How To Build A Python Web Scraping Framework
Python is an extremely powerful language boasting readability, ease of use and a large ecosystem of third party libraries.
In this guide, we will look at how you can build a simple web scraping client/framework that you can use with all your Python scrapers to make them production ready.
This universal web scraping client will making dealing with retries, integrating proxies, monitoring your scrapers and sending concurrent requests much easier when moving a scraper to production.
You can use this client yourself, or use it as a reference to build your own web scraping client.
So in this guide we will walk through:
- How To Architect Our Scraper
- Understanding How To Scrape a Website
- Setting Up Our Scraper Project
- Build A Python Crawler
- Build A Python Scraper
- Legal and Ethical Considerations
- Conclusion
- More Python Web Scraping Guides
Need help scraping the web?
Then check out ScrapeOps, the complete toolkit for web scraping.
How To Architect Our Scraper
As you might have read above, we're going to be using Requests and BeautifulSoup to create our scraping framework.
Now, we need to plan out exactly what this program needs to do. To start, we actually need to build two smaller scrapers.
-
Our first one is called a crawler. The crawler needs to perform a search, interpret the results and then save them to a file.
-
Once our crawler finishes its job, the scraper will take over the process. The scraper will read the results file and go scrape further information about each of the results.
Take a look below to see how the process works.
Crawler
- Make an HTTP request to get our website.
- Receive a response in the form of HTML.
- Parse the response and extract our desired data.
- Save the data to a file for human review and later usage.
Scraper
- Read the file generated by the crawler.
- Use HTTP to fetch the url from each row in the file.
- Receive a response back and extract the results.
- Save these results to a file as well.
In order to cover all of these concepts, we actually need to use two websites. We'll use DuckDuckGo as our target site for the overall project.
However, DuckDuckGo doesn't cover all of the features you might need in your framework, so we'll supplement those features using Quotes to Scrape.
Follow along and learn how to incorporate all of the following in your design.
- Parsing (DuckDuckGo)
- Pagination (Quotes to Scrape)
- Data Storage (DuckDuckGo)
- Concurrency (DuckDuckGo)
- Proxy Integration (DuckDuckGo)
Understanding How To Scrape a Website
Now, let's get a better picture of exactly what your framework needs to do. From simple HTTP requests to proxy integration, we'll give you a brief overview these concepts so you can better understand them when they're implemented.
Once you understand this stuff it'll be time to start coding.
Step 1: How To Request Target Pages
HTTP (Hypertext Transfer Protocol) is the communication system underlying the entire web.
With this protocol, a client (such as Requests or even your web browser) makes a request to a server and the server sends back a response. There are four main types of requests.
- GET: Sends a request to get information such as a website.
- POST: Sends information to a server. Social media posts are an excellent example of this.
- PUT: This is used to alter existing information. If you decide to edit a social media post, this tells the server to retrieve the post in the database and save your desired changes to the database.
- DELETE: This one's pretty self explanatory. You make a delete request when you want to remove something. If you want to remove a post, your browser makes a delete request. Then the server reads it and removes it from a database.
Since we're only fetching pages, all we need are GET requests. This is really easy with Python. Take a look at the snippet below.
import requests
response = requests.get("https://www.duckduckgo.com")
#do stuff with the response
print(response.status_code)
print(response.text)
Here is our target page. As you can see in the address bar, our URL is:
https://duckduckgo.com/?t=h_&q=learn+rust&ia=web
The portion you really need to pay attention to here is q=learn+rust. When we make a query for multiple words (learn rust), our space gets replaced with a +.
Our full target URL will look like this:
https://duckduckgo.com/?q={formatted_keyword}&t=h_&ia=web

Step 2: How To Extract Data From Results and Pages
Next, we need to understand how to extract our desired data. Go ahead inspect the page in your browser. As you can see below, we have a couple elements and they're nested within an h2.
Our h2 includes:
a: This is the link to the site.span: This includes the text for the actual headline.
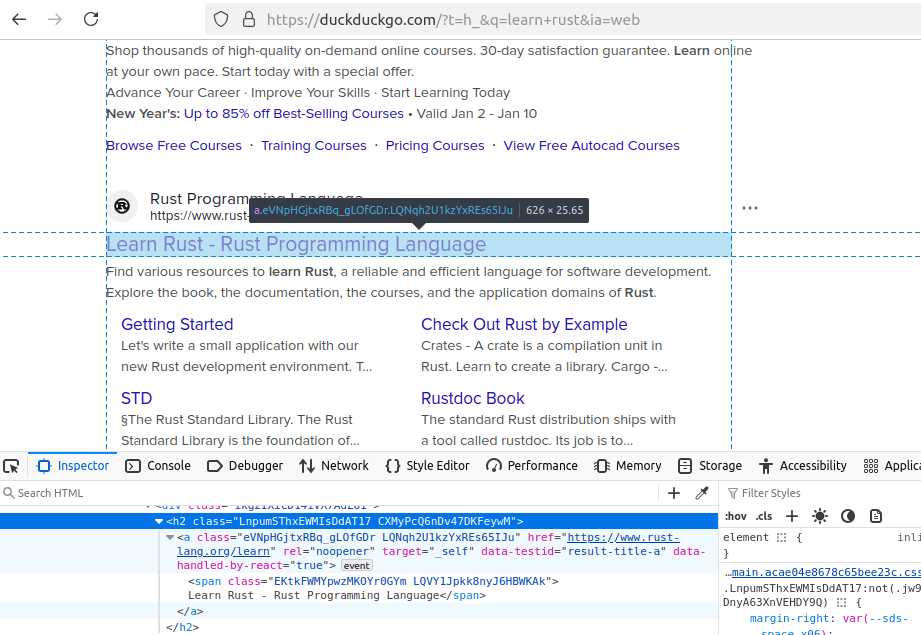
We'll use BeautifulSoup in order to parse our results. Take a look at the snippet below.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.duckduckgo.com")
#do stuff with the response
soup = BeautifulSoup(response.text, "html.parser")
#our parsing logic goes here
Step 3: How To Control Pagination
DuckDuckGo actually doesn't support pagination. You can see evidence of this in a Reddit post below from one one of DuckDuckGo's developers. You can view the post yourself here.
