=20: Fetches the third page, and so on.
By incrementing the value of the start parameter in steps of 10, you can systematically retrieve listings from subsequent pages. For example:
- First Page:
start=0 - Second Page:
start=10 - Third Page:
start=20
This approach ensures that your scraper can traverse all available job listings efficiently, capturing data from every page of results.
Step 4: Geolocated Data
To ensure your scraper fetches jobs specific to certain areas, geolocation plays a critical role.
To handle geolocation we'll actually need to do two things.
-
For starters, there is another parameter we need to look at:
l=Westland%2C+MI.lis the location we'd like to search. If we wanted to search in London, we could passl=London%2CUK. -
Our other geolocation element actually doesn't involve Indeed at all, but rather ScrapeOps. When we talk to the ScrapeOps Proxy API, we can pass in a
countryparam.
- If we tell ScrapeOps
"country": "us", we'll get routed through a server in the US. - If we want to appear in the UK, we could pass
"country": "uk".
Indeed offers flexibility through the l parameter in the query string, while ScrapeOps provides additional geolocation control at the proxy level.
This dual approach, combining Indeed’s native location filter with ScrapeOps geolocation capabilities, ensures precise, location-based data extraction.
Setting Up Our Indeed Scraper Project
Before starting the scraping process, it’s essential to prepare the environment and ensure all necessary tools and configurations are in place.
This setup phase includes installing key libraries and securely managing sensitive information.
Install Required Packages:
To build our scraper, we’ll use:
- Puppeteer for browser automation,
- json2csv for exporting data into CSV files, and
- querystring for handling URL queries.
Install these packages with the following command:
npm install puppeteer json2csv querystring
These tools provide the backbone of our scraper, enabling data extraction, organization, and efficient query management.
Secure API Keys with a Config File:
Create a config.json file in the root of your project directory to store your ScrapeOps API key. This API key is crucial for managing proxies and preventing IP bans.
Here’s an example of what the file should look like:
{
"api_key": "your-api-key-here"
}
Using a separate configuration file keeps sensitive data secure and ensures your code is cleaner and easier to maintain.
With the environment set up and the essential tools installed, you’re ready to dive into building the Indeed crawler. This setup ensures a smooth transition into the development phase, minimizing potential roadblocks along the way.
Building an Indeed Search Crawler
Now that we have set up the project and are familiar with the basics, it’s time to begin building our Indeed Search Crawler.
This crawler will help us extract job listings from the Indeed search results page and gather the necessary details.
Step 1: Create Simple Search Data Parser
The first task in building the crawler is to create a search data parser. This parser is responsible for fetching job listings from a search results page and extracting essential details such as job title, company name, and location.
To retrieve the relevant information, we can use Puppeteer’s $eval() function to target specific elements in each job listing.
Here’s how we can extract the necessary data:
const jobTitle = await job.$eval('h2', el => el.innerText.trim());
const company = await job.$eval('[data-testid="company-name"]', el => el.innerText.trim());
const jobLocation = await job.$eval('[data-testid="text-location"]', el => el.innerText.trim());
Each of these function calls fetches data from specific elements within the job listing card.
Now, let’s look at how we can implement this data parser in the context of the entire crawler:
async function crawlPage(browser, url) {
const page = await browser.newPage();
await page.goto(url);
// Select all job listings on the page
const jobListings = await page.$$('[data-testid="slider_item"]');
const jobs = [];
for (const job of jobListings) {
const jobTitle = await job.$eval('h2', el => el.innerText.trim());
const company = await job.$eval('[data-testid="company-name"]', el => el.innerText.trim());
const jobLocation = await job.$eval('[data-testid="text-location"]', el => el.innerText.trim());
// Extract the job URL
const jobAnchor = await job.$('a');
const href = await page.evaluate(anchor => anchor?.getAttribute('href') || '', jobAnchor);
const urlObj = new URL(href, 'https://www.indeed.com');
const jobKey = urlObj.searchParams.get('jk');
let jobUrl = '';
if (jobKey) {
jobUrl = `https://www.indeed.com/viewjob?jk=${jobKey}`;
console.log(`Found job listing at: ${jobUrl}`);
jobs.push({ jobTitle, company, jobLocation, jobUrl });
}
}
await page.close();
return jobs;
}
The search data parser performs the critical task of gathering essential job details such as the job title, company name, and location, while also constructing URLs for individual job posts.