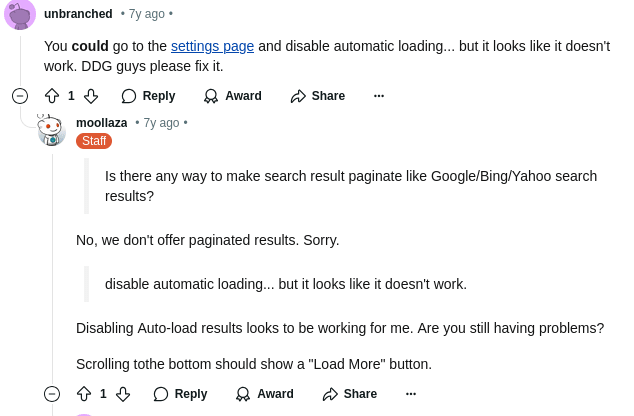
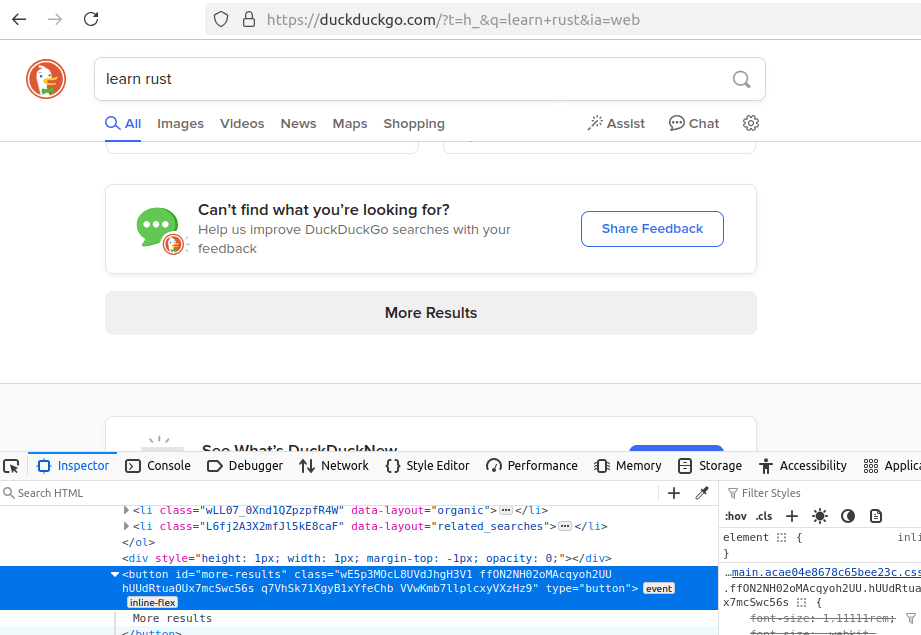
Upon further inspection, it does include a More Results button, but upon further inspection, it doesn't link to anything.
Theoretically, we could try to reverse engineer the API in order to get these results, but the complexity would defeat the purpose of our tutorial here.
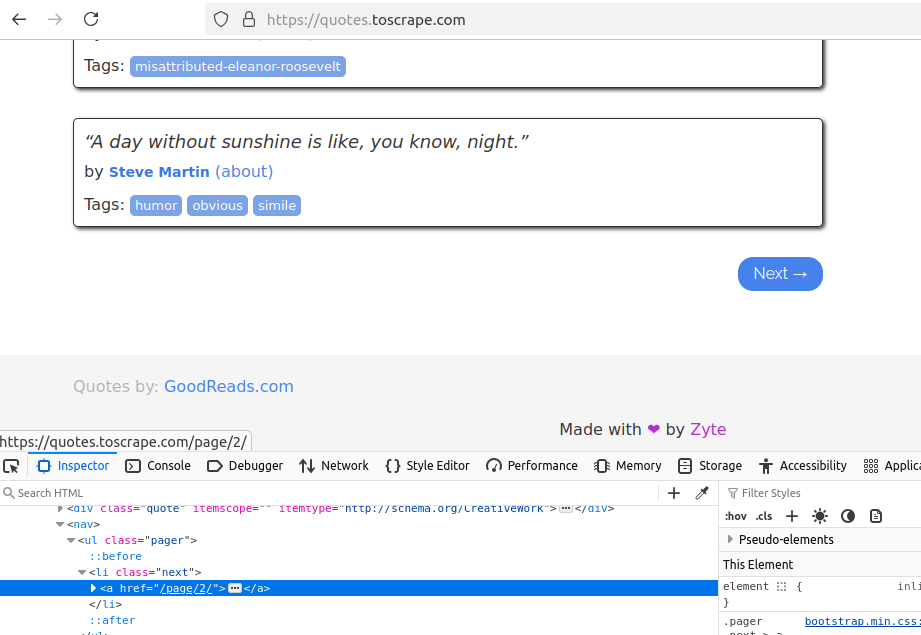
Here is an example from Quotes To Scrape.
- If you look at the Next button, it contains an
aelement linking to page 2. - The
hreftakes us to/page/2. - When using pagination in your crawler, you would extract this URL and then ping it next in order to get more search results.
Step 4: Geolocated Data
Some sites will serve different content based on your geolocation. When you're not using a proxy, your geolocation will show up at your actual house.
If you get an IP block, you're stuck and you can't even get the site. With a decent proxy service, you can actually control your geolocation.
Using Proxy Aggregator, you can actually pass in a country param to the API.
From this query param, Proxy Aggregator reads a 2 character country code and routes your request through the desired country.
You can view our list of fully supported countries below.
| Country | Country Code |
|---|---|
| Brazil | br |
| Canada | ca |
| China | cn |
| India | in |
| Italy | it |
| Japan | jp |
| France | fr |
| Germany | de |
| Russia | ru |
| Spain | es |
| United States | us |
| United Kingdom | uk |
If you'd like to learn more about our geotargeting abilities, you can read the docs here.
Step 5: Bypassing Anti-Bots
As we mentioned earlier, we'll be using Proxy Aggregator to control our geolocation. Proxy Aggregator will also get us past any anti-bots that get in our way.
With DuckDuckGo in particular, the site first checks your browser and loads the content dynamically.
As far as search engines go, this is very advanced compared to Google and Bing.
If you perform a search on DuckDuckGo, you'll notice that there's a slight lag before your content loads.
During this lag, DuckDuckGo is performing a check on your browser and then loading the content. This makes the site much more difficult to scrape.
In order to get past this, we need to render the content. Proxy Aggregator gives us a way to do this as well.
When we pass the wait param to Proxy Aggregator, it knows how long to wait for content to load. "wait": 5 tells Proxy Aggregator to render the page and wait 5 seconds for content to load.
Setting Up Our Scraper Project
Now, let's actually get started building. Follow these commands below to be up and running in minutes.
We'll show you how to create a new project, set up a virtual environment, and install our dependencies.
Create a new project folder.
mkdir duck-scraper
cd duck-scraper
Create a new virtual environment.
python -m venv venv
Activate the environment.
source venv/bin/activate
Install our dependencies.
pip install requests
pip install beautifulsoup4
Build A Python Crawler
Now, we're going learn how to build a crawler. As we mentioned before, the crawler needs to perform a search. Then, it needs to parse and save the results.
If you follow the steps below, you'll have a complete crawler in no time.
Step 1: Create Simple Search Data Parser
The code below contains our intial parser. As you can see, we have our imports, retry logic, and our basic parsing structure.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode, urlparse
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_search_results(keyword, location, retries=3):
formatted_keyword = keyword.replace(" ", "+")
result_number = 0
url = f"https://duckduckgo.com/?q={formatted_keyword}&t=h_&ia=web"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Received [{response.status_code}] from: {url}")
if response.status_code == 200:
success = True
else:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
headers = soup.find_all("h2")
for header in headers:
link = header.find("a")
h2 = header.text
if not link:
continue
href = link.get("href")
rank = result_number
parsed_url = urlparse(href)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
search_data = {
"name": h2,
"base_url": base_url,
"url": href,
"result_number": rank
}
print(search_data)
result_number += 1
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
scrape_search_results(keyword, LOCATION, retries=MAX_RETRIES)
logger.info(f"Crawl complete.")
The parsing logic here is unique to DuckDuckGo. When you're building your own framework, there are some other things you should pay attention to in this code.
formatted_keyword: This removes spaces from your search parameters so the server can properly read them.while tries <= retries and not success:: This statement contains all of our actual scraping logic.whilewe still havetriesleft, we keep attempting to perform our scraping operation. Once this operation has succeeded, we setsuccesstoTrue, which allows us to exit the loop.- In the event of an
Exception, we increment ourtriesand log the error that occurred. - Our
mainholds all of our configuration variables. These are used to tweak and control the scraper later on:MAX_RETRIESMAX_THREADSLOCATION
- Next, our actual runtime gets executed by running a
forloop on ourkeywordsarray.
Step 2: Storing the Scraped Data
Once your parser is extracting data, it needs to actually store that data.
First, you're going to need a class to represent your data.
- Below is our
SearchDataclass. - When using a
dataclass, you can create a strongly typed object in order to represent your data. - This is far safer than using a simple
dictbecause it can account for missing fields and makes sure that your data is properly formatted. - If you're extracting product information, you might have a different set of fields such as
name,sku,price,urletc.
@dataclass
class SearchData:
name: str = ""
base_url: str = ""
url: str = ""
result_number: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
Next, we need a pipeline that controls our data. The snippet below holds our DataPipeline.