By using Puppeteer’s $eval(), we can efficiently parse multiple listings on a page, store the necessary information, and prepare it for further processing in the scraping phase.
- Fetching Job Listings: We use
$$('[data-testid="slider_item"]')to select all elements that represent individual job listings. This allows us to loop through each listing and extract the data we need. - Extracting Job Details: For each job listing, we extract the title, company name, and location using
$eval(). These values are then stored in ajobsarray. - Job URL: We then fetch the URL of the job post. Using Puppeteer’s
evaluate()method, we extract thehrefattribute from the anchor tag inside each job listing. This URL allows us to access the individual job page for more detailed information.
Step 2: Add Pagination
To manage multiple pages of search results, pagination is achieved by dynamically adjusting the start value in the URL. This value increments based on the current page number, allowing us to access a new set of results for each page.
In the code, this is controlled by the totalPages variable:
const totalPages = 1;
// ... rest of the code ...
for (let pageNum = 0; pageNum < totalPages; pageNum++) {
const url = `https://www.indeed.com/jobs?q=${encodeURIComponent(keyword)}&l=${encodeURIComponent(location)}&start=${pageNum * 10}`;
const proxyUrl = getScrapeOpsUrl(url);
console.log(`Navigating to page ${pageNum + 1}: ${url}`);
pagePromises.push(crawlPage(browser, proxyUrl));
}
This setup ensures we efficiently scrape job listings from multiple pages by iterating through the search results using the start query parameter.
Step 3: Storing the Scraped Data
To ensure that the collected job data is stored properly, we save it into a JSON file during the scraping process.
fs.writeFileSync('indeed_jobs.json', JSON.stringify(results, null, 2));
This approach allows us to store all job listings in a structured JSON format, which makes it simple to retrieve, analyze, or process the data in future steps.
Saving data in this format is essential for maintaining an organized collection of job details.
Step 4: Adding Concurrency
To speed up the scraping process, we implement concurrency by launching multiple browser pages that scrape job data simultaneously.
const pagePromises = [];
for (let pageNum = 0; pageNum < totalPages; pageNum++) {
const url = `https://www.indeed.com/jobs?q=${encodeURIComponent(keyword)}&l=${encodeURIComponent(location)}&start=${pageNum * 10}`;
const proxyUrl = getScrapeOpsUrl(url);
console.log(`Navigating to page ${pageNum + 1}: ${url}`);
pagePromises.push(crawlPage(browser, proxyUrl));
}
const allResults = await Promise.all(pagePromises);
In this step, we use Promise.all to wait for all the pages to load concurrently, significantly improving the scraping speed.
Each page runs in the background, allowing us to collect data from multiple pages in parallel, which drastically reduces the overall time spent on the crawling process.
Step 5: Bypassing Anti-Bots
Indeed implements various anti-bot measures to block scrapers. To effectively bypass these restrictions, we use ScrapeOps Proxy Aggregator, a proxy service that helps mask our real IP address and rotate proxies to prevent detection.
The following function generates a proxy URL that routes requests through ScrapeOps, allowing us to scrape Indeed without triggering anti-bot defenses:
function getScrapeOpsUrl(url, location = "us") {
const payload = {
api_key: config.api_key,
url: url,
country: location,
residential: true
};
return "https://proxy.scrapeops.io/v1/?" + querystring.stringify(payload);
}
We use the function to generate the proxy URL like so:
const proxyUrl = getScrapeOpsUrl(url);
By utilizing ScrapeOps, we can safely scrape large volumes of data from Indeed while avoiding detection by their anti-bot systems.
Step 6: Production Run
After testing and ensuring that the crawler works as expected, we can proceed with running it in production. This will store all the collected job listings into the indeed_jobs.json file. This file can then be used for further data analysis or stored for later use.
Below is the main function that executes the crawler in production.
(async () => {
const browser = await puppeteer.launch({ headless: true });
const keyword = 'writer';
const location = 'Westland, MI';
const totalPages = 1;
const results = [];
console.log(`Starting the crawl...`);
const pagePromises = [];
for (let pageNum = 0; pageNum < totalPages; pageNum++) {
const url = `https://www.indeed.com/jobs?q=${encodeURIComponent(keyword)}&l=${encodeURIComponent(location)}&start=${pageNum * 10}`;
const proxyUrl = getScrapeOpsUrl(url);
console.log(`Navigating to page ${pageNum + 1}: ${url}`);
pagePromises.push(crawlPage(browser, proxyUrl));
}
const allResults = await Promise.all(pagePromises);
allResults.forEach(jobList => results.push(...jobList));
fs.writeFileSync('indeed_jobs.json', JSON.stringify(results, null, 2));
console.log('Crawl completed.');
console.log('Saving results to indeed_jobs.json');
await browser.close();
})();
Build An Indeed Scraper
Now that we've set up our crawler, it's time to build the scraper. To make the implementation simpler, we'll expand on the crawler we previously created.
The scraper will leverage the existing crawler functionality, adding an extra layer that will handle the detailed extraction of job data.
Let’s dive into the process of building the Indeed scraper.
Step 1: Create Simple Job Data Parser
In this step, we'll create a parser that will extract relevant job information from each job listing on Indeed. Similar to the crawling phase, our job data parser will gather key details such as salary, job description, and benefits.
We'll define this function as scrapeJobDetails, which will be responsible for collecting the necessary data for each job posting.
Here's how to implement the scrapeJobDetails function:
async function scrapeJobDetails(browser, jobUrl, jobTitle) {
const page = await browser.newPage();
const success = await retryPageGoto(page, jobUrl);
if (!success) {
console.log(`Unable to load job details for: ${jobTitle}. Skipping this job listing.`);
await page.close();
return;
}
// Extracting salary, description, and benefits
const salary = await page.$eval("div[id='salaryInfoAndJobContainer']", el => el?.innerText.trim() || 'Not Available').catch(() => 'Not Available');
const description = await page.$eval("div[id='jobDescriptionText']", el => el?.innerText.trim() || 'No description available').catch(() => 'No description available');
const benefits = await page.$eval("div[id='benefits']", el => el?.innerText.trim() || 'No benefits listed').catch(() => 'No benefits listed');
// Compiling the extracted data into an object
const jobData = { jobTitle, salary, description, benefits };
// Save or process the extracted job data as needed
await page.close();
}
In this function, we use Puppeteer’s $eval method to extract text from specific elements on the job page. If an element isn't found or an error occurs during the extraction, we use a fallback value like 'Not Available' for salary or 'No description available' for the job description.
This ensures that we always have a meaningful result, even if some data is missing.
We are specifically targeting three key elements for each job listing:
- Salary: Extracted from the salary container.
- Job Description: Extracted from the job description section.
- Benefits: Extracted from the benefits section.
By storing the parsed information into a jobData object, we make the data easier to process and store for future use. This approach can be adapted if additional details need to be captured from the job listing page.
This job data parser serves as a core component of the scraper and will be called on each job listing page to ensure that all relevant information is collected.
Step 2: Loading URLs To Scrape
In this step, we'll focus on extracting the job URLs that we want to scrape. This process is straightforward—our crawler will fetch the URLs of job listings, pass them to our scraping function, and then we’ll gather the relevant job data.