The purpose of this pipeline is simple: hold an array of dataclass objects and save them to your desired storage.
In the example below, the save() method executes our save_to_csv() function. These two functions are separated so we can add other storage methods later on.
class DataPipeline:
def __init__(self, filename="", storage_queue_limit=50, output_format="csv"):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.filename = filename
self.file_open = False
self.output_format = output_format.lower()
def save_to_csv(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.filename) and os.path.getsize(self.filename) > 0
with open(self.filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.file_open:
self.save()
def save(self):
if self.output_format == "csv":
self.save_to_csv()
else:
raise ValueError(f"Unsupported output format: {self.output_format}")
def close_pipeline(self):
if self.file_open:
time.sleep(3)
if self.storage_queue:
self.save()
__init__: Instantiates the class.save_to_csv(): Saves ourstorage_queueto a CSV file.is_duplicate(): Recognizes any duplicates within the queue and drops them before they get stored.add_data(): This method allows us to adddataclassobjects to the queue for later storage.save(): For the moment, this just runssave_to_csv(). If we wish to add other storage methods,save()will be used to discern which function to execute and then execute it.close_pipeline(): This checks to see if there is a storage file open, then it waits 3 seconds for any unfinished jobs to complete. Afterward, if there is anything left in the storage queue, it gets stored with thesave()method.
You can view the full code up to this point below.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode, urlparse
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
base_url: str = ""
url: str = ""
result_number: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, filename="", storage_queue_limit=50, output_format="csv"):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.filename = filename
self.file_open = False
self.output_format = output_format.lower()
def save_to_csv(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.filename) and os.path.getsize(self.filename) > 0
with open(self.filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.file_open:
self.save()
def save(self):
if self.output_format == "csv":
self.save_to_csv()
else:
raise ValueError(f"Unsupported output format: {self.output_format}")
def close_pipeline(self):
if self.file_open:
time.sleep(3)
if self.storage_queue:
self.save()
def scrape_search_results(keyword, location, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
result_number = 0
url = f"https://duckduckgo.com/?q={formatted_keyword}&t=h_&ia=web"
tries = 0
success = False
while tries <= retries and not success:
try:
response = requests.get(url)
logger.info(f"Received [{response.status_code}] from: {url}")
if response.status_code == 200:
success = True
else:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
headers = soup.find_all("h2")
for header in headers:
link = header.find("a")
h2 = header.text
if not link:
continue
href = link.get("href")
rank = result_number
parsed_url = urlparse(href)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
search_data = SearchData(
name=h2,
base_url=base_url,
url=href,
result_number=rank
)
data_pipeline.add_data(search_data)
result_number += 1
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Our main changes slightly here as well.
- First, we create a
DataPipeline:crawl_pipeline = DataPipeline(filename=f"{filename}.csv"). - Our pipeline then gets passed into our crawler function:
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES). - Once the job has finished, we close the pipeline.
- We add the finished file to our
aggregate_filesarray. This array isn't necessarily a requirement for your scraper, but we'll use it to run our scraping function later on.
Step 3: Bypassing Anti-Bots
Now, we need to add the functionality we mentioned earlier when talking about geotargeting and anti-bots.
Take a look at the function below. This is our standard proxy function that you'd use with Proxy Aggregator.
We take in our required parameters: api_key, url, and country.
def get_scrapeops_url(url, location="us", wait=None):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
However, with more complicated sites, we need to do other things like render JavaScript content.
To do this, we'll add the wait parameter. We don't need to render dynamic content on all sites when running the scraper, but we do need to render it for our crawler.
We'll add a kwarg here for our wait time. It defaults to None, so normally, we won't render the content. If you decide to pass in wait=5, Proxy Aggregator will wait for 5 seconds.
If you don't pass anything into wait, Proxy Aggregator won't wait at all.
def get_scrapeops_url(url, location="us", wait=None):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
if wait:
payload["wait"] = wait
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
Our full code is available below. Aside from our proxy function, not much has really changed. We use to now create a scrapeops_proxy_url.
Then we perform our GET request to the newly proxied URL.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode, urlparse
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us", wait=None):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
if wait:
payload["wait"] = wait
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
base_url: str = ""
url: str = ""
result_number: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, filename="", storage_queue_limit=50, output_format="csv"):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.filename = filename
self.file_open = False
self.output_format = output_format.lower()
def save_to_csv(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.filename) and os.path.getsize(self.filename) > 0
with open(self.filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.file_open:
self.save()
def save(self):
if self.output_format == "csv":
self.save_to_csv()
else:
raise ValueError(f"Unsupported output format: {self.output_format}")
def close_pipeline(self):
if self.file_open:
time.sleep(3)
if self.storage_queue:
self.save()
def scrape_search_results(keyword, location, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
result_number = 0
url = f"https://duckduckgo.com/?q={formatted_keyword}&t=h_&ia=web"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location, wait=5)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Received [{response.status_code}] from: {url}")
if response.status_code == 200:
success = True
else:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
headers = soup.find_all("h2")
for header in headers:
link = header.find("a")
h2 = header.text
if not link:
continue
href = link.get("href")
rank = result_number
parsed_url = urlparse(href)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
search_data = SearchData(
name=h2,
base_url=base_url,
url=href,
result_number=rank
)
data_pipeline.add_data(search_data)
result_number += 1
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Step 4: Production Run
Now, let's run this thing and test it out. Double check the variables in your main to make sure your settings are configured to your liking. Here's ours.
MAX_RETRIES: The amount of times your crawler will try unsuccessfully before giving up.MAX_THREADS: This variable currently goes unused. Later on, when we run our scrape on a bunch of different sites, this will be used to run multiple jobs concurrently.LOCATION: This gets passed into our crawler function and in turn, our proxy function in order to control our geolocation with Proxy Aggregator.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
Here are our results.

Build A Python Scraper
Now that your crawler's generating a proper report, it's time to build the scraper component of the project.
Your scraper is going to read the crawler report and find look up each individual site from the report.
Follow the steps below and learn how to add things in one step at a time.
Step 1: Create Simple Result Data Parser
Now, you need to perform a scrape on every url that you stored in your crawler report. In our case, we're looking up a ton of different sites all with different structure. Because of this, we're going to focus on the metadata.
In your own project, you'll probably be focusing on product information such as reviews, detailed specs or something similar.
Here is our parsing function. Like our earlier parser, we use a while loop with some basic error handling to help ensure success.
You actual parsing logic will be different from ours but conceptually its the same as this one and our first one.
def process_result(row, location, retries=3):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
head = soup.find("head")
title = head.find("title").text
meta_tags = head.find_all("meta")
description = "n/a"
description_holder = head.select_one("meta[name='description']")
if description_holder:
description = description_holder.get("content")
meta_data = {
"name": title,
"url": row["url"],
"description": description
}
print(meta_data)
success = True
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
Once again, there are a few key factors that every parsing function should rely on.
- Use a
whileloop in order to ensure success and retry things when they fail. - Use a
triesvariables to keep track of how many tries you're willing to execute. This is exactly the same as a basic counter you might have made when you first started coding. - Create a
BeautifulSoupobject out of your response. This allows you to easily parse portions of the HTML page.
Step 2: Loading URLs To Scrape
Before you can actually use the parsing function you just wrote, you need a url to pass into it. We'll accomplish this by writing a function that reads our CSV file.
def process_results(csv_file, location, max_threads=5, retries=3):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_result(row, location, retries=retries)
csv.DictReader()reads our entire CSV file into an array ofdictobjects.- We use a
forloop to runprocess_result()on each of the rows from the file.
Remember the aggregate_files array? Now, we'll actually do something with it. We'll add a couple lines to our main.
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES)
Step 3: Storing the Scraped Data
Your scraper component will also need a way to store its extracted data. We'll do some more work on our classes. We'll write a new dataclass and then we'll add a new function to our DataPipeline.
Here's our new dataclass. We'll call it MetaData. This class is more or less the same as SearchData.
The only real difference is our fields, we now have: name, url, and description. Your dataclass will differ based on the information you want to scrape.
@dataclass
class MetaData:
name: str = ""
url: str = ""
description: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
Now, we'll add a save_to_json() method to our DataPipeline. You can add whichever methods you want to your pipeline. The purpose here is to show that you might have multiple formats for storing your data.
Feel free to write your own custom storage functions.
def save_to_json(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
file_exists = os.path.isfile(self.filename)
existing_data = []
if file_exists:
with open(self.filename, "r", encoding="utf-8") as existing_file:
try:
existing_data = json.load(existing_file)
except json.JSONDecodeError:
logger.error(f"Corrupted JSON file: {self.filename}")
raise
existing_data.extend(asdict(item) for item in data_to_save)
with open(self.filename, "w", encoding="utf-8") as output_file:
json.dump(existing_data, output_file, indent=4)
self.file_open = False
Our fully updated code is available below. Take a look at the overall structure. We're almost done!
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode, urlparse
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us", wait=None):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
if wait:
payload["wait"] = wait
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
base_url: str = ""
url: str = ""
result_number: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class MetaData:
name: str = ""
url: str = ""
description: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, filename="", storage_queue_limit=50, output_format="csv"):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.filename = filename
self.file_open = False
self.output_format = output_format.lower()
def save_to_csv(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.filename) and os.path.getsize(self.filename) > 0
with open(self.filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.file_open = False
def save_to_json(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
file_exists = os.path.isfile(self.filename)
existing_data = []
if file_exists:
with open(self.filename, "r", encoding="utf-8") as existing_file:
try:
existing_data = json.load(existing_file)
except json.JSONDecodeError:
logger.error(f"Corrupted JSON file: {self.filename}")
raise
existing_data.extend(asdict(item) for item in data_to_save)
with open(self.filename, "w", encoding="utf-8") as output_file:
json.dump(existing_data, output_file, indent=4)
self.file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.file_open:
self.save()
def save(self):
if self.output_format == "csv":
self.save_to_csv()
elif self.output_format == "json":
self.save_to_json()
else:
raise ValueError(f"Unsupported output format: {self.output_format}")
def close_pipeline(self):
if self.file_open:
time.sleep(3)
if self.storage_queue:
self.save()
def scrape_search_results(keyword, location, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
result_number = 0
url = f"https://duckduckgo.com/?q={formatted_keyword}&t=h_&ia=web"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location, wait=5)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Received [{response.status_code}] from: {url}")
if response.status_code == 200:
success = True
else:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
headers = soup.find_all("h2")
for header in headers:
link = header.find("a")
h2 = header.text
if not link:
continue
href = link.get("href")
rank = result_number
parsed_url = urlparse(href)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
search_data = SearchData(
name=h2,
base_url=base_url,
url=href,
result_number=rank
)
data_pipeline.add_data(search_data)
result_number += 1
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def process_result(row, location, retries=3, data_pipeline=None):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(url)
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
head = soup.find("head")
title = head.find("title").text
meta_tags = head.find_all("meta")
description = "n/a"
description_holder = head.select_one("meta[name='description']")
if description_holder:
description = description_holder.get("content")
meta_data = MetaData(
name=title,
url=row["url"],
description=description
)
data_pipeline.add_data(meta_data)
success = True
data_pipeline.close_pipeline()
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3, data_pipeline=None):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
for row in reader:
process_result(row, location, retries=retries, data_pipeline=data_pipeline)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
metadata_pipeline = DataPipeline("metadata-report.json", output_format="json")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES, data_pipeline=metadata_pipeline)
Step 4: Adding Concurrency
With concurrency, you can perform multiple operations simultaneously. As you already know, when we parse a page, we need to perform a GET request.