We will enhance our existing crawlPage function to include additional logic that retrieves each job's unique URL and sends it to the scraper we created earlier. Here’s how to do it:
First, we’ll call getScrapeOpsUrl(jobUrl) to get a proxy for each job URL, then pass it along with the job title to the scraping function:
const proxyJobUrl = getScrapeOpsUrl(jobUrl);
await scrapeJobDetails(browser, proxyJobUrl, jobTitle);
The updated crawlPage function now looks like this:
async function crawlPage(browser, url) {
const page = await browser.newPage();
await page.goto(url);
// Extract job listings from the page
const jobListings = await page.$$('[data-testid="slider_item"]');
const jobs = [];
// Iterate through job listings and extract relevant details
for (const job of jobListings) {
const jobTitle = await job.$eval('h2', el => el.innerText.trim());
const company = await job.$eval('[data-testid="company-name"]', el => el.innerText.trim());
const jobLocation = await job.$eval('[data-testid="text-location"]', el => el.innerText.trim());
// Get job URL by extracting the 'href' from the job's anchor tag
const jobAnchor = await job.$('a');
const href = await page.evaluate(anchor => anchor?.getAttribute('href') || '', jobAnchor);
const urlObj = new URL(href, 'https://www.indeed.com');
const jobKey = urlObj.searchParams.get('jk');
// Construct full job URL and pass to the scraper
let jobUrl = '';
if (jobKey) {
jobUrl = `https://www.indeed.com/viewjob?jk=${jobKey}`;
console.log(`Found job listing at: ${jobUrl}`);
jobs.push({ jobTitle, company, jobLocation, jobUrl });
// Pass job URL to the scraping function for detailed parsing
const proxyJobUrl = getScrapeOpsUrl(jobUrl);
await scrapeJobDetails(browser, proxyJobUrl, jobTitle);
}
}
await page.close();
return jobs;
}
- Job URL Extraction: In this function, we scrape the job URL for each listing by grabbing the
hrefattribute from the job's anchor (<a>) tag. This will provide the unique URL for each job listing. - Passing to Scraper: After constructing the full job URL, we pass it to the scraping function (
scrapeJobDetails) using a proxy URL. This ensures that each job's details are fetched and parsed correctly. - Job Data Collection: The job title, company name, location, and URL are stored in the
jobsarray for further processing or saving to a file.
Step 3: Storing the Scraped Data
Now that we've successfully scraped the job data, it's time to save it into a file for further use. We'll store the collected job information in a CSV format, which makes it easy to handle and analyze.
Before storing the data, we need to sanitize the job title to ensure it is clean and compatible with the file system.
This process is important because certain characters, like slashes or colons, are not allowed in filenames. We'll strip out any such invalid characters before saving the data.
Here’s how we can write the job data into a CSV file:
const csv = parse([jobData]);
// Sanitize the job title to make it filesystem-safe
const sanitizedTitle = jobTitle.replace(/[<>:"\/\\|?*]+/g, '');
// Generate the file path using the sanitized title
const filePath = path.join(jobsDir, `${sanitizedTitle}.csv`);
// Write the data to the CSV file
fs.writeFileSync(filePath, csv);
Now, let's take a look at the full scraping function after including the data-saving logic:
async function scrapeJobDetails(browser, jobUrl, jobTitle) {
const page = await browser.newPage();
const success = await retryPageGoto(page, jobUrl);
// If loading fails, skip this job and close the page
if (!success) {
console.log(`Failed to load job details for: ${jobTitle}. Skipping.`);
await page.close();
return;
}
const salary = await page.$eval("div[id='salaryInfoAndJobContainer']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const description = await page.$eval("div[id='jobDescriptionText']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const benefits = await page.$eval("div[id='benefits']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const jobData = { jobTitle, salary, description, benefits };
const csv = parse([jobData]);
const sanitizedTitle = jobTitle.replace(/[<>:"\/\\|?*]+/g, '');
const filePath = path.join(jobsDir, `${sanitizedTitle}.csv`);
fs.writeFileSync(filePath, csv);
console.log(`Saved job details to ${filePath}`);
await page.close();
}
With this setup, once the function completes, a new CSV file is created in the jobsDir directory, and it will be filled with the specific job’s detailed information (such as salary, description, and benefits).
This makes the data easy to access and manage for further analysis or storage.
Step 4: Adding Concurrency
At this stage, we’re considering adding concurrency to our scraping process. However, since the crawler itself is already handling tasks concurrently, adding another layer of concurrency for scraping would be redundant.
Instead, we'll leverage the crawler's existing concurrency system for the scraping part as well.
In simpler terms, the crawler efficiently processes multiple pages at the same time, and since the scraping happens after the crawling phase, we can rely on this built-in concurrency to scrape job data concurrently. This approach simplifies the overall workflow and avoids unnecessary complexity.