Often with these GET requests, we're waiting valuable seconds for response before we can make our next request.
When we perform these tasks concurrently, we set a limit and we can perform tasks up to this limit. For example, if we set our limit at 5, we'll perform up to 5 GET requests all at once.
In order to implement this, we need to import Python's built-in concurrent.futures. This allows us to open a new pool a concurrency limit of our max_threads. concurrent.futures.ThreadPoolExecutor(max_workers=5) will open up a thread pool with a maximum of 5 threads at once.
We'll use ThreadPoolExecutor to replace the for loop we've been using in process_results().
def process_results(csv_file, location, max_threads=5, retries=3, data_pipeline=None):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_result,
reader,
[location] * len(reader),
[retries] * len(reader),
[data_pipeline] * len(reader)
)
We pass all of the following aruments into ThreadPoolExecutor.
process_result: This is the function that we want to call on multiple threads.reader: This is the array ofdictobjects that we read from the CSV file. This tellsThreadPoolExecutorto runprocess_resulton every row from the array.location,retries, anddata_piplineall get passed in as arrays the length of thereader.
Step 5: Bypassing Anti-Bots
We've already written our proxy function. Since we're not loading dynamic content from any of these sites, this time, we'll leave the wait kwarg alone.
We only need to change one line to add our proxy integration to this scraping function.
response = requests.get(get_scrapeops_url(url, location=location))
The completed project is available below.
import os
import csv
import requests
import json
import logging
from urllib.parse import urlencode, urlparse
from bs4 import BeautifulSoup
import concurrent.futures
from dataclasses import dataclass, field, fields, asdict
API_KEY = ""
with open("config.json", "r") as config_file:
config = json.load(config_file)
API_KEY = config["api_key"]
def get_scrapeops_url(url, location="us", wait=None):
payload = {
"api_key": API_KEY,
"url": url,
"country": location,
}
if wait:
payload["wait"] = wait
proxy_url = "https://proxy.scrapeops.io/v1/?" + urlencode(payload)
return proxy_url
## Logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class SearchData:
name: str = ""
base_url: str = ""
url: str = ""
result_number: int = 0
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
@dataclass
class MetaData:
name: str = ""
url: str = ""
description: str = ""
def __post_init__(self):
self.check_string_fields()
def check_string_fields(self):
for field in fields(self):
if isinstance(getattr(self, field.name), str):
if getattr(self, field.name) == "":
setattr(self, field.name, f"No {field.name}")
continue
value = getattr(self, field.name)
setattr(self, field.name, value.strip())
class DataPipeline:
def __init__(self, filename="", storage_queue_limit=50, output_format="csv"):
self.names_seen = []
self.storage_queue = []
self.storage_queue_limit = storage_queue_limit
self.filename = filename
self.file_open = False
self.output_format = output_format.lower()
def save_to_csv(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
keys = [field.name for field in fields(data_to_save[0])]
file_exists = os.path.isfile(self.filename) and os.path.getsize(self.filename) > 0
with open(self.filename, mode="a", newline="", encoding="utf-8") as output_file:
writer = csv.DictWriter(output_file, fieldnames=keys)
if not file_exists:
writer.writeheader()
for item in data_to_save:
writer.writerow(asdict(item))
self.file_open = False
def save_to_json(self):
self.file_open = True
data_to_save = self.storage_queue[:]
self.storage_queue.clear()
if not data_to_save:
return
file_exists = os.path.isfile(self.filename)
existing_data = []
if file_exists:
with open(self.filename, "r", encoding="utf-8") as existing_file:
try:
existing_data = json.load(existing_file)
except json.JSONDecodeError:
logger.error(f"Corrupted JSON file: {self.filename}")
raise
existing_data.extend(asdict(item) for item in data_to_save)
with open(self.filename, "w", encoding="utf-8") as output_file:
json.dump(existing_data, output_file, indent=4)
self.file_open = False
def is_duplicate(self, input_data):
if input_data.name in self.names_seen:
logger.warning(f"Duplicate item found: {input_data.name}. Item dropped.")