By using the existing crawler's concurrent operations, we can efficiently scrape multiple job details in parallel without needing to add additional concurrency logic to the scraping function.
This helps to maintain high performance while keeping the code clean and efficient.
Step 5: Bypassing Anti-Bots
When it comes to bypassing anti-bot protections, it's important to note that the crawling phase has already addressed this issue. Anti-bot measures are typically managed by using techniques such as proxies or rotating IPs to mimic human behavior, and this has been implemented during the crawling process.
Since we’ve already set up the necessary anti-bot handling in the crawler, there's no need to replicate this for the scraping phase. The same protections will continue to work seamlessly as we scrape job data, ensuring that our scraper avoids detection and operates without interruptions.
In essence, by relying on the crawler’s anti-bot strategies, we avoid redundant implementation and maintain a smooth and efficient scraping flow. This approach also reduces the complexity of our scraper code while ensuring it remains robust and effective.
Step 6: Production Run
Now that both the crawler and scraper are fully set up, we’re ready for a production run. This step involves executing the final code, which combines all the previous phases and scrapes job listings from Indeed.
Here's how you can run the complete process:
const fs = require('fs');
const path = require('path');
const { parse } = require('json2csv');
const puppeteer = require('puppeteer');
const querystring = require('querystring');
const config = JSON.parse(fs.readFileSync('config.json', 'utf-8'));
const jobsDir = './jobs';
function cleanJobsFolder() {
if (fs.existsSync(jobsDir)) {
const files = fs.readdirSync(jobsDir);
for (const file of files) {
const filePath = path.join(jobsDir, file);
fs.rmSync(filePath, { recursive: true, force: true });
}
}
}
function getScrapeOpsUrl(url, location = "us") {
const payload = {
api_key: config.api_key,
url: url,
country: location,
residential: true
};
return "https://proxy.scrapeops.io/v1/?" + querystring.stringify(payload);
}
async function crawlPage(browser, url) {
const page = await browser.newPage();
await page.goto(url);
const jobListings = await page.$$('[data-testid="slider_item"]');
const jobs = [];
for (const job of jobListings) {
const jobTitle = await job.$eval('h2', el => el.innerText.trim());
const company = await job.$eval('[data-testid="company-name"]', el => el.innerText.trim());
const jobLocation = await job.$eval('[data-testid="text-location"]', el => el.innerText.trim());
const jobAnchor = await job.$('a');
const href = await page.evaluate(anchor => anchor?.getAttribute('href') || '', jobAnchor);
const urlObj = new URL(href, 'https://www.indeed.com');
const jobKey = urlObj.searchParams.get('jk');
let jobUrl = '';
if (jobKey) {
jobUrl = `https://www.indeed.com/viewjob?jk=${jobKey}`;
console.log(`Found job listing at: ${jobUrl}`);
jobs.push({ jobTitle, company, jobLocation, jobUrl });
const proxyJobUrl = getScrapeOpsUrl(jobUrl);
await scrapeJobDetails(browser, proxyJobUrl, jobTitle);
}
}
await page.close();
return jobs;
}
async function scrapeJobDetails(browser, jobUrl, jobTitle) {
const page = await browser.newPage();
const success = await retryPageGoto(page, jobUrl);
if (!success) {
console.log(`Failed to load job details for: ${jobTitle}. Skipping.`);
await page.close();
return;
}
const salary = await page.$eval("div[id='salaryInfoAndJobContainer']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const description = await page.$eval("div[id='jobDescriptionText']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const benefits = await page.$eval("div[id='benefits']", el => el?.innerText.trim() || 'n/a').catch(() => 'n/a');
const jobData = { jobTitle, salary, description, benefits };
const csv = parse([jobData]);
const sanitizedTitle = jobTitle.replace(/[<>:"\/\\|?*]+/g, '');
const filePath = path.join(jobsDir, `${sanitizedTitle}.csv`);
fs.writeFileSync(filePath, csv);
console.log(`Saved job details to ${filePath}`);
await page.close();
}
async function retryPageGoto(page, url, retries = 3) {
for (let attempt = 1; attempt <= retries; attempt++) {
try {
console.log(`Attempt ${attempt} to navigate to: ${url}`);
await page.goto(url, { timeout: 10000 });