return True
self.names_seen.append(input_data.name)
return False
def add_data(self, scraped_data):
if not self.is_duplicate(scraped_data):
self.storage_queue.append(scraped_data)
if len(self.storage_queue) >= self.storage_queue_limit and not self.file_open:
self.save()
def save(self):
if self.output_format == "csv":
self.save_to_csv()
elif self.output_format == "json":
self.save_to_json()
else:
raise ValueError(f"Unsupported output format: {self.output_format}")
def close_pipeline(self):
if self.file_open:
time.sleep(3)
if self.storage_queue:
self.save()
def scrape_search_results(keyword, location, data_pipeline=None, retries=3):
formatted_keyword = keyword.replace(" ", "+")
result_number = 0
url = f"https://duckduckgo.com/?q={formatted_keyword}&t=h_&ia=web"
tries = 0
success = False
while tries <= retries and not success:
try:
scrapeops_proxy_url = get_scrapeops_url(url, location=location, wait=5)
response = requests.get(scrapeops_proxy_url)
logger.info(f"Received [{response.status_code}] from: {url}")
if response.status_code == 200:
success = True
else:
raise Exception(f"Failed request, Status Code {response.status_code}")
## Extract Data
soup = BeautifulSoup(response.text, "html.parser")
headers = soup.find_all("h2")
for header in headers:
link = header.find("a")
h2 = header.text
if not link:
continue
href = link.get("href")
rank = result_number
parsed_url = urlparse(href)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
search_data = SearchData(
name=h2,
base_url=base_url,
url=href,
result_number=rank
)
data_pipeline.add_data(search_data)
result_number += 1
logger.info(f"Successfully parsed data from: {url}")
success = True
except Exception as e:
logger.error(f"An error occurred while processing page {url}: {e}")
logger.info(f"Retrying request for page: {url}, retries left {retries-tries}")
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
def process_result(row, location, retries=3, data_pipeline=None):
url = row["url"]
tries = 0
success = False
while tries <= retries and not success:
response = requests.get(get_scrapeops_url(url, location=location))
try:
if response.status_code == 200:
logger.info(f"Status: {response.status_code}")
soup = BeautifulSoup(response.text, "html.parser")
head = soup.find("head")
title = head.find("title").text
meta_tags = head.find_all("meta")
description = "n/a"
description_holder = head.select_one("meta[name='description']")
if description_holder:
description = description_holder.get("content")
meta_data = MetaData(
name=title,
url=row["url"],
description=description
)
data_pipeline.add_data(meta_data)
success = True
data_pipeline.close_pipeline()
else:
logger.warning(f"Failed Response: {response.status_code}")
raise Exception(f"Failed Request, status code: {response.status_code}")
except Exception as e:
logger.error(f"Exception thrown: {e}")
logger.warning(f"Failed to process page: {row['url']}")
logger.warning(f"Retries left: {retries-tries}")
tries += 1
if not success:
raise Exception(f"Max Retries exceeded: {retries}")
else:
logger.info(f"Successfully parsed: {row['url']}")
def process_results(csv_file, location, max_threads=5, retries=3, data_pipeline=None):
logger.info(f"processing {csv_file}")
with open(csv_file, newline="") as file:
reader = list(csv.DictReader(file))
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
executor.map(
process_result,
reader,
[location] * len(reader),
[retries] * len(reader),
[data_pipeline] * len(reader)
)
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
metadata_pipeline = DataPipeline("metadata-report.json", output_format="json")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES, data_pipeline=metadata_pipeline)
Step 6: Production Run
Now, we're going to give the entire project a test run and see how things will look in production. Take a look at our main again.
As mentioned throughout this article, yours will probably be different. Change any of the following variables to tweak your scraper.
MAX_RETRIESMAX_THREADSLOCATION
if __name__ == "__main__":
MAX_RETRIES = 3
MAX_THREADS = 5
LOCATION = "us"
logger.info(f"Crawl starting...")
## INPUT ---> List of keywords to scrape
keyword_list = ["learn rust"]
aggregate_files = []
## Job Processes
for keyword in keyword_list:
filename = keyword.replace(" ", "-")
crawl_pipeline = DataPipeline(filename=f"{filename}.csv")
scrape_search_results(keyword, LOCATION, data_pipeline=crawl_pipeline, retries=MAX_RETRIES)
crawl_pipeline.close_pipeline()
aggregate_files.append(f"{filename}.csv")
logger.info(f"Crawl complete.")
metadata_pipeline = DataPipeline("metadata-report.json", output_format="json")
for file in aggregate_files:
process_results(file, LOCATION, max_threads=MAX_THREADS, retries=MAX_RETRIES, data_pipeline=metadata_pipeline)
Our project generated a CSV file with 10 results. If you remember earlier, it did this in 6.435 seconds. The entire crawl and scrape finished in 47.926 seconds. 47.926-6.435 = 41.491 seconds scraping. 41.491/10 results = 4.1491 seconds per page.