return true; // Return true if successful
} catch (error) {
if (error.name === 'TimeoutError') {
console.error(`Timeout error during navigation (Attempt ${attempt}): ${error.message}`);
} else {
console.error(`Error navigating to ${url} (Attempt ${attempt}): ${error.message}`);
}
if (attempt === retries) {
console.log(`Failed to navigate to ${url} after ${retries} attempts. Skipping...`);
return false; // Return false after final failure
}
}
}
}
(async () => {
const browser = await puppeteer.launch({ headless: true });
const keyword = 'writer';
const location = 'Westland, MI';
const totalPages = 1;
const results = [];
console.log(`Crawl starting...`);
cleanJobsFolder();
const pagePromises = [];
for (let pageNum = 0; pageNum < totalPages; pageNum++) {
const url = `https://www.indeed.com/jobs?q=${encodeURIComponent(keyword)}&l=${encodeURIComponent(location)}&start=${pageNum * 10}`;
const proxyUrl = getScrapeOpsUrl(url);
console.log(`Navigating to page ${pageNum + 1}: ${url}`);
pagePromises.push(crawlPage(browser, proxyUrl));
}
const allResults = await Promise.all(pagePromises);
allResults.forEach(jobList => results.push(...jobList));
fs.writeFileSync('indeed_jobs.json', JSON.stringify(results, null, 2));
console.log('Crawling complete.');
console.log('Saving results to indeed_jobs.json');
await browser.close();
})();
In this step, you’ll execute the final scraping script to gather and store job details. The script uses Puppeteer for web scraping, json2csv for formatting the scraped data into CSV files, and ScrapeOps for managing proxy requests to avoid detection.
It first crawls the job listings, scrapes the relevant data, and saves the output in JSON (for the crawling data) and CSV files (for the detailed job data).
One important function is cleanJobsFolder(), which cleans up the directory storing previous data, ensuring that only the latest scraping results are saved.
Legal and Ethical Considerations
Before scraping Indeed or any other website, it's important to follow best practices to ensure that you’re scraping ethically and legally. Here are key points to keep in mind:
-
Review the robots.txt and Legal Documents
Always check the website'srobots.txtfile, which indicates which parts of the site can be crawled and scraped. In addition, carefully read the site's terms of service or any legal documents to ensure you're not violating any restrictions on data usage or scraping. -
Respect Rate Limits and Avoid Overloading Servers
Scraping too frequently or with too many requests in a short amount of time can overload the server, causing potential disruptions for other users. Implement rate-limiting or add sleep intervals between requests to avoid overburdening the website's server. -
Understand Copyright and Data Ownership
Scraped data may be subject to copyright laws. Ensure that you respect the intellectual property rights of the content you're collecting, especially when you use the data for commercial purposes. -
Seek Legal Advice
If you're uncertain about whether your scraper complies with legal requirements, it's a good idea to consult with a legal professional. They can help you understand the implications and ensure that your actions are within the law.
By adhering to these guidelines, you can scrape websites responsibly and avoid potential legal issues.
Conclusion
In this article, we developed a comprehensive job scraper for Indeed using Node.js, Puppeteer, and ScrapeOps. Here’s what we accomplished:
- Scraped job listings from Indeed’s search pages.
- Extracted detailed job information from individual job listings.
- Stored the data in both CSV and JSON formats for easy access and analysis.
- Utilized ScrapeOps proxies to bypass Indeed’s anti-bot measures, ensuring a smooth scraping experience.
With this scraper, you now have a powerful tool to efficiently collect job listings from Indeed, which can be further analyzed or used for automation purposes.
If you want to know more about the tech stack from this article, check out the links below!
More NodeJS Scraping Guides
Here at ScrapeOps, we've got a ton of learning material. Whether you're building your first ever scraper, or you've been scraping for years, we've got something for you.
Check out our Puppeteer Web Scraping Playbook!
If you're interested in more of our "How To Scrape" series, check out the articles below!