If you'd like to view the information we scraped, take a look below to see the CSV file our crawler generated.
name,base_url,url,result_number
Learn Rust - Rust Programming Language,https://www.rust-lang.org,https://www.rust-lang.org/learn,0
Take your first steps with Rust - Training | Microsoft Learn,https://learn.microsoft.com,https://learn.microsoft.com/en-us/training/paths/rust-first-steps/,1
The Rust Programming Language - The Rust Programming Language - Learn Rust,https://doc.rust-lang.org,https://doc.rust-lang.org/stable/book/,2
Getting started - Rust Programming Language,https://www.rust-lang.org,https://www.rust-lang.org/learn/get-started,3
How to Learn Rust in 2024: A Complete Beginner's Guide to Mastering ...,https://blog.jetbrains.com,https://blog.jetbrains.com/rust/2024/09/20/how-to-learn-rust/,4
Introduction - Rust By Example - Learn Rust,https://doc.rust-lang.org,https://doc.rust-lang.org/stable/rust-by-example/,5
Rust for Programmers - Codecademy,https://www.codecademy.com,https://www.codecademy.com/learn/rust-for-programmers,6
Programming with Rust | Coursera,https://www.coursera.org,https://www.coursera.org/specializations/programming-with-rust,7
Rust Programming Essentials - Coursera,https://www.coursera.org,https://www.coursera.org/learn/rust-programming-essentials,8
Rust Fundamentals - Coursera,https://www.coursera.org,https://www.coursera.org/learn/rust-fundamentals,9
If you'd like to see the JSON created by the scraper, take a look at the next snippet.
[
{
"name": "Getting started - Rust Programming Language",
"url": "https://www.rust-lang.org/learn/get-started",
"description": "A language empowering everyone to build reliable and efficient software."
},
{
"name": "Learn Rust - Rust Programming Language",
"url": "https://www.rust-lang.org/learn",
"description": "A language empowering everyone to build reliable and efficient software."
},
{
"name": "The Rust Programming Language - The Rust Programming Language",
"url": "https://doc.rust-lang.org/stable/book/",
"description": "No description"
},
{
"name": "Take your first steps with Rust - Training | Microsoft Learn",
"url": "https://learn.microsoft.com/en-us/training/paths/rust-first-steps/",
"description": "Interested in learning a new programming language that's growing in use and popularity? Start here! Lay the foundation of knowledge you need to build fast and effective programs in Rust."
},
{
"name": "Introduction - Rust By Example",
"url": "https://doc.rust-lang.org/stable/rust-by-example/",
"description": "Rust by Example (RBE) is a collection of runnable examples that illustrate various Rust concepts and standard libraries."
},
{
"name": "Rust for Programmers | Codecademy",
"url": "https://www.codecademy.com/learn/rust-for-programmers",
"description": "A quick primer on the fundamentals of the Rust programming language for experienced programmers."
},
{
"name": "Programming with Rust | Coursera",
"url": "https://www.coursera.org/specializations/programming-with-rust",
"description": "Offered by Edureka. Unlock the power of Rust! Master efficient coding, memory management, and concurrency through hands-on projects. Tackle ... Enroll for free."
},
{
"name": "Rust Programming Essentials | Coursera",
"url": "https://www.coursera.org/learn/rust-programming-essentials",
"description": "Offered by Edureka. The \"Rust Programming Essentials\" course aims to empower learners with the fundamental skills and knowledge necessary ... Enroll for free."
},
{
"name": "Rust Fundamentals | Coursera",
"url": "https://www.coursera.org/learn/rust-fundamentals",
"description": "Offered by Duke University. This comprehensive Rust programming course welcomes learners of all levels, including beginners and those with ... Enroll for free."
}
]
Legal and Ethical Considerations
When you decide to make any scraping project, you need to take a few things under consideration. The biggest ones are legal and ethical.
There are certain times when scraping can cause legal issues for you ranging from fines to even prison time. Even if you're not breaking the law, you need to think about a few things ethically as well.
Here are a couple files that are important regarding DuckDuckGo.
Legal
- Don't Scrape Private Data: In this tutorial, we scraped publicly available data without signing in. When you choose to scrape authenticated data (data behind a login), your are subject to a whole slew of internet privacy and intellectual property laws that change all over the world depending on jurisdiction.
- Scrape Public Data: When data is already available publicly, scraping it is no different that taking a picture of a public billboard.
- Don't Disseminate Private Data: If you do collect data about individual people, don't share it with the web. This is a violation of privacy law all over the place and you can even go to jail for it.
- Terms of Service: In most cases, terms of service are legally binding. If you sign a TOS with a company, and then you violate the policies you agreed to, you can be subject to lawsuits and more. Your account can also be deleted or suspended from the site.
Ethical
- robots.txt: Pay close attention to the
robots.txtfile of the site you're scraping. While not legally binding, these are the rules they set for robots accessing their site. If you choose not to respect it, be prepared to get banned. - Social Media Stalking: Even if you're scraping a public site and somebody's public profile, this can sometimes equate to the feeling of being stalked. How would you feel if someone routinely scraped one of your socials?
Conclusion
Congratulations! You now know how to make your own scraping framework. You should understand the basics of both Requests and BeautifulSoup.
With parsing, pagination, data storage, concurrency and proxy integration, you have all the tools you need to go forward and harvest data from the web.
If you'd like to know more about the tech stack used in this article, check out the links below.
More Python Web Scraping Guides
Here at ScrapeOps, we love scraping the web. We wrote the Python Web Scraping Playbook. Whether you're just starting out or you've been scraping for years, we have something for you.
If you'd like a taste, check out the links below.